Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
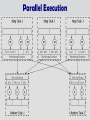
MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat Google, Inc. Presented by Saleh Alnaeli At Kent State University Fall 2010 Advance Database systems course. Prof. Ruoming Jin. Goals Introduction Programming Model Implementation & model features Refinements Performance Evaluation Conclusion What is Map-Reduce? Programming Model, approach, for processing large data sets. Contains Map and Reduce functions. Runs on a large cluster of commodity machines. Many real world tasks are expressible in this model. Programming model Input & Output are sets of key/value pairs Programmer specifies two functions: map (in_key, in_value) -> list(out_key, intermediate_value) reduce (out_key, list(intermediate_value)) -> list(out_value) Combines all intermediate values for a particular key Produces a set of merged output values (usually just one) Example1 : count words in docs Input consists of (url, contents) pairs map(key=url, val=contents): For each word w in contents, emit (w, “1”) reduce(key=word, Sum values=uniq_counts): all “1”s in values list Emit result “(word, sum)” Example1: Cont. map(key=url, val=contents): For each word w in contents, emit (w, “1”) reduce(key=word, values=uniq_counts): Sum all “1”s in values list Emit result “(word, sum)” Doc1: Jin is doing well MAP Doc2: Jin is active Jin Is doing well Jin Is Active 1 Active 1 doing 1 Reduce Is 1 Jin 1 well 1 1 1 1 2 2 1 Model is Widely Applicable MapReduce Programs In Google Source Tree More Example distributed grep (later) distributed sort (later) Reverse web link-graph term-vector / host URL access frequency inverted index And many ……. Implementation Many different implementations are possible The right choice is depending on the environment. Typical cluster: (wide use at Google, large clusters of PC’s connected via switched nets) Hundreds to thousands of dual-processors x86 machines, Linux, 2-4 GB of memory per machine. connected with networking HW, Limited bisection bandwidth Storage is on local IDE disks (inexpensive) GFS: distributed file system manages data Scheduling system by the users to submit the tasks (Job=set of tasks mapped by scheduler to set of available PC within the cluster) Implemented using C++ library and linked into user programs Execution Overview Map and reduce invocations are distributed across multiple PC’s as follows: I. II. III. Partition input key/value pairs into M chunks, run map() tasks in parallel After map()’s are complete, merge all emitted values for each emitted intermediate key then partition space of output map keys into R pieces( user), and run reduce() in parallel. If map() or reduce() fails, fault tolerance technique is used, coming in next slides. Maser keeps several data structures for each map and reduce task. (State, worker Id) The master pings every worker periodically (no response -> worker marked as failed) Execution Overview Execution set of intermediate key/value pairs merges all intermediate values associated with the same intermediate key. Parallel Execution Fault Tolerance Works: Handled through re-execution Detect failure via periodic heartbeats Re-execute completed + in-progress map tasks Why do we need to re-execute even the completed tasks? Re-execute in progress reduce tasks Task completion committed through master Master failure: It can be handled, but don't yet (master failure unlikely) Locality Master scheduling policy: Asks GFS for locations of replicas of input file blocks Map tasks typically split into 64MB (GFS block size) Map tasks scheduled so GFS input block replica are on same machine or same rack As a result: most task’s input data is read locally and consumes no network bandwidth Backup Tasks common causes that lengthens the total time taken for a MapReduce operation is a straggler. mechanism to alleviate the problem of stragglers. the master schedules backup executions of the remaining in-progress tasks. significantly reduces the time to complete large MapReduce operations.( up to 40% ) Refinement Different partitioning functions. Combiner function. Master asks next worker is told to skip the bad record Local execution. Useful for saving network bandwidth Different input/output types. Skipping bad records. User specify the number of reduce tasks/output that they desire (R). an alternative implementation of the MapReduce library that sequentially executes all of the work for a MapReduce operation on the local machine. Status info. Progress of the computation & more info… Counters. count occurrences of various events. (Ex: total number of words processed) Performance measure the performance of MapReduce on two computations running on a large cluster of machines. MR_GrepScan searches through approximately one terabyte of data looking for a particular pattern MR_Sort sorts approximately one terabyte of data Performance Cont. Tests run on : Specifications Cluster 1800 machines Memory 4 GB Processors Hard disk Dual-processor 2 GHz Xeons with Hyper-threading Dual 160 GB IDE disks Network Gigabit Ethernet per machine bandwidth approximately 100 Gbps MR_Grep Data Transfer rate over time Scans 10 billions 100-byte records, searching for rare 3-character pattern (occurs in 92,337 records). input is split into approximately 64MB pieces (M = 15000), entire output is placed in one file , R = 1 Startup overhead is significant for short jobs MR_Sort Backup tasks improves completion time reasonably System manages machine failures relatively quickly. Experience & Conclusions More and more use of MapReduce approach. See the paper. MapReduce has proven to be a useful abstraction Greatly simplifies large-scale computations at Google Fun to use: focus on problem, let library deal with messy details No big need for parallelization knowledge (relief the user from dealing with low level parallelization details) Disadvantages Might be hard to Data parallelism express problem in MapReduce is key Need to be able to break up a problem by data chunks MapReduce is closed-source (to Google) C++ Hadoop is open-source Java-based rewrite Related Work HadoopDB: (An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads) [R4] a hybrid system that takes the best features from both technologies; the prototype approaches parallel databases in performance and efficiency, yet still yields the scalability, fault tolerance, and flexibility of MapReduce-based systems. FREERIDE (Framework for Rapid Implementation of Datamining Engines). [R3] a middleware for rapid development of data mining implementations on large SMPs and clusters of SMPs. The middleware performs distributed memory parallelization across the cluster and shared memory parallelization within each node. River (processes communicate with each other by sending data over distributed queues / similar in Dynamic load balancing) [R5] References J. Dean and S. Ghemawat. Dan Weld’s at U. Washington HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads [R4] Remzi H. Arpaci-Dusseau, Eric Anderson, Noah Treuhaft, David E. Culler, Joseph M. Hellerstein, David Patterson, and Kathy Yelick. Shared Memory Parallelization of Data Mining Algorithms: Techniques, Programming Interface, and Performance (pdf 2004) [R3] Azza Abouzeid, Kamil BajdaPawlikowski,Daniel Abadi, Avi Silberschatz, Alexander Rasin (tutorial & slides) Ruoming Jin, Ge Yang, and Gagan Agrawal MapReduce: Simplified Data Processing on Large Clusters. In OSDI, 2004. (Paper and slides) Cluster I/O with River: Making the fast case common. In Proceedings of the Sixth Workshop on Input/Output in Parallel and DistributedSystems (IOPADS '99), pages 10.22, Atlanta, Georgia, May 1999. [R4] Prof.Demmel inst.eecs.berkeley.edu/~cs61c http://gcu.googlecode.com/files/intermachine-parallelism-lecture.ppt Thank you! Questions and Comments?