Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
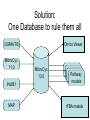
From annotated genomes to metabolic flux models Jeremy Zucker Broad Institute of MIT & Harvard August 25, 2009 Outline • Metabolic flux models – Tuberculosis • Annotating genomes – Rhodococcus opacus – Neurospora crassa E-flux • Goal: To Predict the effect of drugs on growth using expression data and flux models • Resources: – Boshoff compendium – Mycolic acid pathway • Solution: use differential gene expression to differentially constrain flux limits E-flux results • Our method successfully identifies 7 of the 8 known mycolic acid inhibitors in a compendium of 235 conditions, • identifies the top anti-TB drugs in this dataset . Future Tuberculosis Goals To model hypoxia-induced persistence using: Proteomics, Metabolomics, Transcriptomics Fluxomics Glycomics Lipidomics TB Resources • • • • • 3 FBA models, Chemostat experiments 27 genomes sequenced in TBDB On-site TBDB curator. Systems Biology of TB omics data Solution: One Database to rule them all GSMN-TB MtbrvCyc 11.0 iNJ661 MAP Omics Viewer MtbrvCyc 13.0 Pathway models rFBA models Comparative analysis of Mtb metabolic models GSMN-TB iNJ661 MAP Citations 141 99 23 Metabolites 739 740 197 Reactions 849 939 219 Genes 726 661 28 Enzymes 587 543 18 Genes GSMN-TB 235 472 3 19 166 2 4 iNJ661 MAP Compounds GSMN-TB 440 281 0 18 440 1 178 iNJ661 MAP Citations GSMN-TB 118 21 0 78 iNJ661 0 2 21 MAP Reactions GSMN-TB 555 285 646 iNJ661 7 1 2 209 MAP Reconstructing Metabolic models with Pathway-tools • EC predictions from sequence • PGDB from Flux model • Automatically refining flux models based on phenotype data • Applying expression data to Flux models for Omics analysis EFICAz • Goal: Predict EC numbers for protein sequences with known confidence. • Resources: ENZYME, PFAM, PROSITE • Solution: homofunctional and heterofunctional MSA, FDR, SVM, SITbased precision. sbml2biocyc • Goal: Generate PGDB from FBA model • Resources: SBML model • Solution: – sbml2biocyc code to transform SBML data to generate • • • • reactions, metabolites, gene associations, citations for PGDB. Biohacker • Goal: search the space of metabolic models to find the ones that are most consistent with the phenotype data • Resources: – KO data. – Initial metabolic model. – EC confidence predictions • Solution: MILP algorithm. Omics viewer • Goal: Googlemaps-like interface for cellular overview that enables pasting flux, RNA expression, etc • Resources: – Pathway-tools source code – OpenLayers, – Flash, – Googlemaps API Rhodococcus opacus:Goals • To model lipid storage mechanism for biofuels. R. opacus: Resources • • • • • Sinsky lab Biolog data Expression data Genome sequence EC Predictor R. Opacus solution • Use EFICaz to make EC predictions • Use reachability analysis to guide outside-in model reconstruction • Use pathway curation to guide insideout model reconstruction • Can we do better? Neurospora crassa:Goals • Predict phenotype KO experiments N. crassa: Resources • • • • • Systems biology of Neurospora grant Extensive literature very dedicated community Genome sequence Ptools pipeline N. crassa: Solution • Inside-out method with Heather Hood • Outside-in method with MILP algorithm