Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
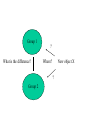
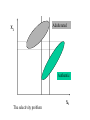
Classification Supervised and unsupervised Tormod Næs Matforsk and University of Oslo Classificaton • Unsupervised (cluster analysis) – Searching for groups in the data • Suspicion or general exploration – Hierarchical methods, partitioning methods • Supervised (discriminant analysis) – Groups determined by other information • External or from a cluster analysis – Understand differences between groups – Allocate new objects to the groups • Scoring, finding degree of membership Group 1 What is the difference? ? Where? New object X ? Group 2 Why supervised classification? • Authenticity studies – Adulteration, impurities, different origin, species etc. • Raw materials • Consumer products according to specification • When quality classes are more important than chemical values • raw materials acceptable or not • raw materials for different products Flow chart for discriminant analysis Main problems • Selectivity – Multivariate methods are needed • Collinearity – Data compression is needed • Complex group structures – Ellipses, squares or ”bananas”? X2 Adulterated Authentic The selectivity problem X1 Solving the selectivity problem • Using several measurements at the same time – The information is there! • Multivariate methods. These methods combine several instrumental NIR variables in order to determine the property of interest • Mathematical ”purification” instead of wet chemical analysis Multivariate methods Too many variables can also sometimes create problems – – – – Interpretation Computations, time and numerical stability Simple and difficult regions (nonlinearity) Overfitting is easier (dependentent on method used) • Sometimes important to find good compromises (variable selection) Conflict between flexibility and stability Estimation error Model error Some main classes of methods • Classical Bayes classification – LDA, QDA • Variants, modifications used to solve the collinearity problem – RDA, DASCO, SIMCA • Classification based on regression analysis – DPLS, DPCR • KNN methods, flexible with respect to shape of the groups Bayes classification • Assume prior probabilities pj for the groups – If unknown, fix them to be pj= 1/C or – equal to the proportions in the dataset • Assume known probability model within each class (fj(x)) – Estimated from the data, usually covariance matrices and means Bayes classification • + • • • • • well understood, much used, often good properties, easy to validate easy to modify for collinear data Easy to updated, covariances Can be modified for cost Outlier diagnostics (not directly, but can be done, M-distance) • • Can not handle too complex group structures, designed for elliptic structures • not so easy to interpret directly • often followed by a Fisher’s linear discriminant analysis. Directly related to interpreting differences between groups Bayes rule Maximise porterior probability Normal data, minimise 1 Li ( xi j ) j ( xi j ) log j 2 log j T Estimate model parameters, ˆL ( x ˆ )T ˆ 1 ( x ˆ ) log ˆ 2 log i i j j i j j j Mahalanobis distance plus determinant minus prior probability Different covariance structures Mahalanobis distance is constant on ellipsoids Best known members • Equal covariance matrix for each group – LDA • Unequal covariance matrices – QDA • Collinear data, unstable inverted covariance matrix (see equation) – Use principal components (or PLS components) – RDA, DASCO estimate stable inverse covariance matrices Classification by regression • 0,1 dummy variables for each group • Run PLS-2 (or PCR) or any other method which solves the collinearity • Predict class membership. – The class with the highest value gets the vote • All regular interpretation tools are available, variable selection, plotting outliers diagnostics etc. • Linear borders between subgroups, not too complicated groups. • Related to LDA, not covered here • If large data sets, we can use more flexible methods Example, classification of mayonnaise based on different oils Indahl et al (1999). Chemolab , Feasibility study, authenticity The oils were •soybean •sunflower •canola •olive •corn •grapeseed 16 samples in each group Start out low Classification properties of QDA, LDA and regression Comparison • LDA and QDA gave almost identical results • It was substantially better to use LDA/QDA based on PLS/PCA components instead of using PLS directly Fisher’s linear discriminant analysis • Closely related to LDA • Focuses on interpretation – Use “spectral loadings” or group averages • Finds the directions in space which distinguish the most between groups – Uncorrelated • Sensitive to overfitting, use PC’s first Fisher’s method. Næs, Isaksson, Fearn and Davies (2001). A user friendly guide to cal. and class. Plot of PC1 vs PC2 Not possible to distinguish the groups from each other Mayonnaise data, clear separation Canonical variates based on PC’s Italian wines from same region, but based on different cultivars, 27 chromatic and chemical variables Barbera Barolo Grignolino PCA Fisher’s method Forina et al(1986), Vitis Error rates Validated properly • LDA – Barolo 100%, Grignolino 97.7%, Barbera 100% • QDA – Barolo 100%, Grignolino 100%, Barbera100% KNN methods • No model assumptions • Therefore: needs data from “everywhere” and many data points • Flexible, complex data structures • Sensitive to overfitting, use PC’s New sample KNN, finds the N samples which are closest In this case 3 samples Cluster analysis Unsupervised classification • Identifying groups in the data – Explorative Examples of use • Forina et al(1982). Olive oil from different regions (fatty acid composition). Ann. Chim. • Armanino et al(1989), Olive oils from different Tuscan provinces (acids, sterols, alcohols). Chemolab. Methods • PCA (informal/graphical) – Look for structures in scores plots – Interpretation of subgroups using loadings plots • Hierarchical methods (more formal) – Based on distances between objects (Euclidean or Mahalanobis) – Join the two most similar – Interpret dendrograms 120 olive oils from one region in Italy, 29 variables (fatty acids, sterols, etc.) Armanino et al(1989), Chem.Int. lab. Systems.