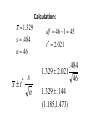Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
AP Statistics Section 8.3C CI for Population Mean When is Unknown In Section 8.3A, we constructed a confidence interval for the population mean when we knew the population standard deviation . It is extremely unlikely that we would actually know the population standard deviation, however. In this section, we will discover how to construct a confidence interval for an unknown population mean when we don’t know the standard deviation . We will do this by estimating from the data. This need to estimate with s introduces additional error into our calculations. To account for this, * we will use a critical value of t instead of z* when computing our confidence interval. Note the following properties of a t distribution: The density curves of the t distributions are similar in shape to the standard Normal, or z, distribution (i.e. bell - shaped and centered at zero Unlike the standard Normal distribution, there is a different t distribution for each sample size n. We specify a particular t distribution by giving its __________________ degrees of freedom ( _____ df ). When we perform inference about using a t distribution, the appropriate degrees of freedom is equal to ______. n - 1 We will write the t distribution with k degrees of freedom as _____. t(k) The spread of the t distributions is slightly greater than that of the z distribution. The t distributions are less concentrated around the mean and have more probability in the tails. This is what accounts for the increased error in using s instead of . As the degrees of freedom increase, the t curve approaches the standard Normal curve ever more closely. This happens because s approximates more accurately as the sample size increases. Table B, gives the values of t* for various degrees of freedom and various upper-tail probabilities. When the actual degrees of freedom does not appear in Table B, use the largest degrees of freedom that is less than your desired degrees of freedom. Example: Determine the appropriate value of t* for a confidence interval for with the given confidence level and sample size. a) 98% with n = 22 .01 .98 .01 df 22 1 21 t 2.518 Example: Determine the appropriate value of t* for a confidence interval for with the given confidence level and sample size. b) 90% with n = 38 .05 .90 .05 df 38 1 37 must use df 30 on the table t 1.697 TI 84: 2 nd VARS DISTR invt ENTER invt (area to left, df) As before, we need to verify three important conditions before we estimate a population mean. SRS: Our data are a SRS of size n from the population of interest or come from a randomized experiment. This condition is very important. Normality of x : The population has a Normal distribution or : n 15 Use t procedures if sample data appears roughly Normal. : n 15 The t procedures can be used except in the presence of outliers or strong skewness in the sample data. The t procedures are robust. : n 30 The t procedures can be used even for clearly skewed distributions. However, outliers are still a concern. You may still refer to the Central Limit Theorem in this situation. Independence: The method for calculating a confidence interval assumes that individual observations are independent. To keep the calculations reasonably accurate when we sample without replacement from a finite population, we should verify that the population size is at least _______________________(________). 10 times the sample size N 10n x t s n Example: A number of groups are interested in studying the auto exhaust emissions produced by motor vehicles. Here is the amount of nitrogen oxides (NOx) emitted by light-duty engines (grams/mile) from a random sample of size n = 46. Construct and interpret a 95% confidence interval for the mean amount of NOX emitted by light-duty engines of this type. Parameter: The population of interest is ____________________. light - duty engines We want to estimate , the mean amount of NO x emitted ____________________________. Conditions: Since we do not know , use ______________________ a one - sample t interval SRS: Data comes from a random sample of size n 46. Normality of x : With n 46, the CLT applies and the distribution of x is approximately Normal. Independence: The population of light duty engines is at least 10 46 or 460. Calculation: x 1.329 s .484 n 46 x t * s n df 46 1 45 t 2.021 .484 1.329 2.021 46 1.329 .144 (1.185,1.473) Interpretation: We are 95% confident that the mean of NO x emissions for light - duty engines is between 1.185 and 1.473 grams/mile. TI 83/84: STATS Tests T - Interval Standard Error When the standard deviation of a statistic, i.e. x or p̂ , is estimated from the data, the result is called the standard error of the statistic. Some textbooks simply refer to standard error as the standard deviation of the sampling distribution, x or p̂ , whether it is estimated from the data or not.