Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
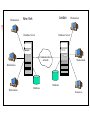
Distributed Database
System
Definition
A distributed Database System consists of a
collection of sites, connected together via
some kind of communication network, in
which:
Each site is a full database system site in its
own right, but
The sites has agrees to work together so that
a user at any site can access data anywhere
in the network exactly as if the data were all
stored at the user’s own site.
Workstation
London
New York
Workstation
Database Server
Database Server
Communication
network
Workstation
Workstation
Database
Workstation
Database
Workstation
Each site is a database system site in its own right.
Each site has it own local “real” database,
Its own local users,
Its own local DBMS and transaction Management software
including it own local locking, logging recovery, and etc.),
Its own local data communication manager (DC manager)
Overall distributed system can thus be
A kind of partnership among the individual local
DBMSs at the individual local site
It has a new S/W component at each site –
logical extension of the local DBMS – provides the necessary
partnership functionality,
and it is the combination of these new components together
with the existing DBMSs that constitutes what is usually called
the “Distributed Database Management System”
Distributed Database (DDB)
DDB is a collection of multiple logically
interrelated database distributed over a
computer network, and a distributed
database management system
(DDBMS) as a software system that
manages a distributed database while
making the distribution transparent to
the user.
Type of Distributed Database
system
Heterogeneous DDBMS
Homogenous DDBMS
Advantage of Distributed
Database
Why desirable?
The enterprise are usually distributed
Data is usually distributed
Each organization unit maintain data that is relevant to its own.
Total information asset of the enterprise is thus splintered into what
are sometime called “islands of information”
And what a Distributed system does is provide the
necessary “bridge” to connect those islands together.
It enables the structure of database to mirror the structure of the
enterprise
Local data can be kept locally, where it most logical belongs
While at the same time remote data can be accessed when necessary
Banking system
SF accounts keep in SF,
NY accounts keep in NY…
The advantage are surely obvious: “The distributed arrange combines
efficiency of processing (the data kept close to the point where it is most
frequency used” with increased accessibility (it is possible to access a LA
account from SF, via the communication network)
San Francisco
New York
Communication
Network
Los Angeles
Atlanta
Function of distributed database
Keeping track of data
Distributed query processing
Distributed transaction management
Replicated data management
Distributed data management
Distributed data recovery
Security
Distributed directory (catalog) management
Fundamental Principle
(Rule zero)
The fundamental principle of distributed database
“To the user, a distributed system should look exactly like a
non-distributed system”
Local autonomy
No reliance on a central site
Continuous operation
Location independence
Fragmentation independence
Replication independence
Distributed query processing
Distributed transaction management
Hardware independence
Network independence
DBMS independence
Local autonomy
The sites in a distributed system should be
autonomous.
Local autonomous means that all operations at a
given site are controlled by that site;
No site X should depend on site Y for its successful
operation
Local data is locally owned and managed, with local
accountability; all data “really” belongs to some local
database, even if it is accessible from other site
Integrity, security and physical storage representation
of local data remain under the control and jurisdiction
of the local site
No reliance on a central site
All site must be treated as equals.
They must not be any reliance on a central
“master” site for some central service – for
example
Central query processing
Central transaction management
Centralized naming services
The entire system is dependent on that central site
Why don’t need
First, that central site might be a bottleneck;
Second, the system would be vulnerable if the central site
went down, the whole system would be down (“The single
point of failure” problem)
Continuous operation
The advantage of distributed systems is provide greater
reliability and greater availability
Reliability is the probability that the system is up and
running any given moment.
Availability is the probability that the system is up and
running continuously (available) during a time interval.
Unplanned shutdowns are undesirable
Planned shutdowns should never be required;
That is it should never necessary to shut the system
down in order to perform a task such as adding a
new site or upgrading the DBMS at an existing site to
a new release version.
Location independence/transparency
Basic idea
Users should not have to know where data is
physically stored, but rather should be able to
perform
– at least from a logical standpoint
– as if data were all stored at their own local site.
Desirable because
It simplifies application programs and user activities
It allows data to migrate from site to site without
invalidating any of those program and activities
(migratability is desirable because it allows data to be
move around the network in respond to changing
performance requirement)
Fragmentation independence /
transparency
Support data fragmentation
Base table can be divided into pieces or
fragments for physical storage purposes, and
distinct fragments can be stored at different
sites.
Fragmentation is desirable for
performance reasons:
Data can be stored at the location where it is most
frequently used, so that most operations are
local and network traffic is reduces
User perception
Site A
Emp
Emp# Dept#
Salary
E1
E2
E3
E4
E5
40000
42000
30000
35000
48000
D1
D1
D2
D2
D3
Site B
S1_Emp
S2_Emp
Emp# Dept#
Salary
Emp# Dept#
Salary
E1
E2
E5
40000
42000
48000
E3
E4
30000
35000
D1
D1
D3
D2
D2
FRAGMENT EMP AS
S1_EMP AT SITE ‘SITE_A’ WHERE DEPT# = DEPT#(‘D1’) OR DEPT# = DEPT#(‘D3’)
S1_EMP AT SITE ‘SITE_B’ WHERE DEPT# = DEPT#(‘D2’)
Fragmentation
Fragmentation type
Horizontal Fragmentation
Vertical Fragmentation
Reconstructing the original base relvar from the fragments in done via
suitable join (for vertical) and union operations (for horizontal)
Fragmentation independence implies that users will be presented
with a view of the data in which the fragments are logically recombines
by means of suitable joins and unions. (no fragmentation)
The optimizer responds to determine which fragments need to be
physically accessed in order to satisfy any given user request.
Emp where salary > 40000 and dept# = dept#(‘D1’)
Optimizer will know from the fragment definitions (in catalog) that the
entire result can be obtained from site_A
Replication independence
Support Data replication
Desirable because
First, it can mean better performance.
Second, it can also mean better availability.
Application can operate on local copies instead of having to
communicate with remote sites.
A given replicated object remains available for processing – at
least for retrieval as long as at least one copy reminds available
Disadvantage
A given replicated object is updates, all copies of that object
must be updated (the update propagation)
Replication transparency
Desirable
Transparency to the user
User should be able to behave, at least from a logical
standpoint, as if the data were in fact not replicated at
all.
It simplifies application programs and end-user activities;
It allows replicas to be created and destroy anytime in
response to changing requirements, without invalidating any
of those programs or activities.
Replication independence implies that it is the
responsibility of the optimizer to determine which
replicas physically need to be access in order to
satisfy any given user request.
Site_A
Site_B
S2_Emp
S1_Emp
Emp# Dept#
Salary
Emp# Dept#
Salary
E1
E2
E5
40000
42000
48000
E3
E4
30000
35000
D1
D1
D3
Emp# Dept#
Salary
E3
E4
30000
35000
D2
D2
S12_Emp (S2_EMP replica)
D2
D2
Emp# Dept#
Salary
E1
E2
E5
40000
42000
48000
D1
D1
D3
S21_Emp (S1_EMP replica)
Distributed query processing
In distributed system data store in many
sites and may replicate
Optimization is even more important in a
distributed system that it is in a centralized
one.
Query that involve several sites
A
CN
B
Database
S{S#,CITY}
10,000 stored at Site A
P{P#,Color}
100,000 stored at site B
SP{S#,P#}
1,000,000 stored at A
Assume every stored tuple is 25 bytes (200bits)
Query (Get supplier numbers for LD suppliers of red
parts”
((S JOIN SP JOIN P) where CITY = “LD” and
COLOR = (‘Red’)) {S#}
Estimated cardinalities of certain intermediate results:
Number of read parts
= 10
Number of shipments by LD suppliers = 100,000
Communication assumptions:
Data Rate = 50,000 bits per second
Access delay = 0.1 second
6 strategies for processing this query and for each i
calculate the total communication time Ti from the formula
Become in second
1.
(total access delay) + (total data volume/data rate)
No of message/10 + No of bits/50000
Move parts to Site A and process the query at A
T1 = 0.1 + (100000 * 200) /50000
2.
Move supplier and shipments to site B and process the query at B
T2 = 0.2 + ((10000 + 100000) * 200)/5000
3.
Join suppliers and shipments at site A, restrict the result to LD suppliers
and then, for each of those supplier in turn, check site B to see
whether corresponding part is red. Each of these checks will involved 2
messages – a query and a respond. The transmission time for these
messages will be small compared with the access delay
T3 = 20000 seconds approx.
Restrict parts at site B of those the red, and then, for each
of those parts in turns, check site A to see whether there
exists a shipment relating the part to a LD supplier. Each of
these checks will involve 2 messages; transmission time
for these message will be small compared with the access
delay
Join supplier and shipments at site A, restrict the result to
LD suppliers, project the result over S# and P#, and move
the result to site B. Complete the processing at site B
T4 = 2 seconds approx.
T5 = 0.1 + (10000 * 200)/50000
Restrict parts at site B to those that are red and move the
result to site A. complete the processing at site A
T6 = 0.1 + (10 * 200) / 50000
Distributed transaction
management
Related to
Transaction management
Recovery and concurrency
2 phase commit
Prepare phase
Commit phase
(see the previous slide)
Hardware / Network / DBMS
independence