Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Serializability wikipedia , lookup
Oracle Database wikipedia , lookup
Open Database Connectivity wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Relational model wikipedia , lookup
Ingres (database) wikipedia , lookup
Clusterpoint wikipedia , lookup
Distributed Databases
and Its Twelve Objectives
CS157B
Name: Yingying Wu
Professor: Sin-Min Lee
Reference Book: An introduction to Database Systems
By C.J.Date
Definition of Distributed Database:
A distributed database system consists of a
collection of sites, connected together via some
kind of communication network, in which:
a. Each site is a full database system site in its own
right.
b. The sites have agreed to work together so that a
user at any site can access data anywhere in the network
exactly as if the data were all stored at the user’s own
site.
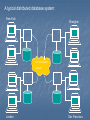
A typical distributed database system:
New York
Shanghai
Communication
network
London
San Francisco
The Fundamental Principle of
Distributed Database
“To the user, a distributed system should
look exactly like a nondistributed system.”
What is the 12 objectives?
Local autonomy
No reliance on a central
site
Continuous operation
Location independence
Fragmentation
independence
Replication independence
Distributed query
processing
Distributed transaction
management
Hardware independence
Operating system
independence
Network independence
DBMS independence
Why study the 12 objectives?
--Useful as
A basis for understanding distributed
technology in general
A framework for characterizing the
functionality of specific distributed
systems.
Objective 1
Local Autonomy
All operations at a given site are controlled
by that site.
No site X should depend on some other
site Y for its successful operation.
-- Otherwise site Y is down might mean that site X is
unable to run even if there is nothing wrong with site X
itself.
Objective 2
No Reliance on a Central Site
All sites must be treated as equals.
There must not be any reliance on a
central “master” site for some central
service—for example, centralized
transaction management.
Two reasons:
1.
The central site might be a bottleneck.
2.
If the central site went down, the whole system would
be down.
Objective 3
Continuous Operation
Provide greater reliability and greater
availability – it is the advantage of
distributed systems in general.
Unplanned shutdowns are undesirable, but
hard to prevent entirely.
Planned shutdowns should never be
required.
Objective 4
Location Independence
Also known as location transparency.
Users should not have to know where data
is physically stored, but rather should be
able to behave -- as if the data were all
stored at their own local site.
Objective 5
Fragmentation Independence
A system supports data fragmentation if a
given base relation can be divided into
pieces or fragments for physical storage
purposes.
Two benefits:
1. most operations are local
2. reduce network traffic
An example of fragmentation
Define two fragments:
FRAGMENT EMP AS
N_EMP AT SITE ‘New York’ WHERE DEPT# = DEPT#(‘D1’)
OR
DEPT# = DEPT#(‘D3’)
S_EMP AT SITE ‘Shanghai’ WHERE DEPT# = DEPT#(‘D2’)
User perception
EMP
New York
N_EMP
EMP#
DEPT#
SALARY
E1
D1
40K
E2
D1
42K
E3
D2
30K
E4
D2
35K
E5
D3
48K
EMP#
DEPT#
SALARY
E1
D1
40K
E2
D1
42K
E5
D3
48K
Shanghai
S_EMP
EMP#
DEPT#
SALARY
E3
D2
30K
E4
D2
45K
Objective 6
Replication Independence
A system supports data replication if a given
base relation or fragment can be represented in
storage by many distinct copies or replicas,
stored at many distinct sites.
Ideally should be “transparent to the user”.
Desirable for two reasons:
1. Applications can operate on local copies instead of remote sites.
2. At least one copy available
An example of replication
REPLICATE N_EMP AS
SN_EMP AT SITE ‘Shanghai’;
REPLICATE S_EMP AS
NS_EMP AT SITE ‘New York’;
New York
EMP#
Shanghai
DEPT#
SALARY
N_EMP E1
D1
40K
E2
D1
42K
E5
D3
48K
NS_EMP
(S_EMP
Replica)
EMP#
DEPT#
SALARY
E3
D2
30K
E4
D2
35K
S_EMP
SN_EMP
(N_EMP
Replica)
EMP#
DEPT#
SALARY
E3
D2
30K
E4
D2
35K
EMP#
DEPT#
SALARY
E1
D1
40K
E2
D1
42K
E5
D3
48K
Objective 7
Distributed Query Processing
A relational distributed system is likely to
outperform a nonrelational one by orders
of magnitude.
The query that involves several sites,
there will be many possible ways of
moving data around the system.
Example:
Consider Query “Get supplier numbers for London suppliers of red parts”
Database (suppliers-and-parts, simplified):
S {S#, CITY}
10,000 stored tuples at site A
P {P#, COLOR}
100,000 stored tuples at site B
SP {S#, P#}
1,000,000 stored tuples at site A
Assume every stored tuple is 25 bytes(200 bits)long.
Query (“Get supplier numbers for London suppliers of red parts”):
( ( S JOIN SP JOIN P )WHERE CITY = ‘London’ AND
COLOR = COLOR (‘Red’) ) { S# }
Estimated cardinalities of certain intermediate results:
Number of red parts
=
10
Number of shipments by London suppliers = 100,000
Communication assumptions:
Data rate = 50,000 bits per second
Access delay = 0.1 second
We now briefly examine three possible strategies for processing this query, and
for each strategy calculate the total communication time T from the formula:
( total access delay ) + (total data volume / data rate)
1. Move parts to site A and process the query at A.
T1 = 0.1 + (100000 * 200 ) / 50000
= 400 seconds approx. (6.67minutes)
2. Move suppliers and shipments to site B and process the query at B.
T2 = 0.2 + ( ( 10000 + 1000000 ) * 200 ) / 50000
= 4040 seconds approx. (1.12 hours)
3. Restrict parts at site B to those that are red and move the result to site A.
Complete the processing at site A.
T3 = 0.1 + (10 * 200 ) / 50000
= 0.1 second approx.
Objective 8
Distributed Transaction
Management
Recovery
The system must ensure that the set of
agents for that transaction either all
commit in unison or all roll back in unison.
Achieved by two-phase commit protocol.
Concurrency
Typically based on locking.
Two-phase commit:
Force decision
Log entry-end
ph.1,start ph.2
Coordinator
t1
t4
G
E
T
R
E
A
D
Y
t2
Participant
Forces
a log
entry for
agent
t5
t6
t9
D
O
O
K
D
O
N
E
I
T
I
T
t3
t7
“In doubt”
t8
Objective 9
Hardware Independence
Real world involves a multiplicity of
different machines—IBM machines, HP
machines, PCs and workstations of various
kinds.
Need to be able to integrate the data on
all of those systems.
Desirable to be able to run the same
DBMS on different hardware platform.
Objective 10
Operating System Independence
Be able to run the same DBMS on
different operating system platforms.
Have (e.g.) an OS/390 version and a UNIX
version and a Windows version all
participate in the same distributed system.
Objective 11
Network Indepence
Desirable to be able to support a variety of
disparate communication networks also.
Objective 12
DBMS Independence
All needed is that the DBMS instances at
different sites all support the same
interface– they don’t necessarily all of the
same DBMS software.
For example, if Ingres and Oracle both supported
the official SQL standard, the Ingres site and the Oracle
site might be able to talk to each other in a distributed
database system.
A hypothetical Ingres–provided gateway to Oracle:
Ingres
(SQL)
Ingres user
Site X
Ingres
database
GATEWAY
Distributed Ingres database
Oracle
(SQL)
Oracle
database
Site Y
Thank you!