Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Entity–attribute–value model wikipedia , lookup
Oracle Database wikipedia , lookup
Serializability wikipedia , lookup
Microsoft Access wikipedia , lookup
Ingres (database) wikipedia , lookup
Concurrency control wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Clusterpoint wikipedia , lookup
Relational model wikipedia , lookup
Database model wikipedia , lookup
Versant Object Database wikipedia , lookup
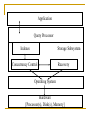
Communicating with the Outside Application Query Processor Indexes Storage Subsystem Concurrency Control Recovery Operating System Hardware [Processor(s), Disk(s), Memory] Accessing the Database 4GL 1. Power++, Visual basic Programming language + Call Level Interface 2. ODBC: Open DataBase Connectivity JDBC: Java based API OCI (C++/Oracle), CLI (C++/ DB2) Perl/DBI ODBC An application using the ODBC interface relies on: A driver manager, to load a driver that is responsible for the interaction with the target DB system The driver implements the ODBC functions and interacts with the DB server API pitfalls Cost of portability Layer of abstraction on top of ODBC drivers to hide discrepancies across drivers with different conformance levels. Beware of performance problems in this layer of abstraction: Use of meta-data description when submitting queries, accessing the result set Iterations over the result set Characterization of ODBC drivers Conformance level: portable applications, level 1 ODBC functions Core functions for allocating, deallocating handles for DB environment, connection, and statements; for connecting to a DB server; for executing SQL statements; for receiving results; for controlling transactions; and for error handling SQL dialect: Generic ODBC drivers transform SQL statements that follow ODBC SQL grammar into the dialect of a particular DB system. Specific ODBC drivers assume SQL statements follow the dialect of the system they are connected to. Client-server communication mechanism: Generic ODBC drivers rely on a DB-independent comm layer; specific ODBC drivers exploit the particular mechanisms supported by the DB server => much faster Specific vs generic ODBC drivers SQLServer, Oracle, DB2 have specific ODBC drivers Allow a program to run on different DB systems as long as queries are expressed in the dialect of the target system DataDirect Technologies and OpenLInk provide generic ODBC drivers Provide transparent portability But worse performance and loss of features ODBC vs. OCI Throughput (records/sec) 80 60 40 20 OCI ODBC 0 0 2000 4000 6000 8000 Number of records transferred 10000 ODBC vs. OCI on Oracle8iEE on Windows 2000 Iteration over a result set one record at a time. Prefetching is performed. Low OCI overhead when number of records transferred is small ODBC performs better when number of records transferred increases. Better job at prefetching. Client-Server Mechanisms DB server produces results that are consumed by the application client The client is asynchronous wrt the server Communication buffer on the database server. One per connection. Two performance issues: 1. If a client does not consume results fast enough, then the server stops producing results and holds resources until it can output the result. 2. A client program executing on a very slow machine can affect the performance of the whole DB system Data is sent either when the communication buffer is full or when a batch is finished executing. Small buffer – frequent transfer overhead Large buffer – time to first record increases. No actual impact on a 100 Mb network. More sensitive in an intranet with low bandwidth. Object-Orientation Considered If each document type is Harmful encapsulated in an object and authorized(user, type) doc(id, type, date) What are the document instances a user can see? SQL: select doc.id, doc.date from authorized, doc where doc.type = authorized.type and authorized.user = <input> each document instance is another object, the risk is the following: Find types t authorized for user input select doc.type as t from authorized where user = <input> For each type t issue the query select id, date from doc where type = <t>; The join is executed in the application and not in the DB! Tuning the Application Interface 1. 2. 3. 4. 5. Avoid user interaction within a transaction Minimize the number of roundtrips between the application and the database Retrieve needed columns only Retrieve needed rows only Minimize the number of query compilations 1. Avoid User Interaction within a Transaction User interaction within a transaction forces locks to be held for a long time. Careful transaction design (possibly transaction chopping) to avoid this problem. 2. Minimize the Number of Roundtrips to the Database (a) Avoid Loops Application programming languages offer looping facilities (SQL statements, cursors, positioned updates) Embedding an SQL SELECT statement inside the loop means there will be application-to-DB interaction in every iteration of the loop Better idea to retrieve a significant amount of data outside the loop and then use the loop to process the data Package several SQL statements within one call to the database server Embedded procedural language (Transact SQL) with control flow facilities. Many such languages are product specific, so they can reduce the portability of the application code Loops throughput (records/sec) 600 500 400 300 200 100 0 loop no loop Fetch 2000 records Loop: 200 queries No loop: 1 query Crossing the application interface too often hurts performances. 2. Minimize the Number of Roundtrips to the Database (b) Use User Defined Functions (UDFs) when they select out a high number of records. Scalar UDFs can be integrated within a query condition: they are part of the execution plan and they are executed on the DB server User Defined Functions Throughput (queries/msec) 6 UDF 5 application function 4 3 2 1 0 20% 80% Function computes the number of working days between two dates. Function executed either on the database site (UDF) or on the application site Applying the UDF yields good performances when it helps reduce significantly the amount of data sent back to the application. 80% of the records: the records where the nb working days between the date of shipping and the date the receipt was sent is greater than 5 working days 20% of the records: …. Is smaller than 5 working days 3. Retrieve Needed Columns Only Reasons why it is a good idea: Avoid transferring unnecessary data Retrieving an unneeded column might prevent the use of a covering index. Ex: if there is a dense composite index on last name and first name, then a query asking for all the first names of people whose last name is ‘Costa’ can be answered by the index alone, provided no irrelevant atts are also selected In the experiment the subset contains ¼ of the attributes. Reducing the amount of data that crosses the application interface yields significant performance improvement. Throughput (queries/msec) 1.75 1.5 1.25 all covered subset 1 0.75 0.5 0.25 0 no index index 4. Retrieve Needed Rows Only If the user is only viewing a small subset of a very large result set, it is best to Only transfer that subset Only compute that subset Use constructs such as TOP or FETCH FIRST Avoid cursors Applications that allow the formulation of ad-hoc queries should permit users to cancel them. Avoids holding resources when a user realizes she made a mistake or when a query takes too long to terminate Cursors Throughput (records/sec) 5000 4000 3000 2000 1000 0 cursor SQL Query fetches 200000 56 bytes records Response time is a few seconds with a SQL query and more than an hour iterating over a cursor. 5. Minimize the Number of Query Compilations Query parsing and optimization is a form of overhead to avoid The compilation simple queries requires from 10,000 to 30,000 instructions; for complicated queries, requires from 100,000 to several million instructions Compilation requires read access to the system catalog . Can cause lock blocking if other transactions are accessing the catalog at the same time A well-tuned online relational environment should rarely perform query compilations The query plan resulting from a compilation should be quickly accessible by the processor – use procedure cache for this purpose and be sure the cache is big enough. Benefits of precompiled queries Prepared execution yields better performance when the query is executed more than once: No compilation No access to catalog. Prepared execution plans become obsolete if indexes are added or the size of the relation changes. Experiment performed on Oracle8iEE on Windows 2000. Throughput (queries/sec) 0.6 0.4 0.2 direct prepared 0 0 1 2 3 4 5 6