Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Entity–attribute–value model wikipedia , lookup
Clusterpoint wikipedia , lookup
Data Protection Act, 2012 wikipedia , lookup
Data center wikipedia , lookup
Forecasting wikipedia , lookup
Data analysis wikipedia , lookup
3D optical data storage wikipedia , lookup
Data vault modeling wikipedia , lookup
Database model wikipedia , lookup
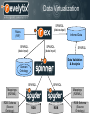
Big Data Without Big Change SemTech West 2012 Michael Lang Revelytix Discussion Points Review the RDBMS, ETL, and data warehouse data management paradigms Compare those paradigms to data virtualization and Big Data Propose “Bigger Data” in support of radically better analytic capability The Last Forty Years In 1970, E.F. Codd, with the IBM Research Laboratory in San Jose, California, wrote a paper published in ACM, “A Relational Model of Data for Large Shared Data Banks” Codd wrote, “The problems treated here are those of data independence – the independence of application programs from the growth in data types and changes in data representation...” This paper set in motion the architecture for data management systems for the next forty years. These systems are known as relational database management systems (RDBMS) The Last Forty Years Siloed Information Management Systems – All data in a single shared databank – Rigid schemas – Data and metadata are different types of things – Query processor only knows about its local data expressed in a fixed schema – Excellent ACID / CRUD capability The Age of Virtualization DIMS Distributed Information Management System Virtualization Hardware and operating system virtualization became available in 2004 and brought great value to IT infrastructure – Cloud-based deployment – Extreme flexibility – Efficient use of hardware resources – Independence from operating systems Leading to an enormous ROI for large enterprises EDM Hardware virtualization did not help with the problems associated with Enterprise Data Management – Data remains distributed over many silos, even in cloud-based environments – Meaning of data in independent silos is still obscure – Schema are still disparate Data Virtualization The advent of RDF, OWL, and SPARQL have created the technical foundation for building a completely virtualized data infrastructure – All information can be managed in the same data model – Any domain can be described at the schema level – SPARQL provides a distributed query and transformation language – R2RML provides mappings from native schema to RDF schema – Standards-based data virtualization is here to stay Data Virtualization This paradigm assumes data is completely distributed, and that anyone/anything should be able to find it and use it – RDF is the data model – OWL is the schema model – SPARQL is the query language – URI provide a unique identifiers – URL provides the location Data Abstraction A RDBMS is an abstraction layer above an OS-based file systems – Made it vastly simpler to work with local data Data Virtualization is an abstraction layer above multiple RDBMS and/or other sources of data – vastly simpler to work with distributed data – Distributed Information Management System Caveats Data virtualization technologies are not as performant as locally managed data Data virtualization depends on sophisticated transformation of complex and unstructured data Bigger Data: Hadoop and Virtual Data DIMS Distributed Information Management System NoSQL / Big Data Another seminal paper: Copyright 2003 ACM “The Google File System” Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung • These data processing systems are highly distributed but, … • Each NoSQL database is a “large shared databank” • Data cannot be combined for analytics across NoSQL databases • NoSQL is an evolutionary step in data storage; it is not a paradigm shift in information management Big Data Hadoop is an excellent technology to use for transforming data of varying structures to formats useful for analytics Hadoop also excels at handling very large amounts of disparate data Virtual data needs a place to be materialized Data Virtualization technologies provide a common structure and access methodology for disparate sets of data Data Virtualization SPARQL (data output) Rules (RIF) Inferred Data SPARQL (data input) SPARQL (data input) SPARQL Data Validation & Analysis Domain Ontology SPARQL SPARQL Mappings (R2RML) RDB Schema (Source Ontology) Mappings (R2RML) RDB RDB RDB Schema (Source Ontology) Hadoop The RDF-based technology implementing a virtual data infrastructure is useful for Hadoop data transformations using MapReduce – All of the disparate data sets in a Hadoop cluster can be organized with a common set of semantics provided by an R2RML map and a Domain Ontology – Data transformations are made using a series of MapReduce jobs – ETL becomes ELT ELT Extract, Load, and Transform is a fundamentally new paradigm facilitating enterprise analytics – Data can be loaded in its native formats and structures – Transformation activities take place after the data is loaded into a Hadoop cluster – Hadoop and MapReduce are excellent technologies for data transformations at scale Query Engine = Transformation Engine Need to transform structure – Relational -> RDF – HDFS/HBase -> Tuples – Merge data from multiple sets (federate) – Basic query processing: join, aggregation, etc – Execute arbitrary user-defined analytical functions (UDFs) Revelytix query engines already do these – Spinner – federation, query processing, Hadoop-to-tuples – Spyder – relational-to-RDF, query processing Transforming Data in Hadoop Source Data Hadoop/Cloud Infrastructure Data Triples Load, Index Relational Database Triples HDFS Files Extract HBase Transform The big win is to leave the data in situ, and define networked pipelines of transformations to move data through various processing stages. Relational Database Distributed Pipelined Processing Processing Pipeline Design Configure execution environments for parts of pipeline local Dataflow Pipeline Definition X1 X6 a X6 b cloud S1a S1b S6 S5 X5 Execution X8 Query S8 S4 S7 ‘endpoints’ S2 D2 S3 D3 F1 Data Flow T Mix of materialized and virtual data sets… inter-linked by a set of transformations D1 T T T T T Query Processing in Hadoop Hadoop and SPARQL Once the data sets have been transformed to a common set of semantics, SPARQL queries can be executed as a set of distributed MapReduce jobs We must know the relationships between data sets The descriptions of the relations need to be available at query time Query Execution in the Cloud Hadoop/Cloud Infrastructure Data Query Client Query Processor Query Query Query Query Processor Processor Processor Processor HDFS Files HBase Query processor is shipped to all Hadoop nodes for parallel processing, using the Hadoop MapReduce framework. Query Processing Hadoop/Cloud Infrastructure Data Spinner • • • Spinner HDFS Files Hadoop Adapter Hadoop/Cloud Infrastructure HBase Data HDFS Spyder Hadoop Adapter Files HBase Query processing can be done locally, remotely (in cloud), or mix Many types of transformations can be done • Basic query processing (SPARQL or SQL) • Relational to graph (R2RML) transformations • Federation over multiple sources or data sets • Hadoop HDFS-to-Tuple and HBase-to-Tuple transformations We can plan and optimize across all these for maximum performance Hadoop and RIF Once the data sets have been transformed to a common set of semantics, RIF rules can be executed as a set of distributed MapReduce jobs – Inference – Classification – Validation – Compliance Why Use Hadoop? Enable access to large volumes of data Warehouse-style access Enable a ‘processing pipeline’ in the cloud Push processing into Map-Reduce infrastructure Parallelize query execution – Extreme scalability Architectural flexibility Future Directions 27 Hadoop and Solr Integration between Hadoop, Data Virtualization, and Solr provides massively scalable faceted search – The common set of semantics, applied over disparate unstructured data sets provides a powerful paradigm for searching with facets over massive amounts of data What Are We Offering? Seamless integration of virtual data and Hadoop Linkage (relationships) between data sets, yielding… – Provenance/traceability/lineage – Metadata management and data visibility/understanding – Powerful analytics infrastructure Common data model, enabling… – Mixing of relational and graph-based data – Mixing of SQL and SPARQL queries – Access to all cloud-based data Optimization across heterogeneous data systems The Shift is On Distributed Information Management System DIMS is available now Questions Revelytix.com for much additional information Thank You