Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
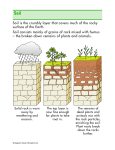
Knowledge Mining and Soil Mapping using Maximum Likelihood Classifier with Gaussian Mixture Models ECE539 final project Instructor: Yu Hen Hu Fall 2005 Jian Liu 12/13/2005 Overview This study deals with data mining from soil survey maps and soil mapping with mined soil-landscape knowledge. Soil – landscape models Soil is a product of the interaction of surrounding environments “soil-landscape model” (Hudson, 1992) Soil can be predicated given the environments Environmental variables Environmental factors affecting soil formation: o Bedrock geology o Elevation (DEM) o Slope gradient 1st derivative along the steepest slope o Profile curvature 2nd derivative along the steepest slope o Planform curvature 2nd derivative perpendicular to contour lines Previous Approaches & Problems Fuzzy system (Zhu 2001) Elicits knowledge from a soil scientist and represents it with arbitrary curves Assumes independence of each environmental variable ANN (Zhu 2000; Behrens 2005; Scull 2005 ) Black box knowledge representation High dimensional matrix is hard to comprehend Decision trees (Bui, 1999; Qi et.al. 2003) Knowledge extracted is crisp (typical case), no information about gradation Proposal – Knowledge Representation GMM representation is more suitable because: Probability representation well captures the physical gradation of the phenomenon The interactions between environmental variables are taken into account by the multivariate Gaussian distribution p( x) 1 exp ( x ) T 1 ( x ) 2 (2 ) d | | 1 Mixture model gives a great potential of capturing the real distribution Physically a soil type may have multiple instances. c p ( x | ) p ( x | (i ), i ) p (i ) i 1 Proposal – Maximum Likelihood Classifier Maximum likelihood P(A|Class1) = 0.8 P(A|Class2) = 0.5 A then is classified into class1 based on “Maximum likelihood” Naturally evaluates the composite effect environmental variables have on the probability of soil formation Algorithm Training procedure: Standardize feature dimensions of training set For each geology group in the training data For each soil type in the geology group Fit a GMM using EM algorithm (# of mixtures is preset, k-means is used to initialize the cluster centers) Testing procedure: Standardize feature dimensions of testing set For each sample point For each class in the corresponding geology group Calculate the corresponding likelihood based on GMM The point is classified to the class with the maximum likelihood Case Study Training set elevation slope gradient profile curvature planform curvature geology soil map Testing set elevation … geology soil map Evaluation of the GMM representation The GMM representations well capture the gradation of soil on the landscape, which complies well with expert knowledge e.g. Council at footslope e.g. Elbaville at backslope Training accuracy & testing accuracy Overall, 80% classification accuracy against testing data Increasing number of mixtures leads to higher classification accuracy at an expense of exponentially increasing storage and computational load classification accuracy (%) geology area 1 geology area 2 # of mixtures training testing training testing 1 70.04 68.07 79.80 77.13 2 76.66 74.50 78.99 76.84 4 81.51 79.27 80.03 75.55 8 83.17 80.12 84.07 79.23 Classification Accuracy vs. # of Mixtures in geology area 2 100 90 90 80 classification accuracy (%) classification accuracy (%) in geology area 1 100 70 60 training accuracy 50 testing accuracy 40 30 20 10 80 70 60 training accuracy 50 testing accuracy 40 30 20 10 0 0 0 2 4 6 # of mixtures 8 10 0 2 4 6 # of mixtures 8 10 Mapping accuracy based on field data 64 points are correctly classified out of 83 field sample points (77%), higher than traditional manual based soil survey (usually 60%) Classification result using 8 mixtures (the dark blue areas are not mapped) More comments Standardization of feature dimensions is very effective, -- improves mapping accuracy from 55% to 80% Preprocessing techniques such as data cleaning required by decision tree is not critical to ML because the ML classifier is not as sensitive to training errors as long as they are not of a huge amount. Conclusion GMM is suitable to represent soil-landscape knowledge ML classifier with GMMs is promising for soil knowledge mining and soil mapping Future improvement? Reduce the storage and computational load so that bigger number of mixtures can be used to improve classification accuracy Use diagonal matrix to replace full covariance matrix (after applying de-correlation to the features)?