Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
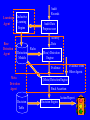
Data Mining Approaches for ID • A systematic data mining framework to: – Build good models: • select appropriate features of audit data to build (inductively learned) intrusion detection models – Build better models: • architect a hierarchical system that combines multiple detection models – Build updated models: • dynamically update and deploy new detection system as needed – Automate the development of IDSs. Learning Agent Base Detection Agent Audit Records Inductive Learning Engine Audit Data Preprocessor Activity Data Detection Models Rules (Base) Detection Engine Evidence Meta Detection Agent Decision Table Evidence from Other Agents (Meta) Detection Engine Final Assertion Decision Engine Action/Report Connection Records 10:35:41.5 128.59.23.34.30 > 113.22.14.65.80 : . 512:1024(512) ack 1 win 9216 10:35:41.5 102.20.57.15.20 > 128.59.12.49.3241: . ack 1073 win 16384 10:35:41.6 128.59.25.14.2623 > 115.35.32.89.21: . ack 2650 win 16225 tcpdump time dur src dst bytes srv … 10:35:41 1.2 A B 42 http … 10:35:41 0.5 C D 22 user … 10:35:41 10.2 E F 1036 ftp … … … … … … ... … Learning header,86,2,inetd, … subject,root,… text,telnet,... ... BSM Network Model Session Records 11:01:35,telnet,-3,0,0,0,... 11:05:20,telnet,0,0,0,6,… 11:07:14,ftp,-1,0,0,0,... ... Learning Host Model Combined Model Data Mining • Relevant data mining algorithms for ID: – Classification: maps a data item into one of several pre-defined categories (e.g., normal or an intrusion) • RIPPER: a classification rule learner – Link analysis: determines relations between fields in database • Association Rules – Sequence analysis: models sequence patterns • Frequent Episodes Classifiers as ID Models • Motivation: – automatically learn “detection rules” from audit data, instead of hand-coding. • Critical requirement: – select the right set of features (attributes). • how to automate feature selection? Classifiers as ID Models (continued) • RIPPER: computes classification rules that consist of the most concise and distinguishing attribute/value tests for each class label. • Example RIPPER rules: – pod :- wrong_fragment >= 1, protocol_type = icmp. – teardrop :- wrong_fragment >= 1. – smurf :- protocol = ecr_i, short_count >= 3, srv_short_count >= 3. – ... – normal :- true. Association Rules • Motivation: – Program executions and user activities have frequent correlation among system features – Incremental updating of the rule set is easy • An example from “telnet/login” sessions commands (of a user): – mail => am, 135.21.59.169 [0.3, 0.1] – Meaning: 30% of the time when the user is sending emails, it is in the morning and from the host 135.21.59.169; and this pattern accounts for 10% of all his/her commands. Frequent Episodes • Motivation: – Sequence information needs to be included in a detection model • An example from telnet sessions commands: – (vi, C, am) => (gcc, C, am) [0.6, 0.2, 5] – Meaning: 60% of the time, after vi (edits) a C file, the user gcc (compiles) a C file within the window of next 5 commands; this pattern occurs 20% of the time. Using the Mined Patterns • Support the feature selection process: – the “unique” patterns (association rules and frequent episodes) from intrusion data are used to construct temporal statistical features for misuse detection. – for example, “neptune” patterns (relative to the same dst_host): • (service = X, flag = S0), (service = X, flag = S0) -> (service = X, flag = S0) [0.6, 0.1, 2s] • add features: for connections to the same dst_host in the past 2 seconds, the # with the same service, and the # with S0 flag. Using the Mined Patterns (cont’d) • Anomaly detection: – patterns mined from user commands in “normal” sessions represent normal behavior. – aggregate patterns from many sessions to a rule set to form the normal profile. – inspecting a session: • mined patterns from commands of this session • compare them with the normal profile, if the measured similarity is below the threshold, then the session is anomalous. • similarity = p/n, where n is the total number of patterns from this session, p is the number of patterns matched in the profile. DARPA ID Evaluation • Our approach: – Misuse detection: • Process packet-level tcpdump data into connection records • Apply association rules and frequent episodes program to connection records. • Use the mined patterns to construct additional temporal statistical features into each record. • Apply RIPPER to learn detection rules for each intrusion. – Anomaly detection: • Process user commands from each session into command records. • Mine patterns and construct normal profile. • Establish the similarity threshold. DARPA ID Evaluation (cont’d) • Preprocessing tcpdump data: – Use Bro (from LBL) as a TCP packet filtering and reassembling platform. – Develop a set of Bro “policy scripts” to gather an extensive set of features for each network connection: • “generic” features: – – – – protocol (service), protocol type (tcp, udp, icmp, etc.) duration of the connection, flag (connection established and terminated properly, SYN error, rejected, etc.), – # of wrong fragments, – whether the connection is from/to the same ip/port pair. DARPA ID Evaluation (cont’d) • “content” features (only useful for TCP connections): – – – – – – – – – – – # of failed logins, successfully logged in or not, # of root shell prompts, “su root” attempted or not, # of access to security control files, # of compromised states (e.g., “Jumping to address”, “path not found” …), # of write access to files, # of outbound commands, # of hot (the sum of all the above “hot” indicators), is login a “guest” or not, is login a root or not. DARPA ID Evaluation (cont’d) • Features constructed from mined patterns: • temporal and statistical “traffic” features: – # of connections to the same destination host as the current connection in the past 2 seconds, and among these connections, – # of rejected connections, – # of connections with “SYN” errors, – # of different services, – rate (%) of connections that have the same service, – rate (%) of different (unique) services. DARPA ID Evaluation (cont’d) • Features constructed from mined patterns: • temporal and statistical “traffic” features (cont’d): – # of connections that have the same service as the current connection, and among these connections, – # of rejected connections, – # of connection with “SYN” errors, – # of different destination hosts, – rate (%) of the connections that have the same destination host, – rate (%) of different (unique) destination hosts. DARPA ID Evaluation (cont’d) • Learning RIPPER rules: – the “content” model for TCP connections: • each record has the “generic” features + the “content” features, total 22 features. • rules to detect many u2r and r2l attacks. • total 55 rules, each with less than 4 attribute tests. DARPA ID Evaluation (cont’d) • example “content” connection records: dur p_type proto flag l_in root su compromised hot … label 92 tcp telnet SF 1 0 0 0 0 … normal 26 tcp telnet SF 1 1 1 0 2 … normal 2 tcp http SF 1 0 0 0 0 … normal 149 tcp telnet SF 1 1 0 1 3 … buffer 2 http 1 0 0 1 1 … back tcp SF • example rules: – buffer_overflow :- hot >= 3, compromised >= 1, su_attempted <= 0, root_shell >= 1. – back :- compromised >= 1, protocol = http. DARPA ID Evaluation (cont’d) • Learning RIPPER rules (cont’d): – the “traffic” model for all connections: • each record has the “generic” features + the “traffic” features, total 20 features. • rules to detect many DOS and probing attacks. • total 26 rules, each with less than 4 attribute tests. DARPA ID Evaluation (cont’d) • example “traffic” connection records: dur p_type proto flag count srv_count r_error diff_srv_rate … label 0 icmp ecr_i SF 1 1 0 1 … normal 0 icmp ecr_i SF 350 350 0 0 … smurf 0 tcp other REJ 231 1 198 1 … satan 2 tcp http 0 0 1 SF 1 normal • example rules: – smurf :- protocol = ecr_i, count > =5, srv_count >= 5. – satan :- r_error >= 3, diff_srv_rate >= 0.8. DARPA ID Evaluation (cont’d) • Learning RIPPER rules (cont’d): – the host-based “traffic” model for all connections: • sort connection records by destination hosts and construct a set of host-based traffic features, similar to the (time-based) temporal statistical features. • each record has the “generic” features + the hostbased “traffic” features, total 14 features. • rules to detect slow probing attacks. • total 8 rules, each with less than 4 attribute tests. DARPA ID Evaluation (cont’d) • example host-based “traffic” connection records: dur p_type proto flag count srv_count srv_diff_host_rate … label 2 tcp http SF 0 0 0 … normal 0 icmp eco_i SF 1 40 0.5 … ipsweep 0 icmp ecr_i SF 112 112 0 … normal • example rules: – ipsweep :- protocol = eco_i, srv_diff_host_rate > = 0.5, count <= 2, srv_count >= 6. DARPA ID Evaluation (cont’d) • Learning RIPPER rules - a summary: Models Attacks Features # Features # Rules contents u2r, r2l generic + content 22 55 traffic DOS, probing generic + traffic 20 26 14 8 host traffic slow probing generic + host traffic DARPA ID Evaluation (cont’d) • Learning RIPPER rules - the main difficulties: – Accuracy depends on selecting the right set of features. – For example, using only “# of failed logins” to detect “guessing passwd” may not be adequate: • guess_passwd :- #_failed_login >= 4. • this rule has high FP rate since a legitimate user can have typos when entering passwd. • need additional features that describe how the passwd is entered wrong. DARPA ID Evaluation (cont’d) • Results: – Very good detection rate for probing, and acceptable detection rates for u2r and DOS attacks • variations of the attacks are relatively limited. • training data contains representative instances. • predictive features are constructed. – Poor detection rate for r2l attacks • too many variations • lack of representative instances in training data Next Steps • Improving our approach: – apply the same methods to DAPAP/MIT LL BSM data, and see whether a combined model yields better detection rate. – develop anomaly detection strategies for network activities (e.g., to detect “new” r2l attacks). – test the efficiency of our models in real-time systems: • translate RIPPER rules into NFR N-codes for realtime ID.