Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
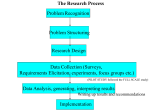
An Improved Categorization of Classifiers’ Sensitivity on Sample Selection Bias Wei Fan Ian Davidson Bianca Zadrozny Philip S. Yu What is sample selection bias? Inductive learning: training data (x,y) is sampled from the universe of examples. In many applications: training data (x,y) is not sampled randomly. Insurance and mortgage data: you only know those people you give a policy. School data: self-select There are different possibilities of how (x,y) is selected (Zadrozny’04) S=1 denotes (x,y) is chosen. S is independent from x and y. Total random sample. S is dependent on y not x. Class bias S is dependent on x not on y. Feature bias. S is dependent on both x and y. Both class and feature. Important Problem It is very hard to guarantee random sample for many real-world applications. Heckman received Nobel Prize for his twostep approach on regression methods. Many recent related work such as Bianca Zadrozny’04 Andrew Smith and Charles Elkan’04. etc Feature Bias P(s=1|x,y) = P(s=1|x) Example: Bias conditional on x But not directly conditional on y. Survey data Loan approval. Question: Given two modeling techniques M1 and M2 Which one is more “sensitive” on feature bias? Sensitive: constructed model and accuracy changes significantly as a result of feature bias. Our paper shows this Most classifier algorithm can be sensitive or insensitive to feature bias. P(y|x) is the true probability distribution, which is unknown for most problems P(y|x,M) is the estimated probability by model M. The dependency on M is none-trivial. Insensitive if the model is the correct model or asymptotically P(y|x,M) = P(y|x) Sensitive if the model is the incorrect model or P(y|x,M) != P(y|x) Correct and Incorrect Model Correct Model Incorrect/Correct Models Result on Decision Tree 25 20 15 Unbiased Biased 10 5 0 1 2 3 4 5 6 Practical Implication Given a realistic dataset, you most likely will never know its true model either before or after data mining. Given a modeling technique, you will most likely not know if it will be or will not be the true model. Reality is: you don’t know if it will be sensitive or insensitive to sample selection bias. Long paper on request.