Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Data Mining: Association Rule Mining
CSE880: Database Systems
Data, data everywhere
Walmart records ~20 million transactions per day
Google indexed ~3 billion Web pages
Yahoo collects ~10 GB Web traffic data per hour
– U of M Computer Science department collects ~80MB
of Web traffic on April 28, 2003
NASA Earth Observing Satellites (EOS) produces over
1 PB of Earth Science data per year
NYSE trading volume: 1,443,627,000 (Oct 31, 2003)
Scientific simulations can produce terabytes of data per
hour
Data Mining - Motivation
There is often information “hidden” in the data that is
not readily evident
Human analysts may take weeks to discover useful information
Much of the data is never analyzed at all
4,000,000
3,500,000
The Data Gap
3,000,000
2,500,000
2,000,000
1,500,000
Total new disk (TB) since 1995
1,000,000
Number of
analysts
500,000
0
1995
1996
1997
1998
1999
From: R. Grossman, C. Kamath, V. Kumar, “Data Mining for Scientific and Engineering Applications”
WhatisisData
DataInformation
Mining?
What
Mining?
Many Definitions
– Non-trivial extraction of implicit, previously unknown and
potentially useful information from data
– Exploration & analysis, by automatic or
semi-automatic means, of
large quantities of data
in order to discover
meaningful patterns
Knowledge
Discovery
Process
Data Mining Tasks
Data
10
Milk
Tid Refund Marital
Status
Taxable
Income Cheat
1
Yes
Single
125K
No
2
No
Married
100K
No
3
No
Single
70K
No
4
Yes
Married
120K
No
5
No
Divorced 95K
Yes
6
No
Married
No
7
Yes
Divorced 220K
No
8
No
Single
85K
Yes
9
No
Married
75K
No
10
No
Single
90K
Yes
11
No
Married
60K
No
12
Yes
Divorced 220K
No
13
No
Single
85K
Yes
14
No
Married
75K
No
15
No
Single
90K
Yes
60K
Association Rule Mining
Given a set of transactions, find rules that will predict the
occurrence of an item based on the occurrences of other
items in the transaction
Market-Basket transactions
TID
Items
1
Bread, Milk
2
3
4
5
Bread, Diaper, Beer, Eggs
Milk, Diaper, Beer, Coke
Bread, Milk, Diaper, Beer
Bread, Milk, Diaper, Coke
Example of Association Rules
{Diaper} {Beer},
{Milk, Bread} {Eggs,Coke},
{Beer, Bread} {Milk},
Implication means co-occurrence,
not causality!
Terminology: Frequent Itemset
Transaction-id
Items bought
1
A, B, C
2
A, C
3
A, D
4
B, E, F
Frequent Itemset
Support
{A}
75%
{B}
50%
{C}
50%
{A, C}
50%
Market Basket: items bought in a
single customer transaction
Itemset: X={x1, …, xk}
Support:
The support of itemset X is the
fraction of transactions in the
database that contains all the
items in the itemset
Let minsup = 50%
Itemsets that meet the minsup threshold
are called frequent itemsets
Itemsets {A,D}, {D} … do not meet the
minsup threshold
Terminology: Association Rule
Given: a pair of itemsets X, Y
Association rule XY: If X is purchased in a transaction, it is very likely that
Y will also be purchased in that transaction.
– Support of XY : the fraction of transactions that contain both X and Y
i.e. the support of itemset XY
– Confidence of XY : conditional probability that a transaction having X
also contains Y. i.e. Support (XY) / support (X)
Customer
buys both
Sup(X)
Customer
buys Y
To discover all rules having
Sup(XY)
Sup(Y)
Customer
buys X
Goal of Association Rule
Mining:
1. support minsup and
2. confidence minconf
An Illustrative Example
TID
Items
1
Bread, Milk
2
3
4
5
Bread, Diaper, Beer, Eggs
Milk, Diaper, Beer, Coke
Bread, Milk, Diaper, Beer
Bread, Milk, Diaper, Coke
Example:
{Milk, Diaper} Beer
2
support 0.4
5
2
confidence 0.67
3
How to Generate Association Rules
How many possible association rules?
Naïve way:
– Enumerate all the possible rules
– Compute support and confidence for each rule
– Exponentially expensive!!
Need to decouple the minimum support and
minimum confidence requirements
How to Generate Association Rules?
TID
Items
1
Bread, Milk
2
3
4
5
Bread, Diaper, Beer, Eggs
Milk, Diaper, Beer, Coke
Bread, Milk, Diaper, Beer
Bread, Milk, Diaper, Coke
Example of Rules:
{Milk,Diaper} {Beer} (s=0.4, c=0.67)
{Milk,Beer} {Diaper} (s=0.4, c=1.0)
{Diaper,Beer} {Milk} (s=0.4, c=0.67)
{Diaper} {Milk,Beer} (s=0.4, c=0.5)
Observations:
• All the rules above have identical support
• Why?
Approach: divide the rule generation process into 2 steps
• Generate the frequent itemsets first
• Generate association rules from the frequent itemsets
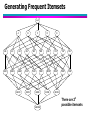
Generating Frequent Itemsets
null
A
B
C
D
E
AB
AC
AD
AE
BC
BD
BE
CD
CE
DE
ABC
ABD
ABE
ACD
ACE
ADE
BCD
BCE
BDE
CDE
ABCD
ABCE
ABDE
ABCDE
ACDE
BCDE
There are 2d
possible itemsets
Generating Frequent Itemsets
Naive approach:
– Each itemset in the lattice is a candidate frequent itemset
– Count the support of each candidate by scanning the
database
Transactions
N
TID
1
2
3
4
5
Items
Bread, Milk
Bread, Diaper, Beer, Eggs
Milk, Diaper, Beer, Coke
Bread, Milk, Diaper, Beer
Bread, Milk, Diaper, Coke
Candidates
M
– Complexity ~ O(NMw) => Expensive since M = 2d !!!
Approach for Mining Frequent Itemsets
Reduce the number of candidates (M)
– Complete search: M=2d
Reduce the number of transactions (N)
– Reduce size of N as the size of itemset increases
Reduce the number of comparisons (NM)
– Use efficient data structures to store the candidates
and transactions
– No need to match every candidate against every
transaction
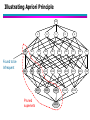
Apriori Principle
Any subset of a frequent itemset must be frequent
– If {beer, diaper, nuts} is frequent, so is {beer, diaper}
– Every transaction having {beer, diaper, nuts} also contains {beer,
diaper}
Support has anti-monotone property
– If A is a subset of B, then support(A) ≥ support(B)
Apriori pruning principle: If there is any itemset that is
infrequent, its superset need not be generated!
Illustrating Apriori Principle
null
A
B
C
D
E
AB
AC
AD
AE
BC
BD
BE
CD
CE
DE
ABC
ABD
ABE
ACD
ACE
ADE
BCD
BCE
BDE
CDE
Found to be
Infrequent
ABCD
Pruned
supersets
ABCE
ABDE
ABCDE
ACDE
BCDE
Apriori Algorithm
Method:
– Let k=1
– Find frequent itemsets of length 1
– Repeat until no new frequent itemsets are identified
Generate
length (k+1) candidate itemsets from length k
frequent itemsets
Update the support count of candidates by scanning the DB
Eliminate candidates that are infrequent, leaving only those
that are frequent
Illustrating Apriori Principle
Item
Bread
Coke
Milk
Beer
Diaper
Eggs
Count
4
2
4
3
4
1
Items (1-itemsets)
Minimum Support = 3
If every subset is considered,
6C + 6C + 6C = 41
1
2
3
With support-based pruning,
6 + 6 + 1 = 13
Itemset
{Bread,Milk}
{Bread,Beer}
{Bread,Diaper}
{Milk,Beer}
{Milk,Diaper}
{Beer,Diaper}
Count
3
2
3
2
3
3
Pairs (2-itemsets)
(No need to generate
candidates involving Coke
or Eggs)
Triplets (3-itemsets)
Itemset
{Bread,Milk,Diaper}
Count
3
How to Generate Candidates?
Given set of frequent itemsets of length 3:
{A,B,C}, {A,B,D}, {A,C,D}, {B,C,D},{B,C,E},{C,D,E}
Generate candidate itemsets of length 4 by
adding a frequent item to each frequent itemset
of length 3
– Produces lots of unnecessary candidates
Suppose A,B,C,D,E,F,G,H are frequent items
{A,B,C} + E produces the candidate {A,B,C,E}
{A,B,C} + F produces the candidate {A,B,C,F}
{A,B,C} + G produces the candidate {A,B,C,G}
{A,B,C} + H produces the candidate {A,B,C,H}
These candidates are guaranteed to be infrequent – Why?
How to Generate Candidates?
Given set of frequent itemsets of length 3:
{A,B,C}, {A,B,D}, {A,C,D}, {B,C,D},{B,C,E},{C,D,E}
Generate candidate itemsets of length 4 by joining
pairs of frequent itemsets of length 3
– Joining {A,B,C} with {A,B,D} will produce the candidate
{A,B,C,D}
– Problem 1: Duplicate/Redundant candidates
Joining {A,B,C} with {B,C,D} will produce the same candidate
{A,B,C,D}
– Problem 2: Unnecessary candidates
Join {A,B,C} with {B,C,E} will produce the candidate {A,B,C,E},
which is guaranteed to be infrequent
How to Generate Candidates?
Given set of frequent itemsets of length 3 (Ordered):
{A,B,C}, {A,B,D}, {A,C,D}, {B,C,D},{B,C,E},{C,D,E}
Ordered: therefore, there is no (A,C,B) between (ACD)
and (BCD), Combing will create infrequent (ACB)
Join a pair of frequent k-itemsets only if its prefix of length
(k-1) are identical (guarantees subset is frequent):
– Join {A,B,C} and {A,B,D} to produce {A,B,C,D}
– Do not have to join {A,B,C} and {B,C,D} since they don’t have the
same prefix
This avoids generating duplicate candidates
– Do not have to join {A,C,D} and {C,D,E}
• Subset is not frequent
Pruning
– Joining {B,C,D} and {B,C,E} will produce {B,C,D,E}
– Prune {B,C,D,E} because one of its subset {B,D,E} is not
How to Generate Candidates?
Let Lk-1 be the set of all frequent itemsets of length k-1
Assume each itemset in Lk-1 are sorted in lexicographic
order
Step 1: self-joining Lk-1
insert into Ck
select p.item1, p.item2, …, p.itemk-1, q.itemk-1
from Lk-1 p, Lk-1 q
where p.item1=q. item1, …, p. itemk-2=q. itemk-2,
p. itemk-1 < q. itemk-1
Step 2: pruning
forall itemsets c in Ck do
forall (k-1)-subsets s of c do
if (s is not in Lk-1 ) then delete c from Ck
How to Count Support of Candidates?
Why counting supports of candidates is a problem?
– The total number of candidates can be huge
–
Each transaction may contain many candidates
Method:
– Store candidate itemsets in a hash-tree
– Leaf node of the hash-tree contains a list of itemsets and their
respective support counts
– Interior node contains a hash table
Transactions
N
TID
1
2
3
4
5
Hash
Structure
Items
Bread, Milk
Bread, Diaper, Beer, Eggs
Milk, Diaper, Beer, Coke
Bread, Milk, Diaper, Beer
Bread, Milk, Diaper, Coke
k
Buckets
Generate Hash Tree
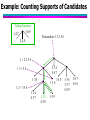
Suppose you have 15 candidate itemsets of length 3:
{1 4 5}, {1 2 4}, {4 5 7}, {1 2 5}, {4 5 8}, {1 5 9}, {1 3 6}, {2 3 4}, {5 6 7},
{3 4 5}, {3 5 6}, {3 5 7}, {6 8 9}, {3 6 7}, {3 6 8}
You need:
• Hash function
• Max leaf size: max number of itemsets stored in a leaf node (if
number of itemsets exceed max leaf size, split the node)
Hash function
3,6,9
1,4,7
2,5,8
234
567
145
124
457
136
125
458
159
345
356
357
689
367
368
Example: Counting Supports of Candidates
Subset function
3,6,9
1,4,7
Transaction: 1 2 3 5 6
2,5,8
1+2356
234
567
13+56
145
136
12+356
124
457
125
458
159
345
356
357
689
367
368
Rule Generation
Given a frequent itemset L, find all non-empty
subsets f L such that f L – f satisfies the
minimum confidence requirement
– If {A,B,C,D} is a frequent itemset, candidate rules:
ABC D,
A BCD,
AB CD,
BD AC,
ABD C,
B ACD,
AC BD,
CD AB,
ACD B,
C ABD,
AD BC,
BCD A,
D ABC
BC AD,
If |L| = k, then there are 2k – 2 candidate
association rules (ignoring L and L)
Rule Generation
How to efficiently generate rules from frequent
itemsets?
– In general, confidence does not have an antimonotone property
– But confidence of rules generated from the same
itemset has an anti-monotone property
– Frequent itemset: f = {A,B,C,D}
conf(ABC D) conf(AB CD) conf(A BCD)
Confidence is non-increasing as number of items in rule
consequent increases
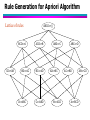
Rule Generation for Apriori Algorithm
Lattice of rules
BCD=>A
CD=>AB
BD=>AC
D=>ABC
ABCD=>{ }
ACD=>B
BC=>AD
C=>ABD
ABD=>C
AD=>BC
B=>ACD
ABC=>D
AC=>BD
A=>BCD
AB=>CD
Bottleneck of Apriori Algorithm
The core of the Apriori algorithm:
– Use frequent (k – 1)-itemsets to generate
candidate frequent k-itemsets
– Use database scan and pattern matching to
collect counts for the candidate itemsets
Bottleneck of Apriori: candidate generation
– Still far too many candidates
– For example, if there are 10000 frequent items, need to
generate (10000 9999)/2 candidates of length 2
Many
of them ends up being infrequent
FP-Tree and FP-growth
Compress a large database into a compact,
Frequent-Pattern tree (FP-tree) structure
– highly condensed, but complete for frequent pattern
mining
– avoid costly database scans
Develop an efficient, FP-tree-based frequent
pattern mining algorithm (called FP-growth)
– A divide-and-conquer methodology: decompose
mining tasks into smaller ones
– Generate “candidates” only if when it is necessary
Construct FP-tree
TID
100
200
300
400
500
Items bought
(ordered) frequent items
{f, a, c, d, g, i, m, p}
{f, c, a, m, p}
{a, b, c, f, l, m, o}
{f, c, a, b, m}
{b, f, h, j, o, w}
{f, b}
{b, c, k, s, p}
{c, b, p}
{a, f, c, e, l, p, m, n}
{f, c, a, m, p}
minsup = 3
{}
Header Table
1. Scan DB once, find
frequent 1-itemset
(single item pattern)
2. Sort frequent items in
frequency descending
order, f-list
3. Scan DB again,
construct FP-tree
Item frequency head
f
4
c
4
a
3
b
3
m
3
p
3
F-list=f-c-a-b-m-p
f:4
c:3
c:1
b:1
a:3
b:1
p:1
m:2
b:1
p:2
m:1
Benefits of the FP-tree Structure
Completeness
– Preserve information for frequent pattern mining
Compactness
– Reduce irrelevant info—infrequent items are gone
– Items in frequency descending order: the more
frequently occurring, the more likely to be shared
– Never larger than the original database (if we exclude
node-links and the count field)
For some dense data sets, compression ratio can be more
than a factor of 100
Partition Patterns and Databases
Frequent patterns can be partitioned into subsets
according to f-list (efficient partitioning because
ordered)
–
–
–
–
–
–
F-list=f-c-a-b-m-p
Patterns containing p
Patterns having m but no p
…
Patterns having c but no a nor b, m, p
Pattern f
Completeness and no redundancy
Deriving Frequent Itemsets from FP-tree
Start at the frequent item header table in the FP-tree
Traverse the FP-tree by following the link of each frequent item p
Accumulate all of transformed prefix paths of item p to form p’s
conditional pattern base
Cond. Pattern base below is generated recursively, shown next
{}
Header Table
Item frequency head
f
4
c
4
a
3
b
3
m
3
p
3
f:4
c:3
c:1
b:1
a:3
Conditional pattern bases
item
cond. pattern base
b:1
c
f:3
p:1
a
fc:3
b
fca:1, f:1, c:1
m:2
b:1
m
fca:2, fcab:1
p:2
m:1
p
fcam:2, cb:1
Deriving Frequent Itemsets from FP-tree
Start with the bottom, p. p is frequent pattern. Pattern
base for p:<f:2, c:2, a:2, m:2>, <c:1, b:1> frequent
items:c:3; Cond. FP-tree for p: <c:3|p>; recursive call
generates freq. pattern pc
m: m is frequent pattern. Pattern base: fca2, fcab1,
frequent items: fca3, Create cond. FP-tree. Mine(<f:3, c:3,
a:3>|m) involves mining a, c, f in sequence
Create frequent pattern am:3 and call mine(<f:3,
c:3>|am)
All frequent
Second: create frequent pattern cm:3 and call
mine(<f:3>|cam)
mine(<f:3>|cam) creates the longest pattern fcam:3
Note: each conditional FP-tree has calls from several
headers
Recursion: Mine Each Conditional FPtree
For each pattern-base
– Accumulate the count for each item in the base
– Construct the FP-tree for the frequent items of the
pattern base
Header Table
Item frequency head
f
4
c
4
a
3
b
3
m
3
p
3
m-conditional pattern base:
fca:2, fcab:1
{}
f:4
c:3
c:1
b:1
a:3
m:2
p:2
b:1
p:1
{}
f:3
c:3
b:1
m:1
All frequent
patterns relate to m
m,
fm, cm, am,
fcm, fam, cam,
fcam
a:3
m-conditional FP-tree
Recursion: Mine Each Conditional FP-tree
{}
{}
Cond. pattern base of “am”: (fc:3)
c:3
f:3
c:3
a:3
f:3
am-conditional FP-tree
Cond. pattern base of “cm”: (f:3)
{}
f:3
m-conditional FP-tree
cm-conditional FP-tree
{}
Cond. pattern base of “cam”: (f:3)
f:3
cam-conditional FP-tree
Special Case: Single Prefix Path in FP-tree
Suppose a (conditional) FP-tree T has a shared single
prefix-path P
Mining can be decomposed into two parts
– Reduction of the single prefix path into one node
– Concatenation of the mining results of the two parts
{}
a1:n1
a2:n2
a3:n3
b1:m1
C2:k2
r1
{}
C1:k1
C3:k3
r1
=
a1:n1
a2:n2
a3:n3
+
b1:m1
C2:k2
C1:k1
C3:k3
Mining Frequent Patterns With FP-trees
Idea: Frequent pattern growth
– Recursively grow frequent patterns by pattern and
database partition
Method
– For each frequent item, construct its conditional
pattern-base, and then its conditional FP-tree
– Repeat the process on each newly created conditional
FP-tree
– Until the resulting FP-tree is empty, or it contains only
one path—single path will generate all the
combinations of its sub-paths, each of which is a
frequent pattern
Scaling FP-growth by DB Projection
FP-tree cannot fit in memory?—DB projection
First partition a database into a set of projected
DBs
Then construct and mine FP-tree for each
projected DB
Partition-based Projection
Parallel projection needs a lot of disk space
Partition projection saves it
Tran. DB
fcamp
fcabm
fb
cbp
fcamp
p-proj DB
fcam
cb
fcam
m-proj DB
fcab
fca
fca
am-proj DB
fc
fc
fc
b-proj DB
f
cb
…
a-proj DB
fc
…
cm-proj DB
f
f
f
…
c-proj DB
f
…
f-proj DB
…
References
Srikant and Agrawal, “Fast Algorithms for Mining
Association Rules”
Han, Pei, Yin, “Mining Frequent Patterns without
Candidate Generation”