Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
CS 345:
Topics in Data Warehousing
Thursday, November 18, 2004
Review of Tuesday’s Class
• Data Mining
– What is data mining?
– Types of data mining
– Data mining pitfalls
• Decision Tree Classifiers
– What is a decision tree?
– Learning decision trees
– Entropy
– Information Gain
– Cross-Validation
Overview of Today’s Class
• Assignment #3 clarifications
• Association Rule Mining
– Market basket analysis
– What is an association rule?
– Frequent itemsets
• Association rule mining algorithms
– A-priori algorithm
– Speeding up A-priori using hashing
– One- and two-pass algorithms
* Adapted from slides by Vipin Kumar (Minnesota)
and Rajeev Motwani (Stanford)
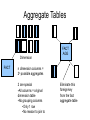
Aggregate Tables
FACT
AGG
Dimension
FACT
n dimension columns =
2n possible aggregates
2 are special
•All columns = original
dimension table
•No grouping columns
•Only 1 row
•No reason to join to
Eliminate this
foreign key
from the fact
aggregate table
Candidate Column Sets
Including fact aggregates
that use some base dimension
tables is optional
Association Rule Mining
• Given a set of transactions, find rules that will
predict the occurrence of an item based on the
occurrences of other items in the transaction
• Also known as market basket analysis
Market-Basket transactions
TID
Items
1
Bread, Milk
2
3
4
5
Bread, Diaper, Beer, Eggs
Milk, Diaper, Beer, Coke
Bread, Milk, Diaper, Beer
Bread, Milk, Diaper, Coke
Example of Association Rules
{Diaper} {Beer},
{Milk, Bread} {Eggs,Coke},
{Beer, Bread} {Milk},
Implication means co-occurrence,
not causality!
Definition: Frequent Itemset
• Itemset
– A collection of one or more items
• Example: {Milk, Bread, Diaper}
– k-itemset
• An itemset that contains k items
• Support count ()
– Frequency of occurrence of an
itemset
– E.g. ({Milk, Bread,Diaper}) = 2
• Support
– Fraction of transactions that
contain an itemset
– E.g. s({Milk, Bread, Diaper}) = 2/5
• Frequent Itemset
– An itemset whose support is
greater than or equal to a minsup
threshold
TID
Items
1
Bread, Milk
2
3
4
5
Bread, Diaper, Beer, Eggs
Milk, Diaper, Beer, Coke
Bread, Milk, Diaper, Beer
Bread, Milk, Diaper, Coke
Definition: Association Rule
• Association Rule
– An implication expression of the
form X Y, where X and Y are
itemsets
– Example:
{Milk, Diaper} {Beer}
• Rule Evaluation Metrics
– Confidence (c)
Items
1
Bread, Milk
2
3
4
5
Bread, Diaper, Beer, Eggs
Milk, Diaper, Beer, Coke
Bread, Milk, Diaper, Beer
Bread, Milk, Diaper, Coke
Example:
– Support (s)
• Fraction of transactions that
contain both X and Y
TID
{Milk , Diaper } Beer
s
(Milk, Diaper, Beer )
|T|
2
0.4
5
• Measures how often items in Y
(Milk, Diaper, Beer ) 2
appear in transactions that
c
0.67
contain X
(Milk, Diaper )
3
Association Rule Mining Task
• Given a set of transactions T, the goal of
association rule mining is to find all rules having
– support ≥ minsup threshold
– confidence ≥ minconf threshold
• High confidence = strong pattern
• High support = occurs often
– Less likely to be random occurrence
– Larger potential benefit from acting on the rule
Application 1 (Retail Stores)
• Real market baskets
– chain stores keep TBs of customer purchase
info
– Value?
• how typical customers navigate stores
• positioning tempting items
• suggests cross-sell opportunities – e.g.,
hamburger sale while raising ketchup price
•…
• High support needed, or no $$’s
Application 2 (Information
Retrieval)
• Scenario 1
– baskets = documents
– items = words in documents
– frequent word-groups = linked concepts.
• Scenario 2
– items = sentences
– baskets = documents containing sentences
– frequent sentence-groups = possible
plagiarism
Application 3 (Web Search)
• Scenario 1
– baskets = web pages
– items = outgoing links
– pages with similar references about same
topic
• Scenario 2
– baskets = web pages
– items = incoming links
– pages with similar in-links mirrors, or same
topic
Mining Association Rules
TID
Items
1
Bread, Milk
2
3
4
5
Bread, Diaper, Beer, Eggs
Milk, Diaper, Beer, Coke
Bread, Milk, Diaper, Beer
Bread, Milk, Diaper, Coke
Example of Rules:
{Milk,Diaper} {Beer} (s=0.4, c=0.67)
{Milk,Beer} {Diaper} (s=0.4, c=1.0)
{Diaper,Beer} {Milk} (s=0.4, c=0.67)
{Beer} {Milk,Diaper} (s=0.4, c=0.67)
{Diaper} {Milk,Beer} (s=0.4, c=0.5)
{Milk} {Diaper,Beer} (s=0.4, c=0.5)
Observations:
• All the above rules are binary partitions of the same itemset:
{Milk, Diaper, Beer}
• Rules originating from the same itemset have identical support but
can have different confidence
• Thus, we may decouple the support and confidence requirements
Mining Association Rules
• Goal – find all association rules such that
– support s
– confidence c
• Reduction to Frequent Itemsets Problems
–
–
–
–
–
Find all frequent itemsets X
Given X={A1, …,Ak}, generate all rules X-Aj Aj
Confidence = sup(X)/sup(X-Aj)
Support = sup(X)
Exclude rules whose confidence is too low
• Observe X-Aj also frequent support known
• Finiding all frequent itemsets is the hard part!
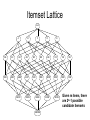
Itemset Lattice
null
A
B
C
D
E
AB
AC
AD
AE
BC
BD
BE
CD
CE
DE
ABC
ABD
ABE
ACD
ACE
ADE
BCD
BCE
BDE
CDE
ABCD
ABCE
ABDE
ABCDE
ACDE
BCDE
Given m items, there
are 2m-1 possible
candidate itemsets
Scale of Problem
• WalMart
– sells m=100,000 items
– tracks n=1,000,000,000 baskets
• Web
– several billion pages
– approximately one new “word” per page
• Exponential number of itemsets
–
–
–
–
m items → 2m-1 possible itemsets
Cannot possibly example all itemsets for large m
Even itemsets of size 2 may be too many
m=100,000 → 5 trillion item pairs
Frequent Itemsets in SQL
• DBMSs are poorly suited to association rule mining
• Star schema
– Sales Fact
– Transaction ID degenerate dimension
– Item dimension
• Finding frequent 3-itemsets:
SELECT Fact1.ItemID, Fact2.ItemID,
Fact3.ItemID, COUNT(*)
FROM Fact1
JOIN Fact2 ON Fact1.TID = Fact2.TID
AND Fact1.ItemID < Fact2.ItemID
JOIN Fact3 ON Fact1.TID = Fact3.TID
AND Fact1.ItemID < Fact2.ItemID
AND Fact2.ItemID < Fact3.ItemID
GROUP BY Fact1.ItemID, Fact2.ItemID, Fact3.ItemID
HAVING COUNT(*) > 1000
• Finding frequent k-itemsets requires joining k copies of fact table
– Joins are non-equijoins
– Impossibly expensive!
Association Rules and
Data Warehouses
• Typical procedure:
– Use data warehouse to apply filters
• Mine association rules for certain regions, dates
– Export all fact rows matching filters to flat file
• Sort by transaction ID
• Items in same transaction are grouped together
– Perform association rule mining on flat file
• An alternative:
– Database vendors are beginning to add specialized data mining
capabilities
– Efficient algorithms for common data mining tasks are built in to
the database system
• Decisions trees, association rules, clustering, etc.
– Not standardized yet
Finding Frequent Pairs
• Frequent 2-Sets
– hard case already
– focus for now, later extend to k-sets
• Naïve Algorithm
– Counters – all m(m–1)/2 item pairs (m = # of distinct items)
– Single pass – scanning all baskets
– Basket of size b – increments b(b–1)/2 counters
• Failure?
– if memory < m(m–1)/2
– m=100,000 → 5 trillion item pairs
– Naïve algorithm is impractical for large m
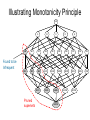
Pruning Candidate Itemsets
• Monotonicity principle:
– If an itemset is frequent, then all of its subsets
must also be frequent
• Monotonicity principle holds due to the
following property of the support measure:
X , Y : ( X Y ) s( X ) s(Y )
• Converse:
– If an itemset is infrequent, then all of its
supersets must also be infrequent
Illustrating Monotonicity Principle
null
A
B
C
D
E
AB
AC
AD
AE
BC
BD
BE
CD
CE
DE
ABC
ABD
ABE
ACD
ACE
ADE
BCD
BCE
BDE
CDE
Found to be
Infrequent
ABCD
Pruned
supersets
ABCE
ABDE
ABCDE
ACDE
BCDE
A-Priori Algorithm
• A-Priori – 2-pass approach in limited memory
• Pass 1
– m counters (candidate items in A)
– Linear scan of baskets b
– Increment counters for each item in b
• Mark as frequent, f items of count at least s
• Pass 2
– f(f-1)/2 counters (candidate pairs of frequent items)
– Linear scan of baskets b
– Increment counters for each pair of frequent items in b
• Failure – if memory < f(f–1)/2
– Suppose that 10% of items are frequent
– Memory is (m2 / 200) vs. (m2 / 2)
Finding Larger Itemsets
• Goal – extend A-Priori to frequent k-sets, k > 2
• Monotonicity
itemset X is frequent only if X – {Xj} is frequent for all Xj
• Idea
–
–
–
–
–
Stage k – finds all frequent k-sets
Stage 1 – gets all frequent items
Stage k – maintain counters for all candidate k-sets
Candidates – k-sets whose (k–1)-subsets are all frequent
Total cost: number of passes = max size of frequent itemset
A-Priori Algorithm
Item
Bread
Coke
Milk
Beer
Diaper
Eggs
Count
4
2
4
3
4
1
Items (1-itemsets)
Minimum Support = 3
If every subset is considered,
6C + 6C + 6C = 41
1
2
3
With support-based pruning,
6 + 6 + 3 = 15
Itemset
{Bread,Milk}
{Bread,Beer}
{Bread,Diaper}
{Milk,Beer}
{Milk,Diaper}
{Beer,Diaper}
Count
3
2
3
2
3
3
Pairs (2-itemsets)
(No need to generate
candidates involving Coke
or Eggs)
Triplets (3-itemsets)
Itemset
{Bread,Milk,Diaper}
Count
3
Memory Usage – A-Priori
M
E
M
O
R
Y
Candidate Items
Frequent Items
Candidate
Pairs
Pass 1
Pass 2
M
E
M
O
R
Y
PCY Idea
• Improvement upon A-Priori
– Uses less memory
– Proposed by Park, Chen, and Yu
• Observe – during Pass 1, memory mostly idle
• Idea
–
–
–
–
–
Use idle memory for hash-table H
Pass 1 – hash pairs from b into H
Increment counter at hash location
At end – bitmap of high-frequency hash locations
Pass 2 – bitmap extra condition for candidate pairs
• Similar to bit-vector filtering in “Bloom join”
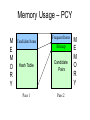
Memory Usage – PCY
M
E
M
O
R
Y
Candidate Items
Frequent Items
Bitmap
Hash Table
Candidate
Pairs
Pass 1
Pass 2
M
E
M
O
R
Y
PCY Algorithm
• Pass 1
–
–
–
–
m counters and hash-table T
Linear scan of baskets b
Increment counters for each item in b
Increment hash-table counter for each item-pair in b
• Mark as frequent, f items of count at least s
• Summarize T as bitmap (count > s bit = 1)
• Pass 2
– Counter only for F qualified pairs (Xi,Xj):
• both are frequent
• pair hashes to frequent bucket (bit=1)
– Linear scan of baskets b
– Increment counters for candidate qualified pairs of items in b
Multistage PCY Algorithm
• Problem – False positives from hashing
• New Idea
–
–
–
–
Multiple rounds of hashing
After Pass 1, get list of qualified pairs
In Pass 2, hash only qualified pairs
Fewer pairs hash to buckets less false positives
(buckets with count >s, yet no pair of count >s)
– In Pass 3, less likely to qualify infrequent pairs
• Repetition – reduce memory, but more passes
• Failure – memory < O(f+F)
Memory Usage – Multistage
PCY
Candidate Items
Hash Table 1
Frequent Items
Frequent Items
Bitmap
Bitmap 1
Bitmap 2
Hash Table 2
Candidate
Pairs
Pass 1
Pass 2
Approximation Techniques
• Goal
– find all frequent k-sets
– reduce to 2 passes
– must lose something accuracy
• Approaches
– Sampling algorithm
– SON (Savasere, Omiecinski, Navathe) Algorithm
– Toivonen Algorithm
Sampling Algorithm
• Pass 1 – load random sample of baskets in memory
• Run A-Priori (or enhancement)
– Scale-down support threshold
(e.g., if 1% sample, use s/100 as support threshold)
– Compute all frequent k-sets in memory from sample
– Need to leave enough space for counters
• Pass 2
– Keep counters only for frequent k-sets of random sample
– Get exact counts for candidates to validate
• Error?
– No false positives (Pass 2)
– False negatives (X frequent, but not in sample)
SON Algorithm
• Pass 1 – Batch Processing
–
–
–
–
Scan data on disk
Repeatedly fill memory with new batch of data
Run sampling algorithm on each batch
Generate candidate frequent itemsets
• Candidate Itemsets – if frequent in some batch
• Pass 2 – Validate candidate itemsets
• Monotonicity Property
Itemset X is frequent overall frequent in at least one
batch
Toivonen’s Algorithm
• Lower Threshold in Sampling Algorithm
– Example – if support threshold is 1%, use 0.8% as support
threshold when evaluating sample
– Goal – overkill to avoid any false negatives
• Negative Border
– Itemset X infrequent in sample, but all subsets are frequent
– Example: AB, BC, AC frequent, but ABC infrequent
• Pass 2
– Count candidates and negative border
– Negative border itemsets all infrequent candidates are exactly
the frequent itemsets
– Otherwise? – start over!
• Achievement? – reduced failure probability, while
keeping candidate-count low enough for memory