Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
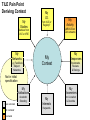
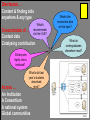
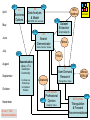
First year History students searching for Napoleon T I L E David Kay Also borrowed … They downloaded … They rated this resource as … They also recommended ... Sitting on a goldmine - the value of attention and activity data Supermarkets “Supermarkets gain valuable insights into user behaviour by data mining purchases and uncovering usage trends. Further insights are gained by analysing purchasing histories, facilitated by the use of store loyalty cards.” Dave Pattern, University of Huddersfield – TILE Workshop – December 2008 Libraries? “Libraries could gain valuable insights into user behaviour by data mining borrowing and uncovering usage trends. Further insights are gained by analysing borrowing histories, facilitated by the use of library cards.” Dave Pattern, University of Huddersfield – TILE Workshop – December 2008 Types of ‘Attention’ Data An attempt to break down the potential sources •Attention •Click stream behaviour indicating interests / connections •queries, navigation, details display, save for later •Activity •Formal Transactions •requesting, borrowing, downloading •Appeal •formal and informal lists •a type of recommendation •can be treated as a proxy for activity? •And … We could concentrate and contextualise the intelligence (patterns of user activity) existing in HE systems at institutional level whilst protecting anonymity in order to deliver ‘web scale’ services of value throughout the community – to undergraduates & researchers, to lecturers & librarians, to the institutions themselves. TILE Pain Point Deriving Context My Studies My I.D. From VLE or Registry? LMS/VLE/etc Click streams Modules from VLE or VRE My Networks e.g. FaceBook Subject Networks My Activity My Context My Responses Bookmarks Reviews & Ratings Not in initial specification My Publications User controlled HE ‘controlled’ Automated Academic Standing My Parameters My Interests Keywords Incl. Location & Override The possibility of critical mass of activity data from ‘Day 1’, brings to life the opportunity & motivation to embrace and curate user contribution (including ratings, reviews, bookmarks, lists) Barriers to contribution & use of contributed information must be as low as possible TILE Pain Point 2 Library 2.0 ‘Catalogue Related’ Activity Examples Enabling Contribution Metadata only Benefits of contribution must be clearly visible with real promise of being useful Metadata + Resource Create Local Catalogue Author Discover BL WorldCat Authorise Search Locate Approve Validate SUNCAT OER Mash Reuse Intute Deliver Enhance Access Request Catalogue Tag Repositories COPAC Publish Expose Liberate Consume Rate Review Use Archives Recommend LibraryThing Local VLE Curate Sustain Persist Business Processes Google Scholar My Website Services Distributed … Content & finding aids anywhere & any type What’s recommende d in the VLE? Concentration of … Context data Catalysing contribution Did anyone highly rate a textbook? What’s did last year’s students download most? Across … An Institution A Consortium A national system Global communities What’s the economics take on this topic? What do undergraduates elsewhere read? California State University 2008 MESUR contains 1bn usage events (2002-2007) obtained from 6 significant publishers, 4 large institutional consortia and 4 significant aggregators! The collected usage data spans more than 100,000 serials (including newspapers, magazines, etc.) and is related to journal citation data that spans about 10,000 journals and nearly 10 years (1996-2006). In addition we have obtained significant publisher-provided COUNTER usage reports that span nearly 2000 institutions worldwide. The data is being ingested into a combination of relational and semantic web databases, the latter of which is now estimated to result in nearly 10 billion semantic statements (triples). MESUR is producing large-scale, longitudinal maps of the scholarly community and a survey of more than 60 different metrics of scholarly impact. MESUR Personalisation > Aggregation? ‘The more we track and aggregate, the more our suggestions will be personalised.’ ‘… and the more we track, the better we can adapt our service without your intervention.’ ‘… we’ll even learn to recommend content by taking account of your location, habits & moods and by making comparisons’ My Calendar My GPS data My activity patterns WP1 April WP2 A2 A1 Business Options HEIs Vendors Data Analysis & Model WP3 LMS, ERM, VLE sources Dataset Extraction May WP4 June mosaic Grant Awards B1 Search Demonstrator Mimas Scale, Facets, Sense July August WP5 H’field Dissemination Library, LT & Developer Community C1 September October November A1 etc = TILE Recommendations Conferences Workshops Competition Website Librarians WP6 User Demand Research Mimas CERLIM Recognition, Value C1/Footnote Professional WP7 Opinion Integrity, Value B2/Footnote WP8 Triangulation & Forward Recommendations The No.1 Challenge - Generating Data Institution LMS Commitment University of Dundee Ex Libris Aleph committed to supplying data University College Falmouth Ex Libris Voyager confirmed interest in supplying data Swansea University Ex Libris Voyager confirmed interest in supplying data University of Warwick Innovative (Millennium) interested but not possible with current LMS University of Huddersfield SirsiDynix Horizon data supplied University of Lincoln SirsiDynix Horizon committed to supplying data University of Wolverhampton Talis data supplied University of Sussex Talis committed to supplying data University of Greenwich Talis recently invited to supply data University of Sheffield Talis interested but cannot commit to supply data Some have the transactions Some have the links Some have the technology Some have the resources Thanks to library teams and individual pioneers for their engagement Six entries to our recent competition to build applications around activity data Using multi-year released by the University of Huddersfield • Improving Resource Discovery – An intuitive interface to navigate the ‘Book Galaxy’ through links based on mass borrowing habits – Users create reading lists and share with other students (and lecturers) • Supporting learning choices – Applicants or new students get a feel a course based on the books students actually borrow – Possible courses of study are suggested based on the ISBNs of books you’ve personally enjoyed reading • Supporting decision making – Collection managers visualise historic circulation data relating to courses of study – Value the loans related to a specific course as a collection performance indicator Some Questions • What range of data sources available within higher education should be used to derive activity and context? • Does activity data need to be aggregated above the institutional level to achieve web scale and network effect? • Amazon tells you that ‘people who did this also did that’. Can academic libraries offer something more significant (‘people LIKE YOU who did this also did that’) because they know the user’s context (typically their course and institution)? • Precision in such as metadata and even citation is subject to personal judgements and motivations. Are these less reliable than pointers derived from mass contextualised activity data? • As proxies for real activity, are lists – formal reading lists, informal student lists – a form of attention data which can be highly weighted?