Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Clustering Algorithms Meta
Applier (CAMA) Toolbox
Dmitry S. Shalymov
Kirill S. Skrygan
Dmitry A. Lyubimov
Clustering
• Goals
– To detect the underlying structure in data
– To reduce data set capacity
– To extract unique objects
• Usage
–
–
–
–
–
–
–
Data mining
Machine learning
Financial mathematics
Optimization
Statistics
Pattern recognition
Control strategies development
SYRCoSE’09
Clustering Problem
{x1 , x2 ,..., xn } X
( x, x)
A lg : X Y
W
i j
[ yi y j ] ( xi , x j )
i j
[ yi y j ]
min
B
i j
[ yi y j ] ( xi , x j )
i j
[ yi y j ]
max
Clustering and Classification
SYRCoSE’09
Variety of Clustering Algorithms
• Hierarchical
– Aglomerative
– Partitioning
• Iterative
– Hard (K-means, SVM, SPSA)
– Fuzzy (FCM)
Important parameters
-Distance norm
-Number of clusters
-Initial values of cluster centers
SYRCoSE’09
Cluster Stability Algorithms
• Indexes
• Stability (similarity, merit) functions
• Probabilistic measures assessing the likelihood of a
decision
• Density estimation approaches
SYRCoSE’09
Stochastic Approximation
* : L / 0
Recursive stochastic approximation
k 1 k ak g k ( k )
g ( ) L /
FDSA
y ( k ck ei ) y ( k ck ei )
g ki ( k )
2ck
SPSA
y ( k ck k ) y ( k ck k )
g ki ( k )
2ck ki
k (k1 , k 2 ,..., kp )T
SYRCoSE’09
SYRCoSE’09
Effectiveness of SPSA
SYRCoSE’09
Finding the number of clusters in data set
• Run the SPSA algorithm for different numbers of clusters, K, and
calculate the corresponding distortions d K
• Select a transformation power, Y
• Calculate the “jumps” in transformed distortion J K d
Y
K
d Y K 1
• Estimate the number of clusters in the data set by
K * arg max K J K
SYRCoSE’09
Structure of data set detection
SYRCoSE’09
Examples
• Iris (3 clusters, 4
features, 150 instances)
• Wine (3 clusters, 13
features, 178 instances)
• Breast Cancer (2
clusters, 32 features,
569 instances)
• Image Segmentation (7
clusters, 19 features,
2310 instances)
SYRCoSE’09
Software Tools for Clustering Analysis
•
Research
–
–
–
–
–
–
–
–
•
License software
–
–
•
SPSS
STATISTICA
Characteristics
–
–
–
•
COMPACT
DCPR (Data Clustering & Pattern Recognition)
FCDA (Fuzzy Clustering and Data Analysis Toolbox)
ClusterPack Matlab Toolbox
The Curve Clustering Toolbox
SOM (Self-Organizing Map)
Spectral Clustering Toolbox
Yashil's FCM Clustering
Visualization
Efectiveness analysis with patterns
Tools to check performance
Shortcomings
–
–
–
–
Limited number of data sets and algorithms
No possibilities to load own algorithm
No on-line services
MATLAB
SYRCoSE’09
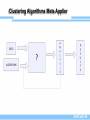
Clustering Algorithms Meta Applier
SYRCoSE’09
Clustering Algorithms Meta Applier
SYRCoSE’09
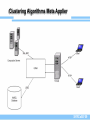
CAMA. Kernel
SYRCoSE’09
CAMA. Kernel
SYRCoSE’09
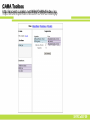
CAMA Toolbox
http://ancient.punklan.net:8084/CAMA2/index.jsp
SYRCoSE’09
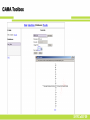
CAMA Toolbox
SYRCoSE’09
CAMA Toolbox
SYRCoSE’09
Thank you!
SYRCoSE’09