Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Predictive analytics wikipedia , lookup
Geographic information system wikipedia , lookup
Corecursion wikipedia , lookup
Theoretical computer science wikipedia , lookup
Non-negative matrix factorization wikipedia , lookup
Data analysis wikipedia , lookup
Computational phylogenetics wikipedia , lookup
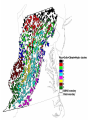
Classification Categorization is the process in which ideas and objects are recognized, differentiated and understood. Categorization implies that objects are grouped into categories, usually for some specific purpose. Ideally, a category illuminates a relationship between the subjects and objects of knowledge. Categorization is fundamental in language, prediction, inference, decision making and in all kinds of interaction with the environment. Statistical classification is a procedure in which individual items are placed into groups based on quantitative information on one or more characteristics inherent in the items (referred to as traits, variables, characters, etc) and based on a training set of previously labeled items. The essential problem categorical and topographic radar hyperspectral Rasters are better. Each cell is a sample point with n layers of attributes. “classification” multispectral thematic map Methods • Rule-based (overlay analysis) • Optimization Methods – Neutral Networks – Genetic Algorithms – Fuzzy Logic • Statistical Methods – – – – – – Clustering Principal Component Analysis (Ordination Analysis) Regression (ordinal logistic regression) Classification and Regression Trees (CART) Bayesian Methods Maximum Likelihood • Spatio-Temporal Analysis – Spatio-Temporal Clustering Image Classification Legend Water/Shadow/Dark Rock Ponderosa Pine/Pinyon-Juniper Pinyon-Juniper (Mixed) Mixed Grassland w/Scrub Mixed Scrub w/Grass Mixed Scrub (Blackbrush/Shadscale) Dark Volcanic Rock w/Mixed Pinyon Unsupervised Classification “is a process whereby numerical operations are performed that search for natural groupings of the spectral properties of pixels.” (Jensen. “Introductory Digital Image Processing.” NJ: Prentice Hall. 1996.) Unsupervised Black Mesa Painted Desert Hopi Buttes Clustering • Clustering is the classification of objects into different groups, or more precisely, the partitioning of a data set into subsets (clusters), so that the data in each subset (ideally) share some common trait often proximity according to some defined distance measure. • An important step in any clustering is to select a distance measure, which will determine how the similarity of two elements is calculated. This will influence the shape of the clusters, as some elements may be close to one another according to one distance and further away according to another. • Many methods (Isodata, K-mean, Fuzzy c-means, Hierarchical) • The main requirements that a clustering algorithm should satisfy are: – – – – – – – – scalability; dealing with different types of attributes; discovering clusters with arbitrary shape; minimal requirements for domain knowledge to determine input parameters; ability to deal with noise and outliers; insensitivity to order of input records; high dimensionality; interpretability and usability. Clustering • Potential problems with clustering are: – current clustering techniques do not address all the requirements adequately (and concurrently); – dealing with large number of dimensions and large number of data items can be problematic; – the effectiveness of the method depends on the definition of “distance” (for distance-based clustering); – if an obvious distance measure doesn’t exist we must “define” it, which is not always easy, especially in multi-dimensional spaces; – the result of the clustering algorithm (that in many cases can be arbitrary itself) can be interpreted in different ways. Principal Component Analysis (PCA) • • • • Numerical method Dimensionality reduction technique Primarily for visualization of arrays/samples ”Unsupervised” method used to explore the intrinsic variability of the data • Performs a rotation of the data that maximizes the variance in the new axes PCA • Projects high dimensional data into a low dimensional sub-space (visualized in 2-3 dims) • Often captures much of the total data variation in a few dimensions (< 5) • Principal Components – 1st Principal component (PC1) • Direction along which there is greatest variation – 2nd Principal component (PC2) • Direction with maximum variation left in data, orthogonal to PC1 Second Principal Component PCA First Principal Component Second Principal Component PCA First Principal Component Distance Measurement • An important component of a clustering algorithm is the distance measure between data points. • If the components of the data instance vectors are all in the same physical units then it is possible that the simple Euclidean distance metric is sufficient to successfully group similar data instances. This is what is done in remote sensing. • However, even in this case the Euclidean distance can sometimes be misleading. Below is an example of the width and height measurements of an object. As the figure shows, different scalings can lead to different clusterings. K-Means Clustering • K-means is one of the simplest unsupervised learning algorithms to solve a clustering problem. The procedure follows a simple and easy way to classify a given data set through a certain number of clusters (assume k clusters) fixed a priori. The main idea is to define k centroids, one for each cluster. • Procedure (for 3 clusters): – Make initial guesses for the means m1, m2, ..., mk – Until there are no changes in any mean • Use the estimated means to classify the samples into clusters • For i from 1 to k – Replace mi with the mean of all of the samples for cluster i • end_for – end_until Classification of watersheds based on abiotic factors