Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Data Mining
Association Analysis: Basic Concepts
and Algorithms
Lecture Notes for Chapter 6 (2)
Introduction to Data Mining
by
Tan, Steinbach, Kumar
© Tan,Steinbach, Kumar
Introduction to Data Mining
4/18/2004
1
Rule Generation
Given a frequent itemset L, find all non-empty
subsets f L such that f L – f satisfies the
minimum confidence requirement
– If {A,B,C,D} is a frequent itemset, candidate rules:
ABC D,
A BCD,
AB CD,
BD AC,
ABD C,
B ACD,
AC BD,
CD AB,
ACD B,
C ABD,
AD BC,
BCD A,
D ABC
BC AD,
If |L| = k, then there are 2k – 2 candidate
association rules (ignoring L and L)
© Tan,Steinbach, Kumar
Introduction to Data Mining
4/18/2004
‹#›
Rule Generation
How to efficiently generate rules from frequent
itemsets?
– In general, confidence does not have an antimonotone property
c(ABC D) can be larger or smaller than c(AB D)
– But confidence of rules generated from the same
itemset has an anti-monotone property
– e.g., L = {A,B,C,D}:
c(ABC D) c(AB CD) c(A BCD)
Confidence is anti-monotone w.r.t. number of items on the
RHS of the rule
© Tan,Steinbach, Kumar
Introduction to Data Mining
4/18/2004
‹#›
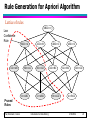
Rule Generation for Apriori Algorithm
Lattice of rules
Low
Confidence
Rule
CD=>AB
ABCD=>{ }
BCD=>A
ACD=>B
BD=>AC
D=>ABC
BC=>AD
C=>ABD
ABD=>C
AD=>BC
B=>ACD
ABC=>D
AC=>BD
AB=>CD
A=>BCD
Pruned
Rules
© Tan,Steinbach, Kumar
Introduction to Data Mining
4/18/2004
‹#›
Rule Generation for Apriori Algorithm
Candidate rule is generated by merging two rules
that share the same prefix
in the rule consequent
CD=>AB
BD=>AC
join(CD=>AB,BD=>AC)
would produce the candidate
rule D => ABC
D=>ABC
Prune rule D=>ABC if its
subset AD=>BC does not have
high confidence
© Tan,Steinbach, Kumar
Introduction to Data Mining
4/18/2004
‹#›