Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Moving Social Network Mining
Algorithms to the MapReduce World
August 23, 2012
KAIST
Jae-Gil Lee
강연자 소개 - 이재길 교수
약력
2010년 12월~현재: KAIST 지식서비스공학과 조교수
2008년 9월~2010년 11월: IBM Almaden Research Center 연구원
2006년 7월~2008년 8월: University of Illinois at UrbanaChampaign 박사후연구원
연구분야
시공간 데이터 마이닝 (경로 및 교통 데이터)
소셜 네트워크 및 그래프 데이터 마이닝
빅 데이터 분석 (MapReduce 및 Hadoop)
연락처
E-mail:
홈페이지: http://dm.kaist.ac.kr/jaegil
2012-08-23
2
KAIST 지식서비스공학과
지식서비스공학은 인지공학,
인공지능, IT 기술, 의사결정,
HCI, 빅데이터 분석 등의 지식
관련 기술을 융합하여 인간과
IT 시스템과의 소통과 협력을
혁신하는 지능적 지식서비스를
연구 개발하는 것을 목표로 하
고 있으며 지식서비스 발전의
중심축을 이루는 학문이다.
홈페이지:
http://kse.kaist.ac.kr/
2012-08-23
3
Contents
1
Big Data and Social Networks
2
MapReduce and Hadoop
3
Data Mining with MapReduce
4
Social Network Data Mining
with MapReduce
5
Conclusions
1. Big Data and Social Networks
Big Data (1/2)
Big data refers to datasets whose size is beyond the
ability of typical database software tools to capture, store,
manage, and analyze [IDC]
IDC forecast of the size of “digital universe” in 2011 is 1.8
zettabytes (A zettabyte is one billion terabytes!)
The size of datasets that qualify as big data will also increase
The three V’s: Volume, Velocity, Variety
Velocity refers to the low-latency, real-time speed at which
analytics needs to be applied
Volume refers to "internet scale"
Variety means that data is in all sorts of forms all over the place
2012-08-23
6
Big Data (2/2)
2012-08-23
7
Big Data Social Networks
The online social network (OSN) is one of the
main sources of big data
2012-08-23
8
Data Growth in Facebook
2012-08-23
9
Data Growth in Twitter
2012-08-23
10
Some Statistics on OSNs
Twitter is estimated to have 140 million users,
generating 340 million tweets a day and handling
over 1.6 billion search queries per day
As of May 2012, Facebook has more than 900
million active users; Facebook has 138.9 million
monthly unique U.S. visitors in May 2011
2012-08-23
11
Social Network Service
An online service, platform, or site that focuses
on building and reflecting of social networks or
social relations among people, who, for example,
share interests and/or activities [wikipedia]
Consists of a representation of each user (often
a profile), his/her social links, and a variety of
additional services
Provides service using web or mobile phones
2012-08-23
12
Popular OSN Services
Facebook, Twitter, LinkedIn, 싸이월드,
카카오스토리, 미투데이
Inherently created for social networking
Flickr, YouTube
Originally created for content sharing
Also allow an extensive level of social interaction
• e.g., subscription features
Foursquare, Google Latitude, 아임IN
Geosocial networking services
2012-08-23
13
Other Forms of OSNs
MSN Messenger, Skype, Google Talk, 카카오톡
Can be considered as an indirect form of social
networks
Bibliographic networks (e.g., DBLP, Google
Scholar)
Co-authorship data
Citation data
Blogs (e.g., Naver Blog)
Neighbor list
2012-08-23
14
Data Characteristics
Relationship data: e.g., follower, …
Content data: e.g., tweets, …
Location data
contents
a user
location
2012-08-23
relationship
15
Graph Data
A social network is usually
modeled as a graph
A node → an actor
An edge → a relationship
or an interaction
2012-08-23
16
Directed or Undirected?
Edges can be either directed or undirected
Undirected edge (or symmetric relationship)
No direction in edges
Facebook friendship: if A is a friend of B, then B
B
should be also a friend of A A
Directed edge (or asymmetric relationship)
Direction does matter in edges
Twitter following: although A is a follower of B, B may
not be a follower of A A
B
2012-08-23
17
Weight on Edges?
Edges can be weighted
A
𝑤
B
Examples of weight?
Geographical social networking data → ?
DBLP co-authorship data → ?
…
2012-08-23
18
Two Types of Graph Data
Multiple graphs (each
of which may possibly
be of modest size)
e.g., chemical
compound database
2012-08-23
A single large graph
Scope of this tutorial
e.g., social network data
(in the previous page)
19
2. MapReduce and Hadoop
Note: Some of the slides in this section are from KDD 2011 tutorial
“Large-scale Data Mining: MapReduce and Beyond”
Big Data Analysis
To handle big data, Google
proposed a new approach
called MapReduce
MapReduce can crunch
huge amounts of data by
splitting the task over
multiple computers that can
operate in parallel
No matter how large the problem
is, you can always increase the
number of processors (that today
are relatively cheap)
2012-08-23
21
MapReduce Basics
Map step: The master node takes the
input, divides it into smaller subproblems, and distributes them to
worker nodes. The worker node
processes the smaller problem, and
passes the answer back to its master
node.
Example:
Reduce step: The master node then
collects the answers to all the subproblems and combines them in some
way to form the output – the answer
to the problem it was originally trying
to solve.
2012-08-23
22
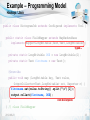
Example – Programming Model
mapper
employees.txt
# LAST
Smith
Brown
Johnson
Yates
Miller
Moore
Taylor
Smith
Harris
...
...
FIRST
John
David
George
John
Bill
Jack
Fred
David
John
...
...
SALARY
$90,000
$70,000
$95,000
$80,000
$65,000
$85,000
$75,000
$80,000
$90,000
...
...
Q: “What is the frequency
of each first name?”
2012-08-23
def getName (line):
return line.split(‘\t’)[1]
reducer
def addCounts (hist, name):
hist[name] = \
hist.get(name,default=0) + 1
return hist
input = open(‘employees.txt’, ‘r’)
intermediate = map(getName, input)
result = reduce(addCounts, \
intermediate, {})
23
Example – Programming Model
mapper
employees.txt
# LAST
Smith
Brown
Johnson
Yates
Miller
Moore
Taylor
Smith
Harris
...
...
FIRST
John
David
George
John
Bill
Jack
Fred
David
John
...
...
SALARY
$90,000
$70,000
$95,000
$80,000
$65,000
$85,000
$75,000
$80,000
$90,000
...
...
Q: “What is the frequency
of each first name?”
2012-08-23
def getName (line):
return (line.split(‘\t’)[1], 1)
reducer
def addCounts (hist, (name, c)):
hist[name] = \
hist.get(name,default=0) + c
return hist
input = open(‘employees.txt’, ‘r’)
intermediate = map(getName, input)
result = reduce(addCounts, \
intermediate, {})
Key-value iterators
24
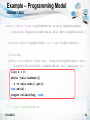
Example – Programming Model
Hadoop / Java
public class HistogramJob extends Configured implements Tool {
public static class FieldMapper extends MapReduceBase
implements Mapper<LongWritable,Text,Text,LongWritable> {
typed…
private static LongWritable ONE = new LongWritable(1);
private static Text firstname = new Text();
@Override
public void map (LongWritable key, Text value,
OutputCollector<Text,LongWritable> out, Reporter r) {
firstname.set(value.toString().split(“\t”)[1]);
output.collect(firstname, ONE);
non-boilerplate
}
} // class FieldMapper
2012-08-23
25
Example – Programming Model
Hadoop / Java
public static class LongSumReducer extends MapReduceBase
implements Mapper<LongWritable,Text,Text,LongWritable> {
private static LongWritable sum = new LongWritable();
@Override
public void reduce (Text key, Iterator<LongWritable> vals,
OutputCollector<Text,LongWritable> out, Reporter r) {
long s = 0;
while (vals.hasNext())
s += vals.next().get();
sum.set(s);
output.collect(key, sum);
}
} // class LongSumReducer
2012-08-23
26
Example – Programming Model
Hadoop / Java
public int run (String[] args) throws Exception {
JobConf job = new JobConf(getConf(), HistogramJob.class);
job.setJobName(“Histogram”);
FileInputFormat.setInputPaths(job, args[0]);
job.setMapperClass(FieldMapper.class);
job.setCombinerClass(LongSumReducer.class);
job.setReducerClass(LongSumReducer.class);
// ...
JobClient.runJob(job);
return 0;
} // run()
public static main (String[] args) throws Exception {
ToolRunner.run(new Configuration(), new HistogramJob(), args);
} // main()
} // class HistogramJob
2012-08-23
27
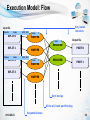
Execution Model: Flow
Key/value
iterators
Input file
Smith
John
$90,000
SPLIT 0
John
1
MAPPER
John
John
SPLIT 2
Output file
REDUCER
SPLIT 1
Yates
2
MAPPER
$80,000
John
1
REDUCER
MAPPER
PART 0
PART 1
SPLIT 3
MAPPER
Sort-merge
All-to-all, hash partitioning
2012-08-23
Sequential scan
28
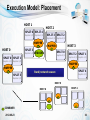
Execution Model: Placement
HOST 1
SPLIT 0
Replica 2/3
HOST 2
SPLIT 4
Replica 1/3
MAPPER
SPLIT 3
HOST 0
SPLIT 0
Replica 1/3
SPLIT 3
Replica 3/3
SPLIT 2
Replica 2/3
MAPPER
HOST 3
SPLIT 0
Replica 1/3
Replica 3/3
SPLIT 1
SPLIT 2
Replica 3/3
SPLIT 1
Replica 1/3
Replica 2/3
MAPPER
MAPPER
SPLIT 3
Computation co-located with data
(as much as possible)
SPLIT 4
Replica 2/3
Replica 2/3
HOST 5
HOST 6
2012-08-23
HOST 4
29
Execution Model: Placement
HOST 1
SPLIT 0
Replica 2/3
HOST 2
SPLIT 4
Replica 1/3
MAPPER
C
SPLIT 3
HOST 0
SPLIT 0
Replica 1/3
Replica 1/3
SPLIT 3
Replica 3/3
SPLIT 2
Replica 2/3
MAPPER
HOST 3
C
SPLIT 0
REDUCER
Replica 3/3
SPLIT 1
SPLIT 2
Replica 3/3
SPLIT 1
Replica 1/3
Replica 2/3
MAPPER
C
MAPPER
C
SPLIT 3
SPLIT 4
Rack/network-aware
Replica 2/3
Replica 2/3
HOST 5
HOST 6
C
HOST 4
COMBINER
2012-08-23
30
Apache Hadoop
The most popular open-source implementation of
MapReduce
http://hadoop.apache.org/
HBase
Pig
MapReduce
Core
2012-08-23
Hive
Chukwa
HDFS
Zoo
Keeper
Avro
31
Apache Mahout (1/2)
A scalable machine learning and data mining library built
upon Hadoop
Currently, ver 0.7: the implementation details are not known
http://mahout.apache.org/
Supporting algorithms
Collaborative filtering
User and Item based recommenders
K-Means, Fuzzy K-Means clustering
Singular value decomposition
Parallel frequent pattern mining
Complementary Naive Bayes classifier
Random forest decision tree based classifier
…
2012-08-23
32
Apache Mahout (2/2)
Data structure for vectors and matrices
Vectors
• Dense vectors as a double[]
• Sparse vectors as a HashMap<Integer, Double>
• Operations: assign, cardinality, copy, divide, dot, get,
haveSharedCells, like, minus, normalize, plus, set, size, times,
toArray, viewPart, zSum, and cross
Matrices
• Dense matrix as a double[][]
• SparseRowMatrix or SparseColumnMatrix as a Vector[] as holding
the rows or columns of the matrix in a SparseVector
• SparseMatrix as a HashMap<Integer, Vector>
• Operations: assign, assignColumn, assignRow, cardinality, copy,
divide, get, haveSharedCells, like, minus, plus, set, size, times,
transpose, toArray, viewPart, and zSum
2012-08-23
33
3. Data Mining with MapReduce
Clustering Basics
Grouping data to form new categories (clusters)
Principle: maximizing intra-cluster similarity and
minimizing inter-cluster similarity
e.g., customer locations in a city
two
clusters
2012-08-23
35
k-Means Clustering (1/3)
1. Arbitrarily choose k points from D as the initial
cluster centers
2. (Re)assign each point to the cluster to which the
point is the most similar, based on the mean
value of the points in the cluster (centroid)
3. Update the cluster centroids, i.e., calculate the
mean value of the points for each cluster
4. Repeat 2~3 until the criterion function converges
2012-08-23
36
k-Means Clustering (2/3)
Iteration 6
1
2
3
4
5
3
2.5
2
y
1.5
1
0.5
0
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
x
2012-08-23
37
k-Means Clustering (3/3)
Iteration 1
Iteration 2
Iteration 3
2.5
2.5
2.5
2
2
2
1.5
1.5
1.5
y
3
y
3
y
3
1
1
1
0.5
0.5
0.5
0
0
0
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
-2
-1.5
-1
-0.5
x
0
0.5
1
1.5
2
-2
Iteration 4
Iteration 5
2.5
2
2
2
1.5
1.5
1.5
1
1
1
0.5
0.5
0.5
0
0
0
-0.5
0
x
2012-08-23
0.5
1
1.5
2
0
0.5
1
1.5
2
1
1.5
2
y
2.5
y
2.5
y
3
-1
-0.5
Iteration 6
3
-1.5
-1
x
3
-2
-1.5
x
-2
-1.5
-1
-0.5
0
x
0.5
1
1.5
2
-2
-1.5
-1
-0.5
0
0.5
x
38
k-Means on MapReduce (1/2)
[Chu et al., 2006]
Map: assigning each point to the closet centroid
Mapper1
Map (point p, the set of centroids):
for c in centroids do
if dist(p, c) < minDist then
minDist = dist(p, c)
closestCentroid = c
emit (closestCentroid, p)
Data
Mapper2
Map
Reduce
(1, …), (2, …)
2012-08-23
Split1
Mapper1
Split2
Mapper2
Reducer1
(3, …), (4, …)
Reducer2
39
k-Means on MapReduce (2/2)
[Chu et al., 2006]
Reduce: updating each centroid with newly
assigned points
Reducer1
Reduce (centroid c, the set of points):
for p in points do
coordinates += p
count += 1
emit (c, coordinates / count)
Reducer2
Repeat
Data
Map
Reduce
(1, …), (2, …)
2012-08-23
Split1
Mapper1
Reducer1
New centroids
for C1 and C2
Split2
Mapper2
Reducer2
New centroids
for C3 and C4
(3, …), (4, …)
40
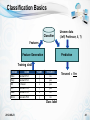
Classification Basics
Classifier
Unseen data
(Jeff, Professor, 4, ?)
Features
Prediction
Feature Generation
Training data
NAME
Mike
Mary
Bill
Jim
Dave
Anne
RANK
Assistant Prof
Assistant Prof
Professor
Associate Prof
Assistant Prof
Associate Prof
YEARS
3
7
2
7
6
3
TENURED
no
yes
yes
yes
no
no
Tenured = Yes
Class label
2012-08-23
41
k-NN Classification (1/2)
Intuition behind k-NN classification
Compute
Distance
Training
Records
2012-08-23
Test
Record
Choose the k
“nearest” records
42
k-NN Classification (2/2)
Compute the distance to
other training records
Identify k nearest
neighbors
Use the class labels of
the NNs to determine
the class label of an
unknown record (e.g., by
the majority vote)
2012-08-23
Unknown record
43
k-NN Classification on MapReduce (1/2)
Map: finding candidates for k-nearest neighbors
Obtaining local k-nearest neighbors in the split
k=3
Map (query q, the set of points):
knns = find k-nearest neighbors
from the given set of points
// Output the k-NNs in the split
emit (q, knns)
Data
Split1
Split2
2012-08-23
Map
Mapper1
Mapper1
Mapper2
Query
Reduce
local
k-nearest
neighbors
Reducer1
Mapper2
44
k-NN Classification on MapReduce (2/2)
Reduce: finding true k-nearest neighbors
Obtaining global k-nearest neighbors
k=3
Reduce (query q, local neighbors):
knns = find k-nearest neighbors
among all local neighbors
emit (q, knns)
Reducer1
Query
Only Once
Data
Split1
Split2
2012-08-23
Map
Mapper1
Reduce
local
k-nearest
neighbors
Reducer1
k-nearest
neighbors
Mapper2
45
Naïve Bayes Classifiers (1/2)
The probability model for a classifier is a
conditional model 𝑝(𝐶|𝐴1 , … , 𝐴𝑛 )
Using Bayes’ theorem, we write
𝑝 𝐶 𝑝(𝐴1 , … , 𝐴𝑛 |𝐶)
𝑝 𝐶 𝐴1 , … , 𝐴𝑛 =
𝑝(𝐴1 , … , 𝐴𝑛 )
Under the conditional independence
assumptions, the conditional distribution can be
expressed as below
𝑛
1
𝑝 𝐶 𝐴1 , … , 𝐴𝑛 = 𝑝(𝐶)
𝑝(𝐴𝑖 |𝐶)
𝑍
𝑖=1
2012-08-23
46
Naïve Bayes Classifiers (2/2)
Example
X = (age <=30, income = medium, student = yes, credit_rating = fair)
P(buy = “yes”) = 9/14 = 0.643
P(buy = “no”) = 5/14= 0.357
P(age = “<=30” | buy = “yes”) = 2/9 = 0.222
P(age = “<= 30” | buy = “no”) = 3/5 = 0.6
P(income = “medium” | buy = “yes”) = 4/9 = 0.444
P(income = “medium” | buy = “no”) = 2/5 = 0.4
P(student = “yes” | buy = “yes) = 6/9 = 0.667
P(student = “yes” | buy = “no”) = 1/5 = 0.2
P(credit_rating = “fair” | buy = “yes”) = 6/9 = 0.667
P(credit_rating = “fair” | buy = “no”) = 2/5 = 0.4
P(X | buy = “yes”) = 0.222 x 0.444 x 0.667 x 0.667 = 0.044
P(X | buy = “no”) = 0.6 x 0.4 x 0.2 x 0.4 = 0.019
0.643 x 0.044 = 0.028 vs. 0.357 x 0.019 = 0.007
buy = yes
2012-08-23
age
income student credit_rating buy
<=30
high
no
fair
no
<=30
high
no
excellent
no
31…40
high
no
fair
yes
>40
medium
no
fair
yes
>40
low
yes
fair
yes
>40
low
yes
excellent
no
31…40
low
yes
excellent
yes
<=30
medium
no
fair
no
<=30
low
yes
fair
yes
>40
medium
yes
fair
yes
<=30
medium
yes
excellent
yes
31…40
medium
no
excellent
yes
31…40
high
yes
fair
yes
>40
medium
no
excellent
no
Training Data
47
Naïve Bayes Classifiers on MapReduce
(1/3) [Chu et al., 2006]
We have to estimate 𝑝(𝐴𝑗 = 𝑘|𝐶 = 1), 𝑝(𝐴𝑗 =
𝑘|𝐶 = 0), 𝑝(𝐶) from the training data
For simplicity, we consider two-class problems
Thus, we count the number of records in parallel
1. 𝑠𝑝𝑙𝑖𝑡 1{𝐴𝑗 = 𝑘|𝐶 = 1}
2.
𝑠𝑝𝑙𝑖𝑡 1{𝐴𝑗
3.
𝑠𝑝𝑙𝑖𝑡 1{𝐶
= 1}
4.
𝑠𝑝𝑙𝑖𝑡 1{𝐶
= 0}
2012-08-23
= 𝑘|𝐶 = 0}
48
Naïve Bayes Classifiers on MapReduce
(2/3) [Chu et al., 2006]
Map: counting the number of records for 1~4 in
the previous page
(1) For conditional probability (2) For class distribution
Map (record):
emit ((Aj, C), 1)
Data
Map (record):
emit (C, 1)
Map
Reduce
Counts for C=1
2012-08-23
Split1
Mapper1
Split2
Mapper2
Reducer1
Counts for C=0
Reducer2
49
Naïve Bayes Classifiers on MapReduce
(3/3) [Chu et al., 2006]
Reduce: summing up the counts
(1) For conditional probability (2) For class distribution
Reduce ((Aj, C), counts):
total += counts
emit ((Aj, C), total)
Reduce (C, counts):
total += counts
emit (C, total)
Only Once
Data
Map
Reduce
Counts for C=1
2012-08-23
Split1
Mapper1
Reducer1
𝑝 𝐴𝑗 𝐶 = 1 , 𝑝(𝐶 = 1)
Split2
Mapper2
Reducer2
𝑝 𝐴𝑗 𝐶 = 0 , 𝑝(𝐶 = 0)
Counts for C=0
50
4. Social Network Data Mining
with MapReduce
Degree Statistics
Vertex in-degree: how many incoming edges
does a vertex X have?
Graph in-degree distribution: how many
vertices have X number of incoming edges?
These two fundamental statistics serve as a
foundation for more quantifying statistics
developed in the domains of graph theory and
network science
2012-08-23
52
Computing Degree Statistics on
MapReduce [Cohen, 2009]
2
input graph
1
3
vertex in-degree
key
value
1
2
1
2
3
graph in-degree distribution
key
value
key
value
1
1
1
1
2
1
2
3
1
3
3
3
1
key
value
1
1
2
1
key
1
value
1
2
2
1
1
2
1
Map
2012-08-23
Reduce
Map
Reduce
53
Clustering Coefficient (1/3)
A measure of degree to which nodes in a graph
tend to cluster together
Definition: Local clustering coefficient
cc(v)
= # of edges between neighbors of a node v /
# of possible edges between neighbors of v
{(𝑢, 𝑤) ∈ 𝐸|𝑢 ∈ Γ(𝑣) ∧ 𝑤 ∈ Γ(𝑣)
=
𝑑𝑣
2
N/A
′
# Δ s incidient on 𝑣
=
𝑑𝑣
2
2012-08-23
1
3
1
1
54
Clustering Coefficient (2/3)
Example
clustering coefficient( ) = 0.5
clustering coefficient( ) = 0.1
It captures how tight-knit the network around a node
Network cohesion: tightly-knit communities foster
more trust and social norms
2012-08-23
55
Clustering Coefficient (3/3)
Approach
Computing the clustering coefficient of each node
reduces to computing the number of triangles incident
on each node
Sequential algorithm
for v ∈V do
for u, w ∈ Γ(𝑣) do
if (u, w) ∈ E then
Triangles[v]++
2012-08-23
Triangles[v]=1
v
w
u
56
Counting Triangles on MapReduce (1/4)
[Suri et al., 2011]
Basic algorithm
Map 1:
• For each 𝑢 ∈ 𝑉, send Γ(𝑢) to a reducer
𝑣1
𝑣2
𝑣3
𝑣4
Reduce 1:
• Generate all 2-paths of the form <𝑣1 , 𝑣2 ; 𝑢>,
where 𝑣1 , 𝑣2 ∈ Γ(𝑢)
𝑢
Map 2:
• Send <𝑣1, 𝑣2 ; 𝑢> to a reducer,
• Send graph edges <𝑣1, 𝑣2 ; $> to the reducer
𝑣2
Reduce 2: input <𝑣1 , 𝑣2 ; 𝑢1 , …, 𝑢𝑘 , $?>
• If $ in input, then 𝑣1 , 𝑣2 get k/3 Δ’s each,
and 𝑢1 , ..., 𝑢𝑘 get 1/3 Δ’s each
2012-08-23
𝑢1
𝑢2
𝑢𝑘
𝑣1
57
Counting Triangles on MapReduce (2/4)
[Suri et al., 2011]
Example
After Map 1 & Reduce 1
;
;
;
;
;
After Map 2 & Reduce 2
2012-08-23
;
;
$
+1/3
+1/3
+1/3
;
;
;
$
+1/3
+1/3
+1/3
$
+1/3
+1/3
+1/3
58
Counting Triangles on MapReduce (3/4)
[Suri et al., 2011]
Possible improvement
Generating 2-paths around high-degree nodes is
expensive
We can make the lowest-degree node
𝑢
responsible for counting the triangle
• Let ≻ be the total order on nodes
such that 𝑣 ≻ 𝑢 if 𝑑𝑣 > 𝑑𝑢
• 2-paths < 𝑢, 𝑤; 𝑣 > are
generated only if 𝑣 ≺ 𝑢 and 𝑣 ≺ 𝑤
𝑤
𝑣
< 𝑢, 𝑤; 𝑣 >
2012-08-23
59
Counting Triangles on MapReduce (4/4)
[Suri et al., 2011]
Improved algorithm
Map 1:
• If 𝑣 ≻ 𝑢, emit < 𝑢; 𝑣 >
≺
Reduce 1: input < 𝑢; 𝑆 ⊆ Γ 𝑢 >
≺
≺
• Generate all 2-paths of the form < 𝑣1 , 𝑣2 ; 𝑢 >, where 𝑣1 , 𝑣2 ∈
𝑆
;
Map 2 and Reduce 2 are the same as before except 1
(instead of 1/3) is added to each node
;
2012-08-23
$
+1
+1
+1
60
Finding Trusses
[Cohen 2009]
A k-truss is a relaxation of a k-clique and is a nontrivial,
single-component maximal subgraph, such that every
edge is contained in at least k - 2 triangles in the
subgraph
(a) 3-trusses
2012-08-23
(b) 4-trusses
(c) 5-trusses
61
Finding Trusses on MapReduce
[Cohen 2009]
Input: triangles
Map
Output: # of triangles for each edge
Reduce
k=4
Output: pass edges that occur in a sufficient number of triangles
2012-08-23
62
PageRank Overview (1/4)
Google describes PageRank:
“… PageRank also considers
the importance of each page
that casts a vote, as votes
from some pages are
considered to have greater
value, thus giving the linked
page greater value. … and
our technology uses the collective intelligence of the
web to determine a page's importance”
A page referenced by many high-quality pages
is also a high-quality page
2012-08-23
63
PageRank Overview (2/4)
Formula
OR
PR(A): PageRank of a page A
d: the probability, at any step, that the person will
continue which is called a damping factor d (usually,
set to be 0.85)
L(B): the number of outbound links on a page B
N: the total number of pages
2012-08-23
64
PageRank Overview (3/4)
Example
PR(A) = (1–d) * (1/N) + d * (PR(C) / 2)
PR(B) = (1–d) * (1/N) + d * (PR(A) / 1 + PR(C) / 2)
PR(C) = (1–d) * (1/N) + d * (PR(B) / 1)
Set d = 0.70 for ease of calculation
PR(A) = 0.1 + 0.35 * PR(C)
PR(B) = 0.1 + 0.70 * PR(A) + 0.35 * PR(C)
B
PR(C) = 0.1 + 0.70 * PR(B)
Iteration 1: PR(A) = 0.33, PR(B) = 0.33, PR(C) = 0.33
Iteration 2: PR(A) = 0.22, PR(B) = 0.45, PR(C) = 0.33
Iteration 3: PR(A) = 0.22, PR(B) = 0.37, PR(C) = 0.41
…
Iteration 9: PR(A) = 0.23, PR(B) = 0.39, PR(C) = 0.38
2012-08-23
A
C
65
PageRank Overview (4/4)
A random surfer selects a page and keeps
clicking links until getting bored, then randomly
selects another page
PR(A) is the probability that such a user visits A
(1-d) is the probability of getting bored at a page (d is
called the damping factor)
PageRank matrix can be computed offline
Google takes into account both the relevance of
the page and PageRank
2012-08-23
66
PageRank on MapReduce (1/2)
[Lin et al., 2010]
Map: distributing PageRank “credit” to link targets
Reduce: summing up PageRank “credit” from multiple
sources to compute new PageRank values
Iterate until
convergence
2012-08-23
67
PageRank on MapReduce (2/2)
[Lin et al., 2010]
Map (nid n, node N)
p ← N.PageRank / |N.AdjacencyList|
emit (nid n, node N) // Pass along the graph structure
for nid m ∈ N.AdjacencyList do
emit (nid m, p)
// Pass a PageRank value to its neighbors
Reduce (nid m, [p1, p2, …])
M←0
for p ∈ [p1, p2, …] do
if IsNode(p) then
M←p
// Recover the graph structure
else
s←s+p
// Sum up the incoming PageRank contributions
M.PageRank ← s
emit (nid m, node M)
2012-08-23
68
Pegasus Graph Mining System
[Kang et al., 2009]
GIM-V
Generalized Iterative Matrix-Vector Multiplication
Extension of plain matrix-vector multiplication
Including the following algorithms as special cases
•
•
•
•
2012-08-23
Connected Components
PageRank
Random Walk with Restart (RWR)
Diameter Estimation
69
Data Model
A matrix represents a graph
Each column or row represents a node
𝑚𝑖,𝑗 represents the weight of the edge from i to j
Example: column-normalized adjacency matrix
1
1
1
1/2
2
1
3
1/2
1/2
1/2
4
5
A vector represents some value of nodes, e.g.,
PageRank
2012-08-23
70
Main Idea of GIM-V (1/2)
The matrix-vector multiplication is 𝑀 × 𝑣 = 𝑣 ′
where 𝑣𝑖′ = 𝑛𝑗=1 𝑚𝑖,𝑗 𝑣𝑗
M
v’
v
X
=
There are three operations in the above formula
combine2: multiply 𝑚𝑖,𝑗 and 𝑣𝑗
combineAll: sum 𝑛 multiplication results for a node i
assign: overwrite the previous value of 𝑣𝑖 with a new
result to make 𝑣𝑖 ′
2012-08-23
71
Main Idea of GIM-V (2/2)
The operator ×𝐺 is defined as follows:
𝑣 ′ = 𝑀 ×𝐺 𝑣, where 𝑣𝑖′ = assign(𝑣𝑖 , combineAlli({𝑥𝑗 |
𝑗=1, …, 𝑛 and 𝑥𝑗 = combine2(𝑚𝑖,𝑗 , 𝑣𝑗 )}))
combine2(𝑚𝑖,𝑗 , 𝑣𝑗 ): combine 𝑚𝑖,𝑗 and 𝑣𝑗
combineAlli(𝑥1 , … , 𝑥𝑛 ): combine all the results from
combine2() for a node i
assign(𝑣𝑖 , 𝑣𝑛𝑒𝑤 ): decide how to update 𝑣𝑖 with 𝑣𝑛𝑒𝑤
×𝐺 is applied until a convergence criterion is met
Customizing the three functions implements
several graph mining operations
e.g., PageRank, Random Walk with Restart, …
2012-08-23
72
Connected Components
How many connected components?
Which node belongs to which component?
component id
1
5
7
2
3
6
8
4
A
2012-08-23
B
C
1
A
1
1
2
A
2
1
3
A
3
1
4
A
4
1
5
B
5
5
6
B
6
5
7
C
7
7
8
C
8
7
or
73
GIM-V and Connected Components
We need to design a proper matrix vector
multiplication
1
1
1
5
7
2
2
3
3
6
8
6
B
C
4
5
6
7
8
1
1
1
1
1
1
1
1
1
2
1
3
1
4
1
5
1
7
8
2012-08-23
3
5
4
A
4
2
1
1
?
5
6
5
7
7
8
7
initial
vector
final
vector
74
Naïve Method (GIM-V BASE) (1/2)
1
1
2
3
2
3
4
5
6
7
8
1
1
1
1
4
1
1
5
6
1
1
7
8
2012-08-23
1
1
1
min(1, min(2) )
1
2
min(2, min(1,3) )
1
3
min(3, min(2,4) )
2
4
min(4, min(3) )
3
5
min(5, min(6) )
5
6
min(6, min(5) )
5
7
min(7, min(8) )
7
8
min(8, min(7) )
7
75
Naïve Method (GIM-V BASE) (2/2)
1
1
2
3
2
3
4
5
6
7
8
1
1
1
1
4
1
1
5
6
1
1
7
8
2012-08-23
1
1
1
min(1, min(2) )
1
1
1
2
min(2, min(1,3) )
1
1
1
3
min(3, min(2,4) )
2
1
1
4
min(4, min(3) )
3
2
1
5
min(5, min(6) )
5
5
5
6
min(6, min(5) )
5
5
5
7
min(7, min(8) )
7
7
7
8
min(8, min(7) )
7
7
7
76
Implementation of GIM-V BASE
1
1
2
Input:
Matrix(src, dst)
Vector(id, val)
3
4
2
3
4
5
7
1
8
dst
1
1
1
2
1
3
1
4
1
5
1
6
7
src
8
1
5
6
6
1
1
7
8
Stage 1: combine2()
Map →
Join M and V using M.dst and V.id
Reduce→
Output (M.src, V.val)
Stage 2: combineAll(), assign()
Map →
Aggregate (M.src, V.val) by M.src
Reduce→
Output (M.src, min(V.val1, V.val2, …))
2012-08-23
77
GIM-V and PageRank
The matrix notation of PageRank
p = d B p + (1 - d)/n 1
p = {d B + (1 - d)/n E } p, where E is a matrix of all 1’s
M: column-normalized
v: PageRank vector
adjacency matrix damping factor
GIM-V operations for PageRank
combine2(𝑚𝑖,𝑗 , 𝑣𝑗 ) = 𝑑 × 𝑚𝑖,𝑗 × 𝑣𝑗
combineAlli(𝑥1 , … , 𝑥𝑛 ) =
(1−𝑑)
𝑛
+
𝑛
𝑗=1 𝑥𝑗
assign(𝑣𝑖 , 𝑣𝑛𝑒𝑤 ) = 𝑣𝑛𝑒𝑤
2012-08-23
78
Pregel
[Malewicz et al., 2010]
A large-scale distributed framework for graph
data developed by Google
C++ API: developed and used only internally
Phoebus: open-source implementation of Pregel
Based on the Erlang programming language
https://github.com/xslogic/phoebus
2012-08-23
79
Bulk Synchronous Parallel Model
Computations consist of a sequence of iterations,
called supersteps
Within each superstep, the vertices execute a
user-defined function in parallel
The function expresses the logic of an algorithm―the
behavior at a single vertex and a single superstep
It can read messages sent to the vertex from the
previous superstep, send messages to other vertices
to be received in the next superstep, and modify the
state of the vertex or that of its outgoing edges
Edges are not first-class citizens
2012-08-23
80
Termination
Algorithm termination is based on every vertex
voting to halt
Vertex state machine
Vote to halt
Active
Inactive
Message received
The algorithm as a whole terminates when all
vertices are simultaneously inactive
2012-08-23
81
Supersteps
Example: getting the maximum value
3
6
2
1
Superstep 0
6
6
2
6
Superstep 1
6
6
6
6
Superstep 2
6
6
6
6
Superstep 3
Edge
2012-08-23
Message
Voted to halt
82
Implementation of Pregel
Basic architecture
The executable is copied to many machines
One machine: Master ← coordinating computation
Other machines: Workers ← performing computation
Basic stages
1.
2.
3.
4.
2012-08-23
Master partitions the graph
Master assigns the input to each Worker
Supersteps begin at Workers
Master can tell Workers to save graphs
83
C++ API
Compute()
Executed at each active vertex in every superstep
Overridden by a user
GetValue() or MutableValue()
Inspect or modify the value associated with a vertex
GetOutEdgeIterator():
Get the iterator of out-going edges
SendMessageTo():
Deliver a message to given vertices
VoteToHalt()
2012-08-23
84
Applications of Pregel
PageRank implementation in Pregel
class PageRankVertex : public Vertex<double, void, double> {
public:
virtual void Compute(MessageIterator* msgs) {
if (superstep() >= 1) {
double sum = 0;
for (; !msgs->Done(); msgs->Next())
sum += msgs->Value();
*MutableValue() = 0.15 / NumVertices() + 0.85 * sum;
}
if (superstep() < 30) {
const int64 n = GetOutEdgeIterator().size();
SendMessageToAllNeighbors(GetValue() / n);
} else {
VoteToHalt();
}
}
};
2012-08-23
85
Related Research Projects
Pegasus (CMU)
Overview: [Kang et al., 2009]
Belief propagation: [Kang et al., 2011a]
Spectral clustering → top k eigensolvers: [Kang et al., 2011b]
SystemML (IBM Watson Research Center)
Overview: [Ghoting et al., 2011a]
• SystemML enables declarative machine learning on Big Data in a MapReduce
environment; Machine learning algorithms are expressed in DML, and
compiled and executed in a MapReduce environment
NIMBLE: [Ghoting et al., 2011b]
Cloud9 (University of Maryland)
Overview: [Lin et al., 2010a]
• Cloud9 is a MapReduce library for Hadoop designed to serve as both
a teaching tool and to support research in data-intensive text
processing
Graph algorithms: [Lin et al., 2010b]
2012-08-23
86
5. Conclusions
Conclusions
More and more algorithms are moving to the
MapReduce world
For social networks, most of such algorithms can
be represented using matrix manipulation, e.g.,
PageRank
We need to work on developing a parallel version
of more-complicated algorithms such as
community discovery and influence analysis
2012-08-23
88
References
[Chu et al., 2006] Cheng-Tao Chu, Sang Kyun Kim, Yi-An Lin,
YuanYuan Yu, Gary R. Bradski, Andrew Y. Ng, Kunle Olukotun:
Map-Reduce for Machine Learning on Multicore. NIPS 2006: 281288
[Kang et al., 2009] U. Kang, Charalampos E. Tsourakakis, Christos
Faloutsos: PEGASUS: A Peta-Scale Graph Mining System. ICDM
2009: 229-238
[Kang et al., 2011a] U. Kang, Duen Horng Chau, Christos Faloutsos:
Mining large graphs: Algorithms, inference, and discoveries. ICDE
2011: 243-254
[Kang et al., 2011b] U. Kang, Brendan Meeder, Christos Faloutsos:
Spectral Analysis for Billion-Scale Graphs: Discoveries and
Implementation. PAKDD (2) 2011: 13-25
[Suri et al., 2011] Siddharth Suri, Sergei Vassilvitskii: Counting
triangles and the curse of the last reducer. WWW 2011: 607-614
2012-08-23
89
References (cont’d)
[Ene et al., 2011] Alina Ene, Sungjin Im, Benjamin Moseley: Fast
clustering using MapReduce. KDD 2011: 681-689
[Morales et al., 2011] Gianmarco De Francisci Morales, Aristides
Gionis, Mauro Sozio: Social Content Matching in MapReduce.
PVLDB 4(7): 460-469 (2011)
[Das et al., 2007] Abhinandan Das, Mayur Datar, Ashutosh Garg,
ShyamSundar Rajaram: Google news personalization: scalable
online collaborative filtering. WWW 2007: 271-280
[Lin et al., 2010a] Jimmy Lin, Chris Dyer: Data-Intensive Text
Processing with MapReduce. Morgan & Claypool Publishers 2010
Cloud9 library: http://lintool.github.com/Cloud9/
[Lin et al., 2010b] Jimmy Lin, Michael Schatz: Design Patterns for
Efficient Graph Algorithms in MapReduce. MLG 2010: 78-85
[Cohen, 2009] Jonathan Cohen: Graph Twiddling in a MapReduce
World. Computing in Science and Engineering 11(4): 29-41 (2009)
2012-08-23
90
References (cont’d)
[Ghoting et al., 2011a] Amol Ghoting, Rajasekar Krishnamurthy,
Edwin P. D. Pednault, Berthold Reinwald, Vikas Sindhwani, Shirish
Tatikonda, Yuanyuan Tian, Shivakumar Vaithyanathan: SystemML:
Declarative machine learning on MapReduce. ICDE 2011: 231-242
[Ghoting et al., 2011b] Amol Ghoting, Prabhanjan Kambadur, Edwin
P. D. Pednault, Ramakrishnan Kannan: NIMBLE: a toolkit for the
implementation of parallel data mining and machine learning
algorithms on mapreduce. KDD 2011: 334-342
[Malewicz et al., 2010] Grzegorz Malewicz, Matthew H. Austern, Aart
J. C. Bik, James C. Dehnert, Ilan Horn, Naty Leiser, Grzegorz
Czajkowski: Pregel: a system for large-scale graph processing.
SIGMOD Conference 2010: 135-146
2012-08-23
91
THANK YOU