Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
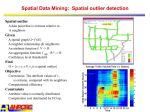
Co-location pattern mining
(for CSCI 5715)
Charandeep Parisineti,
Bhavtosh Rath
Chapter 7: Spatial Data Mining
[1]Yan Huang, Shashi Shekhar, Hui Xiong. Discovering Co-location patterns from Spatial
Datasets: A General Approach. IEEE Transactions on Knowledge and Data Engineering, 2004.
[2]Sajib Barua, Jörg Sander. Mining Statistically Significant Co-location and Segregation
Patterns. IEEE Transactions on Knowledge and Data Engineering, 26(5), 2014.
[3] Shashi Shekar, et al., Trends in Spatial Data Mining
Where do we find Co –location?
In ecology
Symbiotic species : Ox-pecker and giraffe
Public Safety
To determine possible causes of disease outbreak
(London cholera)
In cities
{‘auto dealers’, ‘auto repair shops’}
{‘departmental stores’, ’gift stores’}
Other domains: Earth science, public
safety, transportation, tourism etc.
What are association rules?
Association rules vs Co-location rules
Class Exercise:
Co-location rule mining approaches
b) Reference feature centric approach c) Data partition approach d) Event centric model
• Co-location (A,B) will not be found in (b) since it does not involve the reference feature
• Data partition approach can have many distinct ways of partitioning the data, each yielding
a distinct set of transactions and hence support.
In (c) support of (A,B) is different for different partitions
Event centric model finds the subsets of spatial features likely to occur in a neighborhood
around instances of given subsets of event types
Event Centric model
Drawbacks of event centric model
• In (a) there are only a few instances of A but B is abundant.
As many Bs are without As B’s participation ratio will be small which results the
participation index of {A,B} to be low
• In (b) A and B are abundant in a spatial area but randomly distributed
We might see enough instances of {A,B} even without true spatial dependency
• In (c) both features A and B are spatially auto-correlated. A cluster of A and a cluster of B
happen to overlap by chance.
Enough instances of {A,B} will falsely report a spatial co-location
Statistical approaches
Similar problems as above in association rule mining are handled using Interest
measures such as phi coefficient for a 2x2 contingency table
Coffee
~Coffee
Tea
15
5
~Tea
75
5
~Coffee means the transactions which
don’t contain coffee
The absence of an item doesn’t make sense in spatial data as boolean spatial
features are embedded in continuous space
Hence phi coefficient, odds ratio etc, used in traditional data mining don’t work for
Spatial data
The basic idea in Spatial statistical approach is comparing the observed PI value to a
PI value under no spatial relationship instead of a global threshold
The process is repeated over several spaces with CSR using Monte Carlo simulation
Computing co-location patterns using cross k function for all possible co-location
patterns can be computationally expensive
Q?