Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
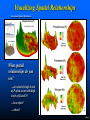
Grid-based Map Analysis Techniques and Modeling Workshop Part 1 – Maps as Data Part 2– Surface Modeling Part 3 – Spatial Data Mining Linking geographic and data space Map similarity Clustering mapped data Map regression Future geo-statistical tools Part 4 – Spatial Analysis Part 5 – GIS Modeling Grid-Based Map Analysis Surface Modeling maps the spatial distribution and pattern of point data… Map Generalization— characterizes spatial trends (e.g., titled plane) Spatial Interpolation— deriving spatial distributions (e.g., IDW, Krig) Other— roving window/facets (e.g., density surface; tessellation) Data Mining investigates the “numerical” relationships in mapped data… Descriptive— aggregate statistics (e.g., average/stdev, similarity, clustering) Predictive— relationships among maps (e.g., regression) Prescriptive— appropriate actions (e.g., optimization) Spatial Analysis investigates the “contextual” relationships in mapped data… Reclassify— reassigning map values (position; value; size, shape; contiguity) Overlay— map overlay (point-by-point; region-wide; map-wide) Distance— proximity and connectivity (movement; optimal paths; visibility) Neighbors— ”roving windows” (slope/aspect; diversity; anomaly) (Berry) Spatial Dependency Spatial Variable Dependence-- what occurs at a location in geographic space is related to: • the conditions of that variable at nearby locations, termed Spatial Autocorrelation (intra-variable dependence) • the conditions of other variables at that location, termed Spatial Correlation (inter-variable dependence; Spatial Data Mining …understanding relationships among sets of map layers) Map Stack– relationships among maps are investigated by aligning grid maps with a common configuration… #cols/rows, cell size and geo-reference. Data Shishkebab– each map represents a variable, each grid space a case and each value a measurement with all of the rights, privileges, and responsibilities of non-spatial mathematical , numerical and statistical analysis (Berry) Linking Data and Map Distributions A histogram depicts the numerical distribution A map depicts the geographical distribution …the data values link the two views— Click anywhere on the map and the histogram interval is highlighted; click on a histogram interval and the map locations are highlighted (See Map Analysis, “Topic 7” for more information) (Berry) Visualizing Spatial Relationships Interpolated Spatial Distribution Phosphorous (P) What spatial relationships do you see? …do relatively high levels of P often occur with high levels of K and N? …how often? …where? (Berry) Calculating Data Distance …an n-dimensional plot depicts the multivariate distribution; the distance between points determines the relative similarity in data patterns …the closest floating ball is the least similar (largest data distance) from the comparison point (Berry) Identifying Map Similarity …the relative data distance between the comparison point’s data pattern and those of all other map locations form a Similarity Index The green tones indicate field locations with fairly similar P, K and N levels; red tones indicate dissimilar areas (See Map Analysis, “Topic 16, Calculating Map Similarity” for more information) (Berry) Clustering Maps for Data Zones …a map stack is a spatially organized set of numbers …groups of “floating balls” in data space identify locations in the field with similar data patterns– data zones …apply different management actions for different “data zones” Variable Rate Application (Berry) Evaluating Clustering Results …graphical and statistics procedures assess how “distinct” clusters are— clustering performance …distinct in K, fairly distinct in N but not distinct in P (overlap) (Berry) The Precision Ag Process (Fertility example) As a combine moves through a field 1) it uses GPS to check its location then 2) checks the yield at that location to 3) create a continuous map of the yield variation every few feet. This map 4) is combined with soil, terrain and other maps to derive a 5) “Prescription Map” that is used to Steps 1)–3) adjust fertilization levels every few feet in the field. Prescription Map (Cyber-Farmer, Circa 1990) 45.00 On-the-Fly Yield Map 40.00 Map Analysis Step 4) Farm dB Step 5) 35.00 Zone 3 30.00 25.00 Zone 2 20.00 15.00 10.00 5.00 Variable Rate Application Zone 1 5.00 10.00 15.00 20.00 25.00 30.00 (See http://www.innovativegis.com/basis, Precision Farming Primer, Appendix D) (Berry) Simple Linear Regression (Berry) Multivariate Map Regression …considering all three map variables at the same time (Berry) Stratifying Regression based on Error Map …in a somewhat analogous manner, Regression Trees are derived by recursively analyzing the data to successively break the entire area into subgroups that form the prediction relationship (Berry) Spatial Data Mining …making sense out of a map stack Mapped data that exhibits high spatial dependency create strong prediction functions. As in traditional statistical analysis, spatial relationships can be used to predict outcomes …the difference is that spatial statistics predicts where responses will be high or low (See Map Analysis, Topic 10 for more information) (Berry)