Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
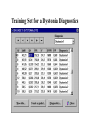
A Technique for Advanced Dynamic Integration of Multiple Classifiers Alexey Tsymbal*, Seppo Puuronen**, Vagan Terziyan* *Department of Artificial Intelligence and Information Systems, Kharkov State Technical University of Radioelectronics, UKRAINE e-mail: [email protected], [email protected] **Department of Computer Science and Information Systems, University of Jyvaskyla, FINLAND, e-mail: [email protected] STeP’98 - Finnish AI Conference, 7-9 September, 1998 Finland and Ukraine University of Jyväskylä Finland State Technical University of Radioelectronics Kharkov Ukraine Metaintelligence Laboratory: Research Topics • Knowledge and metaknowledge engineering; • Multiple experts; • Context in Artificial Intelligence; • Data Mining and Knowledge Discovery; • Temporal Reasoning; • Metamathematics; • Semantic Balance and Medical Applications; • Distance Education and Virtual Universities. Contents • • • • • • • What is Knowledge Discovery ? The Multiple Classifiers Problem A Sample (Training) Set A Sliding Exam of Classifiers as Learning Technique A locality Principle Nearest Neighbours and Distance Measure Weighting Neighbours, Predicting Errors and Selecting Classifiers • Data Preprocessing • Some Examples What is Knowledge Discovery ? • Knowledge discovery in databases (KDD) is a combination of data warehousing, decision support, and data mining and it is an innovative new approach to information management. • KDD is an emerging area that considers the process of finding previously unknown and potentially interesting patterns and relations in large databases*. • __________________________________________________________________________________________________________________________________________ • * Fayyad, U., Piatetsky-Shapiro, G., Smyth, P., Uthurusamy, R., Advances in Knowledge Discovery and Data Mining, AAAI/MIT Press, 1996. The Research Problem During the past several years, in a variety of application domains, researchers in machine learning, computational learning theory, pattern recognition and statistics have tried to combine efforts to learn how to create and combine an ensemble of classifiers. The primary goal of combining several classifiers is to obtain a more accurate prediction than can be obtained from any single classifier alone. Approaches to Integrate Multiple Classifiers Integrating Multiple Classifiers Combination Selection Decontextualization Global (Static) Local (Dynamic) Local Global (“Virtual” (Voting-Type) Classifier) Classification Problem Training set Vector classified J classes, n training observations, p object features Given: n training pairs (xi, yi) Classifiers Classification with xiRp and yi{1,…,J} denoting class membership Class membership Goal: given: new x0 select classifier for x0 predict class y0 A Sample (Training) Set X2 P1:( x11 , x21 ) C1; P2 :( x12 , x22 ) C2 ; ... Pn :( x1n , x2n ) Cn . Ci x2i x1i X1 Classifiers Used in Example • Classifier 1: LDA - Linear Discriminant Analysis; • Classifier 2: k-NN - Nearest Neighbour Classification; • Classifier 3: DANN - Discriminant Adaptive Nearest Neighbour Classification A Sliding Exam of Classifiers (Jackknife Method): We apply all the classifiers to the Training Set points and check correctness of classification X2 (0;0;0) (1;0;0) (0;0;0) (0;0;0) (0;1;0) (0;0;0) LDA - incorrect classification k-NN - incorrect classification DANN - correct classification (0;0;0) (0;0;0) (0;0;1) (0;0;0) (0;1;0) (1;1;0) X1 A Locality Principle X2 (0;0;0) (1;0;0) (0;0;0) (0;0;0) We assume that also in neighbourhood of a point we may expect the same classification result: (0;1;0) (0;0;0) (0;0;1) (0;0;0) (0;0;0) (0;1;0) (0;0;0) LDA - incorrect classification k-NN - incorrect classification DANN - correct classification X1 Selecting Amount of Nearest Neighbours • A suitable amount l of nearest neighbours for a training set point should be selected, which will be used to classify case related to this point. • We have used l = max(3, n div 50) for all training set points in the example, where n is the amount of cases in a training set. •? Should we locally select an appropriate l value ? Brief Review of Distance Functions According to D. Wilson and T. Martinez (1997) Weighting Neighbours X2 (0;0;0) (1;0;0) (0;0;0) NN2 NN3 (0;0;0) (0;0;0) (0;0;0) (0;1;0) d3 d2 d1 NN 1 (0;0;1) (0;0;0) (0;1;0) dmax Pi (0;0;0) (1;1;0) X1 The values of distance measure are used to derive the weight wk for each of selected neighbours k = 1,…,l using for example a cubic function: w k (1 ( d k / d max ) 3 ) 3 Nearest Neighbours’ Weights in the Example X2 (0;0;0) (1;0;0) (0;0;0) NN2 NN3 (0;0;0) (0;0;0) (0;0;0) (0;1;0) d3 d2 d1 NN 1 (0;0;1) (0;0;0) (0;1;0) dmax Pi (0;0;0) (1;1;0) X1 k=3; d1=2,1; d2=3,2; d3=4,3; dmax=6 w1=0,88; w2=0,61; w3=0,25 Selection of a Classifier X2 (0;0;0) (1;0;0) (0;0;0) NN2 NN3 (0;0;0) (0;0;1) (0;0;0) (0;0;0) (0;1;0) dmax (0;0;0) (0;1;0) d3 d2 Pi d1 NN 1 (0,3;0,6;0) (1;1;0) Predicted classification errors: k * qj ( wi qij ) / k , j 1, m. i 1 * (0;0;0) X1 q =(0,3; 0,6; 0). DANN should be selected Compenetnce Map of Classifiers X2 LDA LDA (0;0;0) (1;0;0) (0;0;0) DANN k-NN (0;1;0) (0;0;0) (0;0;1) (0;0;0) (0;0;0) (0;1;0) DANN (0;0;0) (0;0;0) (1;1;0) k-NN X1 Data Preprocessing: Selecting Set of Features p'i Fi - sub system s o f fea tures - c la ssific a tio n erro rs PCM AFS+ LDA AFS+ s-b y-s DA AFS+LDA b y o p tim a l sc o ring p '1 p '2 p '3 p '4 F1 Cla ssific a tio n erro rs a c c o unt 4 3 F2 F F AFS+ FDA AFS+ PDA p '5 p '6 F5 F6 6 F min Fi * p * i 1 - the b est sub system o f fea tures Conclusion: m ethodi - the b est Features Used in Dystonia Diagnostics • AF • AM0 (x1) - attack frequency; (x2) - the mode, the index of sympathetic tone; • dX (x3) - the index of parasympathetic tone; • IVR (x4) - the index of autonomous reactance; • V (x5) - the velocity of brain blood circulation; • GPVR (x6) - the general peripheral blood-vessels’ resistance; • RP (x7) - the index of brain vessels’ resistance. Training Set for a Dystonia Diagnostics Visualizing Training Set for the Dystonia Example Evaluation of Classifiers Diagnostics of the Test Vector Experiments with Heart Disease Database • Database contains 270 instances. Each instance has 13 attributes which have been extracted from a larger set of 75 attributes. The average cross-validation errors for the classification methods were the following: DANN K-NN LDA Dynamic Classifier Selection Method three 0.196, 0.352, 0.156, 0.08 Experiments with Liver Disorders Database • Database contains 345 instances. Each instance has 7 numerical attributes. The average cross-validation errors for classification methods were the following: DANN K-NN LDA Dynamic Classifier Selection Method the three 0.333, 0.365, 0.351, 0.134 Experimental Comparison of Three Integration Techniques Liver learning curves Accuracy 0.7 0.65 Voting 0.6 CVM 0.55 DCS 250 225 200 175 150 125 100 75 50 0.5 Local (Dynamic) Classifier Selection (DCS) is compared with Voting and static Cross-Validation Majority Training Set Size Heart learning curves Accuracy 0,85 0,83 Voting 0,81 CVM 0,79 0,77 100 DCS 120 140 160 Training Set Size 180 200 Conclusion and Future Work • Classifiers can be effectively selected or integrated due to the locality principle • The same principle can be used when preprocessing data • The amount of nearest neighbours and the way of distance measure it is reasonable decided in every separate case • The difference between classification results obtained in different contexts can be used to improve classification due to possible trends