Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Simulación y
Minería de datos:
Dos facetas nuevas de la
modelación computacional
Chris Stephens,
Instituto de Ciencias Nucleares, UNAM
Seminario de Modelación Matemática y Computacional 21/09/2007
¿Qué es un modelo?
“Un modelo matemático es un modelo
abstracto que usa el lenguaje matemático
para describir el comportamiento de un
sistema.” (Wikipedia)
…una representación de los aspectos
esenciales de un sistema que presenta
conocimiento del sistema en forma usable
Debe dar información:
cualitativa – entendimiento y intuición
cuantitativa - predicciones
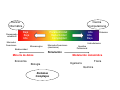
Simulación
Ciencia
Informática
Desempeño
estudiantil
Ciencia
Computacional
Baja
Baja
Alta
Mercados
financieros
Parametricidad
Deductividad
Complejidad
Microarreglos
Biodiversidad
Mercados financieros
(simulacion)
Alta
Alta
Baja
Dinámica
Hidrodinámica
Genética
Poblacional
Simulación
Modelación matemática
Minería de datos
Economía
Biología
Sistemas
Complejos
Física
Ingeniería
Química
Modelos en las
ciencias exactas
Un ejemplo: el problema de dos
cuerpos con interacción gravitacional
v
Ecuaciones de Newton
r
θ
r − rθ 2 = −G ( M + m) / r 2
μr 2θ = L
Solución exacta,
analítica:
A
r (θ ) =
(1 + e cos θ )
Información cualitativa: las orbitas son secciones cónicas, e = 0, círculo;
e < 1, elipse; e = 1, parábola; e > 1, hipérbola
Información cuantitativa: rmin= A/(1+e); rmax = A/(1-e)
Modelos en las
ciencias de la vida
Un ejemplo: dinámica de
poblaciones
• x(t+1) = r x(t)(1-x(t))
– x(t) es la población relativa de un organismo
(relativa al máximo posible entonces 0 < x < 1
– r es la taza efectiva de crecimiento; (0 < r < 4)
– el término x(t) da retroalimentación positiva
(taza de nacimiento) y (1-x(t)) de
retroalimentación negativa (taza de muerte,
debido por ejemplo a recursos finitos)
Un ejemplo: dinámica de
poblaciones
bifurcación
chaos
Y este modelo – ¿de las ciencias
exactas o de la vida?
Competencia entre
una repulsión y
atracción efectiva
entre “partículas”
ci(t), vi(t) – position/direction
vectors of a “particle”
Ecuación para partículas “cargadas”
siguiendo una fuerza externa gi
Couzin, I.D., Krause, J., Franks, N.R. & Levin, S.A.
(2005) Nature, 433, 513-516.
¿Qué son las diferencias y
semejanzas entre estos modelos?
• ¿Cómo tan fieles son?
• ¿Qué grado de idealización hay?
• ¿Dan una descripción tanto cuantitativa como
cualitativa?
• ¿Qué grado de aproximación hay?
• ¿Qué fenómenos capturan y cuales no de los
sistemas que describen?
• ¿Cuántos parámetros hay en los modelos?
Son modelos paramétricos simples que en
ciertos casos (física) capturan “toda” la dinámica
y en otros casos (biología) modelan
cualitativamente un único aspecto del sistema
Mercados
financieros
AFM Model – The Market Mechanism
• One risky asset (no dividends), one
riskless asset (no interest - “cash”)
• No short sales, no borrowing, uniform
trade size (traders buy/sell/hold)
• Double Auction
– At time t list traders’ bids and offers (obtained from a Gaussian
distribution centered on p(t-1)); every auction is a “tick”
– Match best bid with best offer at the midpoint price iff pb(t) ≥ po(t)
– Excess demand/supply is determined only from bids and offers that are
unmatched and overlap, i.e. pb(t) ≥ p(t) p(t) ≥ po(t)
AFM Model – The Traders
• N traders
• One-parameter family of trading strategies
–
–
–
–
–
P(b) = 2d/3; P(h) = 1/3; P(o) = 2(1 - d)/3
d € [0,1]
Denote strategy by (100d,100(1-d))
d = ½ Æ (50,50) “noise” trader
Traders choose a strategy from this family
Traders may dynamically adapt their strategy
• Portfolio for trader i at time t - {ni(t), Ci(t)}
– Wealth Wi(t) = (Ci(t) + ni(t)pi(t)); Ci(t) – riskless asset
• Learning included by “copycat”
mechanism; copycat traders reproduce the
best observed strategy in the market
AFM Model – Price Dynamics
p(t+1) = p(t)(1 + η(D(t) – S(t)))
D(t) = Demand
S(t) = Supply
η = tuning parameter
Market state - {{(Ci(t),ni(t)),(pi(t),Xi(t))},p(t)}
Portfolio
parameters
Position Parameters
Buy/sell/hold price
Xi(t) = X(di(t)) = {-1,0,1} - stochastic variable that depends
only on the strategy parameter di;
In principle: di(t) = F(risk preferences, utility, information
set, price …)
Efficient Markets
100 (90,10)
traders
Graphs of # of traders with a given
excess profit after 3001 ticks
100 (50,50)
traders
Divide traders into two groups, A and B, to see if there exists a relative
inefficiency between them; A and B traders may have unknown beliefs
I(50,50,A)(50,50,B) (t,0)
No statistically significant excess trading
Homogeneous
markets are efficient
gains
(no relative informational advantage for
any given trader group)
Inefficient Markets
50 (90,10) traders and 50 (50,50) traders
Apparent multi-modality – indication of
excess profits? Signal or noise?
Graphs of # of traders with a given
excess profit after 101 and 3001 ticks
Distributions separate
at a speed that depends
on (d(90,10)- d(50,50))
Multi-modality – is evidence that
informed traders are making profits
at the expense of noise traders
Relative informational
advantages lead to
Inefficient markets
¿Cómo difiere esta simulación de
las otras?
• Hay muchos parámetros en este modelo
(pero pocos comparado con el sistema
real)
• Cada objeto no simplemente cambia su
estado pero también ¡puede cambiar la
dinámica que cambia ese estado!
• Cambia de estrategia - “adaptación”
(aprendizaje)
• Muestra un fenómeno emergente – la
eficiencia del mercado
Simulación de la
“Evolucíon”
Evolución
Minería de datos
Minería de datos
• Data mining is the exploration and analysis
of data in order to discover patterns,
correlations and other regularities
– All the previous models we have seen can be
thought of in terms of data mining
Here’s the data… data mining in
one-dimension!
Here, there is no
“law” or fundamental
theory. We have to try
and statistically infer
relationships.
Do you think that the ROI
only depends on
spending?
What would you do?
Let’s make it a bit more
interesting!
Datamining in two dimensions!
• Want to predict the probability to be in a
class C given two “features” 1 and 2.
– E.g. What’s the probability for a client to
spend $ C on a new product as a function of $
spent on two other products 1 and 2?
From past data we find this…
Probability
of health risk
Age level
Income level
(5 is oldest)
(1 is highest)
What model would you use to predict here?
Multi-variate linear regression?
But what if we’d found this…?
What model would you use to predict now?
All we have to do is
understand this “topography”
Sound easy?
Very intuitive
So what’s the catch…?
For good statistical inference we need the height
function for all the feature vectors of the search space
Problem 1: The World is Noisy!
High variance
Low variance
Are we sure
this is a high
point in the
Predictability
Landscape?
Solution:
Obtain more
data?
Problem 2: The Curse of
Dimensionality
• Number of seconds in your lifetime: 2.5 x 109
• Number of atoms in this room: 1025
• Number of atoms in universe: 1080
• Number of possible responses to a 50 question survey
with 1-10 scale answers: 1050
So if everybody on the planet filled in a survey we’d still only be exploring less
than one part in 1040 of the search space
• Number of possible socio-demographic profiles obtained from
100 census-style socio-demographic variables divided into
deciles: 10100
Fastest computer in the world: IBM's BlueGene/L - 360 teraflops (1012 floating
point ops per sec)
The possible data points
The Predictability peaks?
Your data!
How do we infer the height of those
points for which we have no information?
“Coarse graining”
• “Binning”/Grouping data
– E.g. 100 survey respondants, expect ~ 3
respondants for every age in years
bin the data: too few bins risks losing
predictability and discrimination, too many
risks statistically unreliable predictions
• “Ignoring” data
– Removing variables – but which ones?
“Coarse graining”
• Averaging or marginalizing data
– Introduce a new “symbol” “*”
• P(C | X) = P(C | x1 x2 )
– E.g. C = high spending on autos, x1 = age, x2 = income
• P(C | x1 * ) = Σx2 P(C | x1 x2 )
– Probability to have high spending on autos given age x1
irrespective of income
• P(C | * x2 ) = Σx1 P(C | x1 x2 )
– Probability to have high spending on autos given income
x2 irrespective of age
• P(C) = P(C | * * ) = Σx1,x2 P(C | x1 x2 )
– Probability to have high spending on autos irrespective
of age or income
Determining important drivers
A useful statistical diagnostic:
N
C
“Signal”
P( C | X ) = N
N
/
C,X
X
P( C ) = N
N
C
N
C,X
X
N
X
“Noise”
N
/
C
e.g. X is age group 65-70, C is the top 5% of spending on denture cleaners
ε > 2 implies that being in the age group 65-70 is positively correlated in a
statistically significant way with being in the top 5% of spenders
And the “topographic”
interpretation?
High values of ε for feature 1 and feature 2 together associated with
good statistical confidence that these points are significantly above
the random chance plane
So what do data mining
models do?
• They make “guesses” - statistical inferences about the topography of the Predictability
Landscape
• They are “templates” that we try to fit to the form
of the landscape
• There are “zillions” of templates to try!
• We can fit to what we think is a high point
on the landscape only to find with more sampling
that it wasn’t really high (overfitting/variance)
• We can fit with a “biased” (parametric) model
and miss structure
No “Magic Bullet”
• Out of the zillions of models NONE is “perfect”
• Why? Because “perfect” is multi-dimensional:
predictability, discrimination, transparency,
interpretability, robustness, portability, runtime,
cost, simplicity …
• Each model can give a different perspective of
the Predictability Landscape and of the problem
at hand
– E.g. Neural networks can score high on predictability
but low on transparency, simplicity and runtime
– Association rules can score high on interpretability but
often low on predictability
Conclusiones
• Se ha estado haciendo simulación y minería de datos
desde empezó la ciencia
• La computadora ha permitido la creación de
simulaciones mucho mas ricas (mas parámetros) de
sistemas mas complicados
• Se ha podido hacer simulaciones que difieren
intrínsicamente de sus contrapartes tradicionales (una
dinámica en el espacio de “leyes” tanto como de
estados) que aplican a biología, finanzas etc.
(Adaptación y aprendizaje)
• En la Minería de datos se trata de modelos donde en
principio hay muchas variables involucrados donde no
sabemos a priori las correlaciones entre las variables y
no hay leyes fundamentales para guiarnos
• Los modelos no parametrizados características de esa
área no tienen mucho cesgo pero tienen que estar
construidos empiricamente “a mano”
Un ejemplo: el problema de tres
cuerpos con interacción gravitacional
¡Si pasamos a tres cuerpos ya no hay
solución analítica!
Un ejemplo: el problema de tres
cuerpos con interacción gravitacional
¿Y predictabilidad…?
Dinámica Genética
What’s Genetic Dynamics?
Population of “objects” – “genotypes”
P(t)
Evolution
operator
P(t+1)
determines the state of the
population at time t; Ω is the
dimension of the space of
states of an “object”; for linear
chromosomes with binary
alleles Ω = 2N
Space of populations
General evolution equation
p represents a set of parameters associated with
the evolution operator
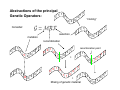
Abstractions of the principal
1
Genetic Operators:
1
1
0
0
0 0 0
Consider:
mutation
1
“cloning”
1 1
1
selection
1
0
0 0 0
1
1
0
recombination
0
0 1
0
1 0
0
0 1
0
0
0 0 0
0
0
1
1
0
1
1
0 1
0
1 0 0
0
0 1
0
1
+
0
1 1 0
recombination point
1
1 1
1
0
+
1
0
0 1 0
0
1
1
1
1
1 1
Mixing of genetic material
0
0 0 0
0
1
1
In mathematics…
Finite population model determined by Markov chain. In the infinite population limit
for haploids:
That’s most of standard population genetics and evolutionary computation!
Implicit summation over repeated indices
Probability to mutate genotype J to genotype I
Probability to implement recombination
Probability that given recombination takes place it is implemented
with mode m
Probability to select genotype I
Conditional probability for “child” J given “parents” K and L and a mode m
Don’t recombine
it with another
Select an object J
Select two “parents”
K and L
Mutate it to object I
Recombine them with
respect to a recombination
mode m applied with probability
pcpc(m) to obtain a “child” J
• Ω coupled non-linear difference equations
• Population genetics has spent the last 70 years
trying to deal with them
• Go to reduced number of loci
• In object basis there are Ω3 different λJKL - that’s a lot!
• Most of them are 0!
Two Questions…
1. Can we “solve” them?
Put them on the computer. Not very feasible for N = 100!
2. Can we understand anything “qualitatively”
from them?
How does genetic dynamics “work”?
What are the effective degrees of freedom/collective modes?
Simula el sistema