Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
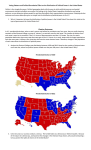
Introduction and Background FOS/FCM 705 Mathematical Statistics for Forensic Analysis Applied Bayesian Statistics Spring 2017 Bayes Theorem Example • A taxicab was involved in a hit and run accident at night. Two cab companies, the Green and the Blue, operate in the city. The following facts are known: o 85% of the cabs in the city are Green and 15% are blue o A witness identified the cab as blue. The court tested the reliability of the witness under the same circumstances that existed on the night of the accident and concluded that the witness correctly identified each one of the two colors 80% of the time and failed 20% of the time. • • What is the probability that the cab involved in the accident was actually blue? What does probability mean in this context? All Models are Wrong, Some Models are Useful Now it would be very remarkable if any system existing in the real world could be exactly represented by any simple model. However, cunningly chosen parsimonious models often do provide remarkably useful approximations. For example, the law PV = RT relating pressure P, volume V and temperature T of an "ideal" gas via a constant R is not exactly true for any real gas, but it frequently provides a useful approximation and furthermore its structure is informative since it springs from a physical view of the behavior of gas molecules. For such a model there is no need to ask the question "Is the model true?". If "truth" is to be the "whole truth" the answer must be "No". The only question of interest is "Is the model illuminating and useful?". Box, G. E. P. (1979), "Robustness in the strategy of scientific model building", in Launer, R. L.; Wilkinson, G. N., Robustness in Statistics, Academic Press, pp. 201–236. Bayes Theorem Example Comment • Notice that in the previous example we assumed we knew the various percentages and the question was essentially “If we know these percentages then what is the probability that the cab was blue?” • This is a characteristic of a probability problem – We assume that we know what the ‘model’ is and then use probability theory to calculate the probability of the event we are interested in. Bayes Theorem Example More Comments • Suppose there were 1000 cabs in the city. Then 850 are green and 150 are blue. o o If the actual cab was blue then the witness would say ‘blue’ for 80% of the 150 blue cabs or for 120 cabs, and the witness would say ‘blue’ for 20% of the 850 green cabs or 170 cabs. (20% wrong). At trial the witness says ‘blue.’ What is the probability the cab was blue? If we repeated the identical situation many times, what percentage of the time when the witness said blue would the cab be blue? (frequentist probability) • Suppose our original assumptions about the population or the witness were incorrect. What about our conclusion? • Garbage In, Garbage Out • Suppose the judge ‘thought’ apriori that witnesses can identify the correct color somewhere between 60 and 80 per cent of the time. Now what percentage of the time when the witness said blue would the cab be blue? Virginia Murders Run this code and the graphical output is: Is there a trend? Virginia Murders -2 • Notice that to analyze the Virginia Data we first entered the data into the computer. Next we plotted the data so that we had a graphical summary. Lastly we “fit” a best straight line through the data. So far this is descriptive statistics. As soon as we use this straight line to predict future values we enter the realm of inferential statistics. Atlantic Hurricanes • The following is a list of the numbers of Atlantic hurricanes for each year from 1960-2010, 51 years in all. • How can we describe this data? You’ll notice that just looking at the numbers doesn’t tell us too much because there are too many numbers. • We can describe the numbers graphically or with numeric summaries. Atlantic Hurricanes The chart to the right is called a histogram or sometimes a bar plot. It gives the frequencies and the number of times each occurred. This is a graphical summary. It summarizes the following which is a tabular summary. Note the number of hurricanes on the 1st row and the frequencies on the second. • • The following is a numerical summary of the hurricane data. The six numbers you see are called the minimum, maximum, median, mean, 1st quartile, and 3rd quartile. • Notice that in the hurricane example (as far as we have followed it.) we had some data and we summarized it. This is the province of descriptive statistics. Matching Hats • You go to a party with 4 others and you all check your hats. The hat check person unfortunately is a little tipsy. Thus she randomly chooses hats and gives the hats back to the party members as they leave. o What is the probability that 1 person gets the correct hat? o What is the probability that 2 people get the correct hat? o What is the probability that nobody gets the correct hat? • What does probability mean in this case? Matching Hats Continued • Suppose we do not know how to solve the matching hat problem using probability. We might ‘simulate’ the experience multiple times. Each time we look at the number of matches. • After many trials a good guess for the probability of 1 match is the proportion of times we get 1 match. Also a good guess for the probability of 2,3,…, k matches is the proportion of times we get that many matches in our simulation. • In this case we are estimating the probabilities from the simulated sample. We used statistics. Matching Hat simulation • Using the R code on the 2nd following page I ran the matching hat simulation 50000 times and created the following bar chart: Matching Hat Simulation Note that we obtained 1 match about 37% of the time. • In many repeatable situations we do not know if an outcome we are looking for is going to occur on the next trial but in a long sequence of trials the relative frequency of occurrence of this outcome approaches some fixed value. We call this fixed value the probability of the outcome. • In our situation the probability of 1 match is about 37%. This may be used as an estimate of the true probability. • R Code for Hat Check Problem Probability, Statistics and the Hat Check Problem • Notice that in the original statement of the problem we stated the entire problem including that the hat check person ‘randomly’ selected the hats. Thus our model was completely determined and the solution (which we didn’t give) could be determined. This solution should be the long run relative frequency of occurrence of getting 1 match if we did the experiment. (Probability problem) • The simulation solutions gives us an estimate of the true probability based just on the sample. (Statistics) Probability, Statistics and the Hat Check Problem In this particular problem, the theoretical probabilities could be calculated. (Not easy but they follow: Note the results are pretty close to the simulation. Often, the simulation can be completed with pretty good accuracy much more easily than developing the related theoretical math. Sometime the math problem is so difficult that the simulation is the only reasonable way to approximate a solution. More Probability Problems • Two fair dice are tossed. What is the probability that the sum of the numbers on the two up faces equals 6? • Assuming that you take a true-false test and you know nothing so you guess each answer. If the test has 7 questions then what is the probability that you get above 50% correct? How about if you think you have between a 50% and 70% chance of getting any question correct? What if you take the test and get 5 correct. Now if you take the test again then what is the probability that you get above 50% correct? • It is known that the number of hurricanes to hit the Atlantic per year is a Poisson random variable with parameter λ= 6.176 and that years are independent from one another. What is the probability that 5 hurricanes hit the Atlantic next year. (Note our assumptions here. Are they reasonable?) More on Hurricane Problem Statistics • For the hurricane problem on the previous page an interesting question is how we ‘knew’ that the number of Atlantic hurricanes in a season is a Poisson random variable with parameter λ= 6.176 and years independent of one another. o The answer is that we looked at data pertaining to Atlantic hurricanes and used that sample data to infer what the true hurricane number distribution is. This is an example of inferential statistics, where we infer something about a population from a sample. o In probability problems we assume we know the characteristics of the population and consider how samples will behave. o In inferential statistics problems we use the sample to infer some characteristics of the population. More on Hurricane Problem Statistics • For the hurricane data we collected data on the number of Atlantic hurricanes for the 51 years between 1960 and 2010. The mean number of hurricanes was 6.176 (Add up frequencies and divide the result by 51. We then plotted a histogram and then the density function (We’ll learn about this later) of a Poisson distribution on the same plot. Does the Poisson closely fit the histogram? If yes then we may use the Poisson distribution to predict numbers of hurricanes in the future. This would be inferential statistics. Why Try Poisson? • Poisson probability mass function is: For k = 0,1,2,3,4,…. where λ is some positive parameter representing the mean of X and k is the number of ‘successes’ in this case hurricanes. For λ=6.176 this plots as: Does the plot look something like the hurricane histogram? In addition, the Poisson distribution often appears when we are counting random events which occur over time. Statistics Definition • The discipline of statistics provides methods for organizing and summarizing data and for drawing conclusions based on information contained in the data. • This includes methods for o Designing experiments to collect data o Extracting information from data through organization, summary and display. o Making decisions and predictions in the presence of uncertainty and variation. Populations, Data, Samples • Engineers and scientists are constantly exposed to collections of facts, or data • Usually the data comes from a well-defined collection of objects we are interested in, called the population. • Examples of possible populations: o All students at John Jay College o The quality of all light bulbs being made by General Electric • Usually we are interested in some characteristic of the population. If we measure that characteristic for all members of the population then we have taken a census. Usually a census is impractical or unfeasible. Then we just measure the characteristic of interest for a well-chosen sample from the population. A sample is a subset of the population. Variables • A variable is any characteristic whose value may change from one object to another in the population. We shall initially denote variables by lowercase letters from the end of our alphabet. Examples include • x = brand of calculator owned by a student • y = number of visits to a particular Web site during a specified period • z = braking distance of an automobile under specified conditions Variables and Samples • Usually data for our census or sample results from making observations either on a single variable or simultaneously on two or more variables. • A univariate data set consists of observations on a single variable. • For example, we might determine the type of transmission, automatic (A) or manual (M), on each of ten automobiles recently purchased at a certain dealership, resulting in the categorical data set • M A A A M A A M A A Variables and Samples II • The following sample of lifetimes (hours) of brand D batteries put to a certain use is a numerical univariate data set: • 5.6 5.1 6.2 6.0 5.8 6.5 5.8 5.5 • We have bivariate data when observations are made on each of two variables. • An example of bivariate data would be measuring the height and weight of each subject so an observation might be a pair like (68, 132) • When each observation involves two or more variables then we talk about multivariate data. Branches of Statistics • An investigator who has collected data may wish simply to summarize and describe important features of the data. This entails using methods from descriptive statistics. • So creating any summary of data from a sample is part of descriptive statistics. This may involve o Graphical Techniques such as creating histograms , boxplots, dotplots, scatter plots, pie charts, etc. o Calculation of numerical summary measures, such as means, standard deviations, and correlation coefficients. • Much of the display results and calculation needed with descriptive statistics are done with dedicated computer statistics packages. We will use R. Branches of Statistics II • Having obtained a sample from a population, an investigator would frequently like to use sample information to draw some type of conclusion (make an inference of some sort) about the population. • That is, the sample is a means to an end rather than an end in itself. Techniques for generalizing from a sample to a population are gathered within the branch of our discipline called inferential statistics. • Mathematical probability theory is needed to develop inferential statistics and study the field. • We start with a short introduction to sampling and descriptive statistics. Sampling • The population we are interested in may be a finite, identifiable, unchanging collection of individuals or objects. Then we are considering an enumerative study. o An example would be if we are interested in the average GPA of all students attending John Jay College in the Spring 2017 semester. o In an enumerative study a sampling frame is a listing of all items in the population that might be part of the sample. Hopefully, but not always, the sampling frame coincides with the population. • For example, the frame might consist of all signatures on a petition to qualify a certain initiative for the ballot in an upcoming election; a sample is usually selected to ascertain whether the number of valid signatures exceeds a specified value. • An analytic study is just defined as one which is not enumerative. o For example, we might be interested in the average weight of a McDonald’s Quarter Pounder Hamburger. This is not a fixed list. More quarter pounders are cooked every day. Collecting Data • If data is not properly collected, an investigator may not be able to answer the questions under consideration with a reasonable degree of confidence. Garbage in, Garbage out!!! • A common problem is that the target population— the one about which conclusions are to be drawn—may be different from the population actually sampled(sampling frame). See the following slide for a famous case. Landon in a Landslide: The Poll That Changed Polling The 1936 presidential election proved a decisive battle, not only in shaping the nation’s political future but for the future of opinion polling. The Literary Digest, the venerable magazine founded in 1890, had correctly predicted the outcomes of the 1916, 1920, 1924, 1928, and 1932 elections by conducting polls. These polls were a lucrative venture for the magazine: readers liked them; newspapers played them up; and each “ballot” included a subscription blank. The 1936 postal card poll claimed to have asked one fourth of the nation’s voters which candidate they intended to vote for. In Literary Digest's October 31 issue, based on more than 2,000,000 returned post cards, it issued its prediction: Republican presidential candidate Alfred Landon would win 57 percent of the popular vote and 370 electoral votes. Has anyone heard about President Landon? Why was Literary Digest’s poll off by so much? 1936 Presidential Election Look up: 1936 Presidential Election in Wikipedia for the information on the left and a fuller discussion of the election. It looks like Landon did not get 57% of the vote. 1936 Presidential Election • Literary Digest’s sampling frame for their survey was not representative of the voters in 1936. Although it had polled 10 million individuals (only about 2.4 million of these individuals responded, an astronomical sum for any survey), it had surveyed firstly its own readers, a group with disposable incomes well above the national average of the time . The Digest used two other lists, registered automobile owners and telephone subscribers. Pretty much all of these lists contained people who had jobs. In 1936 were were in the depths of the Great Depression. Many (most) voters did not have jobs. Hence the poll erred. (Literary Digest in Wikipedia) 2016 Presidential Election • Almost all polls for the 2016 presidential election in the United States predicted that Hillary Clinton would defeat Donald Trump. In each state several polls were taken at various times by various methods. The polling ‘experts’ weighted these polls in various complicated manners in coming up with the final prediction. • The following are the results of simulating the results of the election in numbers of electoral college votes won by Hillary Clinton. The simulation was done the night before the election using probabilities appearing on the web site fivethirtyeight.com 2016 Presidential Election • In the following simelcttot is the vector of simulated electoral college votes for Hillary Clinton. The simulation was done 10000 times. The descriptive statistics are fairly self-explanatory. The next morning fivethirtyeight.com changed its prediction somewhat to give Hillary Clinton about a 69% chance of winning. 2016 Presidential Election The methods used by most of the ’experts’ used previous information to figure out how to weight the results. Simply said, the probabilities used in the predictions involved calculations of probabilities conditional on previous information about the pollsters, the district, the country and their relationships. The fivethirtyeight.com prediction was actually one of the better predictions. In fact, the following link is a discussion by Nate Silver of fivethirtyeight.com of why his predictions were so ‘good.’ http://fivethirtyeight.com/features/why-fivethirtyeight-gave-trump-abetter-chance-than-almost-anyone-else/ Sampling Methods – Simple Random Sample • When data collection entails selecting individuals or objects from a frame, the simplest method for ensuring a representative selection is to take a simple random sample. This is one for which any particular subset of the specified size (e.g., a sample of size 100) has the same chance of being selected as any other. Easy to say, not always so easy to do. • A simple random sample is considered the gold standard when we want to obtain information about a population from a sample. 1969 Draft Lottery • December 1, 1969 marked the date of the first draft lottery held since 1942. This drawing determined the order of induction for men born between January 1, 1944 and December 31, 1950. A large glass container held 366 blue plastic balls containing every possible birth date and affecting men between 18 and 26 years old. • WASHINGTON, Jan. 3 The new draft lottery is being challenged by statisticians and politicians on the ground that the selection process did not produce a truly random result. Results http://en.wikipedia.org/w iki/Draft_lottery_(1969) 1969 Draft Lottery • The method used seems to be random. What happened. This was on TV. (Nobody trusted the government at that time.) Balls were segregated by month. Each month’s balls were dropped into the container in sequence with thorough mixing between. So at the end all balls were (supposedly) mixed. Then the balls were picked 1 by 1 usually by famous people. First number picked corresponded to a birthday.(e.g. 32 was February 1.) All men with that birthday were drafted before anyone else. And so on. • What happened? End of year tended to be picked early. (I was happy. My birthday is in March.) • The selection wasn’t random. It’s difficult to select a random sample. Simple Random Sample by Computer • Computers are currently one of the most reliable mechanisms for creating a simple random sample. • Look at the following session from the R statistical package. • Starting from a list of the integers from 1 – 20 the sample function produced a pseudo-random list of size 5 – 8 5 13 20 18 • Results from computerized procedures tend to be superior to humanly generated results. • If the army had computers and used the code on the following page then the draft lottery results might have been more fair. Code for Draft Lottery New York Lottery Take 5 Sampling Methods – Stratified Sample • Stratified sampling, entails separating the population units into non-overlapping groups and taking a simple random sample sample from each one. • For example, A store wants information on incomes of customers buying TV’s. They break these buyers into Sony, Samsung, and Other and then take a random sample from each group. Later this data is combined in some way. Sampling Methods • A convenience sample is obtained by selecting individuals or objects without systematic randomization. o For example suppose I wish to determine the mean weight of students at John Jay College. I conveniently choose as my sample the students in Mat 301 and weigh each one. Are my results representative of the weights all John Jay students. o This is not considered a reliable sampling method • With a self-selected sample the respondents individually decide whether to take part. o For example a radio show host wants to determine who is the best singer so asks his listeners to text in a name. Only interested listeners answer. o A school runs a satisfaction survey and asks students their ratings for various services. The survey is sent to all students but only 5% of students reply. One result is that 82% of respondents reported they were happy with school e-mail service. The administration used this number in its planning for the next year. Reliable? What’s Next? Descriptive Statistics