Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
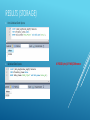
SERIALIZED DATA STORAGE Within a Database James Devens (devensj) THE IDEA Serialized data can be used to store the current state of objects in a database. Good alternative to deprecated object based databases. Storing separate data values into a single byte array. TOOLS USED MySQL Workbench DigitalOcean Server Hosting PuTTY WinSCP Microsoft Excel & PowerPoint Vim (Java Source) Protocol Buffers (Google) JDBC (Java Database Connectivity) United States 2000 Census PREDICTIONS Data will usually take less storage as byte arrays. Data will take less time to do basic queries (non-indexed database). Serialized data will be harder to access in a relational database. It can defeat the purpose of relational databases DATABASE STRUCTURE Census Table Census_ pb Table INSERTING DATA Data inserted into both tables using JDBC Prepared Statements Prevents SQL injections Allows similar queries to execute FASTER Serialized data through the use of Protocol Buffers Developed by Google More secure and portable than Java serialization INSERTING DATA (NON-SERIALIZED) INSERTING DATA (SERIALIZED) QUERYING DATA Use an array of names Each of these names will be queried This process repeats however many times specified (default 1000) Number of Queries = NumLoops * Names.length * 2 QUERYING DATA DATA COLLECTION Modified the simple query class to record data Exported to .csv for Microsoft Excel Each data sample consisted of 5 names being queried 10000 times 5000 data samples were taken Number of Queries = 50000 * 5000 * 2 = 500,000,000 queries DATA COLLECTION RESULTS (INSERTS) Results: Non-Serialized INSERT Dump Success! Took: 204651 ms to complete. Serialized INSERT Dump Success! Took: 190233 ms to complete. RESULTS (DATA COLLECTION) Results: Took 27623887 ms to complete (7.67 hours). 5000 loops, and 500000000 queries executed. RESULTS (DATA COLLECTION) Every 50,000 Queries RESULTS (STORAGE) Non-Serialized Data Space Serialized Data Space 4194303 Byte (4.19 MB) Difference CONCLUSION Data storage is reduced quite a bit, making it efficient to store serialized data The query speeds were roughly the same Serialization is good way to store object states Serialization is NOT a good way to store frequently changing objects If an object class is modified it would ruin all of your current data It is NOT relational friendly (for the most part) You cannot access the original data values inside the byte array without another program’s help FUTURE WORK Write a program to return the byte array back to the original object (easy) Use a different .proto file with tons of data values (e.g. 2000 doubles) Find more test statistics and collect more data Index the data to see how it affects query speeds of both methods