Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
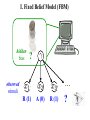
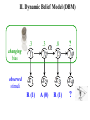
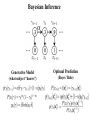
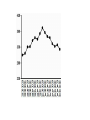
Seeing Patterns in Randomness: Irrational Superstition or Adaptive Behavior? Angela J. Yu University of California, San Diego March 9, 2010 “Irrational” Probabilistic Reasoning in Humans • “hot hand” (Gillovich, Vallon, & Tversky, 1985) (Wilke & Barrett, 2009) • 2AFC: sequential effects (rep/alt) (Soetens, Boer, & Hueting, 1985) Random stimulus sequence: 1 2 2 2 2 2 1 11 22 11 22 1 … “Superstitious” Predictions Subjects are “superstitious” when viewing randomized stimuli Trials repetitions alternations O o o o o o O O o O o O O… fast fast slow slow • Subjects slower & more error-prone when local pattern is violated • Patterns are by chance, not predictive of next stimulus • Such “superstitious” behavior is apparently sub-optimal “Graded” Superstition (Cho et al, 2002) (Soetens et al, 1985) RT [o o O O O] RARR = or [O O o o o] Hypothesis: Sequential adjustments may be adaptive for changing environments. ER t-3 t-2 t-1 t Outline • “Ideal predictor” in a fixed vs. changing world • Exponential forgetting normative and descriptive • Optimal Bayes or exponential filter? • Neural implementation of prediction/learning I. Fixed Belief Model (FBM) hidden bias ? … observed stimuli R (1) A (0) R (1) ? II. Dynamic Belief Model (DBM) .3 .3 .8 ? R (1) A (0) R (1) ? changing bias observed stimuli FBM Subject’s Response to Random Inputs What the FBM subject should believe about the bias of the coin, given a sequence of observations: R R A R R R QuickTime™ and a decompressor are needed to see this picture. A bias R FBM Subject’s Response to Random Inputs What the FBM subject should believe about the bias of the coin, given a long sequence of observations: R R A R A A R A A R A… QuickTime™ and a decompressor are needed to see this picture. A bias R DBM Subject’s Response to Random Inputs What the DBM subject should believe about the bias of the coin, given a long sequence of observations: R R A R A A R A A R A… QuickTime™ and a decompressor are needed to see this picture. A bias R Randomized Stimuli: FBM > DBM Given a sequence of truly random data ( = .5) … DBM: belief distrib. over Probability Probability FBM: belief distrib. over Simulated trials Simulated trials Driven by long-term average Driven by transient patterns “Natural Environment”: DBM > FBM In a changing world, where undergoes un-signaled changes … DBM: posterior over Probability Probability FBM: posterior over Simulated trials Simulated trials Adapt poorly to changes Adapt rapidly to changes Persistence of Sequential Effects Human Data FBM RT P(stimulus) (data from Cho et al, 2002) P(stimulus) DBM • Sequential effects persist in data • DBM produces R/A asymmetry • Subjects=DBM (changing world) Outline • “Ideal predictor” in a fixed vs. changing world • Exponential forgetting normative and descriptive • Optimal Bayes or exponential filter? • Neural implementation of prediction/learning Bayesian Computations in Neurons? Generative Model Optimal Prediction What subjects need to know What subjects need to compute Too hard to represent, too hard to compute! Simpler Alternative for Neural Computation? Inspiration: exponential forgetting in tracking true changes (Sugrue, Corrado, & Newsome, 2004) Exponential Forgetting in Behavior Linear regression: R/A R/A Human Data Coefficients (re-analysis of Cho et al) Trials into the Past Exponential discounting is a good descriptive model Exponential Forgetting Approximates DBM Linear regression: R/A R/A Coefficients DBM Prediction Trials into the Past Exponential discounting is a good normative model Discount Rate vs. Assumed Rate of Change … DBM = .77 Probability = .95 Simulated trials Simulated trials Reverse-engineering Subjects’ Assumptions DBM Simulation = .57 Trials into the Past = p(t=t-1) Coefficients Coefficients Human Data = .57 Trials into the Past 2/3 = .77 = .57 changes once every four trials Analytical Approximation nonlinear Bayesian computations 3-param model 1-param linear model vs. Quality of approximation .57 .77 Outline • “Ideal predictor” in a fixed vs. changing world • Exponential forgetting normative and descriptive • Optimal Bayes or exponential filter? • Neural implementation of prediction/learning Subjects’ RT vs. Model Stimulus Probability Repetition Trials RARR RR … Subjects’ RT vs. Model Stimulus Probability Repetition Trials RARR RR … RT Subjects’ RT vs. Model Stimulus Probability Repetition Trials RARR RR … RT Alternation Trials Subjects’ RT vs. Model Stimulus Probability Repetition vs. Alternation Trials Multiple-Timescale Interactions Optimal discrimination DBM 2 (Wald, 1947) • discrete time, SPRT • continuous-time, DDM (Gold & Shadlen, Neuron 2002) 1 (Yu, NIPS 2007) (Frazier & Yu, NIPS 2008) SPRT/DDM & Linear Effect of Prior on RT <RT> RT hist Timesteps Bias: P(s1) 0 tanh x Bias: P(s1) x SPRT/DDM & Linear Effect of Prior on RT <RT> Predicted RT vs. Stim Probability Bias: P(s1) Empirical RT vs. Stim Probability Outline • “Ideal predictor” in a fixed vs. changing world • Exponential forgetting normative and descriptive • Optimal Bayes or exponential filter? • Neural implementation of prediction/learning Neural Implementation of Prediction Leaky-integrating neuron: • Perceptual decision-making (Grice, 1972; Smith, 1995; Cook & Maunsell, 2002; Busmeyer & Townsend, 1993; McClelland, 1993; Bogacz et al, 2006; Yu, 2007; …) • Trial-to-trial interactions (Kim & Myung, 1995; Dayan & Yu, 2003; Simen, Cohen & Holmes, 2006; Mozer, Kinoshita, & Shettel, 2007; …) = 1/2 (1-) bias 1/3 input 2/3 recurrent Neuromodulation & Dynamic Filters Leaky-integrating neuron: (Yu & Dayan, Neuron, 2000) NE: Unexpected Uncertainty Norepinephrine (NE) (Hasselmo, Wyble, & Wallenstein 1996; Kobayashi, 2000) bias Trials input recurrent Learning the Value of Humans (Behrens et al, 2007) and rats (Gallistel & Latham, 1999) may encode meta-changes in the rate of change, Bayesian Learning Iteratively compute joint posterior … … .3 0 .3 0 .9 1 … … Marginal posterior over Marginal posterior over Neural Parameter Learning? • Neurons don’t need to represent probabilities explicitly • Just need to estimate • Stochastic gradient descent (-rule) ˆ n ˆ n1 (x n Pˆt )Pˆt learning rate Pt 16 (1 )2 13 Qt1 error gradient 1 Qt1 xt1 Qt2 2Pt1 1 Q1 x1 Learning Results Bayesian Learning Stochastic Gradient Descent Trials Trials Summary H: “Superstition” reflects adaptation to changing world Exponential “memory” near-optimal & fits behavior; linear RT Neurobiology: leaky integration, stochastic -rule, neuromodulation Random sequence and changing biases hard to distinguish Questions: multiple outcomes? Explicit versus implicit prediction? Unlearning Temporal Correlation is Slow Probability Marginal posterior over Probability Marginal posterior over Trials (see Bialek, 2005) Insight from Brain’s “Mistakes” Ex: visual illusions (Adelson, 1995) Insight from Brain’s “Mistakes” Ex: visual illusions lightness depth context (Adelson, 1995) Neural computation specialized for natural problems Discount Rate vs. Assumed Rate of Change Iterative form of linear exponential Exact inference is non-linear Linear approximation Empirical distribution Bayesian Inference 1: repetition 0: alternation Generative Model Optimal Prediction (what subject “knows”) (Bayes’ Rule) Posterior Bayesian Inference Generative Model (what subject “knows”) Optimal Prediction (Bayes’ Rule) Power-Law Decay of Memory Human memory Natural (language) statistics (Anderson & Schooler, 1991) Hierarchical Chinese Restaurant Process (Teh, 2006) 10 7 4 … Stationary process! Ties Across Time, Space, and Modality Sequential effects RT Eriksen Stroop SSHSS GREEN (Yu, Dayan, Cohen, JEP: HPP 2008) (Liu, Yu, & Holmes, Neur Comp 2008) time space modality Sequential Effects Perceptual Discrimination Optimal discrimination DBM R (Wald, 1947) • discrete time, SPRT • continuous-time, DDM (Gold & Glimcher, Neuron 2002) PFC A (Yu & Dayan, NIPS 2005) (Yu, NIPS 2007) (Frazier & Yu, NIPS 2008) Exponential Discounting for Changing Rewards (Sugrue, Corrado, & Newsome, 2004) = .63 Trials into past Monkey G Coefficients Coefficients Monkey F = .72 Trials into past Human & Monkey Share Assumptions? Human ! ≈ Monkey = .68 = .63 Trials into past Monkey G Coefficients Coefficients Monkey F = .80 = .72 Trials into past Simulation Results Learning via stochastic -rule Trials Monkeys’ Discount Rates in Choice Task (Sugrue, Corrado, & Newsome, 2004) Monkey G Coefficients Coefficients Monkey F = .63 Trials into past = .72 Trials into past .72 .63 .68 .80 Human & Monkey Share Assumptions? Human ! ≈ Monkey .72 .63 .68 .80