Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
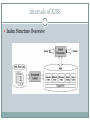
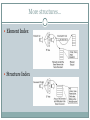
<TITLE> Indexing & Querying XML Data for ../Regular Path Expressions/* </TITLE> <AUTHORS> <NAME ID=1>QUANZHONG LI</NAME> <NAME ID=2>BONGKI MOON</NAME> <AUTHORS> <PRESENTERS> <NAME UFID=1234567>SUNDAR</NAME> <NAME UFID=7654321>SUPRIYA</NAME> <PRESENTERS> Need for this paper XML – emerged as a popular standard for data representation and data exchange on the Internet XML Query Languages use Regular Path Expressions to query the data Conventional approaches (for indexing & searching this data) based on Tree traversals goes for a toss! – under heavy access requests Traversing this hierarchy of XML data becomes a overhead if the path lengths are long or unknown What can be done??? Try our System and the Algorithms !!! New system for indexing & storing XML data – XISS New numbering scheme for elements and attributes Quick in figuring-out ‘ancestor-descendant’ relationship New index structures Easier to find all elements and attributes with a particular given name string Join algorithms for processing Reg-Path-Exp queries EE-Join – to search paths from element to element EA-Join – to find element-attribute pairs KC-Join – to find KC (*) on repeated paths or elements Go XISS!!! In general, XML data can be queried for a particular value (or) a structure By Value: get me “document”; get me “element=‘node1’ ” or “attribute=10” By Structure: get me parent and child elements/attributes for a given element Components: Index Structure: element, attribute and structure (index) Data Loader Query Processor Numbering Scheme first….. Deitz vs. Li-Moon… Deitz says, “If x and y are the nodes of a tree T, x is an ancestor of y iff x comes before y when I climb down the tree (pre-order), and after y when I climb up (post-order)” and shows us his scheme, Ancestor-Descendant relationship determination in constant time Li-Moon says, “but this lacks flexibility” This leads to many re-computations when a new node is inserted. Hmm… let us check-out Li-Moon’s…. Li-Moon’s Numbering… Hey folks, we are going to extend this preorder and cover up a range of descendants Just associate a pair of numbers <order, size> with each node Parent node x says to its child node y, “I came before you so my order is less than yours & my size is >= (your order + your size) and so your interval is always contained in my interval” If there are siblings x & y (same parent), say, x is before y, then order(x) + size(x) < order(y) Voila! Here it goes, So, for any node x, size(x) >= size of all its direct children [ size(x) is Laarrrge!] That being said, “Given nodes x and y of a tree T, x is an ancestor of y iff order(x) < order(y) <= order(x) + size(x) Good news! Easy accommodation of future insertions – more flexible Global reordering not necessary until no more reserved spaces order in <order, size> pair is an unique identifier for each element and attribute in the document Attribute nodes are placed before their sibling elements in the order – why? How this scheme helps? – wait till the algorithms! Switching back to XISS… Internals of XISS Index Structure Overview More structures… Element Index Structure Index Path Join Algorithms Conventional approaches (top down, bottom up and hybrid traversals) – not effective Main Idea of proposed algorithm: For a given query “chapter/-*/figure”, - find all ‘chapter’ elements - find all ‘figure’ elements - join the qualified ‘chapter-figure’ pairs without traversing XML data trees (if ancestordescendant relationship is obtained quickly) Complex -> Simple Complex path expression decomposed to many simple path expressions Intermediate results are joined to get the final result. Different types of sub-expressions EA-Join Algorithm To join intermediate results from sub-expressions with a list of elements and a list of attributes E.g. “figure[@caption=‘flowchart’]” Attributes should be placed before sibling elements in the order by the numbering scheme EA-Join Algorithm Input: List of “figure” elements and List of “caption” attributes grouped by documents Steps: (2 stages) Element sets and attribute sets merged by doc. Id (single scan) Elements and attributes are merged by figuring out the parentchild relationship using <order> value (single scan) Output: A set of (e, a) pairs where e is the parent of a EE-Join Algorithm To join intermediate results each of which is a list of elements from a sub-expression E.g. “chapter/-*/figure” Input: List of “chapter” elements and List of “figure” elements Steps (2 stages) are similar to EA-Algorithm Both element sets are merged by doc. Id (single scan) Chapter element and Figure element are merged by finding the ancestor-descendant relationship using <order, size> values Output: A set of (e, f) pairs where e is the ancestor of f EE-Algorithm The second stage cannot be done in a single scan In this E.g. , a “figure” element can be descendant of more than one “chapter” element (see book1.xml) order(figure) will lie in more than one chapter interval ([order(chapter), order(chapter) + size(chapter)]) This multiple-times scan is still highly effective in searching long or unknown length paths when compared to the conventional tree traversals. KC-Algorithm Processes a regular path expression with zero, one or more occurrences of a subexpression E.g. “chapter*”, “chapter+” Input: Set of elements from an XML document Steps: In each stage applies EE-Algorithm to previous stage’s result Repeat until no change in result Output: Kleene Closure of all elements in the given input set Experiments.. Prototype of XISS was implemented Query Interface – C++; Parse XML – Gnome XML Parser; B+-Tree - GiST C++ Library Workstation: Sun Ultrasparc-II running on Solaris 2.7 RAM: 256 MB; Hard-disk: 20GB Data Sets Shakespeare’s Plays SIGMOD Record NITF100 and NITF1 Performance Comparison EE-Join Query: Outperformed bottom-up method by a wide margin Real-World data set: an order of magnitude faster Synthetic data set: 6 to 10 times faster Disk IO was a dominant Cost factor – 60% to 90% of total elapsed time EA-Join Query: It was comparatively better than top-down and bottom-up approaches KC-Join Query: Performance was not measured; dependent on EE’s performance THE END! Hope this presentation was useful THANKS!