Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Data Protection Act, 2012 wikipedia , lookup
Expense and cost recovery system (ECRS) wikipedia , lookup
Operational transformation wikipedia , lookup
Data center wikipedia , lookup
Database model wikipedia , lookup
Forecasting wikipedia , lookup
Information privacy law wikipedia , lookup
3D optical data storage wikipedia , lookup
Data vault modeling wikipedia , lookup
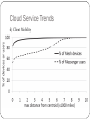
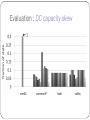
Volley: Automated Data Placement for Geo-distributed Cloud Services Presented ByKomal Pal VaibhavRastogi Agenda Introduction Motivation Design & Implementation Evaluation Conclusions and Future Work Introduction Volley is a system for cloud services that performs automatic placement across geo-distributed datacenters and takes care of User perceived latencies Business constraints - Datacenter resources, bandwidth costs Motivation Motivation Problem : Automated data placement for serving each user from the best datacenter for that user. Simplistic solution : Migrate data to DC geographically closest to user Challenges : Costs to DC operator – WAN bandwidth between DCs Skewed DC utilization due to over-provisioning Motivation Need of a new heuristic that can meet latest trends in modern cloud services : Shared data Data Inter-dependencies Application changes Reaching DC capacity limits User mobility Cloud service trends Live Mesh , Live Messenger: month-long workload traces a) Data Inter-dependencies Cloud Service Trends b) Client Geographic Diversity Cloud Service Trends c) Geographically Distant Data Sharing Cloud Service Trends d) Client Mobility Volley! First research work to address placement of data across geo- distributed DCs. Incorporates an iterative optimization algorithm based on weighted spherical means that handles complexities of shared data and data inter-dependencies. Design and Implementation Design Typical dataflow of an application using Volley Design Workflow – Request logging : timestamp, src, dst, req_size, id Additional inputs – a) b) requirements of RAM, disk, CPU for each type of data capacity & cost model for all DCs Model of inter-DC latency and client-DC latencies Any additional constraints e.g. legal Application specific migration Algorithm Phase 1: Compute initial placement : weighted spherical means Phase 2: Iteratively move data to reduce latency: weighted spring model, spherical coordinates Phase 3: Iteratively collapse data to DCs Evaluation Evaluation Comparison of Volley with – commonIP: data at DC closest to user oneDC: all data in one DC hash : hash data to DCs for load-balancing Analytical evaluation using 12 commercial DCs as potential locations. Evaluation : DC capacity skew Evaluation : Inter-datacenter traffic Evaluation : User-perceived latency Evaluation: Volley vsCommonIPon a live system Evaluation : Convergence Evaluation: Convergence Evaluation : Resource Demands & Frequent re-computation Small operational cost compared to operational savings in B/W consumption Conclusion and Future Work Conclusions and Future Work Need for automated techniques to place data across geo- distributed DCs Volley is the first system in this domain Volley is based on analysis of traces of 2 large scale commercial cloud services – Live Mesh & Live Messenger Conclusions and Future Work Reduces DC capacity skew by over 2x, inter-DC traffic by over 1.8x and 75th percentile latency by over 30% What’s next - Using Volley to identify potential DC sites that will improve latency at modest cost Thank You! Limitations Analysis may not be representative – only 2 applications, MS specific. (data with interdependencies etc. – very representative). Latency improvements are not very significant – no real costbenefit analysis. (confidentiality issues) Too simplistic to assume that only one such policy is in use at every datacenter without any optimization. (most common case – no other published work to show other alternatives) Uses only geographic location – no RTT analysis (first foray into this area, can be combined with other approaches for further optimization) Dependency on geo-location databases – may not be accurate, always. (still an improvement over existing mechanisms, may not even require higher granularity than what is being offered by DB)