Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
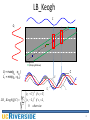
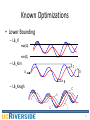
CS 260 Winter 2014 Eamonn Keogh’s Presentation of Thanawin Rakthanmanon, Bilson Campana, Abdullah Mueen, Gustavo Batista, Brandon Westover, Qiang Zhu, Jesin Zakaria, Eamonn Keogh (2012). Searching and Mining Trillions of Time Series Subsequences under Dynamic Time Warping SIGKDD 2012 Slides I created for this 260 class have this green background 1 What is Time Series? Shooting Hand moving to shoulder level Hand moving down to grasp gun Hand moving above holster Hand at rest 0 10 20 30 40 50 60 70 80 90 ? 400 Lance Armstrong 200 0 2000 1 0.5 0 0 50 100 150 200 250 300 350 400 450 2001 2002 What is Similarity Search I? Where is the closest match to Q in T? Q T What is Similarity Search II? Where is the closest match to Q in T? Q T What is Similarity Search II? Note that we must normalize the data Q T What is Indexing I? Indexing refers to any technique to search a collection of items, without having to examine every object. Obvious example: Search by last name Let look for Poe…. A-B-C-D-E-F G-H-I-J-K-L-M N-O-P-Q-R-S T-U-V-W-X-Y-Z 6 What is Indexing II? It is possible to index almost anything, using Spatial Access Methods (SAMs) Q T What is Indexing II? It is possible to index almost anything, using Spatial Access Methods (SAMs) What is Dynamic Time Warping? Lowland Gorilla Gorilla gorilla graueri DTW Alignment Mountain Gorilla Gorilla gorilla beringei Searching and Mining Trillions of Time Series Subsequences under Dynamic Time Warping Thanawin (Art) Rakthanmanon, Bilson Campana, Abdullah Mueen, Gustavo Batista, Qiang Zhu, Brandon Westover, Jesin Zakaria, Eamonn Keogh What is a Trillion? • A trillion is simply one million million. • Up to 2011 there have been 1,709 papers in this conference. If every such paper was on time series, and each had looked at five hundred million objects, this would still not add up to the size of the data we consider here. • However, the largest time series data considered in a SIGKDD paper was a “mere” one hundred million objects. 11 Dynamic Time Warping C Similar but out of phase peaks. Q Q C Q C R (Warping Windows) 12 Motivation • Similarity search is the bottleneck for most time series data mining algorithms. • The difficulty of scaling search to large datasets explains why most academic work considered at few millions of time series objects. 13 Objective • Search and mine really big time series. • Allow us to solve higher-level time series data mining problem such as motif discovery and clustering at scales that would otherwise be untenable. 14 Assumptions (1) • Time Series Subsequences must be Z-Normalized – In order to make meaningful comparisons between two time series, both must be normalized. B – Offset invariance. C – Scale/Amplitude invariance. A • Dynamic Time Warping is the Best Measure (for almost everything) – Recent empirical evidence strongly suggests that none of the published alternatives routinely beats DTW. 15 Assumptions (2) • Arbitrary Query Lengths cannot be Indexed – If we are interested in tackling a trillion data objects we clearly cannot fit even a small footprint index in the main memory, much less the much larger index suggested for arbitrary length queries. • There Exists Data Mining Problems that we are Willing to Wait Some Hours to Answer – a team of entomologists has spent three years gathering 0.2 trillion datapoints – astronomers have spent billions dollars to launch a satellite to collect one trillion datapoints of star-light curve data per day – a hospital charges $34,000 for a daylong EEG session to collect 0.3 trillion datapoints 16 Proposed Method: UCR Suite • An algorithm for searching nearest neighbor • Support both ED and DTW search • Combination of various optimizations – Known Optimizations – New Optimizations 17 Known Optimizations (1) • Using the Squared Distance 𝑛 2 𝐸𝐷 𝑄, 𝐶 = 𝑖=1 𝑞𝑖 − 𝑐𝑖 2 • Exploiting Multicores – More cores, more speed • Lower Bounding – LB_Yi – LB_Kim – LB_Keogh LB_Keogh U L Q C Known Optimizations (2) • Early Abandoning of ED ED(Q, C ) i 1 (qi ci ) 2 bsf n Q C We can early abandon at this point • Early Abandoning of LB_Keogh U C L Q L U, L is an envelope of Q 19 Known Optimizations (3) • Early Abandoning of DTW • Earlier Early Abandoning of DTW using LB Keogh C Q Stop Fully calculated LB Keogh if dtw_dist ≥ bsf U Partial truncation of LBKeogh C L K =0 Q dtw_dist C Partial calculation of DTW K = 11 About to begin calculation of DTW R (Warping Windows) 20 Known Optimizations (3) • Early Abandoning of DTW • Earlier Early Abandoning of DTW using LB_Keogh C Q Stop if dtw_dist +lb_keogh ≥ bsf Fully calculated LBKeogh U L Partial truncation of LBKeogh (partial) C lb_keogh K =0 Q (partial) dtw_dist C Partial calculation of DTW K = 11 About to begin calculation of DTW R (Warping Windows) 21 UCR Suite Known Optimizations – – – – New Optimizations Early Abandoning of ED Early Abandoning of LB_Keogh Early Abandoning of DTW Multicores 22 UCR Suite: New Optimizations (1) • Early Abandoning Z-Normalization – Do normalization only when needed (just in time). – Small but non-trivial. – This step can break O(n) time complexity for ED (and, as we shall see, DTW). – Online mean and std calculation is needed. xi zi 23 UCR Suite: New Optimizations (2) • Reordering Early Abandoning – We don’t have to compute ED or LB from left to right. – Order points by expected contribution. Standard early abandon ordering 12 34 5 6 7 8 Optimized early abandon ordering 9 5 1 3 24 C Q C Q Idea - Order by the absolute height of the query point. - This step only can save about 30%-50% of calculations. 24 UCR Suite: New Optimizations (3) • Reversing the Query/Data Role in LB_Keogh – – – – Make LB_Keogh tighter. Much cheaper than DTW. ------------------Triple the data. Online envelope calculation. Envelop on Q U Envelop on C C L Q U L 25 UCR Suite: New Optimizations (4) • Cascading Lower Bounds – At least 18 lower bounds of DTW was proposed. – Use some lower bounds only on the Skyline. Tightness of LB Tightness of (LB/DTW) bound lower 1 Early_abandoning_DTW max(LB_Keogh EQ, LB_Keogh EC) LB_KimFL LB_FTW LB_Ecorner LB_Keogh EQ LB_Yi LB_Kim 0 O(1) O(n) DTW LB_PAA O(nR) 26 UCR Suite Known Optimizations – – – – Early Abandoning of ED Early Abandoning of LB_Keogh Early Abandoning of DTW Multicores New Optimizations – – – – Just-in-time Z-normalizations Reordering Early Abandoning Reversing LB_Keogh Cascading Lower Bounds 27 UCR Suite State-of-the-art* Known Optimizations – – – – Early Abandoning of ED Early Abandoning of LB_Keogh Early Abandoning of DTW Multicores New Optimizations – – – – Just-in-time Z-normalizations Reordering Early Abandoning Reversing LB_Keogh Cascading Lower Bounds *We implemented the State-of-the-art (SOTA) as well as we could. SOTA is simply the UCR Suite without new optimizations. 28 Experimental Result: Random Walk • Random Walk: Varying size of the data UCR-ED Million (Seconds) 0.034 Billion (Minutes) 0.22 Trillion (Hours) 3.16 SOTA-ED 0.243 2.40 39.80 UCR-DTW 0.159 1.83 34.09 SOTA-DTW 2.447 38.14 472.80 Code and data is available at: www.cs.ucr.edu/~eamonn/UCRsuite.html 29 Experimental Result: Random Walk • Random Walk: Varying size of the query seconds For query lengths of 4,096 Naïve DTW (rightmost part of this graph) 10000 The times are: 1000 Naïve DTW SOTA DTW SOTA ED OPT UCRDTW DTW : 24,286 : 5,078 : 1,850 : 567 SOTA DTW (SOTA ED) OPT UCRDTW DTW 100 Query Length 30 Experimental Result: DNA • Query: Human Chromosome 2 of length 72,500 bps • Data: Chimp Genome 2.9 billion bps • Time: UCR Suite 14.6 hours, SOTA 34.6 days (830 hours) Rhesus macaque Gibbon Orangutan Catarrhines Hominoidea Gorilla Hominidae Chimp Homininae Hominini Human Chromosome 2: BP 5 7 0 9 5 0 0 :5 7 8 2 0 0 0 31 Experimental Result: EEG • Data: 0.3 trillion points of brain wave • Query: Prototypical Epileptic Spike of 7,000 points (2.3 seconds) • Time: UCR-ED 3.4 hours, SOTA-ED 20.6 days (~500 hours) Continuous Intracranial EEG Q Recordings made from 96 active electrodes, with data sampled at 30kHz per electrode Recorded with platinum-tipped silicon micro-electrode probes inserted 1.0 mm into the cerebral cortex 0 1000 2000 3000 4000 5000 6000 7000 32 Experimental Result: ECG • Data: One year of Electrocardiograms 8.5 billion data points. • Query: Idealized Premature Ventricular Contraction (PVC) of length 421 (R=21=5%). PVC (aka. skipped beat) ECG UCR-ED SOTA-ED UCR-DTW SOTA-DTW 4.1 minutes 66.6 minutes 18.0 minutes 49.2 hours ~30,000X faster than real time! 33 Speeding Up Existing Algorithm • Time Series Shapelets: – SOTA 18.9 minutes, UCR Suite 12.5 minutes • Online Time Series Motifs: – SOTA 436 seconds, UCR Suite 156 seconds • Classification of Historical Musical Scores: – SOTA 142.4 hours, UCR Suite 720 minutes • Classification of Ancient Coins: – SOTA 12.8 seconds , UCR Suite 0.8 seconds • Clustering of Star Light Curves: – SOTA 24.8 hours, UCR Suite 2.2 hours 34 Conclusion UCR Suite … • is an ultra-fast algorithm for finding nearest neighbor. • is the first algorithm that exactly mines trillion real-valued objects in a day or two with a "off-theshelf machine". • uses a combination of various optimizations. • can be used as a subroutine to speed up other algorithms. • Probably close to optimal ;-) 35 Authors’ Photo Thanawin Rakthanmanon Bilson Campana Brandon Westover Qiang Zhu Abdullah Mueen Jesin Zakaria Gustavo Batista Eamonn Keogh Acknowledgements • NSF grants 0803410 and 0808770 • FAPESP award 2009/06349-0 • Royal Thai Government Scholarship Papers Impact It was best paper winner at SIGKDD 2012 It has 37 references according to Google Scholar. Given that it has been in print only 18 months, this would make it among the most cited papers of that conference, that year. The work was expanded to a journal paper, which adds a section on uniform scaling. 38 Discussion The paper made use of videos http://www.youtube.com/watch?v=c7xz9pVr05Q 39 Questions About the paper? About the presentation of it? 40 41 LB_Keogh C Q R (Warping Windows) Ui = max(qi-r : qi+r) Li = min(qi-r : qi+r) C U (ci U i ) if ci U i LB _ Keogh(Q, C ) (ci Li ) 2 if ci Li i 1 0 otherwise 2 Q L n 42 Known Optimizations • Lower Bounding – LB_Yi max(Q) min(Q) – LB_Kim C A D B – LB_Keogh C U Q L 43 Ordering Standard early abandon ordering 34 5 7 9 5 1 3 24 C C Q Q Average Number of Point-to-point Distance Calculation 35 Avg No. of Calculation 12 6 8 Optimized early abandon ordering 30 25 This step only can save about 50% of calculations 20 15 10 5 0 SOTA-ED When good candidate is found 0 1 UCR-ED 2 3 4 5 6 Data in Progress 7 8 9 10 x 10 7 44 UCR Suite • New Optimizations – Just-in-time Z-normalizations – Reordering Early Abandoning – Reversing LB_Keogh – Cascading Lower Bounds • Known Optimizations – Early Abandoning of ED/LB_Keogh/DTW – Use Square Distance – Multicores 45