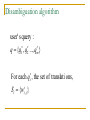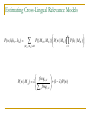Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Wizard of Oz experiment wikipedia , lookup
Machine translation wikipedia , lookup
Personal information management wikipedia , lookup
Human–computer interaction wikipedia , lookup
Personal knowledge base wikipedia , lookup
Visual Turing Test wikipedia , lookup
Cross-Language Information
Retrieval (CLIR)
Ananthakrishnan R
Computer Science & Engg., IIT Bombay
(anand@cse)
April 7, 2006
Natural Language Processing/Language
Technology for the Web
Cross Language Information Retrieval
(CLIR)
“A subfield of information retrieval dealing with retrieving
information written in a language different from the
language of the user's query.”
E.g., Using Hindi queries to retrieve English documents
Also called multi-lingual, cross-lingual, or trans-lingual
IR.
Why CLIR?
E.g., On the web, we have:
Documents in different languages
Multilingual documents
Images with captions in different languages
A single query should retrieve all such resources.
Approaches to CLIR
most
efficient;
commonly
used
Knowledgebased
Corpus-based
Query Translation Dictionary/Thes Pseudoaurus-based
Relevance
Feedback (PRF)
Document
Translation
MT
(rule-based)
MT
(EBMT/StatMT)
Intermediate
Representation
UNL
(AgroExplorer)
Latent Semantic
Indexing
Most effective approaches are hybrid – a combination of knowledge
and corpus-based methods.
infeasible
for
large
collections
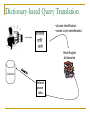
Dictionary-based Query Translation
आयरलैंड
श ांति
विा
• phrase identification
• words to be transliterated
Hindi-English
dictionaries
Collection
Ireland
peace
talks
The problem with dictionary-based
CLIR -- ambiguity
अांिररक्षीय घटन
ज ली धन
आयरलैंड श ांति व ि ा
cosmic outer-space
incident event occurrence
lessen subside decrease lower
diminish ebb decline reduce
lattice mesh net wire_netting
meshed_fabric counterfeit
forged false fabricated
small_net network gauze
grating sieve
money riches wealth appositive
property
Ireland
peace calm tranquility silence
quietude
conversation talk negotiation
tale
… filtering/disambiguation is required after
query translation.
Disambiguation using
co-occurrence statistics
Hypothesis: correct translations of query terms will
co-occur and incorrect translations will tend not
to co-occur
Problem with counting co-occurrences:
data sparsity
freq(Marathi Shallow Parsing CRFs)
freq(Marathi Shallow Structuring CRFs)
freq(Marathi Shallow Analyzing CRFs)
… are all zero.
How do we choose between parsing,
structuring, and analyzing?
Pair-wise co-occurrence
अांिररक्षीय घटन
cosmic outer-space
incident event occurrence lessen subside decrease lower diminish ebb
decline reduce
freq(cosmic incident)
freq(cosmic event
freq(cosmic lessen)
freq(cosmic subside)
freq(outer-space incident)
freq(outer-space event)
freq(outer-space lessen)
freq(outer-space subside)
70800
269000
7130
3120
26100
104000
2600
980
Shallow Parsing, Structuring or Analyzing?
shallow parsing
shallow structuring
shallow analyzing
166000
180000
1230000
CRFs parsing
CRFs structuring
CRFs analyzing
540
125
765
Marathi parsing
Marathi structuring
Marathi analyzing
17100
511
12200
“shallow parsing”
“shallow structuring”
“shallow analyzing”
40700
11
2
But,
analyzing
parsing
structuring
74100000
40400000
17400000
shallow
33300000
collocation?
Ranking senses using co-occurrence
statistics
Use co-occurrence scores to calculate
similarity between two words: sim(x, y)
Point-wise mutual information (PMI)
Dice coefficient
PMI-IR
hits( x AND y )
PMI - IR ( x, y ) log
hits( x) hits( y )
Disambiguation algorithm
user' s query :
q {q , q ..., q }
s
1
s
2
s
m
s
i
For each q , the set of translati ons,
Si {w }
t
i, j
1. sim (wit, j , Si ' )
wt' S '
i ,l
2. score ( wit, j )
sim (wit, j , wit' ,l )
i
t
sim
(
w
i , j , Si ' )
i ' i
3. qit arg max score(wit, j )
wit, j
translated query
q t {q1t , q2t , ..., qmt }
Example
अांिररक्षीय घटन
cosmic outer-space
incident event lessen subside decrease lower
diminish ebb decline reduce
score(cosmic)= PMI-IR(cosmic, incident) +
PMI-IR(cosmic, event) +
PMI-IR(cosmic, lessen) +
PMI-IR(cosmic, subside) …
Disambiguation algorithm: sample outputs
आयरलैंड श ांति व ि ा
Ireland peace talks
अांिररक्षीय घटन
cosmic events
ज ली धन
net money (?)
Results on TREC8 (disks 4 and 5)
English topics (401-450) manually translated to Hindi
Assumption: relevance judgments for English topics
hold for the translated queries
Results (all TF-IDF):
Technique
Monolingual
All-translations
MAP
23
16
PMI based disambiguation
Manual filtering
20.5
21.5
Pseudo-Relevance Feedback for CLIR
(User) Relevance Feedback (mono-lingual)
1.
2.
3.
Retrieve documents using the user’s query
The user marks relevant documents
Choose the top N terms from these
documents
4.
5.
Top terms IDF is one option for scoring
Add these N terms to the user’s query to
form a new query
Use this new query to retrieve a new set of
documents
Pseudo-Relevance Feedback (PRF)
(mono-lingual)
1.
2.
3.
4.
5.
Retrieve documents using the user’s query
Assume that the top M documents retrieved
are relevant
Choose the top N terms from these M
documents
Add these N terms to the user’s query to
form a new query
Use this new query to retrieve a new set of
documents
PRF for CLIR
Corpus-based Query Translation
Uses a parallel corpus of documents:
Hindi collection H
H1 E1
H2 E2
.
.
.
.
.
.
Hm Em
English collection E
PRF for CLIR
1.
Retrieve documents in H using the user’s query
2.
Assume that the top M documents retrieved are
relevant
Select the M documents in E that are aligned to
the top M retrieved documents
Choose the top N terms from these documents
These N terms are the translated query
Use this query to retrieve from the target collection
(which is in the same language as E)
3.
4.
5.
6.
Cross-Lingual Relevance Models
- Estimate relevance models using a parallel corpus
Ranking with Relevance Models
Relevance model or Query
model (distribution encodes
the information need):
Probability of word
occurrence in a relevant
document
Probability of word
occurrence in the candidate
document
Ranking function (relative
entropy or KL divergence)
R
P(w | R )
P(w | D)
KL( D || R)
P( w | D)
P( w | D). log
P( w | R )
w
Estimating Mono-Lingual Relevance
Models
P( w | R ) P( w | Q) P( w | h1h2 ...hm )
P( w, h1h2 ...hm )
P(h1h2 ...hm )
m
P( w, h1h2 ...hm ) P( M ) P( w | M ) P(hi | M )
M
i 1
Estimating Cross-Lingual Relevance Models
m
P( w, h1h2 ...hm ) P({M H , M E }) P( w | M E ) P(hi | M H )
{ M H , M E }
i 1
freqw, X
P( w | M X )
freqv , X
v
(1 ) P( w)
CLIR Evaluation – TREC
(Text REtrieval Conference)
TREC CLIR track (2001 and 2002)
Retrieval of Arabic language newswire documents from
topics in English
383,872 Arabic documents (896 MB) with SGML markup
50 topics
Use of provided resources (stemmers, bilingual
dictionaries, MT systems, parallel corpora) is
encouraged to minimize variability
http://trec.nist.gov/
CLIR Evaluation – CLEF
(Cross Language Evaluation Forum)
Major CLIR evaluation forum
Tracks include
Multilingual retrieval on news collections
topics will be provided in many languages including Hindi
Multiple language Question Answering
ImageCLEF
Cross Language Speech Retrieval
WebCLEF
http://www.clef-campaign.org/
Summary
CLIR techniques
Query Translation-based
Document Translation-based
Intermediate Representation-based
Query translation using dictionaries, followed by
disambiguation, is a simple and effective technique
for CLIR
PRF uses a parallel corpus for query translation
Parallel corpora can also be used to estimate crosslingual relevance models
CLEF and TREC: important CLIR evaluation
conferences
References (1)
1.
2.
3.
4.
Phrasal Translation and Query Expansion Techniques for Crosslanguage Information Retrieval, Lisa Ballesteros and W. Bruce
Croft, Research and Development in Information Retrieval, 1995.
Resolving Ambiguity for Cross-Language Retrieval, Lisa Ballesteros
and W. Bruce Croft, Research and Development in Information
Retrieval, 1998.
A Maximum Coherence Model for Dictionary-Based CrossLanguage Information Retrieval, Yi Liu, Rong Jin, and Joyce Y.
Chai, ACM SIGIR, 2005.
A Comparative Study of Knowledge-Based Approaches for CrossLanguage Information Retrieval, Douglas W. Oard, Bonnie J. Dorr,
Paul G. Hackett, and Maria Katsova, Technical Report CS-TR-3897,
University of Maryland, 1998.
References (2)
5.
6.
7.
8.
Translingual Information Retrieval: A Comparative Evaluation,
Jaime G. Carbonell, Yiming Yang, Robert E. Frederking, Ralf D.
Brown, Yibing Geng, and Danny Lee, International Joint
Conference on Artificial Intelligence, 1997.
A Multistage Search Strategy for Cross Lingual Information
Retrieval, Satish Kagathara, Manish Deodalkar, and Pushpak
Bhattacharyya, Symposium on Indian Morphology, Phonology
and Language Engineering, IIT Kharagpur, February, 2005.
Relevance-Based Language Models, Victor Lavrenko, and W.
Bruce Croft, Research and Development in Information
Retrieval, 2001.
Cross- Lingual Relevance Models, V. Lavrenko, M. Choquette,
and W. Croft, ACM-SIGIR, 2002.
Thank You