Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Part 1: The Bell Curve
Clarification of Symbols:
When reading different articles or text, you may see different symbols to
represent quantities. You may see x or used for the mean and s and used for
the standard deviation*. The reason for the different symbols is that x and s are
symbols used when dealing with samples and and are symbols used when
dealing with entire populations.
Don’t worry too much right now about the distinction, because it will be discussed
later.
*Standard deviation: This term comes up this week and will be discussed in
great detail through out the rest of the course.
Read about the Bell Curve and the Empirical Rule at the site below.
http://www.oswego.edu/~srp/stats/6895997.html" target="new
The key points of this section are:
The normal bell curve is symmetrical; that is the left side is a mirror image
of the right side.
The data in the normal bell curve are distributed according to a definite
pattern.
The distribution of additional data collected from the same population is
predictable.
The other key word here is normal. What is normal? In terms of data, if you
collect enough data randomly from a population, the data will fall into a
predictable distribution. This is the key to solving problems based on
mathematical models. When data is not distributed according to a definite
pattern, it is a signal that something is wrong or different with one or several data
values.
When you look at the next section on standard deviations you will see how the
data is distributed under normal circumstances.
I have included two links to web sites involviing the bell curve. Many web sites
involving standard deviations deal with psychology and social issues. The two
sites I have given are closely realted to what you are studying now.
1) Description of the Bell Curve, http://wwwstat.stanford.edu/~naras/jsm/NormalDensity/NormalDensity.html
At this site, read about normal distribution, the standard deviation, empircal
rule, and observe the bell curve. Make sure to read the examples at the bottom
of the page. A formula for normal density is given and may be a little hard to
read. Don't worry about the formula because we will not be using it at this
time.
2) Application of the Bell Curve,
http://www.tsoft.com/~deano/articles/BellCurve.html" target="new">. This is a site
that deals with basketball statistics and shows a few applications of the bell
curve.
Part 2: Dividing the bell curve into standard deviations
In the previous lesson you learned that the normal bell curve is a predictable
distribution of data. How is that data distributed?
To make life a little easier statisticians have devised a term called the standard
deviation ( S for samples and for populations). The standard deviation is a
calculated distance from the mean. We will be actually calculating this value next
week. For right now it will be given and you just have to use it in a formula.
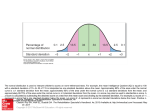
One Standard Deviation (1S)
Since the normal bell curve is symmetrical you can go both to the right of the
mean and to the left of the mean on the curve. The symmetrical line is called the
standard deviation. If you go to the right one line, this is plus one standard
deviation. If you go to the left one line this is minus one standard deviation. The
whole area from minus one standard deviation to plus one standard deviation is
an area that contains 68% of the data. One standard deviation contains 68% of
the data.
Two Standard Deviations (2S)
The next two areas contain 27% percent (13.5% on each side) of the data. This
area is called the second standard deviation. If you combine the first and second
standard deviations, the total data contained in these areas is 95%.
Three Standard Deviations (3S)
The third standard deviation contains 4.7% (2.35% on each side) of the data. If
you combine all the data contained in the all three standard deviations, it totals
99.7%. This means that only 0.3% of data will be outside the third standard
deviation. While this may seem to be pretty good, companies are looking at 6
standard deviations. Why? Because if they consider 3 standard deviations to be
good enough, that means 3 out of 1000 items could be bad, 30 out of
10,000 could be bad, 300 out of 100,000 could be bad and 3000 out of 1,000,000
will be bad. In a time of large scale production, that is just not good enough.
However, in order to keep things simple you will only have to deal with 3
standard deviations. The exercise that you will do today consists of two parts. .
Part 1: Given the mean( = 5.8 and = 0.3 ) and standard deviation ( )
calculate were the three standard deviation lines would appear on a bell curve.
Example: Given that = 15 and = 1.2
The middle line is at 15, the mean
The first line above the mean is at + 1 = 15 + 1.2 = 16.2
The second line above the mean is at + 2 = 15 + 2.4 = 17.4
The third line above the mean is at + 3 = 15 + 3.6 = 18.6
The first line below the mean is at - 1 = 15 - 1.2 = 13.8
The second line below the mean is at - 2 = 15 - 2.4 = 12.6
The third line below the mean is at - 3 = 15 - 3.6 = 11.4
1) = 5.8 and = 0.3 2) = 9.24 and = 1.32
3) = 62.3 and = 0.4 4) = 101.24 and = 2.51
5) = 34 and = 0.5 6) = 20 and = 1
Part 2: Given the number of data values, calculate the number of data values
that will fall between each standard deviation. Assume the data is distributed
normally.
Example: For 200 data values
Between ± 1, 200 x 68% = 136 of the 200 values will exist
Between ± 2, 200 x 95% = 190 of the 200 values will exist
Between ± 3, 200 x 99.7% = 199 of the 200 values will exist
1) 35 values 2) 280 values
3) 88 values 4) 570 values
5) 2009 values 6) 10964 values
Part 3: The Z-score
Once you have information about the mean and the
standard deviation you have a pretty good idea about where individual data values may lie on the bell curve. A
calculated value that gives you a more exact idea of where a data value is on the curve is the Z-Score, sometimes
referred as the Z-Value.
The Z Score measures the exact number of standard deviations between the
data value and the mean. The formula is listed below:
z-score = y - m
Where y = the data value
the mean
= the standard deviation
If you take a good look at this formula you should be aware of 3 things:
1. The mean has a z-score of 0.
2. A data value less than the mean has a negative z-score.
3. A data value greater than the mean has a positive z-score.
To see an example of a z-score calculation go to:
http://www.stat.tamu.edu/stat30x/notes/node34.html
Assignment: This is a real short one.
Calculate the z-score for each.
1) = 5.8, = 0.3 and y = 3.1
2) = 9.24, = 1.32 y = 10.98
3) = 62.3, = 0.4 and y = 62.7
4) = 101.24, = 2.51 and y = 98.24
5) = 34, = 0.5 and y = 32.8
6) = 20, = 1 and y = 22.3
Part 4: Assessment
1) Multiple Choice: What information is not available in a box-and-whisker
plot?
a)
b)
c)
d)
Minimum Value
Mean
Median
Maximum value
2) Multiple Choice: Which of the following values can be calculated from the
information given on a line plot?
a)
b)
c)
d)
Mean
Median
Mode
All of the Above
3) Multiple Choice: For the data set{10,12,13,13,15,16,16,16,20,21} the
innerquartile range is:
a)
b)
c)
d)
3
11
15.5
Does not exist
4) Multiple Choice: Consider the data set {20,25,27,30,33,36}
If the 20 was changed to a 17, which of the following could be done so
that the mean doesn't change?
a)
b)
c)
d)
Change the 25 to 22
Change the 27 to 30
Change the 33 to 30
Change the 36 to 33
5) Multiple Choice: In a data set of 1500 values, a mean of 20, and a
standard deviation of 3, how many values lie between 14 and 26?
a)
b)
c)
d)
12
1020
1425
1496
6) Multiple Choice: What is true about the data in the following frequency
table?
Score
Frequency
80
82
86
90
2
4
3
5
a) The mean is greater
than the median
b) The median is greater
than the mean
c) The mean and median
are equal
d) There is no mode for the data
7) Multiple Choice: Which measure will be most affected by an outlier?
a)
b)
c)
d)
Q1
Q3
Innerquartile Range
Range
8) Multiple Answer: Which of the following are true concerning the z-score?
Select all correct answers.
a)
b)
c)
d)
All z-scores are positive
A z-score greater than the mean is positive
The z-score is the number that appears most
The mean has a z-score of 0
9) Multiple Answers: Choose all the statements that are true about a line
plot for the data set {15, 12, 18, 12, 16, 18, 19, 18, 12}
a)
b)
c)
d)
There will be 3 marks above the 12
There will be one mark above the 15
There will be one mark above the 17
It should start at 12 and end at 19
10) Ordering: For a data set with normal distribution, order the following
from least to greatest:
a)
b)
c)
d)
Q3
a value with a z-score of 1
A value with a z-score of 2
The mean
Essay or Short Response: Refer to the stem and leaf plot below for
questions 11 and 12
Below are the attendance totals for performances of a series of concerts.
21
22
23
24
25
68
1579
227
466
0
11) How many concerts were there?
11)________
12) What was the range in attendance?
12)________
Key: 22/3 means 223
Weekly Resturaunt Sales
13) Refer to the histogram at the right.
Would you consider the data as
Normal ?
Try to answer in 2 sentences or less
6
5
Number
of
Weeks
4
3
2
1
50 to 59 60 to 69 70 to 79 80 to 89 90 to 99
Tatal Sales in Th ousands of Dollars
14) Ken had grades of 95, 90, 90, 100 and 55 on his tests this marking period.
Which measure of central tendency, the mean or median is a better indicator of
his ability. Explain why.
15) Alberto received grades of 85, 97, 95, and 89 on his first four tests. What
must he get on his fifth test, exactly, in order to average a 93?
16) Of 500 high school students whose mean height is 67.8 inches, 150 were
girls. If the mean height of the girls was 63.0 inches, what is the mean height of
the boys?
17) The two stem and leaf plots below represent the final grades for Ms. Sloan’s
Algebra II class and Mr. Clarks Pre-calculus class. The two class are the top two
math classes in the school this year. The class with the highest average will win
a first place prize as best math class. If another class has a better median grade
than the class with the best average, that class will share the first place prize.
Ms. Sloan's Class
5
6
7
8
9
a)
b)
c)
d)
1
8
1488
003889
03338
Mr. Clark's Class
6
7
8
9
9
2689
1222589
03338
Calculate the mean and median for Ms. Sloan’s class.
Calculate the mean and median for Mr. Clark’s class.
Which class wins first prize or will they both share it? Explain.
Before the announcement of first prize took place, the student who
received a 51 in Ms. Sloan’s class dropped out of school. Would removing
the 51 from Ms. Slone’s class change what should be announced?
Explain.
18) Which grade is better: a 78 on a test whose mean is 72 and standard
deviation is 6.5, or an 83 on a test whose mean is 77 and standard deviation is
8.4? Justify your answer.