Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Chapter 4
Continuous Random Variables
In this chapter we study continuous random variables. The linkage between continuous and
discrete random variables is the cumulative distribution (CDF) which we will take a closer
look in this chapter.
4.1
PDF
As we discussed in Chapter 3, random variables are “objects” characterized through their
probability mass functions (for the discrete case). For continuous random variables, we have
an analogous function called the probability density function (PDF).
Definition 1. The probability density function (PDF) of a random variable X is a
function which, when integrated over an interval [a, b], yields the probability of obtaining
a ≤ X(ξ) ≤ b. We denote PDF of X as fX (x), and
Z
P[a ≤ X ≤ b] =
b
fX (x)dx.
(4.1)
a
The key difference between a PMF and a PDF is the integration present in the PDF. However,
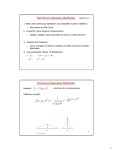
it is possible to include the integration for PMF. Suppose we are interested in calculating
the probability of a random variable X that lies in the interval [a, b], see Figure 4.1. If X is
continuous, this probability (according to the definition of PDF) is
Z b
P[a ≤ X ≤ b] =
fX (x)dx.
a
If X is discrete, then (according to the definition of PMF) the probability is
Z b
(a)
(b)
P[a ≤ X ≤ b] = P[X = x0 ] = pX (x0 ) =
pX (x0 )δ(x − x0 )dx,
{z
}
a |
fX (x)
1
where (a) holds because there is no other non-zero probabilities in the interval [a, b] besides
x0 , and (b) holds because the delta function has the property that δ(x − x0 ) = 1 if x = x0 ,
and δ(x−x0 ) = 0 if x 6= x0 . Therefore, we see that the PMF, which is a sequence of numbers,
can be seen as a train of delta functions. The height of the delta function at x0 is pX (x0 ).
The integration of this train of delta functions returns the probability P[a ≤ X ≤ b].
Figure 4.1: PMF is a train of impulses, whereas PDF is (usually) a smooth function.
Property 1. A PDF fX (x) should satisfy
Z ∞
fX (x)dx = 1.
(4.2)
−∞
Example. Let fX (x) = c(1 − x2 ) for −1 ≤ x ≤ 1, and 0 otherwise. Then, the constant c
can be found as follows. Since
Z 1
Z ∞
4c
c(1 − x2 )dx = ,
fX (x)dx =
3
−1
−∞
R∞
and because −∞ fX (x)dx = 1, we have c = 3/4.
Remark. What is P[X = x0 ] if X is continuous? The long answer will be discussed
in the next section. The short answer is: If the PDF fX (x) (which is a function of x) is
continuous at x = x0 , then P[X = x0 ] = 0. This can be seen from the definition of the PDF.
As a → x0 and b → x0 , the integration interval becomes 0. Thus, unless fX (x) is a delta
function at x0 , which has been excluded because we assumed fX (x) is continuous at x0 , the
integration result must be zero.
4.2
CDF
Definition 2. The cumulative distribution function (CDF) of a continuous random
variable X is
Z x
def
FX (x) = P[X ≤ x] =
fX (x0 )dx0 .
(4.3)
−∞
c 2017 Stanley Chan. All Rights Reserved.
2
Note that the definition of CDF for a continuous X is analogous to that for a discrete X,
with the summation replaced by the integration.
Properties of CDF
As we have seen in Chapter 3, a CDF has several interesting properties. Here we provide
more details. The first four properties come from the integration of the PDF.
Property 1: FX (−∞) = 0
R −∞
• Reason: FX (−∞) = −∞ fX (x0 )dx0 = 0.
Property 2: FX (+∞) = 1
R +∞
• Reason: FX (+∞) = −∞ fX (x0 )dx0 = 1.
Property 3: FX (x) is a non-decreasing function of x.
Rx
• Reason: Since Fx (x) = −∞ fX (x0 )dx0 , and since fX (x0 ) ≥ 0 for all x0 , if we increase
x we integrate over a larger region. The integrated value therefore increases. See
Figure 4.2 for a pictorial illustration.
Property 4: 0 ≤ FX (x) ≤ 1.
• Reason: This follows from Properties 1-3.
Figure 4.2: A CDF is the integration of the PDF. Thus, the height of a stem in the CDF
corresponds to the area under the curve of the PDF.
The next property relates probability and CDF.
Property 5: P[a ≤ X ≤ b] = FX (b) − FX (a).
c 2017 Stanley Chan. All Rights Reserved.
3
• Reason: Note that
Z
b
0
0
Z
a
fX (x )dx −
FX (b) − FX (a) =
−∞
b
Z
=
fX (x0 )dx0
−∞
fX (x0 )dx0
a
= P[a ≤ X ≤ b].
Property 6 and Property 7 are important for discontinuities of FX (x). There are three terms
involved in these two properties:
(i) FX (b): The value of FX (x) at x = b.
(ii) limh→0 FX (b − h): The limit of FX (x) from the left hand side of x = b.
(iii) limh→0 FX (b + h): The limit of FX (x) from the right hand side of x = b.
We say that FX (x) is
• Left-continuous at x = b if FX (b) = limh→0 FX (b − h);
• Right-continuous at x = b if FX (b) = limh→0 FX (b + h);
• Continuous at x = b if it is both right-continuous and left-continuous at x = b. In
this case, we have
lim FX (b − h) = lim FX (b + h) = F (b).
h→0
h→0
Property 6: FX (x) is right-continuous. That is,
lim FX (b + h) = FX (b).
h→0
(4.4)
Right-continuous essentially means that if FX (x) is piecewise, then it must have a solid left
end and an empty right end. See Figure 4.3.
Figure 4.3: Illustration of right continuous.
Of course, FX (x) does not have to be piecewise. When FX (x) is continuous (i.e., both left
and right continuous), the leftmost solid dot will overlap with the rightmost empty dot of
the previous segment, leaving not gap between the two.
c 2017 Stanley Chan. All Rights Reserved.
4
Property 7: P[X = b] is determined by
P[X = b] = FX (b) − lim FX (b − h).
h→0
(4.5)
Property 7 concerns about the probability at discontinuity. It states that when FX (x) is
discontinuous at x = b, then P[X = b] is the difference between FX (b) and the limit from
the left. In other words, the height of the gap determines the probability at discontinuity.
If FX (x) is continuous at x = b, then FX (b) = limh→0 FX (b − h) and so
P[X = b] = 0.
Figure 4.4: Illustration Property 7.
Fundamental Theorem of Calculus
Thus far we have only seen how to obtain FX (x) from fX (x). In order to go in the reverse
direction, we need to recall the fundamental theorem of calculus. Fundamental theorem of
calculus states that if a function f is continuous, then
Z x
d
f (t)dt
f (x) =
dx a
for some constant a. Using this result for CDF and PDF, we have the following result:
Theorem 1. The probability density function (PDF) is the derivative of the cumulative distribution function (CDF):
Z x
dFX (x)
d
fX (x) =
=
fX (x0 )dx0 ,
(4.6)
dx
dx −∞
provided FX is differentiable at x.
c 2017 Stanley Chan. All Rights Reserved.
5
Remark: If FX is not differentiable at x, then,
fX (x) = P[X = x] = FX (x) − lim FX (x − h),
h→0
where the second equality follows from Property 7.
Example 1. Consider a CDF
(
0,
FX (x) =
1 − 14 e−2x ,
x < 0,
x ≥ 0.
Our goal is to find the PDF fX (x).
Figure 4.5: Example 1.
First, it is easy to show that FX (0) = 43 . This corresponds to a discontinuity at x =
0, as shown in Figure 4.5. Because of the discontinuity, we need to consider three when
determining fX (x):
dF (x)
X
x < 0,
dx ,
fX (x) = P[X = 0],
x = 0,
dFX (x)
,
x > 0.
dx
X (x)
When x < 0, FX (x) = 0. So, dFdx
= 0.
1 −2x
X (x)
When x > 0, FX (x) = 1 − 4 e . So, dFdx
= 12 e−2x .
When x = 0, the probability P[X = 0] is determined according to Property 7 which is the
height between the solid dot and the empty dot. This yields
P[X = 0] = FX (0) − lim FX (0 − h) =
h→0
3
3
−0= .
4
4
Therefore, the overall PDF is
0,
fX (x) = 34 ,
1 −2x
e ,
2
c 2017 Stanley Chan. All Rights Reserved.
x < 0,
x = 0,
x > 0.
6
4.3
Expectation, Variance and Moments
Like the discrete random variables, the mean and moments of a continuous random variable
can be defined using integrations.
Definition 3. The expectation of a continuous random variable X is
Z ∞
x fX (x)dx.
E[X] =
(4.7)
−∞
Similarly, any function of X can be defined as:
Definition 4. The expectation of a function g of a continuous random variables X is
Z ∞
E[g(X)] =
g(x) fX (x)dx.
(4.8)
−∞
Note that in this definition, the PDF fX (x) is not changed by the function g.
Definition 5. The kth moment of a continuous random variables X is
Z ∞
k
E[X ] =
xk fX (x)dx.
(4.9)
−∞
Finally, we can define the variance of a continuous random variable:
Definition 6. The variance of a continuous random variables X is
Var[X] = E[(X − µX )2 ],
(4.10)
def
where µX = E[X].
It is not difficult to show that the variance can also be expressed as
Z ∞
Var[X] =
(x − µX )2 fX (x)dx,
−∞
or
Var[X] = E[X 2 ] − E[X]2 .
c 2017 Stanley Chan. All Rights Reserved.
7
4.4
Mean, Mode, Median
In statistics, we are typically interested in three quantities: mean, mode and median. It is
possible to obtain these three quantities from PDF and CDF.
From PDF
We first show how mean, mode and median can be obtained from the PDF. A pictorial
illustration of mode and median is given in Figure 4.6.
Median: The median is the point where the area under fX (x) on the two sides equal:
Z x
Z ∞
0
0
fX (x )dx =
fX (x0 )dx0 .
(4.11)
Median = x such that
−∞
x
Mode: The mode is the point where fX (x) attains the maximum.
Mode = argmax fX (x)
(4.12)
x
Mean: The mean is calculated from the definition of expectation:
Z ∞
Mean = E[X] =
xfX (x)dx.
(4.13)
−∞
Figure 4.6: Mode and median in a PDF and a CDF.
From CDF
Since CDF is the integration of the PDF, it is possible to derive the mean, mode, and median
from the CDF.
c 2017 Stanley Chan. All Rights Reserved.
8
Median: The median is the point where FX (x) achieves 12 :
1
Median = x such that FX (x) = .
2
(4.14)
Mode: The mode is the point where FX (x) attains the steepest slope, so that the derivative
(i.e., PDF) attains the maximum.
Mode = argmax FX0 (x).
(4.15)
x
Mean: The mean can be computed as follows.
∞
Z
0
Z
0
0
FX (x0 )dx0 .
(1 − FX (x )) dx −
E[X] =
(4.16)
−∞
0
Proof. For any random variable X, we can partition X = X + − X − where X + and X −
are the positive and negative parts, respectively. Consider the positive part first. For any
X > 0, it holds that
∞
Z
0
∞
Z
0
0
Z
∞
[1 − P[X ≤ x ]] dx =
P[X > x0 ]dx0
Z0 ∞ Z ∞
Z ∞0Z x
=
fX (x)dxdx0 =
fX (x)dx0 dx
0
0
0
Z0 ∞ x
=
xfX (x)dx = E[X].
(1 − FX (x )) dx =
0
0
0
Now, consider the negative part. For any X < 0, it holds that
Z
0
0
0
Z
0
0
−∞
Z
0
Z
x0
P[X ≤ x ]dx =
fX (x)dxdx0
−∞
−∞ −∞
Z 0 Z 0
Z 0
0
=
fX (x)dx dx =
xfX (x)dx = E[X],
FX (x )dx =
−∞
x
0
−∞
where in both cases we switched the order of the integration.
c 2017 Stanley Chan. All Rights Reserved.
9
4.5
Common Continuous Random Variables
Uniform Random Variable
Definition 7. Let X be a continuous uniform random variable. The PDF of X is
(
1
,
a ≤ x ≤ b,
fX (x) = b−a
(4.17)
0,
otherwise,
where [a, b] is the interval on which X is defined. We write
X ∼ Uniform(a, b)
to say that X is drawn from a uniform distribution on an interval [a, b].
Uniform random variables are very common in numerical simulations. The statistical properties of a uniform random variable is summarized as follows.
Figure 4.7: Uniform distribution
Proposition 1. If X ∼ Uniform(a, b), then
E[X] =
a+b
,
2
and
Var[X] =
(b − a)2
.
12
Proof.
Z
∞
E[X] =
Z
xfX (x)dx =
−∞
∞
a
b
x
a+b
dx =
b−a
2
b
x2
a2 + ab + b2
dx =
3
−∞
a b−a
2
(b − a)
Var[X] = E[X 2 ] − E[X]2 =
.
12
E[X 2 ] =
Z
x2 fX (x)dx =
c 2017 Stanley Chan. All Rights Reserved.
Z
10
Exponential Random Variable
Definition 8. Let X be an exponential random variable. The PDF of X is
(
λe−λx ,
x ≥ 0,
fX (x) =
0,
otherwise,
(4.18)
where λ > 0 is a parameter. We write
X ∼ Exponential(λ)
to say that X is drawn from an exponential distribution of parameter λ.
Figure 4.8: Exponential distribution
Proposition 2. If X ∼ Exponential(λ), then
E[X] =
1
,
λ
and
Var[X] =
1
.
λ2
Proof.
Z
∞
Z
∞
Z
∞
xfX (x)dx =
λxe dx = −
xde−λx
0
0
−∞
∞ Z ∞
1
= −xe−λx +
e−λx dx =
λ
0
0
Z ∞
Z ∞
Z ∞
2
2
2 −λx
E[X ] =
x fX (x)dx =
λx e dx = −
x2 de−λx
−∞
0
0
∞ Z ∞
2
2
2xe−λx dx = 0 + E[X] = 2
= −x2 e−λx +
λ
λ
0
0
1
Var[X] = E[X 2 ] − E[X]2 = 2 ,
λ
E[X] =
−λx
where we used integration by parts in calculating E[X] and E[X 2 ].
c 2017 Stanley Chan. All Rights Reserved.
11
Gaussian Random Variable
Definition 9. Let X be an Gaussian random variable. The PDF of X is
(x−µ)2
1
fX (x) = √
e− 2σ2
2πσ 2
(4.19)
where (µ, σ 2 ) are parameters of the distribution. We write
X ∼ N (µ, σ 2 )
to say that X is drawn from a Gaussian distribution of parameter (µ, σ 2 ).
Gaussian random variables are also called normal random variables. As will be shown, the
parameters (µ, σ 2 ) are in fact the mean and the variance of the random variable. Gaussian
random variables are extremely common in engineering and statistics. Among many reasons,
one important reason is the Central Limit Theorem which we will discuss later.
Figure 4.9: Gaussian distribution
Proposition 3. If X ∼ N (µ, σ 2 ), then
E[X] = µ,
and
Var[X] = σ 2 .
Proof.
E[X] = √
1
Z
∞
xe−
(x−µ)2
2σ 2
dx
2πσ 2 Z−∞
∞
y2
1
(a)
= √
(y + µ)e− 2σ2 dy
2πσ 2 Z −∞
Z ∞
∞
2
y2
1
1
− y2
=√
ye 2σ dy + √
µe− 2σ2 dy
2πσ 2 −∞
2πσ 2 −∞
Z ∞
2
1
(b)
− y2
= 0+µ √
e 2σ dy
2πσ 2 −∞
(c)
= µ,
c 2017 Stanley Chan. All Rights Reserved.
12
where in (a) we substitute y = x − µ, in (b) we use the fact that the first integrand is odd so
that the integration is 0, and in (c) we observe that integration over the entire sample space
of the PDF yields 1.
Var[X] = √
1
Z
∞
(x − µ)2 e−
(x−µ)2
2σ 2
dx
2πσ 2 −∞
2 Z ∞
y2
x−µ
(a) σ
y=
y 2 e− 2 dy,
= √
σ
2π −∞
Z
∞
2
2
y 2 ∞
y2
σ
σ
−ye− 2 e− 2 dy
=√
+√
−∞
2π
2π −∞
Z ∞
2
y
1
− 2
2
e dy
=0+σ √
2π −∞
= σ2,
where in (a) we substitute y = (x − µ)/σ.
Standard Gaussian
In many practical situations, we need to evaluate the probability P[a ≤ X ≤ b] of a Gaussian
random variable X. This involves integration of the Gaussian PDF. Unfortunately, there is
no closed-form expression of P[a ≤ X ≤ b] in terms of (µ, σ 2 ). One often has to use a table
to find the numerical value of the probability. Standard Gaussian is created for this reason.
Definition 10. A standard Gaussian (or standard Normal) random variable X has a
PDF
x2
1
fX (x) = √ e− 2 .
(4.20)
2π
That is, X ∼ N (0, 1) is a Gaussian with µ = 0 and σ 2 = 1.
Definition 11. The Φ(·) function of the standard Gaussian is
Z y
x2
1
Φ(y) = √
e− 2 dx
2π −∞
(4.21)
Essentially, Φ(y) is the CDF of the standard Gaussian. Once we have the Φ(·) function, it
becomes easy to write probability in terms of Φ(·).
c 2017 Stanley Chan. All Rights Reserved.
13
Figure 4.10: Definition of Φ(y).
Example. Let X ∼ N (µ, σ 2 ).
Z
b
√
P[X ≤ b] =
−∞
Z
1
2πσ 2
e−
(x−µ)2
2σ 2
dx
b−µ
σ
y2
1
√ e− 2 dy,
2π
−∞
b−µ
.
=Φ
σ
=
where y =
x−µ
σ
Consequently, we have
P[a < X ≤ b] = P[X ≤ b] − P[X ≤ a]
b−µ
a−µ
=Φ
−Φ
.
σ
σ
4.6
Function of Random Variables
One common question we encounter in practice is the transformation of random variables.
The question is simple: Given a random variable X with PDF fX (x) and CDF FX (x), and
suppose that Y = g(X) for some function g, then what are fY (y) and FY (y)? The general
technique we use to tackle these problem involves the following steps:
• Step 1: Find the CDF FY (y), which is P[Y ≤ y], using FX (x).
• Step 2: Find the PDF fY (y) by taking derivative on FY (y).
To see how these steps are used, we consider the following examples.
Example 1. Let X be a random variable with PDF fX (x) and CDF FX (x). Let Y = 2X +3.
Find fY (y) and FY (y). To tackle this problem, we first note that
y−3
y−3
= FX
.
FY (y) = P[Y ≤ y] = P[2X + 3 ≤ y] = P X ≤
2
2
c 2017 Stanley Chan. All Rights Reserved.
14
Therefore,
d
d
y−3
fY (y) = FY (y) = FX
dy
dy
2
y−3 d y−3
0
= FX
2
dy
2
1
y−3
= fX
.
2
2
Example 2. Let X be a random variable with PDF fX (x) and CDF FX (x). Suppose that
Y = X 2 , find fY (y) and FY (y). To solve this problem, we note that
FY (y) = P[Y ≤ y] = P[X 2 ≤ y]
√
√
= P[− y ≤ X ≤ y]
√
√
= FX ( y) − FX (− y).
Therefore, the PDF is
d
d
√
√
FY (y) =
(FX ( y) − FX (− y))
dy
dy
d
√
√
√ d
√
= FX0 ( y)
y − FX0 (− y) (− y)
dy
dy
1
√
√
= √ (fX ( y) + fX (− y)) .
2 y
fY (y) =
Example 3. Let X ∼ Uniform(0, 2π). Suppose Y = cos X. Find fY (y) and FY (y). First of
all, we need to find the CDF of X. This can be done by noting that
Z x
Z x
1 0
x
0
0
fX (x )dx =
FX (x) =
dx =
.
2π
0 2π
−∞
Thus, the CDF of Y is
FY (y) = P[Y ≤ y] = P[cos X ≤ y]
= P[cos−1 y ≤ 2π − cos−1 y]
= FX (2π − cos−1 y) − FX (cos−1 y)
cos−1 y
=1−
.
π
The PDF of Y is
d
d
fY (y) = FY (y) =
dy
dy
1
,
= p
π 1 − y2
c 2017 Stanley Chan. All Rights Reserved.
cos−1 y
1−
π
15
where we used the fact that
d
dy
cos−1 y = √−1 2 .
1−y
In some cases we do not need to explicitly find the CDF in order to find the PDF. Below is
an example.
Example 4. Let X be a random variable with PDF
x
fX (x) = aex e−ae .
Let Y = eX , and find fY (y). To solve this problem, we first note that
FY (y) = P[Y ≤ y] = P[eX ≤ y]
= P[X ≤ log y]
Z log y
x
aex e−ae dx.
=
−∞
To find the PDF, we recall the fundamental theorem of calculus. This will give us
Z log y
d
x
fY (y) =
aex e−ae dx
dy −∞
Z log y
d
d
x −aex
ae e
log y
dx
=
dy
d log y −∞
1
log y
= aelog y e−ae
y
= ae−ay .
4.7
Generating Random Numbers
For common types of random variables, e.g., Gaussian or exponential, there are often built-in
functions in MATLAB to generate the random numbers. However, for arbitrary PDFs, how
can we generate the random numbers?
Generating arbitrary random numbers can be done with the help of the following theorem.
Theorem 2. Let X be a random variable with an invertible CDF FX (x), i.e., FX−1 exists.
If Y = FX (X), then Y ∼ Uniform(0, 1).
Proof. First, we know that if U ∼ Uniform(0, 1), then fU (u) = 1 for 0 ≤ u ≤ 1 and so
Z u
FU (u) =
fU (u)du = u,
−∞
c 2017 Stanley Chan. All Rights Reserved.
16
for 0 ≤ u ≤ 1. If Y = FX (X), then the CDF of Y is
FY (y) = P[Y ≤ y] = P[FX (X) ≤ y]
= P[X ≤ FX−1 (y)]
= FX (FX−1 (y)) = y.
Therefore, we showed that the CDF of Y is the CDF of a uniform distribution. This
completes the proof.
The consequence of the theorem is the following procedure in generating random numbers:
• Step 1: Generate a random number U ∼ Uniform(0, 1).
• Step 2: Let Y = FX−1 (U ). Then the distribution of Y is FX .
Example. Suppose we want to draw random numbers from an exponential distribution.
Then, we can follow the above two steps as
• Step 1: Generate a random number U ∼ Uniform(0, 1).
• Step 2: Find FX−1 . Since X is exponential, we know that FX (x) = 1 − e−λx . This
gives the inverse FX−1 (x) = − λ1 log(1 − x). Therefore, by letting Y = FX−1 (U ), the
distribution of Y will be exponential.
c 2017 Stanley Chan. All Rights Reserved.
17