Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Describing Numbers
1 / 67
Describing Numbers
Paul E. Johnson1
2
1 Department
of Political Science
University of Kansas
2 Center
for Research Methods and Data Analysis, University of Kansas
2013
Describing Numbers
What is this Presentation?
A Brief summary of the idea “variable”
Ways to Describe Numeric Variables
Central Tendency: Mean, Median, Mode
Dispersion: Variance, Standard Deviation, etc.
Rescalings
2 / 67
Describing Numbers
3 / 67
Numeric Variables
Variable
Variable a collection of scores that represent observations.
Example:
height = {6.0, 5.1, 4.2, 5.8, 5.4}
(1)
Subscript heighti : height1 is observation 1, height2 is observation
2, and so forth
Describing Numbers
4 / 67
Numeric Variables
Common Notation
More abstractly
x = {x1 , x2 , x3, x4 , . . . , xN }
(2)
Or perhaps more succinctly
xi , for i ∈ {1, ..., N}
1
2
3
N: capital N refers to “sample size” or “number of
observations” (in most social sciences).
Usually, when I talk about xi , I mean to refer to any of the
individual observations in x.
Set notation
∈ means “element of,” as in i ∈ N or
x2 ∈ X = {x1 , x2 , . . . , xN }.
2 ∀ abbreviation of “for all”, so “for i ∈ N” might be ∀i ∈ N.
1
(3)
Describing Numbers
5 / 67
Numeric Variables
Numeric Variables
yi is the log of xi
From xi to 2 × xi : there is
twice as much of it
Analysis may be altered
(improved or damaged)
by transformations
1.0
0.5
yi
0.0
−0.5
−1.0
−1.5
The range from
{minimum, maximum} is
(subjectively) meaningful
1.5
NUMERIC variables:
accept mathematical
transformations
0
1
2
3
xi
4
5
6
log() magnifies the importance of a
step from 0.5 to 1 and shrinks the
importance of a step from 4 to 4.5.
Describing Numbers
6 / 67
Numeric Variables
Here’s your Mission
You found some scores (data)
Can your data for yourself
Tell/show other people about it
You need terminology: describe
Show a picture
Summarize with numbers.
Describing Numbers
7 / 67
Numeric Variables
Terminology to Describe Variables
Central Tendency: Where, “generally” are the scores? Is there
a “meaningful” (subjective) characterization of where “most”
scores are situated
Dispersion: How “spread out” are the scores? Is it not
meaningful to talk about a “typical” observation?
Shape of Distributions: Do the observations appear to be
Unimodal (one most-likely score, others less likely)
Symmetric or Skewed
Describing Numbers
8 / 67
Histograms
Histograms: Compare Two Variables
density
0.00
0.06
Lots of Low Scores
0
20
40
60
80
100
80
100
density
0.00 0.03 0.06
x
Lots of Big Scores
0
20
40
60
x
Describing Numbers
9 / 67
Histograms
Histograms: Compare Two Variables
density
0.00
0.15
These are all clumped up
0
20
40
60
80
100
80
100
x
density
0.000 0.015
These are all spread out
0
20
40
60
x
Describing Numbers
Histograms
Define ”Histogram”, Please
Group observations into “bins” of similar scores
Draw bars to represent the proportion of all scores that fall
into each bin
The areas of the bars should sum to 1.0
10 / 67
Describing Numbers
11 / 67
Histograms
Histograms: Check for Data Errors
0.002
But somebody put in 999
for “missing” data points
0.000
Suppose your data is
supposed to be human
age
density
0.004
0.006
0.008
Age data
0
200
400
600
age
800
1000
Describing Numbers
12 / 67
Histograms
Histograms: Check for Data Errors
0.025
density
0.015 0.020
0.010
0.005
Generally, whenever you
get new data from
anybody/anywhere, a
histogram is a good “first
check” on it.
0.000
If you ignore (remove) the
cases that are equal to
999 (or set them to NA)
0.030
0.035
Age data
0
20
40
60
age
80
100
Describing Numbers
13 / 67
Histograms
Various ”transformations” might be applied
Fox, Ch. 2 reviews various ways to re-scale data to make it
’fit’ some statistical tests
I’m cautious about fiddling with data
Some transformations are not “harmless”
Goal: Be honest with self & others about changes applied to
data, including
omission of missing or extreme observations
multiplicative re-scaling
nonlinear transformations (log, Box-Cox, etc.)
Describing Numbers
Histograms
Some Examples from the General Social Survey
/stat/DataSets/GSS/gss-subset2.Rda
14 / 67
Describing Numbers
15 / 67
Histograms
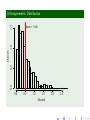
Histogram: Spot Typos/Unusual Scores
Density
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7
Male Sexual Partners (nummen)
Mean= 9.286
Std.Dev= 73.736
Median= 1
C.V.= 7.941
0
200
400
600
800
Number of Male Sexual Partners
1000
Describing Numbers
16 / 67
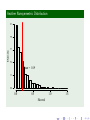
Histograms
Histogram: Eliminate values greater than 99
Density
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7
Male Sexual Partners (nummen)
Mean= 3.034
Std.Dev= 6.897
Median= 1
C.V.= 2.273
0
20
40
60
80
Number of Male Sexual Partners
100
Describing Numbers
Histograms
The Size of the Bins Can Make a Difference
Narrow bars have more detail, possibly less generalizability
(harder to see patterns)
Wide bars smooth out too many bumps, hide details
Many algorithms proposed to choose bin width to automate
production of “good” histograms.
17 / 67
Describing Numbers
18 / 67
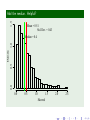
Histograms
Histogram: Fatter Bars!
Density
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7
Male Sexual Partners (nummen)
Mean= 3.034
Std.Dev= 6.897
Median= 1
C.V.= 2.273
0
20
40
60
80
Number of Male Sexual Partners
100
Describing Numbers
Histograms
A Smoothing Curve: Kernel Density Estimate (KDE)
Because of the (subjective) “bin width” problem, other density
estimation methods have been developed
The kernel density estimate is a “smoothing” method that
estimates the density at each value, putting more weight on
nearby observations than far away ones.
Some propose to replace histograms with KDE
19 / 67
Describing Numbers
20 / 67
Histograms
The Density Estimates
0.0
0.1
Density
0.2
0.3
0.4
The default plot of a density object
0
20
40
60
80
N = 2269 Bandwidth = 0.4296
100
Describing Numbers
21 / 67
Histograms
Histogram with Density Super-imposed
Density
0.2
0.3
0.4
0.5
Male Sexual Partners (nummen)
0.0
0.1
kernel density
estimate (green)
0
20
40
60
80
Number of Male Sexual Partners
100
Describing Numbers
Histograms
Histogram: More on Customizing Histograms
My lectures in guides/Rcourse (plot-1, plot-2) have plenty of
additional detail on beautifying plots.
22 / 67
Describing Numbers
23 / 67
Histograms
Histogram: with a ”legend”
0.5
Male Sexual Partners
0.0
0.1
Density
0.2
0.3
0.4
Histogram
Kernel Density
0
20
40
60
80
Number of Male Sexual Partners
100
Describing Numbers
Mean
Convey Same Info Without Graph?
What if your publisher will not allow you the space for a
histogram?
Convey same information without a picture?
Need to develop terminology to describe and compare what
we see.
24 / 67
Describing Numbers
25 / 67
Mean
Mean = Average
The mean is a widely-used indicator of a distribution’s central
tendency
Mean: (same meaning as “average”).
x̄ =
Sum Of All Scores
Number Of Scores
(4)
Suppose x is a variable. Add up the scores, then
divide by N.
PN
xi
x̄ = i=1
(5)
N
1
About Notation: x̄ is common notation, but not required.
Sometimes I write Mean(x) or µ̂, depending on the context.
0.020
0.025
A Histogram with 30 Bins
0.005
0.010
Density
Appears (to me)
unimodal (one
peak)
symmetric
(more or less)
Mean = 50.48
0.015
The sample mean is
50.485
0.000
I manufactured a
sample of pleasantly
symmetrical
random data
−20
0
20
40
60
A Beautiful Variable
80
100
120
Describing Numbers
27 / 67
Mean
You too can manufacture Normal samples
I used R’s rnorm function to draw some example observations
s e t . s e e d (1234321)
myx <− rnorm ( 1 0 0 0 , mean=50 , s d =20)
That creates 1000 observations from the Normal distribution,
N(50, 202 )
We specify 2 parameters
50 is the parameter mu (µ), the ”true mean”
20 is the parameter sigma (σ), which controls the ”dispersion”
of the scores.
”Gaussian distribution” another name for the Normal.
In case you wondered, the sample standard deviation is 19.977
0.025
0.020
Mean = 20.56
Density
0.010
0.005
0.000
0.000
0.005
0.010
Density
0.015
Mean = 50.48
0.015
0.020
0.025
Compare 2 variables
0
50
A Beautiful Variable
100
0
50
Another Variable
100
Describing Numbers
29 / 67
Dispersion
Variance
Variance: the average of squared deviations about the mean.
Calculate the difference between the i’th case and the mean:
xi − x̄
(6)
(xi − x̄)2
(7)
Square that:
Do the same for all and add them up:
N
X
(xi − x̄)2
(8)
i=1
Then divide by N.
PN
Var (x) =
i=1 (xi
N
− x̄)2
(9)
Describing Numbers
30 / 67
Dispersion
Standard Deviation
Standard Deviation: the square root of the variance.
s
Std.Dev .(x) =
q
PN
Var (x) =
i=1 (xi
N
− x̄)2
(10)
Var and Std.Dev. serve same purpose.
Std.Dev. has an advantage: it is measured (roughly speaking)
on the same scale as the mean. (see below on “scaling”)
Please don’t worry right now about the need to divide by
N − 1 instead of N. That distraction is not needed at this
stage.
0.035
0.030
0.030
0.035
Compare 2 variables
Mean = 40.45
0.025
0.025
Mean = 39.87
0.005
0.010
Density
0.015
0.020
Std. Dev. = 20.2
0.000
0.000
0.005
0.010
Density
0.015
0.020
Std. Dev. = 10.14
−20
0
20
40
60
Small Variance
80
100
−20
0
20
40
Big Variance
60
80
100
Describing Numbers
Dispersion
About Notation
1
Some traditional stats books call the observed variance s 2 and
the “true variance” (of which it is an estimate) σ 2 . Same
books say “True standard deviation” is σ and estimate is s.
2
c2 . I like that because I
Some books call estimated variance σ
don’t need separate letters σ and s.
3
Some books call the “true” variance Var (x) while an estimate
\
is Var
(x). I like that too, its easy to remember what’s what.
32 / 67
Describing Numbers
33 / 67
Dispersion
0.04
Socio Economic Status
Proportion
0.01
0.02
0.03
mean= 49.41
std.dev. = 19.6
0.00
kernel
density
estimate
0
20
40
60
Socio−economic Index
80
100
Describing Numbers
34 / 67
Dispersion
0.04
Socio Economic Status: Only Men
Proportion
0.02
0.03
mean= 49.54
std.dev. = 19.95
0.00
0.01
kernel
density
estimate
0
20
40
60
Socio−economic Index
80
100
Describing Numbers
35 / 67
Dispersion
0.04
Socio Economic Status: Women
Proportion
0.02
0.03
mean= 49.3
std.dev.= 19.31
0.00
0.01
kernel
density
estimate
0
20
40
60
Socio−economic Index
80
100
Describing Numbers
36 / 67
Dispersion
Other Diversity Indicators
Inter-Quartile range: group data by ordered quarters, and then
think of the range between 25 percentile and 75 percentile as
a diversity indicator.
Many possible diversity indicators, including
gini index (often used for income inequality)
the mean of absolute valued differences
PN
|x − x̄|
Mean Absolute Deviation = i=1
N
(11)
Describing Numbers
Symmetry & the Median
Symmetry Definition
A distribution is symmetric if the chance of observing a score
x̄ − c is the same as observing x̄ + c.
If a distribution is symmetric, then we have no trouble
conveying the idea of its ’location’.
The mean is in the middle!
37 / 67
1.5
A Nonsymmetric Distribution
0.0
0.5
Density
1.0
Mean = 0.48
0.0
0.5
1.0
1.5
Skewed
2.0
2.5
Density
2
3
4
5
Another Nonsymmetric Distribution
0
1
Mean = 0.19
0.0
0.5
1.0
Skewed
1.5
Describing Numbers
Symmetry & the Median
Median: Center Case
Median: The “center observation,” the number of observations
that are larger equals the number that is smaller.
Questions:
1
When do you think the mean and median are likely to be the
same?
2
Can you think of a situation in which the median may be more
meaningful than the mean?
40 / 67
1.5
Add the median. Helpful?
Mean = 0.51
Std. Dev. = 0.43
0.0
0.5
Density
1.0
Median = 0.4
0.0
0.5
1.0
1.5
Skewed
2.0
2.5
Another Nonsymmetric Distribution
4
Mean = 0.19
Density
2
3
Median = 0.14
0
1
Std. Dev. = 0.19
0.0
0.2
0.4
0.6
0.8
Skewed
1.0
1.2
Describing Numbers
43 / 67
Symmetry & the Median
When To Emphasize The Mode
If lots of observations are clumped up at one point, it is worth
noting!
Suppose I collected data like this:
X = {1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 50}
If almost all of the scores are “2”, we should tell the reader.
Describing Numbers
Symmetry & the Median
Note about Level of Measurement
Mean only useful if we have numerical data (silly to average
“low”, “medium”, “high”)
Median requires ordered data, either numerical or ordered
categorical
Problem with the mean: it is distorted by a change in one
value on either side (change one 50 to 5,000,000 and note the
mean changes)
Median is a more “robust” estimate (jargon: high ’breakdown
point’)
44 / 67
Describing Numbers
Re-Scaling
Should the Scale Matter?
The temperature in Celsius is 10. The temperature in
Farenheit is 50 (32+9/5*10).
My income in dollars is 68,000. My income in Euros is 43,000
and in Pesos it is 1,126,123.
Sometimes, we receive data in one format, but convert to
another
Simple scale conversions SHOULD NOT substantively change
the conclusions we will draw.
If simple scale conversions seem to matter, be VERY cautious.
45 / 67
Describing Numbers
46 / 67
Re-Scaling
The Mean Scales With The Data
Take variable X = {x1 , x2 , . . . , xN }, and multiply each value
by 10 to create newx
newx = {10x1 , 10x2 , . . . , 10xN }
(12)
The mean of newX is obviously 10 the mean of old x. See?
Mean(newX ) =
10x1 + 10x2 + . . . + 10xN
= 10
N
PN
i=1 xi
N
Mean(newX ) = newX = 10 × x̄
Generally (meaning always), the mean of (k × X ) is equal to
k times the mean of X .
Describing Numbers
47 / 67
Re-Scaling
My First Big Fact
State that as a theorem. k1 and k2 are any non-zero
constants. X is any variable. Create a new variable
newX = k1 + k2 X
The Mean scales proportionally. Given constants k1 , k2
Mean(k1 + k2 X ) = k1 + k2 × Mean(X )
(13)
The point: The Mean changes in a completely predictable way
when the data is re-scaled by addition and multiplication. Just
apply same same re-scaling to the old mean.
Describing Numbers
Re-Scaling
The Variance Doesn’t Scale Proportionally
Suppose variance of X is var (X )
Create newX by multiplying by 10, newX = 10 · X
The variance of newX is 102 Var (X )
48 / 67
Describing Numbers
49 / 67
Re-Scaling
General Result for Variance of Re-scaled Variables
Calculate the Variance of a re-scaled Variable, X. Given k1 , k2
Var (k1 + k2 · X ) = k22 · Var (X )
(14)
Adding k1 does not change the dispersion at all, it just shifts
the scores.
The variance of newX = k1 + k2 X is k22 × Var (x)
Describing Numbers
50 / 67
Re-Scaling
Implication: Don’t re-calculate mean and variance if x is
proportionally re-scaled.
Celsius temperature data, x. Suppose the mean is, 100.
Rescale that data to Fahrenheit
9
xFi = 32 + xi
5
(15)
Some students want to re-run xFi through the mean function,
but they don’t need to.
The mean of xF is
32 + (9/5)Mean(x) = 32 + (9/5)100 = 212.
Describing Numbers
51 / 67
Re-Scaling
But the Standard Deviation Scales Proportionally!
The variance of xF is (9/5)2 × Var (x), which is NOT linear
However, recall standard deviation is
standard deviation would be
Std.Dev .(xF ) =
q
p
Var (x), so the
(9/5)2 × Var (x) = (9/5) × Std.Dev .(x)
(16)
Like the mean, the standard deviation scales proportionally.
Standard Deviation of kX is k × Std.Dev .(X )
Std.Dev (k · X ) = k · Std.Dev (X )
(17)
Describing Numbers
52 / 67
Re-Scaling
The ratio Std.Dev /Mean is Also Scale Invariant
Recall Mean(k · x) = kMean(x)
And Std.Dev .(k · x) = kStd.Dev .(x)
Then the ratio of the mean to the standard deviation is not
affected by k
Mean(k · x)
k · Mean(x)
Mean(x)
=
=
Std.Dev .(k · x)
k · Std.Dev .(x)
Std.Dev .(x)
(18)
And the converse is also true
k · Std.Dev (x)
Std.Dev (x)
=
k · Mean(x)
Mean(x)
(19)
Describing Numbers
Re-Scaling
Coefficient of Variation is Std.Dev(x)/M(x)
Coefficient of variation, CV.
Question: is “this distribution” more “spread out” than “that one”?
This is a difficult, possibly silly question when distributions are
fundamentally different
But, if they have roughly the same “shape”, then the re-scaling
might make them comparable.
53 / 67
Describing Numbers
54 / 67
Re-Scaling
Compare dispersion of 2 disparate variables
density
0.000 0.010
Mean= 202.84 SD= 33.08
0
100
200
x
300
400
density
0.00
0.03
Mean= 48.32 SD= 10.4
0
100
200
x
300
400
Describing Numbers
55 / 67
Re-Scaling
Compare 2: plot x/Mean(x)
density
0.0 1.5 3.0
Hist of x1/Mean(x1)
0.0
0.5
1.0
1.5
x
2.0
2.5
3.0
2.5
3.0
density
0.0
1.0
2.0
Hist of x2/Mean(x2)
0.0
0.5
1.0
1.5
x
2.0
Describing Numbers
56 / 67
Re-Scaling
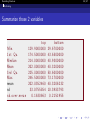
Summarize those 2 variables
Min.
1 s t Qu.
Median
Mean
3 r d Qu.
Max.
mean
sd
sd.over.mean
top
129 . 9 0 0 0 0 0 0
174 . 5 0 0 0 0 0 0
214 . 0 0 0 0 0 0 0
202 . 8 0 0 0 0 0 0
225 . 8 0 0 0 0 0 0
246 . 5 0 0 0 0 0 0
202 . 8 3 5 2 4 6 0
33 . 0 7 5 5 8 5 4
0 .1630663
bottom
29 . 6 7 0 0 0 0 0
43 . 6 8 0 0 0 0 0
48 . 9 3 0 0 0 0 0
48 . 3 2 0 0 0 0 0
50 . 6 0 0 0 0 0 0
73 . 1 7 0 0 0 0 0
48 . 3 2 0 6 2 3 2
10 . 3 9 8 3 7 9 3
0 .2151955
Describing Numbers
57 / 67
Special Re-Scalings
Mean-center xi
Mean centered data (aka “data in deviations form”)
Mean Centered(xi ) = xi − Mean(xi )
Do we need abbreviation for that? xiMC or xei or ?
The mean of a centered variable is always 0
The variance and standard deviation are unchanged by
centering
Sometimes mean-centered data is used to faciliate
interpretation of results in some models.
(20)
Describing Numbers
Special Re-Scalings
Standardized Data: special name for
Mean Centered(xi )/Std.Dev (x)
Standardized Variables.
Standardize means “divide Mean Centered(xi ) by standard
deviation”.
xi − x̄
(21)
σx
Since M(x)/Std.Dev (x) is scale invariant, it makes
Mean Centered(xi )/Std.Dev (x) will also be unaffected by
re-scaling of the observations.
The letter “Z” is often used to refer to standardized variables.
58 / 67
Describing Numbers
59 / 67
Special Re-Scalings
Standardized implies Mean 0, Std.Dev 1
Mean of Z = Z̄ = 0
Std.Dev .(Z ) = SD(Z ) = 1
It is strictly a matter of convention to standardize variables.
Standardization may allow comparison of distributions, but it
may not (more advanced problem I’m not willing to go into)
Describing Numbers
60 / 67
Special Re-Scalings
The log is the most commonly applied nonlinear
transformation
0.1
Examples, income,
education
0.0
We often gather data that
is “clumped” on the left
density
0.2
0.3
x is skewed
0
5
10
x
15
20
Describing Numbers
61 / 67
Special Re-Scalings
The log is the most commonly applied nonlinear
transformation
0.1
0.0
The distribution of log(x)
appears more symmetric
density
0.2
0.3
0.4
x is not so skewed
−3
−2
−1
0
log of x
1
2
3
Describing Numbers
62 / 67
Special Re-Scalings
Difficult to say for sure if logging a variable is good or bad
Some methods books will recommend logging all variables,
claiming that it almost always makes analysis “work better” in
some sense.
Please just remember it is a possibilty
Describing Numbers
63 / 67
Special Re-Scalings
R functions to remember
x is a variable
mean(x, na.rm = TRUE)
summary(x)
sd(x, na.rm = TRUE)
rockchalk::summarize(x)
var(x, na.rm = TRUE)
hist(x, prob = TRUE)
median(x, na.rm = TRUE)
xdens <- density(x)
range(x, na.rm = TRUE)
lines(xdens)
quantile(x, na.rm = TRUE)
plot(xdens)
Describing Numbers
64 / 67
Practice Problems
Problems
1
Better run hist a few times. If you have R handy, try this
x1 <− rnorm ( 1 0 0 , m=20 , s =10)
h i s t ( x1 , p r o b = TRUE, main =
d e v i a t i o n o f 10 ”)
den1 <− d e n s i t y ( x1 )
l i n e s ( den1 , c o l = ”r e d ” , l t y
p l o t ( den1 )
x2 <− x1
x2 [ 9 8 : 1 0 0 ] <− 999
h i s t ( x2 , p r o b = TRUE, main =
d e v i a t i o n o f 10 ”)
den2 <− d e n s i t y ( x2 )
l i n e s ( den2 , c o l = ”r e d ” , l t y
p l o t ( den2 )
2
”mean o f 2 0 , s t a n d a r d
= 4)
”mean o f 2 0 , s t a n d a r d
= 4)
There are some weird arguments you can use with hist. Try this.
1
Change prob = TRUE to prob = FALSE.
Describing Numbers
Practice Problems
Problems ...
Change the number of bins by setting breaks = 40 or breaks =
4.
3 Fiddle with the appearance by adjusting ylim = c(0, 1) or ylim
= c(0.2, 0.8).
2
3
Now make some weird looking data and do the same. This will
create 300 funny looking observations in variable x, I’m pretty sure:
x1 <− rnorm ( 1 0 0 , m=30 , s =10)
x2 <− r p o i s ( 1 0 0 , lambda =1)
x3 <− rnorm ( 1 0 0 , m=80 , s =20)
x <− c ( x1 , x2 , x3 )
use the functions “mean”, “var” and “sd” on each one of those.
Make a histogram for each.
3 It may be beyond your R skills now to insert labels for the
mean or standard deviation, but you could pencil them in if
you had paper.
1
2
65 / 67
Describing Numbers
66 / 67
Practice Problems
Problems ...
4
Try this. It draws a fresh set of data
x1 <− rnorm ( 1 0 0 , m = 3 0 , s = 1 0 )
x2 <− r p o i s ( 1 0 0 , lambda = 1 )
x3 <− rnorm ( 1 0 0 , m = 8 0 , s = 2 0 )
d a t <− d a t a . f r a m e ( x1 , x2 , x3 )
rm ( x1 , x2 , x3 )
l i b r a r y ( rockchalk )
summarize ( dat )
s a p p l y ( dat , mean )
var ( dat )
5
Missing data is a sad fact of life.
1
Insert some missings (by setting cases to NA). Note how I keep
it interesting by changing idioms for access to rows and
columns.
d a t $ x1 [ c ( 1 , 2 , 5 5 ) ] <− NA
d a t [ c ( 5 6 , 9 9 ) , 2 ] <− NA
Describing Numbers
67 / 67
Practice Problems
Problems ...
2
3
Try to collect statistics about that data.
Understand why we need to rewrite the use of the mean
function to tolerate NA?
mean ( d a t $ x1 )
mean ( d a t $ x1 , n a . r m = TRUE)
s a p p l y ( dat , mean , n a . r m = TRUE)