Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Entity–attribute–value model wikipedia , lookup
Open Database Connectivity wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Concurrency control wikipedia , lookup
Functional Database Model wikipedia , lookup
Relational model wikipedia , lookup
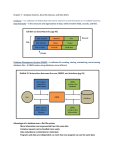
CSC 485E/SENG 480D/CSC 571 Advanced Databases Introduction DB and DBMS • Database (DB): a collection of information that exists over a long period of time. • Database Management System (DBMS): a complex software for handling • Large data efficiently and safely. DBMS 1. Allows users to create new databases and specify their schema, using a data-definition language. 2. Enables users to query and modify the data, using a query and datamanipulation language. 3. Supports intelligent storage of very large amounts of data. – Protects data from accident or not proper use. Example: We can require from the DBMS to not allow the insertion of two different people with the same SIN. – Allows efficient access to the data for queries and modifications. Example: Indexes over specified fields 4. Controls access to data from many users at once (concurrency), without allowing “bad” interactions that can corrupt the data accidentally. 5. Recovers from software failures and crashes. Database Studies • Design of databases. – What kinds of information go into the database? – How is the information structured? – How do data items connect? • Database programming. – How does one express queries on the database? – How is database programming combined with conventional programming? • Database system implementation. We’ll focus on this part – How does one build a DBMS, including such matters as query processing, transaction processing and organizing storage for efficient access? Fictitious Megatron DBMS • Stores relations as Unix files • Students(name, sid, dept) is stored in the file /home/megatron/students as Smith#123#CS Jones#533#EE • Schemas are stored in /home/megatron/schemas e.g. Students#name#STR#id#INT#dept#STR Depts#name#STR#office#str Megatron sample session mayne$ megatron WELCOME TO MEGATRON 2006 megaSQL% SELECT * FROM Students; Name id dept ------------------------------------Smith 123 CSC Johnson 522 ECE megaSQL% Megatron sample session II megaSQL% SELECT * FROM Students WHERE id >= 500; Johnson#522#EE megaSQL% quit THANK YOU FOR USING MEGATRON 2006 mayne$ Megatron Implementation • To execute SELECT * FROM R WHERE <COND> • Read file schema to get attributes of R • Check that the <COND> is semantically valid for R • Read file R, – for each line • check condition • if OK, display What’s wrong with Megatron? • Tuple layout on disk: no flexibility for DB modifications. – Change CSC to ECON and the entire file has to be rewritten. • Search Expensive: no indexes; always read entire relation. • Bruteforce query processing. • No buffer manager: everything comes off of disk all the time. • No concurrency control: several users can modify a file at the same time with unpredictable results. • No reliability: can lose data in a crash or leave operations half done. Architecture of a DBMS • The “cylindrical” component contains not only data, but also metadata, i.e. info about the structure of data. • If DBMS is relational, metadata includes: – names of relations, – names of attributes of those relations, and – data types for those attributes (e.g., integer or character string). • A database also maintains indexes for the data. – Indexes are part of the stored data. – Description of which attributes have indexes is part of the metadata. What will be covered 1. Secondary Storage Management a) Disks Mechanics b) Disk Computation Model c) Handling disk failures 2. Index Structures 1. 2. B-Trees, Extensible Hash Tables, etc. Multidimensional Indexes (for GIS and OLAP) 3. Query Execution a) Algorithms for relational operators b) Join methods. 4. Query Compiler a) Algebraic laws for improving query plans. b) Cost based plan selection c) Join orders What will be covered 5. Parallel and Distributed Databases a) b) c) d) e) Parallel algorithms on relations Distributed query processing Distributed transactions Google’s Map-Reduce framework Peer-to-peer distributed search 6. Data Mining a) Frequent-Itemset Mining b) Finding similar items c) Clustering of large-scale data 7. Databases and the Internet a) b) c) d) Search engines PageRank Data streams Data mining of streams