Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
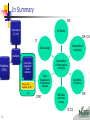
Analytics and OR DP- summary Descriptive (IT, CS) Analytics Predictive (STAT) Theory and methods of OR Prescriptive (Application of OR methods) OR 2 Thinking like an OR Analyst Linear or non-linear Dynamic or Static Probabilistic or Deterministic Problem Definition Decision making in optimization One time decision or sequential decisions Objective • Availability • Type (Static, dynamic (frequency of collection), discrete, continuous) • Size (Big Data) • What is the objective of making the decision(s) (Value Modeling can be used here) Big Data Model 3 • Computational complexity • Verification • Validation • Implementation • Known, unknown (Learning) • Which OR tool is appropriate Solution Strategy The Big Picture Operations Research (Math prog) Static decisions (One-time decision) Dynamic decisions (sequential decision) Linear Programming Integer Programming 4 Optimal control Continuous time Dynamic programming Discrete time Deterministic DP Non-linear Programming Finite Horizon problems Mixed Integer Programming Infinite Horizon problems Metaheuristics Decisions taken over time as the system evolves Stochastic DP Finite Horizon problems Large-scale problems Infinite Horizon problems Approximate Dynamic programming ODE Approach Dynamic programming What is it? Operates by finding the shortest path (minimize cost) or longest path (maximize reward) of decision making problems that are solved over time 5 Myopic vs DP thinking - find shortest path from A to B Cij=10 Cij= cost on the arc 1 40 A B 20 2 10 Myopic policy: V(A)= min (Cij) = min of (10 or 20) leads to solution of 50 from A to 1 to B DP policy: V(A) = min (Cij + V(next node)) = min (10 + 40, 20+10) = 30 leads to solution of 30 from A to 2 to B Key is to find the values of node 1 and 2 How? By learning via simulation-based optimization 6 Dynamic Programming!! for Sequential Decision Making (over time) Is based on the idea that We want to move from one good state of the system to another by making an near-optimal decision in the presence of uncertainty It also means that the future state depends only on the current and the decision taken in the presence of uncertainly (and not on the past – memory-less property) The above is achieved via unsupervised learning that entails only an interaction with the environment in a model-free setting 7 Simulation-based Optimization In more complex problems such as helicopter control the Optimizer is an Artificial Intelligence (Learning) Agent Environment (uncertainty) System simulator built using probability distributions from real-world data Decisions Dynamic Programming Optimizer (learning agent) 8 Output (Objective function) In Summary OR Descriptive (IT, CS) OR Models OR, CS IT Computational complexity Data storage Analytics Predictive (STAT) Optimization in Prescriptive Analytics Prescriptive (Application of OR methods) Theory and methods of OR Data Visualization & Statistical analysis OR STAT Algorithms for solving OR BIG Data and data mining IT, CS 9 In Summary – Main take away In Big Data decision making Problems (Prescriptive Analytics) Understand characteristics of the data, linear/non-linear, deterministic or probabilistic, static or dynamic (frequency of collection) Beware of 1. Myopic policies 2. Exhaustive enumeration of all solutions 3. Computational Complexity Look for appropriate modeling and solution strategies that can provide near-optimal decisions (good-enough) In the long run for the problem at hand. 10 For this course - Main take away Value function V is cumulative When making a decision sequentially over time (dynamic programming), make sure to sum the cost/reward of making the decision with the value of the estimated future state that the decision will take you to. Then pick a decision that minimizes (if cost) or maximizes (if reward) the above sum. DP can handle -non-linear -probabilistic -Computationally hard (high dimensionality and large state space) -dynamic (sequential) and high frequency of decision making -unknown models -Big data problems In this course we solve optimally 11 In OR 774 and in real world we strive of near-optimal (good enough) solutions Thank You 12