Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Text Document
Categorization by Term
Association
Maria-luiza Antonie
Osmar R. Zaiane
University of Alberta, Canada
2002 IEEE International Conference on Data Mining (ICDM’02)
Presentation by Yu-Kai Lin
Outline
Introduction
Related work
Building an Associative Text Classifier
Experimental Results
Conclusion
Introduction
Text categorization is a necessity due
to the very large amount of text
documents that we have to deal with
daily.
A text categorization system can be
used in indexing documents to assist
information retrieval tasks as well as in
classifying e-mails, memos or web
pages in a yahoo-like manner.
Introduction (cont.)
The data classification process :
(a) Learning : Training data are analyzed
by a classification algorithm. (Figure 1)
(b) classification : Test data are used to
estimated in the form of classification
rules. (Figure 2)
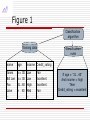
Figure 1
Classification
algorithm
Training data
name
age
income Credit_rating
Jones
Bill Lee
Fox
Lake
…
<= 30
<= 30
31..40
> 40
…
Low
Low
High
Med
…
Fair
Excellent
Excellent
Fair
…
Classification
rules
If age = “31…40”
And income = high
Then
Credit_rating = excellent
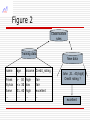
Figure 2
Classification
rules
Training data
name
age
income Credit_rating
Frank
Sylvia
Anne
…
> 30
<= 30
31..40
…
high
low
high
…
fair
fair
excellent
…
New data
( John ,31…40,high)
Credit rating ?
excellent
Related Work
Text classifier
Association Rule Mining
Related Work (cont.)
Text classifier
Naïve Bayesian classifier (chapter 7.4)
ID3 (Decision tree chapter 7.3)
C4.5 ( chapter 7.6)
K-NN (chapter 7.7.1)
Neural Networks
Support Vector Machines (SVM)
Related Work (cont.)
Association Rule Mining
Association Rules Generation
Associative classifiers
Related Work (cont.)
Association Rules Generation
“X=>Y”
support s
confidence c
strong rules:
rules that have a support and confidence
greater than given thresholds
Related Work (cont.)
Associative classifiers
Learning method is represented by the
association rule mining
Discover strong patterns that are
associated with the class labels
New object are categorized by these
patterns (classifier)
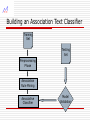
Building an Association Text Classifier
Training
Set
Testing
Set
Preprocessing
Phase
Association
Rule Mining
Associative
Classifier
Model
Validation
Building an Association Text
Classifier (cont.)
Data collection Preprocessing
Association Rules Generation
Pruning the Set of Association Rules
Prediction of Classes Associated with
New Documents
Building an Association Text
Classifier (cont.)
Data collection Preprocessing
Weed out not interesting words
stopwording
stemming
Transform documents into transactions
categories set C = {c1, c2, … , cm}
term set T = {t1, t2, … , tn}
document Di = {cc1, cc2, … , ccm, tt1, tt2, … ,
ttn}
Building an Association Text
Classifier (cont.)
Association Rules Generation
Apriori
Advantage
The performance studies show its efficiency
and scalability
Drawback of using on our transactions
Generate a large number of associations rules
Most of them are irrelevant for classification
ARC-BC
Association Rule-based Categorizer By
Category algorithm
Apriori-based
Interested in rules that indicate a category label
(T => ci ): Strong rules
Prune the rules that no use for categorization
ARC-BC Algorithm
ARC-BC Algorithm
ARC-BC
category 1
association rules
for category 1
category i
association rules
for category i
category n
association rules
for category n
classifier
put the new
documents in the
correct class
Examples of association rules
composing the classifier
Building an Association Text
Classifier (cont.)
Pruning the Set of Association Rules
The number of rules that can be generated in
the association rule mining phase could be very
large
Noisy information mislead the classification
process
Make classification time longer
Pruning method
Eliminate the specific rules and keep only those
that are more general and with high confidence
Prune unnecessary rules by database coverage
Building an Association Text
Classifier (cont.)
Pruning the Set of Association Rules
definition
Pruning the Set of Association
Rules Algorithm
Building an Association Text
Classifier (cont.)
Prediction of Classes Associated with New
Documents
Algorithm
Experimental results
9,603 training
documents and
3,299 testing
documents
Conclusion
Its effectiveness is comparable to
most well-known text classifiers
Relatively fast training time
Rules generated are understandable
and can be easily manually updated
When retraining a new document, only
the concerned categories are adjusted
and the rules could be incrementally
updated