Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Standard solar model wikipedia , lookup
Accretion disk wikipedia , lookup
Cosmic distance ladder wikipedia , lookup
Planetary nebula wikipedia , lookup
Main sequence wikipedia , lookup
Stellar evolution wikipedia , lookup
Astronomical spectroscopy wikipedia , lookup
High-velocity cloud wikipedia , lookup
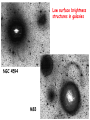
Stellar Cosmology and Virtual Observatory Joss Bland-Hawthorn Anglo-Australian Observatory CDM is a successful but incomplete prescription which breaks down in the non-linear regime. Present effort is to insert complex physics which will always need to be validated by observation. 2005-2015: multi-million stellar surveys at moderate to high resolution — these will require a radically new approach to data analysis. Ho = 68 disk halo Goals of near-field cosmology To tag or associate individual stars with parts of the protocloud. Dynamically this is impossible in general although some integrals of the motion may be preserved, others will be scrambled by dissipation, torques, violent relaxation, scattering. Kinematic tagging is proven for unravelling halo Chemical tagging is essential to unravelling disk, i.e. only way to unravel dissipation Analogy to CMB and problem of seeing beyond the surface of last scattering. For the disk, we can only recover dynamical properties back to the epoch of last dissipation or last scattering. Near-field cosmology: future surveys UKST Echidna = Ukidna: up to 50 million stars at R=10,000 Gemini Wide-Field = KAOS: up to 1 million stars at R=20-40,000 GAIA: up to 300 million stars at R=10,000 sphere 10 as = 10% distances at 10 kpc 10 as/yr = 1 km/sec at 20 kpc Comprehensive inventory of surviving inhomogeneities requires vast catalog of stellar properties - kinematics, ages, abundances - that is now out of reach In the next decade, we expect GAIA to give phase space data for about a billion stars within 10 kpc (the Gaiasphere). Comparable samples of stellar ages and abundances can be contemplated with multi-object high resolution spectrometers on large telescopes technically possible. Detail will be important - a small example of what we might expect is the discovery of the Sgr dwarf from a survey of stellar velocities in the galactic bulge: Sgr was discovered only as a velocity inhomogeneity Sgr dwarf L ~ 108 Lo Ibata, Irwin & Gilmore 1995 ff M31 Ibata et al. (2001) L < 108 Lo Zaritsky & Rix (1997) from m=1 photometry conclude rate of infall is 0.07 - 0.25 dwarf mass / Ga Shang et al (1998) Low surface brightness structures in galaxies NGC 4594 M83 Tidal Streams in the Galactic Halo (simulation of accretion of 100 satellite galaxies) x (kpc) RGC (kpc) The Spaghetti Survey (Morrison et al) Washington system; halo stars out to 100 kpc over 100 deg2 Chemical Tagging All galactic components show abundance dispersion The goal of tagging is to associate stars with elements of the protocloud. May be possible kinematically with some stars of halo and thick disk. For the thin disk, much information was lost by dissipation and dynamical evolution, so kinematical tagging can only be partly successful. Consider chemical tagging: see a large dispersion in element ratios for (neutron capture elements)/Fe in stars of lower metallicity. ° Some elements show up to ~ 3 dex dispersion (Sr, Ba, Eu) Light s Heavy s r Scatter in element ratios at lower [Fe/H] elements have less scatter; Mg,Ti,Al not rigidly coupled to Si,Ca Wallerstein et al 1997 Previous record: CD -38 245 [Fe/H] = -4.0 Now shattered: HE0107 [Fe/H] = -5.3 1 TDO 0 [Fe/H] -1 B TDG -2 YHG -3 OHG 0 7 Age (Gyr) 14 Signatures of Galaxy Formation We seek signatures or fossils from the epoch of Galaxy formation, to give insight into processes that took place as the Galaxy formed. These signatures survived the loss of information that occurred during galaxy formation Long-term goal: chemical clustering in chemical abundance space, Z Short-term goal: chemical trajectories in chemical abundance space, Z Long term goal: reconstructing ancient star clusters Ideally, what we would like to know is a time and a place for the birth of all stars. A starting point is to attempt to reconstruct ancient star clusters from their abundances... Primary requirements: almost all stars born in large clusters certain elements must reflect progenitor cloud abundances, i.e. immune to stellar evol. most stars within a cluster must share identical abundances in a set of elements ? some elements must not be rigidly coupled ? How many distinct enrichment sites might there have been for the thick disk ? • dissipative collapse – 1010 Mo protocloud; Larson 1976; Jones & Wyse 1983 • gradual heating – 109 Mo protoclouds; Noguchi 1998 • rapid heating – “conventional” disk of 103 Mo star clusters heated by merger – 106 Mo star clusters; Kroupa 2002 – 106 Mo protoGCs; Jehin et al 1999 • merger scenarios (e.g. a few infalling systems) – Quinn et al 93; Huang & Carlberg 1997; Sellwood et al 1998 – new 2dF observations (Gilmore, Wyse & Norris 2002) show evidence of a minor merger event Establishing millions of independent chemical signatures may appear out of reach However ... more than 60 of the elements arise from neutron capture processes. Say only 30 of these elements were detectable and we could measure only two distinct abundance levels for each. That would already give more than 109 independent cells in the chemical abundance space (if many of the element abundances are found not to be independent, then the number of independent cells is reduced) Short term goal: Chemical trajectories Z( Fe/H, 1/Fe, 2/Fe, s/Fe, r1/Fe, r2/Fe, ... ) Each generation of SN gives stellar population with progressive enrichment. Stars lie along a trajectory in an n-dimensional space, where we are looking at n elements including isotopes. Trajectories affected by basic processes like star formation efficiency and timescale, mixing efficiency and its timescale and lengthscale, infall rate ... As [Fe/H] –> 0, trajectories converge and power of method is reduced. The chemical n-space will contain a lot of information on the chemical evolution history. May be able to detect evolution of the cluster mass function, and epochs of satellite infall and star-bursts. Chemical tagging Z( Fe/H, 1/Fe, 2/Fe, s/Fe, r1/Fe, r2/Fe, ... ) • Need 10 elements measurable to 0.1 dex or better (which do not vary in lock-step) at R~20,000 to V=16,18,20 • Relative abundance accuracy at R~25,000, SNR~100, [Fe/H] to <0.05 dex (Edvardsson), 0.02 dex (Jehin) • This may greatly improve with 3D atmospheric models, huge database, self calibration! Challenge 1: to achieve 0.1 dex for , r elements Challenge 2: to find 600A window of 3-6 lines per element A new era of precision measurement Self calibration via huge stellar surveys: more stars finer cells better differential abundances Log (g/go) log(L/Lo) + log(M/Mo) + 4 log(T/To) Missing dimensions: microturbulence, hyperfine splitting... GAIA window 8400-8800A Many Fe lines, elements If we go after this window, the same grating could pass 4200-4400A in higher order — expensive option! Many r, s elements Note: you could certainly invent a `genesis machine’, but probably need dual beam R ~ 40,000 at U,B and R ~ 20,000 in red [Fe/H] = -0.5 Important (, r) windows 5490: MgI(1), SiI(3), CaI(4), ScII(1), TiI(2), TiII(2), FeI(18), FeII(2), YII(1), NdII(3), MnI(5) 6270: OI(1), NaI(2), CaI(5), ScII(1), TiI(4), VI(9), CrI(2), FeI(20), FeII(2), NiI(4), YII(1), LaII(2), CeII(1) 6520: CaI(7), ScII(1), TiI(3), TiII(3), VI(2), FeI(19), FeII(4), NiI(3), YI(1), BaII(1), LaII(1) 6780: LiI(1), AlI(2), CaI(1), TiI(1), TiII(1), VI(1), FeI(9), NiI(4), YII(2), LaII(1), NdII(1), Eu(1) All windows 200A wide, R=20,000, optimally 3-6 lines per element Powerful methods required to: Find clustering in abundance space, Z Find trajectories in abundance space, Z Extract information from echelle data, I() Compare to stellar atmospheric models, S Starting point: Consider spectrum I() as 1-D array of intensities in 2048 contiguous energy bins coordinate in 2048-D data space Conventional PCA such that var(Y1) var(Y2) var(Y3) … li12 + li22 + … + lip2 = 1, all i cov(Yi, Yj,) = 0, i j Principal Components Analysis PCA in a curvilinear space orthogonal orthonormal (i.e. orthogonality in a curved geometry) biT bj = 1 (i = j) biT bj = 0 (i j) biT C bj = 1 (i = j) biT C bj = 0 (i j) C = covariance matrix (cf. metric tensor in GR) Need differential form to emphasize weak features... VO must provide tools for n-space analysis • Will be of general use to any waveband or comparison of wavebands, or data set cf. to numerical model, etc. • These codes will need to be parallelized for CPU clusters Epilogue Understanding galaxy formation is mainly about understanding baryon dissipation within CDM - this means understanding the formation of disks. Can this ever be unravelled, kinematically or chemically ? Much information has been lost. We should look for the preserved signatures In the near field, we have the advantage that individual stars can be investigated in detail Maybe one day, we can identify the Solar Family, i.e. all stars born with the Sun