Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
CS 9633 Machine Learning
Support Vector Machines
References:
Cristianini, N. and B. Scholkopf, Support Vector Machines and Kernel
Methods: A New Generation of Learning Machines, AI Magazine, Fall
2002.
Haykin, S. Neural Networks: A Comprehensive Foundation, 2nd Edition, 1999,
Prentice-Hall.
Muller, K.R., S. Mika, G. Ratsch, K. Tsuda, B. Scholkopf, “An introduction to
kernel-based learning algorithms,” IEEE Transactions on Neural Networks,
12(2), March 2001, pp. 181-2001.
Burges, J. C. “A tutorial on support vector machines for pattern recognition,”
Data Mining and Knowledge Discovery, 2(2), 121-167, 1998.
Unique Features of SVM’s
and Kernel Methods
• Are explicitly based on a theoretical model of
learning
• Come with theoretical guarantees about their
performance
• Have a modular design that allows one to
separately implement and design their
components
• Are not affected by local minima
• Do not suffer from the curse of dimensionality
SVMs: A New
Generation of Learning
Algorithms
• Pre 1980:
– Almost all learning methods learned linear decision surfaces.
– Linear learning methods have nice theoretical properties
• 1980’s
– Decision trees and NNs allowed efficient learning of
non-linear decision surfaces
– Little theoretical basis and all suffer from local minima
• 1990’s
– Efficient learning algorithms for non-linear functions
based on computational learning theory developed
– Nice theoretical properties.
Key Ideas
• Two independent developments within
last decade
– Computational learning theory
– New efficient representations of non-linear
functions that use “kernel functions”
• The resulting learning algorithm is an
optimization algorithm rather than a
greedy search.
Statistical Learning
Theory
• Systems can be mathematically described as
a system that
– Receives data (observations) as input and
– Outputs a function that can be used to predict
some features of future data.
• Statistical learning theory models this as a
function estimation problem
• Generalization Performance (accuracy in
labeling test data) is measured
Organization
• Basic idea of support vector machines
– Optimal hyperplane for linearly separable
patterns
– Extend to patterns that are not linearly
separable
• SVM algorithm for pattern recognition
Optimal Hyperplane for
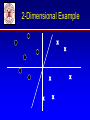
Linearly Separable Patterns
• Set of n training examples (xi,di) where xi is
the feature vector and di is the target output.
Let di = +1 for positive examples and di = -1
for negative examples.
• Assume that the the patterns are linearly
separable.
• Patterns can be separated by a hyper plane
2-Dimensional Example
X
X
X
X
X
X
Defining the Hyper Plane
• Form of equation defining the decision
surface separating the classes is a hyper
plane of the form:
wTx + b = 0
– w is a weight vector
– x is input vector
– b is bias
• Allows us to write
wTx + b 0 for di = +1
wTx + b < 0 for di = -1
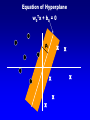
Some definitions
• Margin of Separation (): the
separation between the hyper plane and
the closest data point for a given weight
vector w and bias b.
• Optimal Hyper plane (maximal margin):
the particular hyper plane for which the
margin of separation is maximized.
Equation of Hyperplane
w0Tx + b0 = 0
0
X
X
X
X
X
X
Support Vectors: Input vectors for which
w0 T x + b 0 = 1
or
w0Tx + b0 = -1
0
X
X
X
X
X
X
Support Vectors
• Support vectors are the data points that lie
closest to the decision surface
• They are the most difficult to classify
• They have direct bearing on the optimum
location of the decision surface
• We can show that the optimal hyperplane
stems from the function class with the lowest
capacity (VC dimension).
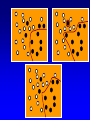
SVM Approach
• Map data into a dot product space using a non-linear
mapping function
• Perform maximal margin algorithm
(x)
(x)
o x
(o)
x
o
(x)
x
(x)
o
(o)
x
(x)
o o x
(o)
(o) (x)
x
(o)
(x)
x
(o)
o
(o)
X
F
Importance of VC
dimension
• The VC dimension is a purely combinatorial
concept (not related to dimension)
• Number of examples needed to learn a class
of interest reliably is proportional to the VC
dimension of the class
• A larger VC dimension implies that it requires
a more complex machine to reliably learn an
accurate function.
Structural Risk
Minimization
• Let be a set of parameters of a learning machine
(for example, in a neural network, it would be the set
of weights and bias.)
• Let h be the VC dimension (capacity) of a learning
machine.
• Consider an ensemble of pattern classifiers {F(x,)}
with respect to input space X.
• For a number of training examples N > h and
simultaneously for all classification functions F(x,),
the generalization error on the test data is lower than
a “guaranteed” risk with probability with probability 1 .
• We will use the term “risk bound” instead of
“guaranteed risk”.
Risk Bound
• The “empirical risk” is just the
measured error rate on the training
data.
• The “loss” is the term:
• One commonly used definition of the
“risk bound” is:
1
Remp ( )
2N
N
y
i 1
i
f (x i , )
1
yi f ( x i , )
2
h(log( 2 N / h) 1) log( / 4)
R( ) Remp ( )
N
where
N is the number of examples
h is the VC dimension
is the probability
And the second term on the rhs is
called the VC confidence
Implications of Bound
• Properties of Bound
– Independent of probability distribution of data
(assumed training and test data from same
distribution).
– Not usually possible to compute the actual risk
R()
– If we know h, we can easily compute the right
hand side.
• Implies that if we have several different
learning machines (families of functions) we
want to select the machine that minimizes the
rhs
Risk
Bound
Error
VC
Confidence
Training
error
VC dimension, h
Method of Structural Risk
Minimization
• Training error for each pattern classifier
is minimized
• The pattern classifier with the smallest
risk bound is identified. This classifier
provides the best compromise between
the training error and the complexity of
the approximating function
Structural Risk Minimization
• SRM finds the subset of functions that
minimizes the bound on the actual risk
h4
h3
h2
h1
h1 < h2 < h3 < h4
Steps in SRM
• Train a series of machines, one for each
subset where for each given subset the
goal of training is to minimize the
empirical risk
• Select that trained machine in the series
whose sum of empirical risk and VC
confidence is minimal
Support Vectors again for
linearly separable case
• Support vectors are the elements of the
training set that would change the position of
the dividing hyper plane if removed.
• Support vectors are the critical elements of
the training set
• The problem of finding the optimal hyper
plane is an optimization problem and can be
solved by optimization techniques (use
Lagrange multipliers to get into a form that
can be solved analytically).
Equation of Hyperplane
w0Tx + b0 = 0
0
X
X
X
X
X
X
Optimization Problem
Maximize :
1
LD i i j yi y j x i x j
2 i, j
i
subject to :
0 i C where C is a penalty for errors
y x
i
i
i
i
The solution is given by
NS
w i yi x i
i 1
where N S is the number of support ve ctors
Nonlinear Support Vector
Machines
• How can we generalize previous result to the case
where the decision function is not a linear function of
the data? Answer: kernel functions
– The only way in which the data appears in the training
problem is in the form of dot products xixj
– First map the data to some other (possibly infinite
dimensional) space H using a mapping .
– Training algorithm now only depends on data through dot
products in H: (xi)(xj)
– If there is a kernel function K such that
K(xi,xj)=(xi)(xj)
we would only need to use K in the training algorithm and
would never need to know explicitly. The conditions under
which such kernel functions exist can be shown.
Inner Product Kernels
Type of Support
Vector Machine
Inner Product Kernel Comments
K(x,xi), I = 1, 2, …, N
Polynomial learning
machine
(xTxi + 1)p
Power p is specified
apriori by the user
Radial-basis function exp(1/(22)||x-xi||2)
network
The width 2 is
specified apriori
Two layer perceptron tanh(0xTxi + 1)
Mercer’s theorem is
satisfied only for
some values of 0
and 1
Support Vector Machine for
Pattern Recognition
• Two key ideas
– Nonlinear mapping of an input vector into a
high-dimensional feature space that is
hidden from both the output and the input
– Construction of an optimal hyperplan for
separating the features descovered in step
1