Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
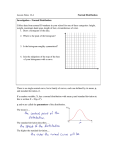
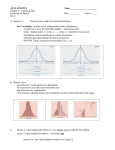
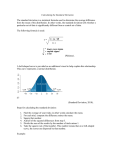
a. b. c. d. High value ⳱ 0.5, low value ⳱ 0 High value ⳱ 1.25, low value ⳱ ⫺1.5 High value ⳱ 7.5, low value ⳱ 6.25 High value ⳱ 20.3, low value ⳱ 13.6 0 to 1 1 to 2 2 to 3 3 to 4 4 to 5 5 to 6 6 to 7 7 to 8 8 to 9 9 to 10 4. A spinner that yields the values 0 to 10, equally spaced, is shown: 9 0 1 8 2 7 3 6 5 4 a. Explain why when you spin the spinner, the exact value that comes up should have the continuous uniform distribution. b. What is the mean and standard deviation of this random variable? c. You try the spinner a few times, and you suspect that there is something wrong with it—namely, that it favors stopping in certain areas. You spin it 100 times, and collect these data: 14 times 15 times 13 times 16 times 11 times 6 times 4 times 3 times 8 times 10 times Perform a chi-square test to test whether the spinner is really giving continuous uniform data. 5. Every time the phone rings, you check the exact position of the second hand of the analog clock on the wall. Explain how this is a continuous uniform variable. What are the upper and lower bounds? 6. The airport shuttle bus will arrive randomly in the next 3 minutes. Find the following probabilities. a. p(wait at least two minutes) b. p(wait less than 1/2 minute) c. p(wait between 1 and 2 minutes). For additional exercises, see page 727. 8.6 THE NORMAL DISTRIBUTION The most famous distribution is the normal distribution. It is also called the Gaussian distribution, after the famous mathematician Carl Friedrich Gauss. More colloquially, it is often referred to as the bell-shaped curve. As seen in Figure 8.4, this density is certainly bell-shaped. The normal curve fits an amazing number of situations. The reason for this lies in the central limit theorem, which is explained in Chapter 11. Figure 8.9 shows the relative frequency histogram of the heights of 102 women in a particular college statistics class. Figure 8.10 is the relative frequency histogram of the body temperatures of 130 people. The superimposed normal curves follow both histograms reasonably well. The one in Figure 8.11 does not. This relative frequency histogram is one of the total number of dogs and cats that the 165 people in the statistics class owned during their lives. The largest number was 40. Note that this is not a physiological measurement. We try to fit it with a normal curve. The normal curve tends to be centered around the bulk of the data, which in Figure 8.11 is in the range from 0 to 5. But in order to extend adequately out to the larger numbers, it also has to extend well below 0.15 0.10 0.05 0.0 55 60 Figure 8.9 65 70 Height (inches) 75 Heights of 102 women. 0.5 0.4 0.3 0.2 0.1 0.0 96 97 98 99 100 Body temperature (°F) 101 Figure 8.10 Body temperatures of 130 people (data are from Allen L. Shoemaker, “What’s Normal?—Temperature, Gender, and Heart Rate,” Journal of Statistics Education, July 1996). 0.15 0.10 0.05 0.0 –10 0 10 20 30 40 Number of dogs and cats owned in lifetime Figure 8.11 Number of dogs and cats owned by 165 students. Statistics and Individual Differences The French scientist A. Quetelet (1796– 1874) first noted that if you measure the heights of a large group of people, the relative frequency polygon of these heights will resemble the bell-shaped curve of a normal distribution. He also studied the distributions of other characteristics, such as weight, chest girth, and arm length, and found that all of these follow nearly the same shape of distribution. This property of the distribution of physiological characteristics was found to occur so frequently that the British scientist Sir Francis Galton (1822–1911) coined the term normal to describe these distributions. This property of most physiological characteristics has many practical applications. For example, the designer of an airplane cockpit must arrange it so that most pilots are comfortable and can reach all of the controls. Clearly, this requires knowledge of average heights, average arm lengths, and so on, as well as knowledge of the variability around these averages so that most pilots will be accommodated. zero, because the normal curve is always symmetric in shape about its midpoint. The area to the left of 0 under the best-fitting normal curve in the graph is about 0.22, which means that 22% of the people should have fewer than 0 dogs and cats. One cannot have a negative number of pets, so the normal distribution is not appropriate here. The point here is not that there is a probability of fewer than 0 cats and dogs, for a probability of 0.01 of this, say, would be tolerable. Rather, the point is that there is the large probability of 0.22, indicating a serious error in fitting the relative frequency histogram of the data with the normal curve. We never seek a perfect fit of distribution to data, but we always seek a good fit! From our viewpoint that data represent a sample from a population, we expect the relative frequency histogram of the sample to fit the population distribution well. If you look at the normal curves in the figures, you see that they all have the same shape but different centers (theoretical means) and spreads (theoretical standard deviations). For the batting averages (Figure 8.4), the best-fitting normal curve covers the data from about 0.200 to 0.360; for the heights (Figure 8.9), it covers the data from about 60 to 71 inches; for the body temperatures (Figure 8.10), it covers the data from about 96 degrees to 101 degrees. For any mean and standard deviation there is a normal curve, which is one reason the normal is so versatile. The three normal curves in Figure 8.12 have different means, ⫺10, 0, and 10, but the same standard deviation of 5. The three normal curves in Figure 8.13, on the other hand, Normal density 0.08 0.06 0.04 0.02 0.0 –30 Figure 8.12 viation of 5. –20 –10 0 10 20 30 Normal curves having a standard de- Normal density 0.4 SD = 1 SD = 5 SD = 10 0.3 0.2 0.1 0.0 –30 Figure 8.13 –20 –10 0 10 20 30 Normal curves having a mean of 0. have the same mean of 0 but three different standard deviations: 2, 5, and 10. The one with standard deviation 2 is the tall narrow curve; the one with standard deviation 10 is the low flat curve. These normal curves are symmetric around their mean; that is, the part of the curve to the right of the mean is a mirror image of the part of the curve to the left. The calculus-based formula for the theoretical mean shows that the mean of a distribution is the geometrical center of gravity, or balance point, of the density curve of the distribution (this is a property of all theoretical means of distributions). Thus in a symmetrical distribution the balance point, or theoretical mean, is located right at the theoretical median, namely, the point that has half the area on either side. Can you think up examples of curves in which the center of gravity (the mean) does not equal the theoretical median? Because all normal curves have the same shape, the areas under normal curves will, if the horizontal axis is given in terms of distances from the mean 0.025 0.025 0.135 –2 × SD Figure 8.14 abilities. 0.34 –1 × SD 0.34 0 Mean 0.135 1 × SD 2 × SD Standard normal curve prob- in standard deviation units, be the same. For example, no matter what the mean and standard deviation are, the area, and hence the probability, between the mean and the mean plus one standard deviation is about 0.34. By symmetry, the area between the mean and the mean minus one standard deviation is also about 0.34. See Figure 8.14. Putting those areas together, the probability of being between the mean minus one standard deviation and the mean plus one standard deviation is about 0.34 Ⳮ 0.34 ⳱ 0.68—that is, approximately 23 . Table 8.8 looks at the examples we have seen so far. For the batting averages the mean was 0.263 and the standard deviation was 0.029. So Mean ⫺ SD ⳱ 0.263 ⫺ 0.029 ⳱ 0.234 Mean Ⳮ SD ⳱ 0.263 Ⳮ 0.029 ⳱ 0.292 It turns out that 178 of the 263 players had batting averages between 0.234 and 0.292, which is a proportion of 0.68, exactly what the normal curve would indicate. In the case of the heights, the mean minus one standard deviation and the mean plus one standard deviation are 62.81 and 68.31, respectively. A proportion of 0.66 of the women had heights in that range— very close to the normal curve’s value of 0.68. Similarly, 90 of 130, or 69% of the people measured, had temperatures between 97.52 and 98.98. Those examples have histograms that look reasonably normal. The dogs and cats histogram did not look normal. Going down one standard deviation from the mean gives ⫺1.15, an impossible number of pets. And 89% of the people are in the range from the mean minus the standard deviation to the mean plus the standard deviation, which is a lot more than the normal distribution would predict. This is simply more evidence that the normal distribution does not fit the pet data well. Table 8.8 The (Mean ⫾ SD): 67% Rule Empirically Demonstrated Batting averages Heights Temperatures Dogs and cats Meanⴱ SDⴱ Mean ⫺ SD Mean Ⳮ SD Actual proportion lying between (mean ⫺ SD) and (mean Ⳮ SD) 0.263 65.56 98.25 4.03 0.029 2.75 0.73 5.18 0.234 62.81 97.52 ⫺1.15 0.292 68.31 98.98 9.21 178/263 ⳱ 0.68 67/102 ⳱ 0.66 90/130 ⳱ 0.69 147/165 ⳱ 0.89 *The means and SDs are sample means and sample SDs. Table 8.9 The (Mean ⫾ 2SD): 95% Rule Empirically Demonstrated Batting averages Heights Temperatures Dogs and cats Mean SD Mean ⫺ (2 ⫻ SD) Mean Ⳮ (2 ⫻ SD) Actual proportion between (mean ⫺ 2 ⫻ SD) and (mean Ⳮ 2 ⫻ SD) 0.263 65.56 98.25 4.03 0.029 2.75 0.73 5.18 0.205 60.06 96.79 ⫺6.33 0.321 61.06 99.71 14.39 251/263 ⳱ 0.95 99/102 ⳱ 0.97 123/130 ⳱ 0.95 159/165 ⳱ 0.96 According to the normal curve in Figure 8.14, going from the mean minus two standard deviations to the mean plus two standard deviations should yield 13.5% Ⳮ 34% Ⳮ 34% Ⳮ 13.5% ⳱ 95% of the data. How does that work in the examples? For the batting averages, Mean ⫺ 2 ⫻ SD ⳱ 0.263 ⫺ 2 ⫻ 0.029 ⳱ 0.205 Mean Ⳮ 2 ⫻ SD ⳱ 0.263 Ⳮ 2 ⫻ 0.029 ⳱ 0.321 Of the 263 players, 251 had batting averages between 0.205 and 0.321, which is 251/263 ⳱ 95%. Table 8.9 shows this and the other examples. This time, even in the case of the dogs and cats data, about 95% of the data are in the range. But this was merely a lucky chance occurrence, because the dogs and cats data do not follow a normal distribution and hence cannot be expected to follow this 95% rule. The conclusion is that if the histogram of a set of data approximately follows a normal curve, then just by knowing the mean and the standard deviation of the data, one can estimate the proportion of the data in the range from the mean minus to the mean plus the standard deviation, or from the mean minus to the mean plus twice the standard deviation. In fact, we can do much more along these lines, as in the following. The z Statistic: One normal curve is the most used of them all. It is called the standard normal curve, or standard normal density, and it is the one with theoretical mean 0 and theoretical standard deviation 1. Figure 8.15 shows the standard normal curve. Any kind of normal data (that is, data whose relative frequency histogram is bell-shaped) can be turned into standard normal data (bell-shaped distribution having a mean of 0 and standard deviation of 1) by standardizing the observations, which means for each observation subtracting the mean of the observations and then dividing by the standard deviation of the observations. Such a standardized value is called a z statistic, often called a standardized score or a z score. As an example, the data columns in Table 8.10 show the calories per hot dog in 20 brands of beef hot dogs. The hot dogs averaged 156.85 calories, and the standard deviation was 22.07 calories. The z columns give the corresponding z statistics: data value ⫺ mean standard deviation It is preferable to insert the theoretical mean and standard deviation in the z-statistic formula. However, because the theoretical mean and standard deviation are usually not known, z statistics typically use the sample mean and standard deviation, quantities known to estimate their theoretical counterparts well. The first brand of hot dog has 186 calories per hot dog. Using the sample mean and standard deviation, its z statistic is (186 ⫺ 156.85)/22.07 ⳱ 1.32. What that means is that this brand has 1.32 standard deviations more than z statistic ⳱ –3 –2 –1 Figure 8.15 Table 8.10 0 z 1 2 3 Standard normal curve. Hot-Dog Calorie Data and z Statistics Datum z Datum z Datum z Datum z Datum z 186 181 176 149 1.32 1.09 0.87 ⫺0.36 184 190 158 139 1.23 1.50 0.05 ⫺0.81 175 148 152 111 0.82 ⫺0.40 ⫺0.22 ⫺2.08 141 153 190 157 ⫺0.72 ⫺0.17 1.50 0.01 131 149 135 132 ⫺1.17 ⫺0.36 ⫺0.99 ⫺1.13 Sources: Davis S. Moore and George P. McCabe, Introduction to the Practice of Statistics, (New York: Freeman, 1989); and Consumer Reports, June 1986, pp. 366–367. the average number (157) of calories per hot dog. There is one brand with 111 calories per hot dog. Its z statistic is (111 ⫺ 156.85)/22.07 ⳱ ⫺2.08, which means it has 2.08 standard deviations fewer calories per hot dog than the average. Note that this brand of hot dog falls outside the 95% range of mean ⫾ 2 standard deviations. In summary, the z statistic for an observation is the number of standard deviations above or below the average. Very often scientists will report data as z statistics instead of reporting raw data. This is especially the case if the original scale is rather arbitrary or it is important to see at a glance where each individual observation ranks relative to the rest of the data. The z statistics now conform to the standard normal curve in that the average of the z statistics is 0, the standard deviation of the z statistics is 1, and the shape of the histogram is, provided the original histogram also was, bell-shaped. One important use of z statistics comes in the next section, where we use the normal curve to estimate proportions for any set of normal-looking data, no matter what the mean and standard deviation are, using just one table of probabilities, namely, the table for the standard normal (Table E). SECTION 8.6 EXERCISES 1. A random variable is assumed to have the normal distribution with mean 5.0 and standard deviation 1.5. a. State a range in which 68% of the observations of this random variable will lie. b. State a range in which 95% of the observations of this random variable will lie. 2. Another random variable is assumed to have the normal distribution, this time with mean ⫺3.5 and standard deviation 0.5. a. State a range in which 68% of the observations of this random variable will lie. b. State a range in which 95% of the observations of this random variable will lie. 3. A random variable was observed 100 times. The observations were as follows: 43.50164 42.17374 47.51862 44.4694 49.31204 44.50963 41.58814 44.30996 42.2318 46.89344 48.0677 44.96988 43.53012 45.09659 47.52947 41.21647 39.81531 41.78741 42.98898 50.89797 43.29784 43.77065 45.71922 41.54672 47.38623 43.56211 43.80182 46.89443 40.79547 44.01106 41.97859 47.93914 53.50043 41.1815 43.72759 48.56094 40.81974 46.58111 46.51913 41.1561 45.62537 44.88452 41.70193 48.42776 45.43842 41.4995 48.26565 47.51046 47.30188 42.12499 44.73116 43.92343 40.97019 52.83752 42.42954 49.37738 45.81967 41.13073 42.17687 51.1321 41.49603 45.58613 44.5927 45.38359 42.97241 49.5567 44.59925 44.26008 45.75363 44.42216 44.54217 40.9955 39.9309 48.91718 40.75161 47.00198 45.50033 49.58127 50.40565 47.77691 43.03819 47.79572 42.30571 42.79054 48.66678 44.49416 40.48248 43.50889 41.08607 40.68009 48.65868 44.94595 39.40947 42.92722 45.72352 41.54957 45.28159 43.87346 44.24591 43.61332 Before gathering the data, the researcher hypothesized that the data would follow the normal distribution with mean 45 and standard deviation 3. a. If the hypothesis is correct, what percentage of the observations should lie between 42 and 48? b. What percentage of the values really lie between 42 and 48? c. If the hypothesis is correct, what percentage of the observations should lie between 39 and 51? d. What percentage of the values really lie between 39 and 51? e. Does the researcher’s hypothesis seem reasonable? 4. A random variable X has a normal distribution with mean 10 and standard deviation 2. Calculate the following probabilities: a. p(X ⬍ 10) b. p(X ⬎ 10) c. p(8 ⬍ X ⬍ 10) d. p(6 ⬍ X ⬍ 12) 5. The following 50 observations were made of the weights (kg) of 12-year-old boys: 40.96 42.99 38.53 44.81 37.06 44.57 42.11 41.06 48.64 44.61 36.13 50.87 31.00 33.54 44.39 34.20 39.69 38.15 42.96 49.99 37.14 32.82 40.61 52.28 45.82 41.86 37.64 32.04 31.54 40.73 34.85 49.89 54.18 39.58 41.62 38.93 29.71 34.87 26.82 31.02 34.66 38.73 33.01 50.05 35.13 41.42 38.07 44.10 35.03 49.15 The mean of this set of data is 40, and the standard deviation is 6.43. a. What percentage of the observations fall 6. 7. 8. 9. within one standard deviation of the mean? b. What percentage of the observations fall within two standard deviations of the mean? c. Do these data seem to follow the normal distribution in the sense of obeying the 67% and 95% rules? A random variable X has the standard normal distribution. a. What is the mean of X? b. What is the standard deviation of X? c. What is the probability of X being between ⫺1 and 1? A random variable has the normal distribution with mean 3 and standard deviation 2. Convert the following observations into standard units: a. 3.234 b. 5.193 c. 1.401 d. ⫺0.0184 Repeat Exercise 7, this time for a normal random variable having mean 6 and standard deviation 3. a. 5.290 b. 2.816 c. 8.791 d. 10.271 Repeat Exercise 7, this time for a normal random variable having mean ⫺5 and standard deviation 4. a. ⫺4.823 b. ⫺5.972 c. ⫺11.732 d. 1.672 8.7 USING THE NORMAL-CURVE TABLE Since the normal curve is so useful, tables have been prepared that provide the area under the curve to the left of a given value of z. Recall that we used similar tables to find chi-square probabilities. Remember from the previous section how you can change any set of observations to z statistics. If you can