Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
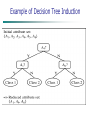
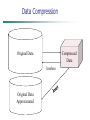
Data Preprocessing Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary Data Transformation Smoothing: remove noise from data Aggregation: summarization, data cube construction Generalization: where low-level or “primitive” (raw) data are replaced by higher-level concepts through the use of concept hierarchies Normalization: scaled to fall within a small, specified range min-max normalization z-score normalization normalization by decimal scaling Attribute/feature construction New attributes constructed from the given ones Data Transformation: Normalization Min-max normalization: Performs a linear transformation on the original data. Suppose that minA and maxA are the minimum and maximum values of an attribute, A. Min-max normalization maps a value, v, of A to v’ in the range [new minA , new maxA ] by computing to [new_minA, new_maxA] Data Transformation: Normalization Eg: Suppose that the minimum and maximum values for the attribute income are $12,000 and $98,000, respectively. We would like to map income to the range [0.0, 1.0]. By min-max normalization, a value of $73,600 for income is trans-formed to Data Transformation: Normalization Z-score normalization: In z-score normalization (or zero-mean normalization), the values for an attribute, A, are normalized based on the mean and standard deviation of A. A value, v, of A is normalized to v' by computing v− μA v'= σA Ex. Let μ = 54,000, σ = 16,000. Then With z-score normalization, a value of $73,600 for income is transformed to 73,600− 54,000 = 1.225 16,000 Data Transformation: Normalization Normalization by decimal scaling; normalizes by moving the decimal point of values of attribute A. The number of decimal points moved depends on the maximum absolute value of A. A value, v, of A is normalized to v' by computing v'= v 10 j where j is the smallest integer such that Max(|v' |) < 1. Data Transformation: Normalization Eg; Suppose that, the recorded value of A range from -986 to 917. The maximum absolute value of A is 986. To normalize by decimal scaling, we therefore divide each value by 1,000 (i.e., j = 3) so that −986 normalizes to −0.986 and 917 normalizes to 0.917. v'= v 10 j Data Transformation: Attribute construction In attribute construction, new attributes are constructed from the given attributes and added in order to help improve the accuracy and understanding of structure in high-dimensional data. For example, we may wish to add the attribute area based on the attributes height and width. By combining attributes, attribute construction can discover missing information about the relationships between data attributes that can be useful for knowledge discovery. Data Preprocessing Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary Data Reduction Strategies Why data reduction? A database/data warehouse may store terabytes of data Complex data analysis/mining may take a very long time to run on the complete data set Data reduction Obtain a reduced representation of the data set that is much smaller in volume but yet produce the same (or almost the same) analytical results Data Reduction Strategies Data reduction strategies Data cube aggregation: where aggregation operations are applied to the data in the construction of the data cube. Dimensionality reduction — where encoding mechanism are used to reduce the data set size. Attribute subset subset selection: where irrelevant, weakly relevant, or redundant attributes or dimensions may be detected and removed. Numerosity reduction — where the data are replaced or estimated by alternative, smaller data representations such as parametric models or nonparametric methods such as clustering, sampling, and the use of histograms. Discretization and concept hierarchy generation: where raw data values for attributes are replaced by ranges or higher conceptual levels Data Cube Aggregation The data can be aggregated so that the resulting data summarize the total of all data. The resulting data set is smaller in volume, without loss of information necessary for the analysis task. Attribute Subset Selection Feature selection (i.e., attribute subset selection): reduces the data set size by removing irrelevant or redundant attributes (or dimensions). The goal of attribute subset selection is to find a minimum set of attributes such that the resulting probability distribution of the data classes is as close as possible to the original distribution obtained using all attributes. Heuristic Method of Attribute Subset Selection Decision tree induction: Decision tree algorithms, such as ID3(interactive dichotomiser),and CART(classfication and regression tree), were originally intended for classification. Decision tree induction constructs a flowchart- like structure where each internal (nonleaf) node denotes a test on an attribute, each branch corresponds to an outcome of the test, and each external (leaf) node denotes a class prediction. At each node, the algorithm chooses the “best” attribute to partition the data into individual classes. When decision tree induction is used for attribute subset selection, a tree is constructed from the given data. All attributes that do not appear in the tree are assumed to be irrelevant. The set of attributes appearing in the tree form the reduced subset of attributes. Example of Decision Tree Induction Dimensionality Reduction: In dimensionality reduction, data encoding or transformations are applied so as to obtain a reduced or “compressed” representation of the original data. If the original data can be reconstructed from the compressed data without any loss of information, the data reduction is called lossless. If, instead, we can reconstruct only an approximation of the original data, then the data reduction is called lossy. Data Compression Compressed Data Original Data lossless Original Data Approximated Numerosity Reduction Reduce data volume by choosing alternative, smaller forms of data representation Parametric methods Assume the data fits some model, estimate model parameters, store only the parameters, and discard the data (except possible outliers) Non-parametric methods Do not assume models, it store reduced representation of the data. Major families: histograms, clustering, sampling Data Reduction Method (1): Regression Linear regression: Data are modeled to fit a straight line Often uses the least-square method to fit the line Multiple regression: allows a response variable Y to be modeled as a linear function of multidimensional feature vector Regression Analysis Linear regression: Y = w X + b Two regression coefficients, w and b, specify the line and are to be estimated by using the data at hand Using the least squares criterion to the known values of Y1, Y2, …, X1, X2, …. Multiple regression: Y = b0 + b1 X1 + b2 X2. Many nonlinear functions can be transformed into the above. Data Reduction Method (2): Histograms Divide data into buckets and store average (sum) for each bucket Partitioning rules: Equal-width: In an equal-width histogram, the width of each bucket range is uniform Equal-frequency (or equal-depth):In an equal-frequency histogram, the buckets are created so that, roughly, the frequency of each bucket is constant Data Reduction Method (3): Clustering It consider data tuples as an object. Partition data set into clusters based on similarity, and store cluster representation (e.g., centroid and diameter) only. Cluster analysis will be studied in depth in Classification. Data Reduction Method (4): Sampling Sampling: obtaining a small sample s to represent the whole data set N. Allow a mining algorithm to run in complexity that is potentially sub-linear to the size of the data Choose a representative subset of the data Simple random sampling may have very poor performance in the presence of skew Develop adaptive sampling methods Stratified sampling: Approximate the percentage of each class (or subpopulation of interest) in the overall database Used in conjunction with twisted data Sampling: with or without Replacement Raw Data Sampling: Cluster or Stratified Sampling Raw Data Cluster/Stratified Sample Sampling: Cont An advantage of sampling for data reduction is that the cost of obtaining a sample is proportional to the size of the sample, s, as opposed to N, the data set size. Hence, sampling complexity is potentially sublinear to the size of the data. Module 3: Data Preprocessing Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary Discretization Data discretization techniques can be used to reduce the number of values for a given continuous attribute by dividing the range of the attribute into intervals. Interval labels can then be used to replace actual data values. Three types of attribute Nominal — values from an unordered set, e.g., color, profession Ordinal — values from an ordered set, e.g., military or academic rank Continuous — real numbers, e.g., integer or real numbers Discretization Discretization: Divide the range of a continuous attribute into intervals Some classification algorithms only accept categorical attributes. Reduce data size by discretization Prepare for further analysis Discretization and Concept Hierarchy Discretization Reduce the number of values for a given continuous attribute by dividing the range of the attribute into intervals Interval labels can then be used to replace actual data values Supervised vs. unsupervised Split (top-down) vs. merge (bottom-up) Discretization can be performed recursively on an attribute Concept hierarchy formation Recursively reduce the data by collecting and replacing low level concepts (such as numeric values for age) by higher level concepts (such as young, middle-aged, or senior) Discretization and Concept Hierarchy Generation for Numeric Data Typical methods: All the methods can be applied recursively Binning (covered above) Histogram analysis (covered above) Clustering analysis (covered above) Data Preprocessing Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary Summary Data preparation or preprocessing is a big issue for both data warehousing and data mining Descriptive data summarization is need for quality data preprocessing Data preparation includes Data cleaning and data integration Data reduction and feature selection Discretization