Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
WEKA and Machine Learning
Algorithms
Algorithm Types
• Classification (supervised)
Given -> A set of classified examples
“instances”
Produce -> A way of classifying new examples
Instances: described by fixed set of features
“attributes”
Classes: discrete or continuous “classification”
“regression”
Interested in:
– Results? (classifying new instances)
– Model? (how the decision is made)
• Clustering (unsupervised)
There are no classes
• Association rules
Look for rules that relate features to other features
Classification
Clustering
Clustering
• It is expected that similarity among members of
a cluster should be high and similarity among
objects of different clusters should be low.
• The objectives of clustering
– knowing which data objects belong to which cluster
– understanding
common
characteristics
of
the
members of a specific cluster
Clustering vs Classification
• There is some similarity between clustering and
classification.
• Both
classification and clustering are about
assigning appropriate class or cluster labels to
data records. However, clustering differs from
classification in two aspects.
– First, in clustering, there are no pre-defined classes.
This means that the number of classes or clusters and
the class or cluster label of each data record are not
known before the operation.
– Second, clustering is about grouping data rather than
developing a classification model. Therefore, there is
no distinction between data records and examples.
The entire data population is used as input to the
clustering process.
Association Mining
Overfitting
• Memorization vs generalization
• To fix, use
– Training data — to form rules
– Validation data — to decide on best rule
– Test data — to determine system performance
• Cross-validation
Baseline Experiments
• In order to evaluate the efficiency of the classifiers used in
experiments, we use baselines:
– Majority based random classification (Kappa=0)
– Class distribution based random classification (Kappa=0)
• Kappa statistics, is used as a measure to assess the
improvement of a classifier’s accuracy over a predictor
employing chance as its guide.
• P0 is the accuracy of the classifier and Pc is the expected
accuracy that can be achieved by a randomly guessing
classifier on the same data set. Kappa statistics has a
range between 1 and 1, where 1 is total disagreement
(i.e., total misclassification) and 1 is perfect agreement
(i.e., a 100% accurate classification).
• Kappa score over 0.4 indicates a reasonable agreement
beyond chance.
9
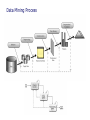
Data Mining Process
WEKA: the software
• Machine learning/data mining software written
in Java (distributed under the GNU Public
License)
• Used for research, education, and applications
• Complements “Data Mining” by Witten & Frank
• Main features:
– Comprehensive set of data pre-processing tools, learning
algorithms and evaluation methods
– Graphical user interfaces (incl. data visualization)
– Environment for comparing learning algorithms
Weka’s Role in the Big Picture
Data Mining
by Weka
Input
•Raw data
•Pre-processing
•Classification
•Regression
•Clustering
•Association Rules
•Visualization
Output
•Result
WEKA: Terminology
Some synonyms/explanations for the terms used by WEKA:
Attribute: feature
Relation: collection of examples
Instance: collection in use
Class: category
13
WEKA only deals with “flat” files
@relation heart-disease-simplified
@attribute age numeric
@attribute sex { female, male}
@attribute chest_pain_type { typ_angina, asympt, non_anginal, atyp_angina}
@attribute cholesterol numeric
@attribute exercise_induced_angina { no, yes}
@attribute class { present, not_present}
@data
63,male,typ_angina,233,no,not_present
67,male,asympt,286,yes,present
67,male,asympt,229,yes,present
38,female,non_anginal,?,no,not_present
...
Explorer: pre-processing the data
• Data can be imported from a file in various
formats: ARFF, CSV, C4.5, binary
• Data can also be read from a URL or from an
SQL database (using JDBC)
• Pre-processing tools in WEKA are called “filters”
• WEKA contains filters for:
– Discretization, normalization, resampling, attribute
selection, transforming and combining attributes, …
Explorer: building “classifiers”
• Classifiers in WEKA are models for predicting
nominal or numeric quantities
• Implemented learning schemes include:
– Decision trees and lists, instance-based classifiers,
support vector machines, multi-layer perceptrons,
logistic regression, Bayes’ nets, …
• “Meta”-classifiers include:
– Bagging, boosting, stacking, error-correcting output
codes, locally weighted learning, …
17
5/7/2017
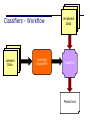
Classifiers - Workflow
Labeled
Data
Learning
Algorithm
Unlabeled
Data
Classifier
Predictions
Evaluation
• Accuracy
– Percentage of Predictions that are correct
– Problematic for some disproportional Data Sets
• Precision
– Percent of positive predictions correct
• Recall (Sensitivity)
– Percent of positive labeled samples predicted as
positive
• Specificity
– The percentage of negative labeled samples
predicted as negative.
Confusion matrix
Contains information about the actual and the predicted
classification
predicted
All measures can be derived from it:
–
+
accuracy: (a+d)/(a+b+c+d)
–
a
b
true
recall: d/(c+d) => R
+
c
d
precision: d/(b+d) => P
F-measure: 2PR/(P+R)
false positive (FP) rate: b /(a+b)
true negative (TN) rate: a /(a+b)
false negative (FN) rate: c /(c+d)
20
Explorer: clustering data
• WEKA contains “clusterers” for finding groups of
similar instances in a dataset
• Implemented schemes are:
– k-Means, EM, Cobweb, X-means, FarthestFirst
• Clusters can be visualized and compared to
“true” clusters (if given)
• Evaluation based on loglikelihood if clustering
scheme produces a probability distribution
21
5/7/2017
Explorer: finding associations
• WEKA contains an implementation of the Apriori
algorithm for learning association rules
– Works only with discrete data
• Can identify statistical dependencies between
groups of attributes:
– milk, butter bread, eggs (with confidence 0.9 and
support 2000)
• Apriori can compute all rules that have a given
minimum support and exceed a given
confidence
22
5/7/2017
Explorer: attribute selection
• Panel that can be used to investigate which
(subsets of) attributes are the most predictive
ones
• Attribute selection methods contain two parts:
– A search method: best-first, forward selection,
random, exhaustive, genetic algorithm, ranking
– An evaluation method: correlation-based, wrapper,
information gain, chi-squared, …
• Very flexible: WEKA allows (almost) arbitrary
combinations of these two
23
5/7/2017
Explorer: data visualization
• Visualization very useful in practice: e.g. helps
to determine difficulty of the learning problem
• WEKA can visualize single attributes (1-d) and
pairs of attributes (2-d)
– To do: rotating 3-d visualizations (Xgobi-style)
• Color-coded class values
• “Jitter” option to deal with nominal attributes
(and to detect “hidden” data points)
• “Zoom-in” function
24
5/7/2017
Performing experiments
• Experimenter makes it easy to compare the
performance of different learning schemes
• For classification and regression problems
• Results can be written into file or database
• Evaluation options: cross-validation, learning
curve, hold-out
• Can also iterate over different parameter
settings
• Significance-testing built in!
25
5/7/2017
The Knowledge Flow GUI
• New graphical user interface for WEKA
• Java-Beans-based interface for setting up and
running machine learning experiments
• Data sources, classifiers, etc. are beans and can
be connected graphically
• Data “flows” through components: e.g.,
“data source” -> “filter” -> “classifier” ->
“evaluator”
• Layouts can be saved and loaded again later
26
5/7/2017
Beyond the GUI
• How to reproduce experiments
with the command-line/API
– GUI, API, and command-line all rely
on the same set of Java classes
– Generally easy to determine what
classes and parameters were used
in the GUI.
– Tree displays in Weka reflect its
Java class hierarchy.
> java -cp ~galley/weka/weka.jar
weka.classifiers.trees.J48 –C 0.25 –M 2
-t <train_arff> -T <test_arff>
27
Important command-line parameters
> java -cp ~galley/weka/weka.jar
weka.classifiers.<classifier_name>
[classifier_options] [options]
where options are:
• Create/load/save a classification model:
-t <file> : training set
-l <file> : load model file
-d <file> : save model file
• Testing:
-x <N> : N-fold cross validation
-T <file> : test set
-p <S> : print predictions + attribute selection S
28
Problem with Running Weka
Problem : Out of memory for large data
set
Solution : java -Xmx1000m -jar
weka.jar