Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Chapter 5 Working with Scores
Raw Score Distribution - simplest way to represent a set of scores, just listed in
a column.
Frequency Table - allows for easier interpretation of data, includes score value
(X), frequency f(X), and cumulative frequency cf(X) columns. X values are
always listed in "descending" (highest to lowest) order.
Frequency Graph - allows for easier (pictorial) interpretation of data, X axis
shows X values, Y axis shows frequencies, axes should be fully labeled.
Descriptive Statistics - are used to summarize sets of data and include 1.
measures of central tendency, and 2. measures of variability.
Measures of Central Tendency (three) - tell about where most of the scores
are gathered, where the distribution is "centered."
1. Mode - the most frequently occurring score (uni-modal), distributions can be
bi-modal or maybe even tri-modal, sometimes there is no mode.
2. Mean - the arithmetic average, most useful and often used of the three
measures. One drawback is that outliers can "pull" the mean in their direction so
it does not really show true central tendency. In that case, the median is a better
measure. We'll learn two formulas for the mean (1.) raw score, and (2) frequency
distribution which requires creating an X[f(X)] column. The mean is represented
as an X with a bar above it (Xbar) or M.
Outlier - an extreme score (high or low) far away from the majority of the other
scores.
3. Median - a value (not necessarily one of the scores and not necessarily a
whole number) that divides the distribution in half. In larger sets of data a
procedure (formula) called "INTERPOLATION" may be needed.
Measures of Variability (three……sort of) - tell us about how spread out or
close together the scores are.
1. Range - simply the highest score - the lowest score, provides only a rough
estimate so not that useful.
2. Standard Deviation - the average distance that the raw scores are from their
mean (i.e., the average of the "deviation scores"). We will learn two formulas: 1.
the Deviation (Derivational) formula and 2. the Computational formula. We
actually must first calculate the "variance" (using the same two formulas) to get
the standard deviation.
Deviation Score - difference between a score and the mean (x - xbar).
3. Variance - the average distance that the "squared" scores are from their
mean (i.e., the average of the "squared" deviation scores).
We will always use N as the denominator in these formulas, giving us the
"Population" Standard Deviation "" or Variance "2"
In common practice, N-1 is used instead of N as the denominator in these
formulas, giving us the "Sample" Standard Deviation "S" or Variance "S2"
The N-1 Correction - Samples tend to underestimate variability. The "N-1
Correction" increases the calculated value so as to be more similar to what it
really is in the population.
Shapes of Distributions:
1. Symmetric Distributions - can be thought of as two mirror image halves, can
be unimodal, bimodal, or without a mode.
The mean, mode, and median, are all equal ONLY IN A SYMMETRIC
UNIMODAL DISTRIBUTION
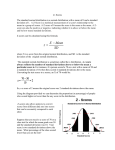
2. Normal Distribution - a special case of the symmetric distribution with
"special" properties: 1. is "hypothetical, 2. is of a specific bell shape, 3.
approximates the distribution of most "naturally occurring variables"
Sometimes called the Gauss-LaPlace curve as both men contributed to its
development. Gauss, the 5050 kid!
Adolph Quetelet - was first to apply the curve to "bio-social" data (i.e., that
human characteristics such as height followed the curve).
Apex - the uppermost point on the curve.
Projection - a vertical line running from a point on the curve to the X axis
Points of Inflection (2) - where the curve changes direction, a projection
dropped from either point of inflection marks off 1 standard
deviation...........WOW!
When combined with the standard deviation concept, the normal curve becomes
an amazingly powerful statistical tool. Standard deviations "mark off" certain
"areas" or "proportions" under the curve.
Skewed Distributions:
Positive Skew - there are fewer high scores than low scores, the mean is larger
than the median as it is "pulled" by the high scores.
Negative Skew - there are low scores than high scores, the mean is smaller than
the median as it is "pulled" by the low scores.
In skewed distributions, the median is a better measure of central tendency
Z scores - we already know, are standardized scores with a mean of 0 and a
standard deviation of 1. Karl Pearson may have come up with these out of
necessity in coming up with a formula for Galton's "correlations."
Z = (X - Xbar) /
Scatter plots - Galton's invention, allows us to plot two variables, if there is a
strong "linear" relationship, we can "predict" one's score on one variable (Y) if
we know his/her score on the other variable (X)
Correlation - mathematical measure that tells us the strength and direction of
the relationship between two variables. Karl Pearson developed the first formula
at Galton's request. Called the "Pearson Product Moment Correlation" and
represented as "r"
Three formulas for calculating Pearson's r:
1. Z score formula - most intuitive, first developed
2. Raw Score formula - looks harder than it is
3. Means and Standard Deviation formula - easiest to use if you have the
means and SDs.
Coefficient of Determination - Pearson's r "squared" represented as r2 Tells us
the proportion of variability in one variable (Y) accounted for or predictable from a
knowledge of the other (X).
If r = 1, then r2 = 1 and 100% of the variability in Y is "accounted for" or
predictable from a knowledge of X. We have perfect prediction, 0 error, this does
not happen in the real world.
Linear Regression - developed by Galton and others, a "regression formula" is
used to "predict" a Y' score based on one's X score.
Regression Equation - Y' = a + bX
It calculates the Y' scores we would
expect to get IF the XY correlation were = to 1.
Regression Line - always a straight line formed when the XY' points are
connected.
Y' - predicted value of Y for a given value of X
b ("beta" or the "Slope") - reflects the rate at which X and Y are changing
relative to each other. b = r (y/x)
a (the Y intercept) - is 1. the point at which the regression line crosses the Y
axis, and 2. the value of Y when X is ). a = Ybar - b(Xbar)
Residuals - the differences between the XY values and XY' values, ERROR,
represented as vertical lines connecting the XY and XY' points
Residual (error) Variance - the variance of the residuals, the average size
(distance) of the residuals in squared unitsy-y'Y-Y'
y = y' + y-y' - if y' = 1, then we have "perfect prediction," no error
Linear Transformations - preserve the equal interval nature of the data
1. Z scores - we already know, awkward for test reporting because of decimals
and negative values.
2. T scores - using the formula T = 50 + 10(Z) we convert to scores with a mean
of 50 and SD of 10, better for test score reporting.
Nonlinear Transformations - basically Percentile Ranks (two methods)
1. Z or Theory based percentiles - we can use the "Z Table" to estimate
percentiles IF the data are more or less normally distributed. For a positive Z
value, add the "area" from the table to .5 and multiply by 100 (to convert to
percent). If the Z value is negative subtract the "area" from the table from .5 and
multiply by 100 (to convert to percent).
2. Data based percentiles - using the actual data (arranged in a frequency
table), we can calculate the actual percentiles, this is always the more accurate
method. Three ways of calculating: PRcfb, PRcf, and PRcf-mp
PRcfb Method - problem is that the person with the lowest score (X) will have a
PR of 0 regardless of how high the scores actually are.
PRcf Method - problem is that the person with the highest score (X) will have a
PR of 100 regardless of how bad the scores actually are.
PRcf-mp Method - is the preferred method (a compromise) and the one we will
use. First calculate "cf-mp for the X value." Then calculate PRcf-mp = (cf-mp /
N) * 100
IF the data are normally distributed, methods 1 and 2 will give similar results.