Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Microsoft SQL Server wikipedia , lookup
Oracle Database wikipedia , lookup
Entity–attribute–value model wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Open Database Connectivity wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Concurrency control wikipedia , lookup
Relational model wikipedia , lookup
ContactPoint wikipedia , lookup
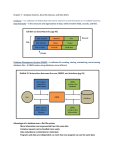
Chapter 9 Databases Objectives In this chapter we will: 1. Scrutinize the characteristics of a Database 2. Study the features of a Database Management System 3. Look at the architectures of Database Management Systems 4. Examine the evolution of Database Technology Learning outcomes: At the end of the chapter, students will be able to: 1. Identify the characteristics of a Database 2. Describe the features of a Database Management System 3. Explain the various architectures of a Database Management System 4. Discuss the evolution of Database Technology 9.0 Introduction What is a database? A database is a collection of information that is organized so that it can easily be accessed, managed, and updated. We can have a database of any kind of content – bibliographic, full-text, numeric and images. We can even have a multimedia database. A database is often abbreviated as DB. You can also think of a database as an electronic filing system. Traditional databases are organized by fields, records, and files. A field is a single piece of information; a record is one complete set of fields; and a file is a collection of records. For example, a telephone book is analogous to a file. It contains a list of records, each of which consists of three fields: name, address, and telephone number. With the advent of the Internet Technology, a new concept in database design has been introduced, which is known as a Hypertext database. In a Hypertext database, any object, whether it is a piece of text, a picture, or a film, it can be linked to any other object. Hypertext databases are particularly useful for organizing large amounts of disparate information, but they are not designed for numerical analysis. The size of a database can vary widely, from a few megabytes for personal databases, to gigabytes (a gigabyte is 1000 megabytes) or even terabytes (a terabyte is 1000 gigabytes) for large corporate databases. The information in a database is stored on a nonvolatile medium that can accommodate large amounts of data; the most commonly used such media are magnetic disks. Magnetic disks can store significantly larger amounts of data than main memory, at much lower costs per unit of data. Examples of the use of database systems include airline reservation systems, company payroll and employee information systems, banking systems, credit card processing systems, and sales and order tracking systems, computerized library systems, automated teller machines, flight reservation systems and computerized parts inventory systems. Let us look at an example illustrated in Table 9.0 Table 9.0 contains details about each student. There are six pieces of information on each student. They are Metric No, Name, Date of birth, Sex, Address and Courses. Each piece of information in database is called a Field. We can define field as the smallest unit in a database. Each field represents one and only one characteristic of an event or item. Thus there are six fields in this database. If we were to take a close look at all these fields, we can see that they are not of the same type. Date of birth is date type whereas Name is character type. All the related fields for a particular event is called a Record. In the example above, all six fields taken together for a particular student is called a record of that student. Since there are six students there are six records. Thus, we can define record as a collection of logically related fields. We can now say that a database is a collection of logically related records. Table 9.0: A Student Database Metric No. Name Date of birth Sex Address Courses 9721001 Maryam 21.05.1980 M C36, Sector 2, Manama, Bahrain Pol Sc, Eco, History, Eng, Statistics 9721002 Aditya 12.06.1981 M At/Po. Orange Street, Dubai Phy, Chem, Biology, Eng, Geology 9732012 Rahul Jain 03.01.1979 F A31, Pilani, Rajasthan, India Pol Sc, Eco, History, Eng, Maths 9724004 Ahmad Ali 23.11.1979 M 12A, Sheikh Sarai-I, Dahran, Saudi Arabia Phy, Chem, Biology, Eng, IT C. Suresh 07.09.1980 M 96, Malviya Nagar, Sri Lanka Pol Sc, Eco, History, Eng, Programming 9715023 9.2 Features of Database Management Systems The next question is: How do we create and manage our databases? Data management involves creating, modifying, deleting and adding data in files, and using this data to generate reports or answer queries. The software that allows us to perform these functions easily is called a Data Base Management System (DBMS). Using a DBMS files can be retrieved easily and effectively. There are many DBMS packages available in the market. Some of them are: MySQL, PostgreSQL, Microsoft Access, SQL Server, FileMaker, Oracle, RDBMS, dBASE, Clipper, and FoxPro. 9.1 Database Characteristics A database has several characteristics that make it useful and irreplaceable. 9.1.1 Concurrent Use A database is always used by more than one user at the same time. In this case a database system allows several users to access the database concurrently. Answering different questions from different users with the same (base) data is a central aspect of an information system. Such concurrent use of data increases the economy of a system. Data capturing and data storage is not redundant, the system can be operated from a central control and the data can be updated more efficient. An example for concurrent use is the travel database of a bigger travel agency. The employees of different branches can access the database concurrently and book journeys for their clients. Each travel agent sees on his computer if there are still seats available for a specific journey or if it is already fully booked. Figure 9.1.1 describes how multiple users can share the same database. Figure 9.1.1: A database enabling concurrent access 9.1.2 Structured and Described Data A database system does not only contain data but also the complete definition and description of these data. A database contains metadata which describes the data itself - the structure, the type and the format of all data and, additionally, the relationship between the data. Metadata is sometimes known as "data about data". Structured Data: Data is called structured if it can be subdivided systematically and linked. Lets us look at an example of how data can be structured. Table 9.1.2 has four columns. First column = Prename, second column = Name, third column = Postcode, forth column = City It is known that an entry in the first column must be a prename (coded as string) and an entry in the third column must be a postcode (coded as number). Table 9.1.2: A table of Names and Addresses Firstname [string] Familyname [string] Postcode City [string] Rohit Gupta 14000 Srinagar Hanif Salam 46350 Klang …. ….. …. …. 9.1.3 Separates Data and Applications When using a database, the application software does not need to know about the physical data storage like encoding, format, storage place, etc. It only communicates with the management system of a database (DBMS) via a standardized interface with the help of a standardized language like SQL. The access to the data and the metadata is entirely done by the DBMS. In this way all the applications can be totally separated from the data. Therefore database internal reorganizations or improvement of efficiency do not have any influence on the application software. Figure 9.1.3 describes how this can be done. Figure 9.1.3: Separating Data from Application Systems 9.1.4 Data Integrity Data integrity means the quality and the reliability of the data of a database system. Data integrity includes also the protection of the database from unauthorized access (confidentiality) and unauthorized changes..Data reflect facts of the real world. Logically, it is demanded that this reflection is done correctly. A DBMS should support the task to bring only correct and consistent data into the database. Additionally, correct transactions ensure that the consistency is maintained during the operation of the system. An example for inconsistency would be if contradictory statements were saved in the same database. Student Record in the Library Name Address Haziq Hamidi No.11, Yellow Road, Ipoh, Malaysia Rami Mayan No.22 Oxfam Road, Klang, Malaysia Sunny Darwish No. 134, Silk Road, Singapore …. …. Student Record in the Accounts Department Name Address Haziq Hamidi No.11, Yellow Road, Ipoh, Malaysia Rami Mayan No.22 Oxfam Road, Klang, Malaysia Sunny Darwish No. 74, Lime Tree Road, Norwich, UK …. …. 9.1.5. Data Persistence Data persistence means that in a DBMS all data is maintained as long as it is not deleted explicitly. The life span of data needs to be determined directly or indirectly be the user and must not be dependent on system features. Additionally data once stored in a database must not be lost. 9.1.6 Data Views Typically, a database has several users and each of them, depending on access rights and desire, needs an individual view of the data (content and form). Such a data view can consist of a subset of the stored data or of from the stored data derived data (not explicitly stored). For example: A university manages the data about students. Beside matriculation number, name, address, etc. other information like in which course the student is registered, if he needs to do a receipt, and so on is managed as well. This extensive database is used by several people all with different needs and rights. A student can view only his own data: - name address, contact number, his courses, grades and fees paid. A lecturer can view only student metric number, names and grades of those students that he/she teaches. A Dean can only see all student, lecturers and staff details if they are in his Faculty. 9.2 Features of Database Management Systems A database management system (DBMS) is designed to manage a large body of information. Data management involves both defining structures for storing information and providing mechanisms for manipulating the information. In addition, the database system must provide for the safety of the stored information, despite system crashes or attempts at unauthorized access. If data are to be shared among several users, the system must avoid possible inconsistent results due to multiple users concurrently accessing the same data. Accessing desired records from a large relation using a scan on the relation can be very expensive. Indices are data structures that permit more efficient access of records. An index is built on one or more attributes of a relation; such attributes constitute the search key. Given a value for each of the search-key attributes, the index structure can be used to retrieve records with the specified search-key values quickly. Indices may also support other operations, such as fetching all records whose search-key values fall in a specified range of values. A database schema is specified by a set of definitions expressed by a data-definition language. The result of execution of data-definition language statements is a set of information stored in a special file called a data dictionary. The data dictionary contains metadata, that is, data about data. This file is consulted before actual data are read or modified in the database system. The data-definition language is also used to specify storage structures and access methods. Data manipulation is the retrieval, insertion, deletion, and modification of information stored in the database. A data-manipulation language enables users to access or manipulate data as organized by the appropriate data model. There are basically two types of data-manipulation languages: Procedural data-manipulation languages require a user to specify what data are needed and how to get those data; nonprocedural data-manipulation languages require a user to specify what data are needed without specifying how to get those data. A query is a statement requesting the retrieval of information. The portion of a datamanipulation language that involves information retrieval is called a query language. Although technically incorrect, it is common practice to use the terms query language and datamanipulation language synonymously. Database languages support both data-definition and data-manipulation functions. Although many database languages have been proposed and implemented, SQL has become a standard language supported by most relational database systems. Databases based on the objectoriented model also support declarative query languages that are similar to SQL. SQL provides a complete data-definition language, including the ability to create relations with specified attribute types, and the ability to define integrity constraints on the data. Query By Example (QBE) is a graphical language for specifying queries. It is widely used in personal database systems, since it is much simpler than SQL for non-expert users. Forms interfaces present a screen view that looks like a form, with fields to be filled in by users. Some of the fields may be filled automatically by the forms system. Report writers permit report formats to be defined, along with queries to fetch data from the database; the results of the queries are shown formatted in the report. These tools in effect provide a new language for building database interfaces and are often referred to as fourth-generation languages (4GLs). Often, several operations on the database form a single logical unit of work, called a transaction. An example of a transaction is the transfer of funds from one account to another. Transactions in databases mirror the corresponding transactions in the commercial world. Traditionally database systems have been designed to support commercial data, consisting mainly of structured alphanumeric data. In recent years, database systems have added support for a number of nontraditional data types such as text documents, images, and maps and other spatial data. The goal is to make databases universal servers, which can store all types of data. Rather than add support for all such data types into the core database, vendors offer add-on packages that integrate with the database to provide such functionality. 9.3 Architectures of Database Management Systems The database architecture is the set of specifications, rules, and processes that dictate how data is stored in a database and how data is accessed by components of a system. It includes data types, relationships, and naming conventions. The database architecture describes the organization of all database objects and how they work together. It affects integrity, reliability, scalability, and performance. The database architecture involves anything that defines the nature of the data, the structure of the data, or how the data flows. The overall structure of the database is called the database schema. The schema specifies data, data relationships, data semantics, and consistency constraints on the data. The entityrelationship data model is based on a collection of basic objects, called entities, and of relationships among these objects. An entity is a “thing” or “object” in the real world that is distinguishable from other objects. For example, each person is an entity, and bank accounts can be considered entities. Entities are described in a database by a set of attributes. For example, the attributes account-number and balance describe one particular account in a bank. A relationship is an association among several entities. For example, a depositor relationship associates a customer with each of her accounts. The set of all entities of the same type and the set of all relationships of the same type are termed an entity set and a relationship set, respectively. Like the entity-relationship model, the object-oriented model is based on a collection of objects. An object contains values stored in instance variables within the object. An object also contains bodies of code that operate on the object. These bodies of code are called methods. The only way in which one object can access the data of another object is by invoking a method of that other object. This action is called sending a message to the object. Thus, the call interface of the methods of an object defines that object's externally visible part. The internal part of the object—the instance variables and method code—are not visible externally. The result is two levels of data abstraction, which are important to abstract away (hide) internal details of objects. Object-oriented data models also provide object references which can be used to identify (refer to) objects. In record-based models, the database is structured in fixed-format records of several types. Each record has a fixed set of fields. The three most widely accepted record-based data models are the relational, network, and hierarchical models. The latter two were widely used once, but are of declining importance. The relational model is very widely used. Databases based on the relational model are called relational databases. The relational model uses a collection of tables (called relations) to represent both data and the relationships among those data. Each table has multiple columns, and each column has a unique name. Each row of the table is called a tuple, and each column represents the value of an attribute of the tuple. 9.4 Evolution of Database Technology Ancient to modern: The origins go back to libraries, governmental, business, and medical records. There is a very long history of information storage, indexing, and retrieval. 1960's: Computers become cost effective for private companies along with increasing storage capability of computers. Two main data models were developed: network model (CODASYL) and hierarchical (IMS). Access to database is through low-level pointer operations linking records. Storage details depended on the type of data to be stored. Thus adding an extra field to your database requires rewriting the underlying access/modification scheme. Emphasis was on records to be processed, not overall structure of the system. A user would need to know the physical structure of the database in order to query for information. One major commercial success was SABRE system from IBM and American Airlines. 1970-72: E.F. Codd proposed relational model for databases in a landmark paper on how to think about databases. He disconnects the schema (logical organization) of a database from the physical storage methods. This system has been standard ever since. 1970's: Several camps of proponents argue about merits of these competing systems while the theory of databases leads to mainstream research projects. Two main prototypes for relational systems were developed during 1974-77. These provide nice example of how theory leads to best practice. Ingres: Developed at UCB. This ultimately led to Ingres Corp., Sybase, MS SQL Server, BrittonLee, Wang's PACE. This system used QUEL as query language. System R: Developed at IBM San Jose and led to IBM's SQL/DS & DB2, Oracle, HP's Allbase, Tandem's Non-Stop SQL. This system used SEQUEL as query language. The term Relational Database Management System (RDBMS) is coined during this period. 1976: P. Chen proposed the Entity-Relationship (ER) model for database design giving yet another important insight into conceptual data models. Such higher level modeling allows the designer to concentrate on the use of data instead of logical table structure. Early 1980's: Commercialization of relational systems begins as a boom in computer purchasing fuels DB market for business. Mid-1980's: SQL (Structured Query Language) becomes "intergalactic standard". DB2 becomes IBM's flagship product. Network and hierarchical models fade into the background, with essentially no development of these systems today but some legacy systems are still in use. Development of the IBM PC gives rise to many DB companies and products such as RIM, RBASE 5000, PARADOX, OS/2 Database Manager, Dbase III, IV (later Foxbase, even later Visual FoxPro), Watcom SQL. Early 1990's: An industry shakeout begins with fewer surviving companies offering increasingly complex products at higher prices. Much development during this period centers on client tools for application development such as PowerBuilder (Sybase), Oracle Developer, VB (Microsoft), etc. Client-server model for computing becomes the norm for future business decisions. Development of personal productivity tools such as Excel/Access (MS) and ODBC. This also marks the beginning of Object Database Management Systems (ODBMS) prototypes. Mid-1990's: The usable Internet/WWW appears. A mad scramble ensues to allow remote access to computer systems with legacy data. Client-server frenzy reaches the desktop of average users with little patience for complexity while Web/DB grows exponentially. Late-1990's: The large investment in Internet companies fuels tools market boom for Web/Internet/DB connectors. Active Server Pages, Front Page, Java Servlets, JDBC, Enterprise Java Beans, ColdFusion, Dream Weaver, Oracle Developer 2000, etc are examples of such offerings. Open source solution come online with widespread use of gcc, cgi, Apache, MySQL, etc. Online Transaction processing (OLTP) and online analytic processing (OLAP) comes of age with many merchants using point-of-sale (POS) technology on a daily basis. Early 21st century: Decline of the Internet industry as a whole but solid growth of DB applications continues. More interactive applications appear with use of PDAs, POS transactions, consolidation of vendors, etc. Three main (western) companies predominate in the large DB market: IBM (buys Informix), Microsoft, and Oracle. Future trends: Huge (terabyte) systems are appearing and will require novel means of handling and analyzing data. Large science databases such as genome project, geological, national security, and space exploration data. Data mining, data warehousing, data marts are a commonly used technique today. More of this in the future without a doubt. Smart/personalized shopping using purchase history, time of day, etc. Successors to SQL (and perhaps RDBMS) will be emerging in the future. Most attempts to standardize SQL successors have not been successful. SQL92, SQL2, SQL3 are still underpowered and more extensions are hard to agree upon. Most likely this will be overtaken by XML and other emerging techniques. XML with Java for databases is the current poster child of the "next great thing". Mobile database use is a product now coming to market in various ways. Distributed transaction processing is becoming the norm for business planning in many arenas. Probably there will be a continuing shakeout in the RDBMS market. Linux with Apache supporting mySQL (or even Oracle) on relatively cheap hardware is a major threat to high cost legacy systems of Oracle and DB2. Object Oriented Everything, including databases, seems to be always on the verge to sweeping everything before it. Object Database Management Group (ODMG) standards are proposed and accepted and maybe something comes from that. Ethical/security/use issues tend to be diminished at times but always come back. Should you be able to consult a database of the medical records/genetic makeup of a prospective employee? Should you be able to screen a prospective partner/lover for genetic diseases? Should amazon.com keep track of your book purchasing? Should there be a national database of convicted sex offenders/violent criminals/drug traffickers? Who is allowed to do Web tracking? How many times in the last six months did you visit a particular sex chat room/porn site/political satire site? Who should be able to keep or view such data? Who makes these decisions? Summary A database is a collection of information that is organized so that it can easily be accessed, managed, and updated. The software that allows us to perform these functions easily is called a Data Base Management System (DBMS). Using a DBMS files can be retrieved easily and effectively. A database has several characteristics that make it useful and irreplaceable. It enables concurrent use; it can describe and structure data, separate data from application, ensures data integrity, data persistence, and provide multiple data views. The database architecture is the set of specifications, rules, and processes that dictate how data is stored in a database and how data is accessed by components of a system. It includes data types, relationships, and naming conventions. The origins go back to libraries, governmental, business, and medical records. There is a very long history of information storage, indexing, and retrieval. Future trend of database will be focused on mobile database usage. Data mining, data warehousing, data marts are a commonly used technique in the future. Exercise: True or False 1. The relational model uses a collection of tables (called relations) to represent both data and the relationships amongst data files. 2. The entity-relationship model and the object-oriented model are based on a collection of objects. 3. The database design is the set of specifications, rules, and processes that dictate how data is stored in a database and how data is accessed by components of a system. 4. A database management system (DBMS) is designed to manage a large body of records. 5. Query By Example (QBE) is a graphical language for specifying queries. It is widely used in personal database systems, since it is much simpler than SQL for non-expert users. 6. A data view can consist of a subset of the stored data or from the stored data derived data (not explicitly stored). 7. A database contains metadata which describes the data itself. 8. The size of a database can only be from a few megabytes for personal databases, to gigabytes (a gigabyte is 1000 megabytes) for large corporate databases. 9. Answering different questions from different users with the same (base) data is a central aspect of a database. 10. A record is a collection of logically related fields. Answers: 1. False 2. True 3. False 4. False 5. True 6. True 7. True 8. False 9. False 10. True Short Essay questions: 1. Define field, record, file, and database briefly. 2. Name three DBMS packages. 3. What are the benefits of using a database in an information system? 4. What are the features of a DBMS? 5. Describe briefly the evolution of the database.