Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
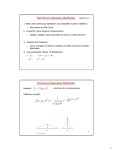
Gaussian Processes • Introduction • GP or Regression • GP for Classification • References Introduction _______________________________________ One common problem in classification is that of overfitting. Two possible approaches to avoid overfitting in classification are as follows: Limit the learning method to “simple” functions. Problem: we do not have flexible decision boundaries. Assign a probability to each function and pay more attention to those functions with higher probabilities. Problem: the space of functions may be infinite. Introduction _______________________________________ Gaussian Processes assign a probability to functions (efficiently). They are a combination of SVMs and a Bayesian approach to prediction. GP govern the properties of functions. prior probability Bayes Formula. P(w | D) = p( D | w) P(w) / p(D) posterior probability evidence likelihood Introduction _______________________________________ Figures obtained from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. Introduction _______________________________________ Figures obtained from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. Gaussian Processes • Introduction • GP or Regression • GP for Classification • References GP for Regression _______________________________________ Simple Bayesian Regression Problem. Consider a linear regression problem: Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Regression _______________________________________ Simple Bayesian Regression Problem. Consider a linear regression problem: Figures copied from Wikipedia. GP for Regression _______________________________________ We want to find the weight vector that best fits the data. In Bayesian analysis: Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Regression _______________________________________ For the likelihood: For the prior: Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Regression _______________________________________ Finally: Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Regression _______________________________________ To make a prediction f* on example x*, we average over all parameter values: Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Regression _______________________________________ Figures copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Regression _______________________________________ Figure copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Regression _______________________________________ We can expand the analysis by using a higher dimensional space (feature space). Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Regression _______________________________________ We now move to the space of functions (not weights). A Gaussian process is a collection of random variables where any subset of those variables has a joint Gaussian distribution. where, The random variables are the values of f(x) at location x. Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Regression _______________________________________ In the case of the linear model: This kernel guarantees smoothness in the family of functions. The covariance specifies a distribution over the functions. Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Regression _______________________________________ Example: generate a random Gaussian vector with the exponential covariance: Figure copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Regression _______________________________________ Prediction with no noise. We do not want the prior distribution, but rather the posterior distribution given a training set. The joint distribution of training and testing outputs is as follows: Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Regression _______________________________________ Prediction with no noise. What we want is the joint posterior distribution: Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Regression _______________________________________ Figures copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. Gaussian Processes • Introduction • GP or Regression • GP for Classification • References GP for Classification _______________________________________ In classification we can follow two directions: Use generative models, and assume a probability distribution for the likelihood and prior distributions. Problem: your assumption can be wrong. Use discriminative models, where no probability distribution is assumed. Problem: difficult to deal with outliers and missing values. Here we focus on discriminative models. Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Classification _______________________________________ The problem is more complicated because there is no analogous analytical solution as in the case of regression. To begin, assume a linear model such that f(x) = wt x Starting again with the “weight space”, remember we wish to compute the posterior distribution p(w | X, y). Assume a Gaussian prior distribution : Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Classification _______________________________________ Then the log posterior is as follows: And there is no simple analytical form for this (as in regression). Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Classification _______________________________________ We are going to place a prior GP over f(x) and then compress the function using a sigmoid function: Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Classification _______________________________________ Figures copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Classification _______________________________________ And we follow two steps: Compute the distribution of the output values in the test set: and then produce a prediction: Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Classification _______________________________________ Example Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. GP for Classification _______________________________________ Example Formulas copied from “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press. Gaussian Processes • Introduction • GP or Regression • GP for Classification • References References _______________________________________ “Gaussian Processes for Machine Learning” by Rasmussen and Williams, 2006, MIT Press.