Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
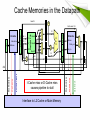
Lecture 19 • Today’s topics – Types of memory – Memory hierarchy 1 6.1 Introduction • Memory organization • A clear understanding of these ideas is essential for the analysis of system performance. 2 Types of Memory • There are two kinds of main memory: – Random access memory (RAM) • Dynamic RAM (DRAM) • Static RAM (SRAM) – Read-only-memory (ROM) • ROM does not need to be refreshed. • ROM is used to store permanent, or semi-permanent data that persists even while the system is turned off. 3 Random Access Memory RAM n Address Data m OE WE SRAM vs. DRAM • Static RAM (SRAM) for Cache – Requires 6-8 transistors per bit – Requires low power to retain bit • Dynamic RAM (DRAM) for Main Memory – One transistor + capacitor per bit – Must be re-written after being read – Must also be periodically refreshed • Each row can be refreshed simultaneously – Address lines are multiplexed • Upper half of address: Row Access Strobe (RAS) • Lower half of address: Column Access Strobe (CAS) Static RAM Storage Cell • Static RAM (SRAM): fast but expensive RAM • 6-Transistor cell with no static current Word line Vcc • Typically used for caches • Provides fast access time • Cell Implementation: – Cross-coupled inverters store bit bit bit Typical SRAM cell – Two pass transistors enable the cell to be read and written Dynamic RAM Storage Cell • Dynamic RAM (DRAM): slow, cheap, and dense memory • Typical choice for main memory Word line • Cell Implementation: – 1-Transistor cell (pass transistor) Pass Transistor – Trench capacitor (stores bit) • Bit is stored as a charge on capacitor • Must be refreshed periodically Capacitor bit – Because of leakage of charge from tiny capacitor Typical DRAM cell • Refreshing for all memory rows – Reading each row and writing it back to restore the charge DRAM Refresh Cycles • Refresh cycle is about tens of milliseconds • Refreshing is done for the entire memory • Each row is read and written back to restore the charge • Some of the memory bandwidth is lost to refresh cycles Voltage for 1 1 Written Refreshed Refreshed Refreshed Threshold voltage Voltage for 0 0 Stored Refresh Cycle Time Processor-Memory Performance Gap Performance Gap CPU Performance: 55% per year, slowing down after 2004 DRAM: 7% per year 1980 – No cache in microprocessor 1995 – Two-level cache on microprocessor The Need for Cache Memory • Widening speed gap between CPU and main memory – Processor operation takes less than 1 ns – Main memory requires more than 50 ns to access • Each instruction involves at least one memory access – One memory access to fetch the instruction – A second memory access for load and store instructions • Memory bandwidth limits the instruction execution rate • Cache memory can help bridge the CPU-memory gap • Cache memory is small in size but fast The Memory Hierarchy • Faster memory is more expensive than slower memory. • To provide the best performance at the lowest cost, memory is organized in a hierarchical fashion. • Small, fast storage elements are kept in the CPU, larger, slower main memory is accessed through the data bus. • Larger, (almost) permanent storage in the form of disk and tape drives is still further from the CPU. 11 Typical Memory Hierarchy • Registers are at the top of the hierarchy – Typical size < 1 KB – Access time < 0.5 ns Microprocessor • Level 1 Cache (8 – 64 KB) Registers – Access time: 1 ns • Main Memory (4 – 16 GB) – Access time: 50 – 100 ns • Disk Storage (> 200 GB) – Access time: 5 – 10 ms L2 Cache Memory Bus Main Memory I/O Bus Magnetic or Flash Disk Bigger – Access time: 3 – 10 ns Faster • L2 Cache (512KB – 8MB) L1 Cache 6.3 The Memory Hierarchy • Data are processed at CPU. • To access a particular piece of data, the CPU first sends a request to its nearest memory, usually cache. • If the data is not in cache, then main memory is queried. If the data is not in main memory, then the request goes to disk. • Once the data is located, then the data, and a number of its nearby data elements are fetched into cache memory. 13 Principle of Locality of Reference • Programs access small portion of their address space – At any time, only a small set of instructions & data is needed • Temporal Locality (in time) – If an item is accessed, probably it will be accessed again soon – Same loop instructions are fetched each iteration – Same procedure may be called and executed many times • Spatial Locality (in space) – Tendency to access contiguous instructions/data in memory – Sequential execution of Instructions – Traversing arrays element by element What is a Cache Memory ? • Small and fast (SRAM) memory technology – Stores the subset of instructions & data currently being accessed • Used to reduce average access time to memory • Caches exploit temporal locality by … – Keeping recently accessed data closer to the processor • Caches exploit spatial locality by … – Moving blocks consisting of multiple contiguous words • Goal is to achieve – Fast speed of cache memory access – Balance the cost of the memory system Cache Memories in the Datapath Imm Rd 0 1 BusW 32 0 1 2 3 1 0 D-Cache 0 Address 32 Data_out Data_in 32 Interface to L2 Cache or Main Memory Data Block D-Cache miss I-Cache miss or D-Cache miss causes pipeline to stall Block Address Instruction Block I-Cache miss clk Block Address 1 WB Data BusB ALUout A A L U 3 Rd4 RW 2 D RB BusA 32 B Address Rt 5 RA ALU result 32 Rd2 PC Instruction Rs 5 Register File I-Cache Instruction 0 1 E Rd3 Imm16 Almost Everything is a Cache ! • In computer architecture, almost everything is a cache! • Registers: a cache on variables – software managed • First-level cache: a cache on second-level cache • Second-level cache: a cache on memory • Memory: a cache on hard disk – Stores recent programs and their data – Hard disk can be viewed as an extension to main memory • Branch target and prediction buffer – Cache on branch target and prediction information Definitions • This leads us to some definitions. – A hit is when data is found at a given memory level. – A miss is when it is not found. – The hit rate is the percentage of time data is found at a given memory level. – The miss rate is the percentage of time it is not. – Miss rate = 1 - hit rate. – The hit time is the time required to access data at a given memory level. – The miss penalty is the time required to process a miss, including the time that it takes to replace a block of memory plus the time it takes to deliver the data to the processor. 18 Four Basic Questions on Caches • Q1: Where can a block be placed in a cache? – Block placement – Direct Mapped, Set Associative, Fully Associative • Q2: How is a block found in a cache? – Block identification – Block address, tag, index • Q3: Which block should be replaced on a miss? – Block replacement – FIFO, Random, LRU • Q4: What happens on a write? – Write strategy – Write Back or Write Through (with Write Buffer)