Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
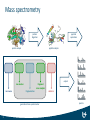
9th Benelux Bioinformatics Conference, 09/12/2014 Pattern mining of mass spectrometry quality control data Wout Bittremieux Mass spectrometry protein digestion protein sample peptide separation peptide sample output ion selector ion source fragment mass analyzer fragmentation generalized mass spectrometer 3 detector spectra Quality control metrics Derived from experimental data Instrument settings Walzer, M. et al. qcML: An exchange format for quality control metrics from mass spectrometry experiments. Molecular & Cellular Proteomics 13, 1905–1913 (2014). Bittremieux, W. et al. jqcML: An open-source Java API for mass spectrometry quality control data in the qcML format. Journal of Proteome Research 13, 3484–3487 (2014). Bittremieux, W. et al. Mass spectrometry quality control through instrument monitoring. In preparation. 4 Metrics derived from experimental data 5 Metrics derived from experimental data 6 Metrics derived from experimental data 7 Metrics derived from experimental data 8 Metrics derived from experimental data 9 Metrics derived from experimental data 10 Instrument settings 11 Instrument settings 12 Instrument settings 13 Instrument settings 14 Instrument settings 15 Instrument settings 16 High dimensionality 17 Previous approaches: Univariate 18 Previous approaches: Multivariate 19 Previous approaches: Multivariate 20 Our approach: Subspace clustering • 21 Try to find a suitable subset of the original feature space in which (dis)similar items can be found Experiment QC1 QC2 QC3 QC4 Exp1 5 6 1000 2000 Exp2 6 8 170 150 Exp3 7 6 140 160 Exp4 3000 400 160 110 Our approach: Subspace clustering • 22 Try to find a suitable subset of the original feature space in which (dis)similar items can be found Experiment QC1 QC2 QC3 QC4 Exp1 5 6 1000 2000 Exp2 6 8 170 150 Exp3 7 6 140 160 Exp4 3000 400 160 110 Our approach: Subspace clustering • 23 Try to find a suitable subset of the original feature space in which (dis)similar items can be found Experiment QC1 QC2 QC3 QC4 Exp1 5 ✓ 8 1000 2000 Exp2 ✓ 6 6 170 150 Exp3 7 6 140 160 Exp4 3000 400 160 110 Our approach: Subspace clustering • 24 Try to find a suitable subset of the original feature space in which (dis)similar items can be found Experiment QC1 QC2 QC3 QC4 Exp1 5 ✓ 8 1000 ✗ 170 2000 Exp2 ✓ 6 6 Exp3 7 6 140 160 Exp4 3000 400 160 110 ✗ 150 Our approach: Subspace clustering • 25 Try to find a suitable subset of the original feature space in which (dis)similar items can be found Experiment QC1 QC2 QC3 QC4 Exp1 5 6 1000 2000 Exp2 6 8 170 150 Exp3 7 6 140 160 Exp4 3000 400 160 110 Frequent itemset mining Aksehirli, E. et al. Cartification: A neighborhood preserving transformation for mining high dimensional data. in 13th IEEE International Conference on Data Mining 937–942 (2013). Naulaerts, S. et al. A primer to frequent itemset mining for bioinformatics. Briefings in Bioinformatics (2013). 26 Cartification Transactions consist of the k nearest neighbors on a single dimension for each item 10 11 20 9 7 8 16 6 12 4 8 5 3 4 1 2 27 0 4 8 12 16 20 Cartification Transactions consist of the k nearest neighbors on a single dimension for each item 10 1 11 20 9 7 8 16 6 12 4 8 5 3 4 1 2 28 0 4 8 12 16 20 2 3 Cartification Transactions consist of the k nearest neighbors on a single dimension for each item 10 1 2 3 1 2 3 11 20 9 7 8 16 6 12 4 8 5 3 4 1 2 29 0 4 8 12 16 20 Cartification Transactions consist of the k nearest neighbors on a single dimension for each item 10 1 2 3 1 2 3 2 3 4 11 20 9 7 8 16 6 12 4 8 5 3 4 1 2 30 0 4 8 12 16 20 Cartification 31 k-nearest neighbors in the first k-nearest neighbors in the dimension (X-axis) second dimension (Y-axis) 1 2 3 1 2 3 2 3 4 1 2 3 1 2 3 1 3 5 3 4 5 3 4 5 5 6 7 3 4 5 3 4 5 4 6 8 7 8 9 7 8 9 8 9 10 7 8 9 7 8 9 7 9 11 9 10 11 9 10 11 9 10 11 9 10 11 Cartification Frequent itemset mining: 4 maximal frequent itemsets with support = 4 10 11 20 9 7 8 16 6 12 4 8 5 3 4 1 2 32 0 4 8 12 16 20 CartiClus 1. Convert the high-dimensional database to a transaction database 2. Mine (maximal) frequent itemsets 3. Convert the itemsets to subspace clusters 4. Redo clustering projected on the detected subspaces (optional) 33 CartiClus 1.0 F1 score 0.8 0.6 0.4 0.2 0.0 CartiClus FIRES 1 34 PROCLUS 2 4 8 16 32 100 STATPC 200 SUBCLU Results Detected subspaces • • • Various quartiles of the same metric Related metrics: significant overlap with previous manually defined groups of co-occurring metrics New relationships between metrics to be validated using expert knowledge Detected clusters • Highly dependent on projected subspaces • Able to capture valid relationships between experiments 35 Results 36 Results 37 Conclusion Different sources of qualitative data • Metrics derived from experimental data • Instrument settings Subspace clustering to detect patterns in high-dimensional data • Univariate insufficient: metrics influence each other • Multivariate insufficient: global transformation 38 Conclusion Cartification: Neighborhood-preserving transformation • Finds relevant subspaces and discards noise • Fast Resulting subspace clustering • Able to identify relationships between various qualitative metrics • Clusters experiments exhibiting similar behavior 39 Acknowledgments ADReM / biomina Emin Aksehirli Bart Cuypers Aida Mrzic Stefan Naulaerts Pieter Meysman Bart Goethals Kris Laukens InSPECtor Hanny Willems Lennart Martens Dirk Valkenborg 40 biomina