Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Linear least squares (mathematics) wikipedia , lookup
Euclidean vector wikipedia , lookup
Rotation matrix wikipedia , lookup
System of linear equations wikipedia , lookup
Determinant wikipedia , lookup
Matrix (mathematics) wikipedia , lookup
Orthogonal matrix wikipedia , lookup
Non-negative matrix factorization wikipedia , lookup
Jordan normal form wikipedia , lookup
Cayley–Hamilton theorem wikipedia , lookup
Gaussian elimination wikipedia , lookup
Singular-value decomposition wikipedia , lookup
Covariance and contravariance of vectors wikipedia , lookup
Matrix multiplication wikipedia , lookup
Matrix calculus wikipedia , lookup
Perron–Frobenius theorem wikipedia , lookup
Eigenvalues and eigenvectors wikipedia , lookup
Principal Components of
Principal Component Analysis
Mark Stamp
Principal Components of PCA
1
Intro
PCA
based on linear algebra
Reveals “hidden” structure
o That is, structure may be non-obvious
Nice
geometric intuition
But, theory is somewhat challenging …
… and training is somewhat complex
However, scoring is fast and very easy
Principal Components of PCA
2
Background
Here,
we discuss the following
relevant background topics
o Linear algebra basics…
o …especially, eigenvalues and eigenvectors
o Basic statistics, covariance matrix
Main
topics are
o Principal Component Analysis (PCA)
o Singular Value Decomposition (SVD)
Principal Components of PCA
3
Linear Algebra Basics
Principal Components of PCA
4
Vectors
A
vector is a 1-d array of numbers
For example x = [1 2 0 5]
o Here, x is a row vector
Can
also have column vectors such as
Transpose
of a row vector is a column
vector and vice versa denoted xT
Principal Components of PCA
5
Dot Product of Vectors
Let
X = [x1 x2 … xm] and Y = [y1 y2 … ym]
Then dot product is defined as
o X Y = x1y1 + x2y2 + … + xmym
o Note that X Y is a number, not a vector
o Dot product is only defined for vectors of
same length
Euclidean
distance between X and Y,
sqrt((x1 - y1)2 + (x2 - y2)2 + … + (xm - ym)2)
Principal Components of PCA
6
Matrices
Matrix
A with n rows and m columns
o We sometimes write this as Anxm
Often
denote elements by A = {aij}
where i = 1,2,…,n and j = 1,2,…,m
Can add 2 matrices of same size
o Simply add corresponding elements
Matrix
multiplication not so obvious
o Next slide
Principal Components of PCA
7
Matrix Multiplication
Suppose
Anxm and Bsxt
Product AB is only defined if m = s
o And product C = AB is n by t, that is Cnxt
o Elements cij is the dot products of row i
of A with column j of B
Example
on next slide…
Principal Components of PCA
8
Matrix Multiplication Example
Suppose
Then
In
this example, AB is undefined
Principal Components of PCA
9
Scalars
Scalars
are numbers
o As opposed to vectors or matrices
Can
multiply vector or matrix by scalar
For example,
Here,
A is matrix and 3 is a scalar
Principal Components of PCA
10
Span
Given
a set of vectors, the span
consists of all linear combinations
What is a linear combination?
o Scalar multiplication and/or vector sums
The
span of vectors x and y consists
of all vectors ax + by
o Where a and b are scalars
Principal Components of PCA
11
Basis
Given
a set of vectors…
A basis is a minimal spanning set
o That is, no fewer vectors will span
For
example, [1 0] and [0 1] form a
basis for 2-d space
o Since any [x y] in 2-d space can be written
as [x y] = x [0 1] + y [1 0]
And
no single vector is sufficient
Principal Components of PCA
12
Eigenvalues and Eigenvectors
In
German, “eigen” means “proper” or
“characteristic”
Given a matrix A, an eigenvector is a
nonzero vector x satisfying Ax = λx
o And λ is the corresponding eigenvalue
For
eigenvector x, mult. by matrix A is
same as scalar multiplication by λ
So what?
Principal Components of PCA
13
Matrix Multiplication Example
Consider
the matrix
and x = [1 2]T
A=
Then
Ax = [6 3]T
Not an eigenvector
Can x and Ax align?
o Next slide…
Principal Components of PCA
x
Ax
14
Eigenvector Example
Consider
the matrix
and x = [1 1]T
A=
Then
Ax = [4 4]T = 4x
So, x is eigenvector
Ax
o Of matrix A
o With eigenvalue λ = 4
Principal Components of PCA
x
15
Finding Eigenvectors
Eigenvalues
roots of characteristic poly.
That is, eigenvalues λ satisfy
det(A - λI) = 0
Where I is the identity matrix
o Square matrix, 1 on diagonal, 0 elsewhere
And
det is the determinant
o In 2x2 case,
Principal Components of PCA
16
Eigenvalue Example
Consider
the matrix
Eigenvalues
Principal Components of PCA
computes from
17
Eigenvector Example
For
matrix A on previous slide,
λ1 = 2 and λ2 = -1
Eigenvector for λ1 is x = [1 0]T since
Any
multiple of x is also eigenvector,
with same eigenvalue
Principal Components of PCA
18
Eigenvectors
Why
are eigenvectors important?
o Can “decompose” A by eigenvectors
Matrix
A can be written in terms of
operations on its eigenvectors
o Actually, eigenvectors form a basis
o Bigger eigenvalues are most “influential”
o Thus, we can reduce the dimensionality
by ignoring small eigenvalues
Principal Components of PCA
19
Statistics 101
Principal Components of PCA
20
Mean, Variance, Covariance
Mean
is the average
μx = (x1 + x2 + … + xn) / n
Variance
measures “spread” about mean
σx2 = [(x1 – μx)2 + (x2 – μx)2 +…+ (xn – μx)2] / n
Let
X = (x1,…,xn) and Y = (y1,…,yn), then
cov(X,Y) = [(x1 – μx)(y1 – μy) +…+ (xn – μx)(yn – μy)] / n
If μx = μy= 0 then cov(X,Y) = (x1y1 +…+ xnyn) / n
Variance
is special case of covariance
σx2 = cov(X,X)
Principal Components of PCA
21
Covariance Examples
Things
simplify when the means are 0 …
If X = (-1,2,1,-2) and Y = (1,-1,1,-1)
o In this case, (x1,y1)=(-1,1), (x2,y2)=(2,-1), …
o Also, in this example, cov(X,Y) = 0
If
X = (-1,2,1,-2) and Y = (-1,1,1,-1)
o Then cov(X,Y) = 6
Sign
of covariance is slope of relationship
o Covariance of 0 implies uncorrelated
Principal Components of PCA
22
Covariance Matrix
Let
Amxn be matrix where column i is a
set of measurements for experiment i
o I.e., n experiments, each with m values
o Row of A is n measurements of same type
o And ditto for column of AT
Let
Cmxm = {cij} = 1/n AAT
o If mean of each measurement type is 0,
then C is known as covariance matrix
o Why do we call it covariance matrix?
Principal Components of PCA
23
Covariance Matrix C
Diagonal elements of C
o Variance within a measurement type
o Large variances are most interesting
o Best case? A few big ones, others are all small
Off-diagonal elements of C
o Covariance between all pairs of different types
o Nonzero redundancy, while 0 uncorrelated
o Best case? Off-diagonal elements are all 0
Ideally covariance matrix is diagonal
o And better yet, a few large elements on diagonal
Principal Components of PCA
24
Principal Component Analysis
Principal Components of PCA
25
Basic Example
Consider
data from an
experiment
y
o Suppose (x,y) values
o E.g., height and weight
The
“natural” basis
not most informative
x
o There is a “better”
way to view this…
Principal Components of PCA
26
Linear Regression
Blue
line is “best fit”
y
o Minimizes variance
o Essentially, reduces
2-d data to 1-d
Regression
line
o Accounts for error
and/or variation
x
o And it reduces
dimensionality
Principal Components of PCA
27
Principal Component Analysis
Principal
Component
Analysis (PCA)
y
o Length is magnitude
o Direction related to
actual structure
The
red basis
reveals structure
x
o Better than the
“natural” (x,y) basis
Principal Components of PCA
28
PCA: The Big Idea
In PCA, align basis with variances
o Do this by diagonalizing covariance matrix C
Many ways to diagonalize a matrix
PCA uses following for diagonalization
1. Choose direction with max variance
2. Find direction with max variance that is
orthogonal to all previously selected
3. Goto 2, until we run out of dimensions
Resulting vectors are principal components
Principal Components of PCA
29
Road Analogy
Suppose we explore a town in Western U.S.
using the following algorithm
1. Drive on the longest street
2. When we see another long street, drive on it
3. Continue for a while…
By driving a few streets, we get most of
the important information
o So, no need to drive all of the streets
o Thereby reducing “dimensionality” of problem
Principal Components of PCA
30
PCA Assumptions
1.
Linearity
o
o
2.
Large variances most “interesting”
o
o
3.
Change of basis is linear operation
But, some processes inherently non-linear
Large variance is “signal”, small is “noise”
But, may not be valid for some problems
Principal components are orthogonal
o
o
Makes problem efficiently solvable
But, non-orthogonal might be best in some cases
Principal Components of PCA
31
PCA
Problems in 2 dimensions are easy
o Best fit line (linear regression)
o Spread of data around best fit line
But real problems can have hundreds or
thousands (or more) dimensions
In higher dimensions, PCA can be used to…
o Reveal structure
o Reduce dimensionality, since unimportant
aspects can be ignored
Eigenvectors make PCA efficient & practical
Principal Components of PCA
32
PCA Success
Longer
red vector is
the “signal”
y
o More informative
than short vector
So,
we can ignore
short vector
o Short one is “noise”
x
o Reduces problem
from 2-d to 1-d
Principal Components of PCA
33
PCA Failure: Example 1
Periodically,
measure
position on Ferris
Wheel
o PCA results useless
o Angle θ has all the info
o But θ is nonlinear wrt
(x,y) basis
PCA
assumes linearity
Principal Components of PCA
34
PCA Failure: Example 2
Sometimes, important
info is not orthogonal
Then PCA not so good
o Since PCA basis vectors
must be orthogonal
A serious weakness?
o PCA is optimal for a large
class of problems
o Kernel methods provide a
possible workaround
Principal Components of PCA
35
PCA Failure: Example 3
In
PCA, we assume large variances
reveal the most interesting structure
In the analogy, we choose longest
road
But, there could be an interesting
street that is very short
In many towns, Main Street is most
important, but can be very short
o Downtown area may be small
Principal Components of PCA
36
Summary of PCA
1.
Organize data into m x n matrix A
o Where n is number of “experiments”
o And m “measurements” per experiment
2.
3.
4.
Subtract mean per measurement type
Form covariance matrix Cmxm = 1/n AAT
Compute eigenvalues and eigenvectors
of this covariance matrix C
o Why eigenvectors? Next slide please…
Principal Components of PCA
37
Why Eigenvectors?
Given
any square symmetric matrix C
Let E be matrix of eigenvectors
o I.e., ith column of E is ith eigenvector of C
By
well-known theorem, C = EDET
where D is diagonal, and ET = E-1
Which implies ETCE = D
o So, eigenvectors diagonalize matrix C
o And diagonal is ideal case wrt PCA
Principal Components of PCA
38
Why Eigenvectors?
We
cannot choose the matrix C
o Since it comes from the data
So,
C won’t be ideal in general
o Recall, ideal case is diagonal matrix
The
best we can do is diagonalize C…
o …to reveal “hidden” structure
Lots
of ways to diagonalize…
o Eigenvectors are easy way to do so
Principal Components of PCA
39
Technical Issue
There is a serious practical difficulty
o This issue arises in all applications we consider
Recall that A is m x n
o Where m is number of “measurements”
o And n is number of “experiments”
And C = 1/n AAT, so that C is m x m
Often, m is much, much bigger than n
Hence, C may be a HUGE matrix
o For training, we must find eigenvectors of C
Principal Components of PCA
40
More Efficient Training
Instead
of C = 1/n AAT, suppose that
we start with L = 1/n ATA
Note that L is n x n, while C is m x m
o Often, L is much, much smaller than C
Find
eigenvector x, eigenvalue λ of L
o That is, Lx = λx
And
ALx = 1/n AATAx = C(Ax) = λ(Ax)
o That is, Cy = λy where y = Ax
Principal Components of PCA
41
More Efficient Training
The
bottom line…
Let L = 1/n ATA and find eignevectors
o For each such eigenvector x, let y = Ax
o Then y is eigenvector of C = 1/n AAT with
same eigenvalue as x
This
may be more efficient (Why?)
Note we get n (out of m) eigenvectors
o But, only need a few eigenvectors anyway
Principal Components of PCA
42
Singular Value Decomposition
SVD
is fancy way to find eigenvectors
o Very useful and practical
Let
Y be an n x m matrix
Then SVD decomposes the matrix as
Y = USVT
Note that this works in general
o Implies it is a very general process
Principal Components of PCA
43
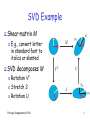
SVD Example
Shear
matrix M
o E.g., convert letter
in standard font to
italics or slanted
SVD
decomposes M
o Rotation VT
o Stretch S
o Rotation U
Principal Components of PCA
44
What Good is SVD?
SVD
is a (better) way to do PCA
o A way to compute eigenvectors
o Scoring part stays exactly the same
Let
Y be an n x m matrix
The SVD is Y = USVT, where
o U contains left “singular vectors” of Y
o V contains right “singular vectors” of Y
o S is diagonal, square roots of eigenvalues
Principal Components of PCA
45
SVD
Left
singular vectors contained in U
o That is, eigenvectors of YYT
o Note YYT is n x n
Right
singular vectors contained in V
o That is, eigenvectors of YTY
o Note that YTY is m x m
Can
we use these to find eigenvectors
of a covariance matrix?
Principal Components of PCA
46
SVD
1.
Start with m x n data matrix A
o Same matrix A as previously considered
2.
3.
Let Y = 1/√n AT, which is m x n matrix
Then YTY = 1/n AAT
o That is, YTY is covariance matrix C of A
4.
Apply SVD to Y = 1/√n AT
o Obtain Y = USVT
5.
Columns of V are eigenvectors of C
Principal Components of PCA
47
Numerical Example
Principal Components of PCA
48
Example: Training
E.g.,
training set of 4 family viruses
V1 = (2, 1, 0, 3, 1, 1)
V3 = (1, 0, 3, 3, 1, 1)
For
V2 = (2, 3, 1, 2, 3, 0)
V4 = (2, 3, 1, 0, 3, 2)
simplicity, assume means are all 0
Form matrix
A = [V1 V2 V3 V4] =
Principal Components of PCA
49
Example: Training
Next,
form the matrix
L = ATA =
Note
that L is 4x4, not 6x6
Compute eigenvalues of L matrix
λ1 = 68.43, λ2 = 15.16, λ3 = 4.94, λ4 = 2.47
Principal Components of PCA
50
Example: Training
Corresponding
eigenvectors are
v1 = ( 0.41, 0.60, 0.41,
v2 = (-0.31, 0.19, -0.74,
v3 = (-0.69, -0.26, 0.54,
v4 = ( 0.51, -0.73, -0.05,
0.55)
0.57)
0.41)
0.46)
Eigenvectors
of covariance matrix C
are given by ui = Avi for i = 1,2,3,4
o Eigenvalues don’t change
Principal Components of PCA
51
Example: Training
Compute
eigenvectors of C to find
u1 = ( 3.53, 3.86, 2.38, 3.66, 4.27, 1.92)
u2 = ( 0.16, 1.97,-1.46,-2.77, 1.23, 0.09)
u3 = (-0.54,-0.24, 1.77,-0.97, 0.30, 0.67)
u4 = ( 0.43,-0.30,-0.42,-0.08,-0.35, 1.38)
Normalize
by dividing by length
μ1 = ( 0.43, 0.47, 0.29, 0.44, 0.52, 0.23)
μ2 = ( 0.04, 0.50,-0.37,-0.71, 0.32, 0.02)
μ3 = (-0.24,-0.11, 0.79,-0.44, 0.13, 0.30)
μ4 = ( 0.27,-0.19,-0.27,-0.05,-0.22, 0.88)
Principal Components of PCA
52
Example: Training
Scoring
matrix is Δ = [Ω1 Ω2 Ω3 Ω4]
Where Ωi = [Vi μ1 Vi μ2 Vi μ3 Vi μ4]T
o For i = 1,2,3,4, where “ ” is dot product
In
this example, we find
Δ=
Principal Components of PCA
53
Example: Training
Spse
we only use 3 most significant
eigenvectors for scoring
o Truncate last row of Δ on previous slide
And
the scoring matrix becomes
Δ=
So,
no need to compute last row
Principal Components of PCA
54
Scoring
How
do we use Δ to score a file?
Let X = (x1,x2,…,x6) be a file to score
Compute its weight vector
W = [w1 w2 w3]T = [X μ1 X μ2 X μ3]T
Then score(X) = min d(W,Ωi)
o Where d(X,Y) is Euclidean distance
o Recall that Ωi are columns of Δ
Principal Components of PCA
55
Example: Scoring (1)
Suppose
Then
X = V1 = (2, 1, 0, 3, 1, 1)
W = [X μ1 X μ2 X μ3]T = [3.40 -1.21 -1.47]T
That
is, W = Ω1 and hence score(X) = 0
So, minimum occurs when we score an
element in training set
o This is a good thing…
Principal Components of PCA
56
Example: Scoring (2)
Suppose
X = (2, 3, 4, 4, 3, 2)
Then W = [X μ1 X μ2 X μ3]T=[7.19,-
1.75,1.64]T
And
d(W,Ω1) = 4.93, d(W,Ω2) = 3.96,
d(W,Ω3) = 4.00, d(W,Ω4) = 4.81
And
hence, score(X) = 3.96
o So score of a “random” X is “large”
o This is also a good thing
Principal Components of PCA
57
Comparison with SVD
Suppose
we had used SVD…
What would change in training?
o Would have gotten μi directly from SVD…
o …instead of getting eigenvectors ui, then
normalizing them to get μi
o In this case, not too much difference
And
what about the scoring?
o It would be exactly the same
Principal Components of PCA
58
Conclusions
Eigenvector
techniques very powerful
Theory is fairly complex…
Training is somewhat involved…
But, scoring is simple, fast, efficient
Next, we consider 3 applications
o Facial recognition (eigenfaces)
o Malware detection (eigenviruses)
o Image spam detection (eigenspam)
Principal Components of PCA
59
References: PCA
J. Shlens, A tutorial on principal component
analysis, 2009
M. Turk and A. Petland, Eigenfaces for
recognition, Journal of Cognitive
Neuroscience, 3(1):71-86, 1991
Principal Components of PCA
60





































































![Fodor I K. A survey of dimension reduction techniques[J]. 2002.](http://s1.studyres.com/store/data/000160867_1-28e411c17beac1fc180a24a440f8cb1c-150x150.png)
