Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
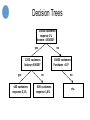
Some working definitions…. • ‘Data Mining’ and ‘Knowledge Discovery in Databases’ (KDD) are used interchangeably • Data mining = – the discovery of interesting, meaningful and actionable patterns hidden in large amounts of data • Multidisciplinary field originating from artificial intelligence, pattern recognition, statistics, machine learning, econometrics, …. Data mining is a process… • Business objectives • Model Development – – – – – Model objective Data collection & preparation Model construction Model evaluation Combining models with business knowledge into decision logic • Model / decision logic deployment • Model / decision logic monitoring Data mining is a process… a marketing example • Business objectives – • Cross sell MMS bundle to lapsed users / non users Model Development – Model objective • – Data collection & preparation • – Target the top 30% and randomly test two propositions (50 MMS for 5Euro; 100MMS for 7.50Euro) across two channel (Direct mail and SMS) Model / decision logic deployment – • Evaluate predictive power on 70% data for model development and 30% test set Combining models with business knowledge into decision logic • • Build various models to predict MMS Bundle MAY or JUNE or JULY = ‘N’ on 70% if the data Model evaluation • – All fields for all active customers as of end APR05; remove all customers with MMS bundle in NOV04APR05; Left join MMS Bundle field from MAY05, JUNE05, JULY05 Model construction • – For consumers with no MMS bundle in past 6 months, predict MMS bundle ownership yes/no in next three months Run the campaign Model / decision logic monitoring – – Compare predctions against actual response to evaluate model quality and robustness What propositions / channels work best Data mining tasks • Undirected, explorative, descriptive, ‘unsupervised’ data mining – Matching & search – Profile & rule extraction – Clustering & segmentation; dimension reduction • Directed, predictive, ‘supervised’ data mining – Predictive modeling Data mining task example: Clustering & segmentation Data mining task example: Clustering & segmentation Start Looking Glass Source: Sentient Information Systems (www.sentient.nl) Tussenresultaat looking glass Source: Sentient Information Systems (www.sentient.nl) Resultaat Looking Glass Source: Sentient Information Systems (www.sentient.nl) Resultaat Looking Glass Source: Sentient Information Systems (www.sentient.nl) Data mining task example: predictive modeling Past experience Data Behaviour Good Bad Bad Case A Good Case B Score Model Case A 7 Case B 4 10 9 8 7 6 5 4 3 2 1 Better business Worse business Data mining task example: predictive modeling Income Age Children 60K 38 2 30K 23 1 30K 29 0 ... ... ... 120K 55 2 Collected data Data mining task example: predictive modeling Income Age Children Status Value Score 60K 38 2 Good 100 12 30K 23 1 Good 45 2 30K 29 0 Bad -80 -24 ... ... ... ... ... ... 120K 55 2 Bad -40 -5 score = (0 x Income) + (-1 x Age) + (25 x Children) Data mining techniques for predictive modeling • • • • • • Linear and logistic regression Decision trees Neural Networks Nearest Neighbor Genetic Algorithms …. Linear Regression Models score = (0 x Income) + (-1 x Age) + (25 x Children) Regression in pattern space Only a single line available in pattern space to separate classes income Class ‘square’ Class ‘circle’ age Decision Trees 20000 customers response 1% Income >150000? yes no 1200 customers balance>50000? yes 400 customers response 0,1% 18800 customers Purchases >10? no 800 customers response 1,8% no etc. Decision Trees in Pattern Space Line pieces perpendicular to axes income Each line is a split in the tree, two answers to a question age Decision Trees in Pattern Space Goal classifier is to seperate classes (circle, square) on the basis of attribute age and income Each line corresponds to a split in the tree weight Decision areas are ‘tiles’ in pattern space age Nearest Neighbour • Data itself is the classification model, so no abstraction like a tree etc. • For a given instance x, search the k instances that are most similar to x • Classify x as the most occurring class for the k most similar instances Nearest Neighbor in Pattern Space Classification = new instance Any decision area possible fe weight Condition: enough data available fe age Nearest Neighbor in Pattern Space Voorspellen Any decision area possible bvb. weight Condition: enough data available f.e. age Example classification algorithm 3: Neural Networks • Inspired by neuronal computation in the brain (McCullough & Pitts 1943 (!)) invoer: bvb. klantkenmerken uitvoer: bvb. respons • Input (attributes) is coded as activation on the input layer neurons, activation feeds forward through network of weighted links between neurons and causes activations on the output neurons (for instance diabetic yes/no) • Algorithm learns to find optimal weight using the training instances and a general learning rule. Neural Networks • Example simple network (2 layers) age weightage body_mass_index Weightbody mass index Probability of being diabetic • Probability of being diabetic = f (age * weightage + body mass index * weightbody mass index) Neural Networks in Pattern Space Classification Simpel network: only a line available (why?) to seperate classes Multilayer network: f.e. weight Any classification boundary possible f.e. age Dilbert’s Perspective on Data Mining