Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Contents
1 Introduction
1.1 What motivated data mining? Why is it important? . . . . . . . . . . .
1.2 So, what is data mining? . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.3 Data mining | on what kind of data? . . . . . . . . . . . . . . . . . . .
1.3.1 Relational databases . . . . . . . . . . . . . . . . . . . . . . . . .
1.3.2 Data warehouses . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.3.3 Transactional databases . . . . . . . . . . . . . . . . . . . . . . .
1.3.4 Advanced database systems and advanced database applications
1.4 Data mining functionalities | what kinds of patterns can be mined? . .
1.4.1 Concept/class description: characterization and discrimination .
1.4.2 Association analysis . . . . . . . . . . . . . . . . . . . . . . . . .
1.4.3 Classication and prediction . . . . . . . . . . . . . . . . . . . .
1.4.4 Clustering analysis . . . . . . . . . . . . . . . . . . . . . . . . . .
1.4.5 Evolution and deviation analysis . . . . . . . . . . . . . . . . . .
1.5 Are all of the patterns interesting? . . . . . . . . . . . . . . . . . . . . .
1.6 A classication of data mining systems . . . . . . . . . . . . . . . . . . .
1.7 Major issues in data mining . . . . . . . . . . . . . . . . . . . . . . . . .
1.8 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
3
3
6
8
9
11
12
13
13
13
14
15
16
16
17
18
19
21
Contents
2 Data Warehouse and OLAP Technology for Data Mining
2.1 What is a data warehouse? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2 A multidimensional data model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2.1 From tables to data cubes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2.2 Stars, snowakes, and fact constellations: schemas for multidimensional databases
2.2.3 Examples for dening star, snowake, and fact constellation schemas . . . . . . . .
2.2.4 Measures: their categorization and computation . . . . . . . . . . . . . . . . . . .
2.2.5 Introducing concept hierarchies . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2.6 OLAP operations in the multidimensional data model . . . . . . . . . . . . . . . .
2.2.7 A starnet query model for querying multidimensional databases . . . . . . . . . . .
2.3 Data warehouse architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.3.1 Steps for the design and construction of data warehouses . . . . . . . . . . . . . .
2.3.2 A three-tier data warehouse architecture . . . . . . . . . . . . . . . . . . . . . . . .
2.3.3 OLAP server architectures: ROLAP vs. MOLAP vs. HOLAP . . . . . . . . . . . .
2.3.4 SQL extensions to support OLAP operations . . . . . . . . . . . . . . . . . . . . .
2.4 Data warehouse implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.4.1 Ecient computation of data cubes . . . . . . . . . . . . . . . . . . . . . . . . . .
2.4.2 Indexing OLAP data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.4.3 Ecient processing of OLAP queries . . . . . . . . . . . . . . . . . . . . . . . . . .
2.4.4 Metadata repository . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.4.5 Data warehouse back-end tools and utilities . . . . . . . . . . . . . . . . . . . . . .
2.5 Further development of data cube technology . . . . . . . . . . . . . . . . . . . . . . . . .
2.5.1 Discovery-driven exploration of data cubes . . . . . . . . . . . . . . . . . . . . . .
2.5.2 Complex aggregation at multiple granularities: Multifeature cubes . . . . . . . . .
2.6 From data warehousing to data mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.6.1 Data warehouse usage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.6.2 From on-line analytical processing to on-line analytical mining . . . . . . . . . . .
2.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
3
3
6
6
8
11
13
14
15
18
19
19
20
22
24
24
25
30
30
31
32
32
33
36
38
38
39
41
Contents
3 Data Preprocessing
3.1 Why preprocess the data? . . . . . . . . . . . . . . . . . . . . . . . . . .
3.2 Data cleaning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.2.1 Missing values . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.2.2 Noisy data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.2.3 Inconsistent data . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.3 Data integration and transformation . . . . . . . . . . . . . . . . . . . .
3.3.1 Data integration . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.3.2 Data transformation . . . . . . . . . . . . . . . . . . . . . . . . .
3.4 Data reduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.4.1 Data cube aggregation . . . . . . . . . . . . . . . . . . . . . . . .
3.4.2 Dimensionality reduction . . . . . . . . . . . . . . . . . . . . . .
3.4.3 Data compression . . . . . . . . . . . . . . . . . . . . . . . . . .
3.4.4 Numerosity reduction . . . . . . . . . . . . . . . . . . . . . . . .
3.5 Discretization and concept hierarchy generation . . . . . . . . . . . . . .
3.5.1 Discretization and concept hierarchy generation for numeric data
3.5.2 Concept hierarchy generation for categorical data . . . . . . . . .
3.6 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
3
3
5
5
6
7
8
8
8
10
10
11
13
14
19
19
23
25
Contents
4 Primitives for Data Mining
4.1 Data mining primitives: what denes a data mining task? . . . . . . . . . .
4.1.1 Task-relevant data . . . . . . . . . . . . . . . . . . . . . . . . . . . .
4.1.2 The kind of knowledge to be mined . . . . . . . . . . . . . . . . . . .
4.1.3 Background knowledge: concept hierarchies . . . . . . . . . . . . . .
4.1.4 Interestingness measures . . . . . . . . . . . . . . . . . . . . . . . . .
4.1.5 Presentation and visualization of discovered patterns . . . . . . . . .
4.2 A data mining query language . . . . . . . . . . . . . . . . . . . . . . . . . .
4.2.1 Syntax for task-relevant data specication . . . . . . . . . . . . . . .
4.2.2 Syntax for specifying the kind of knowledge to be mined . . . . . . .
4.2.3 Syntax for concept hierarchy specication . . . . . . . . . . . . . . .
4.2.4 Syntax for interestingness measure specication . . . . . . . . . . . .
4.2.5 Syntax for pattern presentation and visualization specication . . .
4.2.6 Putting it all together | an example of a DMQL query . . . . . . .
4.3 Designing graphical user interfaces based on a data mining query language .
4.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
3
3
4
6
7
10
12
12
15
15
18
20
20
21
22
22
Contents
5 Concept Description: Characterization and Comparison
5.1 What is concept description? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.2 Data generalization and summarization-based characterization . . . . . . . . . . .
5.2.1 Data cube approach for data generalization . . . . . . . . . . . . . . . . . .
5.2.2 Attribute-oriented induction . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.2.3 Presentation of the derived generalization . . . . . . . . . . . . . . . . . . .
5.3 Ecient implementation of attribute-oriented induction . . . . . . . . . . . . . . .
5.3.1 Basic attribute-oriented induction algorithm . . . . . . . . . . . . . . . . . .
5.3.2 Data cube implementation of attribute-oriented induction . . . . . . . . . .
5.4 Analytical characterization: Analysis of attribute relevance . . . . . . . . . . . . .
5.4.1 Why perform attribute relevance analysis? . . . . . . . . . . . . . . . . . . .
5.4.2 Methods of attribute relevance analysis . . . . . . . . . . . . . . . . . . . .
5.4.3 Analytical characterization: An example . . . . . . . . . . . . . . . . . . . .
5.5 Mining class comparisons: Discriminating between dierent classes . . . . . . . . .
5.5.1 Class comparison methods and implementations . . . . . . . . . . . . . . .
5.5.2 Presentation of class comparison descriptions . . . . . . . . . . . . . . . . .
5.5.3 Class description: Presentation of both characterization and comparison . .
5.6 Mining descriptive statistical measures in large databases . . . . . . . . . . . . . .
5.6.1 Measuring the central tendency . . . . . . . . . . . . . . . . . . . . . . . . .
5.6.2 Measuring the dispersion of data . . . . . . . . . . . . . . . . . . . . . . . .
5.6.3 Graph displays of basic statistical class descriptions . . . . . . . . . . . . .
5.7 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.7.1 Concept description: A comparison with typical machine learning methods
5.7.2 Incremental and parallel mining of concept description . . . . . . . . . . . .
5.7.3 Interestingness measures for concept description . . . . . . . . . . . . . . .
5.8 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
i
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
1
1
2
3
3
7
10
10
11
12
12
13
15
17
17
19
20
22
22
23
25
28
28
30
30
31
Contents
6 Mining Association Rules in Large Databases
6.1 Association rule mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.1.1 Market basket analysis: A motivating example for association rule mining . . . . . . . . . . . .
6.1.2 Basic concepts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.1.3 Association rule mining: A road map . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.2 Mining single-dimensional Boolean association rules from transactional databases . . . . . . . . . . . .
6.2.1 The Apriori algorithm: Finding frequent itemsets . . . . . . . . . . . . . . . . . . . . . . . . . .
6.2.2 Generating association rules from frequent itemsets . . . . . . . . . . . . . . . . . . . . . . . . .
6.2.3 Variations of the Apriori algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.3 Mining multilevel association rules from transaction databases . . . . . . . . . . . . . . . . . . . . . .
6.3.1 Multilevel association rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.3.2 Approaches to mining multilevel association rules . . . . . . . . . . . . . . . . . . . . . . . . . .
6.3.3 Checking for redundant multilevel association rules . . . . . . . . . . . . . . . . . . . . . . . . .
6.4 Mining multidimensional association rules from relational databases and data warehouses . . . . . . .
6.4.1 Multidimensional association rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.4.2 Mining multidimensional association rules using static discretization of quantitative attributes
6.4.3 Mining quantitative association rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.4.4 Mining distance-based association rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.5 From association mining to correlation analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.5.1 Strong rules are not necessarily interesting: An example . . . . . . . . . . . . . . . . . . . . . .
6.5.2 From association analysis to correlation analysis . . . . . . . . . . . . . . . . . . . . . . . . . .
6.6 Constraint-based association mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.6.1 Metarule-guided mining of association rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.6.2 Mining guided by additional rule constraints . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
3
3
3
4
5
6
6
9
10
12
12
14
16
17
17
18
19
21
23
23
23
24
25
26
29
Contents
7 Classication and Prediction
7.1 What is classication? What is prediction? . . . . . . . . . . . . . . . . . .
7.2 Issues regarding classication and prediction . . . . . . . . . . . . . . . . . .
7.3 Classication by decision tree induction . . . . . . . . . . . . . . . . . . . .
7.3.1 Decision tree induction . . . . . . . . . . . . . . . . . . . . . . . . . .
7.3.2 Tree pruning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.3.3 Extracting classication rules from decision trees . . . . . . . . . . .
7.3.4 Enhancements to basic decision tree induction . . . . . . . . . . . .
7.3.5 Scalability and decision tree induction . . . . . . . . . . . . . . . . .
7.3.6 Integrating data warehousing techniques and decision tree induction
7.4 Bayesian classication . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.4.1 Bayes theorem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.4.2 Naive Bayesian classication . . . . . . . . . . . . . . . . . . . . . .
7.4.3 Bayesian belief networks . . . . . . . . . . . . . . . . . . . . . . . . .
7.4.4 Training Bayesian belief networks . . . . . . . . . . . . . . . . . . . .
7.5 Classication by backpropagation . . . . . . . . . . . . . . . . . . . . . . . .
7.5.1 A multilayer feed-forward neural network . . . . . . . . . . . . . . .
7.5.2 Dening a network topology . . . . . . . . . . . . . . . . . . . . . . .
7.5.3 Backpropagation . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.5.4 Backpropagation and interpretability . . . . . . . . . . . . . . . . . .
7.6 Association-based classication . . . . . . . . . . . . . . . . . . . . . . . . .
7.7 Other classication methods . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.7.1 k-nearest neighbor classiers . . . . . . . . . . . . . . . . . . . . . .
7.7.2 Case-based reasoning . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.7.3 Genetic algorithms . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.7.4 Rough set theory . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.7.5 Fuzzy set approaches . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.8 Prediction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.8.1 Linear and multiple regression . . . . . . . . . . . . . . . . . . . . .
7.8.2 Nonlinear regression . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.8.3 Other regression models . . . . . . . . . . . . . . . . . . . . . . . . .
7.9 Classier accuracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.9.1 Estimating classier accuracy . . . . . . . . . . . . . . . . . . . . . .
7.9.2 Increasing classier accuracy . . . . . . . . . . . . . . . . . . . . . .
7.9.3 Is accuracy enough to judge a classier? . . . . . . . . . . . . . . . .
7.10 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
3
3
5
6
7
9
10
11
12
13
15
15
16
17
19
19
20
21
21
24
25
27
27
28
28
28
29
30
30
32
32
33
33
34
34
35
&( *' )+-,/.1032*4658 !7*9(#4:"$0: ;<=.1>/.17@?4:2@4BAC'='C'=''D''''D'''D''=''D'''D''''D''='C'='''D'''D'''='C'=''D'''' % E
&(' FHG3(& ' ?F(IJ'@) ;#4LK1VLM2@N4:[email protected]@2@7X>P.1<:5O2@0Q7@92Y;#4:4Z0Q;#.T<:>J2@>N[RS4:[email protected]>J.12@[email protected]?<Q4:2@2@0:4D2Y;'4\!']^'D;_'.14:'9('D<:2@>'R'=0:',(;a'D`b'9J'.1'D7@2@0$'?a'KTMZ'5O'D7@9'4:0Q'=;#<:'C2@>'=Rc''''D'D'''''D'D'''''='='C'C'='='''D'D'''''''' Ud
(&(& '' F(F('e'eFE f$no>2@0Q>J;#.1<:<Qgh?S.T7Yghi$4B.T5<:.12X.17@;kN[7@;#gh4p.1<Q2j'=.Tk'C7@'=;#4l''D'D'''''''D'D'''''D'D'''='='''D'D'''''D'D'''''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D'''''''' mq
(&(& '' F(F(''eUd y3rs.1Kh<:W[2X.T2*k>/[email protected];#7$4Zt1KhKT<OMzNW[2@>J2Y{.17$;tNv.10$>J?N[IJ<O;#.140:2@'DKTiu'4O5#'.1'7@;'DNv'gh.1'<:2X'D.Tk'7@'=;#4w''D'D'''''D'D'''''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D'''''''
' )|x
&(&('' UEH}l.1#5Q< .T0:2@0:0:;#2@RbKbKh><Q2@2*>~_RD.10:WS2@Kb;>0:,KTKMzNW^4.#'OKh'<3'=5O7@'C9'=4:0Q';#<:'D2@>'R['WS';#0Q'D,'KN'4c'D'''='='''D'D'''''D'D'''''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D'''''''
'
))hF)
&(&('' U/U/@'e' F) 3.T7X.T<:4:0:4:2@0Q2X5#2*Kb.T>72@IJ>.1RD<Q0:W[2@0:;#2@0:Kb,>K2@>NRD4WS2@>[;7j0:.T,<:KRbN;4_N(\.1b0Biu.TW[kJ.1;4Q.1;#>(44
\.TM <:>JKhN^WbiubW[i$WS;N;KbN2jKhN2X4cN4'D0QKS''='C}='=s'}='rL'D''''D'D'''''='='C'C'='='''D'D'''''''
'
))Fd
&(' d&(s' 2*d(;'@B< ) .1<O5Q,}L2XRh5#Rb.177*KbWSWS;#;#0Q<O,.1K0Q2*Ngb4S;6'.1>J'N['=N'C2@g'=2*4Q'2@gh'D;6',(2*';<B'.1'D<O5Q',2X'5#.1'D7'5O7@'=94:'0Q;#'D<:2@'>R''D'D'''''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D'''''''
'
))mm
&(&('' d(d('e'eFE on f:L6D\\[email protected]:;#>J<Q5O2@;>N[RSf$0:;4Q<B2*.1>(0QRS2@gh6;asI;<QN;#4:9J;5O>2@>0O.1RS0Q2*.Tgb>J;#NS43'7@9'D4Q0:';#'<Q2@>'DR'9'4:2@'>RS'D's'=2@;#<B'C.T'=<B5Q',2@';#4'D'''''D'D'''''='='C'C'='='''D'D'''''''
'
))&q
&(' m&(&(VL'' ;#d(m(>''@U) 4Q2@0$?hV$i kJs3n .T}=4:;3]PN^}=o5OrC7@!9\14Q}-0:;#<QNrD2*;#>(\(>RS}4Q2@WS0$,?h;2@i$0:;#kJ,<B.T.TK4:<BN;5Q4SN,2X5O'5#[email protected]'7z4Q'0:5O;#7@'D9<Q2@4Q'>0:R;#'<QWS2*'D>(;#R'0Q,'=.1K7@'RbNDKh'DkJ<:2@'.T0Q4:,';W
NC'DKh9'>4:'2@>5O'KbR>'DN>'?;>J5O'=0Q.1;'CW[N'=2X<Q5;#'RhWS'2@KbK'D>N4';7*2@'>2*'D0QR ,a'4Q''9'='=5O'C'C2@;#'='=>''0:7@?D'D'D,(''2*'Rb', ''''FFh|)
&(&('' m(m('e'eFE NV;#> GLr4:2@f:0$? !L\J'L'\J<B3N'D;7@'<:92@4Q>'0:RS;#'=<Q2*'C>(KhR'=2@>'kJ0:.14'D4QG;'N[K'Khf:'N>P;#'D>N0:';#2>M'?[4Q2@'D0$0:?,';DN'=2@34:'0Q7@9<:'D2@4:k'0Q9;#'<:0Q2@2@'D>Kh>RS'M'90:>J'<:9/5O'D0Q5O2*0:'Kb9><Q'=4;'C'='='='''''''D'D'D'''''''D'D'D'''''''='='='C'C'C'='='=''''D'D'D''''''''''''FFhFhEF)
&(' q&(' <Qq(2X'@Nb) iuk/.14:G;_Nf:r685 7* 9(4:\0:}l;<:2@>0OR.10QWS2*4Q;0:2X0:5#,.TK7Nf$4>MKh'D<QW'.T'0:2@'Kh>S'D''<Q2XN'D'}6I('=I'<:K'D.h'5Q,''D'D'''''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D''''''''F1FhUd
&(&('' q(q('e'eFE +._f:gb¡;3 6 7@94:\/0Q3;#<7*9(\4:30:;7@9<:2@4Q>0:R;#<Q,2@>2@RhR,9i¢N4:2@2@>W[R;#>4:._2@ghKb;#>[email protected];#074Q0QIJ<B.1.h>(58;=4$M'DKb<:'W'.T0:'D2@Kh'> ''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D''''''''FhFh&m
&(&('' &
^
]
K
N
;
Y
7
$
i
J
k
T
.
:
4
;
^
N
5
O
@
7
9
Q
4
:
0
#
;
Q
<
*
2
(
>
S
R
S
W
;
:
0
,
K
N
£
4
'
'
'
D
'
'
'
D
'
'
=
'
'
D
'
'
'
D
'
'
'
'
D
'
'
=
'
C
'
=
'
'
'
D
'
'
'
D
'
'
'
=
'
C
'
=
'
'
D
'
'
'
'
'
h
F
x
x&(L' 9x(0Q'@)7*2@;#<6.T0B>J.1.10Q7@2@?4:0:4:2X@2 #5 4P.T7!'.1'I'DI(<:'K.b'5Q'=,S'CM Kh'=<3'Kh9'D0Q'7*2@;#'<6'N;#'D0:';58'0:2@'DKh>¤''='='''D'D'''''D'D'''''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D''''''''FhEhx|
&(&('' x(x('e'eFE VLVL2@;#4:g0O2X.1.1>J0Q582@KhO; >iuk/i$kJ.14:.1;_4QN^;NKhKb990Q7@0:2*7@;2@<
;#<6NN;0:;;0:5O;0Q5O2@0QKh2@Kh> >c'''''D'D'''='='''D'D'''''D'D'''''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D''''''''EEhF)
&('*)_|9(WSW.T<:?¥'''D' ''D'''='C'=''D''''D'''D''=''D'''D''''D''='C'='''D'''D'''='C'=''D''''EhE
)
*1 2436587:9'7<;>=@?BA4CD=FEGABHI!9J#"=F9$KJ%'LN&(M'*?BEG)AOK+-ABP-,*./7<,9*QGABHR9S=@?'TU9=F?BVQGABQWH@XWYZHRP-[*?47]\_^8=FE`=ba#cRd`7De`EGQ!28282f28282f282822g2282f2828282
*1*1 24243I3I2B2ml3 T#5inR7<9'nI;G7<7<;`n=F?B=FABEGC/AB=FHIEj9JA4HI=F9-9HIKJ9J=@Qj['EG[';j;jMSHDe`\oEGM*ABPp;G7/=FKEGABK'HI9b=FE`AB=k9-Qj[S28=F2fEjAO28=F?q2=F289K-2f28Pr28M*?42fEjAB28Pr287/K28AO=82fK'28=F2E`=f2gnI27<9'287<28;`=F2f?BAB28C/=F28EjA42fHI9s282828222g2g2228282f2f28282828282822
*1*1 24243I3I2m2 th 5i5i7<7<9'9'7<7<;`;`=F=F?B?BABABC/C/=F=FEjEjA4A4HIHI9-9-H@HIXu9JHRABcR9'd]{*7/7<e`;GEUABEGAO7DKKJ7:9v=@Ej9SAxwSKp7<K;GQ87<;j=FA4~I9S7/KyKye`['?O=F;GQjHIQ>[SzF7:Qj;GM'EGc$AB7<e`Q?O=FQG28Q#28{'AB287<;>2f=@;>28ej{'2AB2g7<Q|2282828282f2f282828282f2f28282828222g2g2228282f2f28282828282822
*1*1 24243I3I2m2m} 5iYZ?O7<=@9'QG7<Q;`cS=F?B=@ABQGC/7/=FKyEjA4HInR9-7:9'HI7<9N;>=@e]?BA4?CD=@=FQGQUEGABHIe`HI9NP-=@[9SHRKrQjA4PyEjABABHR9'9rAB9'{'nfAB7<HR;`cR=Fd];>7/eje`{'EUAB7<K'Q=@E>28=r2fe`M'28c287<Q(282f2f2828222g2g22282828282f2f282828282f2f28282828222g2g2228282f2f28282828282822
1*2 lk1*pL 2 l*AB9'2B3 AB9'nr
o
[S[S=F=@EjEGAAO=@=F?q?qK'^8=F=@E`=bE>=Fe]cM'=FcSQG7(7:Qe`HR2g9'Qj2EG;j28MS2fe`EG28ABHI28928=F9S2fKy28Qj28[S2f=FEj28A=@2?qa828$2fT28282f2f2828282828282f2f2828222g2g22282828282f2f282828282f2f28282828222g2g2228282f2f28282828282822
1*1*22 l*l*2m2mlh
o
o[S[S=F=FEjEjAA=@=@?q?qej=F{SQjQG=FH';`e`=RAOe`=FEjEj7<A4;GHIAB9JC/=@=@EG9SABHR=F9?BVQG2fABQ28282828282f2f282828282f2f28282228282f2f282828282f2f2828282828282f2f2828222g2g22282828282f2f282828282f2f28282828222g2g2228282f2f28282828282822
1*1*22 l*l*22mt}
o
o[S[S=F=FEjEjAA=@=@?q?qe`e`?O?BM'=FQjQGQGEjAx7<w;Ge<AB9'=@nrEGABHRPy9p7<=FEG{*9SHoKyKo['Q;j287/K28AOe`28EGAB2fHI9 28282f2f28282228282f2f282828282f2f2828282828282f2f2828222g2g22282828282f2f282828282f2f28282828222g2g2228282f2f28282828282822
1*2 hk1*Lp2 h*BA 9'B2 3 AB9'n(
oA4PyABP-AB?7`=@G;G
AB7<EV8;jAB7<QGQ7/=@^8;>ej=@{sE>=FABc9p=FEGQGAB7:P-QU7]=F9SQjKy7<;GAB7<7<QUP-=@9S[=FHR?B;`V=FQG?$ABQ^8=FE>2=@28cS=F2fQj7<28Q282f2f2828282828282f2f2828222g2g22282828282f2f282828282f2f28282828222g2g2228282f2f28282828282822
1*1*22 h*h*m2m2 lh ;j7<7<;j9SABHoKpKoA=Fe]9SA4E=@V-?BVv=@Qj9SABQ=F?BV28QGAB2QU2g2g2228282f2f2828282828282f2f282828282f2f28282228282f2f282828282f2f2828282828282f2f2828222g2g22282828282f2f282828282f2f28282828222g2g2228282f2f28282828282822
1*1*22 h*h*2m2 t}
o7/?=@I9-M'7<Py9EGA4AO9*=FA4?$9*[nf=FcEGV-Ej7<K;G9AB~vP-AOKAB7]9'=@AB9'9SnKIG28e`HR289SI28M'2f7:;-2828282f2f28282228282f2f282828282f2f2828282828282f2f2828222g2g22282828282f2f282828282f2f28282828222g2g2228282f2f28282828282822
1*2 t Lp1*2 tAB9'2B3 BA 9'n( 7`7`\'\'EUEUK'^8=@=FE>=(E>=@=FcS9S=F=@Qj?B7<VvQQj28ABQ2=@2g9SKy2A4289oX2fHR;j28PJ28=F28EjAB2fHR9(28;G287<Ej2f;GAB287<~R2=F28?2f2f282828282f2f2828282828282f2f2828222g2g22282828282f2f282828282f2f28282828222g2g2228282f2f28282828282822
1*1*22 tt2m2mlh ##^ 7<H'Ve`M'ZPyHR;`7<KI9Ec=Fe]?QG=@7DQGKsQjA=Fw$Qje<QG=FH'Eje`A4AOHI=F9sEjA4=FHI9S9J=@=@?4V9SQj=FA4?BQVQGAB28Q28282f2f28282228282f2f282828282f2f2828282828282f2f2828222g2g22282828282f2f282828282f2f28282828222g2g2228282f2f28282828282822
1*2 }k1*1*Lp22 t}*AB9'22Bt3 AB9'nrT#
oLpA4'M Py'M EGHI?BBA Ej?PJ=@A4Py;G=@ABE7/EGV87/KK_AOQG=87/7`=@^8\';>EGej=F;>{sE>=I=@e`ABcSEG9pAB=FHIQjPr9J7<QbM'H@?B28XuEGABQjPr2fEG;G287/MK28e`AOEG=828M'K';j2f7<=@Qf28E>=AB289-2f2fEj7`2828\'22E2828KH'2f2fe`2828M*P-28287<2f2f92828EGQ28282828282f2f2f2828282222g2g2g2222828282828282f2f2f2828282828282f2f2f2828282828282222g2g2g2222828282f2f2f282828282828282828222
1*1*22 }*}*2m2mlh LNLNM'A49*?BGE4A 9*Axn KoA4=@PyQGQG7<H'9'e`QjAOA4=@HIEG9SABHR=F9'?Q=F9SAB9y=@?4PrVQjM'A4QZ?BEGHFABPrXPr7/KM'AO?B=8EGABK'Pr=F7/E`=KAO=82K'=@28E>2f=62828282f2f2828282828282f2f2828222g2g22282828282f2f282828282f2f28282828222g2g2228282f2f28282828282822
1*2 k1*Lp2 *AB9'2B3 AB9'n(¡EG{*7:7c-¡ -P HIAB;G9'?OABKI9'n(¡¢=FAO9SKKy7`=r¡e`7<?Oc£=FQGQjAx28w2fe<=F28EjAB28HR9p28HF2fX28¡287<2fcp28P-2AB9'28AB9'2fn828E>28=@QG2f¤Q-28282828282f2f2828222g2g22282828282f2f282828282f2f28282828222g2g2228282f2f28282828282822
1*1*22 **2m2mlh ¡¡7:7:c-c-'MGQ EjQ`;G=FMSnRe]7gEGM'P-;j7bAB9'PyAB9'A4n¥9*A49*2gn228282f2f2828282828282f2f282828282f2f28282228282f2f282828282f2f2828282828282f2f2828222g2g22282828282f2f282828282f2f28282828222g2g2228282f2f28282828282822
1*2 k1*
M*2 *P-2 t PJ=@¡;GV7:cJ28`e 82HI9v2fEj7<28928EU2fPy28A49*28A49*2n¦2g2228282f2f2828282828282f2f282828282f2f28282228282f2f282828282f2f2828282828282f2f2828222g2g22282828282f2f282828282f2f28282828222g2g2228282f2f28282828282822
3
0h
ht
}
11
11
1
}}
456748/9-:;9=<?>A@B>A@BC=D'E!E"F7>HGI#9-$:J>A&KL%'@MN&6O(*6P)&6/+-6Q,.&6/(6/%/6/06Q16/6/6Q26/6P6/6Q06/6/6Q6/6/6/6Q6/6P6O6P6/6/6Q6/6/6Q6/6/6P6O6P6/6Q6/6/6/6
[email protected]:JMW[I:WF7FAKL>7XYCL[I>[email protected]:u[#\t'8/U[I9-cJ:]v_9^Dd<_@>7MJ@wx>7@[IC^cJ>7@`CKaKLwyF7M&>7:Wb0z{KLcd8/8'9-:]KS9^Xe<_9">7>7@.@fh>7gi@EjC^[#`Gk>m[#lnGJGVz@Dd>HE|LEUF7[I>HM}GI9":W>76PKS@6OM16P6/6/6/6/6Q6Q6/6/6/6/6Q6Q6/6/6/6/6P6P6O6O6P6P6/6/6Q6Q6/6/6/6/6/6/66
456po~'45:W6pzBo[I67cd41`y'z>7[MWXYUj9"[IFMy9-KL@j@e\_8/9-U9-:;\.9>7K
<_\>79"@:]>79O@CXY>7@6Q>76/@C6/6/6/6Q6Q6/6/6/6/6Q6Q6/6/6P6P6/6/6Q6Q6/6/6/6/6Q6Q6/6/6/6/6/6/6Q6Q6/6/6P6P6O6O6P6P6/6/6/6/6Q6Q6/6/6/6/6Q6Q6/6/6/6/6P6P6O6O6P6P6/6/6Q6Q6/6/6/6/6/6/66
44556p6poo6p6poRgBTVG;KL>7XY[[email protected]:W>l[Ic]G/G;>H\9"9-Fj:;8/9^9-XY:]9^>7@<_>7@>7C@>7@6/C6Qg.6/v.MW6/:J[I6/XY6QMy6/9-@j6/\_6Q6/cJ6PKS:J6/KS:s6Qv.6/Ej[6/M6Q6/6/6/6/6/6/6Q6Q6/6/6P6P6O6O6P6P6/6/6/6/6Q6Q6/6/6/6/6Q6Q6/6/6/6/6P6P6O6O6P6P6/6/6Q6Q6/6/6/6/6/6/66
44556p6 R`g.KcW[G;@j>H9"\.FnMPqsXY9"@jEj\Y9LG;:W[IMVMWK-[bx9-c]8/GJz{9-:;qs9=MJMW<_U[>7@MP>7>7@@_C8P9"6Q:]6/9^6/<_6/>7@6Q>7@6/C6/6Q6Q6/6/6P6P6/6/6Q6Q6/6/6/6/6Q6Q6/6/6/6/6/6/6Q6Q6/6/6P6P6O6O6P6P6/6/6/6/6Q6Q6/6/6/6/6Q6Q6/6/6/6/6P6P6O6O6P6P6/6/6Q6Q6/6/6/6/6/6/66
456pg.UBXYXe9"cWv6/6/6Q6/6/6Q6/6/6P6O6P6/6Q6/6/6/6Q6/6/6Q6/6P6/6Q6/6/6Q6/6/6/6Q6/6P6O6P6/6/6Q6/6/6Q6/6/6P6O6P6/6Q6/6/6/6
4
3R
RR
RR
RR
R
Data Mining: Concepts and Techniques
Jiawei Han and Micheline Kamber
Simon Fraser University
Note: This manuscript is based on a forthcoming book by Jiawei Han
c 2000 (c) Morgan Kaufmann Publishers. All
and Micheline Kamber, rights reserved.
Preface
Our capabilities of both generating and collecting data have been increasing rapidly in the last several decades.
Contributing factors include the widespread use of bar codes for most commercial products, the computerization
of many business, scientic and government transactions and managements, and advances in data collection tools
ranging from scanned texture and image platforms, to on-line instrumentation in manufacturing and shopping, and to
satellite remote sensing systems. In addition, popular use of the World Wide Web as a global information system has
ooded us with a tremendous amount of data and information. This explosive growth in stored data has generated
an urgent need for new techniques and automated tools that can intelligently assist us in transforming the vast
amounts of data into useful information and knowledge.
This book explores the concepts and techniques of data mining, a promising and ourishing frontier in database
systems and new database applications. Data mining, also popularly referred to as knowledge discovery in databases
(KDD), is the automated or convenient extraction of patterns representing knowledge implicitly stored in large
databases, data warehouses, and other massive information repositories.
Data mining is a multidisciplinary eld, drawing work from areas including database technology, articial intelligence, machine learning, neural networks, statistics, pattern recognition, knowledge based systems, knowledge
acquisition, information retrieval, high performance computing, and data visualization. We present the material in
this book from a database perspective. That is, we focus on issues relating to the feasibility, usefulness, eciency, and
scalability of techniques for the discovery of patterns hidden in large databases. As a result, this book is not intended
as an introduction to database systems, machine learning, or statistics, etc., although we do provide the background
necessary in these areas in order to facilitate the reader's comprehension of their respective roles in data mining.
Rather, the book is a comprehensive introduction to data mining, presented with database issues in focus. It should
be useful for computing science students, application developers, and business professionals, as well as researchers
involved in any of the disciplines listed above.
Data mining emerged during the late 1980's, has made great strides during the 1990's, and is expected to continue
to ourish into the new millennium. This book presents an overall picture of the eld from a database researcher's
point of view, introducing interesting data mining techniques and systems, and discussing applications and research
directions. An important motivation for writing this book was the need to build an organized framework for the
study of data mining | a challenging task owing to the extensive multidisciplinary nature of this fast developing
eld. We hope that this book will encourage people with dierent backgrounds and experiences to exchange their
views regarding data mining so as to contribute towards the further promotion and shaping of this exciting and
dynamic eld.
To the teacher
This book is designed to give a broad, yet in depth overview of the eld of data mining. You will nd it useful
for teaching a course on data mining at an advanced undergraduate level, or the rst-year graduate level. In
addition, individual chapters may be included as material for courses on selected topics in database systems or in
articial intelligence. We have tried to make the chapters as self-contained as possible. For a course taught at the
undergraduate level, you might use chapters 1 to 8 as the core course material. Remaining class material may be
selected from among the more advanced topics described in chapters 9 and 10. For a graduate level course, you may
choose to cover the entire book in one semester.
Each chapter ends with a set of exercises, suitable as assigned homework. The exercises are either short questions
i
ii
that test basic mastery of the material covered, or longer questions which require analytical thinking.
To the student
We hope that this textbook will spark your interest in the fresh, yet evolving eld of data mining. We have attempted
to present the material in a clear manner, with careful explanation of the topics covered. Each chapter ends with a
summary describing the main points. We have included many gures and illustrations throughout the text in order
to make the book more enjoyable and \reader-friendly". Although this book was designed as a textbook, we have
tried to organize it so that it will also be useful to you as a reference book or handbook, should you later decide to
pursue a career in data mining.
What do you need to know in order to read this book?
You should have some knowledge of the concepts and terminology associated with database systems. However,
we do try to provide enough background of the basics in database technology, so that if your memory is a bit
rusty, you will not have trouble following the discussions in the book. You should have some knowledge of
database querying, although knowledge of any specic query language is not required.
You should have some programming experience. In particular, you should be able to read pseudo-code, and
understand simple data structures such as multidimensional arrays.
It will be helpful to have some preliminary background in statistics, machine learning, or pattern recognition.
However, we will familiarize you with the basic concepts of these areas that are relevant to data mining from
a database perspective.
To the professional
This book was designed to cover a broad range of topics in the eld of data mining. As a result, it is a good handbook
on the subject. Because each chapter is designed to be as stand-alone as possible, you can focus on the topics that
most interest you. Much of the book is suited to applications programmers or information service managers like
yourself who wish to learn about the key ideas of data mining on their own.
The techniques and algorithms presented are of practical utility. Rather than selecting algorithms that perform
well on small \toy" databases, the algorithms described in the book are geared for the discovery of data patterns
hidden in large, real databases. In Chapter 10, we briey discuss data mining systems in commercial use, as well
as promising research prototypes. Each algorithm presented in the book is illustrated in pseudo-code. The pseudocode is similar to the C programming language, yet is designed so that it should be easy to follow by programmers
unfamiliar with C or C++. If you wish to implement any of the algorithms, you should nd the translation of our
pseudo-code into the programming language of your choice to be a fairly straightforward task.
Organization of the book
The book is organized as follows.
Chapter 1 provides an introduction to the multidisciplinary eld of data mining. It discusses the evolutionary path
of database technology which led up to the need for data mining, and the importance of its application potential. The
basic architecture of data mining systems is described, and a brief introduction to the concepts of database systems
and data warehouses is given. A detailed classication of data mining tasks is presented, based on the dierent kinds
of knowledge to be mined. A classication of data mining systems is presented, and major challenges in the eld are
discussed.
Chapter 2 is an introduction to data warehouses and OLAP (On-Line Analytical Processing). Topics include the
concept of data warehouses and multidimensional databases, the construction of data cubes, the implementation of
on-line analytical processing, and the relationship between data warehousing and data mining.
Chapter 3 describes techniques for preprocessing the data prior to mining. Methods of data cleaning, data
integration and transformation, and data reduction are discussed, including the use of concept hierarchies for dynamic
and static discretization. The automatic generation of concept hierarchies is also described.
iii
Chapter 4 introduces the primitives of data mining which dene the specication of a data mining task. It
describes a data mining query language (DMQL), and provides examples of data mining queries. Other topics
include the construction of graphical user interfaces, and the specication and manipulation of concept hierarchies.
Chapter 5 describes techniques for concept description, including characterization and discrimination. An
attribute-oriented generalization technique is introduced, as well as its dierent implementations including a generalized relation technique and a multidimensional data cube technique. Several forms of knowledge presentation and
visualization are illustrated. Relevance analysis is discussed. Methods for class comparison at multiple abstraction
levels, and methods for the extraction of characteristic rules and discriminant rules with interestingness measurements
are presented. In addition, statistical measures for descriptive mining are discussed.
Chapter 6 presents methods for mining association rules in transaction databases as well as relational databases
and data warehouses. It includes a classication of association rules, a presentation of the basic Apriori algorithm
and its variations, and techniques for mining multiple-level association rules, multidimensional association rules,
quantitative association rules, and correlation rules. Strategies for nding interesting rules by constraint-based
mining and the use of interestingness measures to focus the rule search are also described.
Chapter 7 describes methods for data classication and predictive modeling. Major methods of classication and
prediction are explained, including decision tree induction, Bayesian classication, the neural network technique of
backpropagation, k-nearest neighbor classiers, case-based reasoning, genetic algorithms, rough set theory, and fuzzy
set approaches. Association-based classication, which applies association rule mining to the problem of classication,
is presented. Methods of regression are introduced, and issues regarding classier accuracy are discussed.
Chapter 8 describes methods of clustering analysis. It rst introduces the concept of data clustering and then
presents several major data clustering approaches, including partition-based clustering, hierarchical clustering, and
model-based clustering. Methods for clustering continuous data, discrete data, and data in multidimensional data
cubes are presented. The scalability of clustering algorithms is discussed in detail.
Chapter 9 discusses methods for data mining in advanced database systems. It includes data mining in objectoriented databases, spatial databases, text databases, multimedia databases, active databases, temporal databases,
heterogeneous and legacy databases, and resource and knowledge discovery in the Internet information base.
Finally, in Chapter 10, we summarize the concepts presented in this book and discuss applications of data mining
and some challenging research issues.
Errors
It is likely that this book may contain typos, errors, or omissions. If you notice any errors, have suggestions regarding
additional exercises or have other constructive criticism, we would be very happy to hear from you. We welcome and
appreciate your suggestions. You can send your comments to:
Data Mining: Concept and Techniques
Intelligent Database Systems Research Laboratory
Simon Fraser University,
Burnaby, British Columbia
Canada V5A 1S6
Fax: (604) 291-3045
Alternatively, you can use electronic mails to submit bug reports, request a list of known errors, or make constructive suggestions. To receive instructions, send email to
with \Subject: help" in the message header.
We regret that we cannot personally respond to all e-mails. The errata of the book and other updated information
related to the book can be found by referencing the Web address: http://db.cs.sfu.ca/Book.
[email protected]
Acknowledgements
We would like to express our sincere thanks to all the members of the data mining research group who have been
working with us at Simon Fraser University on data mining related research, and to all the members of the
system development team, who have been working on an exciting data mining project,
, and have made
it a real success. The data mining research team currently consists of the following active members: Julia Gitline,
DBMiner
DBMiner
iv
Kan Hu, Jean Hou, Pei Jian, Micheline Kamber, Eddie Kim, Jin Li, Xuebin Lu, Behzad Mortazav-Asl, Helen Pinto,
Yiwen Yin, Zhaoxia Wang, and Hua Zhu. The
development team currently consists of the following active
members: Kan Hu, Behzad Mortazav-Asl, and Hua Zhu, and some partime workers from the data mining research
team. We are also grateful to Helen Pinto, Hua Zhu, and Lara Winstone for their help with some of the gures in
this book.
More acknowledgements will be given at the nal stage of the writing.
DBMiner
Contents
1 Introduction
1.1 What motivated data mining? Why is it important? . . . . . . . . . . .
1.2 So, what is data mining? . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.3 Data mining | on what kind of data? . . . . . . . . . . . . . . . . . . .
1.3.1 Relational databases . . . . . . . . . . . . . . . . . . . . . . . . .
1.3.2 Data warehouses . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.3.3 Transactional databases . . . . . . . . . . . . . . . . . . . . . . .
1.3.4 Advanced database systems and advanced database applications
1.4 Data mining functionalities | what kinds of patterns can be mined? . .
1.4.1 Concept/class description: characterization and discrimination .
1.4.2 Association analysis . . . . . . . . . . . . . . . . . . . . . . . . .
1.4.3 Classication and prediction . . . . . . . . . . . . . . . . . . . .
1.4.4 Clustering analysis . . . . . . . . . . . . . . . . . . . . . . . . . .
1.4.5 Evolution and deviation analysis . . . . . . . . . . . . . . . . . .
1.5 Are all of the patterns interesting? . . . . . . . . . . . . . . . . . . . . .
1.6 A classication of data mining systems . . . . . . . . . . . . . . . . . . .
1.7 Major issues in data mining . . . . . . . . . . . . . . . . . . . . . . . . .
1.8 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
3
3
6
8
9
11
12
13
13
13
14
15
16
16
17
18
19
21
2
CONTENTS
c J. Han and M. Kamber, 1998, DRAFT!! DO NOT COPY!! DO NOT DISTRIBUTE!!
September 7, 1999
Chapter 1
Introduction
This book is an introduction to what has come to be known as data mining and knowledge discovery in databases.
The material in this book is presented from a database perspective, where emphasis is placed on basic data mining
concepts and techniques for uncovering interesting data patterns hidden in large data sets. The implementation
methods discussed are particularly oriented towards the development of scalable and ecient data mining tools.
In this chapter, you will learn how data mining is part of the natural evolution of database technology, why data
mining is important, and how it is dened. You will learn about the general architecture of data mining systems,
as well as gain insight into the kinds of data on which mining can be performed, the types of patterns that can be
found, and how to tell which patterns represent useful knowledge. In addition to studying a classication of data
mining systems, you will read about challenging research issues for building data mining tools of the future.
1.1 What motivated data mining? Why is it important?
Necessity is the mother of invention.
| English proverb.
The major reason that data mining has attracted a great deal of attention in information industry in recent
years is due to the wide availability of huge amounts of data and the imminent need for turning such data into
useful information and knowledge. The information and knowledge gained can be used for applications ranging from
business management, production control, and market analysis, to engineering design and science exploration.
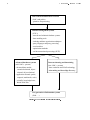
Data mining can be viewed as a result of the natural evolution of information technology. An evolutionary path
has been witnessed in the database industry in the development of the following functionalities (Figure 1.1): data
collection and database creation, data management (including data storage and retrieval, and database transaction
processing), and data analysis and understanding (involving data warehousing and data mining). For instance, the
early development of data collection and database creation mechanisms served as a prerequisite for later development
of eective mechanisms for data storage and retrieval, and query and transaction processing. With numerous database
systems oering query and transaction processing as common practice, data analysis and understanding has naturally
become the next target.
Since the 1960's, database and information technology has been evolving systematically from primitive le processing systems to sophisticated and powerful databases systems. The research and development in database systems
since the 1970's has led to the development of relational database systems (where data are stored in relational table
structures; see Section 1.3.1), data modeling tools, and indexing and data organization techniques. In addition, users
gained convenient and exible data access through query languages, query processing, and user interfaces. Ecient
methods for on-line transaction processing (OLTP), where a query is viewed as a read-only transaction, have
contributed substantially to the evolution and wide acceptance of relational technology as a major tool for ecient
storage, retrieval, and management of large amounts of data.
Database technology since the mid-1980s has been characterized by the popular adoption of relational technology
and an upsurge of research and development activities on new and powerful database systems. These employ ad3
CHAPTER 1. INTRODUCTION
4
Data collection and database creation
(1960’s and earlier)
- primitive file processing
Database management systems
(1970’s)
- network and relational database systems
- data modeling tools
- indexing and data organization techniques
- query languages and query processing
- user interfaces
- optimization methods
- on-line transactional processing (OLTP)
Advanced databases systems
(mid-1980’s - present)
Data warehousing and data mining
(late-1980’s - present)
- advanced data models:
extended-relational, objectoriented, object-relational
- application-oriented: spatial,
temporal, multimedia, active,
scientific, knowledge-bases,
World Wide Web.
- data warehouse and OLAP technology
- data mining and knowledge discovery
New generation of information systems
(2000 - ...)
Figure 1.1: The evolution of database technology.
1.1. WHAT MOTIVATED DATA MINING? WHY IS IT IMPORTANT?
5
How can I analyze
???
this data?
???
Figure 1.2: We are data rich, but information poor.
vanced data models such as extended-relational, object-oriented, object-relational, and deductive models Applicationoriented database systems, including spatial, temporal, multimedia, active, and scientic databases, knowledge bases,
and oce information bases, have ourished. Issues related to the distribution, diversication, and sharing of data
have been studied extensively. Heterogeneous database systems and Internet-based global information systems such
as the World-Wide Web (WWW) also emerged and play a vital role in the information industry.
The steady and amazing progress of computer hardware technology in the past three decades has led to powerful,
aordable, and large supplies of computers, data collection equipment, and storage media. This technology provides
a great boost to the database and information industry, and makes a huge number of databases and information
repositories available for transaction management, information retrieval, and data analysis.
Data can now be stored in many dierent types of databases. One database architecture that has recently emerged
is the data warehouse (Section 1.3.2), a repository of multiple heterogeneous data sources, organized under a unied
schema at a single site in order to facilitate management decision making. Data warehouse technology includes data
cleansing, data integration, and On-Line Analytical Processing (OLAP), that is, analysis techniques with
functionalities such as summarization, consolidation and aggregation, as well as the ability to view information at
dierent angles. Although OLAP tools support multidimensional analysis and decision making, additional data
analysis tools are required for in-depth analysis, such as data classication, clustering, and the characterization of
data changes over time.
The abundance of data, coupled with the need for powerful data analysis tools, has been described as a \data
rich but information poor" situation. The fast-growing, tremendous amount of data, collected and stored in large
and numerous databases, has far exceeded our human ability for comprehension without powerful tools (Figure 1.2).
As a result, data collected in large databases become \data tombs" | data archives that are seldom revisited.
Consequently, important decisions are often made based not on the information-rich data stored in databases but
rather on a decision maker's intuition, simply because the decision maker does not have the tools to extract the
valuable knowledge embedded in the vast amounts of data. In addition, consider current expert system technologies,
which typically rely on users or domain experts to manually input knowledge into knowledge bases. Unfortunately,
this procedure is prone to biases and errors, and is extremely time-consuming and costly. Data mining tools which
perform data analysis may uncover important data patterns, contributing greatly to business strategies, knowledge
bases, and scientic and medical research. The widening gap between data and information calls for a systematic
development of data mining tools which will turn data tombs into \golden nuggets" of knowledge.
CHAPTER 1. INTRODUCTION
6
[beads of sweat]
[gold nuggets]
[a pick]
Knowledge
[a shovel]
[ a mountain of data]
Figure 1.3: Data mining - searching for knowledge (interesting patterns) in your data.
1.2 So, what is data mining?
Simply stated, data mining refers to extracting or \mining" knowledge from large amounts of data. The term is
actually a misnomer. Remember that the mining of gold from rocks or sand is referred to as gold mining rather than
rock or sand mining. Thus, \data mining" should have been more appropriately named \knowledge mining from
data", which is unfortunately somewhat long. \Knowledge mining", a shorter term, may not reect the emphasis on
mining from large amounts of data. Nevertheless, mining is a vivid term characterizing the process that nds a small
set of precious nuggets from a great deal of raw material (Figure 1.3). Thus, such a misnomer which carries both
\data" and \mining" became a popular choice. There are many other terms carrying a similar or slightly dierent
meaning to data mining, such as knowledge mining from databases, knowledge extraction, data/pattern
analysis, data archaeology, and data dredging.
Many people treat data mining as a synonym for another popularly used term, \Knowledge Discovery in
Databases", or KDD. Alternatively, others view data mining as simply an essential step in the process of knowledge
discovery in databases. Knowledge discovery as a process is depicted in Figure 1.4, and consists of an iterative
sequence of the following steps:
data cleaning (to remove noise or irrelevant data),
data integration (where multiple data sources may be combined)1,
data selection (where data relevant to the analysis task are retrieved from the database),
data transformation (where data are transformed or consolidated into forms appropriate for mining by
performing summary or aggregation operations, for instance)2 ,
data mining (an essential process where intelligent methods are applied in order to extract data patterns),
pattern evaluation (to identify the truly interesting patterns representing knowledge based on some interestingness measures; Section 1.5), and
knowledge presentation (where visualization and knowledge representation techniques are used to present
the mined knowledge to the user).
1 A popular trend in the information industry is to perform data cleaning and data integration as a preprocessing step where the
resulting data are stored in a data warehouse.
2 Sometimes data transformation and consolidation are performed before the data selection process, particularly in the case of data
warehousing.
1.2. SO, WHAT IS DATA MINING?
7
Evaluation
& Presentation
knowledge
Data
Mining
Selection &
patterns
Transformation
Cleaning &
data
warehouse
Integration
..
..
data bases
flat files
Figure 1.4: Data mining as a process of knowledge discovery.
The data mining step may interact with the user or a knowledge base. The interesting patterns are presented to
the user, and may be stored as new knowledge in the knowledge base. Note that according to this view, data mining
is only one step in the entire process, albeit an essential one since it uncovers hidden patterns for evaluation.
We agree that data mining is a knowledge discovery process. However, in industry, in media, and in the database
research milieu, the term \data mining" is becoming more popular than the longer term of \knowledge discovery
in databases". Therefore, in this book, we choose to use the term \data mining". We adopt a broad view of data
mining functionality: data mining is the process of discovering interesting knowledge from large amounts of data
stored either in databases, data warehouses, or other information repositories.
Based on this view, the architecture of a typical data mining system may have the following major components
(Figure 1.5):
1. Database, data warehouse, or other information repository. This is one or a set of databases, data
warehouses, spread sheets, or other kinds of information repositories. Data cleaning and data integration
techniques may be performed on the data.
2. Database or data warehouse server. The database or data warehouse server is responsible for fetching the
relevant data, based on the user's data mining request.
3. Knowledge base. This is the domain knowledge that is used to guide the search, or evaluate the interestingness of resulting patterns. Such knowledge can include concept hierarchies, used to organize attributes
or attribute values into dierent levels of abstraction. Knowledge such as user beliefs, which can be used to
assess a pattern's interestingness based on its unexpectedness, may also be included. Other examples of domain
knowledge are additional interestingness constraints or thresholds, and metadata (e.g., describing data from
multiple heterogeneous sources).
4. Data mining engine. This is essential to the data mining system and ideally consists of a set of functional
modules for tasks such as characterization, association analysis, classication, evolution and deviation analysis.
5. Pattern evaluation module. This component typically employs interestingness measures (Section 1.5) and
interacts with the data mining modules so as to focus the search towards interesting patterns. It may access
interestingness thresholds stored in the knowledge base. Alternatively, the pattern evaluation module may be
CHAPTER 1. INTRODUCTION
8
Graphic User Interface
Pattern Evaluation
Data Mining
Engine
Knowledge
Base
Database or
Data Warehouse
Server
Data cleaning
data integration
Data
Base
filtering
Data
Warehouse
Figure 1.5: Architecture of a typical data mining system.
integrated with the mining module, depending on the implementation of the data mining method used. For
ecient data mining, it is highly recommended to push the evaluation of pattern interestingness as deep as
possible into the mining process so as to conne the search to only the interesting patterns.
6. Graphical user interface. This module communicates between users and the data mining system, allowing
the user to interact with the system by specifying a data mining query or task, providing information to help
focus the search, and performing exploratory data mining based on the intermediate data mining results. In
addition, this component allows the user to browse database and data warehouse schemas or data structures,
evaluate mined patterns, and visualize the patterns in dierent forms.
From a data warehouse perspective, data mining can be viewed as an advanced stage of on-line analytical processing (OLAP). However, data mining goes far beyond the narrow scope of summarization-style analytical processing
of data warehouse systems by incorporating more advanced techniques for data understanding.
While there may be many \data mining systems" on the market, not all of them can perform true data mining.
A data analysis system that does not handle large amounts of data can at most be categorized as a machine learning
system, a statistical data analysis tool, or an experimental system prototype. A system that can only perform data
or information retrieval, including nding aggregate values, or that performs deductive query answering in large
databases should be more appropriately categorized as either a database system, an information retrieval system, or
a deductive database system.
Data mining involves an integration of techniques from multiple disciplines such as database technology, statistics,
machine learning, high performance computing, pattern recognition, neural networks, data visualization, information
retrieval, image and signal processing, and spatial data analysis. We adopt a database perspective in our presentation
of data mining in this book. That is, emphasis is placed on ecient and scalable data mining techniques for large
databases. By performing data mining, interesting knowledge, regularities, or high-level information can be extracted
from databases and viewed or browsed from dierent angles. The discovered knowledge can be applied to decision
making, process control, information management, query processing, and so on. Therefore, data mining is considered
as one of the most important frontiers in database systems and one of the most promising, new database applications
in the information industry.
1.3 Data mining | on what kind of data?
In this section, we examine a number of dierent data stores on which mining can be performed. In principle,
data mining should be applicable to any kind of information repository. This includes relational databases, data
1.3. DATA MINING | ON WHAT KIND OF DATA?
9
warehouses, transactional databases, advanced database systems, at les, and the World-Wide Web. Advanced
database systems include object-oriented and object-relational databases, and specic application-oriented databases,
such as spatial databases, time-series databases, text databases, and multimedia databases. The challenges and
techniques of mining may dier for each of the repository systems.
Although this book assumes that readers have primitive knowledge of information systems, we provide a brief
introduction to each of the major data repository systems listed above. In this section, we also introduce the ctitious
AllElectronics store which will be used to illustrate concepts throughout the text.
1.3.1 Relational databases
A database system, also called a database management system (DBMS), consists of a collection of interrelated
data, known as a database, and a set of software programs to manage and access the data. The software programs
involve mechanisms for the denition of database structures, for data storage, for concurrent, shared or distributed
data access, and for ensuring the consistency and security of the information stored, despite system crashes or
attempts at unauthorized access.
A relational database is a collection of tables, each of which is assigned a unique name. Each table consists
of a set of attributes (columns or elds) and usually stores a large number of tuples (records or rows). Each tuple
in a relational table represents an object identied by a unique key and described by a set of attribute values.
Consider the following example.
Example 1.1 The AllElectronics company is described by the following relation tables: customer, item, employee,
and branch. Fragments of the tables described here are shown in Figure 1.6. The attribute which represents key or
composite key component of each relation is underlined.
The relation customer consists of a set of attributes, including a unique customer identity number (cust ID),
customer name, address, age, occupation, annual income, credit information, category, etc.
Similarly, each of the relations employee, branch, and items, consists of a set of attributes, describing their
properties.
Tables can also be used to represent the relationships between or among multiple relation tables. For our
example, these include purchases (customer purchases items, creating a sales transaction that is handled by an
employee), items sold (lists the items sold in a given transaction), and works at (employee works at a branch
of AllElectronics).
2
Relational data can be accessed by database queries written in a relational query language, such as SQL, or
with the assistance of graphical user interfaces. In the latter, the user may employ a menu, for example, to specify
attributes to be included in the query, and the constraints on these attributes. A given query is transformed into a
set of relational operations, such as join, selection, and projection, and is then optimized for ecient processing. A
query allows retrieval of specied subsets of the data. Suppose that your job is to analyze the AllElectronics data.
Through the use of relational queries, you can ask things like \Show me a list of all items that were sold in the last
quarter". Relational languages also include aggregate functions such as sum, avg (average), count, max (maximum),
and min (minimum). These allow you to nd out things like \Show me the total sales of the last month, grouped
by branch", or \How many sales transactions occurred in the month of December?", or \Which sales person had the
highest amount of sales?".
When data mining is applied to relational databases, one can go further by searching for trends or data patterns.
For example, data mining systems may analyze customer data to predict the credit risk of new customers based on
their income, age, and previous credit information. Data mining systems may also detect deviations, such as items
whose sales are far from those expected in comparison with the previous year. Such deviations can then be further
investigated, e.g., has there been a change in packaging of such items, or a signicant increase in price?
Relational databases are one of the most popularly available and rich information repositories for data mining,
and thus they are a major data form in our study of data mining.
CHAPTER 1. INTRODUCTION
10
customer
cust ID
name
address
age income credit info ...
C1
Smith, Sandy 5463 E. Hastings, Burnaby, BC, V5A 4S9, Canada 21 $27000
1
...
...
...
...
...
...
...
...
item
item ID
name
brand
category
type
price place made supplier
cost
I3
hi-res-TV
Toshiba high resolution
TV
$988.00
Japan
NikoX
$600.00
I8
multidisc-CDplay Sanyo
multidisc
CD player $369.00
Japan
MusicFront $120.00
...
...
...
...
...
...
...
...
...
employee
empl ID
name
category
group
salary commission
E55
Jones, Jane home entertainment manager $18,000
2%
...
...
...
...
...
...
branch
branch ID
name
address
B1
City Square 369 Cambie St., Vancouver, BC V5L 3A2, Canada
...
...
...
purchases
trans ID cust ID empl ID
date
time method paid amount
T100
C1
E55
09/21/98 15:45
Visa
$1357.00
...
...
...
...
...
...
...
items sold
trans ID item ID qty
T100
I3
1
T100
I8
2
...
...
...
works at
empl ID branch ID
E55
B1
...
...
Figure 1.6: Fragments of relations from a relational database for AllElectronics .
data source in Vancouver
client
clean
data source in New York
.
.
transform
integrate
load
data
warehouse
query
and
analysis
tools
.
.
.
client
data source in Chicago
Figure 1.7: Architecture of a typical data warehouse.
1.3. DATA MINING | ON WHAT KIND OF DATA?
a)
11
address
(cities)
Chicago
New York
Montreal
Vancouver
Q1
time
(quarters)
605K
825K
14K
400K
<Vancouver,Q1,security>
Q2
Q3
Q4
computer
security
phone
home
entertainment
item
(types)
b)
drill-down
on time data
for Q1
roll-up
on address
address
(regions)
address
(cities)
North
Chicago
New York
Montreal
Vancouver
time
(months)
South
East
West
Jan
150K
Feb
100K
March
150K
computer
security
phone
home
entertainment
item
(types)
Q1
time
(quarters)
Q2
Q3
Q4
computer
security
phone
home
entertainment
item
(types)
Figure 1.8: A multidimensional data cube, commonly used for data warehousing, a) showing summarized data for
AllElectronics and b) showing summarized data resulting from drill-down and roll-up operations on the cube in a).
1.3.2 Data warehouses
Suppose that AllElectronics is a successful international company, with branches around the world. Each branch has
its own set of databases. The president of AllElectronics has asked you to provide an analysis of the company's sales
per item type per branch for the third quarter. This is a dicult task, particularly since the relevant data are spread
out over several databases, physically located at numerous sites.
If AllElectronics had a data warehouse, this task would be easy. A data warehouse is a repository of information
collected from multiple sources, stored under a unied schema, and which usually resides at a single site. Data
warehouses are constructed via a process of data cleansing, data transformation, data integration, data loading, and
periodic data refreshing. This process is studied in detail in Chapter 2. Figure 1.7 shows the basic architecture of a
data warehouse for AllElectronics.
In order to facilitate decision making, the data in a data warehouse are organized around major subjects, such
as customer, item, supplier, and activity. The data are stored to provide information from a historical perspective
(such as from the past 5-10 years), and are typically summarized. For example, rather than storing the details of
each sales transaction, the data warehouse may store a summary of the transactions per item type for each store, or,
summarized to a higher level, for each sales region.
A data warehouse is usually modeled by a multidimensional database structure, where each dimension corresponds to an attribute or a set of attributes in the schema, and each cell stores the value of some aggregate measure,
such as count or sales amount. The actual physical structure of a data warehouse may be a relational data store or
a multidimensional data cube. It provides a multidimensional view of data and allows the precomputation and
CHAPTER 1. INTRODUCTION
12
sales
trans ID list of item ID's
T100 I1, I3, I8, I16
. ..
.. .
Figure 1.9: Fragment of a transactional database for sales at AllElectronics .
fast accessing of summarized data.
Example 1.2 A data cube for summarized sales data of AllElectronics is presented in Figure 1.8a). The cube has
three dimensions: address (with city values Chicago, New York, Montreal, Vancouver), time (with quarter values
Q1, Q2, Q3, Q4), and item (with item type values home entertainment, computer, phone, security). The aggregate
value stored in each cell of the cube is sales amount. For example, the total sales for Q1 of items relating to security
systems in Vancouver is $400K, as stored in cell hVancouver, Q1, securityi. Additional cubes may be used to store
aggregate sums over each dimension, corresponding to the aggregate values obtained using dierent SQL group-bys,
e.g., the total sales amount per city and quarter, or per city and item, or per quarter and item, or per each individual
dimension.
2
In research literature on data warehouses, the data cube structure that stores the primitive or lowest level of
information is called a base cuboid. Its corresponding higher level multidimensional (cube) structures are called
(non-base) cuboids. A base cuboid together with all of its corresponding higher level cuboids form a data cube.
By providing multidimensional data views and the precomputation of summarized data, data warehouse systems are well suited for On-Line Analytical Processing, or OLAP. OLAP operations make use of background
knowledge regarding the domain of the data being studied in order to allow the presentation of data at dierent
levels of abstraction. Such operations accommodate dierent user viewpoints. Examples of OLAP operations include
drill-down and roll-up, which allow the user to view the data at diering degrees of summarization, as illustrated
in Figure 1.8b). For instance, one may drill down on sales data summarized by quarter to see the data summarized
by month. Similarly, one may roll up on sales data summarized by city to view the data summarized by region.
Although data warehouse tools help support data analysis, additional tools for data mining are required to allow
more in depth and automated analysis. Data warehouse technology is discussed in detail in Chapter 2.
1.3.3 Transactional databases
In general, a transactional database consists of a le where each record represents a transaction. A transaction
typically includes a unique transaction identity number (trans ID), and a list of the items making up the transaction
(such as items purchased in a store). The transactional database may have additional tables associated with it, which
contain other information regarding the sale, such as the date of the transaction, the customer ID number, the ID
number of the sales person, and of the branch at which the sale occurred, and so on.
Example 1.3 Transactions can be stored in a table, with one record per transaction. A fragment of a transactional
database for AllElectronics is shown in Figure 1.9. From the relational database point of view, the sales table in
Figure 1.9 is a nested relation because the attribute \list of item ID's" contains a set of items. Since most relational
database systems do not support nested relational structures, the transactional database is usually either stored in a
at le in a format similar to that of the table in Figure 1.9, or unfolded into a standard relation in a format similar
to that of the items sold table in Figure 1.6.
2
As an analyst of the AllElectronics database, you may like to ask \Show me all the items purchased by Sandy
Smith" or \How many transactions include item number I3?". Answering such queries may require a scan of the
entire transactional database.
Suppose you would like to dig deeper into the data by asking \Which items sold well together?". This kind of
market basket data analysis would enable you to bundle groups of items together as a strategy for maximizing sales.
For example, given the knowledge that printers are commonly purchased together with computers, you could oer
1.4. DATA MINING FUNCTIONALITIES | WHAT KINDS OF PATTERNS CAN BE MINED?
13
an expensive model of printers at a discount to customers buying selected computers, in the hopes of selling more
of the expensive printers. A regular data retrieval system is not able to answer queries like the one above. However,
data mining systems for transactional data can do so by identifying sets of items which are frequently sold together.
1.3.4 Advanced database systems and advanced database applications
Relational database systems have been widely used in business applications. With the advances of database technology, various kinds of advanced database systems have emerged and are undergoing development to address the
requirements of new database applications.
The new database applications include handling spatial data (such as maps), engineering design data (such
as the design of buildings, system components, or integrated circuits), hypertext and multimedia data (including
text, image, video, and audio data), time-related data (such as historical records or stock exchange data), and the
World-Wide Web (a huge, widely distributed information repository made available by Internet). These applications
require ecient data structures and scalable methods for handling complex object structures, variable length records,
semi-structured or unstructured data, text and multimedia data, and database schemas with complex structures and
dynamic changes.
In response to these needs, advanced database systems and specic application-oriented database systems have
been developed. These include object-oriented and object-relational database systems, spatial database systems, temporal and time-series database systems, text and multimedia database systems, heterogeneous and legacy database
systems, and the Web-based global information systems.
While such databases or information repositories require sophisticated facilities to eciently store, retrieve, and
update large amounts of complex data, they also provide fertile grounds and raise many challenging research and
implementation issues for data mining.
1.4 Data mining functionalities | what kinds of patterns can be mined?
We have observed various types of data stores and database systems on which data mining can be performed. Let
us now examine the kinds of data patterns that can be mined.
Data mining functionalities are used to specify the kind of patterns to be found in data mining tasks. In general,
data mining tasks can be classied into two categories: descriptive and predictive. Descriptive mining tasks
characterize the general properties of the data in the database. Predictive mining tasks perform inference on the
current data in order to make predictions.
In some cases, users may have no idea of which kinds of patterns in their data may be interesting, and hence may
like to search for several dierent kinds of patterns in parallel. Thus it is important to have a data mining system that
can mine multiple kinds of patterns to accommodate dierent user expectations or applications. Furthermore, data
mining systems should be able to discover patterns at various granularities (i.e., dierent levels of abstraction). To
encourage interactive and exploratory mining, users should be able to easily \play" with the output patterns, such as
by mouse clicking. Operations that can be specied by simple mouse clicks include adding or dropping a dimension
(or an attribute), swapping rows and columns (pivoting, or axis rotation), changing dimension representations
(e.g., from a 3-D cube to a sequence of 2-D cross tabulations, or crosstabs), or using OLAP roll-up or drill-down
operations along dimensions. Such operations allow data patterns to be expressed from dierent angles of view and
at multiple levels of abstraction.
Data mining systems should also allow users to specify hints to guide or focus the search for interesting patterns.
Since some patterns may not hold for all of the data in the database, a measure of certainty or \trustworthiness" is
usually associated with each discovered pattern.
Data mining functionalities, and the kinds of patterns they can discover, are described below.
1.4.1 Concept/class description: characterization and discrimination
Data can be associated with classes or concepts. For example, in the AllElectronics store, classes of items for
sale include computers and printers, and concepts of customers include bigSpenders and budgetSpenders. It can be
useful to describe individual classes and concepts in summarized, concise, and yet precise terms. Such descriptions
of a class or a concept are called class/concept descriptions. These descriptions can be derived via (1) data
CHAPTER 1. INTRODUCTION
14
characterization , by summarizing the data of the class under study (often called the target class) in general terms,
or (2) data discrimination , by comparison of the target class with one or a set of comparative classes (often called
the contrasting classes), or (3) both data characterization and discrimination.
Data characterization is a summarization of the general characteristics or features of a target class of data. The
data corresponding to the user-specied class are typically collected by a database query. For example, to study the
characteristics of software products whose sales increased by 10% in the last year, one can collect the data related
to such products by executing an SQL query.
There are several methods for eective data summarization and characterization. For instance, the data cubebased OLAP roll-up operation (Section 1.3.2) can be used to perform user-controlled data summarization along a
specied dimension. This process is further detailed in Chapter 2 which discusses data warehousing. An attributeoriented induction technique can be used to perform data generalization and characterization without step-by-step
user interaction. This technique is described in Chapter 5.
The output of data characterization can be presented in various forms. Examples include pie charts, bar charts,
curves, multidimensional data cubes, and multidimensional tables, including crosstabs. The resulting descriptions can also be presented as generalized relations, or in rule form (called characteristic rules). These
dierent output forms and their transformations are discussed in Chapter 5.
Example 1.4 A data mining system should be able to produce a description summarizing the characteristics of
customers who spend more than $1000 a year at AllElectronics. The result could be a general prole of the customers
such as they are 40-50 years old, employed, and have excellent credit ratings. The system should allow users to drilldown on any dimension, such as on \employment" in order to view these customers according to their occupation.
2
Data discrimination is a comparison of the general features of target class data objects with the general features
of objets from one or a set of contrasting classes. The target and contrasting classes can be specied by the user,
and the corresponding data objects retrieved through data base queries. For example, one may like to compare the
general features of software products whose sales increased by 10% in the last year with those whose sales decreased
by at least 30% during the same period.
The methods used for data discrimination are similar to those used for data characterization. The forms of output
presentation are also similar, although discrimination descriptions should include comparative measures which help
distinguish between the target and contrasting classes. Discrimination descriptions expressed in rule form are referred
to as discriminant rules. The user should be able to manipulate the output for characteristic and discriminant
descriptions.
Example 1.5 A data mining system should be able to compare two groups of AllElectronics customers, such as
those who shop for computer products regularly (more than 4 times a month) vs. those who rarely shop for such
products (i.e., less than three times a year). The resulting description could be a general, comparative prole of the
customers such as 80% of the customers who frequently purchase computer products are between 20-40 years old
and have a university education, whereas 60% of the customers who infrequently buy such products are either old or
young, and have no university degree. Drilling-down on a dimension, such as occupation, or adding new dimensions,
such as income level, may help in nding even more discriminative features between the two classes.
2
Concept description, including characterization and discrimination, is the topic of Chapter 5.
1.4.2 Association analysis
Association analysis is the discovery of association rules showing attribute-value conditions that occur frequently
together in a given set of data. Association analysis is widely used for market basket or transaction data analysis.
More formally, association rules are of the form X ) Y , i.e., \A1 ^ ^ Am ! B1 ^ ^ Bn ", where Ai (for
i 2 f1; : : :; mg) and Bj (for j 2 f1; : : :; ng) are attribute-value pairs. The association rule X ) Y is interpreted as
\database tuples that satisfy the conditions in X are also likely to satisfy the conditions in Y ".
Example 1.6 Given the AllElectronics relational database, a data mining system may nd association rules like
age(X; \20 , 29") ^ income(X; \20 , 30K") ) buys(X; \CD player")
[support = 2%; confidence = 60%]
1.4. DATA MINING FUNCTIONALITIES | WHAT KINDS OF PATTERNS CAN BE MINED?
15
meaning that of the AllElectronics customers under study, 2% (support) are 20-29 years of age with an income of
20-30K and have purchased a CD player at AllElectronics. There is a 60% probability (condence, or certainty)
that a customer in this age and income group will purchase a CD player.
Note that this is an association between more than one attribute, or predicate (i.e., age, income, and buys).
Adopting the terminology used in multidimensional databases, where each attribute is referred to as a dimension,
the above rule can be referred to as a multidimensional association rule.
Suppose, as a marketing manager of AllElectronics, you would like to determine which items are frequently
purchased together within the same transactions. An example of such a rule is
contains(T; \computer") ) contains(T; \software")
[support = 1%; confidence = 50%]
meaning that if a transaction T contains \computer", there is a 50% chance that it contains \software" as well,
and 1% of all of the transactions contain both. This association rule involves a single attribute or predicate (i.e.,
contains) which repeats. Association rules that contain a single predicate are referred to as single-dimensional
association rules. Dropping the predicate notation, the above rule can be written simply as \computer ) software
[1%, 50%]".
2
In recent years, many algorithms have been proposed for the ecient mining of association rules. Association
rule mining is discussed in detail in Chapter 6.
1.4.3 Classication and prediction
Classication is the processing of nding a set of models (or functions) which describe and distinguish data classes
or concepts, for the purposes of being able to use the model to predict the class of objects whose class label is
unknown. The derived model is based on the analysis of a set of training data (i.e., data objects whose class label
is known).
The derived model may be represented in various forms, such as classication (IF-THEN) rules, decision trees,
mathematical formulae, or neural networks. A decision tree is a ow-chart-like tree structure, where each node
denotes a test on an attribute value, each branch represents an outcome of the test, and tree leaves represent classes
or class distributions. Decision trees can be easily converted to classication rules. A neural network is a collection
of linear threshold units that can be trained to distinguish objects of dierent classes.
Classication can be used for predicting the class label of data objects. However, in many applications, one may
like to predict some missing or unavailable data values rather than class labels. This is usually the case when the
predicted values are numerical data, and is often specically referred to as prediction. Although prediction may
refer to both data value prediction and class label prediction, it is usually conned to data value prediction and
thus is distinct from classication. Prediction also encompasses the identication of distribution trends based on the
available data.
Classication and prediction may need to be preceded by relevance analysis which attempts to identify attributes that do not contribute to the classication or prediction process. These attributes can then be excluded.
Example 1.7 Suppose, as sales manager of AllElectronics, you would like to classify a large set of items in the store,
based on three kinds of responses to a sales campaign: good response, mild response, and no response. You would like
to derive a model for each of these three classes based on the descriptive features of the items, such as price, brand,
place made, type, and category. The resulting classication should maximally distinguish each class from the others,
presenting an organized picture of the data set. Suppose that the resulting classication is expressed in the form of
a decision tree. The decision tree, for instance, may identify price as being the single factor which best distinguishes
the three classes. The tree may reveal that, after price, other features which help further distinguish objects of each
class from another include brand and place made. Such a decision tree may help you understand the impact of the
given sales campaign, and design a more eective campaign for the future.
2
Chapter 7 discusses classication and prediction in further detail.
CHAPTER 1. INTRODUCTION
16
+
+
+
Figure 1.10: A 2-D plot of customer data with respect to customer locations in a city, showing three data clusters.
Each cluster `center' is marked with a `+'.
1.4.4 Clustering analysis
Unlike classication and predication, which analyze class-labeled data objects, clustering analyzes data objects
without consulting a known class label. In general, the class labels are not present in the training data simply
because they are not known to begin with. Clustering can be used to generate such labels. The objects are clustered
or grouped based on the principle of maximizing the intraclass similarity and minimizing the interclass similarity.
That is, clusters of objects are formed so that objects within a cluster have high similarity in comparison to one
another, but are very dissimilar to objects in other clusters. Each cluster that is formed can be viewed as a class
of objects, from which rules can be derived. Clustering can also facilitate taxonomy formation, that is, the
organization of observations into a hierarchy of classes that group similar events together.
Example 1.8 Clustering analysis can be performed on AllElectronics customer data in order to identify homogeneous subpopulations of customers. These clusters may represent individual target groups for marketing. Figure 1.10
shows a 2-D plot of customers with respect to customer locations in a city. Three clusters of data points are evident.
2
Clustering analysis forms the topic of Chapter 8.
1.4.5 Evolution and deviation analysis
Data evolution analysis describes and models regularities or trends for objects whose behavior changes over time.
Although this may include characterization, discrimination, association, classication, or clustering of time-related
data, distinct features of such an analysis include time-series data analysis, sequence or periodicity pattern matching,
and similarity-based data analysis.
Example 1.9 Suppose that you have the major stock market (time-series) data of the last several years available
from the New York Stock Exchange and you would like to invest in shares of high-tech industrial companies. A data
mining study of stock exchange data may identify stock evolution regularities for overall stocks and for the stocks of
particular companies. Such regularities may help predict future trends in stock market prices, contributing to your
decision making regarding stock investments.
2
In the analysis of time-related data, it is often desirable not only to model the general evolutionary trend of
the data, but also to identify data deviations which occur over time. Deviations are dierences between measured
values and corresponding references such as previous values or normative values. A data mining system performing
deviation analysis, upon the detection of a set of deviations, may do the following: describe the characteristics of
the deviations, try to explain the reason behind them, and suggest actions to bring the deviated values back to their
expected values.
1.5. ARE ALL OF THE PATTERNS INTERESTING?
17
Example 1.10 A decrease in total sales at AllElectronics for the last month, in comparison to that of the same
month of the last year, is a deviation pattern. Having detected a signicant deviation, a data mining system may go
further and attempt to explain the detected pattern (e.g., did the company have more sales personnel last year in
comparison to the same period this year?).
2
Data evolution and deviation analysis are discussed in Chapter 9.
1.5 Are all of the patterns interesting?
A data mining system has the potential to generate thousands or even millions of patterns, or rules. Are all of the
patterns interesting? Typically not | only a small fraction of the patterns potentially generated would actually be
of interest to any given user.
This raises some serious questions for data mining: What makes a pattern interesting? Can a data mining system
generate all of the interesting patterns? Can a data mining system generate only the interesting patterns?
To answer the rst question, a pattern is interesting if (1) it is easily understood by humans, (2) valid on new
or test data with some degree of certainty, (3) potentially useful, and (4) novel. A pattern is also interesting if it
validates a hypothesis that the user sought to conrm. An interesting pattern represents knowledge.
Several objective measures of pattern interestingness exist. These are based on the structure of discovered
patterns and the statistics underlying them. An objective measure for association rules of the form X ) Y is rule
support, representing the percentage of data samples that the given rule satises. Another objective measure for
association rules is condence, which assesses the degree of certainty of the detected association. It is dened as
the conditional probability that a pattern Y is true given that X is true. More formally, support and condence are
dened as
support(X ) Y ) = ProbfX [ Y g:
condence (X ) Y ) = ProbfY jX g:
In general, each interestingness measure is associated with a threshold, which may be controlled by the user. For
example, rules that do not satisfy a condence threshold of say, 50%, can be considered uninteresting. Rules below
the threshold likely reect noise, exceptions, or minority cases, and are probably of less value.
Although objective measures help identify interesting patterns, they are insucient unless combined with subjective measures that reect the needs and interests of a particular user. For example, patterns describing the
characteristics of customers who shop frequently at AllElectronics should interest the marketing manager, but may
be of little interest to analysts studying the same database for patterns on employee performance. Furthermore, many
patterns that are interesting by objective standards may represent common knowledge, and therefore, are actually
uninteresting. Subjective interestingness measures are based on user beliefs in the data. These measures nd
patterns interesting if they are unexpected (contradicting a user belief) or oer strategic information on which the
user can act. In the latter case, such patterns are referred to as actionable. Patterns that are expected can be
interesting if they conrm a hypothesis that the user wished to validate, or resemble a user's hunch.
The second question, \Can a data mining system generate of the interesting patterns?", refers to the completeness of a data mining algorithm. It is unrealistic and inecient for data mining systems to generate all of the
possible patterns. Instead, a focused search which makes use of interestingness measures should be used to control
pattern generation. This is often sucient to ensure the completeness of the algorithm. Association rule mining is
an example where the use of interestingness measures can ensure the completeness of mining. The methods involved
are examined in detail in Chapter 6.
Finally, the third question, \Can a data mining system generate
the interesting patterns?", is an optimization
problem in data mining. It is highly desirable for data mining systems to generate only the interesting patterns.
This would be much more ecient for users and data mining systems, since neither would have to search through
the patterns generated in order to identify the truely interesting ones. Such optimization remains a challenging issue
in data mining.
Measures of pattern interestingness are essential for the ecient discovery of patterns of value to the given user.
Such measures can be used after the data mining step in order to rank the discovered patterns according to their
interestingness, ltering out the uninteresting ones. More importantly, such measures can be used to guide and
all
only
CHAPTER 1. INTRODUCTION
18
Database
Systems
Statistics
Information
Science
Visualization
Machine
Learning
Other disciplines
Figure 1.11: Data mining as a conuence of multiple disciplines.
constrain the discovery process, improving the search eciency by pruning away subsets of the pattern space that
do not satisfy pre-specied interestingness constraints.
Methods to assess pattern interestingness, and their use to improve data mining eciency are discussed throughout
the book, with respect to each kind of pattern that can be mined.
1.6 A classication of data mining systems
Data mining is an interdisciplinary eld, the conuence of a set of disciplines (as shown in Figure 1.11), including
database systems, statistics, machine learning, visualization, and information science. Moreover, depending on the
data mining approach used, techniques from other disciplines may be applied, such as neural networks, fuzzy and/or
rough set theory, knowledge representation, inductive logic programming, or high performance computing. Depending
on the kinds of data to be mined or on the given data mining application, the data mining system may also integrate
techniques from spatial data analysis, information retrieval, pattern recognition, image analysis, signal processing,
computer graphics, Web technology, economics, or psychology.
Because of the diversity of disciplines contributing to data mining, data mining research is expected to generate
a large variety of data mining systems. Therefore, it is necessary to provide a clear classication of data mining
systems. Such a classication may help potential users distinguish data mining systems and identify those that best
match their needs. Data mining systems can be categorized according to various criteria, as follows.
Classication according to the kinds of databases mined.
A data mining system can be classied according to the kinds of databases mined. Database systems themselves
can be classied according to dierent criteria (such as data models, or the types of data or applications
involved), each of which may require its own data mining technique. Data mining systems can therefore be
classied accordingly.
For instance, if classifying according to data models, we may have a relational, transactional, object-oriented,
object-relational, or data warehouse mining system. If classifying according to the special types of data handled,
we may have a spatial, time-series, text, or multimedia data mining system, or a World-Wide Web mining
system. Other system types include heterogeneous data mining systems, and legacy data mining systems.
Classication according to the kinds of knowledge mined.
Data mining systems can be categorized according to the kinds of knowledge they mine, i.e., based on data
mining functionalities, such as characterization, discrimination, association, classication, clustering, trend and
evolution analysis, deviation analysis, similarity analysis, etc. A comprehensive data mining system usually
provides multiple and/or integrated data mining functionalities.
Moreover, data mining systems can also be distinguished based on the granularity or levels of abstraction of the
knowledge mined, including generalized knowledge (at a high level of abstraction), primitive-level knowledge
(at a raw data level), or knowledge at multiple levels (considering several levels of abstraction). An advanced
data mining system should facilitate the discovery of knowledge at multiple levels of abstraction.
Classication according to the kinds of techniques utilized.
1.7. MAJOR ISSUES IN DATA MINING
19
Data mining systems can also be categorized according to the underlying data mining techniques employed.
These techniques can be described according to the degree of user interaction involved (e.g., autonomous
systems, interactive exploratory systems, query-driven systems), or the methods of data analysis employed (e.g.,
database-oriented or data warehouse-oriented techniques, machine learning, statistics, visualization, pattern
recognition, neural networks, and so on). A sophisticated data mining system will often adopt multiple data
mining techniques or work out an eective, integrated technique which combines the merits of a few individual
approaches.
Chapters 5 to 8 of this book are organized according to the various kinds of knowledge mined. In Chapter 9, we
discuss the mining of dierent kinds of data on a variety of advanced and application-oriented database systems.
1.7 Major issues in data mining
The scope of this book addresses major issues in data mining regarding mining methodology, user interaction,
performance, and diverse data types. These issues are introduced below:
1. Mining methodology and user-interaction issues. These reect the kinds of knowledge mined, the ability
to mine knowledge at multiple granularities, the use of domain knowledge, ad-hoc mining, and knowledge
visualization.
Mining dierent kinds of knowledge in databases.
Since dierent users can be interested in dierent kinds of knowledge, data mining should cover a wide
spectrum of data analysis and knowledge discovery tasks, including data characterization, discrimination,
association, classication, clustering, trend and deviation analysis, and similarity analysis. These tasks
may use the same database in dierent ways and require the development of numerous data mining
techniques.
Interactive mining of knowledge at multiple levels of abstraction.
Since it is dicult to know exactly what can be discovered within a database, the data mining process
should be interactive. For databases containing a huge amount of data, appropriate sampling technique can
rst be applied to facilitate interactive data exploration. Interactive mining allows users to focus the search
for patterns, providing and rening data mining requests based on returned results. Specically, knowledge
should be mined by drilling-down, rolling-up, and pivoting through the data space and knowledge space
interactively, similar to what OLAP can do on data cubes. In this way, the user can interact with the data
mining system to view data and discovered patterns at multiple granularities and from dierent angles.
Incorporation of background knowledge.
Background knowledge, or information regarding the domain under study, may be used to guide the
discovery process and allow discovered patterns to be expressed in concise terms and at dierent levels of
abstraction. Domain knowledge related to databases, such as integrity constraints and deduction rules,
can help focus and speed up a data mining process, or judge the interestingness of discovered patterns.
Data mining query languages and ad-hoc data mining.
Relational query languages (such as SQL) allow users to pose ad-hoc queries for data retrieval. In a similar
vein, high-level data mining query languages need to be developed to allow users to describe ad-hoc
data mining tasks by facilitating the specication of the relevant sets of data for analysis, the domain
knowledge, the kinds of knowledge to be mined, and the conditions and interestingness constraints to
be enforced on the discovered patterns. Such a language should be integrated with a database or data
warehouse query language, and optimized for ecient and exible data mining.
Presentation and visualization of data mining results.
Discovered knowledge should be expressed in high-level languages, visual representations, or other expressive forms so that the knowledge can be easily understood and directly usable by humans. This is
especially crucial if the data mining system is to be interactive. This requires the system to adopt expressive knowledge representation techniques, such as trees, tables, rules, graphs, charts, crosstabs, matrices,
or curves.
CHAPTER 1. INTRODUCTION
20
Handling outlier or incomplete data.
The data stored in a database may reect outliers | noise, exceptional cases, or incomplete data objects.
These objects may confuse the analysis process, causing overtting of the data to the knowledge model
constructed. As a result, the accuracy of the discovered patterns can be poor. Data cleaning methods
and data analysis methods which can handle outliers are required. While most methods discard outlier
data, such data may be of interest in itself such as in fraud detection for nding unusual usage of telecommunication services or credit cards. This form of data analysis is known as outlier mining.
Pattern evaluation: the interestingness problem.
A data mining system can uncover thousands of patterns. Many of the patterns discovered may be uninteresting to the given user, representing common knowledge or lacking novelty. Several challenges remain
regarding the development of techniques to assess the interestingness of discovered patterns, particularly
with regard to subjective measures which estimate the value of patterns with respect to a given user class,
based on user beliefs or expectations. The use of interestingness measures to guide the discovery process
and reduce the search space is another active area of research.
2. Performance issues. These include eciency, scalability, and parallelization of data mining algorithms.
Eciency and scalability of data mining algorithms.
To eectively extract information from a huge amount of data in databases, data mining algorithms must
be ecient and scalable. That is, the running time of a data mining algorithm must be predictable and
acceptable in large databases. Algorithms with exponential or even medium-order polynomial complexity
will not be of practical use. From a database perspective on knowledge discovery, eciency and scalability
are key issues in the implementation of data mining systems. Many of the issues discussed above under
mining methodology and user-interaction must also consider eciency and scalability.
Parallel, distributed, and incremental updating algorithms.
The huge size of many databases, the wide distribution of data, and the computational complexity of
some data mining methods are factors motivating the development of parallel and distributed data
mining algorithms. Such algorithms divide the data into partitions, which are processed in parallel.
The results from the partitions are then merged. Moreover, the high cost of some data mining processes
promotes the need for incremental data mining algorithms which incorporate database updates without
having to mine the entire data again \from scratch". Such algorithms perform knowledge modication
incrementally to amend and strengthen what was previously discovered.
3. Issues relating to the diversity of database types.
Handling of relational and complex types of data.
There are many kinds of data stored in databases and data warehouses. Can we expect that a single
data mining system can perform eective mining on all kinds of data? Since relational databases and data
warehouses are widely used, the development of ecient and eective data mining systems for such data is
important. However, other databases may contain complex data objects, hypertext and multimedia data,
spatial data, temporal data, or transaction data. It is unrealistic to expect one system to mine all kinds
of data due to the diversity of data types and dierent goals of data mining. Specic data mining systems
should be constructed for mining specic kinds of data. Therefore, one may expect to have dierent data
mining systems for dierent kinds of data.
Mining information from heterogeneous databases and global information systems.
Local and wide-area computer networks (such as the Internet) connect many sources of data, forming
huge, distributed, and heterogeneous databases. The discovery of knowledge from dierent sources of
structured, semi-structured, or unstructured data with diverse data semantics poses great challenges
to data mining. Data mining may help disclose high-level data regularities in multiple heterogeneous
databases that are unlikely to be discovered by simple query systems and may improve information
exchange and interoperability in heterogeneous databases.
The above issues are considered major requirements and challenges for the further evolution of data mining
technology. Some of the challenges have been addressed in recent data mining research and development, to a
1.8. SUMMARY
21
certain extent, and are now considered requirements, while others are still at the research stage. The issues, however,
continue to stimulate further investigation and improvement. Additional issues relating to applications, privacy, and
the social impact of data mining are discussed in Chapter 10, the nal chapter of this book.
1.8 Summary
Database technology has evolved from primitive le processing to the development of database management
systems with query and transaction processing. Further progress has led to the increasing demand for ecient
and eective data analysis and data understanding tools. This need is a result of the explosive growth in
data collected from applications including business and management, government administration, scientic
and engineering, and environmental control.
Data mining is the task of discovering interesting patterns from large amounts of data where the data can
be stored in databases, data warehouses, or other information repositories. It is a young interdisciplinary eld,
drawing from areas such as database systems, data warehousing, statistics, machine learning, data visualization,
information retrieval, and high performance computing. Other contributing areas include neural networks,
pattern recognition, spatial data analysis, image databases, signal processing, and inductive logic programming.
A knowledge discovery process includes data cleaning, data integration, data selection, data transformation,
data mining, pattern evaluation, and knowledge presentation.
Data patterns can be mined from many dierent kinds of databases, such as relational databases, data
warehouses, and transactional, object-relational, and object-oriented databases. Interesting data patterns
can also be extracted from other kinds of information repositories, including spatial, time-related, text,
multimedia, and legacy databases, and the World-Wide Web.
A data warehouse is a repository for long term storage of data from multiple sources, organized so as
to facilitate management decision making. The data are stored under a unied schema, and are typically
summarized. Data warehouse systems provide some data analysis capabilities, collectively referred to as OLAP
(On-Line Analytical Processing). OLAP operations include drill-down, roll-up, and pivot.
Data mining functionalities include the discovery of concept/class descriptions (i.e., characterization and
discrimination), association, classication, prediction, clustering, trend analysis, deviation analysis, and similarity analysis. Characterization and discrimination are forms of data summarization.
A pattern represents knowledge if it is easily understood by humans, valid on test data with some degree
of certainty, potentially useful, novel, or validates a hunch about which the user was curious. Measures of
pattern interestingness, either objective or subjective, can be used to guide the discovery process.
Data mining systems can be classied according to the kinds of databases mined, the kinds of knowledge
mined, or the techniques used.
Ecient and eective data mining in large databases poses numerous requirements and great challenges to
researchers and developers. The issues involved include data mining methodology, user-interaction, performance
and scalability, and the processing of a large variety of data types. Other issues include the exploration of data
mining applications, and their social impacts.
Exercises
1. What is data mining? In your answer, address the following:
(a) Is it another hype?
(b) Is it a simple transformation of technology developed from databases, statistics, and machine learning?
(c) Explain how the evolution of database technology led to data mining.
(d) Describe the steps involved in data mining when viewed as a process of knowledge discovery.
CHAPTER 1. INTRODUCTION
22
2. Present an example where data mining is crucial to the success of a business. What data mining functions
does this business need? Can they be performed alternatively by data query processing or simple statistical
analysis?
3. How is a data warehouse dierent from a database? How are they similar to each other?
4. Dene each of the following data mining functionalities: characterization, discrimination, association, classication, prediction, clustering, and evolution and deviation analysis. Give examples of each data mining
functionality, using a real-life database that you are familiar with.
5. Suppose your task as a software engineer at Big-University is to design a data mining system to examine
their university course database, which contains the following information: the name, address, and status (e.g.,
undergraduate or graduate) of each student, and their cumulative grade point average (GPA). Describe the
architecture you would choose. What is the purpose of each component of this architecture?
6. Based on your observation, describe another possible kind of knowledge that needs to be discovered by data
mining methods but has not been listed in this chapter. Does it require a mining methodology that is quite
dierent from those outlined in this chapter?
7. What is the dierence between discrimination and classication? Between characterization and clustering?
Between classication and prediction? For each of these pairs of tasks, how are they similar?
8. Describe three challenges to data mining regarding data mining methodology and user-interaction issues.
9. Describe two challenges to data mining regarding performance issues.
Bibliographic Notes
The book Knowledge Discovery in Databases, edited by Piatetsky-Shapiro and Frawley [26], is an early collection of
research papers on knowledge discovery in databases. The book Advances in Knowledge Discovery and Data Mining,
edited by Fayyad et al. [10], is a good collection of recent research results on knowledge discovery and data mining.
Other books on data mining include Predictive Data Mining by Weiss and Indurkhya [37], and Data Mining by
Adriaans and Zantinge [1]. There are also books containing collections of papers on particular aspects of knowledge
discovery, such as Machine Learning & Data Mining: Methods and Applications, edited by Michalski, Bratko, and
Kubat [20], Rough Sets, Fuzzy Sets and Knowledge Discovery, edited by Ziarko [39], as well as many tutorial notes
on data mining, such as Tutorial Notes of 1999 International Conference on Knowledge Disocvery and Data Mining
(KDD99) published by ACM Press.
KDD Nuggets is a regular, free electronic newsletter containing information relevant to knowledge discovery and
data mining. Contributions can be e-mailed with a descriptive subject line (and a URL) to \[email protected]".
Information regarding subscription can be found at \http://www.kdnuggets.com/subscribe.html". KDD Nuggets
has been moderated by Piatetsky-Shapiro since 1991. The Internet site, Knowledge Discovery Mine, located at
\http://www.kdnuggets.com/", contains a good collection of KDD-related information.
The research community of data mining set up a new academic organization called ACM-SIGKDD, a Special
Interested Group on Knowledge Discovery in Databases under ACM in 1998. The community started its rst
international conference on knowledge discovery and data mining in 1995 [12]. The conference evolved from the four
international workshops on knowledge discovery in databases, held from 1989 to 1994 [7, 8, 13, 11]. ACM-SIGKDD
is organizing its rst, but the fth international conferences on knowledge discovery and data mining (KDD'99). A
new journal, Data Mining and Knowledge Discovery, published by Kluwers Publishers, has been available since 1997.
Research in data mining has also been published in major textbooks, conferences and journals on databases,
statistics, machine learning, and data visualization. References to such sources are listed below.
Popular textbooks on database systems include Database System Concepts, 3rd ed., by Silberschatz, Korth, and
Sudarshan [30], Fundamentals of Database Systems, 2nd ed., by Elmasri and Navathe [9], and Principles of Database
and Knowledge-Base Systems, Vol. 1, by Ullman [36]. For an edited collection of seminal articles on database
systems, see Readings in Database Systems by Stonebraker [32]. Overviews and discussions on the achievements and
research challenges in database systems can be found in Stonebraker et al. [33], and Silberschatz, Stonebraker, and
Ullman [31].
1.8. SUMMARY
23
Many books on data warehouse technology, systems and applications have been published in the last several years,
such as The Data Warehouse Toolkit by Kimball [17], and Building the Data Warehouse by Inmon [14]. Chaudhuri
and Dayal [3] present a comprehensive overview of data warehouse technology.
Research results relating to data mining and data warehousing have been published in the proceedings of many
international database conferences, including ACM-SIGMOD International Conference on Management of Data
(SIGMOD), International Conference on Very Large Data Bases (VLDB), ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS), International Conference on Data Engineering (ICDE), International Conference on Extending Database Technology (EDBT), International Conference on Database Theory
(ICDT), International Conference on Information and Knowledge Management (CIKM), and International Symposium on Database Systems for Advanced Applications (DASFAA). Research in data mining is also published in
major database journals, such as IEEE Transactions on Knowledge and Data Engineering (TKDE), ACM Transactions on Database Systems (TODS), Journal of ACM (JACM), Information Systems, The VLDB Journal, Data and
Knowledge Engineering, and International Journal of Intelligent Information Systems (JIIS).
There are many textbooks covering dierent topics in statistical analysis, such as Probability and Statistics for
Engineering and the Sciences, 4th ed. by Devore [4], Applied Linear Statistical Models, 4th ed. by Neter et al. [25],
An Introduction to Generalized Linear Models by Dobson [5], Applied Statistical Time Series Analysis by Shumway
[29], and Applied Multivariate Statistical Analysis, 3rd ed. by Johnson and Wichern [15].
Research in statistics is published in the proceedings of several major statistical conferences, including Joint
Statistical Meetings, International Conference of the Royal Statistical Society, and Symposium on the Interface:
Computing Science and Statistics. Other source of publication include the Journal of the Royal Statistical Society,
The Annals of Statistics, Journal of American Statistical Association, Technometrics, and Biometrika.
Textbooks and reference books on machine learning include Machine Learning by Mitchell [24], Machine Learning,
An Articial Intelligence Approach, Vols. 1-4, edited by Michalski et al. [21, 22, 18, 23], C4.5: Programs for Machine
Learning by Quinlan [27], and Elements of Machine Learning by Langley [19]. The book Computer Systems that
Learn: Classication and Prediction Methods from Statistics, Neural Nets, Machine Learning, and Expert Systems,
by Weiss and Kulikowski [38], compares classication and prediction methods from several dierent elds, including
statistics, machine learning, neural networks, and expert systems. For an edited collection of seminal articles on
machine learning, see Readings in Machine Learning by Shavlik and Dietterich [28].
Machine learning research is published in the proceedings of several large machine learning and articial intelligence conferences, including the International Conference on Machine Learning (ML), ACM Conference on Computational Learning Theory (COLT), International Joint Conference on Articial Intelligence (IJCAI), and American
Association of Articial Intelligence Conference (AAAI). Other sources of publication include major machine learning, articial intelligence, and knowledge system journals, some of which have been mentioned above. Others include
Machine Learning (ML), Articial Intelligence Journal (AI) and Cognitive Science. An overview of classication
from a statistical pattern recognition perspective can be found in Duda and Hart [6].
Pioneering work on data visualization techniques is described in The Visual Display of Quantitative Information
[34] and Envisioning Information [35], both by Tufte, and Graphics and Graphic Information Processing by Bertin [2].
Visual Techniques for Exploring Databases by Keim [16] presents a broad tutorial on visualization for data mining.
Major conferences and symposiums on visualization include ACM Human Factors in Computing Systems (CHI),
Visualization, and International Symposium on Information Visualization. Research on visualization is also published
in Transactions on Visualization and Computer Graphics, Journal of Computational and Graphical Statistics, and
IEEE Computer Graphics and Applications.
24
CHAPTER 1. INTRODUCTION
Bibliography
[1] P. Adriaans and D. Zantinge. Data Mining. Addison-Wesley: Harlow, England, 1996.
[2] J. Bertin. Graphics and Graphic Information Processing. Berlin, 1981.
[3] S. Chaudhuri and U. Dayal. An overview of data warehousing and OLAP technology. ACM SIGMOD Record,
26:65{74, 1997.
[4] J. L. Devore. Probability and Statistics for Engineering and the Science, 4th ed. Duxbury Press, 1995.
[5] A. J. Dobson. An Introduction to Generalized Linear Models. Chapman and Hall, 1990.
[6] R. Duda and P. Hart. Pattern Classication and Scene Analysis. Wiley: New York, 1973.
[7] G. Piatetsky-Shapiro (ed.). Notes of IJCAI'89 Workshop Knowledge Discovery in Databases (KDD'89). Detroit,
Michigan, July 1989.
[8] G. Piatetsky-Shapiro (ed.). Notes of AAAI'91 Workshop Knowledge Discovery in Databases (KDD'91). Anaheim, CA, July 1991.
[9] R. Elmasri and S. B. Navathe. Fundamentals of Database Systems, 2nd ed. Bemjamin/Cummings, 1994.
[10] U. M. Fayyad, G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy (eds.). Advances in Knowledge Discovery
and Data Mining. AAAI/MIT Press, 1996.
[11] U.M. Fayyad and R. Uthurusamy (eds.). Notes of AAAI'94 Workshop Knowledge Discovery in Databases
(KDD'94). Seattle, WA, July 1994.
[12] U.M. Fayyad and R. Uthurusamy (eds.). Proc. 1st Int. Conf. Knowledge Discovery and Data Mining (KDD'95).
AAAI Press, Aug. 1995.
[13] U.M. Fayyad, R. Uthurusamy, and G. Piatetsky-Shapiro (eds.). Notes of AAAI'93 Workshop Knowledge Discovery in Databases (KDD'93). Washington, DC, July 1993.
[14] W. H. Inmon. Building the Data Warehouse. John Wiley, 1996.
[15] R. A. Johnson and D. W. Wickern. Applied Multivariate Statistical Analysis, 3rd ed. Prentice Hall, 1992.
[16] D. A. Keim. Visual techniques for exploring databases. In Tutorial Notes, 3rd Int. Conf. on Knowledge Discovery
and Data Mining (KDD'97), Newport Beach, CA, Aug. 1997.
[17] R. Kimball. The Data Warehouse Toolkit. John Wiley & Sons, New York, 1996.
[18] Y. Kodrato and R. S. Michalski. Machine Learning, An Articial Intelligence Approach, Vol. 3. Morgan
Kaufmann, 1990.
[19] P. Langley. Elements of Machine Learning. Morgan Kaufmann, 1996.
[20] R. S. Michalski, I. Bratko, and M. Kubat. Machine Learning and Data Mining: Methods and Applications. John
Wiley & Sons, 1998.
25
26
BIBLIOGRAPHY
[21] R. S. Michalski, J. G. Carbonell, and T. M. Mitchell. Machine Learning, An Articial Intelligence Approach,
Vol. 1. Morgan Kaufmann, 1983.
[22] R. S. Michalski, J. G. Carbonell, and T. M. Mitchell. Machine Learning, An Articial Intelligence Approach,
Vol. 2. Morgan Kaufmann, 1986.
[23] R. S. Michalski and G. Tecuci. Machine Learning, A Multistrategy Approach, Vol. 4. Morgan Kaufmann, 1994.
[24] T. M. Mitchell. Machine Learning. McGraw Hill, 1997.
[25] J. Neter, M. H. Kutner, C. J. Nachtsheim, and L. Wasserman. Applied Linear Statistical Models, 4th ed. Irwin:
Chicago, 1996.
[26] G. Piatetsky-Shapiro and W. J. Frawley. Knowledge Discovery in Databases. AAAI/MIT Press, 1991.
[27] J. R. Quinlan. C4.5: Programs for Machine Learning. Morgan Kaufmann, 1993.
[28] J.W. Shavlik and T.G. Dietterich. Readings in Machine Learning. Morgan Kaufmann, 1990.
[29] R. H. Shumway. Applied Statistical Time Series Analysis. Prentice Hall, 1988.
[30] A. Silberschatz, H. F. Korth, and S. Sudarshan. Database System Concepts, 3ed. McGraw-Hill, 1997.
[31] A. Silberschatz, M. Stonebraker, and J. D. Ullman. Database research: Achievements and opportunities into
the 21st century. ACM SIGMOD Record, 25:52{63, March 1996.
[32] M. Stonebraker. Readings in Database Systems, 2ed. Morgan Kaufmann, 1993.
[33] M. Stonebraker, R. Agrawal, U. Dayal, E. Neuhold, and A. Reuter. DBMS research at a crossroads: The vienna
update. In Proc. 19th Int. Conf. Very Large Data Bases, pages 688{692, Dublin, Ireland, Aug. 1993.
[34] E. R. Tufte. The Visual Display of Quantitative Information. Graphics Press, Cheshire, CT, 1983.
[35] E. R. Tufte. Envisioning Information. Graphics Press, Cheshire, CT, 1990.
[36] J. D. Ullman. Principles of Database and Knowledge-Base Systems, Vol. 1. Computer Science Press, 1988.
[37] S. M. Weiss and N. Indurkhya. Predictive Data Mining. Morgan Kaufmann, 1998.
[38] S. M. Weiss and C. A. Kulikowski. Computer Systems that Learn: Classication and Prediction Methods from
Statistics, Neural Nets, Machine Learning, and Expert Systems. Morgan Kaufman, 1991.
[39] W. Ziarko. Rough Sets, Fuzzy Sets and Knowledge Discovery. Springer-Verlag, 1994.
Contents
2 Data Warehouse and OLAP Technology for Data Mining
2.1 What is a data warehouse? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2 A multidimensional data model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2.1 From tables to data cubes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2.2 Stars, snowakes, and fact constellations: schemas for multidimensional databases
2.2.3 Examples for dening star, snowake, and fact constellation schemas . . . . . . . .
2.2.4 Measures: their categorization and computation . . . . . . . . . . . . . . . . . . .
2.2.5 Introducing concept hierarchies . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2.6 OLAP operations in the multidimensional data model . . . . . . . . . . . . . . . .
2.2.7 A starnet query model for querying multidimensional databases . . . . . . . . . . .
2.3 Data warehouse architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.3.1 Steps for the design and construction of data warehouses . . . . . . . . . . . . . .
2.3.2 A three-tier data warehouse architecture . . . . . . . . . . . . . . . . . . . . . . . .
2.3.3 OLAP server architectures: ROLAP vs. MOLAP vs. HOLAP . . . . . . . . . . . .
2.3.4 SQL extensions to support OLAP operations . . . . . . . . . . . . . . . . . . . . .
2.4 Data warehouse implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.4.1 Ecient computation of data cubes . . . . . . . . . . . . . . . . . . . . . . . . . .
2.4.2 Indexing OLAP data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.4.3 Ecient processing of OLAP queries . . . . . . . . . . . . . . . . . . . . . . . . . .
2.4.4 Metadata repository . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.4.5 Data warehouse back-end tools and utilities . . . . . . . . . . . . . . . . . . . . . .
2.5 Further development of data cube technology . . . . . . . . . . . . . . . . . . . . . . . . .
2.5.1 Discovery-driven exploration of data cubes . . . . . . . . . . . . . . . . . . . . . .
2.5.2 Complex aggregation at multiple granularities: Multifeature cubes . . . . . . . . .
2.6 From data warehousing to data mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.6.1 Data warehouse usage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.6.2 From on-line analytical processing to on-line analytical mining . . . . . . . . . . .
2.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
3
3
6
6
8
11
13
14
15
18
19
19
20
22
24
24
25
30
30
31
32
32
33
36
38
38
39
41
2
CONTENTS
c J. Han and M. Kamber, 1998, DRAFT!! DO NOT COPY!! DO NOT DISTRIBUTE!!
September 7, 1999
Chapter 2
Data Warehouse and OLAP Technology
for Data Mining
The construction of data warehouses, which involves data cleaning and data integration, can be viewed as an
important preprocessing step for data mining. Moreover, data warehouses provide on-line analytical processing
(OLAP) tools for the interactive analysis of multidimensional data of varied granularities, which facilitates eective
data mining. Furthermore, many other data mining functions such as classication, prediction, association, and
clustering, can be integrated with OLAP operations to enhance interactive mining of knowledge at multiple levels
of abstraction. Hence, data warehouse has become an increasingly important platform for data analysis and online analytical processing and will provide an eective platform for data mining. Therefore, prior to presenting a
systematic coverage of data mining technology in the remainder of this book, we devote this chapter to an overview
of data warehouse technology. Such an overview is essential for understanding data mining technology.
In this chapter, you will learn the basic concepts, general architectures, and major implementation techniques
employed in data warehouse and OLAP technology, as well as their relationship with data mining.
2.1 What is a data warehouse?
Data warehousing provides architectures and tools for business executives to systematically organize, understand,
and use their data to make strategic decisions. A large number of organizations have found that data warehouse
systems are valuable tools in today's competitive, fast evolving world. In the last several years, many rms have spent
millions of dollars in building enterprise-wide data warehouses. Many people feel that with competition mounting in
every industry, data warehousing is the latest must-have marketing weapon | a way to keep customers by learning
more about their needs.
\So", you may ask, full of intrigue, \what exactly is a data warehouse?"
Data warehouses have been dened in many ways, making it dicult to formulate a rigorous denition. Loosely
speaking, a data warehouse refers to a database that is maintained separately from an organization's operational
databases. Data warehouse systems allow for the integration of a variety of application systems. They support
information processing by providing a solid platform of consolidated, historical data for analysis.
According to W. H. Inmon, a leading architect in the construction of data warehouse systems, \a data warehouse
is a subject-oriented, integrated, time-variant, and nonvolatile collection of data in support of management's
decision making process." (Inmon 1992). This short, but comprehensive denition presents the major features of
a data warehouse. The four keywords, subject-oriented, integrated, time-variant, and nonvolatile, distinguish data
warehouses from other data repository systems, such as relational database systems, transaction processing systems,
and le systems. Let's take a closer look at each of these key features.
Subject-oriented: A data warehouse is organized around major subjects, such as customer, vendor, product,
and sales. Rather than concentrating on the day-to-day operations and transaction processing of an organization, a data warehouse focuses on the modeling and analysis of data for decision makers. Hence, data
3
4
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
warehouses typically provide a simple and concise view around particular subject issues by excluding data that
are not useful in the decision support process.
Integrated: A data warehouse is usually constructed by integrating multiple heterogeneous sources, such as
relational databases, at les, and on-line transaction records. Data cleaning and data integration techniques
are applied to ensure consistency in naming conventions, encoding structures, attribute measures, and so on.
Time-variant: Data are stored to provide information from a historical perspective (e.g., the past 5-10 years).
Every key structure in the data warehouse contains, either implicitly or explicitly, an element of time.
Nonvolatile: A data warehouse is always a physically separate store of data transformed from the application
data found in the operational environment. Due to this separation, a data warehouse does not require transaction processing, recovery, and concurrency control mechanisms. It usually requires only two operations in data
accessing: initial loading of data and access of data.
In sum, a data warehouse is a semantically consistent data store that serves as a physical implementation of a
decision support data model and stores the information on which an enterprise needs to make strategic decisions. A
data warehouse is also often viewed as an architecture, constructed by integrating data from multiple heterogeneous
sources to support structured and/or ad hoc queries, analytical reporting, and decision making.
\OK", you now ask, \what, then, is data warehousing?"
Based on the above, we view data warehousing as the process of constructing and using data warehouses. The
construction of a data warehouse requires data integration, data cleaning, and data consolidation. The utilization of
a data warehouse often necessitates a collection of decision support technologies. This allows \knowledge workers"
(e.g., managers, analysts, and executives) to use the warehouse to quickly and conveniently obtain an overview of
the data, and to make sound decisions based on information in the warehouse. Some authors use the term \data
warehousing" to refer only to the process of data warehouse construction , while the term warehouse DBMS is
used to refer to the management and utilization of data warehouses. We will not make this distinction here.
\How are organizations using the information from data warehouses?" Many organizations are using this information to support business decision making activities, including (1) increasing customer focus, which includes
the analysis of customer buying patterns (such as buying preference, buying time, budget cycles, and appetites for
spending), (2) repositioning products and managing product portfolios by comparing the performance of sales by
quarter, by year, and by geographic regions, in order to ne-tune production strategies, (3) analyzing operations and
looking for sources of prot, and (4) managing the customer relationships, making environmental corrections, and
managing the cost of corporate assets.
Data warehousing is also very useful from the point of view of heterogeneous database integration. Many organizations typically collect diverse kinds of data and maintain large databases from multiple, heterogeneous, autonomous,
and distributed information sources. To integrate such data, and provide easy and ecient access to it is highly
desirable, yet challenging. Much eort has been spent in the database industry and research community towards
achieving this goal.
The traditional database approach to heterogeneous database integration is to build wrappers and integrators
(or mediators) on top of multiple, heterogeneous databases. A variety of data joiner and data blade products
belong to this category. When a query is posed to a client site, a metadata dictionary is used to translate the
query into queries appropriate for the individual heterogeneous sites involved. These queries are then mapped and
sent to local query processors. The results returned from the dierent sites are integrated into a global answer set.
This query-driven approach requires complex information ltering and integration processes, and competes for
resources with processing at local sources. It is inecient and potentially expensive for frequent queries, especially
for queries requiring aggregations.
Data warehousing provides an interesting alternative to the traditional approach of heterogeneous database integration described above. Rather than using a query-driven approach, data warehousing employs an update-driven
approach in which information from multiple, heterogeneous sources is integrated in advance and stored in a warehouse for direct querying and analysis. Unlike on-line transaction processing databases, data warehouses do not
contain the most current information. However, a data warehouse brings high performance to the integrated heterogeneous database system since data are copied, preprocessed, integrated, annotated, summarized, and restructured
into one semantic data store. Furthermore, query processing in data warehouses does not interfere with the processing at local sources. Moreover, data warehouses can store and integrate historical information and support complex
multidimensional queries. As a result, data warehousing has become very popular in industry.
2.1. WHAT IS A DATA WAREHOUSE?
5
Dierences between operational database systems and data warehouses
Since most people are familiar with commercial relational database systems, it is easy to understand what a data
warehouse is by comparing these two kinds of systems.
The major task of on-line operational database systems is to perform on-line transaction and query processing.
These systems are called on-line transaction processing (OLTP) systems. They cover most of the day-today operations of an organization, such as, purchasing, inventory, manufacturing, banking, payroll, registration,
and accounting. Data warehouse systems, on the other hand, serve users or \knowledge workers" in the role of
data analysis and decision making. Such systems can organize and present data in various formats in order to
accommodate the diverse needs of the dierent users. These systems are known as on-line analytical processing
(OLAP) systems.
The major distinguishing features between OLTP and OLAP are summarized as follows.
1. Users and system orientation: An OLTP system is customer-oriented and is used for transaction and query
processing by clerks, clients, and information technology professionals. An OLAP system is market-oriented
and is used for data analysis by knowledge workers, including managers, executives, and analysts.
2. Data contents: An OLTP system manages current data that, typically, are too detailed to be easily used for
decision making. An OLAP system manages large amounts of historical data, provides facilities for summarization and aggregation, and stores and manages information at dierent levels of granularity. These features
make the data easier for use in informed decision making.
3. Database design: An OLTP system usually adopts an entity-relationship (ER) data model and an applicationoriented database design. An OLAP system typically adopts either a star or snowake model (to be discussed
in Section 2.2.2), and a subject-oriented database design.
4. View: An OLTP system focuses mainly on the current data within an enterprise or department, without
referring to historical data or data in dierent organizations. In contrast, an OLAP system often spans multiple
versions of a database schema, due to the evolutionary process of an organization. OLAP systems also deal
with information that originates from dierent organizations, integrating information from many data stores.
Because of their huge volume, OLAP data are stored on multiple storage media.
5. Access patterns: The access patterns of an OLTP system consist mainly of short, atomic transactions. Such
a system requires concurrency control and recovery mechanisms. However, accesses to OLAP systems are
mostly read-only operations (since most data warehouses store historical rather than up-to-date information),
although many could be complex queries.
Other features which distinguish between OLTP and OLAP systems include database size, frequency of operations,
and performance metrics. These are summarized in Table 2.1.
But, why have a separate data warehouse?
\Since operational databases store huge amounts of data", you observe, \why not perform on-line analytical
processing directly on such databases instead of spending additional time and resources to construct a separate data
warehouse?"
A major reason for such a separation is to help promote the high performance of both systems. An operational
database is designed and tuned from known tasks and workloads, such as indexing and hashing using primary keys,
searching for particular records, and optimizing \canned" queries. On the other hand, data warehouse queries are
often complex. They involve the computation of large groups of data at summarized levels, and may require the
use of special data organization, access, and implementation methods based on multidimensional views. Processing
OLAP queries in operational databases would substantially degrade the performance of operational tasks.
Moreover, an operational database supports the concurrent processing of several transactions. Concurrency
control and recovery mechanisms, such as locking and logging, are required to ensure the consistency and robustness
of transactions. An OLAP query often needs read-only access of data records for summarization and aggregation.
Concurrency control and recovery mechanisms, if applied for such OLAP operations, may jeopardize the execution
of concurrent transactions and thus substantially reduce the throughput of an OLTP system.
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
6
Feature
Characteristic
Orientation
User
Function
DB design
Data
Summarization
View
Unit of work
Access
Focus
Operations
# of records accessed
# of users
DB size
Priority
Metric
OLTP
operational processing
transaction
clerk, DBA, database professional
day-to-day operations
OLAP
informational processing
analysis
knowledge worker (e.g., manager, executive, analyst)
long term informational requirements,
decision support
E-R based, application-oriented
star/snowake, subject-oriented
current; guaranteed up-to-date
historical; accuracy maintained over time
primitive, highly detailed
summarized, consolidated
detailed, at relational
summarized, multidimensional
short, simple transaction
complex query
read/write
mostly read
data in
information out
index/hash on primary key
lots of scans
tens
millions
thousands
hundreds
100 MB to GB
100 GB to TB
high performance, high availability high exibility, end-user autonomy
transaction throughput
query throughput, response time
Table 2.1: Comparison between OLTP and OLAP systems.
Finally, the separation of operational databases from data warehouses is based on the dierent structures, contents,
and uses of the data in these two systems. Decision support requires historical data, whereas operational databases
do not typically maintain historical data. In this context, the data in operational databases, though abundant, is
usually far from complete for decision making. Decision support requires consolidation (such as aggregation and
summarization) of data from heterogeneous sources, resulting in high quality, cleansed and integrated data. In
contrast, operational databases contain only detailed raw data, such as transactions, which need to be consolidated
before analysis. Since the two systems provide quite dierent functionalities and require dierent kinds of data, it is
necessary to maintain separate databases.
2.2 A multidimensional data model
Data warehouses and OLAP tools are based on a multidimensional data model. This model views data in the
form of a data cube. In this section, you will learn how data cubes model n-dimensional data. You will also learn
about concept hierarchies and how they can be used in basic OLAP operations to allow interactive mining at multiple
levels of abstraction.
2.2.1 From tables to data cubes
\What is a data cube?"
A data cube allows data to be modeled and viewed in multiple dimensions. It is dened by dimensions and
facts.
In general terms, dimensions are the perspectives or entities with respect to which an organization wants to
keep records. For example, AllElectronics may create a sales data warehouse in order to keep records of the store's
sales with respect to the dimensions time, item, branch, and location. These dimensions allow the store to keep track
of things like monthly sales of items, and the branches and locations at which the items were sold. Each dimension
may have a table associated with it, called a dimension table, which further describes the dimension. For example,
a dimension table for item may contain the attributes item name, brand, and type. Dimension tables can be specied
by users or experts, or automatically generated and adjusted based on data distributions.
A multidimensional data model is typically organized around a central theme, like sales, for instance. This theme
2.2. A MULTIDIMENSIONAL DATA MODEL
7
is represented by a fact table. Facts are numerical measures. Think of them as the quantities by which we want to
analyze relationships between dimensions. Examples of facts for a sales data warehouse include dollars sold (sales
amount in dollars), units sold (number of units sold), and amount budgeted. The fact table contains the names of
the facts, or measures, as well as keys to each of the related dimension tables. You will soon get a clearer picture of
how this works when we later look at multidimensional schemas.
Although we usually think of cubes as 3-D geometric structures, in data warehousing the data cube is ndimensional. To gain a better understanding of data cubes and the multidimensional data model, let's start by
looking at a simple 2-D data cube which is, in fact, a table for sales data from AllElectronics. In particular, we will
look at the AllElectronics sales data for items sold per quarter in the city of Vancouver. These data are shown in
Table 2.2. In this 2-D representation, the sales for Vancouver are shown with respect to the time dimension (organized in quarters) and the item dimension (organized according to the types of items sold). The fact, or measure
displayed is dollars sold.
Sales for all locations in Vancouver
time (quarter) item (type)
home
entertainment
605K
680K
812K
927K
Q1
Q2
Q3
Q4
computer phone security
825K
952K
1023K
1038K
14K
31K
30K
38K
400K
512K
501K
580K
Table 2.2: A 2-D view of sales data for AllElectronics according to the dimensions time and item, where the sales
are from branches located in the city of Vancouver. The measure displayed is dollars sold.
t
i
m
e
Q1
Q2
Q3
Q4
location = \Vancouver"
item
home
ent.
comp.
phone
sec.
605K
680K
812K
927K
825K
952K
1023K
1038K
14K
31K
30K
38K
400K
512K
501K
580K
location = \Montreal"
item
home
ent.
comp.
phone
sec.
818K
894K
940K
978K
746K
769K
795K
864K
43K
52K
58K
59K
591K
682K
728K
784K
location = \New York"
item
home
ent.
comp.
phone
sec.
1087K
1130K
1034K
1142K
968K
1024K
1048K
1091K
38K
41K
45K
54K
872K
925K
1002K
984K
location = \Chicago"
item
home
ent.
comp.
phone
sec.
854K
943K
1032K
1129K
882K
890K
924K
992K
89K
64K
59K
63K
623K
698K
789K
870K
Table 2.3: A 3-D view of sales data for AllElectronics, according to the dimensions time, item, and location. The
measure displayed is dollars sold.
Now, suppose that we would like to view the sales data with a third dimension. For instance, suppose we would
like to view the data according to time, item, as well as location. These 3-D data are shown in Table 2.3. The 3-D
data of Table 2.3 are represented as a series of 2-D tables. Conceptually, we may also represent the same data in the
form of a 3-D data cube, as in Figure 2.1.
Suppose that we would now like to view our sales data with an additional fourth dimension, such as supplier.
Viewing things in 4-D becomes tricky. However, we can think of a 4-D cube as being a series of 3-D cubes, as shown
in Figure 2.2. If we continue in this way, we may display any n-D data as a series of (n , 1)-D \cubes". The data
cube is a metaphor for multidimensional data storage. The actual physical storage of such data may dier from its
logical representation. The important thing to remember is that data cubes are n-dimensional, and do not conne
data to 3-D.
The above tables show the data at dierent degrees of summarization. In the data warehousing research literature,
a data cube such as each of the above is referred to as a cuboid. Given a set of dimensions, we can construct a
lattice of cuboids, each showing the data at a dierent level of summarization, or group by (i.e., summarized by a
dierent subset of the dimensions). The lattice of cuboids is then referred to as a data cube. Figure 2.8 shows a
lattice of cuboids forming a data cube for the dimensions time, item, location, and supplier.
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
8
location
(cities)
Chicago
882
854
New York
968
1087
38
Montreal
818 746
43
Vancouver
Q1
605K
Q2
680
825K
14K
952
31
89
623
872
591
698
925
400K
682
time
(quarters)
Q3
812
1023
512
30
789
1002
870
728
984
501
784
Q4
927
1038
38
580
computer
security
phone
home
entertainment
item
(types)
Figure 2.1: A 3-D data cube representation of the data in Table 2.3, according to the dimensions time, item, and
location. The measure displayed is dollars sold.
supplier =
location
(cities)
"SUP1"
supplier = "SUP2"
supplier =
"SUP3"
Chicago
New York
Montreal
Vancouver
Q1
time
(quarters)
605K
825K
14K
400K
Q2
Q3
Q4
computer
phone
home
entertainment
item
(types)
security
computer
phone
home
entertainment
item
(types)
security
computer
security
phone
home
entertainment
item
(types)
Figure 2.2: A 4-D data cube representation of sales data, according to the dimensions time, item, location, and
supplier. The measure displayed is dollars sold.
The cuboid which holds the lowest level of summarization is called the base cuboid. For example, the 4-D
cuboid in Figure 2.2 is the base cuboid for the given time, item, location, and supplier dimensions. Figure 2.1 is a
3-D (non-base) cuboid for time, item, and location, summarized for all suppliers. The 0-D cuboid which holds the
highest level of summarization is called the apex cuboid. In our example, this is the total sales, or dollars sold,
summarized for all four dimensions. The apex cuboid is typically denoted by all.
2.2.2 Stars, snowakes, and fact constellations: schemas for multidimensional databases
The entity-relationship data model is commonly used in the design of relational databases, where a database schema
consists of a set of entities or objects, and the relationships between them. Such a data model is appropriate for online transaction processing. Data warehouses, however, require a concise, subject-oriented schema which facilitates
on-line data analysis.
The most popular data model for data warehouses is a multidimensional model. This model can exist in the
form of a star schema, a snowake schema, or a fact constellation schema. Let's have a look at each of these
schema types.
2.2. A MULTIDIMENSIONAL DATA MODEL
9
0-D (apex) cuboid
all
time
item
location
time, supplier
time, item
time, item, location
2-D cuboids
item, supplier
item, location
time, location
1-D cuboids
supplier
location, supplier
time, location, supplier
time, item, supplier
3-D cuboids
item, location, supplier
4-D (base) cuboid
item, item, location, supplier
Figure 2.3: Lattice of cuboids, making up a 4-D data cube for the dimensions time, item, location, and supplier.
Each cuboid represents a dierent degree of summarization.
Star schema: The star schema is a modeling paradigm in which the data warehouse contains (1) a large central
table (fact table), and (2) a set of smaller attendant tables (dimension tables), one for each dimension. The
schema graph resembles a starburst, with the dimension tables displayed in a radial pattern around the central
fact table.
Time Dimension
year
quarter
month
day_of_week
day
time_key
Branch Dimension
branch_type
branch_name
branch_key
Sales Fact
time_key
item_key
branch_key
location_key
dollars_sold
units_sold
Item Dimension
supplier_type
type
brand
item_name
item_key
Location Dimension
country
province_or_state
city
street
location_key
Figure 2.4: Star schema of a data warehouse for sales.
Example 2.1 An example of a star schema for AllElectronics sales is shown in Figure 2.4. Sales are considered
along four dimensions, namely time, item, branch, and location. The schema contains a central fact table for
sales which contains keys to each of the four dimensions, along with two measures: dollars sold and units sold.
2
Notice that in the star schema, each dimension is represented by only one table, and each table contains a
set of attributes. For example, the location dimension table contains the attribute set flocation key, street,
10
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
city, province or state, countryg. This constraint may introduce some redundancy. For example, \Vancou-
ver" and \Victoria" are both cities in the Canadian province of British Columbia. Entries for such cities in
the location dimension table will create redundancy among the attributes province or state and country, i.e.,
(.., Vancouver, British Columbia, Canada) and (.., Victoria, British Columbia, Canada). Moreover, the attributes within a dimension table may form either a hierarchy (total order) or a lattice (partial
order).
Snowake schema: The snowake schema is a variant of the star schema model, where some dimension tables
are normalized, thereby further splitting the data into additional tables. The resulting schema graph forms a
shape similar to a snowake.
The major dierence between the snowake and star schema models is that the dimension tables of the snowake
model may be kept in normalized form. Such a table is easy to maintain and also saves storage space because
a large dimension table can be extremely large when the dimensional structure is included as columns. Since
much of this space is redundant data, creating a normalized structure will reduce the overall space requirement.
However, the snowake structure can reduce the eectiveness of browsing since more joins will be needed to
execute a query. Consequently, the system performance may be adversely impacted. Performance benchmarking
can be used to determine what is best for your design.
Sales Fact
Time Dimension
year
quarter
month
day_of_week
day
time_key
Branch Dimension
branch_type
branch_name
branch_key
time_key
item_key
branch_key
location_key
dollars_sold
units_sold
Item Dimension
supplier_key
type
brand
item_name
item_key
Location Dimension
city_key
street
location_key
Supplier Dimension
supplier_type
supplier_key
City Dimension
country
province_or_state
city
city_key
Figure 2.5: Snowake schema of a data warehouse for sales.
Example 2.2 An example of a snowake schema for AllElectronics sales is given in Figure 2.5. Here, the sales
fact table is identical to that of the star schema in Figure 2.4. The main dierence between the two schemas
is in the denition of dimension tables. The single dimension table for item in the star schema is normalized
in the snowake schema, resulting in new item and supplier tables. For example, the item dimension table
now contains the attributes supplier key, type, brand, item name, and item key, the latter of which is linked
to the supplier dimension table, containing supplier type and supplier key information. Similarly, the single
dimension table for location in the star schema can be normalized into two tables: new location and city. The
location key of the new location table now links to the city dimension. Notice that further normalization can
be performed on province or state and country in the snowake schema shown in Figure 2.5, when desirable.
2
A compromise between the star schema and the snowake schema is to adopt a mixed schema where only
the very large dimension tables are normalized. Normalizing large dimension tables saves storage space, while
keeping small dimension tables unnormalized may reduce the cost and performance degradation due to joins on
multiple dimension tables. Doing both may lead to an overall performance gain. However, careful performance
tuning could be required to determine which dimension tables should be normalized and split into multiple
tables.
Fact constellation: Sophisticated applications may require multiple fact tables to share dimension tables.
This kind of schema can be viewed as a collection of stars, and hence is called a galaxy schema or a fact
constellation.
2.2. A MULTIDIMENSIONAL DATA MODEL
Time Dimension
year
quarter
month
day_of_week
day
time_key
Branch Dimension
branch_type
branch_name
branch_key
Sales Fact
time_key
item_key
branch_key
location_key
dollars_sold
units_sold
11
Item Dimension
type
brand
item_name
item_key
Location Dimension
country
province_or_state
city
street
location_key
Shipper Dimension
Shipping Fact
time_key
item_key
shipper_key
from_location
to_location
dollars_cost
units_shipped
shipper_type
location_key
shipper_name
shipper_key
Figure 2.6: Fact constellation schema of a data warehouse for sales and shipping.
Example 2.3 An example of a fact constellation schema is shown in Figure 2.6. This schema species two
fact tables, sales and shipping. The sales table denition is identical to that of the star schema (Figure 2.4).
The shipping table has ve dimensions, or keys: time key, item key, shipper key, from location, and to location,
and two measures: dollars cost and units shipped. A fact constellation schema allows dimension tables to be
shared between fact tables. For example, the dimensions tables for time, item, and location, are shared between
both the sales and shipping fact tables.
2
In data warehousing, there is a distinction between a data warehouse and a data mart. A data warehouse
collects information about subjects that span the entire organization, such as customers, items, sales, assets, and
personnel, and thus its scope is enterprise-wide. For data warehouses, the fact constellation schema is commonly
used since it can model multiple, interrelated subjects. A data mart, on the other hand, is a department subset
of the data warehouse that focuses on selected subjects, and thus its scope is department-wide. For data marts, the
star or snowake schema are popular since each are geared towards modeling single subjects.
2.2.3 Examples for dening star, snowake, and fact constellation schemas
\How can I dene a multidimensional schema for my data?"
Just as relational query languages like SQL can be used to specify relational queries, a data mining query
language can be used to specify data mining tasks. In particular, we examine an SQL-based data mining query
language called DMQL which contains language primitives for dening data warehouses and data marts. Language
primitives for specifying other data mining tasks, such as the mining of concept/class descriptions, associations,
classications, and so on, will be introduced in Chapter 4.
Data warehouses and data marts can be dened using two language primitives, one for cube denition and one
for dimension denition. The cube denition statement has the following syntax.
dene cube hcube namei [hdimension listi] : hmeasure listi
The dimension denition statement has the following syntax.
dene dimension hdimension namei as (hattribute or subdimension listi)
Let's look at examples of how to dene the star, snowake and constellations schemas of Examples 2.1 to 2.3
using DMQL. DMQL keywords are displayed in sans serif font.
12
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
Example 2.4 The star schema of Example 2.1 and Figure 2.4 is dened in DMQL as follows.
dene cube sales star [time, item, branch, location]:
dollars sold = sum(sales in dollars), units sold = count(*)
dene dimension time as (time key, day, day of week, month, quarter, year)
dene dimension item as (item key, item name, brand, type, supplier type)
dene dimension branch as (branch key, branch name, branch type)
dene dimension location as (location key, street, city, province or state, country)
The dene cube statement denes a data cube called sales star, which corresponds to the central sales fact table
of Example 2.1. This command species the keys to the dimension tables, and the two measures, dollars sold and
units sold. The data cube has four dimensions, namely time, item, branch, and location. A dene dimension statement
is used to dene each of the dimensions.
2
Example 2.5 The snowake schema of Example 2.2 and Figure 2.5 is dened in DMQL as follows.
dene cube sales snowake [time, item, branch, location]:
dollars sold = sum(sales in dollars), units sold = count(*)
dene dimension time as (time key, day, day of week, month, quarter, year)
dene dimension item as (item key, item name, brand, type, supplier (supplier key, supplier type))
dene dimension branch as (branch key, branch name, branch type)
dene dimension location as (location key, street, city (city key, city, province or state, country))
This denition is similar to that of sales star (Example 2.4), except that, here, the item and location dimensions
tables are normalized. For instance, the item dimension of the sales star data cube has been normalized in the
sales snowake cube into two dimension tables, item and supplier. Note that the dimension denition for supplier
is specied within the denition for item. Dening supplier in this way implicitly creates a supplier key in the item
dimension table denition. Similarly, the location dimension of the sales star data cube has been normalized in the
sales snowake cube into two dimension tables, location and city. The dimension denition for city is specied within
the denition for location. In this way, a city key is implicitly created in the location dimension table denition. 2
Finally, a fact constellation schema can be dened as a set of interconnected cubes. Below is an example.
Example 2.6 The fact constellation schema of Example 2.3 and Figure 2.6 is dened in DMQL as follows.
dene cube sales [time, item, branch, location]:
dollars sold = sum(sales in dollars), units sold = count(*)
dene dimension time as (time key, day, day of week, month, quarter, year)
dene dimension item as (item key, item name, brand, type)
dene dimension branch as (branch key, branch name, branch type)
dene dimension location as (location key, street, city, province or state, country)
dene cube shipping [time, item, shipper, from location, to location]:
dollars cost = sum(cost in dollars), units shipped = count(*)
dene dimension time as time in cube sales
dene dimension item as item in cube sales
dene dimension shipper as (shipper key, shipper name, location as location in cube sales, shipper type)
dene dimension from location as location in cube sales
dene dimension to location as location in cube sales
A dene cube statement is used to dene data cubes for sales and shipping, corresponding to the two fact tables
of the schema of Example 2.3. Note that the time, item, and location dimensions of the sales cube are shared with
the shipping cube. This is indicated for the time dimension, for example, as follows. Under the dene cube statement
for shipping, the statement \dene dimension time as time in cube sales" is specied.
2
Instead of having users or experts explicitly dene data cube dimensions, dimensions can be automatically generated or adjusted based on the examination of data distributions. DMQL primitives for specifying such automatic
generation or adjustments are discussed in the following chapter.
2.2. A MULTIDIMENSIONAL DATA MODEL
13
2.2.4 Measures: their categorization and computation
\How are measures computed?"
To answer this question, we will rst look at how measures can be categorized. Note that multidimensional points
in the data cube space are dened by dimension-value pairs. For example, the dimension-value pairs in htime=\Q1",
location=\Vancouver", item=\computer"i dene a point in data cube space. A data cube measure is a numerical
function that can be evaluated at each point in the data cube space. A measure value is computed for a given point
by aggregating the data corresponding to the respective dimension-value pairs dening the given point. We will look
at concrete examples of this shortly.
Measures can be organized into three categories, based on the kind of aggregate functions used.
distributive: An aggregate function is distributive if it can be computed in a distributed manner as follows:
Suppose the data is partitioned into n sets. The computation of the function on each partition derives one
aggregate value. If the result derived by applying the function to the n aggregate values is the same as that
derived by applying the function on all the data without partitioning, the function can be computed in a
distributed manner. For example, count() can be computed for a data cube by rst partitioning the cube
into a set of subcubes, computing count() for each subcube, and then summing up the counts obtained for
each subcube. Hence count() is a distributive aggregate function. For the same reason, sum(), min(), and
max() are distributive aggregate functions. A measure is distributive if it is obtained by applying a distributive
aggregate function.
algebraic: An aggregate function is algebraic if it can be computed by an algebraic function with M argu-
ments (where M is a bounded integer), each of which is obtained by applying a distributive aggregate function.
For example, avg() (average) can be computed by sum()/count() where both sum() and count() are distributive aggregate functions. Similarly, it can be shown that min N(), max N(), and standard deviation()
are algebraic aggregate functions. A measure is algebraic if it is obtained by applying an algebraic aggregate
function.
holistic: An aggregate function is holistic if there is no constant bound on the storage size needed to describe
a subaggregate. That is, there does not exist an algebraic function with M arguments (where M is a constant)
that characterizes the computation. Common examples of holistic functions include median(), mode() (i.e.,
the most frequently occurring item(s)), and rank(). A measure is holistic if it is obtained by applying a holistic
aggregate function.
Most large data cube applications require ecient computation of distributive and algebraic measures. Many
ecient techniques for this exist. In contrast, it can be dicult to compute holistic measures eciently. Ecient
techniques to approximate the computation of some holistic measures, however, do exist. For example, instead of
computing the exact median(), there are techniques which can estimate the approximate median value for a large
data set with satisfactory results. In many cases, such techniques are sucient to overcome the diculties of ecient
computation of holistic measures.
Example 2.7 Many measures of a data cube can be computed by relational aggregation operations. In Figure 2.4,
we saw a star schema for AllElectronics sales which contains two measures, namely dollars sold and units sold. In
Example 2.4, the sales star data cube corresponding to the schema was dened using DMQL commands. \But, how
are these commands interpreted in order to generate the specied data cube?"
Suppose that the relational database schema of AllElectronics is the following:
time(time key, day, day of week, month, quarter, year)
item(item key, item name, brand, type)
branch(branch key, branch name, branch type)
location(location key, street, city, province or state, country)
sales(time key, item key, branch key, location key, number of units sold, price)
The DMQL specication of Example 2.4 is translated into the following SQL query, which generates the required
sales star cube. Here, the sum aggregate function is used to compute both dollars sold and units sold.
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
14
s.time key, s.item key, s.branch key, s.location key,
sum(s.number of units sold s.price), sum(s.number of units sold)
from time t, item i, branch b, location l, sales s,
where s.time key = t.time key and s.item key = i.item key
and s.branch key = b.branch key and s.location key = l.location key
group by s.time key, s.item key, s.branch key, s.location key
select
The cube created in the above query is the base cuboid of the sales star data cube. It contains all of the dimensions
specied in the data cube denition, where the granularity of each dimension is at the join key level. A join key
is a key that links a fact table and a dimension table. The fact table associated with a base cuboid is sometimes
referred to as the base fact table.
By changing the group by clauses, we may generate other cuboids for the sales star data cube. For example,
instead of grouping by s.time key, we can group by t.month, which will sum up the measures of each group by
month. Also, removing \group by s.branch key" will generate a higher level cuboid (where sales are summed for all
branches, rather than broken down per branch). Suppose we modify the above SQL query by removing all of the
group by clauses. This will result in obtaining the total sum of dollars sold and the total count of units sold for the
given data. This zero-dimensional cuboid is the apex cuboid of the sales star data cube. In addition, other cuboids
can be generated by applying selection and/or projection operations on the base cuboid, resulting in a lattice of
cuboids as described in Section 2.2.1. Each cuboid corresponds to a dierent degree of summarization of the given
data.
2
Most of the current data cube technology connes the measures of multidimensional databases to numerical data.
However, measures can also be applied to other kinds of data, such as spatial, multimedia, or text data. Techniques
for this are discussed in Chapter 9.
2.2.5 Introducing concept hierarchies
\What is a concept hierarchy?"
A concept hierarchy denes a sequence of mappings from a set of low level concepts to higher level, more
general concepts. Consider a concept hierarchy for the dimension location. City values for location include Vancouver,
Montreal, New York, and Chicago. Each city, however, can be mapped to the province or state to which it belongs.
For example, Vancouver can be mapped to British Columbia, and Chicago to Illinois. The provinces and states can
in turn be mapped to the country to which they belong, such as Canada or the USA. These mappings form a concept
hierarchy for the dimension location, mapping a set of low level concepts (i.e., cities) to higher level, more general
concepts (i.e., countries). The concept hierarchy described above is illustrated in Figure 2.7.
Many concept hierarchies are implicit within the database schema. For example, suppose that the dimension
location is described by the attributes number, street, city, province or state, zipcode, and country. These attributes
are related by a total order, forming a concept hierarchy such as \street < city < province or state < country". This
hierarchy is shown in Figure 2.8a). Alternatively, the attributes of a dimension may be organized in a partial order,
forming a lattice. An example of a partial order for the time dimension based on the attributes day, week, month,
quarter, and year is \day < fmonth <quarter; weekg < year" 1 . This lattice structure is shown in Figure 2.8b).
A concept hierarchy that is a total or partial order among attributes in a database schema is called a schema
hierarchy. Concept hierarchies that are common to many applications may be predened in the data mining
system, such as the the concept hierarchy for time. Data mining systems should provide users with the exibility
to tailor predened hierarchies according to their particular needs. For example, one may like to dene a scal year
starting on April 1, or an academic year starting on September 1.
Concept hierarchies may also be dened by discretizing or grouping values for a given dimension or attribute,
resulting in a set-grouping hierarchy. A total or partial order can be dened among groups of values. An example
of a set-grouping hierarchy is shown in Figure 2.9 for the dimension price.
There may be more than one concept hierarchy for a given attribute or dimension, based on dierent user
viewpoints. For instance, a user may prefer to organize price by dening ranges for inexpensive, moderately priced,
and expensive.
1 Since a week usually crosses the boundary of two consecutive months, it is usually not treated as a lower abstraction of month.
Instead, it is often treated as a lower abstraction of year, since a year contains approximately 52 weeks.
2.2. A MULTIDIMENSIONAL DATA MODEL
15
location
all
all
...
Canada
country
province_or_state
city
USA
Ontario ... Quebec
British
Columbia
...
Vancouver
...
...
Victoria
Toronto
...
...
Montreal
...
New York
California
...
...
New York
...
...
Los Angeles...San Francisco
Illinois
...
Chicago
...
Figure 2.7: A concept hierarchy for the dimension location.
Concept hierarchies may be provided manually by system users, domain experts, knowledge engineers, or automatically generated based on statistical analysis of the data distribution. The automatic generation of concept
hierarchies is discussed in Chapter 3. Concept hierarchies are further discussed in Chapter 4.
Concept hierarchies allow data to be handled at varying levels of abstraction, as we shall see in the following
subsection.
2.2.6 OLAP operations in the multidimensional data model
\How are concept hierarchies useful in OLAP?"
In the multidimensional model, data are organized into multiple dimensions and each dimension contains multiple
levels of abstraction dened by concept hierarchies. This organization provides users with the exibility to view data
from dierent perspectives. A number of OLAP data cube operations exist to materialize these dierent views,
allowing interactive querying and analysis of the data at hand. Hence, OLAP provides a user-friendly environment
country
year
quarter
province_or_state
city
street
month
week
day
a) a hierarchy for location b) a lattice for time
Figure 2.8: Hierarchical and lattice structures of attributes in warehouse dimensions.
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
16
($0 - $1000]
($0 - $200]
($200 - $400]
($400 - $600]
($600 - $800]
($0 - $100] ($100 - $200] ($200 - $300] ($300 - $400] ($400 - $500] ($500 - $600] ($600 - $700] ($700 - $800]
($800 - $1,000]
($800 - $900] ($900 - $1,000]
Figure 2.9: A concept hierarchy for the attribute price.
for interactive data analysis.
Example 2.8 Let's have a look at some typical OLAP operations for multidimensional data. Each of the operations
described below is illustrated in Figure 2.10. At the center of the gure is a data cube for AllElectronics sales. The
cube contains the dimensions location, time, and item, where location is aggregated with respect to city values, time
is aggregated with respect to quarters, and item is aggregated with respect to item types. To aid in our explanation,
we refer to this cube as the central cube. The data examined are for the cities Vancouver, Montreal, New York, and
Chicago.
1. roll-up: The roll-up operation (also called the \drill-up" operation by some vendors) performs aggregation on
a data cube, either by climbing-up a concept hierarchy for a dimension or by dimension reduction . Figure 2.10
shows the result of a roll-up operation performed on the central cube by climbing up the concept hierarchy for
location given in Figure 2.7. This hierarchy was dened as the total order street < city < province or state <
country. The roll-up operation shown aggregates the data by ascending the location hierarchy from the level
of city to the level of country. In other words, rather than grouping the data by city, the resulting cube groups
the data by country.
When roll-up is performed by dimension reduction, one or more dimensions are removed from the given cube.
For example, consider a sales data cube containing only the two dimensions location and time. Roll-up may
be performed by removing, say, the time dimension, resulting in an aggregation of the total sales by location,
rather than by location and by time.
2. drill-down: Drill-down is the reverse of roll-up. It navigates from less detailed data to more detailed data.
Drill-down can be realized by either stepping-down a concept hierarchy for a dimension or introducing additional
dimensions. Figure 2.10 shows the result of a drill-down operation performed on the central cube by stepping
down a concept hierarchy for time dened as day < month < quarter < year. Drill-down occurs by descending
the time hierarchy from the level of quarter to the more detailed level of month. The resulting data cube details
the total sales per month rather than summarized by quarter.
Since a drill-down adds more detail to the given data, it can also be performed by adding new dimensions to
a cube. For example, a drill-down on the central cube of Figure 2.10 can occur by introducing an additional
dimension, such as customer type.
3. slice and dice: The slice operation performs a selection on one dimension of the given cube, resulting in a
subcube. Figure 2.10 shows a slice operation where the sales data are selected from the central cube for the
dimension time using the criteria time=\Q2". The dice operation denes a subcube by performing a selection
on two or more dimensions. Figure 2.10 shows a dice operation on the central cube based on the following
selection criteria which involves three dimensions: (location=\Montreal" or \Vancouver") and (time=\Q1" or
\Q2") and (item=\home entertainment" or \computer").
4. pivot (rotate): Pivot (also called \rotate") is a visualization operation which rotates the data axes in view
in order to provide an alternative presentation of the data. Figure 2.10 shows a pivot operation where the
2.2. A MULTIDIMENSIONAL DATA MODEL
17
location
(cities)
location
(countries)
US
Canada
Chicago
New York
Montreal
Vancouver
Q1
time
(quarters)
Q2
time
(months)
Q3
Q4
January
150K
February
March
April
May
June
100K
150K
July
August
computer
security
phone
home
entertainment
item
(types)
September
October
November
December
computer
security
phone
home
entertainment
item
(types)
roll-up
drill-down
on location
on time
(from cities to countries)
(from quarters
to months)
location
(cities)
Chicago
New York
Montreal
Vancouver
Q1
time
(quarters)
605K 825K
14K 400K
Q2
Q3
Q4
computer
security
phone
home
entertainment
item
(types)
dice for
slice
(location="Montreal" or "Vancouver") and
for time="Q2"
(time="Q1" or "Q2") and
(item="home entertainment" or "computer")
Chicago
location
(cities) Montreal
Vancouver
location
(cities)
pivot
New York
item
(types)
home
entertainment
computer
Q1
time
(quarters)
Montreal
phone
Vancouver
security
Q2
computer
home
entertainment
item
(types)
computer
phone
home
entertainment
security
New York Vancouver
Chicago
Montreal
item
(types)
Figure 2.10: Examples of typical OLAP operations on multidimensional data.
location
(cities)
18
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
location
continent
customer
country
group
province_or_state
category
city
street
day
name
item
name
brand
category
type
month
quarter
year
time
Figure 2.11: Modeling business queries: A starnet model.
item and location axes in a 2-D slice are rotated. Other examples include rotating the axes in a 3-D cube, or
transforming a 3-D cube into a series of 2-D planes.
5. other OLAP operations: Some OLAP systems oer additional drilling operations. For example, drillacross executes queries involving (i.e., acrosss) more than one fact table. The drill-through operation makes
use of relational SQL facilities to drill through the bottom level of a data cube down to its back-end relational
tables.
Other OLAP operations may include ranking the top-N or bottom-N items in lists, as well as computing moving
averages, growth rates, interests, internal rates of return, depreciation, currency conversions, and statistical
functions.
OLAP oers analytical modeling capabilities, including a calculation engine for deriving ratios, variance, etc., and
for computing measures across multiple dimensions. It can generate summarizations, aggregations, and hierarchies
at each granularity level and at every dimension intersection. OLAP also supports functional models for forecasting,
trend analysis, and statistical analysis. In this context, an OLAP engine is a powerful data analysis tool.
2.2.7 A starnet query model for querying multidimensional databases
The querying of multidimensional databases can be based on a starnet model. A starnet model consists of radial
lines emanating from a central point, where each line represents a concept hierarchy for a dimension. Each abstraction
level in the hierarchy is called a footprint. These represent the granularities available for use by OLAP operations
such as drill-down and roll-up.
Example 2.9 A starnet query model for the AllElectronics data warehouse is shown in Figure 2.11. This starnet
consists of four radial lines, representing concept hierarchies for the dimensions location, customer, item, and time ,
respectively. Each line consists of footprints representing abstraction levels of the dimension. For example, the time
line has four footprints: \day", \month", \quarter" and \year". A concept hierarchy may involve a single attribute
(like date for the time hierarchy), or several attributes (e.g., the concept hierarchy for location involves the attributes
street, city, province or state, and country). In order to examine the item sales at AllElectronics, one can roll up
along the time dimension from month to quarter, or, say, drill down along the location dimension from country to
city. Concept hierarchies can be used to generalize data by replacing low-level values (such as \day" for the time
dimension) by higher-level abstractions (such as \year"), or to specialize data by replacing higher-level abstractions
with lower-level values.
2
2.3. DATA WAREHOUSE ARCHITECTURE
19
2.3 Data warehouse architecture
2.3.1 Steps for the design and construction of data warehouses
The design of a data warehouse: A business analysis framework
\What does the data warehouse provide for business analysts?"
First, having a data warehouse may provide a competitive advantage by presenting relevant information from
which to measure performance and make critical adjustments in order to help win over competitors. Second, a
data warehouse can enhance business productivity since it is able to quickly and eciently gather information which
accurately describes the organization. Third, a data warehouse facilitates customer relationship marketing since
it provides a consistent view of customers and items across all lines of business, all departments, and all markets.
Finally, a data warehouse may bring about cost reduction by tracking trends, patterns, and exceptions over long
periods of time in a consistent and reliable manner.
To design an eective data warehouse one needs to understand and analyze business needs, and construct a
business analysis framework. The construction of a large and complex information system can be viewed as the
construction of a large and complex building, for which the owner, architect, and builder have dierent views.
These views are combined to form a complex framework which represents the top-down, business-driven, or owner's
perspective, as well as the bottom-up, builder-driven, or implementor's view of the information system.
Four dierent views regarding the design of a data warehouse must be considered: the top-down view, the data
source view, the data warehouse view, and the business query view.
The top-down view allows the selection of the relevant information necessary for the data warehouse. This
information matches the current and coming business needs.
The data source view exposes the information being captured, stored, and managed by operational systems.
This information may be documented at various levels of detail and accuracy, from individual data source tables
to integrated data source tables. Data sources are often modeled by traditional data modeling techniques, such
as the entity-relationship model or CASE (Computer Aided Software Engineering) tools.
The data warehouse view includes fact tables and dimension tables. It represents the information that is
stored inside the data warehouse, including precalculated totals and counts, as well as information regarding
the source, date, and time of origin, added to provide historical context.
Finally, the business query view is the perspective of data in the data warehouse from the view point of the
end-user.
Building and using a data warehouse is a complex task since it requires business skills, technology skills, and
program management skills. Regarding business skills, building a data warehouse involves understanding how such
systems store and manage their data, how to build extractors which transfer data from the operational system
to the data warehouse, and how to build warehouse refresh software that keeps the data warehouse reasonably
up to date with the operational system's data. Using a data warehouse involves understanding the signicance of
the data it contains, as well as understanding and translating the business requirements into queries that can be
satised by the data warehouse. Regarding technology skills, data analysts are required to understand how to make
assessments from quantitative information and derive facts based on conclusions from historical information in the
data warehouse. These skills include the ability to discover patterns and trends, to extrapolate trends based on
history and look for anomalies or paradigm shifts, and to present coherent managerial recommendations based on
such analysis. Finally, program management skills involve the need to interface with many technologies, vendors and
end-users in order to deliver results in a timely and cost-eective manner.
The process of data warehouse design
\How can I design a data warehouse?"
A data warehouse can be built using a top-down approach, a bottom-up approach, or a combination of both. The
top-down approach starts with the overall design and planning. It is useful in cases where the technology is
mature and well-known, and where the business problems that must be solved are clear and well-understood. The
20
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
bottom-up approach starts with experiments and prototypes. This is useful in the early stage of business modeling
and technology development. It allows an organization to move forward at considerably less expense and to evaluate
the benets of the technology before making signicant commitments. In the combined approach, an organization
can exploit the planned and strategic nature of the top-down approach while retaining the rapid implementation and
opportunistic application of the bottom-up approach.
From the software engineering point of view, the design and construction of a data warehouse may consist of
the following steps: planning, requirements study, problem analysis, warehouse design, data integration and testing,
and nally deployment of the data warehouse. Large software systems can be developed using two methodologies:
the waterfall method or the spiral method. The waterfall method performs a structured and systematic analysis
at each step before proceeding to the next, which is like a waterfall, falling from one step to the next. The spiral
method involves the rapid generation of increasingly functional systems, with short intervals between successive
releases. This is considered a good choice for data warehouse development, especially for data marts, because the
turn-around time is short, modications can be done quickly, and new designs and technologies can be adapted in a
timely manner.
In general, the warehouse design process consists of the following steps.
1. Choose a business process to model, e.g., orders, invoices, shipments, inventory, account administration, sales,
and the general ledger. If the business process is organizational and involves multiple, complex object collections, a data warehouse model should be followed. However, if the process is departmental and focuses on the
analysis of one kind of business process, a data mart model should be chosen.
2. Choose the grain of the business process. The grain is the fundamental, atomic level of data to be represented
in the fact table for this process, e.g., individual transactions, individual daily snapshots, etc.
3. Choose the dimensions that will apply to each fact table record. Typical dimensions are time, item, customer,
supplier, warehouse, transaction type, and status.
4. Choose the measures that will populate each fact table record. Typical measures are numeric additive quantities
like dollars sold and units sold.
Since data warehouse construction is a dicult and long term task, its implementation scope should be clearly
dened. The goals of an initial data warehouse implementation should be specic, achievable, and measurable. This
involves determining the time and budget allocations, the subset of the organization which is to be modeled, the
number of data sources selected, and the number and types of departments to be served.
Once a data warehouse is designed and constructed, the initial deployment of the warehouse includes initial
installation, rollout planning, training and orientation. Platform upgrades and maintenance must also be considered.
Data warehouse administration will include data refreshment, data source synchronization, planning for disaster
recovery, managing access control and security, managing data growth, managing database performance, and data
warehouse enhancement and extension. Scope management will include controlling the number and range of queries,
dimensions, and reports; limiting the size of the data warehouse; or limiting the schedule, budget, or resources.
Various kinds of data warehouse design tools are available. Data warehouse development tools provide
functions to dene and edit metadata repository contents such as schemas, scripts or rules, answer queries, output
reports, and ship metadata to and from relational database system catalogues. Planning and analysis tools study
the impact of schema changes and of refresh performance when changing refresh rates or time windows.
2.3.2 A three-tier data warehouse architecture
\What is data warehouse architecture like?"
Data warehouses often adopt a three-tier architecture, as presented in Figure 2.12. The bottom tier is a warehouse database server which is almost always a relational database system. The middle tier is an OLAP server
which is typically implemented using either (1) a Relational OLAP (ROLAP) model, i.e., an extended relational
DBMS that maps operations on multidimensional data to standard relational operations; or (2) a Multidimensional OLAP (MOLAP) model, i.e., a special purpose server that directly implements multidimensional data and
operations. The top tier is a client, which contains query and reporting tools, analysis tools, and/or data mining
tools (e.g., trend analysis, prediction, and so on).
2.3. DATA WAREHOUSE ARCHITECTURE
Query/Report
21
Analysis
Data Mining
Front-End Tools
OLAP Server
Output
OLAP Server
OLAP Engine
Monitoring
Administration
Data Warehouse
Data Marts
Metadata Repository
Data Storage
Extract
Clean
Transform
Load
Refresh
Operational Databases
Data Cleaning
and
Data Integration
External sources
Figure 2.12: A three-tier data warehousing architecture.
From the architecture point of view, there are three data warehouse models: the enterprise warehouse, the data
mart, and the virtual warehouse.
Enterprise warehouse: An enterprise warehouse collects all of the information about subjects spanning the
entire organization. It provides corporate-wide data integration, usually from one or more operational systems
or external information providers, and is cross-functional in scope. It typically contains detailed data as well as
summarized data, and can range in size from a few gigabytes to hundreds of gigabytes, terabytes, or beyond.
An enterprise data warehouse may be implemented on traditional mainframes, UNIX superservers, or parallel
architecture platforms. It requires extensive business modeling and may take years to design and build.
Data mart: A data mart contains a subset of corporate-wide data that is of value to a specic group of
users. The scope is conned to specic, selected subjects. For example, a marketing data mart may conne its
subjects to customer, item, and sales. The data contained in data marts tend to be summarized.
Data marts are usually implemented on low cost departmental servers that are UNIX-, Windows/NT-, or
OS/2-based. The implementation cycle of a data mart is more likely to be measured in weeks rather than
months or years. However, it may involve complex integration in the long run if its design and planning were
not enterprise-wide.
Depending on the source of data, data marts can be categorized into the following two classes:
{ Independent data marts are sourced from data captured from one or more operational systems or external
information providers, or from data generated locally within a particular department or geographic area.
{ Dependent data marts are sourced directly from enterprise data warehouses.
Virtual warehouse: A virtual warehouse is a set of views over operational databases. For ecient query
processing, only some of the possible summary views may be materialized. A virtual warehouse is easy to build
but requires excess capacity on operational database servers.
The top-down development of an enterprise warehouse serves as a systematic solution and minimizes integration
problems. However, it is expensive, takes a long time to develop, and lacks exibility due to the diculty in achieving
consistency and consensus for a common data model for the entire organization. The bottom-up approach to the
design, development, and deployment of independent data marts provides exibility, low cost, and rapid return
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
22
Multi-Tier
Data
Warehouse
Distributed
Data Marts
Data
Mart
Enterprise
Data
Warehouse
Data
Mart
model
refinement
model refinement
Define a high-level corporate data model
Figure 2.13: A recommended approach for data warehouse development.
of investment. It, however, can lead to problems when integrating various disparate data marts into a consistent
enterprise data warehouse.
A recommended method for the development of data warehouse systems is to implement the warehouse in an
incremental and evolutionary manner, as shown in Figure 2.13. First, a high-level corporate data model is dened
within a reasonably short period of time (such as one or two months) that provides a corporate-wide, consistent,
integrated view of data among dierent subjects and potential usages. This high-level model, although it will need to
be rened in the further development of enterprise data warehouses and departmental data marts, will greatly reduce
future integration problems. Second, independent data marts can be implemented in parallel with the enterprise
warehouse based on the same corporate data model set as above. Third, distributed data marts can be constructed
to integrate dierent data marts via hub servers. Finally, a multi-tier data warehouse is constructed where the
enterprise warehouse is the sole custodian of all warehouse data, which is then distributed to the various dependent
data marts.
2.3.3 OLAP server architectures: ROLAP vs. MOLAP vs. HOLAP
\What is OLAP server architecture like?"
Logically, OLAP engines present business users with multidimensional data from data warehouses or data marts,
without concerns regarding how or where the data are stored. However, the physical architecture and implementation
of OLAP engines must consider data storage issues. Implementations of a warehouse server engine for OLAP
processing include:
Relational OLAP (ROLAP) servers: These are the intermediate servers that stand in between a relational
back-end server and client front-end tools. They use a relational or extended-relational DBMS to store and
manage warehouse data, and OLAP middleware to support missing pieces. ROLAP servers include optimization
for each DBMS back-end, implementation of aggregation navigation logic, and additional tools and services.
ROLAP technology tends to have greater scalability than MOLAP technology. The DSS server of Microstrategy
and Metacube of Informix, for example, adopt the ROLAP approach2 .
Multidimensional OLAP (MOLAP) servers: These servers support multidimensional views of data
through array-based multidimensional storage engines. They map multidimensional views directly to data
2
Information on these products can be found at www.informix.com and www.microstrategy.com, respectively.
2.3. DATA WAREHOUSE ARCHITECTURE
23
cube array structures. For example, Essbase of Arbor is a MOLAP server. The advantage of using a data
cube is that it allows fast indexing to precomputed summarized data. Notice that with multidimensional data
stores, the storage utilization may be low if the data set is sparse. In such cases, sparse matrix compression
techniques (see Section 2.4) should be explored.
Many OLAP servers adopt a two-level storage representation to handle sparse and dense data sets: the dense
subcubes are identied and stored as array structures, while the sparse subcubes employ compression technology
for ecient storage utilization.
Hybrid OLAP (HOLAP) servers: The hybrid OLAP approach combines ROLAP and MOLAP technology,
benetting from the greater scalability of ROLAP and the faster computation of MOLAP. For example, a
HOLAP server may allow large volumes of detail data to be stored in a relational database, while aggregations
are kept in a separate MOLAP store. The Microsoft SQL Server 7.0 OLAP Services supports a hybrid OLAP
server.
Specialized SQL servers: To meet the growing demand of OLAP processing in relational databases, some
relational and data warehousing rms (e.g., Redbrick) implement specialized SQL servers which provide advanced query language and query processing support for SQL queries over star and snowake schemas in a
read-only environment.
The OLAP functional architecture consists of three components: the data store, the OLAP server, and the user
presentation module. The data store can be further classied as a relational data store or a multidimensional data
store, depending on whether a ROLAP or MOLAP architecture is adopted.
\So, how are data actually stored in ROLAP and MOLAP architectures?"
As its name implies, ROLAP uses relational tables to store data for on-line analytical processing. Recall that
the fact table associated with a base cuboid is referred to as a base fact table. The base fact table stores data at
the abstraction level indicated by the join keys in the schema for the given data cube. Aggregated data can also be
stored in fact tables, referred to as summary fact tables. Some summary fact tables store both base fact table
data and aggregated data, as in Example 2.10. Alternatively, separate summary fact tables can be used for each
level of abstraction, to store only aggregated data.
Example 2.10 Table 2.4 shows a summary fact table which contains both base fact data and aggregated data. The
schema of the table is \hrecord identier (RID), item, location, day, month, quarter, year, dollars sold (i.e., sales
amount)i", where day, month, quarter, and year dene the date of sales. Consider the tuple with an RID of 1001.
The data of this tuple are at the base fact level. Here, the date of sales is October 15, 1997. Consider the tuple with
an RID of 5001. This tuple is at a more general level of abstraction than the tuple having an RID of 1001. Here,
the \Main Street" value for location has been generalized to \Vancouver". The day value has been generalized to
all, so that the corresponding time value is October 1997. That is, the dollars sold amount shown is an aggregation
representing the entire month of October 1997, rather than just October 15, 1997. The special value all is used to
represent subtotals in summarized data.
RID item location day month quarter year dollars sold
1001 TV Main Street 15
10
Q4 1997
250.60
. .. .. .
.. .
.. .
. ..
.. .
. ..
.. .
5001 TV Vancouver all
10
Q4 1997 45,786.08
. .. .. .
.. .
.. .
. ..
.. .
. ..
.. .
Table 2.4: Single table for base and summary facts.
2
MOLAP uses multidimensional array structures to store data for on-line analytical processing. For example, the
data cube structure described and referred to throughout this chapter is such an array structure.
24
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
Most data warehouse systems adopt a client-server architecture. A relational data store always resides at the
data warehouse/data mart server site. A multidimensional data store can reside at either the database server site or
the client site. There are several alternative physical conguration options.
If a multidimensional data store resides at the client side, it results in a \fat client". In this case, the system
response time may be quick since OLAP operations will not consume network trac, and the network bottleneck
happens only at the warehouse loading stage. However, loading a large data warehouse can be slow and the processing
at the client side can be heavy, which may degrade the system performance. Moreover, data security could be a
problem because data are distributed to multiple clients. A variation of this option is to partition the multidimensional
data store and distribute selected subsets of the data to dierent clients.
Alternatively, a multidimensional data store can reside at the server site. One option is to set both the multidimensional data store and the OLAP server at the data mart site. This conguration is typical for data marts that
are created by rening or re-engineering the data from an enterprise data warehouse.
A variation is to separate the multidimensional data store and OLAP server. That is, an OLAP server layer is
added between the client and data mart. This conguration is used when the multidimensional data store is large,
data sharing is needed, and the client is \thin" (i.e., does not require many resources).
2.3.4 SQL extensions to support OLAP operations
\How can SQL be extended to support OLAP operations?"
An OLAP server should support several data types including text, calendar, and numeric data, as well as data at
dierent granularities (such as regarding the estimated and actual sales per item). An OLAP server should contain a
calculation engine which includes domain-specic computations (such as for calendars) and a rich library of aggregate
functions. Moreover, an OLAP server should include data load and refresh facilities so that write operations can
update precomputed aggregates, and write/load operations are accompanied by data cleaning.
A multidimensional view of data is the foundation of OLAP. SQL extensions to support OLAP operations have
been proposed and implemented in extended-relational servers. Some of these are enumerated as follows.
1. Extending the family of aggregate functions.
Relational database systems have provided several useful aggregate functions, including sum(), avg(), count(),
min(), and max() as SQL standards. OLAP query answering requires the extension of these standards to include other aggregate functions such as rank(), N tile(), median(), and mode(). For example, a user may
like to list the top ve most protable items (using rank()), list the rms whose performance is in the bottom
10% in comparison to all other rms (using N tile()), or print the most frequently sold items in March (using
mode()).
2. Adding reporting features.
Many report writer softwares allow aggregate features to be evaluated on a time window. Examples include
running totals, cumulative totals, moving averages, break points, etc. OLAP systems, to be truly useful for
decision support, should introduce such facilities as well.
3. Implementing multiple group-by's.
Given the multidimensional view point of data warehouses, it is important to introduce group-by's for grouping
sets of attributes. For example, one may want to list the total sales from 1996 to 1997 grouped by item, by
region, and by quarter. Although this can be simulated by a set of SQL statements, it requires multiple scans
of databases, and is thus a very inecient solution. New operations, including cube and roll-up, have been
introduced in some relational system products which explore ecient implementation methods.
2.4 Data warehouse implementation
Data warehouses contain huge volumes of data. OLAP engines demand that decision support queries be answered in
the order of seconds. Therefore, it is crucial for data warehouse systems to support highly ecient cube computation
techniques, access methods, and query processing techniques. \How can this be done?", you may wonder. In this
section, we examine methods for the ecient implementation of data warehouse systems.
2.4. DATA WAREHOUSE IMPLEMENTATION
25
()
(city)
(city, item)
(item)
0-D (apex) cuboid; all
(year)
1-D cuboids
(city, year) (item, year)
2-D cuboids
(city, item, year)
3-D (base) cuboid
Figure 2.14: Lattice of cuboids, making up a 3-dimensional data cube. Each cuboid represents a dierent group-by.
The base cuboid contains the three dimensions, city, item, and year.
2.4.1 Ecient computation of data cubes
At the core of multidimensional data analysis is the ecient computation of aggregations across many sets of dimensions. In SQL terms, these aggregations are referred to as group-by's.
The compute cube operator and its implementation
One approach to cube computation extends SQL so as to include a compute cube operator. The compute cube
operator computes aggregates over all subsets of the dimensions specied in the operation.
Example 2.11 Suppose that you would like to create a data cube for AllElectronics sales which contains the fol-
lowing: item, city, year, and sales in dollars. You would like to be able to analyze the data, with queries such as the
following:
1. \Compute the sum of sales, grouping by item and city."
2. \Compute the sum of sales, grouping by item."
3. \Compute the sum of sales, grouping by city".
What is the total number of cuboids, or group-by's, that can be computed for this data cube? Taking the
three attributes, city, item, and year, as three dimensions and sales in dollars as the measure, the total number
of cuboids, or group-by's, that can be computed for this data cube is 23 = 8. The possible group-by's are the
following: f(city; item; year), (city; item), (city; year), (item; year), (city), (item), (year), ()g, where () means that
the group-by is empty (i.e., the dimensions are not grouped). These group-by's form a lattice of cuboids for the data
cube, as shown in Figure 2.14. The base cuboid contains all three dimensions, city, item, and year. It can return the
total sales for any combination of the three dimensions. The apex cuboid, or 0-D cuboid, refers to the case where
the group-by is empty. It contains the total sum of all sales. Consequently, it is represented by the special value all.
2
An SQL query containing no group-by, such as \compute the sum of total sales" is a zero-dimensional operation.
An SQL query containing one group-by, such as \compute the sum of sales, group by city" is a one-dimensional
operation. A cube operator on n dimensions is equivalent to a collection of group by statements, one for each subset
of the n dimensions. Therefore, the cube operator is the n-dimensional generalization of the group by operator.
Based on the syntax of DMQL introduced in Section 2.2.3, the data cube in Example 2.11, can be dened as
dene cube sales [item, city, year]: sum(sales in dollars)
26
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
For a cube with n dimensions, there are a total of 2n cuboids, including the base cuboid. The statement
compute cube sales
explicitly instructs the system to compute the sales aggregate cuboids for all of the eight subsets of the set fitem,
city, yearg, including the empty subset. A cube computation operator was rst proposed and studied by Gray, et al.
(1996).
On-line analytical processing may need to access dierent cuboids for dierent queries. Therefore, it does seem
like a good idea to compute all or at least some of the cuboids in a data cube in advance. Precomputation leads
to fast response time and avoids some redundant computation. Actually, most, if not all, OLAP products resort to
some degree of precomputation of multidimensional aggregates.
A major challenge related to this precomputation, however, is that the required storage space may explode if
all of the cuboids in a data cube are precomputed, especially when the cube has several dimensions associated with
multiple level hierarchies.
\How many cuboids are there in an n-dimensional data cube?" If there were no hierarchies associated with each
dimension, then the total number of cuboids for an n-dimensional data cube, as we have seen above, is 2n . However,
in practice, many dimensions do have hierarchies. For example, the dimension time is usually not just one level, such
as year, but rather a hierarchy or a lattice, such as day < week < month < quarter < year. For an n-dimensional
data cube, the total number of cuboids that can be generated (including the cuboids generated by climbing up the
hierarchies along each dimension) is:
Yn
T = (Li + 1);
i=1
where Li is the number of levels associated with dimension i (excluding the virtual top level all since generalizing to
all is equivalent to the removal of a dimension). This formula is based on the fact that at most one abstraction level
in each dimension will appear in a cuboid. For example, if the cube has 10 dimensions and each dimension has 4
levels, the total number of cuboids that can be generated will be 510 9:8 106.
By now, you probably realize that it is unrealistic to precompute and materialize all of the cuboids that can
possibly be generated for a data cube (or, from a base cuboid). If there are many cuboids, and these cuboids are
large in size, a more reasonable option is partial materialization, that is, to materialize only some of the possible
cuboids that can be generated.
Partial materialization: Selected computation of cuboids
There are three choices for data cube materialization: (1) precompute only the base cuboid and none of the remaining
\non-base" cuboids (no materialization), (2) precompute all of the cuboids (full materialization), and (3)
selectively compute a proper subset of the whole set of possible cuboids (partial materialization). The rst choice
leads to computing expensive multidimensional aggregates on the y, which could be slow. The second choice may
require huge amounts of memory space in order to store all of the precomputed cuboids. The third choice presents
an interesting trade-o between storage space and response time.
The partial materialization of cuboids should consider three factors: (1) identify the subset of cuboids to materialize, (2) exploit the materialized cuboids during query processing, and (3) eciently update the materialized
cuboids during load and refresh.
The selection of the subset of cuboids to materialize should take into account the queries in the workload, their
frequencies, and their accessing costs. In addition, it should consider workload characteristics, the cost for incremental
updates, and the total storage requirements. The selection must also consider the broad context of physical database
design, such as the generation and selection of indices. Several OLAP products have adopted heuristic approaches
for cuboid selection. A popular approach is to materialize the set of cuboids having relatively simple structure. Even
with this restriction, there are often still a large number of possible choices. Under a simplied assumption, a greedy
algorithm has been proposed and has shown good performance.
Once the selected cuboids have been materialized, it is important to take advantage of them during query
processing. This involves determining the relevant cuboid(s) from among the candidate materialized cuboids, how
to use available index structures on the materialized cuboids, and how to transform the OLAP operations on to the
selected cuboid(s). These issues are discussed in Section 2.4.3 on query processing.
2.4. DATA WAREHOUSE IMPLEMENTATION
27
Finally, during load and refresh, the materialized cuboids should be updated eciently. Parallelism and incremental update techniques for this should be explored.
Multiway array aggregation in the computation of data cubes
In order to ensure fast on-line analytical processing, however, we may need to precompute all of the cuboids for a
given data cube. Cuboids may be stored on secondary storage, and accessed when necessary. Hence, it is important
to explore ecient methods for computing all of the cuboids making up a data cube, that is, for full materialization.
These methods must take into consideration the limited amount of main memory available for cuboid computation,
as well as the time required for such computation. To simplify matters, we may exclude the cuboids generated by
climbing up existing hierarchies along each dimension.
Since Relational OLAP (ROLAP) uses tuples and relational tables as its basic data structures, while the basic
data structure used in multidimensional OLAP (MOLAP) is the multidimensional array, one would expect that
ROLAP and MOLAP each explore very dierent cube computation techniques.
ROLAP cube computation uses the following major optimization techniques.
1. Sorting, hashing, and grouping operations are applied to the dimension attributes in order to reorder and
cluster related tuples.
2. Grouping is performed on some subaggregates as a \partial grouping step". These \partial groupings" may be
used to speed up the computation of other subaggregates.
3. Aggregates may be computed from previously computed aggregates, rather than from the base fact tables.
\How do these optimization techniques apply to MOLAP?" ROLAP uses value-based addressing, where dimension
values are accessed by key-based addressing search strategies. In contrast, MOLAP uses direct array addressing,
where dimension values are accessed via the position or index of their corresponding array locations. Hence, MOLAP
cannot perform the value-based reordering of the rst optimization technique listed above for ROLAP. Therefore, a
dierent approach should be developed for the array-based cube construction of MOLAP, such as the following.
1. Partition the array into chunks. A chunk is a subcube that is small enough to t into the memory available
for cube computation. Chunking is a method for dividing an n-dimensional array into small n-dimensional
chunks, where each chunk is stored as an object on disk. The chunks are compressed so as to remove wasted
space resulting from empty array cells (i.e., cells that do not contain any valid data). For instance, \chunkID
+ oset" can be used as a cell addressing mechanism to compress a sparse array structure and when
searching for cells within a chunk. Such a compression technique is powerful enough to handle sparse cubes,
both on disk and in memory.
2. Compute aggregates by visiting (i.e., accessing the values at) cube cells. The order in which cells are visited can
be optimized so as to minimize the number of times that each cell must be revisited, thereby reducing memory
access and storage costs. The trick is to exploit this ordering so that partial aggregates can be computed
simultaneously, and any unnecessary revisiting of cells is avoided.
Since this chunking technique involves \overlapping" some of the aggregation computations, it is referred to as
multiway array aggregation in data cube computation.
We explain this approach to MOLAP cube construction by looking at a concrete example.
Example 2.12 Consider a 3-D data array containing the three dimensions, A, B, and C.
The 3-D array is partitioned into small, memory-based chunks. In this example, the array is partitioned into
64 chunks as shown in Figure 2.15. Dimension A is organized into 4 partitions, a0 ; a1; a2, and a3 . Dimensions
B and C are similarly organized into 4 partitions each. Chunks 1, 2, .. ., 64 correspond to the subcubes a0 b0c0 ,
a1 b0c0 , . . . , a3 b3c3 , respectively. Suppose the size of the array for each dimension, A, B, and C is 40, 400,
4000, respectively.
Full materialization of the corresponding data cube involves the computation of all of the cuboids dening this
cube. These cuboids consist of:
28
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
c3
C
c1
c2
29
c0
b3
13
61
45
14
30
62
46
15
63
31
47
32
64
48
16
28
b2
44
9
60
56
24 40
B
b1
b0
52
5
1
a0
2
a1
3
a2
4
20
36
a3
A
Figure 2.15: A 3-D array for the dimensions A, B, and C, organized into 64 chunks.
{ The base cuboid, denoted by ABC (from which all of the other cuboids are directly or indirectly computed).
This cube is already computed and corresponds to the given 3-D array.
{ The 2-D cuboids, AB, AC, and BC, which respectively correspond to the group-by's AB, AC, and BC.
These cuboids must be computed.
{ The 1-D cuboids, A, B, and C, which respectively correspond to the group-by's A, B, and C. These
cuboids must be computed.
{ The 0-D (apex) cuboid, denoted by all, which corresponds to the group-by (), i.e., there is no group-by
here. This cuboid must be computed.
Let's look at how the multiway array aggregation technique is used in this computation.
There are many possible orderings with which chunks can be read into memory for use in cube computation.
Consider the ordering labeled from 1 to 64, shown in Figure 2.15. Suppose we would like to compute the b0 c0
chunk of the BC cuboid. We allocate space for this chunk in \chunk memory". By scanning chunks 1 to 4 of
ABC, the b0 c0 chunk is computed. That is, the cells for b0c0 are aggregated over a0 to a3.
The chunk memory can then be assigned to the next chunk, b1 c0, which completes its aggregation after the
scanning of the next 4 chunks of ABC: 5 to 8.
Continuing in this way, the entire BC cuboid can be computed. Therefore, only one chunk of BC needs to be
in memory, at a time, for the computation of all of the chunks of BC.
In computing the BC cuboid, we will have scanned each of the 64 chunks. \Is there a way to avoid having to
rescan all of these chunks for the computation of other cuboids, such as AC and AB ?" The answer is, most
denitely - yes. This is where the multiway computation idea comes in. For example, when chunk 1, i.e.,
a0 b0c0 , is being scanned (say, for the computation of the 2-D chunk b0c0 of BC, as described above), all of the
other 2-D chunks relating to a0b0 c0 can be simultaneously computed. That is, when a0 b0c0 , is being scanned,
each of the three chunks, b0c0 , a0 c0, and a0 b0, on the three 2-D aggregation planes, BC, AC, and AB, should
be computed then as well. In other words, multiway computation aggregates to each of the 3-D planes while a
3-D chunk is in memory.
Let's look at how dierent orderings of chunk scanning and of cuboid computation can aect the overall data
cube computation eciency. Recall that the size of the dimensions A, B, and C is 40, 400, and 4000, respectively.
Therefore, the largest 2-D plane is BC (of size 400 4; 000 = 1; 600; 000). The second largest 2-D plane is AC (of
size 40 4; 000 = 160; 000). AB is the smallest 2-D plane (with a size of 40 400 = 16; 000).
Suppose that the chunks are scanned in the order shown, from chunk 1 to 64. By scanning in this order, one
chunk of the largest 2-D plane, BC, is fully computed for each row scanned. That is, b0c0 is fully aggregated
2.4. DATA WAREHOUSE IMPLEMENTATION
29
ALL
A
B
AB
ALL
C
AC
BC
ABC
a) Most efficient ordering of array aggregation
(min. memory requirements = 156,000
memory units)
A
B
AB
AC
C
BC
ABC
b) Least efficient ordering of array aggregation
(min. memory requirements = 1,641,000
memory units)
Figure 2.16: Two orderings of multiway array aggregation for computation of the 3-D cube of Example 2.12.
after scanning the row containing chunks 1 to 4; b1 c0 is fully aggregated after scanning chunks 5 to 8, and
so on. In comparison, the complete computation of one chunk of the second largest 2-D plane, AC, requires
scanning 13 chunks (given the ordering from 1 to 64). For example, a0 c0 is fully aggregated after the scanning
of chunks 1, 5, 9, and 13. Finally, the complete computation of one chunk of the smallest 2-D plane, AB,
requires scanning 49 chunks. For example, a0 b0 is fully aggregated after scanning chunks 1, 17, 33, and 49.
Hence, AB requires the longest scan of chunks in order to complete its computation. To avoid bringing a 3-D
chunk into memory more than once, the minimum memory requirement for holding all relevant 2-D planes in
chunk memory, according to the chunk ordering of 1 to 64 is as follows: 40 400 (for the whole AB plane) +
40 1; 000 (for one row of the AC plane) + 100 1; 000 (for one chunk of the BC plane) = 16,000 + 40,000
+ 100,000 = 156,000.
Suppose, instead, that the chunks are scanned in the order 1, 17, 33, 49, 5, 21, 37, 53, etc. That is, suppose
the scan is in the order of rst aggregating towards the AB plane, and then towards the AC plane and lastly
towards the BC plane. The minimum memory requirement for holding 2-D planes in chunk memory would be
as follows: 400 4; 000 (for the whole BC plane) + 40 1; 000 (for one row of the AC plane) + 10 100 (for
one chunk of the AB plane) = 1,600,000 + 40,000 + 1,000 = 1,641,000. Notice that this is more than 10 times
the memory requirement of the scan ordering of 1 to 64.
Similarly, one can work out the minimum memory requirements for the multiway computation of the 1-D and
0-D cuboids. Figure 2.16 shows a) the most ecient ordering and b) the least ecient ordering, based on
the minimum memory requirements for the data cube computation. The most ecient ordering is the chunk
ordering of 1 to 64.
In conclusion, this example shows that the planes should be sorted and computed according to their size in
ascending order. Since jAB j < jAC j < jBC j, the AB plane should be computed rst, followed by the AC and
BC planes. Similarly, for the 1-D planes, jAj < jB j < jC j and therefore the A plane should be computed before
the B plane, which should be computed before the C plane.
2
Example 2.12 assumes that there is enough memory space for one-pass cube computation (i.e., to compute all of
the cuboids from one scan of all of the chunks). If there is insucient memory space, the computation will require
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
30
more than one pass through the 3-D array. In such cases, however, the basic principle of ordered chunk computation
remains the same.
\Which is faster | ROLAP or MOLAP cube computation?" With the use of appropriate sparse array compression
techniques and careful ordering of the computation of cuboids, it has been shown that MOLAP cube computation
is signicantly faster than ROLAP (relational record-based) computation. Unlike ROLAP, the array structure of
MOLAP does not require saving space to store search keys. Furthermore, MOLAP uses direct array addressing,
which is faster than the key-based addressing search strategy of ROLAP. In fact, for ROLAP cube computation,
instead of cubing a table directly, it is even faster to convert the table to an array, cube the array, and then convert
the result back to a table.
2.4.2 Indexing OLAP data
To facilitate ecient data accessing, most data warehouse systems support index structures and materialized views
(using cuboids). Methods to select cuboids for materialization were discussed in the previous section. In this section,
we examine how to index OLAP data by bitmap indexing and join indexing.
The bitmap indexing method is popular in OLAP products because it allows quick searching in data cubes.
The bitmap index is an alternative representation of the record ID (RID) list. In the bitmap index for a given
attribute, there is a distinct bit vector, Bv, for each value v in the domain of the attribute. If the domain of a given
attribute consists of n values, then n bits are needed for each entry in the bitmap index (i.e., there are n bit vectors).
If the attribute has the value v for a given row in the data table, then the bit representing that value is set to 1 in
the corresponding row of the bitmap index. All other bits for that row are set to 0.
Bitmap indexing is especially advantageous for low cardinality domains because comparison, join, and aggregation
operations are then reduced to bit-arithmetic, which substantially reduces the processing time. Bitmap indexing also
leads to signicant reductions in space and I/O since a string of characters can be represented by a single bit. For
higher cardinality domains, the method can be adapted using compression techniques.
The join indexing method gained popularity from its use in relational database query processing. Traditional
indexing maps the value in a given column to a list of rows having that value. In contrast, join indexing registers the
joinable rows of two relations from a relational database. For example, if two relations R(RID; A) and S(B; SID)
join on the attributes A and B, then the join index record contains the pair (RID; SID), where RID and SID are
record identiers from the R and S relations, respectively. Hence, the join index records can identify joinable tuples
without performing costly join operations. Join indexing is especially useful for maintaining the relationship between
a foreign key3 and its matching primary keys, from the joinable relation.
The star schema model of data warehouses makes join indexing attractive for cross table search because the linkage
between a fact table and its corresponding dimension tables are the foreign key of the fact table and the primary key
of the dimension table. Join indexing maintains relationships between attribute values of a dimension (e.g., within
a dimension table) and the corresponding rows in the fact table. Join indices may span multiple dimensions to form
composite join indices. We can use join indexing to identify subcubes that are of interest.
To further speed up query processing, the join indexing and bitmap indexing methods can be integrated to form
bitmapped join indices.
2.4.3 Ecient processing of OLAP queries
The purpose of materializing cuboids and constructing OLAP index structures is to speed up query processing in
data cubes. Given materialized views, query processing should proceed as follows:
1. Determine which operations should be performed on the available cuboids. This involves transforming any selection, projection, roll-up (group-by) and drill-down operations specied in the query into
corresponding SQL and/or OLAP operations. For example, slicing and dicing of a data cube may correspond
to selection and/or projection operations on a materialized cuboid.
2. Determine to which materialized cuboid(s) the relevant operations should be applied. This involves
identifying all of the materialized cuboids that may potentially be used to answer the query, pruning the
3
A set of attributes in a relation schema that forms a primary key for another schema is called a foreign key.
2.4. DATA WAREHOUSE IMPLEMENTATION
31
above set using knowledge of \dominance" relationships among the cuboids, estimating the costs of using the
remaining materialized cuboids, and selecting the cuboid with the least cost.
Example 2.13 Suppose that we dene a data cube for AllElectronics of the form \sales [time, item, location]:
in dollars)". The dimension hierarchies used are \day < month < quarter < year" for time, \item name
< brand < type" for item, and \street < city < province or state < country" for location.
Suppose that the query to be processed is on fbrand, province or stateg, with the selection constant \year =
1997". Also, suppose that there are four materialized cuboids available, as follows.
sum(sales
cuboid 1: fitem name, city, yearg
cuboid 2: fbrand, country, yearg
cuboid 3: fbrand, province or state, yearg
cuboid 4: fitem name, province or stateg where year = 1997.
\Which of the above four cuboids should be selected to process the query?" Finer granularity data cannot be
generated from coarser granularity data. Therefore, cuboid 2 cannot be used since country is a more general concept
than province or state. Cuboids 1, 3 and 4 can be used to process the query since: (1) they have the same set or
a superset of the dimensions in the query, and (2) the selection clause in the query can imply the selection in the
cuboid, and (3) the abstraction levels for the item and location dimensions in these cuboids are at a ner level than
brand and province or state, respectively.
\How would the costs of each cuboid compare if used to process the query?" It is likely that using cuboid 1 would
cost the most since both item name and city are at a lower level than the brand and province or state concepts
specied in the query. If there are not many year values associated with items in the cube, but there are several
item names for each brand, then cuboid 3 will be smaller than cuboid 4, and thus cuboid 3 should be chosen to
process the query. However, if ecient indices are available for cuboid 4, then cuboid 4 may be a better choice.
Therefore, some cost-based estimation is required in order to decide which set of cuboids should be selected for query
processing.
2
Since the storage model of a MOLAP sever is an n-dimensional array, the front-end multidimensional queries are
mapped directly to server storage structures, which provide direct addressing capabilities. The straightforward array
representation of the data cube has good indexing properties, but has poor storage utilization when the data are
sparse. For ecient storage and processing, sparse matrix and data compression techniques (Section 2.4.1) should
therefore be applied.
The storage structures used by dense and sparse arrays may dier, making it advantageous to adopt a two-level
approach to MOLAP query processing: use arrays structures for dense arrays, and sparse matrix structures for sparse
arrays. The two-dimensional dense arrays can be indexed by B-trees.
To process a query in MOLAP, the dense one- and two- dimensional arrays must rst be identied. Indices are
then built to these arrays using traditional indexing structures. The two-level approach increases storage utilization
without sacricing direct addressing capabilities.
2.4.4 Metadata repository
\What are metadata?"
Metadata are data about data. When used in a data warehouse, metadata are the data that dene warehouse
objects. Metadata are created for the data names and denitions of the given warehouse. Additional metadata are
created and captured for timestamping any extracted data, the source of the extracted data, and missing elds that
have been added by data cleaning or integration processes.
A metadata repository should contain:
a description of the structure of the data warehouse. This includes the warehouse schema, view, dimensions,
hierarchies, and derived data denitions, as well as data mart locations and contents;
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
32
operational metadata, which include data lineage (history of migrated data and the sequence of transformations
applied to it), currency of data (active, archived, or purged), and monitoring information (warehouse usage
statistics, error reports, and audit trails);
the algorithms used for summarization, which include measure and dimension denition algorithms, data on
granularity, partitions, subject areas, aggregation, summarization, and predened queries and reports;
the mapping from the operational environment to the data warehouse, which includes source databases and their
contents, gateway descriptions, data partitions, data extraction, cleaning, transformation rules and defaults,
data refresh and purging rules, and security (user authorization and access control);
data related to system performance, which include indices and proles that improve data access and retrieval
performance, in addition to rules for the timing and scheduling of refresh, update, and replication cycles; and
business metadata, which include business terms and denitions, data ownership information, and charging
policies.
A data warehouse contains dierent levels of summarization, of which metadata is one type. Other types include
current detailed data which are almost always on disk, older detailed data which are usually on tertiary storage,
lightly summarized data, and highly summarized data (which may or may not be physically housed). Notice that
the only type of summarization that is permanently stored in the data warehouse is that data which is frequently
used.
Metadata play a very dierent role than other data warehouse data, and are important for many reasons. For
example, metadata are used as a directory to help the decision support system analyst locate the contents of the
data warehouse, as a guide to the mapping of data when the data are transformed from the operational environment
to the data warehouse environment, and as a guide to the algorithms used for summarization between the current
detailed data and the lightly summarized data, and between the lightly summarized data and the highly summarized
data. Metadata should be stored and managed persistently (i.e., on disk).
2.4.5 Data warehouse back-end tools and utilities
Data warehouse systems use back-end tools and utilities to populate and refresh their data. These tools and facilities
include the following functions:
1.
2.
3.
4.
data extraction, which typically gathers data from multiple, heterogeneous, and external sources;
data cleaning, which detects errors in the data and recties them when possible;
data transformation, which converts data from legacy or host format to warehouse format;
load, which sorts, summarizes, consolidates, computes views, checks integrity, and builds indices and partitions;
and
5. refresh, which propagates the updates from the data sources to the warehouse.
Besides cleaning, loading, refreshing, and metadata denition tools, data warehouse systems usually provide a
good set of data warehouse management tools.
Since we are mostly interested in the aspects of data warehousing technology related to data mining, we will not
get into the details of these tools and recommend interested readers to consult books dedicated to data warehousing
technology.
2.5 Further development of data cube technology
In this section, you will study further developments in data cube technology. Section 2.5.1 describes data mining
by discovery-driven exploration of data cubes, where anomalies in the data are automatically detected and marked
for the user with visual cues. Section 2.5.2 describes multifeature cubes for complex data mining queries involving
multiple dependent aggregates at multiple granularities.
2.5. FURTHER DEVELOPMENT OF DATA CUBE TECHNOLOGY
33
2.5.1 Discovery-driven exploration of data cubes
As we have seen in this chapter, data can be summarized and stored in a multidimensional data cube of an OLAP
system. A user or analyst can search for interesting patterns in the cube by specifying a number of OLAP operations,
such as drill-down, roll-up, slice, and dice. While these tools are available to help the user explore the data, the
discovery process is not automated. It is the user who, following her own intuition or hypotheses, tries to recognize
exceptions or anomalies in the data. This hypothesis-driven exploration has a number of disadvantages. The
search space can be very large, making manual inspection of the data a daunting and overwhelming task. High level
aggregations may give no indication of anomalies at lower levels, making it easy to overlook interesting patterns.
Even when looking at a subset of the cube, such as a slice, the user is typically faced with many data values to
examine. The sheer volume of data values alone makes it easy for users to miss exceptions in the data if using
hypothesis-driven exploration.
Discovery-driven exploration is an alternative approach in which precomputed measures indicating data
exceptions are used to guide the user in the data analysis process, at all levels of aggregation. We hereafter refer
to these measures as exception indicators. Intuitively, an exception is a data cube cell value that is signicantly
dierent from the value anticipated, based on a statistical model. The model considers variations and patterns in
the measure value across all of the dimensions to which a cell belongs. For example, if the analysis of item-sales data
reveals an increase in sales in December in comparison to all other months, this may seem like an exception in the
time dimension. However, it is not an exception if the item dimension is considered, since there is a similar increase
in sales for other items during December. The model considers exceptions hidden at all aggregated group-by's of a
data cube. Visual cues such as background color are used to reect the degree of exception of each cell, based on
the precomputed exception indicators. Ecient algorithms have been proposed for cube construction, as discussed
in Section 2.4.1. The computation of exception indicators can be overlapped with cube construction, so that the
overall construction of data cubes for discovery-driven exploration is ecient.
Three measures are used as exception indicators to help identify data anomalies. These measures indicate the
degree of surprise that the quantity in a cell holds, with respect to its expected value. The measures are computed
and associated with every cell, for all levels of aggregation. They are:
1. SelfExp: This indicates the degree of surprise of the cell value, relative to other cells at the same level of
aggregation.
2. InExp: This indicates the degree of surprise somewhere beneath the cell, if we were to drill down from it.
3. PathExp: This indicates the degree of surprise for each drill-down path from the cell.
The use of these measures for discovery-driven exploration of data cubes is illustrated in the following example.
Example 2.14 Suppose that you would like to analyze the monthly sales at AllElectronics as a percentage dierence
from the previous month. The dimensions involved are item, time, and region. You begin by studying the data
aggregated over all items and sales regions for each month, as shown in Figure 2.17.
To view the exception indicators, you would click on a button marked highlight exceptions on the screen. This
translates the SelfExp and InExp values into visual cues, displayed with each cell. The background color of each cell
is based on its SelfExp value. In addition, a box is drawn around each cell, where the thickness and color of the box
are a function of its InExp value. Thick boxes indicate high InExp values. In both cases, the darker the color is, the
greater the degree of exception is. For example, the dark thick boxes for sales during July, August, and September
signal the user to explore the lower level aggregations of these cells by drilling down.
Drill downs can be executed along the aggregated item or region dimensions. Which path has more exceptions?
To nd this out, you select a cell of interest and trigger a path exception module that colors each dimension based
on the PathExp value of the cell. This value reects the degree of surprise of that path. Consider the PathExp
indicators for item and region in the upper left-hand corner of Figure 2.17. We see that the path along item contains
more exceptions, as indicated by the darker color.
A drill-down along item results in the cube slice of Figure 2.18, showing the sales over time for each item. At this
point, you are presented with many dierent sales values to analyze. By clicking on the highlight exceptions button,
the visual cues are displayed, bringing focus towards the exceptions. Consider the sales dierence of 41% for \Sony
b/w printers" in September. This cell has a dark background, indicating a high SelfExp value, meaning that the cell
is an exception. Consider now the the sales dierence of -15% for \Sony b/w printers" in November, and of -11% in
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
34
item all
region all
Sum of sales month
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
Total
1% -1% 0% 1% 3% -1 -9% -1% 2% -4% 3%
Figure 2.17: Change in sales over time.
Avg sales
item
month
Jan Feb
Sony b/w printer
Sony color printer
HP b/w printer
HP color printer
IBM home computer
IBM laptop computer
Toshiba home computer
Toshiba laptop computer
Logitech mouse
Ergo-way mouse
9%
0%
-2%
0%
1%
0%
-2%
1%
3%
0%
Mar Apr
May Jun
-8%
0%
1%
0%
-2%
0%
-5%
0%
-2%
0%
-5%
2%
3%
1%
-1%
3%
1%
0%
0%
3%
2%
3%
2%
-2%
-1%
-1%
1%
3%
-1%
2%
14%
4%
8%
0%
3%
4%
-1%
-2%
4%
1%
Jul
Aug Sep
-4%
-10%
0%
-1%
3%
2%
1%
-2%
6%
-2%
0%
-13%
-12%
-7%
-10%
-10%
5%
5%
-5%
-11%
-2%
41%
0%
-9%
-2%
4%
-2%
-3%
3%
2%
-5%
Oct
Nov Dec
-13%
-13%
4%
3%
1%
1%
0%
-5%
2%
1%
0%
-15%
-6%
-3%
-5%
-4%
-9%
-1%
-1%
-4%
-5%
Figure 2.18: Change in sales for each item-time combination.
-11%
4%
6%
1%
-1%
3%
-1%
0%
0%
8%
2.5. FURTHER DEVELOPMENT OF DATA CUBE TECHNOLOGY
item
IBM home computer
Avg sales month
region Jan Feb Mar Apr May Jun Jul
North
South
East
West
35
-1%
-1%
-1%
4%
-3%
1%
-2%
0%
-1%
-9%
2%
-1%
0%
6%
-3%
-3%
3%
-1%
1%
5%
4%
-39%
-39%
18%
1%
Aug Sep
Oct Nov Dec
-7%
9%
-2%
-18%
0%
4%
-3%
5%
1%
-34%
11%
8%
-3%
1%
-2%
-8%
-3%
7%
-1%
1%
Figure 2.19: Change in sales for the item \IBM home computer" per region.
December. The -11% value for December is marked as an exception, while the -15% value is not, even though -15%
is a bigger deviation than -11%. This is because the exception indicators consider all of the dimensions that a cell is
in. Notice that the December sales of most of the other items have a large positive value, while the November sales
do not. Therefore, by considering the position of the cell in the cube, the sales dierence for \Sony b/w printers" in
December is exceptional, while the November sales dierence of this item is not.
The InExp values can be used to indicate exceptions at lower levels that are not visible at the current level.
Consider the cells for \IBM home computers" in July and September. These both have a dark thick box around
them, indicating high InExp values. You may decide to further explore the sales of \IBM home computers" by
drilling down along region. The resulting sales dierence by region is shown in Figure 2.19, where the highlight
exceptions option has been invoked. The visual cues displayed make it easy to instantly notice an exception for
the sales of \IBM home computers" in the southern region, where such sales have decreased by -39% and -34% in
July and September, respectively. These detailed exceptions were far from obvious when we were viewing the data
as an item-time group-by, aggregated over region in Figure 2.18. Thus, the InExp value is useful for searching for
exceptions at lower level cells of the cube. Since there are no other cells in Figure 2.19 having a high InExp value,
you may roll up back to the data of Figure 2.18, and choose another cell from which to drill down. In this way, the
exception indicators can be used to guide the discovery of interesting anomalies in the data.
2
\How are the exception values computed?" The SelfExp, InExp, and PathExp measures are based on a statistical
method for table analysis. They take into account all of the group-by (aggregations) in which a given cell value
participates. A cell value is considered an exception based on how much it diers from its expected value, where
its expected value is determined with a statistical model described below. The dierence between a given cell value
and its expected value is called a residual. Intuitively, the larger the residual, the more the given cell value is an
exception. The comparison of residual values requires us to scale the values based on the expected standard deviation
associated with the residuals. A cell value is therefore considered an exception if its scaled residual value exceeds a
prespecied threshold. The SelfExp, InExp, and PathExp measures are based on this scaled residual.
The expected value of a given cell is a function of the higher level group-by's of the given cell. For example,
given a cube with the three dimensions A; B, and C, the expected value for a cell at the ith position in A, the jth
BC , which are coecients
position in B, and the kth position in C is a function of ; iA ; jB ; kC ; ijAB ; ikAC , and jk
of the statistical model used. The coecients reect how dierent the values at more detailed levels are, based on
generalized impressions formed by looking at higher level aggregations. In this way, the exception quality of a cell
value is based on the exceptions of the values below it. Thus, when seeing an exception, it is natural for the user to
further explore the exception by drilling down.
\How can the data cube be eciently constructed for discovery-driven exploration?" This computation consists
of three phases. The rst step involves the computation of the aggregate values dening the cube, such as sum or
count, over which exceptions will be found. There are several ecient techniques for cube computation, such as
the multiway array aggregation technique discussed in Section 2.4.1. The second phase consists of model tting, in
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
36
which the coecients mentioned above are determined and used to compute the standardized residuals. This phase
can be overlapped with the rst phase since the computations involved are similar. The third phase computes the
SelfExp, InExp, and PathExp values, based on the standardized residuals. This phase is computationally similar to
phase 1. Therefore, the computation of data cubes for discovery-driven exploration can be done eciently.
2.5.2 Complex aggregation at multiple granularities: Multifeature cubes
Data cubes facilitate the answering of data mining queries as they allow the computation of aggregate data at multiple
levels of granularity. In this section, you will learn about multifeature cubes which compute complex queries involving
multiple dependent aggregates at multiple granularities. These cubes are very useful in practice. Many complex data
mining queries can be answered by multifeature cubes without any signicant increase in computational cost, in
comparison to cube computation for simple queries with standard data cubes.
All of the examples in this section are from the Purchases data of AllElectronics, where an item is purchased in
a sales region on a business day (year, month, day). The shelf life in months of a given item is stored in shelf. The
item price and sales (in dollars) at a given region are stored in price and sales, respectively. To aid in our study of
multifeature cubes, let's rst look at an example of a simple data cube.
Example 2.15 Query 1: A simple data cube query: Find the total sales in 1997, broken down by item, region,
and month, with subtotals for each dimension.
To answer Query 1, a data cube is constructed which aggregates the total sales at the following 8 dierent levels
of granularity: f(item, region, month), (item, region), (item, month), (month, region), (item), (month), (region), ()g,
where () represents all. There are several techniques for computing such data cubes eciently (Section 2.4.1). 2
Query 1 uses a data cube like that studied so far in this chapter. We call such a data cube a simple data cube
since it does not involve any dependent aggregates.
\What is meant by \dependent aggregates"?" We answer this by studying the following example of a complex
query.
Example 2.16 Query 2: A complex query: Grouping by all subsets of fitem, region, monthg, nd the maximum
price in 1997 for each group, and the total sales among all maximum price tuples.
The specication of such a query using standard SQL can be long, repetitive, and dicult to optimize and
maintain. Alternatively, Query 2 can be specied concisely using an extended SQL syntax as follows:
select
from
where
cube by
such that
item, region, month, MAX(price), SUM(R.sales)
Purchases
year = 1997
item, region, month: R
R.price = MAX(price)
The tuples representing purchases in 1997 are rst selected. The cube by clause computes aggregates (or groupby's) for all possible combinations of the attributes item, region, and month. It is an n-dimensional generalization
of the group by clause. The attributes specied in the cube by clause are the grouping attributes. Tuples with the
same value on all grouping attributes form one group. Let the groups be g1; ::; gr . For each group of tuples gi , the
maximum price maxg among the tuples forming the group is computed. The variable R is a grouping variable,
ranging over all tuples in group gi whose price is equal to maxg (as specied in the such that clause). The sum of
sales of the tuples in gi that R ranges over is computed, and returned with the values of the grouping attributes of
gi . The resulting cube is a multifeature cube in that it supports complex data mining queries for which multiple
dependent aggregates are computed at a variety of granularities. For example, the sum of sales returned in Query 2
is dependent on the set of maximum price tuples for each group.
2
i
i
Let's look at another example.
Example 2.17 Query 3: An even more complex query: Grouping by all subsets of fitem, region, monthg,
nd the maximum price in 1997 for each group. Among the maximum price tuples, nd the minimum and maximum
2.5. FURTHER DEVELOPMENT OF DATA CUBE TECHNOLOGY
{=MIN(R1.shelf)}
R2
37
{=MAX(R1.shelf)}
R3
R1
{=MAX(price)}
R0
Figure 2.20: A multifeature cube graph for Query 3.
item shelf lives. Also nd the fraction of the total sales due to tuples that have minimum shelf life within the set of
all maximum price tuples, and the fraction of the total sales due to tuples that have maximum shelf life within the
set of all maximum price tuples.
The multifeature cube graph of Figure 2.20 helps illustrate the aggregate dependencies in the query. There
is one node for each grouping variable, plus an additional initial node, R0. Starting from node R0, the set of
maximum price tuples in 1997 is rst computed (node R1). The graph indicates that grouping variables R2 and R3
are \dependent" on R1, since a directed line is drawn from R1 to each of R2 and R3. In a multifeature cube graph,
a directed line from grouping variable Ri to Rj means that Rj always ranges over a subset of the tuples that Ri
ranges for. When expressing the query in extended SQL, we write \Rj in Ri" as shorthand to refer to this case. For
example, the minimum shelf life tuples at R2 range over the maximum price tuples at R1, i.e., R2 in R1. Similarly,
the maximum shelf life tuples at R3 range over the maximum price tuples at R1, i.e., R3 in R1.
From the graph, we can express Query 3 in extended SQL as follows:
select
item, region, month, MAX(price), MIN(R1.shelf), MAX(R1.shelf),
SUM(R1.sales), SUM(R2.sales), SUM(R3.sales)
from
Purchases
where
year = 1997
cube by item, region, month: R1, R2, R3
such that R1.price = MAX(price) and
R2 in R1 and R2.shelf = MIN(R1.shelf) and
R3 in R1 and R3.shelf = MAX(R1.shelf)
2
\How can multifeature cubes be computed eciently?" The computation of a multifeature cube depends on the
types of aggregate functions used in the cube. Recall in Section 2.2.4, we saw that aggregate functions can be
categorized as either distributive (such as count(), sum(), min(), and max()), algebraic (such as avg(), min N(),
max N()), or holistic (such as median(), mode(), and rank()). Multifeature cubes can be organized into the same
categories.
Intuitively, Query 2 is a distributive multifeature cube since we can distribute its computation by incrementally
generating the output of the cube at a higher level granularity using only the output of the cube at a lower level
granularity. Similarly, Query 3 is also distributive. Some multifeature cubes that are not distributive may be
\converted" by adding aggregates to the select clause so that the resulting cube is distributive. For example, suppose
that the select clause for a given multifeature cube has AVG(sales), but neither COUNT(sales) nor SUM(sales).
By adding SUM(sales) to the select clause, the resulting data cube is distributive. The original cube is therefore
algebraic. In the new distributive cube, the average sales at a higher level granularity can be computed from the
average and total sales at lower level granularities. A cube that is neither distributive nor algebraic is holistic.
38
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
The type of multifeature cube determines the approach used in its computation. There are a number of methods
for the ecient computation of data cubes (Section 2.4.1). The basic strategy of these algorithms is to exploit the
lattice structure of the multiple granularities dening the cube, where higher level granularities are computed from
lower level granularities. This approach suits distributive multifeature cubes, as described above. For example, in
Query 2, the computation of MAX(price) at a higher granularity group can be done by taking the maximum of
all of the MAX(price) values at the lower granularity groups. Similarly, SUM(sales) can be computed for a higher
level group by summing all of the SUM(sales) values in its lower level groups. Some algorithms for ecient cube
construction employ optimization techniques based on the estimated size of answers of groups within a data cube.
Since the output size for each group in a multifeature cube is constant, the same estimation techniques can be
used to estimate the size of intermediate results. Thus, the basic algorithms for ecient computation of simple
data cubes can be used to compute distributive multifeature cubes for complex queries without any increase in I/O
complexity. There may be a negligible increase in the CPU cost if the aggregate function of the multifeature cube
is more complex than, say, a simple SUM(). Algebraic multifeature cubes must rst be transformed into distributive
multifeature cubes in order for these algorithms to apply. The computation of holistic multifeature cubes is sometimes
signicantly more expensive than the computation of distributive cubes, although the CPU cost involved is generally
acceptable. Therefore, multifeature cubes can be used to answer complex queries with very little additional expense
in comparison to simple data cube queries.
2.6 From data warehousing to data mining
2.6.1 Data warehouse usage
Data warehouses and data marts are used in a wide range of applications. Business executives in almost every
industry use the data collected, integrated, preprocessed, and stored in data warehouses and data marts to perform
data analysis and make strategic decisions. In many rms, data warehouses are used as an integral part of a planexecute-assess \closed-loop" feedback system for enterprise management. Data warehouses are used extensively in
banking and nancial services, consumer goods and retail distribution sectors, and controlled manufacturing, such
as demand-based production.
Typically, the longer a data warehouse has been in use, the more it will have evolved. This evolution takes
place throughout a number of phases. Initially, the data warehouse is mainly used for generating reports and
answering predened queries. Progressively, it is used to analyze summarized and detailed data, where the results
are presented in the form of reports and charts. Later, the data warehouse is used for strategic purposes, performing
multidimensional analysis and sophisticated slice-and-dice operations. Finally, the data warehouse may be employed
for knowledge discovery and strategic decision making using data mining tools. In this context, the tools for data
warehousing can be categorized into access and retrieval tools, database reporting tools, data analysis tools, and data
mining tools.
Business users need to have the means to know what exists in the data warehouse (through metadata), how to
access the contents of the data warehouse, how to examine the contents using analysis tools, and how to present the
results of such analysis.
There are three kinds of data warehouse applications: information processing, analytical processing, and data
mining:
Information processing supports querying, basic statistical analysis, and reporting using crosstabs, tables,
charts or graphs. A current trend in data warehouse information processing is to construct low cost Web-based
accessing tools which are then integrated with Web browsers.
Analytical processing supports basic OLAP operations, including slice-and-dice, drill-down, roll-up, and
pivoting. It generally operates on historical data in both summarized and detailed forms. The major strength
of on-line analytical processing over information processing is the multidimensional data analysis of data warehouse data.
Data mining supports knowledge discovery by nding hidden patterns and associations, constructing ana-
lytical models, performing classication and prediction, and presenting the mining results using visualization
tools.
2.6. FROM DATA WAREHOUSING TO DATA MINING
39
\How does data mining relate to information processing and on-line analytical processing?"
Information processing, based on queries, can nd useful information. However, answers to such queries reect
the information directly stored in databases or computable by aggregate functions. They do not reect sophisticated
patterns or regularities buried in the database. Therefore, information processing is not data mining.
On-line analytical processing comes a step closer to data mining since it can derive information summarized
at multiple granularities from user-specied subsets of a data warehouse. Such descriptions are equivalent to the
class/concept descriptions discussed in Chapter 1. Since data mining systems can also mine generalized class/concept
descriptions, this raises some interesting questions: Do OLAP systems perform data mining? Are OLAP systems
actually data mining systems?
The functionalities of OLAP and data mining can be viewed as disjoint: OLAP is a data summarization/aggregation
tool which helps simplify data analysis, while data mining allows the automated discovery of implicit patterns and
interesting knowledge hidden in large amounts of data. OLAP tools are targeted toward simplifying and supporting
interactive data analysis, but the goal of data mining tools is to automate as much of the process as possible, while
still allowing users to guide the process. In this sense, data mining goes one step beyond traditional on-line analytical
processing.
An alternative and broader view of data mining may be adopted in which data mining covers both data description
and data modeling. Since OLAP systems can present general descriptions of data from data warehouses, OLAP
functions are essentially for user-directed data summary and comparison (by drilling, pivoting, slicing, dicing, and
other operations). These are, though limited, data mining functionalities. Yet according to this view, data mining
covers a much broader spectrum than simple OLAP operations because it not only performs data summary and
comparison, but also performs association, classication, prediction, clustering, time-series analysis, and other data
analysis tasks.
Data mining is not conned to the analysis of data stored in data warehouses. It may analyze data existing at more
detailed granularities than the summarized data provided in a data warehouse. It may also analyze transactional,
textual, spatial, and multimedia data which are dicult to model with current multidimensional database technology.
In this context, data mining covers a broader spectrum than OLAP with respect to data mining functionality and
the complexity of the data handled.
Since data mining involves more automated and deeper analysis than OLAP, data mining is expected to have
broader applications. Data mining can help business managers nd and reach more suitable customers, as well as
gain critical business insights that may help to drive market share and raise prots. In addition, data mining can
help managers understand customer group characteristics and develop optimal pricing strategies accordingly, correct
item bundling based not on intuition but on actual item groups derived from customer purchase patterns, reduce
promotional spending and at the same time, increase net eectiveness of promotions overall.
2.6.2 From on-line analytical processing to on-line analytical mining
In the eld of data mining, substantial research has been performed for data mining at various platforms, including
transaction databases, relational databases, spatial databases, text databases, time-series databases, at les, data
warehouses, etc.
Among many dierent paradigms and architectures of data mining systems, On-Line Analytical Mining
(OLAM) (also called OLAP mining), which integrates on-line analytical processing (OLAP) with data mining
and mining knowledge in multidimensional databases, is particularly important for the following reasons.
1. High quality of data in data warehouses. Most data mining tools need to work on integrated, consistent,
and cleaned data, which requires costly data cleaning, data transformation, and data integration as preprocessing steps. A data warehouse constructed by such preprocessing serves as a valuable source of high quality
data for OLAP as well as for data mining. Notice that data mining may also serve as a valuable tool for data
cleaning and data integration as well.
2. Available information processing infrastructure surrounding data warehouses. Comprehensive information processing and data analysis infrastructures have been or will be systematically constructed surrounding
data warehouses, which include accessing, integration, consolidation, and transformation of multiple, heterogeneous databases, ODBC/OLEDB connections, Web-accessing and service facilities, reporting and OLAP
40
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
User GUI API
OLAM
Engine
OLAP
Engine
Cube API
Meta
Data
Data
Cube
Database API
Data cleaning
data integration
Data
Base
filtering
Data
Warehouse
Figure 2.21: An integrated OLAM and OLAP architecture.
analysis tools. It is prudent to make the best use of the available infrastructures rather than constructing
everything from scratch.
3. OLAP-based exploratory data analysis. Eective data mining needs exploratory data analysis. A user
will often want to traverse through a database, select portions of relevant data, analyze them at dierent granularities, and present knowledge/results in dierent forms. On-line analytical mining provides facilities for data
mining on dierent subsets of data and at dierent levels of abstraction, by drilling, pivoting, ltering, dicing
and slicing on a data cube and on some intermediate data mining results. This, together with data/knowledge
visualization tools, will greatly enhance the power and exibility of exploratory data mining.
4. On-line selection of data mining functions. Often a user may not know what kinds of knowledge that she
wants to mine. By integrating OLAP with multiple data mining functions, on-line analytical mining provides
users with the exibility to select desired data mining functions and swap data mining tasks dynamically.
Architecture for on-line analytical mining
An OLAM engine performs analytical mining in data cubes in a similar manner as an OLAP engine performs on-line
analytical processing. An integrated OLAM and OLAP architecture is shown in Figure 2.21, where the OLAM and
OLAP engines both accept users' on-line queries (or commands) via a User GUI API and work with the data cube
in the data analysis via a Cube API. A metadata directory is used to guide the access of the data cube. The data
cube can be constructed by accessing and/or integrating multiple databases and/or by ltering a data warehouse via
a Database API which may support OLEDB or ODBC connections. Since an OLAM engine may perform multiple
data mining tasks, such as concept description, association, classication, prediction, clustering, time-series analysis,
etc., it usually consists of multiple, integrated data mining modules and is more sophisticated than an OLAP engine.
The following chapters of this book are devoted to the study of data mining techniques. As we have seen, the
introduction to data warehousing and OLAP technology presented in this chapter is essential to our study of data
mining. This is because data warehousing provides users with large amounts of clean, organized, and summarized
data, which greatly facilitates data mining. For example, rather than storing the details of each sales transaction, a
data warehouse may store a summary of the transactions per item type for each branch, or, summarized to a higher
level, for each country. The capability of OLAP to provide multiple and dynamic views of summarized data in a
data warehouse sets a solid foundation for successful data mining.
2.7. SUMMARY
41
Moreover, we also believe that data mining should be a human-centered process. Rather than asking a data
mining system to generate patterns and knowledge automatically, a user will often need to interact with the system
to perform exploratory data analysis. OLAP sets a good example for interactive data analysis, and provides the
necessary preparations for exploratory data mining. Consider the discovery of association patterns, for example.
Instead of mining associations at a primitive (i.e., low) data level among transactions, users should be allowed to
specify roll-up operations along any dimension. For example, a user may like to roll-up on the item dimension to go
from viewing the data for particular TV sets that were purchased to viewing the brands of these TVs, such as SONY
or Panasonic. Users may also navigate from the transaction level to the customer level or customer-type level in the
search for interesting associations. Such an OLAP-style of data mining is characteristic of OLAP mining.
In our study of the principles of data mining in the following chapters, we place particular emphasis on OLAP
mining, that is, on the integration of data mining and OLAP technology.
2.7 Summary
A data warehouse is a subject-oriented, integrated, time-variant, and nonvolatile collection of data organized
in support of management decision making. Several factors distinguish data warehouses from operational
databases. Since the two systems provide quite dierent functionalities and require dierent kinds of data, it
is necessary to maintain data warehouses separately from operational databases.
A multidimensional data model is typically used for the design of corporate data warehouses and departmental data marts. Such a model can adopt either a star schema, snowake schema, or fact constellation
schema. The core of the multidimensional model is the data cube, which consists of a large set of facts (or
measures) and a number of dimensions. Dimensions are the entities or perspectives with respect to which an
organization wants to keep records, and are hierarchical in nature.
Concept hierarchies organize the values of attributes or dimensions into gradual levels of abstraction. They
are useful in mining at multiple levels of abstraction.
On-line analytical processing (OLAP) can be performed in data warehouses/marts using the multidimensional data model. Typical OLAP operations include roll-up, drill-(down, cross, through), slice-and-dice, pivot
(rotate), as well as statistical operations such as ranking, computing moving averages and growth rates, etc.
OLAP operations can be implemented eciently using the data cube structure.
Data warehouses often adopt a three-tier architecture. The bottom tier is a warehouse database server,
which is typically a relational database system. The middle tier is an OLAP server, and the top tier is a client,
containing query and reporting tools.
OLAP servers may use Relational OLAP (ROLAP), or Multidimensional OLAP (MOLAP), or Hybrid OLAP (HOLAP). A ROLAP server uses an extended relational DBMS that maps OLAP operations
on multidimensional data to standard relational operations. A MOLAP server maps multidimensional data
views directly to array structures. A HOLAP server combines ROLAP and MOLAP. For example, it may use
ROLAP for historical data while maintaining frequently accessed data in a separate MOLAP store.
A data cube consists of a lattice of cuboids, each corresponding to a dierent degree of summarization of the
given multidimensional data. Partial materialization refers to the selective computation of a subset of the
cuboids in the lattice. Full materialization refers to the computation of all of the cuboids in the lattice. If
the cubes are implemented using MOLAP, then multiway array aggregation can be used. This technique
\overlaps" some of the aggregation computation so that full materialization can be computed eciently.
OLAP query processing can be made more ecient with the use of indexing techniques. In bitmap indexing,
each attribute has its own bimap vector. Bitmap indexing reduces join, aggregation, and comparison operations
to bit arithmetic. Join indexing registers the joinable rows of two or more relations from a relational database,
reducing the overall cost of OLAP join operations. Bitmapped join indexing, which combines the bitmap
and join methods, can be used to further speed up OLAP query processing.
Data warehouse metadata are data dening the warehouse objects. A metadata repository provides details
regarding the warehouse structure, data history, the algorithms used for summarization, mappings from the
source data to warehouse form, system performance, and business terms and issues.
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
42
A data warehouse contains back-end tools and utilities for populating and refreshing the warehouse. These
cover data extraction, data cleaning, data transformation, loading, refreshing, and warehouse management.
Discovery-driven exploration of data cubes uses precomputed measures and visual cues to indicate data
exceptions, guiding the user in the data analysis process, at all levels of aggregation. Multifeature cubes
compute complex queries involving multiple dependent aggregates at multiple granularities. The computation of
cubes for discovery-driven exploration and of multifeature cubes can be achieved eciently by taking advantage
of ecient algorithms for standard data cube computation.
Data warehouses are used for information processing (querying and reporting), analytical processing (which
allows users to navigate through summarized and detailed data by OLAP operations), and data mining (which
supports knowledge discovery). OLAP-based data mining is referred to as OLAP mining, or on-line analytical
mining (OLAM), which emphasizes the interactive and exploratory nature of OLAP mining.
Exercises
1. State why, for the integration of multiple, heterogeneous information sources, many companies in industry
prefer the update-driven approach (which constructs and uses data warehouses), rather than the query-driven
approach (which applies wrappers and integrators). Describe situations where the query-driven approach is
preferable over the update-driven approach.
2. Design a data warehouse for a regional weather bureau. The weather bureau has about 1,000 probes which are
scattered throughout various land and ocean locations in the region to collect basic weather data, including
air pressure, temperature, and precipitation at each hour. All data are sent to the central station, which has
collected such data for over 10 years. Your design should facilitate ecient querying and on-line analytical
processing, and derive general weather patterns in multidimensional space.
3. What are the dierences between the three typical methods for modeling multidimensionaldata: the star model,
the snowake model, and the fact constellation model? What is the dierence between the star warehouse
model and the starnet query model? Use an example to explain your point(s).
4. A popular data warehouse implementation is to construct a multidimensional database, known as a data cube.
Unfortunately, this may often generate a huge, yet very sparse multidimensional matrix.
(a) Present an example, illustrating such a huge and sparse data cube.
(b) Design an implementation method which can elegantly overcome this sparse matrix problem. Note that
you need to explain your data structures in detail and discuss the space needed, as well as how to retrieve
data from your structures, and how to handle incremental data updates.
5. Data warehouse design:
(a) Enumerate three classes of schemas that are popularly used for modeling data warehouses.
(b) Draw a schema diagram for a data warehouse which consists of three dimensions: time, doctor, and patient,
and two measures: count, and charge, where charge is the fee that a doctor charges a patient for a visit.
(c) Starting with the base cuboid (day; doctor; patient), what specic OLAP operations should be performed
in order to list the total fee collected by each doctor in VGH (Vancouver General Hospital) in 1997?
(d) To obtain the same list, write an SQL query assuming the data is stored in a relational database with the
schema.
fee(day; month; year; doctor; hospital; patient; count; charge):
6. Computing measures in a data cube:
(a) Enumerate three categories of measures, based on the kind of aggregate functions used in computing a
data cube.
(b) For a data cube with three dimensions: time, location, and product, which category does the function
variance belong to? Describe how to compute it P
if the cube is partitioned into many chunks.
1
Hint: The formula for computing variance is: n ni=1(xi )2 , xi2 , where xi is the average of xi 's.
2.7. SUMMARY
7.
8.
9.
10.
11.
12.
13.
43
(c) Suppose the function is \top 10 sales". Discuss how to eciently compute this measure in a data cube.
Suppose that one needs to record three measures in a data cube: min, average, and median. Design an ecient
computation and storage method for each measure given that the cube allows data to be deleted incrementally
(i.e., in small portions at a time) from the cube.
In data warehouse technology, a multiple dimensional view can be implemented by a multidimensional database
technique (MOLAP), or by a relational database technique (ROLAP), or a hybrid database technique (HOLAP).
(a) Briey describe each implementation technique.
(b) For each technique, explain how each of the following functions may be implemented:
i. The generation of a data warehouse (including aggregation).
ii. Roll-up.
iii. Drill-down.
iv. Incremental updating.
Which implementation techniques do you prefer, and why?
Suppose that a data warehouse contains 20 dimensions each with about 5 levels of granularity.
(a) Users are mainly interested in four particular dimensions, each having three frequently accessed levels for
rolling up and drilling down. How would you design a data cube structure to support this preference
eciently?
(b) At times, a user may want to drill-through the cube, down to the raw data for one or two particular
dimensions. How would you support this feature?
Data cube computation: Suppose a base cuboid has 3 dimensions, (A; B; C), with the number of cells shown
below: jAj = 1; 000; 000, jB j = 100, and jC j = 1; 000. Suppose each dimension is partitioned evenly into 10
portions for chunking.
(a) Assuming each dimension has only one level, draw the complete lattice of the cube.
(b) If each cube cell stores one measure with 4 bytes, what is the total size of the computed cube if the cube
is dense?
(c) If the cube is very sparse, describe an eective multidimensional array structure to store the sparse cube.
(d) State the order for computing the chunks in the cube which requires the least amount of space, and
compute the total amount of main memory space required for computing the 2-D planes.
In both data warehousing and data mining, it is important to have some hierarchy information associated with
each dimension. If such a hierarchy is not given, discuss how to generate such a hierarchy automatically for
the following cases:
(a) a dimension containing only numerical data.
(b) a dimension containing only categorical data.
Suppose that a data cube has 2 dimensions, (A; B), and each dimension can be generalized through 3 levels
(with the top-most level being all). That is, starting with level A0 , A can be generalized to A1 , then to A2, and
then to all. How many dierent cuboids (i.e., views) can be generated for this cube? Sketch a lattice of these
cuboids to show how you derive your answer. Also, give a general formula for a data cube with D dimensions,
each starting at a base level and going up through L levels, with the top-most level being all.
Consider the following multifeature cube query: Grouping by all subsets of fitem, region, monthg, nd the
minimum shelf life in 1997 for each group, and the fraction of the total sales due to tuples whose price is less
than $100, and whose shelf life is within 25% of the minimum shelf life, and within 50% of the minimum shelf
life.
(a) Draw the multifeature cube graph for the query.
44
CHAPTER 2. DATA WAREHOUSE AND OLAP TECHNOLOGY FOR DATA MINING
(b) Express the query in extended SQL.
(c) Is this a distributive multifeature cube? Why or why not?
14. What are the dierences between the three main types of data warehouse usage: information processing,
analytical processing, and data mining? Discuss the motivation behind OLAP mining (OLAM).
Bibliographic Notes
There are a good number of introductory level textbooks on data warehousing and OLAP technology, including
Inmon [15], Kimball [16], Berson and Smith [4], and Thomsen [24]. Chaudhuri and Dayal [6] provide a general
overview of data warehousing and OLAP technology.
The history of decision support systems can be traced back to the 1960s. However, the proposal of the construction
of large data warehouses for multidimensional data analysis is credited to Codd [7] who coined the term OLAP for
on-line analytical processing. The OLAP council was established in 1995. Widom [26] identied several research
problems in data warehousing. Kimball [16] provides an overview of the deciencies of SQL regarding the ability to
support comparisons that are common in the business world.
The DMQL data mining query language was proposed by Han et al. [11] Data mining query languages are
further discussed in Chapter 4. Other SQL-based languages for data mining are proposed in Imielinski, Virmani,
and Abdulghani [14], Meo, Psaila, and Ceri [17], and Baralis and Psaila [3].
Gray et al. [9, 10] proposed the data cube as a relational aggregation operator generalizing group-by, crosstabs, and
sub-totals. Harinarayan, Rajaraman, and Ullman [13] proposed a greedy algorithm for the partial materialization of
cuboids in the computation of a data cube. Agarwal et al. [1] proposed several methods for the ecient computation
of multidimensional aggregates for ROLAP servers. The chunk-based multiway array aggregation method described
in Section 2.4.1 for data cube computation in MOLAP was proposed in Zhao, Deshpande, and Naughton [27].
Additional methods for the fast computation of data cubes can be found in Beyer and Ramakrishnan [5], and Ross
and Srivastava [19]. Sarawagi and Stonebraker [22] developed a chunk-based computation technique for the ecient
organization of large multidimensional arrays.
For work on the selection of materialized cuboids for ecient OLAP query processing, see Harinarayan, Rajaraman, and Ullman [13], and Sristava et al. [23]. Methods for cube size estimation can be found in Beyer and
Ramakrishnan [5], Ross and Srivastava [19], and Deshpande et al. [8]. Agrawal, Gupta, and Sarawagi [2] proposed
operations for modeling multidimensional databases.
The use of join indices to speed up relational query processing was proposed by Valduriez [25]. O'Neil and Graefe
[18] proposed a bitmapped join index method to speed-up OLAP-based query processing.
There are some recent studies on the implementation of discovery-oriented data cubes for data mining. This
includes the discovery-driven exploration of OLAP data cubes by Sarawagi, Agrawal, and Megiddo [21], and the construction of multifeature data cubes by Ross, Srivastava, and Chatziantoniou [20]. For a discussion of methodologies
for OLAM (On-Line Analytical Mining), see Han et al. [12].
Bibliography
[1] S. Agarwal, R. Agrawal, P. M. Deshpande, A. Gupta, J. F. Naughton, R. Ramakrishnan, and S. Sarawagi.
On the computation of multidimensional aggregates. In Proc. 1996 Int. Conf. Very Large Data Bases, pages
506{521, Bombay, India, Sept. 1996.
[2] R. Agrawal, A. Gupta, and S. Sarawagi. Modeling multidimensional databases. In Proc. 1997 Int. Conf. Data
Engineering, pages 232{243, Birmingham, England, April 1997.
[3] E. Baralis and G. Psaila. Designing templates for mining association rules. Journal of Intelligent Information
Systems, 9:7{32, 1997.
[4] A. Berson and S. J. Smith. Data Warehousing, Data Mining, and OLAP. New York: McGraw-Hill, 1997.
[5] K. Beyer and R. Ramakrishnan. Bottom-up computation of sparse and iceberg cubes. In Proc. 1999 ACMSIGMOD Int. Conf. Management of Data, pages 359{370, Philadelphia, PA, June 1999.
[6] S. Chaudhuri and U. Dayal. An overview of data warehousing and OLAP technology. ACM SIGMOD Record,
26:65{74, 1997.
[7] E. F Codd, S. B. Codd, and C. T. Salley. Providing OLAP (on-line analytical processing) to user-analysts: An
IT mandate. In E. F. Codd & Associates available at http://www.arborsoft.com/OLAP.html, 1993.
[8] P. Deshpande, J. Naughton, K. Ramasamy, A. Shukla, K. Tufte, and Y. Zhao. Cubing algorithms, storage
estimation, and storage and processing alternatives for olap. Data Engineering Bulletin, 20:3{11, 1997.
[9] J. Gray, A. Bosworth, A. Layman, and H. Pirahesh. Data cube: A relational operator generalizing group-by,
cross-tab and sub-totals. In Proc. 1996 Int. Conf. Data Engineering, pages 152{159, New Orleans, Louisiana,
Feb. 1996.
[10] J. Gray, S. Chaudhuri, A. Bosworth, A. Layman, D. Reichart, M. Venkatrao, F. Pellow, and H. Pirahesh.
Data cube: A relational aggregation operator generalizing group-by, cross-tab and sub-totals. Data Mining and
Knowledge Discovery, 1:29{54, 1997.
[11] J. Han, Y. Fu, W. Wang, J. Chiang, W. Gong, K. Koperski, D. Li, Y. Lu, A. Rajan, N. Stefanovic, B. Xia, and
O. R. Zaane. DBMiner: A system for mining knowledge in large relational databases. In Proc. 1996 Int. Conf.
Data Mining and Knowledge Discovery (KDD'96), pages 250{255, Portland, Oregon, August 1996.
[12] J. Han, Y. J. Tam, E. Kim, H. Zhu, and S. H. S. Chee. Methodologies for integration of data mining and on-line
analytical processing in data warehouses. In submitted to DAMI, 1999.
[13] V. Harinarayan, A. Rajaraman, and J. D. Ullman. Implementing data cubes eciently. In Proc. 1996 ACMSIGMOD Int. Conf. Management of Data, pages 205{216, Montreal, Canada, June 1996.
[14] T. Imielinski, A. Virmani, and A. Abdulghani. DataMine { application programming interface and query
language for KDD applications. In Proc. 1996 Int. Conf. Data Mining and Knowledge Discovery (KDD'96),
pages 256{261, Portland, Oregon, August 1996.
[15] W. H. Inmon. Building the Data Warehouse. QED Technical Publishing Group, Wellesley, Massachusetts, 1992.
[16] R. Kimball. The Data Warehouse Toolkit. John Wiley & Sons, New York, 1996.
45
46
BIBLIOGRAPHY
[17] R. Meo, G. Psaila, and S. Ceri. A new SQL-like operator for mining association rules. In Proc. 1996 Int. Conf.
Very Large Data Bases, pages 122{133, Bombay, India, Sept. 1996.
[18] P. O'Neil and G. Graefe. Multi-table joins through bitmapped join indices. SIGMOD Record, 24:8{11, September
1995.
[19] K. Ross and D. Srivastava. Fast computation of sparse datacubes. In Proc. 1997 Int. Conf. Very Large Data
Bases, pages 116{125, Athens, Greece, Aug. 1997.
[20] K. A. Ross, D. Srivastava, and D. Chatziantoniou. Complex aggregation at multiple granularities. In Proc. Int.
Conf. of Extending Database Technology (EDBT'98), pages 263{277, Valencia, Spain, March 1998.
[21] S. Sarawagi, R. Agrawal, and N. Megiddo. Discovery-driven exploration of OLAP data cubes. In Proc. Int.
Conf. of Extending Database Technology (EDBT'98), pages 168{182, Valencia, Spain, March 1998.
[22] S. Sarawagi and M. Stonebraker. Ecient organization of large multidimensional arrays. In Proc. 1994 Int.
Conf. Data Engineering, pages 328{336, Feb. 1994.
[23] D. Sristava, S. Dar, H. V. Jagadish, and A. V. Levy. Answering queries with aggregation using views. In Proc.
1996 Int. Conf. Very Large Data Bases, pages 318{329, Bombay, India, September 1996.
[24] E. Thomsen. OLAP Solutions: Building Multidimensional Information Systems. John Wiley & Sons, 1997.
[25] P. Valduriez. Join indices. In ACM Trans. Database System, volume 12, pages 218{246, 1987.
[26] J. Widom. Research problems in data warehousing. In Proc. 4th Int. Conf. Information and Knowledge Management, pages 25{30, Baltimore, Maryland, Nov. 1995.
[27] Y. Zhao, P. M. Deshpande, and J. F. Naughton. An array-based algorithm for simultaneous multidimensional
aggregates. In Proc. 1997 ACM-SIGMOD Int. Conf. Management of Data, pages 159{170, Tucson, Arizona,
May 1997.
Contents
3 Data Preprocessing
3.1 Why preprocess the data? . . . . . . . . . . . . . . . . . . . . . . . . . .
3.2 Data cleaning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.2.1 Missing values . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.2.2 Noisy data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.2.3 Inconsistent data . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.3 Data integration and transformation . . . . . . . . . . . . . . . . . . . .
3.3.1 Data integration . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.3.2 Data transformation . . . . . . . . . . . . . . . . . . . . . . . . .
3.4 Data reduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.4.1 Data cube aggregation . . . . . . . . . . . . . . . . . . . . . . . .
3.4.2 Dimensionality reduction . . . . . . . . . . . . . . . . . . . . . .
3.4.3 Data compression . . . . . . . . . . . . . . . . . . . . . . . . . .
3.4.4 Numerosity reduction . . . . . . . . . . . . . . . . . . . . . . . .
3.5 Discretization and concept hierarchy generation . . . . . . . . . . . . . .
3.5.1 Discretization and concept hierarchy generation for numeric data
3.5.2 Concept hierarchy generation for categorical data . . . . . . . . .
3.6 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
3
3
5
5
6
7
8
8
8
10
10
11
13
14
19
19
23
25
2
CONTENTS
September 7, 1999
Chapter 3
Data Preprocessing
Today's real-world databases are highly susceptible to noise, missing, and inconsistent data due to their typically
huge size, often several gigabytes or more. How can the data be preprocessed in order to help improve the quality of
the data, and consequently, of the mining results? How can the data be preprocessed so as to improve the eciency
and ease of the mining process?
There are a number of data preprocessing techniques. Data cleaning can be applied to remove noise and correct
inconsistencies in the data. Data integration merges data from multiple sources into a coherent data store, such
as a data warehouse or a data cube. Data transformations, such as normalization, may be applied. For example,
normalization may improve the accuracy and eciency of mining algorithms involving distance measurements. Data
reduction can reduce the data size by aggregating, eliminating redundant features, or clustering, for instance. These
data processing techniques, when applied prior to mining, can substantially improve the overall data mining results.
In this chapter, you will learn methods for data preprocessing. These methods are organized into the following
categories: data cleaning, data integration and transformation, and data reduction. The use of concept hierarchies
for data discretization, an alternative form of data reduction, is also discussed. Concept hierarchies can be further
used to promote mining at multiple levels of abstraction. You will study how concept hierarchies can be generated
automatically from the given data.
3.1 Why preprocess the data?
Imagine that you are a manager at AllElectronics and have been charged with analyzing the company's data with
respect to the sales at your branch. You immediately set out to perform this task. You carefully study/inspect
the company's database or data warehouse, identifying and selecting the attributes or dimensions to be included
in your analysis, such as item, price, and units sold. Alas! You note that several of the attributes for various
tuples have no recorded value. For your analysis, you would like to include information as to whether each item
purchased was advertised as on sale, yet you discover that this information has not been recorded. Furthermore,
users of your database system have reported errors, unusual values, and inconsistencies in the data recorded for some
transactions. In other words, the data you wish to analyze by data mining techniques are incomplete (lacking
attribute values or certain attributes of interest, or containing only aggregate data), noisy (containing errors, or
outlier values which deviate from the expected), and inconsistent (e.g., containing discrepancies in the department
codes used to categorize items). Welcome to the real world!
Incomplete, noisy, and inconsistent data are commonplace properties of large, real-world databases and data
warehouses. Incomplete data can occur for a number of reasons. Attributes of interest may not always be available,
such as customer information for sales transaction data. Other data may not be included simply because it was
not considered important at the time of entry. Relevant data may not be recorded due to a misunderstanding, or
because of equipment malfunctions. Data that were inconsistent with other recorded data may have been deleted.
Furthermore, the recording of the history or modications to the data may have been overlooked. Missing data,
particularly for tuples with missing values for some attributes, may need to be inferred.
Data can be noisy, having incorrect attribute values, owing to the following. The data collection instruments used
3
4
CHAPTER 3. DATA PREPROCESSING
may be faulty. There may have been human or computer errors occurring at data entry. Errors in data transmission
can also occur. There may be technology limitations, such as limited buer size for coordinating synchronized data
transfer and consumption. Incorrect data may also result from inconsistencies in naming conventions or data codes
used. Duplicate tuples also require data cleaning.
Data cleaning routines work to \clean" the data by lling in missing values, smoothing noisy data, identifying or
removing outliers, and resolving inconsistencies. Dirty data can cause confusion for the mining procedure. Although
most mining routines have some procedures for dealing with incomplete or noisy data, they are not always robust.
Instead, they may concentrate on avoiding overtting the data to the function being modeled. Therefore, a useful
preprocessing step is to run your data through some data cleaning routines. Section 3.2 discusses methods for
\cleaning" up your data.
Getting back to your task at AllElectronics, suppose that you would like to include data from multiple sources in
your analysis. This would involve integrating multiple databases, data cubes, or les, i.e., data integration. Yet
some attributes representing a given concept may have dierent names in dierent databases, causing inconsistencies
and redundancies. For example, the attribute for customer identication may be referred to as customer id is one
data store, and cust id in another. Naming inconsistencies may also occur for attribute values. For example, the
same rst name could be registered as \Bill" in one database, but \William" in another, and \B." in the third.
Furthermore, you suspect that some attributes may be \derived" or inferred from others (e.g., annual revenue).
Having a large amount of redundant data may slow down or confuse the knowledge discovery process. Clearly, in
addition to data cleaning, steps must be taken to help avoid redundancies during data integration. Typically, data
cleaning and data integration are performed as a preprocessing step when preparing the data for a data warehouse.
Additional data cleaning may be performed to detect and remove redundancies that may have resulted from data
integration.
Getting back to your data, you have decided, say, that you would like to use a distance-based mining algorithm
for your analysis, such as neural networks, nearest neighbor classiers, or clustering. Such methods provide better
results if the data to be analyzed have been normalized, that is, scaled to a specic range such as [0, 1.0]. Your
customer data, for example, contains the attributes age, and annual salary. The annual salary attribute can take
many more values than age. Therefore, if the attributes are left un-normalized, then distance measurements taken
on annual salary will generally outweigh distance measurements taken on age. Furthermore, it would be useful for
your analysis to obtain aggregate information as to the sales per customer region | something which is not part of
any precomputed data cube in your data warehouse. You soon realize that data transformation operations, such
as normalization and aggregation, are additional data preprocessing procedures that would contribute towards the
success of the mining process. Data integration and data transformation are discussed in Section 3.3.
\Hmmm", you wonder, as you consider your data even further. \The data set I have selected for analysis is
huge | it is sure to slow or wear down the mining process. Is there any way I can `reduce' the size of my data set,
without jeopardizing the data mining results?" Data reduction obtains a reduced representation of the data set
that is much smaller in volume, yet produces the same (or almost the same) analytical results. There are a number
of strategies for data reduction. These include data aggregation (e.g., building a data cube), dimension reduction
(e.g., removing irrelevant attributes through correlation analysis), data compression (e.g., using encoding schemes
such as minimum length encoding or wavelets), and numerosity reduction (e.g., \replacing" the data by alternative,
smaller representations such as clusters, or parametric models). Data can also be \reduced" by generalization,
where low level concepts such as city for customer location, are replaced with higher level concepts, such as region
or province or state. A concept hierarchy is used to organize the concepts into varying levels of abstraction. Data
reduction is the topic of Section 3.4. Since concept hierarchies are so useful in mining at multiple levels of abstraction,
we devote a separate section to the automatic generation of this important data structure. Section 3.5 discusses
concept hierarchy generation, a form of data reduction by data discretization.
Figure 3.1 summarizes the data preprocessing steps described here. Note that the above categorization is not
mutually exclusive. For example, the removal of redundant data may be seen as a form of data cleaning, as well as
data reduction.
In summary, real world data tend to be dirty, incomplete, and inconsistent. Data preprocessing techniques can
improve the quality of the data, thereby helping to improve the accuracy and eciency of the subsequent mining
process. Data preprocessing is therefore an important step in the knowledge discovery process, since quality decisions
must be based on quality data. Detecting data anomalies, rectifying them early, and reducing the data to be analyzed
can lead to huge pay-os for decision making.
3.2. DATA CLEANING
Data Cleaning
5
[water to clean dirty-looking data]
[‘clean’-looking data]
[show soap suds on data]
Data Integration
Data Transformation
-2, 32, 100, 59, 48
A1
Data Reduction
A2
A3
-0.02, 0.32, 1.00, 0.59, 0.48
... A126
T1
T2
T3
A1
A3
...
A115
T1
T4
...
T1456
T4
...
T2000
Figure 3.1: Forms of data preprocessing.
3.2 Data cleaning
Real-world data tend to be incomplete, noisy, and inconsistent. Data cleaning routines attempt to ll in missing
values, smooth out noise while identifying outliers, and correct inconsistencies in the data. In this section, you will
study basic methods for data cleaning.
3.2.1 Missing values
Imagine that you need to analyze AllElectronics sales and customer data. You note that many tuples have no
recorded value for several attributes, such as customer income. How can you go about lling in the missing values
for this attribute? Let's look at the following methods.
1. Ignore the tuple: This is usually done when the class label is missing (assuming the mining task involves
classication or description). This method is not very eective, unless the tuple contains several attributes with
missing values. It is especially poor when the percentage of missing values per attribute varies considerably.
2. Fill in the missing value manually: In general, this approach is time-consuming and may not be feasible
given a large data set with many missing values.
3. Use a global constant to ll in the missing value: Replace all missing attribute values by the same
constant, such as a label like \Unknown", or ,1. If missing values are replaced by, say, \Unknown", then the
mining program may mistakenly think that they form an interesting concept, since they all have a value in
common | that of \Unknown". Hence, although this method is simple, it is not recommended.
4. Use the attribute mean to ll in the missing value: For example, suppose that the average income of
AllElectronics customers is $28,000. Use this value to replace the missing value for income.
5. Use the attribute mean for all samples belonging to the same class as the given tuple: For example,
if classifying customers according to credit risk, replace the missing value with the average income value for
CHAPTER 3. DATA PREPROCESSING
6
Sorted data for price (in dollars): 4, 8, 15, 21, 21, 24, 25, 28, 34
Partition into (equi-width) bins:
{ Bin 1: 4, 8, 15
{ Bin 2: 21, 21, 24
{ Bin 3: 25, 28, 34
Smoothing by bin means:
{ Bin 1: 9, 9, 9,
{ Bin 2: 22, 22, 22
{ Bin 3: 29, 29, 29
Smoothing by bin boundaries:
{ Bin 1: 4, 4, 15
{ Bin 2: 21, 21, 24
{ Bin 3: 25, 25, 34
Figure 3.2: Binning methods for data smoothing.
customers in the same credit risk category as that of the given tuple.
6. Use the most probable value to ll in the missing value: This may be determined with inference-based
tools using a Bayesian formalism or decision tree induction. For example, using the other customer attributes
in your data set, you may construct a decision tree to predict the missing values for income. Decision trees are
described in detail in Chapter 7.
Methods 3 to 6 bias the data. The lled-in value may not be correct. Method 6, however, is a popular strategy.
In comparison to the other methods, it uses the most information from the present data to predict missing values.
3.2.2 Noisy data
\What is noise?" Noise is a random error or variance in a measured variable. Given a numeric attribute such
as, say, price, how can we \smooth" out the data to remove the noise? Let's look at the following data smoothing
techniques.
1. Binning methods: Binning methods smooth a sorted data value by consulting the \neighborhood", or
values around it. The sorted values are distributed into a number of `buckets', or bins. Because binning
methods consult the neighborhood of values, they perform local smoothing. Figure 3.2 illustrates some binning
techniques. In this example, the data for price are rst sorted and partitioned into equi-depth bins (of depth 3).
In smoothing by bin means, each value in a bin is replaced by the mean value of the bin. For example, the
mean of the values 4, 8, and 15 in Bin 1 is 9. Therefore, each original value in this bin is replaced by the value
9. Similarly, smoothing by bin medians can be employed, in which each bin value is replaced by the bin
median. In smoothing by bin boundaries, the minimum and maximum values in a given bin are identied
as the bin boundaries. Each bin value is then replaced by the closest boundary value. In general, the larger the
width, the greater the eect of the smoothing. Alternatively, bins may be equi-width, where the interval range
of values in each bin is constant. Binning is also used as a discretization technique and is further discussed in
Section 3.5, and in Chapter 6 on association rule mining.
2. Clustering: Outliers may be detected by clustering, where similar values are organized into groups or \clusters". Intuitively, values which fall outside of the set of clusters may be considered outliers (Figure 3.3).
Chapter 9 is dedicated to the topic of clustering.
3.2. DATA CLEANING
7
+
+
+
Figure 3.3: Outliers may be detected by clustering analysis.
3. Combined computer and human inspection: Outliers may be identied through a combination of computer and human inspection. In one application, for example, an information-theoretic measure was used to
help identify outlier patterns in a handwritten character database for classication. The measure's value reected the \surprise" content of the predicted character label with respect to the known label. Outlier patterns
may be informative (e.g., identifying useful data exceptions, such as dierent versions of the characters \0"
or \7"), or \garbage" (e.g., mislabeled characters). Patterns whose surprise content is above a threshold are
output to a list. A human can then sort through the patterns in the list to identify the actual garbage ones.
This is much faster than having to manually search through the entire database. The garbage patterns can
then be removed from the (training) database.
4. Regression: Data can be smoothed by tting the data to a function, such as with regression. Linear regression
involves nding the \best" line to t two variables, so that one variable can be used to predict the other. Multiple
linear regression is an extension of linear regression, where more than two variables are involved and the data
are t to a multidimensional surface. Using regression to nd a mathematical equation to t the data helps
smooth out the noise. Regression is further described in Section 3.4.4, as well as in Chapter 7.
Many methods for data smoothing are also methods of data reduction involving discretization. For example,
the binning techniques described above reduce the number of distinct values per attribute. This acts as a form
of data reduction for logic-based data mining methods, such as decision tree induction, which repeatedly make
value comparisons on sorted data. Concept hierarchies are a form of data discretization which can also be used
for data smoothing. A concept hierarchy for price, for example, may map price real values into \inexpensive",
\moderately priced", and \expensive", thereby reducing the number of data values to be handled by the mining
process. Data discretization is discussed in Section 3.5. Some methods of classication, such as neural networks,
have built-in data smoothing mechanisms. Classication is the topic of Chapter 7.
3.2.3 Inconsistent data
There may be inconsistencies in the data recorded for some transactions. Some data inconsistencies may be corrected
manually using external references. For example, errors made at data entry may be corrected by performing a
paper trace. This may be coupled with routines designed to help correct the inconsistent use of codes. Knowledge
engineering tools may also be used to detect the violation of known data constraints. For example, known functional
dependencies between attributes can be used to nd values contradicting the functional constraints.
There may also be inconsistencies due to data integration, where a given attribute can have dierent names in
dierent databases. Redundancies may also result. Data integration and the removal of redundant data are described
in Section 3.3.1.
CHAPTER 3. DATA PREPROCESSING
8
3.3 Data integration and transformation
3.3.1 Data integration
It is likely that your data analysis task will involve data integration, which combines data from multiple sources into
a coherent data store, as in data warehousing. These sources may include multiple databases, data cubes, or at
les.
There are a number of issues to consider during data integration. Schema integration can be tricky. How can
like real world entities from multiple data sources be `matched up'? This is referred to as the entity identication
problem. For example, how can the data analyst or the computer be sure that customer id in one database, and
cust number in another refer to the same entity? Databases and data warehouses typically have metadata - that is,
data about the data. Such metadata can be used to help avoid errors in schema integration.
Redundancy is another important issue. An attribute may be redundant if it can be \derived" from another
table, such as annual revenue. Inconsistencies in attribute or dimension naming can also cause redundancies in the
resulting data set.
Some redundancies can be detected by correlation analysis. For example, given two attributes, such analysis
can measure how strongly one attribute implies the other, based on the available data. The correlation between
attributes A and B can be measured by
P(A ^ B) :
P(A)P(B)
(3.1)
If the resulting value of Equation (3.1) is greater than 1, then A and B are positively correlated. The higher the
value, the more each attribute implies the other. Hence, a high value may indicate that A (or B) may be removed as
a redundancy. If the resulting value is equal to 1, then A and B are independent and there is no correlation between
them. If the resulting value is less than 1, then A and B are negatively correlated. This means that each attribute
discourages the other. Equation (3.1) may detect a correlation between the customer id and cust number attributes
described above. Correlation analysis is further described in Chapter 6 (Section 6.5.2 on mining correlation rules).
In addition to detecting redundancies between attributes, \duplication" should also be detected at the tuple level
(e.g., where there are two or more identical tuples for a given unique data entry case.
A third important issue in data integration is the detection and resolution of data value conicts. For example,
for the same real world entity, attribute values from dierent sources may dier. This may be due to dierences in
representation, scaling, or encoding. For instance, a weight attribute may be stored in metric units in one system,
and British imperial units in another. The price of dierent hotels may involve not only dierent currencies but also
dierent services (such as free breakfast) and taxes. Such semantic heterogeneity of data poses great challenges in
data integration.
Careful integration of the data from multiple sources can help reduce and avoid redundancies and inconsistencies
in the resulting data set. This can help improve the accuracy and speed of the subsequent mining process.
3.3.2 Data transformation
In data transformation, the data are transformed or consolidated into forms appropriate for mining. Data transformation can involve the following:
1. Normalization, where the attribute data are scaled so as to fall within a small specied range, such as -1.0
to 1.0, or 0 to 1.0.
2. Smoothing, which works to remove the noise from data. Such techniques include binning, clustering, and
regression.
3. Aggregation, where summary or aggregation operations are applied to the data. For example, the daily sales
data may be aggregated so as to compute monthly and annual total amounts. This step is typically used in
constructing a data cube for analysis of the data at multiple granularities.
3.3. DATA INTEGRATION AND TRANSFORMATION
9
4. Generalization of the data, where low level or `primitive' (raw) data are replaced by higher level concepts
through the use of concept hierarchies. For example, categorical attributes, like street, can be generalized to
higher level concepts, like city or county. Similarly, values for numeric attributes, like age, may be mapped to
higher level concepts, like young, middle-aged, and senior.
In this section, we discuss normalization. Smoothing is a form of data cleaning, and was discussed in Section 3.2.2.
Aggregation and generalization also serve as forms of data reduction, and are discussed in Sections 3.4 and 3.5,
respectively.
An attribute is normalized by scaling its values so that they fall within a small specied range, such as 0 to 1.0.
Normalization is particularly useful for classication algorithms involving neural networks, or distance measurements
such as nearest-neighbor classication and clustering. If using the neural network backpropagation algorithm for
classication mining (Chapter 7), normalizing the input values for each attribute measured in the training samples
will help speed up the learning phase. For distance-based methods, normalization helps prevent attributes with
initially large ranges (e.g., income) from outweighing attributes with initially smaller ranges (e.g., binary attributes).
There are many methods for data normalization. We study three: min-max normalization, z-score normalization,
and normalization by decimal scaling.
Min-max normalization performs a linear transformation on the original data. Suppose that minA and maxA
are the minimum and maximum values of an attribute A. Min-max normalization maps a value v of A to v0 in the
range [new minA ; new maxA ] by computing
v , minA (new max , new min ) + new min :
v0 = max
A
A
A
, min
A
(3.2)
A
Min-max normalization preserves the relationships among the original data values. It will encounter an \out of
bounds" error if a future input case for normalization falls outside of the original data range for A.
Example 3.1 Suppose that the maximum and minimum values for the attribute income are $98,000 and $12,000,
respectively. We would like to map income to the range [0; 1]. By min-max normalization, a value of $73,600 for
;600,12;000
2
income is transformed to 73
98;000,12;000(1 , 0) + 0 = 0:716.
In z-score normalization (or zero-mean normalization), the values for an attribute A are normalized based on
the mean and standard deviation of A. A value v of A is normalized to v0 by computing
v , meanA
v0 = stand
dev
(3.3)
A
where meanA and stand devA are the mean and standard deviation, respectively, of attribute A. This method of
normalization is useful when the actual minimum and maximum of attribute A are unknown, or when there are
outliers which dominate the min-max normalization.
Example 3.2 Suppose that the mean and standard deviation of the values for the attribute income are
$54,000 and
73;600,54;000
$16,000, respectively. With z-score normalization, a value of $73,600 for income is transformed to
1:225.
16;000
=
2
Normalization by decimal scaling normalizes by moving the decimal point of values of attribute A. The
number of decimal points moved depends on the maximum absolute value of A. A value v of A is normalized to v0
by computing
v0 = 10v j ;
(3.4)
where j is the smallest integer such that Max(jv0 j) < 1.
Example 3.3 Suppose that the recorded values of A range from ,986 to 917. The maximum absolute value of A is
986. To normalize by decimal scaling, we therefore divide each value by 1,000 (i.e., j = 3) so that ,986 normalizes
to ,0:986.
2
CHAPTER 3. DATA PREPROCESSING
10
Note that normalization can change the original data quite a bit, especially the latter two of the methods shown
above. It is also necessary to save the normalization parameters (such as the mean and standard deviation if using
z-score normalization) so that future data can be normalized in a uniform manner.
3.4 Data reduction
Imagine that you have selected data from the AllElectronics data warehouse for analysis. The data set will likely be
huge! Complex data analysis and mining on huge amounts of data may take a very long time, making such analysis
impractical or infeasible. Is there any way to \reduce" the size of the data set without jeopardizing the data mining
results?
Data reduction techniques can be applied to obtain a reduced representation of the data set that is much
smaller in volume, yet closely maintains the integrity of the original data. That is, mining on the reduced data set
should be more ecient yet produce the same (or almost the same) analytical results.
Strategies for data reduction include the following.
1. Data cube aggregation, where aggregation operations are applied to the data in the construction of a data
cube.
2. Dimension reduction, where irrelevant, weakly relevant, or redundant attributes or dimensions may be
detected and removed.
3. Data compression, where encoding mechanisms are used to reduce the data set size.
4. Numerosity reduction, where the data are replaced or estimated by alternative, smaller data representations
such as parametric models (which need store only the model parameters instead of the actual data), or nonparametric methods such as clustering, sampling, and the use of histograms.
5. Discretization and concept hierarchy generation, where raw data values for attributes are replaced
by ranges or higher conceptual levels. Concept hierarchies allow the mining of data at multiple levels of
abstraction, and are a powerful tool for data mining. We therefore defer the discussion of automatic concept
hierarchy generation to Section 3.5 which is devoted entirely to this topic.
Strategies 1 to 4 above are discussed in the remainder of this section. The computational time spent on data
reduction should not outweight or \erase" the time saved by mining on a reduced data set size.
3.4.1 Data cube aggregation
Imagine that you have collected the data for your analysis. These data consist of the AllElectronics sales per quarter,
for the years 1997 to 1999. You are, however, interested in the annual sales (total per year), rather than the total
per quarter. Thus the data can be aggregated so that the resulting data summarize the total sales per year instead of
per quarter. This aggregation is illustrated in Figure 3.4. The resulting data set is smaller in volume, without loss
of information necessary for the analysis task.
Data cubes were discussed in Chapter 2. For completeness, we briefely review some of that material here. Data
cubes store multidimensionalaggregated information. For example, Figure 3.5 shows a data cube for multidimensional
analysis of sales data with respect to annual sales per item type for each AllElectronics branch. Each cells holds
an aggregate data value, corresponding to the data point in multidimensional space. Concept hierarchies may exist
for each attribute, allowing the analysis of data at multiple levels of abstraction. For example, a hierarchy for
branch could allow branches to be grouped into regions, based on their address. Data cubes provide fast access to
precomputed, summarized data, thereby beneting on-line analytical processing as well as data mining.
The cube created at the lowest level of abstraction is referred to as the base cuboid. A cube for the highest level
of abstraction is the apex cuboid. For the sales data of Figure 3.5, the apex cuboid would give one total | the total
sales for all three years, for all item types, and for all branches. Data cubes created for varying levels of abstraction
are sometimes referred to as cuboids, so that a \data cube" may instead refer to a lattice of cuboids. Each higher
level of abstraction further reduces the resulting data size.
3.4. DATA REDUCTION
11
Year = 1999
Year = 1998
Year=1997
Quarter
Sales
Q1
Q2
Q3
Q4
$224,000
$408,000
$350,000
$586,000
Year
Sales
1997
1998
1999
$1,568,000
$2,356,000
$3,594,000
Figure 3.4: Sales data for a given branch of AllElectronics for the years 1997 to 1999. In the data on the left, the
sales are shown per quarter. In the data on the right, the data are aggregated to provide the annual sales.
Branch
A
Item
type
D
B
C
home
entertainment
computer
phone
security
1997 1998 1999
Year
Figure 3.5: A data cube for sales at AllElectronics.
The base cuboid should correspond to an individual entity of interest, such as sales or customer. In other words,
the lowest level should be \usable", or useful for the analysis. Since data cubes provide fast accessing to precomputed,
summarized data, they should be used when possible to reply to queries regarding aggregated information. When
replying to such OLAP queries or data mining requests, the smallest available cuboid relevant to the given task
should be used. This issue is also addressed in Chapter 2.
3.4.2 Dimensionality reduction
Data sets for analysis may contain hundreds of attributes, many of which may be irrelevant to the mining task, or
redundant. For example, if the task is to classify customers as to whether or not they are likely to purchase a popular
new CD at AllElectronics when notied of a sale, attributes such as the customer's telephone number are likely to be
irrelevant, unlike attributes such as age or music taste. Although it may be possible for a domain expert to pick out
some of the useful attributes, this can be a dicult and time-consuming task, especially when the behavior of the
data is not well-known (hence, a reason behind its analysis!). Leaving out relevant attributes, or keeping irrelevant
attributes may be detrimental, causing confusion for the mining algorithm employed. This can result in discovered
patterns of poor quality. In addition, the added volume of irrelevant or redundant attributes can slow down the
mining process.
CHAPTER 3. DATA PREPROCESSING
12
Forward Selection
Backward Elimination
Decision Tree Induction
Initial attribute set:
{A1, A2, A3, A4, A5, A6}
Initial attribute set:
{A1, A2, A3, A4, A5, A6}
Initial attribute set:
{A1, A2, A3, A4, A5, A6}
Initial reduced set:
{}
-> {A1}
--> {A1, A4}
---> Reduced attribute set:
{A1, A4, A6}
-> {A1, A3, A4, A5, A6}
--> {A1, A4, A5, A6}
---> Reduced attribute set:
{A1, A4, A6}
A4?
Y
Class1
Y
N
A1?
A6?
N
Class2
Y
N
Class1
Class2
---> Reduced attribute set:
{A1, A4, A6}
Figure 3.6: Greedy (heuristic) methods for attribute subset selection.
Dimensionality reduction reduces the data set size by removing such attributes (or dimensions) from it. Typically,
methods of attribute subset selection are applied. The goal of attribute subset selection is to nd a minimum set
of attributes such that the resulting probability distribution of the data classes is as close as possible to the original
distribution obtained using all attributes. Mining on a reduced set of attributes has an additional benet. It reduces
the number of attributes appearing in the discovered patterns, helping to make the patterns easier to understand.
\How can we nd a `good' subset of the original attributes?" There are 2d possible subsets of d attributes. An
exhaustive search for the optimal subset of attributes can be prohibitively expensive, especially as d and the number
of data classes increase. Therefore, heuristic methods which explore a reduced search space are commonly used for
attribute subset selection. These methods are typically greedy in that, while searching through attribute space, they
always make what looks to be the best choice at the time. Their strategy is to make a locally optimal choice in the
hope that this will lead to a globally optimal solution. Such greedy methods are eective in practice, and may come
close to estimating an optimal solution.
The `best' (and `worst') attributes are typically selected using tests of statistical signicance, which assume that
the attributes are independent of one another. Many other attribute evaluation measures can be used, such as the
information gain measure used in building decision trees for classication1.
Basic heuristic methods of attribute subset selection include the following techniques, some of which are illustrated
in Figure 3.6.
1. Step-wise forward selection: The procedure starts with an empty set of attributes. The best of the original
attributes is determined and added to the set. At each subsequent iteration or step, the best of the remaining
original attributes is added to the set.
2. Step-wise backward elimination: The procedure starts with the full set of attributes. At each step, it
removes the worst attribute remaining in the set.
3. Combination forward selection and backward elimination: The step-wise forward selection and backward elimination methods can be combined, where at each step one selects the best attribute and removes the
worst from among the remaining attributes.
The stopping criteria for methods 1 to 3 may vary. The procedure may employ a threshold on the measure used
to determine when to stop the attribute selection process.
4. Decision tree induction: Decision tree algorithms, such as ID3 and C4.5, were originally intended for
classication. Decision tree induction constructs a ow-chart-like structure where each internal (non-leaf) node
denotes a test on an attribute, each branch corresponds to an outcome of the test, and each external (leaf)
1
The information gain measure is described in Chapters 5 and 7.
3.4. DATA REDUCTION
13
node denotes a class prediction. At each node, the algorithm chooses the \best" attribute to partition the data
into individual classes.
When decision tree induction is used for attribute subset selection, a tree is constructed from the given data.
All attributes that do not appear in the tree are assumed to be irrelevant. The set of attributes appearing in
the tree form the reduced subset of attributes. This method of attribute selection is visited again in greater
detail in Chapter 5 on concept description.
3.4.3 Data compression
In data compression, data encoding or transformations are applied so as to obtain a reduced or \compressed"
representation of the original data. If the original data can be reconstructed from the compressed data without any
loss of information, the data compression technique used is called lossless. If, instead, we can reconstruct only an
approximation of the original data, then the data compression technique is called lossy. There are several well-tuned
algorithms for string compression. Although they are typically lossless, they allow only limited manipulation of the
data. In this section, we instead focus on two popular and eective methods of lossy data compression: wavelet
transforms, and principal components analysis.
Wavelet transforms
The discrete wavelet transform (DWT) is a linear signal processing technique that, when applied to a data
vector D, transforms it to a numerically dierent vector, D0 , of wavelet coecients. The two vectors are of the
same length.
\Hmmm", you wonder. \How can this technique be useful for data reduction if the wavelet transformed data are
of the same length as the original data?" The usefulness lies in the fact that the wavelet transformed data can be
truncated. A compressed approximation of the data can be retained by storing only a small fraction of the strongest
of the wavelet coecients. For example, all wavelet coecients larger than some user-specied threshold can be
retained. The remaining coecients are set to 0. The resulting data representation is therefore very sparse, so that
operations that can take advantage of data sparsity are computationally very fast if performed in wavelet space.
The DWT is closely related to the discrete Fourier transform (DFT), a signal processing technique involving
sines and cosines. In general, however, the DWT achieves better lossy compression. That is, if the same number
of coecients are retained for a DWT and a DFT of a given data vector, the DWT version will provide a more
accurate approximation of the original data. Unlike DFT, wavelets are quite localized in space, contributing to the
conservation of local detail.
There is only one DFT, yet there are several DWTs. The general algorithm for a discrete wavelet transform is
as follows.
1. The length, L, of the input data vector must be an integer power of two. This condition can be met by padding
the data vector with zeros, as necessary.
2. Each transform involves applying two functions. The rst applies some data smoothing, such as a sum or
weighted average. The second performs a weighted dierence.
3. The two functions are applied to pairs of the input data, resulting in two sets of data of length L=2. In general,
these respectively represent a smoothed version of the input data, and the high-frequency content of it.
4. The two functions are recursively applied to the sets of data obtained in the previous loop, until the resulting
data sets obtained are of desired length.
5. A selection of values from the data sets obtained in the above iterations are designated the wavelet coecients
of the transformed data.
Equivalently, a matrix multiplication can be applied to the input data in order to obtain the wavelet coecients.
For example, given an input vector of length 4 (represented as the column vector [x0; x1; x2; x3]), the 4-point Haar
CHAPTER 3. DATA PREPROCESSING
14
transform of the vector can be obtained by the following matrix multiplication:
2
1=2
1=2
1=2
66 1=2
1=2
,
1=2
4 1=p2 ,1=p2 0p
3 2
3
1=2
x0
,1=2 77 66 x1 77
(3.5)
0p 5 4 x2 5
x3
0
0
1= 2 ,1= 2
The matrix on the left is orthonormal, meaning that the columns are unit vectors (multiplied by a constant) and are
mutually orthogonal, so that the matrix inverse is just its transpose. Although we do not have room to discuss
it here, this property allows the reconstruction of the data from the smooth and smooth-dierence data sets. Other
popular wavelet transforms include the Daubechies-4 and the Daubechies-6 transforms.
Wavelet transforms can be applied to multidimensional data, such as a data cube. This is done by rst applying
the transform to the rst dimension, then to the second, and so on. The computational complexity involved is linear
with respect to the number of cells in the cube. Wavelet transforms give good results on sparse or skewed data, and
data with ordered attributes.
Principal components analysis
Herein, we provide an intuitive introduction to principal components analysis as a method of data compression. A
detailed theoretical explanation is beyond the scope of this book.
Suppose that the data to be compressed consists of N tuples or data vectors, from k-dimensions. Principal
components analysis (PCA) searches for c k-dimensional orthogonal vectors that can best be used to represent
the data, where c << N. The original data is thus projected onto a much smaller space, resulting in data compression.
PCA can be used as a form of dimensionality reduction. However, unlike attribute subset selection, which reduces
the attribute set size by retaining a subset of the initial set of attributes, PCA \combines" the essence of attributes
by creating an alternative, smaller set of variables. The initial data can then be projected onto this smaller set.
The basic procedure is as follows.
1. The input data are normalized, so that each attribute falls within the same range. This step helps ensure that
attributes with large domains will not dominate attributes with smaller domains.
2. PCA computes N orthonormal vectors which provide a basis for the normalized input data. These are unit
vectors that each point in a direction perpendicular to the others. These vectors are referred to as the principal
components. The input data are a linear combination of the principal components.
3. The principal components are sorted in order of decreasing \signicance" or strength. The principal components
essentially serve as a new set of axes for the data, providing important information about variance. That is,
the sorted axes are such that the rst axis shows the most variance among the data, the second axis shows the
next highest variance, and so on. This information helps identify groups or patterns within the data.
4. Since the components are sorted according to decreasing order of \signicance", the size of the data can be
reduced by eliminating the weaker components, i.e., those with low variance. Using the strongest principal
components, it should be possible to reconstruct a good approximation of the original data.
PCA can be applied to ordered and unordered attributes, and can handle sparse data and skewed data. Multidimensional data of more than two dimensions can be handled by reducing the problem to two dimensions. For
example, a 3-D data cube for sales with the dimensions item type, branch, and year must rst be reduced to a 2-D
cube, such as with the dimensions item type, and branch year.
3.4.4 Numerosity reduction
\Can we reduce the data volume by choosing alternative, `smaller' forms of data representation?" Techniques of numerosity reduction can indeed be applied for this purpose. These techniques may be parametric or non-parametric.
For parametric methods, a model is used to estimate the data, so that typically only the data parameters need be
stored, instead of the actual data. (Outliers may also be stored). Log-linear models, which estimate discrete multidimensional probability distributions, are an example. Non-parametric methods for storing reduced representations
of the data include histograms, clustering, and sampling.
3.4. DATA REDUCTION
15
count
10
9
8
7
6
5
4
3
2
1
5
10
15
20
25
30
price
Figure 3.7: A histogram for price using singleton buckets - each bucket represents one price-value/frequency pair.
Let's have a look at each of the numerosity reduction techniques mentioned above.
Regression and log-linear models
Regression and log-linear models can be used to approximate the given data. In linear regression, the data are
modeled to t a straight line. For example, a random variable, Y (called a response variable), can be modeled as a
linear function of another random variable, X (called a predictor variable), with the equation
Y = + X;
(3.6)
where the variance of Y is assumed to be constant. The coecients and (called regression coecients) specify
the Y -intercept and slope of the line, respectively. These coecients can be solved for by the method of least squares,
which minimizes the error between the actual line separating the data and the estimate of the line. Multiple
regression is an extension of linear regression allowing a response variable Y to be modeled as a linear function of
a multidimensional feature vector.
Log-linear models approximate discrete multidimensional probability distributions. The method can be used to
estimate the probability of each cell in a base cuboid for a set of discretized attributes, based on the smaller cuboids
making up the data cube lattice. This allows higher order data cubes to be constructed from lower order ones.
Log-linear models are therefore also useful for data compression (since the smaller order cuboids together typically
occupy less space than the base cuboid) and data smoothing (since cell estimates in the smaller order cuboids are less
subject to sampling variations than cell estimates in the base cuboid). Regression and log-linear models are further
discussed in Chapter 7 (Section 7.8 on Prediction).
Histograms
Histograms use binning to approximate data distributions and are a popular form of data reduction. A histogram
for an attribute A partitions the data distribution of A into disjoint subsets, or buckets. The buckets are displayed
on a horizontal axis, while the height (and area) of a bucket typically reects the average frequency of the values
represented by the bucket. If each bucket represents only a single attribute-value/frequency pair, the buckets are
called singleton buckets. Often, buckets instead represent continuous ranges for the given attribute.
Example 3.4 The following data are a list of prices of commonly sold items at AllElectronics (rounded to the
nearest dollar). The numbers have been sorted.
1, 1, 5, 5, 5, 5, 5, 8, 8, 10, 10, 10, 10, 12, 14, 14, 14, 15, 15, 15, 15, 15, 15, 18, 18, 18, 18, 18, 18, 18, 18, 20, 20,
20, 20, 20, 20, 20, 21, 21, 21, 21, 25, 25, 25, 25, 25, 28, 28, 30, 30, 30.
CHAPTER 3. DATA PREPROCESSING
16
count
6
5
4
3
2
1
1-10
11-20
21-30
price
Figure 3.8: A histogram for price where values are aggregated so that each bucket has a uniform width of $10.
Figure 3.7 shows a histogram for the data using singleton buckets. To further reduce the data, it is common to
have each bucket denote a continuous range of values for the given attribute. In Figure 3.8, each bucket represents
a dierent $10 range for price.
2
How are the buckets determined and the attribute values partitioned? There are several partitioning rules,
including the following.
1. Equi-width: In an equi-width histogram, the width of each bucket range is constant (such as the width of
$10 for the buckets in Figure 3.8).
2. Equi-depth (or equi-height): In an equi-depth histogram, the buckets are created so that, roughly, the frequency of each bucket is constant (that is, each bucket contains roughly the same number of contiguous data
samples).
3. V-Optimal: If we consider all of the possible histograms for a given number of buckets, the V-optimal
histogram is the one with the least variance. Histogram variance is a weighted sum of the original values that
each bucket represents, where bucket weight is equal to the number of values in the bucket.
4. MaxDi: In a MaxDi histogram, we consider the dierence between each pair of adjacent values. A bucket
boundary is established between each pair for pairs having the , 1 largest dierences, where is user-specied.
V-Optimal and MaxDi histograms tend to be the most accurate and practical. Histograms are highly eective at approximating both sparse and dense data, as well as highly skewed, and uniform data. The histograms
described above for single attributes can be extended for multiple attributes. Multidimensional histograms can capture dependencies between attributes. Such histograms have been found eective in approximating data with up
to ve attributes. More studies are needed regarding the eectiveness of multidimensional histograms for very high
dimensions. Singleton buckets are useful for storing outliers with high frequency. Histograms are further described
in Chapter 5 (Section 5.6 on mining descriptive statistical measures in large databases).
Clustering
Clustering techniques consider data tuples as objects. They partition the objects into groups or clusters, so that
objects within a cluster are \similar" to one another and \dissimilar" to objects in other clusters. Similarity is
commonly dened in terms of how \close" the objects are in space, based on a distance function. The \quality" of a
cluster may be represented by its diameter, the maximum distance between any two objects in the cluster. Centroid
distance is an alternative measure of cluster quality, and is dened as the average distance of each cluster object
from the cluster centroid (denoting the \average object", or average point in space for the cluster). Figure 3.9 shows
3.4. DATA REDUCTION
17
+
+
+
Figure 3.9: A 2-D plot of customer data with respect to customer locations in a city, showing three data clusters.
Each cluster centroid is marked with a \+".
986
3396
5411
8392
9544
Figure 3.10: The root of a B+-tree for a given set of data.
a 2-D plot of customer data with respect to customer locations in a city, where the centroid of each cluster is shown
with a \+". Three data clusters are visible.
In data reduction, the cluster representations of the data are used to replace the actual data. The eectiveness
of this technique depends on the nature of the data. It is much more eective for data that can be organized into
distinct clusters, than for smeared data.
In database systems, multidimensional index trees are primarily used for providing fast data access. They can
also be used for hierarchical data reduction, providing a multiresolution clustering of the data. This can be used to
provide approximate answers to queries. An index tree recursively partitions the multidimensional space for a given
set of data objects, with the root node representing the entire space. Such trees are typically balanced, consisting of
internal and leaf nodes. Each parent node contains keys and pointers to child nodes that, collectively, represent the
space represented by the parent node. Each leaf node contains pointers to the data tuples they represent (or to the
actual tuples).
An index tree can therefore store aggregate and detail data at varying levels of resolution or abstraction. It
provides a hierarchy of clusterings of the data set, where each cluster has a label that holds for the data contained
in the cluster. If we consider each child of a parent node as a bucket, then an index tree can be considered as a
hierarchical histogram. For example, consider the root of a B+-tree as shown in Figure 3.10, with pointers to the
data keys 986, 3396, 5411, 8392, and 9544. Suppose that the tree contains 10,000 tuples with keys ranging from 1
to 9,999. The data in the tree can be approximated by an equi-depth histogram of 6 buckets for the key ranges 1 to
985, 986 to 3395, 3396 to 5410, 5411 to 8392, 8392 to 9543, and 9544 to 9999. Each bucket contains roughly 10,000/6
items. Similarly, each bucket is subdivided into smaller buckets, allowing for aggregate data at a ner-detailed level.
The use of multidimensional index trees as a form of data resolution relies on an ordering of the attribute values in
each dimension. Multidimensional index trees include R-trees, quad-trees, and their variations. They are well-suited
for handling both sparse and skewed data.
There are many measures for dening clusters and cluster quality. Clustering methods are further described in
Chapter 8.
CHAPTER 3. DATA PREPROCESSING
18
Sampling
Sampling can be used as a data reduction technique since it allows a large data set to be represented by a much
smaller random sample (or subset) of the data. Suppose that a large data set, D, contains N tuples. Let's have a
look at some possible samples for D.
T5
T1
T8
T6
SRSWOR
(n=4)
T1
T2
T3
T4
T5
T6
T7
T8
SRSWR
(n=4)
T4
T7
T4
T1
Cluster Sample
T1
T2
T3
T4
...
T5
T32
T53
T75
T100
T201
T202
T203
T204
...
T298
T216
T228
249
T300
T301
T302
T303
T304
...
T368
T391
T307
T326
T400
Stratified Sample
(according to age)
T38
T256
T307
T391
T96
T117
T138
T263
T290
T308
T326
T387
T69
T284
young
young
young
young
middle-aged
middle-aged
middle-aged
middle-aged
middle-aged
middle-aged
middle-aged
middle-aged
senior
senior
T38
T391
T117
T138
T290
T326
T69
young
young
middle-aged
middle-aged
middle-aged
middle-aged
senior
Figure 3.11: Sampling can be used for data reduction.
1. Simple random sample without replacement (SRSWOR) of size n: This is created by drawing n of the
N tuples from D (n < N), where the probably of drawing any tuple in D is 1=N, i.e., all tuples are equally
likely.
2. Simple random sample with replacement (SRSWR) of size n: This is similar to SRSWOR, except
that each time a tuple is drawn from D, it is recorded and then replaced. That is, after a tuple is drawn, it is
placed back in D so that it may be drawn again.
3.5. DISCRETIZATION AND CONCEPT HIERARCHY GENERATION
19
3. Cluster sample: If the tuples in D are grouped into M mutually disjoint \clusters", then a SRS of m clusters
can be obtained, where m < M. For example, tuples in a database are usually retrieved a page at a time, so
that each page can be considered a cluster. A reduced data representation can be obtained by applying, say,
SRSWOR to the pages, resulting in a cluster sample of the tuples.
4. Stratied sample: If D is divided into mutually disjoint parts called \strata", a stratied sample of D is
generated by obtaining a SRS at each stratum. This helps to ensure a representative sample, especially when
the data are skewed. For example, a stratied sample may be obtained from customer data, where stratum is
created for each customer age group. In this way, the age group having the smallest number of customers will
be sure to be represented.
These samples are illustrated in Figure 3.11. They represent the most commonly used forms of sampling for data
reduction.
An advantage of sampling for data reduction is that the cost of obtaining a sample is proportional to the size of
the sample, n, as opposed to N, the data set size. Hence, sampling complexity is potentially sub-linear to the size
of the data. Other data reduction techniques can require at least one complete pass through D. For a xed sample
size, sampling complexity increases only linearly as the number of data dimensions, d, increases, while techniques
using histograms, for example, increase exponentially in d.
When applied to data reduction, sampling is most commonly used to estimate the answer to an aggregate query.
It is possible (using the central limit theorem) to determine a sucient sample size for estimating a given function
within a specied degree of error. This sample size, n, may be extremely small in comparison to N. Sampling is
a natural choice for the progressive renement of a reduced data set. Such a set can be further rened by simply
increasing the sample size.
3.5 Discretization and concept hierarchy generation
Discretization techniques can be used to reduce the number of values for a given continuous attribute, by dividing
the range of the attribute into intervals. Interval labels can then be used to replace actual data values. Reducing
the number of values for an attribute is especially benecial if decision tree-based methods of classication mining
are to be applied to the preprocessed data. These methods are typically recursive, where a large amount of time is
spent on sorting the data at each step. Hence, the smaller the number of distinct values to sort, the faster these
methods should be. Many discretization techniques can be applied recursively in order to provide a hierarchical,
or multiresolution partitioning of the attribute values, known as a concept hierarchy. Concept hierarchies were
introduced in Chapter 2. They are useful for mining at multiple levels of abstraction.
A concept hierarchy for a given numeric attribute denes a discretization of the attribute. Concept hierarchies can
be used to reduce the data by collecting and replacing low level concepts (such as numeric values for the attribute age)
by higher level concepts (such as young, middle-aged, or senior). Although detail is lost by such data generalization,
the generalized data may be more meaningful and easier to interpret, and will require less space than the original
data. Mining on a reduced data set will require fewer input/output operations and be more ecient than mining on
a larger, ungeneralized data set. An example of a concept hierarchy for the attribute price is given in Figure 3.12.
More than one concept hierarchy can be dened for the same attribute in order to accommodate the needs of the
various users.
Manual denition of concept hierarchies can be a tedious and time-consuming task for the user or domain expert.
Fortunately, many hierarchies are implicit within the database schema, and can be dened at the schema denition
level. Concept hierarchies often can be automatically generated or dynamically rened based on statistical analysis
of the data distribution.
Let's look at the generation of concept hierarchies for numeric and categorical data.
3.5.1 Discretization and concept hierarchy generation for numeric data
It is dicult and tedious to specify concept hierarchies for numeric attributes due to the wide diversity of possible
data ranges and the frequent updates of data values.
Concept hierarchies for numeric attributes can be constructed automatically based on data distribution analysis.
We examine ve methods for numeric concept hierarchy generation. These include binning, histogram analysis,
CHAPTER 3. DATA PREPROCESSING
20
($0 - $1000]
($0 - $200]
($200 - $400]
($400 - $600]
($600 - $800]
($800 - $1,000]
($0 - $100] ($100 - $200] ($200 - $300] ($300 - $400] ($400 - $500] ($500 - $600] ($600 - $700] ($700 - $800]
($800 - $900] ($900 - $1,000]
Figure 3.12: A concept hierarchy for the attribute price.
count
4,000
3,500
3,000
2,500
2,000
1,500
1,000
500
$100
$200
$300
$400
$500
$600
$700
$800
$900
$1,000
price
Figure 3.13: Histogram showing the distribution of values for the attribute price.
clustering analysis, entropy-based discretization, and data segmentation by \natural partitioning".
1. Binning.
Section 3.2.2 discussed binning methods for data smoothing. These methods are also forms of discretization.
For example, attribute values can be discretized by replacing each bin value by the bin mean or median, as in
smoothing by bin means or smoothing by bin medians, respectively. These techniques can be applied recursively
to the resulting partitions in order to generate concept hierarchies.
2. Histogram analysis.
Histograms, as discussed in Section 3.4.4, can also be used for discretization. Figure 3.13 presents a histogram
showing the data distribution of the attribute price for a given data set. For example, the most frequent price
range is roughly $300-$325. Partitioning rules can be used to dene the ranges of values. For instance, in an
equi-width histogram, the values are partitioned into equal sized partions or ranges (e.g., ($0-$100], ($100-$200],
. .., ($900-$1,000]). With an equi-depth histogram, the values are partitioned so that, ideally, each partition
contains the same number of data samples. The histogram analysis algorithm can be applied recursively to
each partition in order to automatically generate a multilevel concept hierarchy, with the procedure terminating
once a pre-specied number of concept levels has been reached. A minimum interval size can also be used per
level to control the recursive procedure. This species the minimum width of a partition, or the minimum
number of values for each partition at each level. A concept hierarchy for price, generated from the data of
Figure 3.13 is shown in Figure 3.12.
3. Clustering analysis.
A clustering algorithm can be applied to partition data into clusters or groups. Each cluster forms a node of a
concept hierarchy, where all nodes are at the same conceptual level. Each cluster may be further decomposed
3.5. DISCRETIZATION AND CONCEPT HIERARCHY GENERATION
21
into several subclusters, forming a lower level of the hierarchy. Clusters may also be grouped together in order
to form a higher conceptual level of the hierarchy. Clustering methods for data mining are studied in Chapter
8.
4. Entropy-based discretization.
An information-based measure called \entropy" can be used to recursively partition the values of a numeric
attribute A, resulting in a hierarchical discretization. Such a discretization forms a numerical concept hierarchy
for the attribute. Given a set of data tuples, S, the basic method for entropy-based discretization of A is as
follows.
Each value of A can be considered a potential interval boundary or threshold T. For example, a value v of
A can partition the samples in S into two subsets satisfying the conditions A < v and A v, respectively,
thereby creating a binary discretization.
Given S, the threshold value selected is the one that maximizes the information gain resulting from the
subsequent partitioning. The information gain is:
I(S; T ) = jjSS1jj Ent(S1 ) + jjSS2jj Ent(S2 );
(3.7)
where S1 and S2 correspond to the samples in S satisfying the conditions A < T and A T , respectively.
The entropy function Ent for a given set is calculated based on the class distribution of the samples in
the set. For example, given m classes, the entropy of S1 is:
Ent(S1 ) = ,
m
X
i=1
pi log2 (pi );
(3.8)
where pi is the probability of class i in S1 , determined by dividing the number of samples of class i in S1
by the total number of samples in S1 . The value of Ent(S2 ) can be computed similarly.
The process of determining a threshold value is recursively applied to each partition obtained, until some
stopping criterion is met, such as
Ent(S) , I(S; T ) > (3.9)
Experiments show that entropy-based discretization can reduce data size and may improve classication accuracy. The information gain and entropy measures described here are also used for decision tree induction.
These measures are revisited in greater detail in Chapter 5 (Section 5.4 on analytical characterization) and
Chapter 7 (Section 7.3 on decision tree induction).
5. Segmentation by natural partitioning.
Although binning, histogram analysis, clustering and entropy-based discretization are useful in the generation
of numerical hierarchies, many users would like to see numerical ranges partitioned into relatively uniform,
easy-to-read intervals that appear intuitive or \natural". For example, annual salaries broken into ranges
like [$50,000, $60,000) are often more desirable than ranges like [$51263.98, $60872.34), obtained by some
sophisticated clustering analysis.
The 3-4-5 rule can be used to segment numeric data into relatively uniform, \natural" intervals. In general,
the rule partitions a given range of data into either 3, 4, or 5 relatively equi-length intervals, recursively and
level by level, based on the value range at the most signicant digit. The rule is as follows.
(a) If an interval covers 3, 6, 7 or 9 distinct values at the most signicant digit, then partition the range into
3 intervals (3 equi-width intervals for 3, 6, 9, and three intervals in the grouping of 2-3-2 for 7);
(b) if it covers 2, 4, or 8 distinct values at the most signicant digit, then partition the range into 4 equi-width
intervals; and
CHAPTER 3. DATA PREPROCESSING
22
count
Step 1:
-$351,976.00 -$159,876
MIN
LOW (i.e., 5%-tile)
profit
Step 2:
msd = 1,000,000
HIGH’ = $2,000,000
LOW’ = -$1,000,000
Step 3:
$1,838,761
HIGH (i.e., 95%-tile)
$4,700,896.50
MAX
(-$1,000,000 - $2,000,000]
(-$1,000,000 - 0]
($0 - $1,000,000]
($1,000,000 - $2,000,000]
(-$400,000 - $5,000,000]
Step 4:
(-$400,000 - 0]
(0 - $1,000,000]
($1,000,000 - $2,000,000]
($2,000,000 - $5,000,000]
Step 5:
($1,000,000 $1,200,000]
($0 $200,000]
(-$400,000 -$300,000]
(-$300,000 -$200,000]
(-$200,000 -$100,000]
(-$100,000 $0]
($200,000 $400,000]
($1,200,000 $1,400,000]
(400,000 -
($1,400,000 -
$600,000]
$1,600,000]
($600,000 -
($1,600,000 -
$800,000]
$1,800,000]
($800,000 $1,000,000]
($2,000,000 $3,000,000]
($3,000,000 $4,000,000]
($4,000,000 $5,000,000]
($1,800,000 $2,000,000]
Figure 3.14: Automatic generation of a concept hierarchy for prot based on the 3-4-5 rule.
(c) if it covers 1, 5, or 10 distinct values at the most signicant digit, then partition the range into 5 equi-width
intervals.
The rule can be recursively applied to each interval, creating a concept hierarchy for the given numeric attribute.
Since there could be some dramatically large positive or negative values in a data set, the top level segmentation,
based merely on the minimum and maximum values, may derive distorted results. For example, the assets of a
few people could be several orders of magnitude higher than those of others in a data set. Segmentation based
on the maximal asset values may lead to a highly biased hierarchy. Thus the top level segmentation can be
performed based on the range of data values representing the majority (e.g., 5%-tile to 95%-tile) of the given
data. The extremely high or low values beyond the top level segmentation will form distinct interval(s) which
can be handled separately, but in a similar manner.
The following example illustrates the use of the 3-4-5 rule for the automatic construction of a numeric hierarchy.
Example 3.5 Suppose that prots at dierent branches of AllElectronics for the year 1997 cover a wide
range, from ,$351,976.00 to $4,700,896.50. A user wishes to have a concept hierarchy for prot automatically
3.5. DISCRETIZATION AND CONCEPT HIERARCHY GENERATION
23
generated. For improved readability, we use the notation (l | r] to represent the interval (l; r]. For example,
(,$1,000,000 | $0] denotes the range from ,$1,000,000 (exclusive) to $0 (inclusive).
Suppose that the data within the 5%-tile and 95%-tile are between ,$159,876 and $1,838,761. The results of
applying the 3-4-5 rule are shown in Figure 3.14.
Step 1: Based on the above information, the minimum and maximum values are: MIN = ,$351; 976:00,
and MAX = $4; 700; 896:50. The low (5%-tile) and high (95%-tile) values to be considered for the top or
rst level of segmentation are: LOW = ,$159; 876, and HIGH = $1; 838; 761.
Step 2: Given LOW and HIGH, the most signicant digit is at the million dollar digit position (i.e., msd =
1,000,000). Rounding LOW down to the million dollar digit, we get LOW 0 = ,$1; 000; 000; and rounding
HIGH up to the million dollar digit, we get HIGH 0 = +$2; 000; 000.
Step 3: Since this interval ranges over 3 distinct values at the most signicant digit, i.e., (2; 000; 000 ,
(,1; 000; 000))=1; 000;000 = 3, the segment is partitioned into 3 equi-width subsegments according to the
3-4-5 rule: (,$1,000,000 | $0], ($0 | $1,000,000], and ($1,000,000 | $2,000,000]. This represents the
top tier of the hierarchy.
Step 4: We now examine the MIN and MAX values to see how they \t" into the rst level partitions.
Since the rst interval, (,$1; 000; 000 | $0] covers the MIN value, i.e., LOW 0 < MIN, we can adjust
the left boundary of this interval to make the interval smaller. The most signicant digit of MIN is the
hundred thousand digit position. Rounding MIN down to this position, we get MIN 0 = ,$400; 000.
Therefore, the rst interval is redened as (,$400; 000 | 0].
Since the last interval, ($1,000,000 | $2,000,000] does not cover the MAX value, i.e., MAX > HIGH 0 , we
need to create a new interval to cover it. Rounding up MAX at its most signicant digit position, the new
interval is ($2,000,000 | $5,000,000]. Hence, the top most level of the hierarchy contains four partitions,
(,$400,000 | $0], ($0 | $1,000,000], ($1,000,000 | $2,000,000], and ($2,000,000 | $5,000,000].
Step 5: Recursively, each interval can be further partitioned according to the 3-4-5 rule to form the next
lower level of the hierarchy:
{ The rst interval (,$400,000 | $0] is partitioned into 4 sub-intervals: (,$400,000 | ,$300,000],
(,$300,000 | ,$200,000], (,$200,000 | ,$100,000], and (,$100,000 | $0].
{ The second interval, ($0 | $1,000,000], is partitioned into 5 sub-intervals: ($0 | $200,000], ($200,000
| $400,000], ($400,000 | $600,000], ($600,000 | $800,000], and ($800,000 | $1,000,000].
{ The third interval, ($1,000,000 | $2,000,000], is partitioned into 5 sub-intervals: ($1,000,000 |
$1,200,000], ($1,200,000 | $1,400,000], ($1,400,000 | $1,600,000], ($1,600,000 | $1,800,000], and
($1,800,000 | $2,000,000].
{ The last interval, ($2,000,000 | $5,000,000], is partitioned into 3 sub-intervals: ($2,000,000 |
$3,000,000], ($3,000,000 | $4,000,000], and ($4,000,000 | $5,000,000].
Similarly, the 3-4-5 rule can be carried on iteratively at deeper levels, as necessary.
2
3.5.2 Concept hierarchy generation for categorical data
Categorical data are discrete data. Categorical attributes have a nite (but possibly large) number of distinct values,
with no ordering among the values. Examples include geographic location, job category, and item type. There are
several methods for the generation of concept hierarchies for categorical data.
1. Specication of a partial ordering of attributes explicitly at the schema level by users or experts.
Concept hierarchies for categorical attributes or dimensions typically involve a group of attributes. A user or
an expert can easily dene a concept hierarchy by specifying a partial or total ordering of the attributes at
the schema level. For example, a relational database or a dimension location of a data warehouse may contain
the following group of attributes: street, city, province or state, and country. A hierarchy can be dened by
specifying the total ordering among these attributes at the schema level, such as street < city < province or state
< country.
CHAPTER 3. DATA PREPROCESSING
24
country
15 distinct values
province_or_state
65 distinct values
city
street
3567 distinct values
674,339 distinct values
Figure 3.15: Automatic generation of a schema concept hierarchy based on the number of distinct attribute values.
2. Specication of a portion of a hierarchy by explicit data grouping.
This is essentially the manual denition of a portion of concept hierarchy. In a large database, it is unrealistic
to dene an entire concept hierarchy by explicit value enumeration. However, it is realistic to specify explicit
groupings for a small portion of intermediate level data. For example, after specifying that province and country
form a hierarchy at the schema level, one may like to add some intermediate levels manually, such as dening
explicitly, \fAlberta, Saskatchewan, Manitobag prairies Canada", and \fBritish Columbia, prairies Canadag
Western Canada".
3. Specication of a set of attributes , but not of their partial ordering.
A user may simply group a set of attributes as a preferred dimension or hierarchy, but may omit stating their
partial order explicitly. This may require the system to automatically generate the attribute ordering so as
to construct a meaningful concept hierarchy. Without knowledge of data semantics, it is dicult to provide
an ideal hierarchical ordering for an arbitrary set of attributes. However, an important observation is that
since higher level concepts generally cover several subordinate lower level concepts, an attribute dening a high
concept level will usually contain a smaller number of distinct values than an attribute dening a lower concept
level. Based on this observation, a concept hierarchy can be automatically generated based on the number of
distinct values per attribute in the given attribute set. The attribute with the most distinct values is placed
at the lowest level of the hierarchy. The lesser the number of distinct values an attribute has, the higher it is
in the generated concept hierarchy. This heuristic rule works ne in many cases. Some local level swapping
or adjustments may be performed by users or experts, when necessary, after examination of the generated
hierarchy.
Let's examine an example of this method.
Example 3.6 Suppose a user selects a set of attributes, street, country, province or state, and city, for a
dimension location from the database AllElectronics, but does not specify the hierarchical ordering among the
attributes.
The concept hierarchy for location can be generated automatically as follows. First, sort the attributes in
ascending order based on the number of distinct values in each attribute. This results in the following (where
the number of distinct values per attribute is shown in parentheses): country (15), province or state (65), city
(3567), and street (674,339). Second, generate the hierarchy from top down according to the sorted order,
with the rst attribute at the top-level and the last attribute at the bottom-level. The resulting hierarchy is
shown in Figure 3.15. Finally, the user examines the generated hierarchy, and when necessary, modies it to
reect desired semantic relationship among the attributes. In this example, it is obvious that there is no need
to modify the generated hierarchy.
2
Note that this heristic rule cannot be pushed to the extreme since there are obvious cases which do not follow
such a heuristic. For example, a time dimension in a database may contain 20 distinct years, 12 distinct months
and 7 distinct days of the week. However, this does not suggest that the time hierarchy should be \year <
month < days of the week", with days of the week at the top of the hierarchy.
4. Specication of only a partial set of attributes.
3.6. SUMMARY
25
Sometimes a user can be sloppy when dening a hierarchy, or may have only a vague idea about what should be
included in a hierarchy. Consequently, the user may have included only a small subset of the relevant attributes
in a hierarchy specication. For example, instead of including all the hierarchically relevant attributes for
location, one may specify only street and city. To handle such partially specied hierarchies, it is important to
embed data semantics in the database schema so that attributes with tight semantic connections can be pinned
together. In this way, the specication of one attribute may trigger a whole group of semantically tightly linked
attributes to be \dragged-in" to form a complete hierarchy. Users, however, should have the option to over-ride
this feature, as necessary.
Example 3.7 Suppose that a database system has pinned together the ve attributes, number, street, city,
province or state, and country, because they are closely linked semantically, regarding the notion of location.
If a user were to specify only the attribute city for a hierarchy dening location, the system may automatically
drag all of the above ve semantically-related attributes to form a hierarchy. The user may choose to drop any
of these attributes, such as number and street, from the hierarchy, keeping city as the lowest conceptual level
in the hierarchy.
2
3.6 Summary
Data preparation is an important issue for both data warehousing and data mining, as real-world data tends
to be incomplete, noisy, and inconsistent. Data preparation includes data cleaning, data integration, data
transformation, and data reduction.
Data cleaning routines can be used to ll in missing values, smooth noisy data, identify outliers, and correct
data inconsistencies.
Data integration combines data from multiples sources to form a coherent data store. Metadata, correlation
analysis, data conict detection, and the resolution of semantic heterogeneity contribute towards smooth data
integration.
Data transformation routines conform the data into appropriate forms for mining. For example, attribute
data may be normalized so as to fall between a small range, such as 0 to 1.0.
Data reduction techniques such as data cube aggregation, dimension reduction, data compression, numerosity
reduction, and discretization can be used to obtain a reduced representation of the data, while minimizing the
loss of information content.
Concept hierarchies organize the values of attributes or dimensions into gradual levels of abstraction. They
are a form a discretization that is particularly useful in multilevel mining.
Automatic generation of concept hierarchies for categoric data may be based on the number of distinct
values of the attributes dening the hierarchy. For numeric data, techniques such as data segmentation by
partition rules, histogram analysis, and clustering analysis can be used.
Although several methods of data preparation have been developed, data preparation remains an active area
of research.
Exercises
1. Data quality can be assessed in terms of accuracy, completeness, and consistency. Propose two other dimensions
of data quality.
2. In real-world data, tuples with missing values for some attributes are a common occurrence. Describe various
methods for handling this problem.
3. Suppose that the data for analysis includes the attribute age. The age values for the data tuples are (in
increasing order):
13, 15, 16, 16, 19, 20, 20, 21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45, 46, 52, 70.
CHAPTER 3. DATA PREPROCESSING
26
(a) Use smoothing by bin means to smooth the above data, using a bin depth of 3. Illustrate your steps.
Comment on the eect of this technique for the given data.
(b) How might you determine outliers in the data?
(c) What other methods are there for data smoothing?
4. Discuss issues to consider during data integration.
5. Using the data for age given in Question 3, answer the following:
(a) Use min-max normalization to transform the value 35 for age onto the range [0; 1].
(b) Use z-score normalization to transform the value 35 for age, where the standard deviation of age is ??.
(c) Use normalization by decimal scaling to transform the value 35 for age.
(d) Comment on which method you would prefer to use for the given data, giving reasons as to why.
6. Use a ow-chart to illustrate the following procedures for attribute subset selection:
(a) step-wise forward selection.
(b) step-wise backward elimination
(c) a combination of forward selection and backward elimination.
7. Using the data for age given in Question 3:
(a) Plot an equi-width histogram of width 10.
(b) Sketch examples of each of the following sample techniques: SRSWOR, SRSWR, cluster sampling, stratied sampling.
8. Propose a concept hierarchy for the attribute age using the 3-4-5 partition rule.
9. Propose an algorithm, in pseudo-code or in your favorite programming language, for
(a) the automatic generation of a concept hierarchy for categorical data based on the number of distinct values
of attributes in the given schema,
(b) the automatic generation of a concept hierarchy for numeric data based on the equi-width partitioning
rule, and
(c) the automatic generation of a concept hierarchy for numeric data based on the equi-depth partitioning
rule.
Bibliographic Notes
Data preprocessing is discussed in a number of textbooks, including Pyle [28], Kennedy et al. [21], and Weiss and
Indurkhya [37]. More specic references to individual preprocessing techniques are given below.
For discussion regarding data quality, see Ballou and Tayi [3], Redman [31], Wand and Wang [35], and Wang,
Storey and Firth [36]. The handling of missing attribute values is discussed in Quinlan [29], Breiman et al. [5], and
Friedman [11]. A method for the detection of outlier or \garbage" patterns in a handwritten character database
is given in Guyon, Matic, and Vapnik [14]. Binning and data normalization are treated in several texts, including
[28, 21, 37].
A good survey of data reduction techniques can be found in Barbara et al. [4]. For algorithms on data cubes
and their precomputation, see [33, 16, 1, 38, 32]. Greedy methods for attribute subset selection (or feature subset
selection) are described in several texts, such as Neter et al. [24], and John [18]. A combination forward selection
and backward elimination method was proposed in Siedlecki and Sklansky [34]. For a description of wavelets for
data compression, see Press et al. [27]. Daubechies transforms are described in Daubechies [6]. The book by Press
et al. [27] also contains an introduction to singular value decomposition for principal components analysis.
An introduction to regression and log-linear models can be found in several textbooks, such as [17, 9, 20, 8, 24].
For log-linear models (known as multiplicative models in the computer science literature), see Pearl [25]. For a
3.6. SUMMARY
27
general introduction to histograms, see [7, 4]. For extensions of single attribute histograms to multiple attributes,
see Muralikrishna and DeWitt [23], and Poosala and Ioannidis [26]. Several references to clustering algorithms are
given in Chapter 7 of this book, which is devoted to this topic. A survey of multidimensional indexing structures is
in Gaede and Gunther [12]. The use of multidimensional index trees for data aggregation is discussed in Aoki [2].
Index trees include R-trees (Guttman [13]), quad-trees (Finkel and Bentley [10]), and their variations. For discussion
on sampling and data mining, see John and Langley [19], and Kivinen and Mannila [22].
Entropy and information gain are described in Quinlan [30]. Concept hierarchies, and their automatic generation
from categorical data are described in Han and Fu [15].
28
CHAPTER 3. DATA PREPROCESSING
Bibliography
[1] S. Agarwal, R. Agrawal, P. M. Deshpande, A. Gupta, J. F. Naughton, R. Ramakrishnan, and S. Sarawagi.
On the computation of multidimensional aggregates. In Proc. 1996 Int. Conf. Very Large Data Bases, pages
506{521, Bombay, India, Sept. 1996.
[2] P. M. Aoki. Generalizing \search" in generalized search trees. In Proc. 1998 Int. Conf. Data Engineering
(ICDE'98), April 1998.
[3] D. P. Ballou and G. K. Tayi. Enhancing data quality in data warehouse environments. Communications of
ACM, 42:73{78, 1999.
[4] D. Barbara et al. The new jersey data reduction report. Bulletin of the Technical Committee on Data Engineering, 20:3{45, December 1997.
[5] L. Breiman, J. Friedman, R. Olshen, and C. Stone. Classication and Regression Trees. Wadsworth International
Group, 1984.
[6] I. Daubechies. Ten Lectures on Wavelets. Capital City Press, Montpelier, Vermont, 1992.
[7] J. Devore and R. Peck. Statistics: The Exploration and Analysis of Data. New York: Duxbury Press, 1997.
[8] J. L. Devore. Probability and Statistics for Engineering and the Science, 4th ed. Duxbury Press, 1995.
[9] A. J. Dobson. An Introduction to Generalized Linear Models. Chapman and Hall, 1990.
[10] R. A. Finkel and J. L. Bentley. Quad-trees: A data structure for retrieval on composite keys. ACTA Informatica,
4:1{9, 1974.
[11] J. H. Friedman. A recursive partitioning decision rule for nonparametric classiers. IEEE Trans. on Comp.,
26:404{408, 1977.
[12] V. Gaede and O. Gunther. Multdimensional access methods. ACM Comput. Surv., 30:170{231, 1998.
[13] A. Guttman. R-tree: A dynamic index structure for spatial searching. In Proc. 1984 ACM-SIGMOD Int. Conf.
Management of Data, June 1984.
[14] I. Guyon, N. Matic, and V. Vapnik. Discoverying informative patterns and data cleaning. In U.M. Fayyad,
G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy, editors, Advances in Knowledge Discovery and Data
Mining, pages 181{203. AAAI/MIT Press, 1996.
[15] J. Han and Y. Fu. Dynamic generation and renement of concept hierarchies for knowledge discovery in
databases. In Proc. AAAI'94 Workshop Knowledge Discovery in Databases (KDD'94), pages 157{168, Seattle,
WA, July 1994.
[16] V. Harinarayan, A. Rajaraman, and J. D. Ullman. Implementing data cubes eciently. In Proc. 1996 ACMSIGMOD Int. Conf. Management of Data, pages 205{216, Montreal, Canada, June 1996.
[17] M. James. Classication Algorithms. John Wiley, 1985.
[18] G. H. John. Enhancements to the Data Mining Process. Ph.D. Thesis, Computer Science Dept., Stanford
Univeristy, 1997.
29
30
BIBLIOGRAPHY
[19] G. H. John and P. Langley. Static versus dynamic sampling for data mining. In Proc. 2nd Int. Conf. on
Knowledge Discovery and Data Mining (KDD'96), pages 367{370, Portland, OR, Aug. 1996.
[20] R. A. Johnson and D. W. Wickern. Applied Multivariate Statistical Analysis, 3rd ed. Prentice Hall, 1992.
[21] R. L Kennedy, Y. Lee, B. Van Roy, C. D. Reed, and R. P. Lippman. Solving Data Mining Problems Through
Pattern Recognition. Upper Saddle River, NJ: Prentice Hall, 1998.
[22] J. Kivinen and H. Mannila. The power of sampling in knowledge discovery. In Proc. 13th ACM Symp. Principles
of Database Systems, pages 77{85, Minneapolis, MN, May 1994.
[23] M. Muralikrishna and D. J. DeWitt. Equi-depth histograms for extimating selectivity factors for multidimensional queries. In Proc. 1988 ACM-SIGMOD Int. Conf. Management of Data, pages 28{36, Chicago,
IL, June 1988.
[24] J. Neter, M. H. Kutner, C. J. Nachtsheim, and L. Wasserman. Applied Linear Statistical Models, 4th ed. Irwin:
Chicago, 1996.
[25] J. Pearl. Probabilistic Reasoning in Intelligent Systems. Palo Alto, CA: Morgan Kauman, 1988.
[26] V. Poosala and Y. Ioannidis. Selectivity estimationwithout the attribute value independence assumption. In
Proc. 23rd Int. Conf. on Very Large Data Bases, pages 486{495, Athens, Greece, Aug. 1997.
[27] W. H. Press, S. A. Teukolosky, W. T. Vetterling, and B. P. Flannery. Numerical Recipes in C: The Art of
Scientic Computing. Cambridge University Press, Cambridge, MA, 1996.
[28] D. Pyle. Data Preparation for Data Mining. Morgan Kaufmann, 1999.
[29] J. R. Quinlan. Unknown attribute values in induction. In Proc. 6th Int. Workshop on Machine Learning, pages
164{168, Ithaca, NY, June 1989.
[30] J. R. Quinlan. C4.5: Programs for Machine Learning. Morgan Kaufmann, 1993.
[31] T. Redman. Data Quality: Management and Technology. Bantam Books, New York, 1992.
[32] K. Ross and D. Srivastava. Fast computation of sparse datacubes. In Proc. 1997 Int. Conf. Very Large Data
Bases, pages 116{125, Athens, Greece, Aug. 1997.
[33] S. Sarawagi and M. Stonebraker. Ecient organization of large multidimensional arrays. In Proc. 1994 Int.
Conf. Data Engineering, pages 328{336, Feb. 1994.
[34] W. Siedlecki and J. Sklansky. On automatic feature selection. Int. J. of Pattern Recognition and Articial
Intelligence, 2:197{220, 1988.
[35] Y. Wand and R. Wang. Anchoring data quality dimensions ontological foundations. Communications of ACM,
39:86{95, 1996.
[36] R. Wang, V. Storey, and C. Firth. A framework for analysis of data quality research. IEEE Trans. Knowledge
and Data Engineering, 7:623{640, 1995.
[37] S. M. Weiss and N. Indurkhya. Predictive Data Mining. Morgan Kaufmann, 1998.
[38] Y. Zhao, P. M. Deshpande, and J. F. Naughton. An array-based algorithm for simultaneous multidimensional
aggregates. In Proc. 1997 ACM-SIGMOD Int. Conf. Management of Data, pages 159{170, Tucson, Arizona,
May 1997.
Contents
4 Primitives for Data Mining
4.1 Data mining primitives: what denes a data mining task? . . . . . . . . . .
4.1.1 Task-relevant data . . . . . . . . . . . . . . . . . . . . . . . . . . . .
4.1.2 The kind of knowledge to be mined . . . . . . . . . . . . . . . . . . .
4.1.3 Background knowledge: concept hierarchies . . . . . . . . . . . . . .
4.1.4 Interestingness measures . . . . . . . . . . . . . . . . . . . . . . . . .
4.1.5 Presentation and visualization of discovered patterns . . . . . . . . .
4.2 A data mining query language . . . . . . . . . . . . . . . . . . . . . . . . . .
4.2.1 Syntax for task-relevant data specication . . . . . . . . . . . . . . .
4.2.2 Syntax for specifying the kind of knowledge to be mined . . . . . . .
4.2.3 Syntax for concept hierarchy specication . . . . . . . . . . . . . . .
4.2.4 Syntax for interestingness measure specication . . . . . . . . . . . .
4.2.5 Syntax for pattern presentation and visualization specication . . .
4.2.6 Putting it all together | an example of a DMQL query . . . . . . .
4.3 Designing graphical user interfaces based on a data mining query language .
4.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
3
3
4
6
7
10
12
12
15
15
18
20
20
21
22
22
2
CONTENTS
September 7, 1999
Chapter 4
Primitives for Data Mining
A popular misconception about data mining is to expect that data mining systems can autonomously dig out
all of the valuable knowledge that is embedded in a given large database, without human intervention or guidance.
Although it may at rst sound appealing to have an autonomous data mining system, in practice, such systems will
uncover an overwhelmingly large set of patterns. The entire set of generated patterns may easily surpass the size
of the given database! To let a data mining system \run loose" in its discovery of patterns, without providing it
with any indication regarding the portions of the database that the user wants to probe or the kinds of patterns
the user would nd interesting, is to let loose a data mining \monster". Most of the patterns discovered would be
irrelevant to the analysis task of the user. Furthermore, many of the patterns found, though related to the analysis
task, may be dicult to understand, or lack of validity, novelty, or utility | making them uninteresting. Thus, it is
neither realistic nor desirable to generate, store, or present all of the patterns that could be discovered from a given
database.
A more realistic scenario is to expect that users can communicate with the data mining system using a set of
data mining primitives designed in order to facilitate ecient and fruitful knowledge discovery. Such primitives
include the specication of the portions of the database or the set of data in which the user is interested (including
the database attributes or data warehouse dimensions of interest), the kinds of knowledge to be mined, background
knowledge useful in guiding the discovery process, interestingness measures for pattern evaluation, and how the
discovered knowledge should be visualized. These primitives allow the user to interactively communicate with the
data mining system during discovery in order to examine the ndings from dierent angles or depths, and direct the
mining process.
A data mining query language can be designed to incorporate these primitives, allowing users to exibly interact
with data mining systems. Having a data mining query language also provides a foundation on which friendly
graphical user interfaces can be built. In this chapter, you will learn about the data mining primitives in detail, as
well as study the design of a data mining query language based on these principles.
4.1 Data mining primitives: what denes a data mining task?
Each user will have a data mining task in mind, i.e., some form of data analysis that she would like to have
performed. A data mining task can be specied in the form of a data mining query, which is input to the data
mining system. A data mining query is dened in terms of the following primitives, as illustrated in Figure 4.1.
1. task-relevant data: This is the database portion to be investigated. For example, suppose that you are a
manager of AllElectronics in charge of sales in the United States and Canada. In particular, you would like
to study the buying trends of customers in Canada. Rather than mining on the entire database, you can
specify that only the data relating to customer purchases in Canada need be retrieved, along with the related
customer prole information. You can also specify attributes of interest to be considered in the mining process.
These are referred to as relevant attributes1. For example, if you are interested only in studying possible
1 If mining is to be performed on data from a multidimensional data cube, the user can specify relevant dimensions.
3
CHAPTER 4. PRIMITIVES FOR DATA MINING
4
Task-relevant data: what is the data set that I want to mine?
What kind of knowledge do I want to mine?
What background knowledge could be useful here?
Which measurements can be used to estimate pattern interestingness?
How do I want the discovered patterns to be presented?
Figure 4.1: Dening a data mining task or query.
2.
3.
4.
5.
relationships between, say, the items purchased, and customer annual income and age, then the attributes name
of the relation item, and income and age of the relation customer can be specied as the relevant attributes
for mining. The portion of the database to be mined is called the minable view. A minable view can also be
sorted and/or grouped according to one or a set of attributes or dimensions.
the kinds of knowledge to be mined: This species the data mining functions to be performed, such as
characterization, discrimination, association, classication, clustering, or evolution analysis. For instance, if
studying the buying habits of customers in Canada, you may choose to mine associations between customer
proles and the items that these customers like to buy.
background knowledge: Users can specify background knowledge, or knowledge about the domain to be
mined. This knowledge is useful for guiding the knowledge discovery process, and for evaluating the patterns
found. There are several kinds of background knowledge. In this chapter, we focus our discussion on a popular
form of background knowledge known as concept hierarchies. Concept hierarchies are useful in that they allow
data to be mined at multiple levels of abstraction. Other examples include user beliefs regarding relationships
in the data. These can be used to evaluate the discovered patterns according to their degree of unexpectedness,
where unexpected patterns are deemed interesting.
interestingness measures: These functions are used to separate uninteresting patterns from knowledge. They
may be used to guide the mining process, or after discovery, to evaluate the discovered patterns. Dierent kinds
of knowledge may have dierent interestingness measures. For example, interestingness measures for association
rules include support (the percentage of task-relevant data tuples for which the rule pattern appears), and
condence (the strength of the implication of the rule). Rules whose support and condence values are below
user-specied thresholds are considered uninteresting.
presentation and visualization of discovered patterns: This refers to the form in which discovered
patterns are to be displayed. Users can choose from dierent forms for knowledge presentation, such as rules,
tables, charts, graphs, decision trees, and cubes.
Below, we examine each of these primitives in greater detail. The specication of these primitives is summarized
in Figure 4.2.
4.1.1 Task-relevant data
The rst primitive is the specication of the data on which mining is to be performed. Typically, a user is interested
in only a subset of the database. It is impractical to indiscriminately mine the entire database, particularly since the
number of patterns generated could be exponential with respect to the database size. Furthermore, many of these
patterns found would be irrelevant to the interests of the user.
4.1. DATA MINING PRIMITIVES: WHAT DEFINES A DATA MINING TASK?
Task-relevant data
- database or data warehouse name
- database tables or data warehouse cubes
- conditions for data selection
- relevant attributes or dimensions
- data grouping criteria
Knowledge type to be mined
- characterization
- discrimination
- association
- classification/prediction
- clustering
Background knowledge
- concept hierarchies
- user beliefs about relationships in the data
Pattern interestingness measurements
- simplicity
- certainty (e.g., confidence)
- utility (e.g., support)
- novelty
Visualization of discovered patterns
- rules, tables, reports, charts, graphs, decisison trees, and cubes
- drill-down and roll-up
Figure 4.2: Primitives for specifying a data mining task.
5
6
CHAPTER 4. PRIMITIVES FOR DATA MINING
In a relational database, the set of task-relevant data can be collected via a relational query involving operations
like selection, projection, join, and aggregation. This retrieval of data can be thought of as a \subtask" of the data
mining task. The data collection process results in a new data relation, called the initial data relation. The initial
data relation can be ordered or grouped according to the conditions specied in the query. The data may be cleaned
or transformed (e.g., aggregated on certain attributes) prior to applying data mining analysis. The initial relation
may or may not correspond to a physical relation in the database. Since virtual relations are called views in the
eld of databases, the set of task-relevant data for data mining is called a minable view.
Example 4.1 If the data mining task is to study associations between items frequently purchased at AllElectronics
by customers in Canada, the task-relevant data can be specied by providing the following information:
the name of the database or data warehouse to be used (e.g., AllElectronics db),
the names of the tables or data cubes containing the relevant data (e.g., item, customer, purchases, and
items sold),
conditions for selecting the relevant data (e.g., retrieve data pertaining to purchases made in Canada for the
current year),
the relevant attributes or dimensions (e.g., name and price from the item table, and income and age from the
customer table).
In addition, the user may specify that the data retrieved be grouped by certain attributes, such as \group by date".
Given this information, an SQL query can be used to retrieve the task-relevant data.
2
In a data warehouse, data are typically stored in a multidimensional database, known as a data cube, which
can be implemented using a multidimensional array structure, a relational structure, or a combination of both, as
discussed in Chapter 2. The set of task-relevant data can be specied by condition-based data ltering, slicing
(extracting data for a given attribute value, or \slice"), or dicing (extracting the intersection of several slices) of the
data cube.
Notice that in a data mining query, the conditions provided for data selection can be at a level that is conceptually
higher than the data in the database or data warehouse. For example, a user may specify a selection on items at
AllElectronics using the concept \type = home entertainment", even though individual items in the database may
not be stored according to type, but rather, at a lower conceptual, such as \TV", \CD player", or \VCR". A concept
hierarchy on item which species that \home entertainment" is at a higher concept level, composed of the lower level
concepts f\TV", \CD player", \VCR"g can be used in the collection of the task-relevant data.
The set of relevant attributes specied may involve other attributes which were not explicitly mentioned, but
which should be included because they are implied by the concept hierarchy or dimensions involved in the set of
relevant attributes specied. For example, a query-relevant set of attributes may contain city. This attribute,
however, may be part of other concept hierarchies such as the concept hierarchy street < city < province or state <
country for the dimension location. In this case, the attributes street, province or state, and country should also be
included in the set of relevant attributes since they represent lower or higher level abstractions of city. This facilitates
the mining of knowledge at multiple levels of abstraction by specialization (drill-down) and generalization (roll-up).
Specication of the relevant attributes or dimensions can be a dicult task for users. A user may have only a
rough idea of what the interesting attributes for exploration might be. Furthermore, when specifying the data to be
mined, the user may overlook additional relevant data having strong semantic links to them. For example, the sales
of certain items may be closely linked to particular events such as Christmas or Halloween, or to particular groups of
people, yet these factors may not be included in the general data analysis request. For such cases, mechanisms can
be used which help give a more precise specication of the task-relevant data. These include functions to evaluate
and rank attributes according to their relevancy with respect to the operation specied. In addition, techniques that
search for attributes with strong semantic ties can be used to enhance the initial dataset specied by the user.
4.1.2 The kind of knowledge to be mined
It is important to specify the kind of knowledge to be mined, as this determines the data mining function to be
performed. The kinds of knowledge include concept description (characterization and discrimination), association,
classication, prediction, clustering, and evolution analysis.
4.1. DATA MINING PRIMITIVES: WHAT DEFINES A DATA MINING TASK?
7
In addition to specifying the kind of knowledge to be mined for a given data mining task, the user can be more
specic and provide pattern templates that all discovered patterns must match. These templates, or metapatterns
(also called metarules or metaqueries), can be used to guide the discovery process. The use of metapatterns is
illustrated in the following example.
Example 4.2 A user studying the buying habits of AllElectronics customers may choose to mine association rules
of the form
P(X : customer; W) ^ Q(X; Y ) ) buys(X; Z)
where X is a key of the customer relation, P and Q are predicate variables which can be instantiated to the
relevant attributes or dimensions specied as part of the task-relevant data, and W, Y , and Z are object variables
which can take on the values of their respective predicates for customers X.
The search for association rules is conned to those matching the given metarule, such as
age(X; \30 39") ^ income(X; \40 50K") ) buys(X; \V CR")
[2:2%; 60%]
(4.1)
and
occupation(X; \student") ^ age(X; \20 29") ) buys(X; \computer")
[1:4%; 70%]:
(4.2)
The former rule states that customers in their thirties, with an annual income of between 40K and 50K, are likely
(with 60% condence) to purchase a VCR, and such cases represent about 2.2% of the total number of transactions.
The latter rule states that customers who are students and in their twenties are likely (with 70% condence) to
purchase a computer, and such cases represent about 1.4% of the total number of transactions.
2
4.1.3 Background knowledge: concept hierarchies
Background knowledge is information about the domain to be mined that can be useful in the discovery process.
In this section, we focus our attention on a simple yet powerful form of background knowledge known as concept
hierarchies. Concept hierarchies allow the discovery of knowledge at multiple levels of abstraction.
As described in Chapter 2, a concept hierarchy denes a sequence of mappings from a set of low level concepts
to higher level, more general concepts. A concept hierarchy for the dimension location is shown in Figure 4.3, mapping
low level concepts (i.e., cities) to more general concepts (i.e., countries).
Notice that this concept hierarchy is represented as a set of nodes organized in a tree, where each node, in
itself, represents a concept. A special node, all, is reserved for the root of the tree. It denotes the most generalized
value of the given dimension. If not explicitly shown, it is implied. This concept hierarchy consists of four levels.
By convention, levels within a concept hierarchy are numbered from top to bottom, starting with level 0 for the all
node. In our example, level 1 represents the concept country, while levels 2 and 3 respectively represent the concepts
province or state and city. The leaves of the hierarchy correspond to the dimension's raw data values (primitive
level data). These are the most specic values, or concepts, of the given attribute or dimension. Although a concept
hierarchy often denes a taxonomy represented in the shape of a tree, it may also be in the form of a general lattice
or partial order.
Concept hierarchies are a useful form of background knowledge in that they allow raw data to be handled at
higher, generalized levels of abstraction. Generalization of the data, or rolling up is achieved by replacing primitive
level data (such as city names for location, or numerical values for age) by higher level concepts (such as continents for
location, or ranges like \20-39", \40-59", \60+" for age). This allows the user to view the data at more meaningful
and explicit abstractions, and makes the discovered patterns easier to understand. Generalization has an added
advantage of compressing the data. Mining on a compressed data set will require fewer input/output operations and
be more ecient than mining on a larger, uncompressed data set.
If the resulting data appear overgeneralized, concept hierarchies also allow specialization, or drilling down,
whereby concept values are replaced by lower level concepts. By rolling up and drilling down, users can view the
data from dierent perspectives, gaining further insight into hidden data relationships.
Concept hierarchies can be provided by system users, domain experts, or knowledge engineers. The mappings
are typically data- or application-specic. Concept hierarchies can often be automatically discovered or dynamically
rened based on statistical analysis of the data distribution. The automatic generation of concept hierarchies is
discussed in detail in Chapter 3.
CHAPTER 4. PRIMITIVES FOR DATA MINING
8
location
level 0
all
all
...
Canada
country
province_or_state
Vancouver
city
Ontario ... Quebec
British
Columbia
...
...
...
Victoria
level 1
USA
Toronto
...
...
Montreal
...
New York
California
...
...
New York
...
...
Illinois
level 2
...
Los Angeles...San Francisco Chicago
... level 3
Figure 4.3: A concept hierarchy for the dimension location.
location
all
language_used
English
Vancouver
Toronto
...
...
level 1
French
Spanish
...
city
level 0
all
New York Miami
...
...
Montreal
...
Figure 4.4: Another concept hierarchy for the dimension location, based on language.
level 2
4.1. DATA MINING PRIMITIVES: WHAT DEFINES A DATA MINING TASK?
9
There may be more than one concept hierarchy for a given attribute or dimension, based on dierent user
viewpoints. Suppose, for instance, that a regional sales manager of AllElectronics is interested in studying the
buying habits of customers at dierent locations. The concept hierarchy for location of Figure 4.3 should be useful
for such a mining task. Suppose that a marketing manager must devise advertising campaigns for AllElectronics.
This user may prefer to see location organized with respect to linguistic lines (e.g., including English for Vancouver,
Montreal and New York; French for Montreal; Spanish for New York and Miami; and so on) in order to facilitate
the distribution of commercial ads. This alternative hierarchy for location is illustrated in Figure 4.4. Note that
this concept hierarchy forms a lattice, where the node \New York" has two parent nodes, namely \English" and
\Spanish".
There are four major types of concept hierarchies. Chapter 2 introduced the most common types | schema hierarchies and set-grouping hierarchies, which we review here. In addition, we also study operation-derived hierarchies
and rule-based hierarchies.
1. A schema hierarchy (or more rigorously, a schema-dened hierarchy) is a total or partial order among
attributes in the database schema. Schema hierarchies may formally express existing semantic relationships
between attributes. Typically, a schema hierarchy species a data warehouse dimension.
Example 4.3 Given the schema of a relation for address containing the attributes street, city, province or state,
and country, we can dene a location schema hierarchy by the following total order:
street < city < province or state < country
This means that street is at a conceptually lower level than city, which is lower than province or state, which
is conceptually lower than country. A schema hierarchy provides metadata information, i.e., data about the
data. Its specication in terms of a total or partial order among attributes is more concise than an equivalent
denition that lists all instances of streets, provinces or states, and countries.
Recall that when specifying the task-relevant data, the user species relevant attributes for exploration. If
a user had specied only one attribute pertaining to location, say, city, other attributes pertaining to any
schema hierarchy containing city may automatically be considered relevant attributes as well. For instance,
the attributes street, province or state, and country may also be automatically included for exploration. 2
2. A set-grouping hierarchy organizes values for a given attribute or dimension into groups of constants or
range values. A total or partial order can be dened among groups. Set-grouping hierarchies can be used to
rene or enrich schema-dened hierarchies, when the two types of hierarchies are combined. They are typically
used for dening small sets of object relationships.
Example 4.4 A set-grouping hierarchy for the attribute age can be specied in terms of ranges, as in the
following.
f20 , 39g young
f40 , 59g middle aged
f60 , 89g senior
fyoung, middle aged, seniorg all(age)
Notice that similar range specications can also be generated automatically, as detailed in Chapter 3.
2
Example 4.5 A set-grouping hierarchy may form a portion of a schema hierarchy, and vice versa. For example,
consider the concept hierarchy for location in Figure 4.3, dened as city < province or state < country. Suppose
that possible constant values for country include \Canada", \USA", \Germany", \England", and \Brazil". Setgrouping may be used to rene this hierarchy by adding an additional level above country, such as continent,
which groups the country values accordingly.
2
3. Operation-derived hierarchies are based on operations specied by users, experts, or the data mining
system. Operations can include the decoding of information-encoded strings, information extraction from
complex data objects, and data clustering.
CHAPTER 4. PRIMITIVES FOR DATA MINING
10
Example 4.6 An e-mail address or a URL of the WWW may contain hierarchy information relating de-
partments, universities (or companies), and countries. Decoding operations can be dened to extract such
information in order to form concept hierarchies.
For example, the e-mail address \[email protected]" gives the partial order, \login-name < department < university < country", forming a concept hierarchy for e-mail addresses. Similarly, the URL address \http://www.c
s.sfu.ca/research/DB/DBMiner" can be decoded so as to provide a partial order which forms the base of a concept hierarchy for URLs.
2
Example 4.7 Operations can be dened to extract information from complex data objects. For example, the
string \Ph.D. in Computer Science, UCLA, 1995" is a complex object representing a university degree. This
string contains rich information about the type of academic degree, major, university, and the year that the
degree was awarded. Operations can be dened to extract such information, forming concept hierarchies. 2
Alternatively, mathematical and statistical operations, such as data clustering and data distribution analysis
algorithms, can be used to form concept hierarchies, as discussed in Section 3.5
4. A rule-based hierarchy occurs when either a whole concept hierarchy or a portion of it is dened by a set
of rules, and is evaluated dynamically based on the current database data and the rule denition.
Example 4.8 The following rules may be used to categorize AllElectronics items as low prot margin items,
medium prot margin items, and high prot margin items, where the prot margin of an item X is dened as
the dierence between the retail price and actual cost of X. Items having a prot margin of less than $50
may be dened as low prot margin items, items earning a prot between $50 and $250 may be dened as
medium prot margin items, and items earning a prot of more than $250 may be dened as high prot margin
items.
low prot margin(X) ( price(X; P1) ^ cost(X; P 2) ^ ((P1 , P2) < $50)
medium prot margin(X) ( price(X; P1) ^ cost(X; P 2) ^ ((P1 , P2) > $50) ^ ((P1 , P2) $250)
high prot margin(X) ( price(X; P1) ^ cost(X; P2) ^ ((P1 , P2) > $250)
2
The use of concept hierarchies for data mining is described in the remaining chapters of this book.
4.1.4 Interestingness measures
Although specication of the task-relevant data and of the kind of knowledge to be mined (e.g, characterization,
association, etc.) may substantially reduce the number of patterns generated, a data mining process may still generate
a large number of patterns. Typically, only a small fraction of these patterns will actually be of interest to the given
user. Thus, users need to further conne the number of uninteresting patterns returned by the process. This can
be achieved by specifying interestingness measures which estimate the simplicity, certainty, utility, and novelty of
patterns.
In this section, we study some objective measures of pattern interestingness. Such objective measures are based on
the structure of patterns and the statistics underlying them. In general, each measure is associated with a threshold
that can be controlled by the user. Rules that do not meet the threshold are considered uninteresting, and hence are
not presented to the user as knowledge.
Simplicity. A factor contributing to the interestingness of a pattern is the pattern's overall simplicity for
human comprehension. Objective measures of pattern simplicity can be viewed as functions of the pattern
structure, dened in terms of the pattern size in bits, or the number of attributes or operators appearing in
the pattern. For example, the more complex the structure of a rule is, the more dicult it is to interpret, and
hence, the less interesting it is likely to be.
Rule length, for instance, is a simplicity measure. For rules expressed in conjunctive normal form (i.e.,
as a set of conjunctive predicates), rule length is typically dened as the number of conjuncts in the rule.
4.1. DATA MINING PRIMITIVES: WHAT DEFINES A DATA MINING TASK?
11
Association, discrimination, or classication rules whose lengths exceed a user-dened threshold are considered
uninteresting. For patterns expressed as decision trees, simplicity may be a function of the number of tree
leaves or tree nodes.
Certainty. Each discovered pattern should have a measure of certainty associated with it which assesses the
validity or \trustworthiness" of the pattern. A certainty measure for association rules of the form \A ) B," is
condence. Given a set of task-relevant data tuples (or transactions in a transaction database) the condence
of \A ) B" is dened as:
containing both A and B :
Condence(A ) B) = P(B jA) = # tuples
# tuples containing A
(4.3)
Example 4.9 Suppose that the set of task-relevant data consists of transactions from the computer department
of AllElectronics. A condence of 85% for the association rule
buys(X; \computer") ) buys(X; \software")
means that 85% of all customers who purchased a computer also bought software.
(4.4)
2
A condence value of 100%, or 1, indicates that the rule is always correct on the data analyzed. Such rules are
called exact.
For classication rules, condence is referred to as reliability or accuracy. Classication rules propose a
model for distinguishing objects, or tuples, of a target class (say, bigSpenders) from objects of contrasting
classes (say, budgetSpenders). A low reliability value indicates that the rule in question incorrectly classies
a large number of contrasting class objects as target class objects. Rule reliability is also known as rule
strength, rule quality, certainty factor, and discriminating weight.
Utility. The potential usefulness of a pattern is a factor dening its interestingness. It can be estimated
by a utility function, such as support. The support of an association pattern refers to the percentage of
task-relevant data tuples (or transactions) for which the pattern is true. For association rules of the form
\A ) B", it is dened as
containing both A and B :
Support(A ) B) = P(A [ B) = # tuples total
# of tuples
(4.5)
Example 4.10 Suppose that the set of task-relevant data consists of transactions from the computer depart-
ment of AllElectronics. A support of 30% for the association rule (4.4) means that 30% of all customers in the
computer department purchased both a computer and software.
2
Association rules that satisfy both a user-specied minimum condence threshold and user-specied minimum
support threshold are referred to as strong association rules, and are considered interesting. Rules with low
support likely represent noise, or rare or exceptional cases.
The numerator of the support equation is also known as the rule count. Quite often, this number is displayed
instead of support. Support can easily be derived from it.
Characteristic and discriminant descriptions are, in essence, generalized tuples. Any generalized tuple representing less than Y % of the total number of task-relevant tuples is considered noise. Such tuples are not
displayed to the user. The value of Y is referred to as the noise threshold.
Novelty. Novel patterns are those that contribute new information or increased performance to the given
pattern set. For example, a data exception may be considered novel in that it diers from that expected based
on a statistical model or user beliefs. Another strategy for detecting novelty is to remove redundant patterns.
If a discovered rule can be implied by another rule that is already in the knowledge base or in the derived rule
set, then either rule should be re-examined in order to remove the potential redundancy.
12
CHAPTER 4. PRIMITIVES FOR DATA MINING
Mining with concept hierarchies can result in a large number of redundant rules. For example, suppose that
the following association rules were mined from the AllElectronics database, using the concept hierarchy in
Figure 4.3 for location:
location(X; \Canada") ) buys(X; \SONY TV ")
[8%; 70%]
(4.6)
location(X; \Montreal") ) buys(X; \SONY TV ")
[2%; 71%]
(4.7)
Suppose that Rule (4.6) has 8% support and 70% condence. One may expect Rule (4.7) to have a condence
of around 70% as well, since all the tuples representing data objects for Montreal are also data objects for
Canada. Rule (4.6) is more general than Rule (4.7), and therefore, we would expect the former rule to occur
more frequently than the latter. Consequently, the two rules should not have the same support. Suppose that
about one quarter of all sales in Canada comes from Montreal. We would then expect the support of the rule
involving Montreal to be one quarter of the support of the rule involving Canada. In other words, we expect
the support of Rule (4.7) to be 8% 14 = 2%. If the actual condence and support of Rule (4.7) are as expected,
then the rule is considered redundant since it does not oer any additional information and is less general than
Rule (4.6). These ideas are further discussed in Chapter 6 on association rule mining.
The above example also illustrates that when mining knowledge at multiple levels, it is reasonable to have
dierent support and condence thresholds, depending on the degree of granularity of the knowledge in the
discovered pattern. For instance, since patterns are likely to be more scattered at lower levels than at higher
ones, we may set the minimum support threshold for rules containing low level concepts to be lower than that
for rules containing higher level concepts.
Data mining systems should allow users to exibly and interactively specify, test, and modify interestingness
measures and their respective thresholds. There are many other objective measures, apart from the basic ones
studied above. Subjective measures exist as well, which consider user beliefs regarding relationships in the data, in
addition to objective statistical measures. Interestingness measures are discussed in greater detail throughout the
book, with respect to the mining of characteristic, association, and classication rules, and deviation patterns.
4.1.5 Presentation and visualization of discovered patterns
For data mining to be eective, data mining systems should be able to display the discovered patterns in multiple
forms, such as rules, tables, crosstabs, pie or bar charts, decision trees, cubes, or other visual representations (Figure
4.5). Allowing the visualization of discovered patterns in various forms can help users with dierent backgrounds to
identify patterns of interest and to interact or guide the system in further discovery. A user should be able to specify
the kinds of presentation to be used for displaying the discovered patterns.
The use of concept hierarchies plays an important role in aiding the user to visualize the discovered patterns.
Mining with concept hierarchies allows the representation of discovered knowledge in high level concepts, which may
be more understandable to users than rules expressed in terms of primitive (i.e., raw) data, such as functional or
multivalued dependency rules, or integrity constraints. Furthermore, data mining systems should employ concept
hierarchies to implement drill-down and roll-up operations, so that users may inspect discovered patterns at multiple
levels of abstraction. In addition, pivoting (or rotating), slicing, and dicing operations aid the user in viewing
generalized data and knowledge from dierent perspectives. These operations were discussed in detail in Chapter 2.
A data mining system should provide such interactive operations for any dimension, as well as for individual values
of each dimension.
Some representation forms may be better suited than others for particular kinds of knowledge. For example,
generalized relations and their corresponding crosstabs (cross-tabulations) or pie/bar charts are good for presenting
characteristic descriptions, whereas decision trees are a common choice for classication. Interestingness measures
should be displayed for each discovered pattern, in order to help users identify those patterns representing useful
knowledge. These include condence, support, and count, as described in Section 4.1.4.
4.2 A data mining query language
Why is it important to have a data mining query language? Well, recall that a desired feature of data mining
systems is the ability to support ad-hoc and interactive data mining in order to facilitate exible and eective
knowledge discovery. Data mining query languages can be designed to support such a feature.
4.2. A DATA MINING QUERY LANGUAGE
Rules
13
Crosstab
Table
age(X, "young") and income(X, "high") => class(X, "A")
age
income
class
income
count
age(X, "young") and income(X, "low") => class(X, "B")
age(X, "old") => class(X, "C")
Pie chart
young
high
young
old
old
low
A
1,402
low
B
1038
high
C
C
786
A
1,402
1,038
1,402
786
1,374
0
0 2,160
2,188
2,412
1,402
1,038 2,160
high
young
old
1,374
class
low
age
count
Decision tree
Bar chart
1,038
0
A
class
B
old
C
class B
young
class A
income?
class C
C
Data cube
age?
young
B
class
A
class class
B
C
high
class A
class C
low
class B
age
old
high
low
income
Figure 4.5: Various forms of presenting and visualizing the discovered patterns.
The importance of the design of a good data mining query language can also be seen from observing the history
of relational database systems. Relational database systems have dominated the database market for decades. The
standardization of relational query languages, which occurred at the early stages of relational database development,
is widely credited for the success of the relational database eld. Although each commercial relational database
system has its own graphical user interace, the underlying core of each interface is a standardized relational query
language. The standardization of relational query languages provided a foundation on which relational systems were
developed, and evolved. It facilitated information exchange and technology transfer, and promoted commercialization
and wide acceptance of relational database technology. The recent standardization activities in database systems,
such as work relating to SQL-3, OMG, and ODMG, further illustrate the importance of having a standard database
language for success in the development and commercialization of database systems. Hence, having a good query
language for data mining may help standardize the development of platforms for data mining systems.
Designing a comprehensive data mining language is challenging because data mining covers a wide spectrum of
tasks, from data characterization to mining association rules, data classication, and evolution analysis. Each task
has dierent requirements. The design of an eective data mining query language requires a deep understanding of
the power, limitation, and underlying mechanisms of the various kinds of data mining tasks.
How would you design a data mining query language? Earlier in this chapter, we looked at primitives for dening
a data mining task in the form of a data mining query. The primitives specify:
the set of task-relevant data to be mined,
the kind of knowledge to be mined,
the background knowledge to be used in the discovery process,
the interestingness measures and thresholds for pattern evaluation, and
the expected representation for visualizing the discovered patterns.
Based on these primitives, we design a query language for data mining called DMQL which stands for Data
Mining Query Language. DMQL allows the ad-hoc mining of several kinds of knowledge from relational databases
and data warehouses at multiple levels of abstraction 2 .
2
DMQL syntax for dening data warehouses and data marts is given in Chapter 2.
CHAPTER 4. PRIMITIVES FOR DATA MINING
14
hDMQLi
::=
hDMQL Statementi ::=
j
j
hData Mining Statementi
hDMQL Statementi; fhDMQL Statementig
hData Mining Statmenti
hConcept Hierarchy Denition Statementi
hVisualization and Presentationi
::=
use database hdatabase namei j use data warehouse hdata warehouse namei
fuse hierarchy hhierarchy namei for hattribute or dimensionig
hMine Knowledge Specicationi
in relevance to hattribute or dimension listi
from hrelation(s)/cubei
[where hconditioni]
[order by horder listi]
[group by hgrouping listi]
[having hconditioni]
...
measure namei] threshold = hthreshold valuei [for hattribute(s)i ]g
fwith [hinterest
hMine Knowledge Specicationi::= hMine Chari j hMine Discri j hMine Associ j hMine Classi j hMine Predi
hMine Chari ::=
mine characteristics [as hpattern namei]
analyze hmeasure(s)i
hMine Discri ::=
mine comparison [as hpattern namei]
for htarget classi where htarget conditioni
fversus hcontrast class ii where hcontrast condition iig
analyze hmeasure(s)i
hMine Associ ::=
mine associations [as hpattern namei]
[matching hmetapatterni]
hMine Classi ::=
mine classication [as hpattern namei]
analyze hclassifying attribute or dimensioni
hMine Predi ::=
mine prediction [as hpattern namei]
analyze hprediction attribute or dimensioni
fset fhattribute or dimension ii= hvalue iigg
hConcept Hierarchy Dention Statementi ::=
dene hierarchy hhierarchy namei
[for hattribute or dimensioni]
on hrelation or cube or hierarchyi
as hhierarchy descriptioni
[where hconditioni]
hVisualization and Presentationi ::=
display as hresult formi
j
roll up on hattribute or dimension i
j
drill down on hattribute or dimensioni
j
add hattribute or dimensioni
j
drop hattribute or dimensioni
Figure 4.6: Top-level syntax of a data mining query language, DMQL.
4.2. A DATA MINING QUERY LANGUAGE
15
The language adopts an SQL-like syntax, so that it can easily be integrated with the relational query language,
SQL. The syntax of DMQL is dened in an extended BNF grammar, where \[ ]" represents 0 or one occurrence,
\f g" represents 0 or more occurrences, and words in sans serif font represent keywords.
In Sections 4.2.1 to 4.2.5, we develop DMQL syntax for each of the data mining primitives. In Section 4.2.6, we
show an example data mining query, specied in the proposed syntax. A top-level summary of the language is shown
in Figure 4.6.
4.2.1 Syntax for task-relevant data specication
The rst step in dening a data mining task is the specication of the task-relevant data, i.e., the data on which
mining is to be performed. This involves specifying the database and tables or data warehouse containing the
relevant data, conditions for selecting the relevant data, the relevant attributes or dimensions for exploration, and
instructions regarding the ordering or grouping of the data retrieved. DMQL provides clauses for the specication
of such information, as follows.
use database hdatabase namei, or use data warehouse hdata warehouse namei: The use clause directs the mining
task to the database or data warehouse specied.
from hrelation(s)/cube(s)i [where hconditioni]: The from and where clauses respectively specify the database
tables or data cubes involved, and the conditions dening the data to be retrieved.
in relevance to hatt or dim listi: This clause lists the attributes or dimensions for exploration.
order by horder listi: The order by clause species the sorting order of the task-relevant data.
group by hgrouping listi: The group by clause species criteria for grouping the data.
having hconditioni: The having clause species the condition by which groups of data are considered relevant.
These clauses form an SQL query to collect the task-relevant data.
Example 4.11 This example shows how to use DMQL to specify the task-relevant data described in Example 4.1
for the mining of associations between items frequently purchased at AllElectronics by Canadian customers, with
respect to customer income and age. In addition, the user species that she would like the data to be grouped by
date. The data are retrieved from a relational database.
use database AllElectronics db
in relevance to I.name, I.price, C.income, C.age
from customer C, item I, purchases P, items sold S
where I.item ID = S.item ID and S.trans ID = P.trans ID and P.cust ID = C.cust ID
and C.address = \Canada"
group by P.date
2
4.2.2 Syntax for specifying the kind of knowledge to be mined
The hMine Knowledge Specicationi statement is used to specify the kind of knowledge to be mined. In other
words, it indicates the data mining functionality to be performed. Its syntax is dened below for characterization,
discrimination, association, classication, and prediction.
1. Characterization.
hMine Knowledge Specicationi ::=
mine characteristics [as hpattern namei]
analyze hmeasure(s)i
CHAPTER 4. PRIMITIVES FOR DATA MINING
16
This species that characteristic descriptions are to be mined. The analyze clause, when used for characterization, species aggregate measures, such as count, sum, or count% (percentage count, i.e., the percentage of
tuples in the relevant data set with the specied characteristics). These measures are to be computed for each
data characteristic found.
Example 4.12 The following species that the kind of knowledge to be mined is a characteristic description
describing customer purchasing habits. For each characteristic, the percentage of task-relevant tuples satisfying
that characteristic is to be displayed.
mine characteristics as customerPurchasing
analyze count%
2
2. Discrimination.
hMine Knowledge Specicationi ::=
mine comparison [as hpattern namei]
for htarget classi where htarget conditioni
fversus hcontrast class ii where hcontrast condition iig
analyze hmeasure(s)i
This species that discriminant descriptions are to be mined. These descriptions compare a given target class of
objects with one or more other contrasting classes. Hence, this kind of knowledge is referred to as a comparison.
As for characterization, the analyze clause species aggregate measures, such as count, sum, or count%, to be
computed and displayed for each description.
Example 4.13 The user may dene categories of customers, and then mine descriptions of each category. For
instance, a user may dene bigSpenders as customers who purchase items that cost $100 or more on average,
and budgetSpenders as customers who purchase items at less than $100 on average. The mining of discriminant
descriptions for customers from each of these categories can be specied in DMQL as shown below, where I
refers to the item relation. The count of task-relevant tuples satisfying each description is to be displayed.
mine comparison as purchaseGroups
for bigSpenders where avg(I.price) $100
versus budgetSpenders where avg(I.price) < $100
analyze count
2
3. Association.
hMine Knowledge Specicationi ::=
mine associations [as hpattern namei]
[matching hmetapatterni]
This species the mining of patterns of association. When specifying association mining, the user has the option
of providing templates (also known as metapatterns or metarules) with the matching clause. The metapatterns
can be used to focus the discovery towards the patterns that match the given metapatterns, thereby enforcing
additional syntactic constraints for the mining task. In addition to providing syntactic constraints, the metapatterns represent data hunches or hypotheses that the user nds interesting for investigation. Mining with the
use of metapatterns, or metarule-guided mining, allows additional exibility for ad-hoc rule mining. While
metapatterns may be used in the mining of other forms of knowledge, they are most useful for association
mining due to the vast number of potentially generated associations.
4.2. A DATA MINING QUERY LANGUAGE
17
Example 4.14 The metapattern of Example 4.2 can be specied as follows to guide the mining of association
rules describing customer buying habits.
mine associations as buyingHabits
matching P(X : customer; W) ^ Q(X; Y ) ) buys(X; Z)
2
4. Classication.
hMine Knowledge Specicationi ::=
mine classication [as hpattern namei]
analyze hclassifying attribute or dimensioni
This species that patterns for data classication are to be mined. The analyze clause species that the classication is performed according to the values of hclassifying attribute or dimensioni. For categorical attributes
or dimensions, typically each value represents a class (such as \Vancouver", \New York", \Chicago", and so
on for the dimension location). For numeric attributes or dimensions, each class may be dened by a range
of values (such as \20-39", \40-59", \60-89" for age). Classication provides a concise framework which best
describes the objects in each class and distinguishes them from other classes.
Example 4.15 To mine patterns classifying customer credit rating where credit rating is determined by the
attribute credit info, the following DMQL specication is used:
mine classication as classifyCustomerCreditRating
analyze credit info
2
5. Prediction.
hMine Knowledge Specicationi ::=
mine prediction [as hpattern namei]
analyze hprediction attribute or dimensioni
fset fhattribute or dimension ii= hvalue iigg
This DMQL syntax is for prediction. It species the mining of missing or unknown continuous data values,
or of the data distribution, for the attribute or dimension specied in the analyze clause. A predictive model
is constructed based on the analysis of the values of the other attributes or dimensions describing the data
objects (tuples). The set clause can be used to x the values of these other attributes.
Example 4.16 To predict the retail price of a new item at AllElectronics, the following DMQL specication
is used:
mine prediction as predictItemPrice
analyze price
set category = \TV" and brand = \SONY"
The set clause species that the resulting predictive patterns regarding price are for the subset of task-relevant
data relating to SONY TV's. If no set clause is specied, then the prediction returned would be a data
distribution for all categories and brands of AllElectronics items in the task-relevant data.
2
The data mining language should also allow the specication of other kinds of knowledge to be mined, in addition
to those shown above. These include the miningof data clusters, evolution rules or sequential patterns, and deviations.
CHAPTER 4. PRIMITIVES FOR DATA MINING
18
4.2.3 Syntax for concept hierarchy specication
Concept hierarchies allow the mining of knowledge at multiple levels of abstraction. In order to accommodate the
dierent viewpoints of users with regards to the data, there may be more than one concept hierarchy per attribute
or dimension. For instance, some users may prefer to organize branch locations by provinces and states, while others
may prefer to organize them according to languages used. In such cases, a user can indicate which concept hierarchy
is to be used with the statement
use hierarchy hhierarchyi for hattribute or dimensioni.
Otherwise, a default hierarchy per attribute or dimension is used.
How can we dene concept hierarchies, using DMQL? In Section 4.1.3, we studied four types of concept hierarchies,
namely schema, set-grouping, operation-derived, and rule-based hierarchies. Let's look at the following syntax for
dening each of these hierarchy types.
1. Denition of schema hierarchies.
Example 4.17 Earlier, we dened a schema hierarchy for a relation address as the total order street < city <
province or state < country. This can be dened in the data mining query language as:
dene hierarchy location hierarchy on address as [street, city, province or state, country]
The ordering of the listed attributes is important. In fact, a total order is dened which species that street
is conceptually one level lower than city, which is in turn conceptually one level lower than province or state,
and so on.
2
Example 4.18 A data mining system will typically have a predened concept hierarchy for the schema date
(day, month, quarter, year), such as:
dene hierarchy time hierarchy on date as [day, month, quarter, year]
2
Example 4.19 Concept hierarchy denitions can involve several relations. For example, an item hierarchy
may involve two relations, item and supplier, dened by the following schema.
item(item ID; brand; type; place made; supplier)
supplier(name; type; headquarter location; owner; size; assets; revenue)
The hierarchy item hierarchy can be dened as follows:
dene hierarchy item hierarchy on item, supplier as
[item ID, brand, item.supplier, item.type, supplier.type]
where item.supplier = supplier.name
If the concept hierarchy denition contains an attribute name that is shared by two relations, then the attribute
is prexed by its relation name, using the same dot (\.") notation as in SQL (e.g., item.supplier). The join
condition of the two relations is specied by a where clause.
2
2. Denition of set-grouping hierarchies.
Example 4.20 The set-grouping hierarchy for age of Example 4.4 can be dened in terms of ranges as follows:
dene hierarchy age hierarchy for age on customer as
level1: fyoung, middle aged, seniorg < level0: all
level2: f20, .. ., 39g < level1: young
level2: f40, .. ., 59g < level1: middle aged
level2: f60, .. ., 89g < level1: senior
4.2. A DATA MINING QUERY LANGUAGE
level 0
level 1
level 2
19
all
young
20,...,39
middle_aged
senior
40,...59
60,...89
Figure 4.7: A concept hierarchy for the attribute age.
The notation \... " implicitly species all the possible values within the given range. For example, \f20, . .. ,
39g" includes all integers within the range of the endpoints, 20 and 39. Ranges may also be specied with real
numbers as endpoints. The corresponding concept hierarchy is shown in Figure 4.7. The most general concept
for age is all, and is placed at the root of the hierarchy. By convention, the all value is always at level 0 of
any hierarchy. The all node in Figure 4.7 has three child nodes, representing more specic abstractions of age,
namely young, middle aged, and senior. These are at level 1 of the hierarchy. The age ranges for each of these
level 1 concepts are dened at level 2 of the hierarchy.
2
Example 4.21 The schema hierarchy in Example 4.17 for location can be rened by adding an additional
concept level, continent.
dene hierarchy on location hierarchy as
country: fCanada, USA, Mexicog < continent: NorthAmerica
country: fEngland, France, Germany, Italyg < continent: Europe
...
continent: fNorthAmerica, Europe, Asiag < all
By listing the countries (for which AllElectronics sells merchandise) belonging to each continent, we build an
additional concept layer on top of the schema hierarchy of Example 4.17.
2
3. Denition of operation-derived hierarchies
Example 4.22 As an alternative to the set-grouping hierarchy for age in Example 4.20, a user may wish to
dene an operation-derived hierarchy for age based on data clustering routines. This is especially useful when
the values of a given attribute are not uniformly distributed. A hierarchy for age based on clustering can be
dened with the following statement:
dene hierarchy age hierarchy for age on customer as
fage category(1), . .. , age category(5)g := cluster(default, age, 5) < all(age)
This statement indicates that a default clustering algorithm is to be performed on all of the age values in
the relation customer in order to form ve clusters. The clusters are ranges with names explicitly dened as
\age category(1), .. ., age category(5)", organized in ascending order.
2
4. Denition of rule-based hierarchies
Example 4.23 A concept hierarchy can be dened based on a set of rules. Consider the concept hierarchy of
Example 4.8 for items at AllElectronics. This hierarchy is based on item prot margins, where the prot margin
of an item is dened as the dierence between the retail price of the item, and the cost incurred by AllElectronics
to purchase the item for sale. The hierarchy organizes items into low prot margin items, medium-prot margin
items, and high prot margin items, and is dened in DMQL by the following set of rules.
20
CHAPTER 4. PRIMITIVES FOR DATA MINING
dene hierarchy prot margin hierarchy on item as
level 1: low prot margin < level 0: all
if (price , cost) < $50
level 1: medium-prot margin < level 0: all
if ((price , cost) > $50) and ((price , cost) $250))
level 1: high prot margin < level 0: all
if (price , cost) > $250
2
4.2.4 Syntax for interestingness measure specication
The user can control the number of uninteresting patterns returned by the data mining system by specifying measures of pattern interestingness and their corresponding thresholds. Interestingness measures include the condence,
support, noise, and novelty measures described in Section 4.1.4. Interestingness measures and thresholds can be
specied by the user with the statement:
with [hinterest measure namei] threshold = hthreshold valuei
Example 4.24 In mining association rules, a user can conne the rules to be found by specifying a minimum support
and minimum condence threshold of 0.05 and 0.7, respectively, with the statements:
with support threshold = 0.05
with condence threshold = 0.7
2
The interestingness measures and threshold values can be set and modied interactively.
4.2.5 Syntax for pattern presentation and visualization specication
How can users specify the forms of presentation and visualization to be used in displaying the discovered patterns?
Our data mining query language needs syntax which allows users to specify the display of discovered patterns in
one or more forms, including rules, tables, crosstabs, pie or bar charts, decision trees, cubes, curves, or surfaces. We
dene the DMQL display statement for this purpose:
display as hresult formi
where the hresult formi could be any of the knowledge presentation or visualization forms listed above.
Interactive mining should allow the discovered patterns to be viewed at dierent concept levels or from dierent
angles. This can be accomplished with roll-up and drill-down operations, as described in Chapter 2. Patterns can
be rolled-up, or viewed at a more general level, by climbing up the concept hierarchy of an attribute or dimension
(replacing lower level concept values by higher level values). Generalization can also be performed by dropping
attributes or dimensions. For example, suppose that a pattern contains the attribute city. Given the location
hierarchy city < province or state < country < continent, then dropping the attribute city from the patterns will
generalize the data to the next lowest level attribute, province or state. Patterns can be drilled-down on, or viewed
at a less general level, by stepping down the concept hierarchy of an attribute or dimension. Patterns can also be
made less general by adding attributes or dimensions to their description. The attribute added must be one of the
attributes listed in the in relevance to clause for task-relevant specication. The user can alternately view the patterns
at dierent levels of abstractions with the use of the following DMQL syntax:
hMultilevel Manipulationi ::= roll up on hattribute or dimensioni
j drill down on hattribute or dimensioni
j add hattribute or dimensioni
j drop hattribute or dimensioni
Example 4.25 Suppose descriptions are mined based on the dimensions location, age, and income. One may \roll
up on location" or \drop age" to generalize the discovered patterns.
2
4.2. A DATA MINING QUERY LANGUAGE
age
30-39
40-49
20-29
30-39
40-49
.. .
type
home security system
home security system
CD player
CD player
large screen TV
. ..
21
place made count%
USA
19
USA
15
Japan
26
USA
13
Japan
8
.. .
. ..
100%
Figure 4.8: Characteristic descriptions in the form of a table, or generalized relation.
4.2.6 Putting it all together | an example of a DMQL query
In the above discussion, we presented DMQL syntax for specifying data mining queries in terms of the ve data
mining primitives. For a given query, these primitives dene the task-relevant data, the kind of knowledge to be
mined, the concept hierarchies and interestingness measures to be used, and the representation forms for pattern
visualization. Here we put these components together. Let's look at an example for the full specication of a DMQL
query.
Example 4.26 Mining characteristic descriptions. Suppose, as a marketing manager of AllElectronics, you
would like to characterize the buying habits of customers who purchase items priced at no less than $100, with respect
to the customer's age, the type of item purchased, and the place in which the item was made. For each characteristic
discovered, you would like to know the percentage of customers having that characteristic. In particular, you are
only interested in purchases made in Canada, and paid for with an American Express (\AmEx") credit card. You
would like to view the resulting descriptions in the form of a table. This data mining query is expressed in DMQL
as follows.
use database AllElectronics db
use hierarchy location hierarchy for B.address
mine characteristics as customerPurchasing
analyze count%
in relevance to C.age, I.type, I.place made
from customer C, item I, purchases P, items sold S, works at W, branch B
where I.item ID = S.item ID and S.trans ID = P.trans ID and P.cust ID = C.cust ID
and P.method paid = \AmEx" and P.empl ID = W.empl ID and W.branch ID = B.branch ID
and B.address = \Canada" and I.price 100
with noise threshold = 0.05
display as table
The data mining query is parsed to form an SQL query which retrieves the set of task-relevant data from the
AllElectronics database. The concept hierarchy location hierarchy, corresponding to the concept hierarchy of Figure
4.3 is used to generalize branch locations to high level concept levels such as \Canada". An algorithm for mining
characteristic rules, which uses the generalized data, can then be executed. Algorithms for mining characteristic
rules are introduced in Chapter 5. The mined characteristic descriptions, derived from the attributes age, type and
place made , are displayed as a table, or generalized relation (Figure 4.8). The percentage of task-relevant tuples
satisfying each generalized tuple is shown as count%. If no visualization form is specied, a default form is used. The
noise threshold of 0.05 means any generalized tuple found that represents less than 5% of the total count is omitted
from display.
2
Similarly, the complete DMQL specication of data mining queries for discrimination, association, classication,
and prediction can be given. Example queries are presented in the following chapters which respectively study the
mining of these kinds of knowledge.
CHAPTER 4. PRIMITIVES FOR DATA MINING
22
4.3 Designing graphical user interfaces based on a data mining query language
A data mining query language provides necessary primitives which allow users to communicate with data mining
systems. However, inexperienced users may nd data mining query languages awkward to use, and the syntax
dicult to remember. Instead, users may prefer to communicate with data mining systems through a Graphical User
Interface (GUI). In relational database technology, SQL serves as a standard \core" language for relational systems,
on top of which GUIs can easily be designed. Similarly, a data mining query language may serve as a \core language"
for data mining system implementations, providing a basis for the development of GUI's for eective data mining.
A data mining GUI may consist of the following functional components.
1. Data collection and data mining query composition: This component allows the user to specify taskrelevant data sets, and to compose data mining queries. It is similar to GUIs used for the specication of
relational queries.
2. Presentation of discovered patterns: This component allows the display of the discovered patterns in
various forms, including tables, graphs, charts, curves, or other visualization techniques.
3. Hierarchy specication and manipulation: This component allows for concept hierarchy specication,
either manually by the user, or automatically (based on analysis of the data at hand). In addition, this
component should allow concept hierarchies to be modied by the user, or adjusted automatically based on a
given data set distribution.
4. Manipulation of data mining primitives: This component may allow the dynamic adjustment of data
mining thresholds, as well as the selection, display, and modication of concept hierarchies. It may also allow
the modication of previous data mining queries or conditions.
5. Interactive multilevel mining: This component should allow roll-up or drill-down operations on discovered
patterns.
6. Other miscellaneous information: This component may include on-line help manuals, indexed search,
debugging, and other interactive graphical facilities.
Do you think that data mining query languages may evolve to form a standard for designing data mining GUIs?
If such an evolution is possible, the standard would facilitate data mining software development and system communication. Some GUI primitives, such as pointing to a particular point in a curve or graph, however, are dicult to
specify using a text-based data mining query language like DMQL. Alternatively, a standardized GUI-based language
may evolve and replace SQL-like data mining languages. Only time will tell.
4.4 Summary
We have studied ve primitives for specifying a data mining task in the form of a data mining query. These
primitives are the specication of task-relevant data (i.e., the data set to be mined), the kind of knowledge to
be mined (e.g., characterization, discrimination, association, classication, or prediction), background knowledge (typically in the form of concept hierarchies), interestingness measures, and knowledge presentation and
visualization techniques to be used for displaying the discovered patterns.
In dening the task-relevant data, the user species the database and tables (or data warehouse and data
cubes) containing the data to be mined, conditions for selecting and grouping such data, and the attributes (or
dimensions) to be considered during mining.
Concept hierarchies provide useful background knowledge for expressing discovered patterns in concise, high
level terms, and facilitate the mining of knowledge at multiple levels of abstraction.
Measures of pattern interestingness assess the simplicity, certainty, utility, or novelty of discovered patterns.
Such measures can be used to help reduce the number of uninteresting patterns returned to the user.
4.4. SUMMARY
23
Users should be able to specify the desired form for visualizing the discovered patterns, such as rules, tables,
charts, decision trees, cubes, graphs, or reports. Roll-up and drill-down operations should also be available for
the inspection of patterns at multiple levels of abstraction.
Data mining query languages can be designed to support ad-hoc and interactive data mining. A data
mining query language, such as DMQL, should provide commands for specifying each of the data mining
primitives, as well as for concept hierarchy generation and manipulation. Such query languages are SQL-based,
and may eventually form a standard on which graphical user interfaces for data mining can be based.
Exercises
1. List and describe the ve primitives for specifying a data mining task.
2. Suppose that the university course database for Big-University contains the following attributes: the name,
address, status (e.g., undergraduate or graduate), and major of each student, and their cumulative grade point
average (GPA).
(a) Propose a concept hierarchy for the attributes status, major, GPA, and address.
(b) For each concept hierarchy that you have proposed above, what type of concept hierarchy have you
proposed?
(c) Dene each hierarchy using DMQL syntax.
(d) Write a DMQL query to nd the characteristics of students who have an excellent GPA.
(e) Write a DMQL query to compare students majoring in science with students majoring in arts.
(f) Write a DMQL query to nd associations involving course instructors, student grades, and some other
attribute of your choice. Use a metarule to specify the format of associations you would like to nd.
Specify minimum thresholds for the condence and support of the association rules reported.
(g) Write a DMQL query to predict student grades in \Computing Science 101" based on student GPA to
date and course instructor
3. Consider association rule 4.8 below, which was mined from the student database at Big-University.
major(X; \science") ) status(X; \undergrad"):
(4.8)
Suppose that the number of students at the university (that is, the number of task-relevant data tuples) is
5000, that 56% of undergraduates at the university major in science, that 64% of the students are registered
in programs leading to undergraduate degrees, and that 70% of the students are majoring in science.
(a) Compute the condence and support of Rule (4.8).
(b) Consider Rule (4.9) below.
major(X; \biology") ) status(X; \undergrad")
[17%; 80%]
(4.9)
Suppose that 30% of science students are majoring in biology. Would you consider Rule (4.9) to be novel
with respect to Rule (4.8)? Explain.
4. The hMine Knowledge Specicationi statement can be used to specify the mining of characteristic, discriminant,
association, classication, and prediction rules. Propose a syntax for the mining of clusters.
5. Rather than requiring users to manually specify concept hierarchy denitions, some data mining systems can
generate or modify concept hierarchies automatically based on the analysis of data distributions.
(a) Propose concise DMQL syntax for the automatic generation of concept hierarchies.
(b) A concept hierarchy may be automatically adjusted to reect changes in the data. Propose concise DMQL
syntax for the automatic adjustment of concept hierarchies.
CHAPTER 4. PRIMITIVES FOR DATA MINING
24
(c) Give examples of your proposed syntax.
6. In addition to concept hierarchy creation, DMQL should also provide syntax which allows users to modify
previously dened hierarchies. This syntax should allow the insertion of new nodes, the deletion of nodes, and
the moving of nodes within the hierarchy.
To insert a new node N into level L of a hierarchy, one should specify its parent node P in the hierarchy,
unless N is at the topmost layer.
To delete node N from a hierarchy, all of its descendent nodes should be removed from the hierarchy as
well.
To move a node N to a dierent location within the hierarchy, the parent of N will change, and all of the
descendents of N should be moved accordingly.
(a) Propose DMQL syntax for each of the above operations.
(b) Show examples of your proposed syntax.
(c) For each operation, illustrate the operation by drawing the corresponding concept hierarchies (\before"
and \after").
Bibliographic Notes
A number of objective interestingness measures have been proposed in the literature. Simplicity measures are given
in Michalski [23]. The condence and support measures for association rule interestingness described in this chapter
were proposed in Agrawal, Imielinski, and Swami [1]. The strategy we described for identifying redundant multilevel
association rules was proposed in Srikant and Agrawal [31, 32]. Other objective interestingness measures have been
presented in [1, 6, 12, 17, 27, 19, 30]. Subjective measures of interestingness, which consider user beliefs regarding
relationships in the data, are discussed in [18, 21, 20, 26, 29].
The DMQL data mining query language was proposed by Han et al. [11] for the DBMiner data mining system.
Discovery Board (formerly Data Mine) was proposed by Imielinski, Virmani, and Abdulghani [13] as an application
development interface prototype involving an SQL-based operator for data mining query specication and rule
retrieval. An SQL-like operator for mining single-dimensional association rules was proposed by Meo, Psaila, and
Ceri [22], and extended by Baralis and Psaila [4]. Mining with metarules is described in Klemettinen et al. [16],
Fu and Han [9], Shen et al. [28], and Kamber et al. [14]. Other ideas involving the use of templates or predicate
constraints in mining have been discussed in [3, 7, 18, 29, 33, 25].
For a comprehensive survey of visualization techniques, see Visual Techniques for Exploring Databases by Keim
[15].
Bibliography
[1] R. Agrawal, T. Imielinski, and A. Swami. Database mining: A performance perspective. IEEE Trans. Knowledge
and Data Engineering, 5:914{925, 1993.
[2] R. Agrawal and R. Srikant. Mining sequential patterns. In Proc. 1995 Int. Conf. Data Engineering, pages 3{14,
Taipei, Taiwan, March 1995.
[3] T. Anand and G. Kahn. Opportunity explorer: Navigating large databases using knowledge discovery templates.
In Proc. AAAI-93 Workshop Knowledge Discovery in Databases, pages 45{51, Washington DC, July 1993.
[4] E. Baralis and G. Psaila. Designing templates for mining association rules. Journal of Intelligent Information
Systems, 9:7{32, 1997.
[5] R.G.G. Cattell. Object Data Management: Object-Oriented and Extended Relational Databases, Rev. Ed.
Addison-Wesley, 1994.
[6] M. S. Chen, J. Han, and P. S. Yu. Data mining: An overview from a database perspective. IEEE Trans.
Knowledge and Data Engineering, 8:866{883, 1996.
[7] V. Dhar and A. Tuzhilin. Abstract-driven pattern discovery in databases. IEEE Trans. Knowledge and Data
Engineering, 5:926{938, 1993.
[8] M. Ester, H.-P. Kriegel, and X. Xu. Knowledge discovery in large spatial databases: Focusing techniques for
ecient class identication. In Proc. 4th Int. Symp. Large Spatial Databases (SSD'95), pages 67{82, Portland,
Maine, August 1995.
[9] Y. Fu and J. Han. Meta-rule-guided mining of association rules in relational databases. In Proc. 1st Int.
Workshop Integration of Knowledge Discovery with Deductive and Object-Oriented Databases (KDOOD'95),
pages 39{46, Singapore, Dec. 1995.
[10] J. Han, Y. Cai, and N. Cercone. Data-driven discovery of quantitative rules in relational databases. IEEE
Trans. Knowledge and Data Engineering, 5:29{40, 1993.
[11] J. Han, Y. Fu, W. Wang, J. Chiang, W. Gong, K. Koperski, D. Li, Y. Lu, A. Rajan, N. Stefanovic, B. Xia, and
O. R. Zaane. DBMiner: A system for mining knowledge in large relational databases. In Proc. 1996 Int. Conf.
Data Mining and Knowledge Discovery (KDD'96), pages 250{255, Portland, Oregon, August 1996.
[12] J. Hong and C. Mao. Incremental discovery of rules and structure by hierarchical and parallel clustering. In
G. Piatetsky-Shapiro and W. J. Frawley, editors, Knowledge Discovery in Databases, pages 177{193. AAAI/MIT
Press, 1991.
[13] T. Imielinski, A. Virmani, and A. Abdulghani. DataMine { application programming interface and query
language for KDD applications. In Proc. 1996 Int. Conf. Data Mining and Knowledge Discovery (KDD'96),
pages 256{261, Portland, Oregon, August 1996.
[14] M. Kamber, J. Han, and J. Y. Chiang. Metarule-guided mining of multi-dimensional association rules using
data cubes. In Proc. 3rd Int. Conf. Knowledge Discovery and Data Mining (KDD'97), pages 207{210, Newport
Beach, California, August 1997.
25
26
BIBLIOGRAPHY
[15] D. A. Keim. Visual techniques for exploring databases. In Tutorial Notes, 3rd Int. Conf. on Knowledge Discovery
and Data Mining (KDD'97), Newport Beach, CA, Aug. 1997.
[16] M. Klemettinen, H. Mannila, P. Ronkainen, H. Toivonen, and A.I. Verkamo. Finding interesting rules from large
sets of discovered association rules. In Proc. 3rd Int. Conf. Information and Knowledge Management, pages
401{408, Gaithersburg, Maryland, Nov. 1994.
[17] A. J. Knobbe and P. W. Adriaans. Analysing binary associations. In Proc. 2nd Int. Conf. on Knowledge
Discovery and Data Mining (KDD'96), pages 311{314, Portland, OR, Aug. 1996.
[18] B. Liu, W. Hsu, and S. Chen. Using general impressions to analyze discovered classication rules. In Proc. 3rd
Int.. Conf. on Knowledge Discovery and Data Mining (KDD'97), pages 31{36, Newport Beach, CA, August
1997.
[19] J. Major and J. Mangano. Selecting among rules induced from a hurricane database. Journal of Intelligent
Information Systems, 4:39{52, 1995.
[20] C. J. Matheus and G. Piatesky-Shapiro. An application of KEFIR to the analysis of healthcare information.
In Proc. AAAI'94 Workshop Knowledge Discovery in Databases (KDD'94), pages 441{452, Seattle, WA, July
1994.
[21] C.J. Matheus, G. Piatetsky-Shapiro, and D. McNeil. Selecting and reporting what is interesting: The KEFIR
application to healthcare data. In U.M. Fayyad, G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy, editors,
Advances in Knowledge Discovery and Data Mining, pages 495{516. AAAI/MIT Press, 1996.
[22] R. Meo, G. Psaila, and S. Ceri. A new SQL-like operator for mining association rules. In Proc. 1996 Int. Conf.
Very Large Data Bases, pages 122{133, Bombay, India, Sept. 1996.
[23] R. S. Michalski. A theory and methodology of inductive learning. In Michalski et al., editor, Machine Learning:
An Articial Intelligence Approach, Vol. 1, pages 83{134. Morgan Kaufmann, 1983.
[24] R. Ng and J. Han. Ecient and eective clustering method for spatial data mining. In Proc. 1994 Int. Conf.
Very Large Data Bases, pages 144{155, Santiago, Chile, September 1994.
[25] R. Ng, L. V. S. Lakshmanan, J. Han, and A. Pang. Exploratory mining and pruning optimizations of constrained associations rules. In Proc. 1998 ACM-SIGMOD Int. Conf. Management of Data, pages 13{24, Seattle,
Washington, June 1998.
[26] G. Piatesky-Shapiro and C. J. Matheus. The interestingness of deviations. In Proc. AAAI'94 Workshop Knowledge Discovery in Databases (KDD'94), pages 25{36, Seattle, WA, July 1994.
[27] G. Piatetsky-Shapiro. Discovery, analysis, and presentation of strong rules. In G. Piatetsky-Shapiro and W. J.
Frawley, editors, Knowledge Discovery in Databases, pages 229{238. AAAI/MIT Press, 1991.
[28] W. Shen, K. Ong, B. Mitbander, and C. Zaniolo. Metaqueries for data mining. In U.M. Fayyad, G. PiatetskyShapiro, P. Smyth, and R. Uthurusamy, editors, Advances in Knowledge Discovery and Data Mining, pages
375{398. AAAI/MIT Press, 1996.
[29] A. Silberschatz and A. Tuzhilin. What makes patterns interesting in knowledge discovery systems. IEEE
Trans. on Knowledge and Data Engineering, 8:970{974, Dec. 1996.
[30] P. Smyth and R.M. Goodman. An information theoretic approch to rule induction. IEEE Trans. Knowledge
and Data Engineering, 4:301{316, 1992.
[31] R. Srikant and R. Agrawal. Mining generalized association rules. In Proc. 1995 Int. Conf. Very Large Data
Bases, pages 407{419, Zurich, Switzerland, Sept. 1995.
[32] R. Srikant and R. Agrawal. Mining quantitative association rules in large relational tables. In Proc. 1996
ACM-SIGMOD Int. Conf. Management of Data, pages 1{12, Montreal, Canada, June 1996.
[33] R. Srikant, Q. Vu, and R. Agrawal. Mining association rules with item constraints. In Proc. 3rd Int. Conf.
Knowledge Discovery and Data Mining (KDD'97), pages 67{73, Newport Beach, California, August 1997.
BIBLIOGRAPHY
27
[34] M. Stonebraker. Readings in Database Systems, 2ed. Morgan Kaufmann, 1993.
[35] T. Zhang, R. Ramakrishnan, and M. Livny. BIRCH: an ecient data clustering method for very large databases.
In Proc. 1996 ACM-SIGMOD Int. Conf. Management of Data, pages 103{114, Montreal, Canada, June 1996.
Contents
5 Concept Description: Characterization and Comparison
5.1 What is concept description? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.2 Data generalization and summarization-based characterization . . . . . . . . . . .
5.2.1 Data cube approach for data generalization . . . . . . . . . . . . . . . . . .
5.2.2 Attribute-oriented induction . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.2.3 Presentation of the derived generalization . . . . . . . . . . . . . . . . . . .
5.3 Ecient implementation of attribute-oriented induction . . . . . . . . . . . . . . .
5.3.1 Basic attribute-oriented induction algorithm . . . . . . . . . . . . . . . . . .
5.3.2 Data cube implementation of attribute-oriented induction . . . . . . . . . .
5.4 Analytical characterization: Analysis of attribute relevance . . . . . . . . . . . . .
5.4.1 Why perform attribute relevance analysis? . . . . . . . . . . . . . . . . . . .
5.4.2 Methods of attribute relevance analysis . . . . . . . . . . . . . . . . . . . .
5.4.3 Analytical characterization: An example . . . . . . . . . . . . . . . . . . . .
5.5 Mining class comparisons: Discriminating between dierent classes . . . . . . . . .
5.5.1 Class comparison methods and implementations . . . . . . . . . . . . . . .
5.5.2 Presentation of class comparison descriptions . . . . . . . . . . . . . . . . .
5.5.3 Class description: Presentation of both characterization and comparison . .
5.6 Mining descriptive statistical measures in large databases . . . . . . . . . . . . . .
5.6.1 Measuring the central tendency . . . . . . . . . . . . . . . . . . . . . . . . .
5.6.2 Measuring the dispersion of data . . . . . . . . . . . . . . . . . . . . . . . .
5.6.3 Graph displays of basic statistical class descriptions . . . . . . . . . . . . .
5.7 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.7.1 Concept description: A comparison with typical machine learning methods
5.7.2 Incremental and parallel mining of concept description . . . . . . . . . . . .
5.7.3 Interestingness measures for concept description . . . . . . . . . . . . . . .
5.8 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
i
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
1
1
2
3
3
7
10
10
11
12
12
13
15
17
17
19
20
22
22
23
25
28
28
30
30
31
ii
CONTENTS
List of Figures
5.1
5.2
5.3
5.4
5.5
5.6
5.7
5.8
5.9
Bar chart representation of the sales in 1997. . . . . .
Pie chart representation of the sales in 1997. . . . . . .
A 3-D Cube view representation of the sales in 1997. .
A boxplot for the data set of Table 5.11. . . . . . . . .
A histogram for the data set of Table 5.11. . . . . . .
A quantile plot for the data set of Table 5.11. . . . . .
A quantile-quantile plot for the data set of Table 5.11.
A scatter plot for the data set of Table 5.11. . . . . . .
A loess curve for the data set of Table 5.11. . . . . . .
iii
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
8
8
9
24
26
26
27
27
28
c J. Han and M. Kamber, 1998, DRAFT!! DO NOT COPY!! DO NOT DISTRIBUTE!!
September 15, 1999
Chapter 5
Concept Description: Characterization
and Comparison
From a data analysis point of view, data mining can be classied into two categories: descriptive data mining
and predictive data mining. The former describes the data set in a concise and summarative manner and presents
interesting general properties of the data; whereas the latter constructs one or a set of models, by performing certain
analysis on the available set of data, and attempts to predict the behavior of new data sets.
Databases usually store large amounts of data in great detail. However, users often like to view sets of summarized
data in concise, descriptive terms. Such data descriptions may provide an overall picture of a class of data or
distinguish it from a set of comparative classes. Moreover, users like the ease and exibility of having data sets
described at dierent levels of granularity and from dierent angles. Such descriptive data mining is called concept
description, and forms an important component of data mining.
In this chapter, you will learn how concept description can be performed eciently and eectively.
5.1 What is concept description?
A database management system usually provides convenient tools for users to extract various kinds of data stored
in large databases. Such data extraction tools often use database query languages, such as SQL, or report writers.
These tools, for example, may be used to locate a person's telephone number from an on-line telephone directory, or
print a list of records for all of the transactions performed in a given computer store in 1997. The retrieval of data
from databases, and the application of aggregate functions (such as summation, counting, etc.) to the data represent
an important functionality of database systems: that of query processing. Various kinds of query processing
techniques have been developed. However, query processing is not data mining. While query processing retrieves
sets of data from databases and can compute aggregate functions on the retrieved data, data mining analyzes the
data and discovers interesting patterns hidden in the database.
The simplest kind of descriptive data mining is concept description. Concept description is sometimes called
class description when the concept to be described refers to a class of objects. A concept usually refers to a
collection of data such as stereos, frequent buyers, graduate students, and so on. As a data mining task, concept
description is not a simple enumeration of the data. Instead, it generates descriptions for characterization and
comparison of the data. Characterization provides a concise and succinct summarization of the given collection
of data, while concept or class comparison (also known as discrimination) provides descriptions comparing two
or more collections of data. Since concept description involves both characterization and comparison, we will study
techniques for accomplishing each of these tasks.
There are often many ways to describe a collection of data, and dierent people may like to view the same
concept or class of objects from dierent angles or abstraction levels. Therefore, the description of a concept or a
class is usually not unique. Some descriptions may be more preferred than others, based on objective interestingness
measures regarding the conciseness or coverage of the description, or on subjective measures which consider the users'
background knowledge or beliefs. Therefore, it is important to be able to generate dierent concept descriptions
1
2
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
both eciently and conveniently.
Concept description has close ties with data generalization. Given the large amount of data stored in databases,
it is useful to be able to describe concepts in concise and succinct terms at generalized (rather than low) levels
of abstraction. Allowing data sets to be generalized at multiple levels of abstraction facilitates users in examining
the general behavior of the data. Given the AllElectronics database, for example, instead of examining individual
customer transactions, sales managers may prefer to view the data generalized to higher levels, such as summarized
by customer groups according to geographic regions, frequency of purchases per group, and customer income. Such
multiple dimensional, multilevel data generalization is similar to multidimensional data analysis in data warehouses.
In this context, concept description resembles on-line analytical processing (OLAP) in data warehouses, discussed in
Chapter 2.
\What are the dierences between concept description in large databases and on-line analytical processing?" The
fundamental dierences between the two include the following.
Data warehouses and OLAP tools are based on a multidimensionaldata model which views data in the form of a
data cube, consisting of dimensions (or attributes) and measures (aggregate functions). However, the possible
data types of the dimensions and measures for most commercial versions of these systems are restricted.
Many current OLAP systems conne dimensions to nonnumeric data1 . Similarly, measures (such as count(),
sum(), average()) in current OLAP systems apply only to numeric data. In contrast, for concept formation,
the database attributes can be of various data types, including numeric, nonnumeric, spatial, text or image.
Furthermore, the aggregation of attributes in a database may include sophisticated data types, such as the
collection of nonnumeric data, the merge of spatial regions, the composition of images, the integration of texts,
and the group of object pointers. Therefore, OLAP, with its restrictions on the possible dimension and measure
types, represents a simplied model for data analysis. Concept description in databases can handle complex
data types of the attributes and their aggregations, as necessary.
On-line analytical processing in data warehouses is a purely user-controlled process. The selection of dimensions
and the application of OLAP operations, such as drill-down, roll-up, dicing, and slicing, are directed and
controlled by the users. Although the control in most OLAP systems is quite user-friendly, users do require a
good understanding of the role of each dimension. Furthermore, in order to nd a satisfactory description of
the data, users may need to specify a long sequence of OLAP operations. In contrast, concept description in
data mining strives for a more automated process which helps users determine which dimensions (or attributes)
should be included in the analysis, and the degree to which the given data set should be generalized in order
to produce an interesting summarization of the data.
In this chapter, you will learn methods for concept description, including multilevel generalization, summarization,
characterization and discrimination. Such methods set the foundation for the implementation of two major functional
modules in data mining: multiple-level characterization and discrimination. In addition, you will also examine
techniques for the presentation of concept descriptions in multiple forms, including tables, charts, graphs, and rules.
5.2 Data generalization and summarization-based characterization
Data and objects in databases often contain detailed information at primitive concept levels. For example, the item
relation in a sales database may contain attributes describing low level item information such as item ID, name,
brand, category, supplier, place made, and price. It is useful to be able to summarize a large set of data and present it
at a high conceptual level. For example, summarizing a large set of items relating to Christmas season sales provides
a general description of such data, which can be very helpful for sales and marketing managers. This requires an
important functionality in data mining: data generalization.
Data generalization is a process which abstracts a large set of task-relevant data in a database from a relatively
low conceptual level to higher conceptual levels. Methods for the ecient and exible generalization of large data
sets can be categorized according to two approaches: (1) the data cube approach, and (2) the attribute-oriented
induction approach.
1 Note that in Chapter 3, we showed how concept hierarchies may be automatically generated from numeric data to form numeric
dimensions. This feature, however, is a result of recent research in data mining and is not available in most commercial systems.
5.2. DATA GENERALIZATION AND SUMMARIZATION-BASED CHARACTERIZATION
3
5.2.1 Data cube approach for data generalization
In the data cube approach (or OLAP approach) to data generalization, the data for analysis are stored in a
multidimensional database, or data cube. Data cubes and their use in OLAP for data generalization were described
in detail in Chapter 2. In general, the data cube approach \materializes data cubes" by rst identifying expensive
computations required for frequently-processed queries. These operations typically involve aggregate functions, such
as count(), sum(), average(), and max(). The computations are performed, and their results are stored in data
cubes. Such computations may be performed for various levels of data abstraction. These materialized views can
then be used for decision support, knowledge discovery, and many other applications.
A set of attributes may form a hierarchy or a lattice structure, dening a data cube dimension. For example,
date may consist of the attributes day, week, month, quarter, and year which form a lattice structure, and a data
cube dimension for time. A data cube can store pre-computed aggregate functions for all or some of its dimensions.
The precomputed aggregates correspond to specied group-by's of dierent sets or subsets of attributes.
Generalization and specialization can be performed on a multidimensional data cube by roll-up or drill-down
operations. A roll-up operation reduces the number of dimensions in a data cube, or generalizes attribute values to
higher level concepts. A drill-down operation does the reverse. Since many aggregate functions need to be computed
repeatedly in data analysis, the storage of precomputed results in a multidimensional data cube may ensure fast
response time and oer exible views of data from dierent angles and at dierent levels of abstraction.
The data cube approach provides an ecient implementation of data generalization, which in turn forms an
important function in descriptive data mining. However, as we pointed out in Section 5.1, most commercial data
cube implementations conne the data types of dimensions to simple, nonnumeric data and of measures to simple,
aggregated numeric values, whereas many applications may require the analysis of more complex data types. Moreover, the data cube approach cannot answer some important questions which concept description can, such as which
dimensions should be used in the description, and at what levels should the generalization process reach. Instead, it
leaves the responsibility of these decisions to the users.
In the next subsection, we introduce an alternative approach to data generalization called attribute-oriented
induction, and examine how it can be applied to concept description. Moreover, we discuss how to integrate the two
approaches, data cube and attribute-oriented induction, for concept description.
5.2.2 Attribute-oriented induction
The attribute-oriented induction approach to data generalization and summarization-based characterization was rst
proposed in 1989, a few years prior to the introduction of the data cube approach. The data cube approach can
be considered as a data warehouse-based, precomputation-oriented, materialized view approach. It performs o-line
aggregation before an OLAP or data mining query is submitted for processing. On the other hand, the attributeoriented approach, at least in its initial proposal, is a relational database query-oriented, generalization-based, on-line
data analysis technique. However, there is no inherent barrier distinguishing the two approaches based on on-line
aggregation versus o-line precomputation. Some aggregations in the data cube can be computed on-line, while
o-line precomputation of multidimensional space can speed up attribute-oriented induction as well. In fact, data
mining systems based on attribute-oriented induction, such as DBMiner, have been optimized to include such o-line
precomputation.
Let's rst introduce the attribute-oriented induction approach. We will then perform a detailed analysis of the
approach and its variations and extensions.
The general idea of attribute-oriented induction is to rst collect the task-relevant data using a relational database
query and then perform generalization based on the examination of the number of distinct values of each attribute
in the relevant set of data. The generalization is performed by either attribute removal or attribute generalization
(also known as concept hierarchy ascension). Aggregation is performed by merging identical, generalized tuples, and
accumulating their respective counts. This reduces the size of the generalized data set. The resulting generalized
relation can be mapped into dierent forms for presentation to the user, such as charts or rules.
The following series of examples illustrates the process of attribute-oriented induction.
Example 5.1 Specifying a data mining query for characterization with DMQL. Suppose that a user would
like to describe the general characteristics of graduate students in the Big-University database, given the attributes
name, gender, major, birth place, birth date, residence, phone# (telephone number), and gpa (grade point average).
4
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
A data mining query for this characterization can be expressed in the data mining query language DMQL as follows.
use Big University DB
mine characteristics as \Science Students"
in relevance to name, gender, major, birth place, birth date, residence, phone#, gpa
from student
where status in \graduate"
We will see how this example of a typical data mining query can apply attribute-oriented induction for mining
characteristic descriptions.
2
\What is the rst step of attribute-oriented induction?"
First, data focusing should be performed prior to attribute-oriented induction. This step corresponds to the
specication of the task-relevant data (or, data for analysis) as described in Chapter 4. The data are collected
based on the information provided in the data mining query. Since a data mining query is usually relevant to only
a portion of the database, selecting the relevant set of data not only makes mining more ecient, but also derives
more meaningful results than mining on the entire database.
Specifying the set of relevant attributes (i.e., attributes for mining, as indicated in DMQL with the in relevance
to clause) may be dicult for the user. Sometimes a user may select only a few attributes which she feels may
be important, while missing others that would also play a role in the description. For example, suppose that the
dimension birth place is dened by the attributes city, province or state, and country. Of these attributes, the
user has only thought to specify city. In order to allow generalization on the birth place dimension, the other
attributes dening this dimension should also be included. In other words, having the system automatically include
province or state and country as relevant attributes allows city to be generalized to these higher conceptual levels
during the induction process.
At the other extreme, a user may introduce too many attributes by specifying all of the possible attributes with
the clause \in relevance to ". In this case, all of the attributes in the relation specied by the from clause would be
included in the analysis. Many of these attributes are unlikely to contribute to an interesting description. Section
5.4 describes a method to handle such cases by ltering out statistically irrelevant or weakly relevant attributes from
the descriptive mining process.
\What does the `where status in \graduate"' clause mean?"
The above where clause implies that a concept hierarchy exists for the attribute status. Such a concept hierarchy
organizes primitive level data values for status, such as \M.Sc.", \M.A.", \M.B.A.", \Ph.D.", \B.Sc.", \B.A.", into
higher conceptual levels, such as \graduate" and \undergraduate". This use of concept hierarchies does not appear
in traditional relational query languages, yet is a common feature in data mining query languages.
Example 5.2 Transforming a data mining query to a relational query. The data mining query presented
in Example 5.1 is transformed into the following relational query for the collection of the task-relevant set of data.
use Big University DB
select name, gender, major, birth place, birth date, residence, phone#, gpa
from student
where status in f\M.Sc.", \M.A.", \M.B.A.", \Ph.D."g
The transformed query is executed against the relational database, Big University DB, and returns the data
shown in Table 5.1. This table is called the (task-relevant) initial working relation. It is the data on which
induction will be performed. Note that each tuple is, in fact, a conjunction of attribute-value pairs. Hence, we can
think of a tuple within a relation as a rule of conjuncts, and of induction on the relation as the generalization of
these rules.
2
\Now that the data are ready for attribute-oriented induction, how is attribute-oriented induction performed?"
The essential operation of attribute-oriented induction is data generalization, which can be performed in one of
two ways on the initial working relation: (1) attribute removal, or (2) attribute generalization.
5.2. DATA GENERALIZATION AND SUMMARIZATION-BASED CHARACTERIZATION
5
name
gender major
birth place
birth date
residence
phone# gpa
Jim Woodman
M
CS
Vancouver, BC, Canada 8-12-76 3511 Main St., Richmond 687-4598 3.67
Scott Lachance
M
CS
Montreal, Que, Canada 28-7-75
345 1st Ave., Vancouver 253-9106 3.70
Laura Lee
F
physics
Seattle, WA, USA
25-8-70 125 Austin Ave., Burnaby 420-5232 3.83
Table 5.1: Initial working relation: A collection of task-relevant data.
1. Attribute removal is based on the following rule: If there is a large set of distinct values for an attribute
of the initial working relation, but either (1) there is no generalization operator on the attribute (e.g., there is
no concept hierarchy dened for the attribute), or (2) its higher level concepts are expressed in terms of other
attributes, then the attribute should be removed from the working relation.
What is the reasoning behind this rule? An attribute-value pair represents a conjunct in a generalized tuple,
or rule. The removal of a conjunct eliminates a constraint and thus generalizes the rule. If, as in case 1, there
is a large set of distinct values for an attribute but there is no generalization operator for it, the attribute
should be removed because it cannot be generalized, and preserving it would imply keeping a large number
of disjuncts which contradicts the goal of generating concise rules. On the other hand, consider case 2, where
the higher level concepts of the attribute are expressed in terms of other attributes. For example, suppose
that the attribute in question is street , whose higher level concepts are represented by the attributes hcity,
province or state, countryi. The removal of street is equivalent to the application of a generalization operator.
This rule corresponds to the generalization rule known as dropping conditions in the machine learning literature
on learning-from-examples.
2. Attribute generalization is based on the following rule: If there is a large set of distinct values for an
attribute in the initial working relation, and there exists a set of generalization operators on the attribute, then
a generalization operator should be selected and applied to the attribute.
This rule is based on the following reasoning. Use of a generalization operator to generalize an attribute value
within a tuple, or rule, in the working relation will make the rule cover more of the original data tuples,
thus generalizing the concept it represents. This corresponds to the generalization rule known as climbing
generalization trees in learning-from-examples .
Both rules, attribute removal and attribute generalization, claim that if there is a large set of distinct values for
an attribute, further generalization should be applied. This raises the question: how large is \a large set of distinct
values for an attribute" considered to be?
Depending on the attributes or application involved, a user may prefer some attributes to remain at a rather
low abstraction level while others to be generalized to higher levels. The control of how high an attribute should be
generalized is typically quite subjective. The control of this process is called attribute generalization control.
If the attribute is generalized \too high", it may lead to over-generalization, and the resulting rules may not be
very informative. On the other hand, if the attribute is not generalized to a \suciently high level", then undergeneralization may result, where the rules obtained may not be informative either. Thus, a balance should be attained
in attribute-oriented generalization.
There are many possible ways to control a generalization process. Two common approaches are described below.
The rst technique, called attribute generalization threshold control, either sets one generalization thresh-
old for all of the attributes, or sets one threshold for each attribute. If the number of distinct values in an
attribute is greater than the attribute threshold, further attribute removal or attribute generalization should
be performed. Data mining systems typically have a default attribute threshold value (typically ranging from
2 to 8), and should allow experts and users to modify the threshold values as well. If a user feels that the generalization reaches too high a level for a particular attribute, she can increase the threshold. This corresponds
to drilling down along the attribute. Also, to further generalize a relation, she can reduce the threshold of a
particular attribute, which corresponds to rolling up along the attribute.
The second technique, called generalized relation threshold control, sets a threshold for the generalized
relation. If the number of (distinct) tuples in the generalized relation is greater than the threshold, further
6
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
generalization should be performed. Otherwise, no further generalization should be performed. Such a threshold
may also be preset in the data mining system (usually within a range of 10 to 30), or set by an expert or user,
and should be adjustable. For example, if a user feels that the generalized relation is too small, she can
increase the threshold, which implies drilling down. Otherwise, to further generalize a relation, she can reduce
the threshold, which implies rolling up.
These two techniques can be applied in sequence: rst apply the attribute threshold control technique to generalize
each attribute, and then apply relation threshold control to further reduce the size of the generalized relation.
Notice that no matter which generalization control technique is applied, the user should be allowed to adjust
the generalization thresholds in order to obtain interesting concept descriptions. This adjustment, as we saw above,
is similar to drilling down and rolling up, as discussed under OLAP operations in Chapter 2. However, there is a
methodological distinction between these OLAP operations and attribute-oriented induction. In OLAP, each step of
drilling down or rolling up is directed and controlled by the user; whereas in attribute-oriented induction, most of
the work is performed automatically by the induction process and controlled by generalization thresholds, and only
minor adjustments are made by the user after the automated induction.
In many database-oriented induction processes, users are interested in obtaining quantitative or statistical information about the data at dierent levels of abstraction. Thus, it is important to accumulate count and other
aggregate values in the induction process. Conceptually, this is performed as follows. A special measure, or numerical
attribute, that is associated with each database tuple is the aggregate function, count. Its value for each tuple in the
initial working relation is initialized to 1. Through attribute removal and attribute generalization, tuples within the
initial working relation may be generalized, resulting in groups of identical tuples. In this case, all of the identical
tuples forming a group should be merged into one tuple. The count of this new, generalized tuple is set to the total
number of tuples from the initial working relation that are represented by (i.e., were merged into) the new generalized
tuple. For example, suppose that by attribute-oriented induction, 52 data tuples from the initial working relation are
all generalized to the same tuple, T. That is, the generalization of these 52 tuples resulted in 52 identical instances
of tuple T. These 52 identical tuples are merged to form one instance of T, whose count is set to 52. Other popular
aggregate functions include sum and avg. For a given generalized tuple, sum contains the sum of the values of a
given numeric attribute for the initial working relation tuples making up the generalized tuple. Suppose that tuple
T contained sum(units sold) as an aggregate function. The sum value for tuple T would then be set to the total
number of units sold for each of the 52 tuples. The aggregate avg (average) is computed according to the formula,
avg = sum/count.
Example 5.3 Attribute-oriented induction. Here we show how attributed-oriented induction is performed on
the initial working relation of Table 5.1, obtained in Example 5.2. For each attribute of the relation, the generalization
proceeds as follows:
1. name: Since there are a large number of distinct values for name and there is no generalization operation
dened on it, this attribute is removed.
2. gender: Since there are only two distinct values for gender, this attribute is retained and no generalization is
performed on it.
3. major: Suppose that a concept hierarchy has been dened which allows the attribute major to be generalized
to the values fletters&science, engineering, businessg. Suppose also that the attribute generalization threshold
is set to 5, and that there are over 20 distinct values for major in the initial working relation. By attribute
generalization and attribute generalization control, major is therefore generalized by climbing the given concept
hierarchy.
4. birth place: This attribute has a large number of distinct values, therefore, we would like to generalize it.
Suppose that a concept hierarchy exists for birth place, dened as city < province or state < country. Suppose
also that the number of distinct values for country in the initial working relation is greater than the attribute
generalization threshold. In this case, birth place would be removed, since even though a generalization operator
exists for it, the generalization threshold would not be satised. Suppose instead that for our example, the
number of distinct values for country is less than the attribute generalization threshold. In this case, birth place
is generalized to birth country.
5.2. DATA GENERALIZATION AND SUMMARIZATION-BASED CHARACTERIZATION
7
5. birth date: Suppose that a hierarchy exists which can generalize birth date to age, and age to age range , and
that the number of age ranges (or intervals) is small with respect to the attribute generalization threshold.
Generalization of birth date should therefore take place.
6. residence: Suppose that residence is dened by the attributes number, street, residence city, residence province or state and residence country. The number of distinct values for number and street will likely be very high,
since these concepts are quite low level. The attributes number and street should therefore be removed, so that
residence is then generalized to residence city, which contains fewer distinct values.
7. phone#: As with the attribute name above, this attribute contains too many distinct values and should
therefore be removed in generalization.
8. gpa: Suppose that a concept hierarchy exists for gpa which groups grade point values into numerical intervals
like f3.75-4.0, 3.5-3.75, . .. g, which in turn are grouped into descriptive values, such as fexcellent, very good,
. . . g. The attribute can therefore be generalized.
The generalization process will result in groups of identical tuples. For example, the rst two tuples of Table 5.1
both generalize to the same identical tuple (namely, the rst tuple shown in Table 5.2). Such identical tuples are
then merged into one, with their counts accumulated. This process leads to the generalized relation shown in Table
5.2.
gender major birth country age range residence city
gpa
count
M
Science
Canada
20-25
Richmond very good 16
F
Science
Foreign
25-30
Burnaby
excellent
22
Table 5.2: A generalized relation obtained by attribute-oriented induction on the data of Table 4.1.
Based on the vocabulary used in OLAP, we may view count as a measure, and the remaining attributes as
dimensions. Note that aggregate functions, such as sum, may be applied to numerical attributes, like salary and
sales. These attributes are referred to as measure attributes.
The generalized relation can also be presented in other forms, as discussed in the following subsection.
2
5.2.3 Presentation of the derived generalization
\Attribute-oriented induction generates one or a set of generalized descriptions. How can these descriptions be
visualized?" The descriptions can be presented to the user in a number of dierent ways.
Generalized descriptions resulting from attribute-oriented induction are most commonly displayed in the form of
a generalized relation, such as the generalized relation presented in Table 5.2 of Example 5.3.
Example 5.4 Suppose that attribute-oriented induction was performed on a sales relation of the AllElectronics
database, resulting in the generalized description of Table 5.3 for sales in 1997. The description is shown in the form
of a generalized relation.
location
Asia
Europe
North America
Asia
Europe
North America
item
sales (in million dollars) count (in thousands)
TV
15
300
TV
12
250
TV
28
450
computer
120
1000
computer
150
1200
computer
200
1800
Table 5.3: A generalized relation for the sales in 1997.
2
8
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
Descriptions can also be visualized in the form of cross-tabulations, or crosstabs. In a two-dimensional
crosstab, each row represents a value from an attribute, and each column represents a value from another attribute.
In an n-dimensional crosstab (for n > 2), the columns may represent the values of more than one attribute, with
subtotals shown for attribute-value groupings. This representation is similar to spreadsheets. It is easy to map
directly from a data cube structure to a crosstab.
Example 5.5 The generalized relation shown in Table 5.3 can be transformed into the 3-dimensionalcross-tabulation
shown in Table 5.4.
location item
n
Asia
Europe
North America
all regions
TV
sales count
15
300
12
250
28
450
45 1000
computer
sales count
120 1000
150 1200
200 1800
470 4000
both items
sales count
135 1300
162 1450
228 2250
525 5000
Table 5.4: A crosstab for the sales in 1997.
2
Generalized data may be presented in graph forms, such as bar charts, pie charts, and curves. Visualization with
graphs is popular in data analysis. Such graphs and curves can represent 2-D or 3-D data.
Example 5.6 The sales data of the crosstab shown in Table 5.4 can be transformed into the bar chart representation
of Figure 5.1, and the pie chart representation of Figure 5.2.
2
Figure 5.1: Bar chart representation of the sales in 1997.
Figure 5.2: Pie chart representation of the sales in 1997.
Finally, a three-dimensional generalized relation or crosstab can be represented by a 3-D data cube. Such a 3-D
cube view is an attractive tool for cube browsing.
5.2. DATA GENERALIZATION AND SUMMARIZATION-BASED CHARACTERIZATION
9
Figure 5.3: A 3-D Cube view representation of the sales in 1997.
Example 5.7 Consider the data cube shown in Figure 5.3 for the dimensions item, location, and cost. The size of a
cell (displayed as a tiny cube) represents the count of the corresponding cell, while the brightness of the cell can be
used to represent another measure of the cell, such as sum(sales). Pivoting, drilling, and slicing-and-dicing operations
can be performed on the data cube browser with mouse clicking.
2
A generalized relation may also be represented in the form of logic rules. Typically, each generalized tuple
represents a rule disjunct. Since data in a large database usually span a diverse range of distributions, a single
generalized tuple is unlikely to cover, or represent, 100% of the initial working relation tuples, or cases. Thus
quantitative information, such as the percentage of data tuples which satises the left-hand side of the rule that
also satises the right-hand side the rule, should be associated with each rule. A logic rule that is associated with
quantitative information is called a quantitative rule.
To dene a quantitative characteristic rule, we introduce the t-weight as an interestingness measure which
describes the typicality of each disjunct in the rule, or of each tuple in the corresponding generalized relation. The
measure is dened as follows. Let the class of objects that is to be characterized (or described by the rule) be called
the target class. Let qa be a generalized tuple describing the target class. The t-weight for qa is the percentage of
tuples of the target class from the initial working relation that are covered by qa. Formally, we have
t weight = count(qa )=Ni=1count(qi );
(5.1)
where N is the number of tuples for the target class in the generalized relation, q1, .. ., qN are tuples for the target
class in the generalized relation, and qa is in q1, . .. , qN . Obviously, the range for the t-weight is [0, 1] (or [0%,
100%]).
A quantitative characteristic rule can then be represented either (i) in logic form by associating the corresponding t-weight value with each disjunct covering the target class, or (ii) in the relational table or crosstab form
by changing the count values in these tables for tuples of the target class to the corresponding t-weight values.
Each disjunct of a quantitative characteristic rule represents a condition. In general, the disjunction of these
conditions forms a necessary condition of the target class, since the condition is derived based on all of the cases
of the target class, that is, all tuples of the target class must satisfy this condition. However, the rule may not be
a sucient condition of the target class, since a tuple satisfying the same condition could belong to another class.
Therefore, the rule should be expressed in the form
8X; target class(X) ) condition1 (X)[t : w1] _ _ conditionn (X)[t : wn ]:
(5.2)
The rule indicates that if X is in the target class, there is a possibility of wi that X satises conditioni , where wi
is the t-weight value for condition or disjunct i, and i is in f1; : : :; ng,
10
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
Example 5.8 The crosstab shown in Table 5.4 can be transformed into logic rule form. Let the target class be the
set of computer items. The corresponding characteristic rule, in logic form, is
8X; item(X) = \computer" )
(location(X) = \Asia") [t : 25:00%] _ (location(X) = \Europe") [t : 30:00%] _
(location(X) = \North America") [t : 45:00%]
(5.3)
Notice that the rst t-weight value of 25.00% is obtained by 1000, the value corresponding to the count slot for
(computer; Asia), divided by 4000, the value corresponding to the count slot for (computer; all regions). (That is,
4000 represents the total number of computer items sold). The t-weights of the other two disjuncts were similarly
derived. Quantitative characteristic rules for other target classes can be computed in a similar fashion.
2
5.3 Ecient implementation of attribute-oriented induction
5.3.1 Basic attribute-oriented induction algorithm
Based on the above discussion, we summarize the attribute-oriented induction technique with the following algorithm
which mines generalized characteristic rules in a relational database based on a user's data mining request.
Algorithm 5.3.1 (Basic attribute-oriented induction for mining data characteristics) Mining generalized
characteristics in a relational database based on a user's data mining request.
Input. (i) A relational database DB, (ii) a data mining query, DMQuery, (iii) Gen(ai), a set of concept hierarchies
or generalization operators on attributes ai , and (iv) Ti , a set of attribute generalization thresholds for attributes ai ,
and T, a relation generalization threshold.
Output. A characteristic description based on DMQuery.
Method.
1. InitRel: Derivation of the initial working relation, W 0. This is performed by deriving a relational database
query based on the data mining query, DMQuery. The relational query is executed against the database, DB,
and the query result forms the set of task-relevant data, W 0 .
2. PreGen: Preparation of the generalization process. This is performed by (1) scanning the initial working
relation W 0 once and collecting the distinct values for each attribute ai and the number of occurrences of
each distinct value in W 0 , (2) computing the minimum desired level Li for each attribute ai based on its
given or default attribute threshold Ti , as explained further in the following paragraph, and (3) determining
the mapping-pairs (v; v ) for each attribute ai in W 0 , where v is a distinct value of ai in W 0, and v is its
corresponding generalized value at level Li .
Notice that the minimum desirable level Li of ai is determined based on a sequence of Gen operators and/or
the available concept hierarchy so that all of the distinct values for attribute ai in W 0 can be generalized to a
small number of distinct generalized concepts, where is the largest possible number of distinct generalized
values of ai in W 0 at a level of concept hierarchy which is no greater than the attribute threshold of ai. Notice
that a concept hierarchy, if given, can be adjusted or rened dynamically, or, if not given, may be generated
dynamically based on data distribution statistics, as discussed in Chapter 3.
3. PrimeGen: Derivation of the prime generalized relation, R p . This is done by (1) replacing each value
v in ai of W 0 with its corresponding ancestor concept v determined at the PreGen stage; and (2) merging
identical tuples in the working relation. This involves accumulating the count information and computing any
other aggregate values for the resulting tuples. The resulting relation is R p .
This step can be eciently implemented in two variations: (1) For each generalized tuple, insert the tuple into
a sorted prime relation R p by a binary search: if the tuple is already in R p , simply increase its count and
other aggregate values accordingly; otherwise, insert it into R p . (2) Since in most cases the number of distinct
values at the prime relation level is small, the prime relation can be coded as an m-dimensional array where
m is the number of attributes in R p , and each dimension contains the corresponding generalized attribute
values. Each array element holds the corresponding count and other aggregation values, if any. The insertion
of a generalized tuple is performed by measure aggregation in the corresponding array element.
0
0
0
5.3. EFFICIENT IMPLEMENTATION OF ATTRIBUTE-ORIENTED INDUCTION
11
4. Presentation: Presentation of the derived generalization.
Determine whether the generalization is to be presented at the abstraction level of the prime relation, or
if further enforcement of the relation generalization threshold is desired. In the latter case, further generalization is performed on R p by selecting attributes for further generalization. (This can be performed by
either interactive drilling or presetting some preference standard for such a selection). This generalization
process continues until the number of distinct generalized tuples is no greater than T. This derives the
nal generalized relation R f .
Multiple forms can be selected for visualization of the output relation. These include a (1) generalized
relation, (2) crosstab, (3) bar chart, pie chart, or curve, and (4) quantitative characteristic rule.
2
\How ecient is this algorithm?"
Let's examine its computational complexity. Step 1 of the algorithm is essentially a relational query whose
processing eciency depends on the query processing methods used. With the successful implementation and commercialization of numerous database systems, this step is expected to have good performance.
For Steps 2 & 3, the collection of the statistics of the initial working relation W 0 scans the relation only once.
The cost for computing the minimum desired level and determining the mapping pairs (v; v ) for each attribute is
dependent on the number of distinct values for each attribute and is smaller than n, the number of tuples in the
initial relation. The derivation of the prime relation R p is performed by inserting generalized tuples into the prime
relation. There are a total of n tuples in W 0 and p tuples in R p . For each tuple t in W 0 , substitute its attribute
values based on the derived mapping-pairs. This results in a generalized tuple t . If variation (1) is adopted, each
t takes O(log p) to nd the location for count incrementation or tuple insertion. Thus the total time complexity is
O(n log p) for all of the generalized tuples. If variation (2) is adopted, each t takes O(1) to nd the tuple for count
incrementation. Thus the overall time complexity is O(n) for all of the generalized tuples. (Note that the total array
size could be quite large if the array is sparse). Therefore, the worst case time complexity should be O(n log p) if
the prime relation is structured as a sorted relation, or O(n) if the prime relation is structured as a m-dimensional
array, and the array size is reasonably small.
Finally, since Step 4 for visualization works on a much smaller generalized relation, Algorithm 5.3.1 is ecient
based on this complexity analysis.
0
0
0
0
5.3.2 Data cube implementation of attribute-oriented induction
Section 5.3.1 presented a database implementation of attribute-oriented induction based on a descriptive data mining
query. This implementation, though ecient, has some limitations.
First, the power of drill-down analysis is limited. Algorithm 5.3.1 generalizes its task-relevant data from the
database primitive concept level to the prime relation level in a single step. This is ecient. However, it facilitates
only the roll up operation from the prime relation level, and the drill down operation from some higher abstraction
level to the prime relation level. It cannot drill from the prime relation level down to any lower level because the
system saves only the prime relation and the initial task-relevant data relation, but nothing in between. Further
drilling-down from the prime relation level has to be performed by proper generalization from the initial task-relevant
data relation.
Second, the generalization in Algorithm 5.3.1 is initiated by a data mining query. That is, no precomputation is
performed before a query is submitted. The performance of such query-triggered processing is acceptable for a query
whose relevant set of data is not very large, e.g., in the order of a few mega-bytes. If the relevant set of data is large,
as in the order of many giga-bytes, the on-line computation could be costly and time-consuming. In such cases, it is
recommended to perform precomputation using data cube or relational OLAP structures, as described in Chapter 2.
Moreover, many data analysis tasks need to examine a good number of dimensions or attributes. For example,
an interactive data mining system may dynamically introduce and test additional attributes rather than just those
specied in the mining query. Advanced descriptive data mining tasks, such as analytical characterization (to be
discussed in Section 5.4), require attribute relevance analysis for a large set of attributes. Furthermore, a user with
little knowledge of the truly relevant set of data may simply specify \in relevance to " in the mining query. In
these cases, the precomputation of aggregation values will speed up the analysis of a large number of dimensions or
attributes.
The data cube implementation of attribute-oriented induction can be performed in two ways.
12
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
Construct a data cube on-the-y for the given data mining query: The rst method constructs a data
cube dynamically based on the task-relevant set of data. This is desirable if either the task-relevant data set is
too specic to match any predened data cube, or it is not very large. Since such a data cube is computed only
after the query is submitted, the major motivation for constructing such a data cube is to facilitate ecient
drill-down analysis. With such a data cube, drilling-down below the level of the prime relation will simply
require retrieving data from the cube, or performing minor generalization from some intermediate level data
stored in the cube instead of generalization from the primitive level data. This will speed up the drill-down
process. However, since the attribute-oriented data generalization involves the computation of a query-related
data cube, it may involve more processing than simple computation of the prime relation and thus increase the
response time. A balance between the two may be struck by computing a cube-structured \subprime" relation
in which each dimension of the generalized relation is a few levels deeper than the level of the prime relation.
This will facilitate drilling-down to these levels with a reasonable storage and processing cost, although further
drilling-down beyond these levels will still require generalization from the primitive level data. Notice that such
further drilling-down is more likely to be localized, rather than spread out over the full spectrum of the cube.
Use a predened data cube: The second alternative is to construct a data cube before a data mining
query is posed to the system, and use this predened cube for subsequent data mining. This is desirable
if the granularity of the task-relevant data can match that of the predened data cube and the set of taskrelevant data is quite large. Since such a data cube is precomputed, it facilitates attribute relevance analysis,
attribute-oriented induction, dicing and slicing, roll-up, and drill-down. The cost one must pay is the cost of
cube computation and the nontrivial storage overhead. A balance between the computation/storage overheads
and the accessing speed may be attained by precomputing a selected set of all of the possible materializable
cuboids, as explored in Chapter 2.
5.4 Analytical characterization: Analysis of attribute relevance
5.4.1 Why perform attribute relevance analysis?
The rst limitation of class characterization for multidimensional data analysis in data warehouses and OLAP tools
is the handling of complex objects. This was discussed in Section 5.2. The second limitation is the lack of an
automated generalization process: the user must explicitly tell the system which dimensions should be included in
the class characterization and to how high a level each dimension should be generalized. Actually, each step of
generalization or specialization on any dimension must be specied by the user.
Usually, it is not dicult for a user to instruct a data mining system regarding how high a level each dimension
should be generalized. For example, users can set attribute generalization thresholds for this, or specify which level
a given dimension should reach, such as with the command \generalize dimension location to the country level". Even
without explicit user instruction, a default value such as 2 to 8 can be set by the data mining system, which would
allow each dimension to be generalized to a level that contains only 2 to 8 distinct values. If the user is not satised
with the current level of generalization, she can specify dimensions on which drill-down or roll-up operations should
be applied.
However, it is nontrivial for users to determine which dimensions should be included in the analysis of class
characteristics. Data relations often contain 50 to 100 attributes, and a user may have little knowledge regarding
which attributes or dimensions should be selected for eective data mining. A user may include too few attributes
in the analysis, causing the resulting mined descriptions to be incomplete or incomprehensive. On the other hand,
a user may introduce too many attributes for analysis (e.g., by indicating \in relevance to ", which includes all the
attributes in the specied relations).
Methods should be introduced to perform attribute (or dimension) relevance analysis in order to lter out statistically irrelevant or weakly relevant attributes, and retain or even rank the most relevant attributes for the descriptive
mining task at hand. Class characterization which includes the analysis of attribute/dimension relevance is called
analytical characterization. Class comparison which includes such analysis is called analytical comparison.
Intuitively, an attribute or dimension is considered highly relevant with respect to a given class if it is likely that
the values of the attribute or dimension may be used to distinguish the class from others. For example, it is unlikely
that the color of an automobile can be used to distinguish expensive from cheap cars, but the model, make, style, and
number of cylinders are likely to be more relevant attributes. Moreover, even within the same dimension, dierent
5.4. ANALYTICAL CHARACTERIZATION: ANALYSIS OF ATTRIBUTE RELEVANCE
13
levels of concepts may have dramatically dierent powers for distinguishing a class from others. For example, in
the birth date dimension, birth day and birth month are unlikely relevant to the salary of employees. However, the
birth decade (i.e., age interval) may be highly relevant to the salary of employees. This implies that the analysis
of dimension relevance should be performed at multilevels of abstraction, and only the most relevant levels of a
dimension should be included in the analysis.
Above we said that attribute/dimension relevance is evaluated based on the ability of the attribute/dimension
to distinguish objects of a class from others. When mining a class comparison (or discrimination), the target class
and the contrasting classes are explicitly given in the mining query. The relevance analysis should be performed by
comparison of these classes, as we shall see below. However, when mining class characteristics, there is only one class
to be characterized. That is, no contrasting class is specied. It is therefore not obvious what the contrasting class
to be used in the relevance analysis should be. In this case, typically, the contrasting class is taken to be the set of
comparable data in the database which excludes the set of the data to be characterized. For example, to characterize
graduate students, the contrasting class is composed of the set of students who are registered but are not graduate
students.
5.4.2 Methods of attribute relevance analysis
There have been many studies in machine learning, statistics, fuzzy and rough set theories, etc. on attribute relevance
analysis. The general idea behind attribute relevance analysis is to compute some measure which is used to quantify
the relevance of an attribute with respect to a given class. Such measures include the information gain, Gini index,
uncertainty, and correlation coecients.
Here we introduce a method which integrates an information gain analysis technique (such as that presented in the
ID3 and C4.5 algorithms for learning decision trees2 ) with a dimension-based data analysis method. The resulting
method removes the less informative attributes, collecting the more informative ones for use in class description
analysis.
We rst examine the information-theoretic approach applied to the analysis of attribute relevance. Let's
take ID3 as an example. ID3 constructs a decision tree based on a given set of data tuples, or training objects,
where the class label of each tuple is known. The decision tree can then be used to classify objects for which the
class label is not known. To build the tree, ID3 uses a measure known as information gain to rank each attribute.
The attribute with the highest information gain is considered the most discriminating attribute of the given set. A
tree node is constructed to represent a test on the attribute. Branches are grown from the test node according to
each of the possible values of the attribute, and the given training objects are partitioned accordingly. In general, a
node containing objects which all belong to the same class becomes a leaf node and is labeled with the class. The
procedure is repeated recursively on each non-leaf partition of objects, until no more leaves can be created. This
attribute selection process minimizes the expected number of tests to classify an object. When performing descriptive
mining, we can use the information gain measure to perform relevance analysis, as we shall show below.
\How does the information gain calculation work?" Let S be a set of training objects where the class label of
each object is known. (Each object is in fact a tuple. One attribute is used to determine the class of the objects).
Suppose that there are m classes. Let S contain si objects of class Ci , for i = 1; : : :; m. An arbitrary object belongs
to class Ci with probability si /s, where s is the total number of objects in set S. When a decision tree is used to
classify an object, it returns a class. A decision tree can thus be regarded as a source of messages for Ci's with the
expected information needed to generate this message given by
I(s1 ; s2; : : :; sm ) = ,
m s
X
i log si :
i=1
s
2
s
(5.4)
If an attribute A with values fa1 ; a2; ; av g is used as the test at the root of the decision tree, it will partition S
into the subsets fS1 ; S2 ; ; Sv g, where Sj contains those objects in S that have value aj of A. Let Sj contain sij
objects of class Ci . The expected information based on this partitioning by A is known as the entropy of A. It is the
2 A decision tree is a ow-chart-like tree structure, where each node denotes a test on an attribute, each branch represents an outcome
of the test, and tree leaves represent classes or class distributions. Decision trees are useful for classication, and can easily be converted
to logic rules. Decision tree induction is described in Chapter 7.
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
14
weighted average:
E(A) =
Xv s j + + smj I(s
1
j =1
s
1
j ; : : :; smj ):
(5.5)
The information gained by branching on A is dened by:
Gain(A) = I(s1 ; s2 ; : : :; sm ) , E(A):
(5.6)
ID3 computes the information gain for each of the attributes dening the objects in S. The attribute which maximizes
Gain(A) is selected, a tree root node to test this attribute is created, and the objects in S are distributed accordingly
into the subsets S1 ; S2; ; Sm . ID3 uses this process recursively on each subset in order to form a decision tree.
Notice that class characterization is dierent from the decision tree-based classication analysis. The former
identies a set of informative attributes for class characterization, summarization and comparison, whereas the latter
constructs a model in the form of a decision tree for classication of unknown data (i.e., data whose class label is
not known) in the future. Therefore, for the purpose of class description, only the attribute relevance analysis step
of the decision tree construction process is performed. That is, rather than constructing a decision tree, we will use
the information gain measure to rank and select the attributes to be used in class description.
Attribute relevance analysis for class description is performed as follows.
1. Collect data for both the target class and the contrasting class by query processing.
Notice that for class comparison, both the target class and the contrasting class are provided by the user in
the data mining query. For class characterization, the target class is the class to be characterized, whereas the
contrasting class is the set of comparable data which are not in the target class.
2. Identify a set of dimensions and attributes on which the relevance analysis is to be performed.
Since dierent levels of a dimension may have dramatically dierent relevance with respect to a given class, each
attribute dening the conceptual levels of the dimension should be included in the relevance analysis in principle. However, although attributes having a very large number of distinct values (such as name and phone#)
may return nontrivial relevance measure values, they are unlikely to be meaningful for concept description.
Thus, such attributes should rst be removed or generalized before attribute relevance analysis is performed.
Therefore, only the dimensions and attributes remaining after attribute removal and attribute generalization
should be included in the relevance analysis. The thresholds used for attributes in this step are called the attribute analytical thresholds. To be conservative in this step, note that the attribute analytical threshold
should be set reasonably large so as to allow more attributes to be considered in the relevance analysis. The
relation obtained by such an attribute removal and attribute generalization process is called the candidate
relation of the mining task.
3. Perform relevance analysis for each attribute in the candidation relation.
The relevance measure used in this step may be built into the data mining system, or provided by the user
(depending on whether the system is exible enough to allow users to dene their own relevance measurements).
For example, the information gain measure described above may be used. The attributes are then sorted (i.e.,
ranked) according to their computed relevance to the data mining task.
4. Remove from the candidate relation the attributes which are not relevant or are weakly relevant to the class
description task.
A threshold may be set to dene \weakly relevant". This step results in an initial target class working
relation and an initial contrasting class working relation.
If the class description task is class characterization, only the initial target class working relation will be included
in further analysis. If the class description task is class comparison, both the initial target class working relation
and the initial contrasting class working relation will be included in further analysis.
The above discussion is summarized in the following algorithm for analytical characterization in relational
databases.
5.4. ANALYTICAL CHARACTERIZATION: ANALYSIS OF ATTRIBUTE RELEVANCE
15
Algorithm 5.4.1 (Analytical characterization) Mining class characteristic descriptions by performing both attribute relevance analysis and class characterization.
Input. 1. A mining task for characterization of a specied set of data from a relational database,
2.
3.
4.
5.
Gen(ai ), a set of concept hierarchies or generalization operators on attributes ai ,
Ui , a set of attribute analytical thresholds for attributes ai,
Ti , a set of attribute generalization thresholds for attributes ai, and
R, an attribute relevance threshold .
Output. Class characterization presented in user-specied visualization formats.
Method. 1. Data collection: Collect data for both the target class and the contrasting class by query processing,
where the target class is the class to be characterized, and the contrasting class is the set of comparable
data which are in the database but are not in the target class.
2. Analytical generalization: Perform attribute removal and attribute generalization based on the set
of provided attribute analytical thresholds, Ui . That is, if the attribute contains many distinct values,
it should be either removed or generalized to satisfy the thresholds. This process identies the set of
attributes on which the relevance analysis is to be performed. The resulting relation is the candidate
relation.
3. Relevance analysis: Perform relevance analysis for each attribute of the candidate relation using the
specied relevance measurement. The attributes are ranked according to their computed relevance to the
data mining task.
4. Initial working relation derivation: Remove from the candidate relation the attributes which are not
relevant or are weakly relevant to the class description task, based on the attribute relevance threshold, R.
Then remove the contrasting class. The result is called the initial (target class) working relation.
5. Induction on the initial working relation: Perform attribute-oriented induction according to Algorithm 5.3.1, using the attribute generalization thresholds, Ti .
2
Since the algorithm is derived following the reasoning provided before the algorithm, its correctness can be
proved accordingly. The complexity of the algorithm is similar to the attribute-oriented induction algorithm since
the induction process is performed twice in both analytical generalization (Step 2) and induction on the initial
working relation (Step 5). Relevance analysis (Step 3) is performed by scanning through the database once to derive
the probability distribution for each attribute.
5.4.3 Analytical characterization: An example
If the mined class descriptions involve many attributes, analytical characterization should be performed. This
procedure rst removes irrelevant or weakly relevant attributes prior to performing generalization. Let's examine an
example of such an analytical mining process.
Example 5.9 Suppose that we would like to mine the general characteristics describing graduate students at BigUniversity using analytical characterization. Given are the attributes name, gender, major, birth place, birth date,
phone#, and gpa.
\How is the analytical characterization performed?"
1. In Step 1, the target class data are collected, consisting of the set of graduate students. Data for a contrasting
class are also required in order to perform relevance analysis. This is taken to be the set of undergraduate
students.
2. In Step 2, analytical generalization is performed in the form of attribute removal and attribute generalization.
Similar to Example 5.3, the attributes name and phone# are removed because their number of distinct values
exceeds their respective attribute analytical thresholds. Also as in Example 5.3, concept hierarchies are used
to generalize birth place to birth country, and birth date to age range. The attributes major and gpa are also
generalized to higher abstraction levels using the concept hierarchies described in Example 5.3. Hence, the
attributes remaining for the candidate relation are gender, major, birth country, age range, and gpa. The
resulting relation is shown in Table 5.5.
16
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
gender
major
birth country age range
M
Science
Canada
20-25
F
Science
Foreign
25-30
M
Engineering
Foreign
25-30
F
Science
Foreign
25-30
M
Science
Canada
20-25
F
Engineering
Canada
20-25
Target class: Graduate students
gpa
count
very good 16
excellent
22
excellent
18
excellent
25
excellent
21
excellent
18
gender
major
birth country age range
gpa
count
M
Science
Foreign
<20
very good 18
F
Business
Canada
<20
fair
20
M
Business
Canada
<20
fair
22
F
Science
Canada
20-25
fair
24
M
Engineering
Foreign
20-25
very good 22
F
Engineering
Canada
< 20
excellent
24
Contrasting class: Undergraduate students
Table 5.5: Candidate relation obtained for analytical characterization: the target class and the contrasting class.
3. In Step 3, relevance analysis is performed on the attributes in the candidate relation. Let C1 correspond to
the class graduate and class C2 correspond to undergraduate. There are 120 samples of class graduate and 130
samples of class undergraduate. To compute the information gain of each attribute, we rst use Equation (5.4)
to compute the expected information needed to classify a given sample. This is:
120 log 120 , 130 log 130 = 0:9988
I(s1 ; s2) = I(120; 130) = , 250
2
250 250 2 250
Next, we need to compute the entropy of each attribute. Let's try the attribute major. We need to look at
the distribution of graduate and undergraduate students for each value of major. We compute the expected
information for each of these distributions.
for major = \Science":
s11 = 84
s21 = 42
I(s11 ; s21 ) = 0.9183
for major = \Engineering":
s12 = 36
s22 = 46
I(s12 ; s22 ) = 0.9892
for major = \Business":
s13 = 0
s23 = 42
I(s13 ; s23 ) = 0
Using Equation (5.5), the expected information needed to classify a given sample if the samples are partitioned
according to major, is:
82
42
E(major) = 126
250 I(s11 ; s21) + 250 I(s12 ; s22) + 250 I(s13 ; s23) = 0:7873
Hence, the gain in information from such a partitioning would be:
Gain(age) = I(s1 ; s2 ) , E(major) = 0:2115
Similarly, we can compute the information gain for each of the remaining attributes. The information gain for
each attribute, sorted in increasing order, is : 0.0003 for gender, 0.0407 for birth country, 0.2115 for major,
0.4490 for gpa, and 0.5971 for age range.
4. In Step 4, suppose that we use an attribute relevance threshold of 0.1 to identify weakly relevant attributes. The
information gain of the attributes gender and birth country are below the threshold, and therefore considered
weakly relevant. Thus, they are removed. The contrasting class is also removed, resulting in the initial target
class working relation.
5. In Step 5, attribute-oriented induction is applied to the initial target class working relation, following Algorithm
5.3.1.
2
5.5. MINING CLASS COMPARISONS: DISCRIMINATING BETWEEN DIFFERENT CLASSES
17
5.5 Mining class comparisons: Discriminating between dierent classes
In many applications, one may not be interested in having a single class (or concept) described or characterized,
but rather would prefer to mine a description which compares or distinguishes one class (or concept) from other
comparable classes (or concepts). Class discrimination or comparison (hereafter referred to as class comparison)
mines descriptions which distinguish a target class from its contrasting classes. Notice that the target and contrasting
classes must be comparable in the sense that they share similar dimensions and attributes. For example, the three
classes person, address, and item are not comparable. However, the sales in the last three years are comparable
classes, and so are computer science students versus physics students.
Our discussions on class characterization in the previous several sections handle multilevel data summarization
and characterization in a single class. The techniques developed should be able to be extended to handle class
comparison across several comparable classes. For example, attribute generalization is an interesting method used in
class characterization. When handling multiple classes, attribute generalization is still a valuable technique. However,
for eective comparison, the generalization should be performed synchronously among all the classes compared so
that the attributes in all of the classes can be generalized to the same levels of abstraction. For example, suppose
we are given the AllElectronics data for sales in 1999 and sales in 1998, and would like to compare these two classes.
Consider the dimension location with abstractions at the city, province or state, and country levels. Each class of
data should be generalized to the same location level. That is, they are synchronously all generalized to either the
city level, or the province or state level, or the country level. Ideally, this is more useful than comparing, say, the sales
in Vancouver in 1998 with the sales in U.S.A. in 1999 (i.e., where each set of sales data are generalized to dierent
levels). The users, however, should have the option to over-write such an automated, synchronous comparison with
their own choices, when preferred.
5.5.1 Class comparison methods and implementations
\How is class comparison performed?"
In general, the procedure is as follows.
1. Data collection: The set of relevant data in the database is collected by query processing and is partitioned
respectively into a target class and one or a set of contrasting class(es) .
2. Dimension relevance analysis: If there are many dimensions and analytical class comparison is desired,
then dimension relevance analysis should be performed on these classes as described in Section 5.4, and only
the highly relevant dimensions are included in the further analysis.
3. Synchronous generalization: Generalization is performed on the target class to the level controlled by
a user- or expert-specied dimension threshold, which results in a prime target class relation/cuboid.
The concepts in the contrasting class(es) are generalized to the same level as those in the prime target class
relation/cuboid, forming the prime contrasting class(es) relation/cuboid.
4. Drilling down, rolling up, and other OLAP adjustment: Synchronous or asynchronous (when such an
option is allowed) drill-down, roll-up, and other OLAP operations, such as dicing, slicing, and pivoting, can be
performed on the target and contrasting classes based on the user's instructions.
5. Presentation of the derived comparison: The resulting class comparison description can be visualized
in the form of tables, graphs, and rules. This presentation usually includes a \contrasting" measure (such as
count%) which reects the comparison between the target and contrasting classes.
The above discussion outlines a general algorithm for mining analytical class comparisons in databases. In comparison with Algorithm 5.4.1 which mines analytical class characterization, the above algorithm involves synchronous
generalization of the target class with the contrasting classes so that classes are simultaneously compared at the same
levels of abstraction.
\Can class comparison mining be implemented eciently using data cube techniques?" Yes | the procedure is
similar to the implementation for mining data characterizations discussed in Section 5.3.2. A ag can be used to
indicate whether or not a tuple represents a target or contrasting class, where this ag is viewed as an additional
dimension in the data cube. Since all of the other dimensions of the target and contrasting classes share the same
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
18
portion of the cube, the synchronous generalization and specialization are realized automatically by rolling up and
drilling down in the cube.
Let's study an example of mining a class comparison describing the graduate students and the undergraduate
students at Big-University.
Example 5.10 Mining a class comparison. Suppose that you would like to compare the general properties
between the graduate students and the undergraduate students at Big-University , given the attributes name, gender,
major, birth place, birth date, residence, phone#, and gpa (grade point average).
This data mining task can be expressed in DMQL as follows.
use Big University DB
mine comparison as \grad vs undergrad students"
in relevance to name, gender, major, birth place, birth date, residence, phone#, gpa
for \graduate students"
where status in \graduate"
versus \undergraduate students"
where status in \undergraduate"
analyze count%
from student
Let's see how this typical example of a data mining query for mining comparison descriptions can be processed.
name
gender major
birth place
birth date
residence
phone# gpa
Jim Woodman
M
CS
Vancouver, BC, Canada 8-12-76 3511 Main St., Richmond 687-4598 3.67
Scott Lachance
M
CS
Montreal, Que, Canada 28-7-75
345 1st Ave., Vancouver 253-9106 3.70
Laura Lee
F
Physics
Seattle, WA, USA
25-8-70 125 Austin Ave., Burnaby 420-5232 3.83
Target class: Graduate students
name
gender
major
birth place
birth date
residence
phone# gpa
Bob Schumann
M
Chemistry Calgary, Alt, Canada 10-1-78
2642 Halifax St., Burnaby 294-4291 2.96
Amy Eau
F
Biology Golden, BC, Canada 30-3-76 463 Sunset Cres., Vancouver 681-5417 3.52
Contrasting class: Undergraduate students
Table 5.6: Initial working relations: the target class vs. the contrasting class.
1. First, the query is transformed into two relational queries which collect two sets of task-relevant data: one
for the initial target class working relation, and the other for the initial contrasting class working relation, as
shown in Table 5.6. This can also be viewed as the construction of a data cube, where the status fgraduate,
undergraduateg serves as one dimension, and the other attributes form the remaining dimensions.
2. Second, dimension relevance analysis is performed on the two classes of data. After this analysis, irrelevant or
weakly relevant dimensions, such as name, gender, major, and phone# are removed from the resulting classes.
Only the highly relevant attributes are included in the subsequent analysis.
3. Third, synchronous generalization is performed: Generalization is performed on the target class to the levels
controlled by user- or expert-specied dimension thresholds, forming the prime target class relation/cuboid. The
contrasting class is generalized to the same levels as those in the prime target class relation/cuboid, forming
the prime contrasting class(es) relation/cuboid, as presented in Table 5.7. The table shows that in comparison
with undergraduate students, graduate students tend to be older and have a higher GPA, in general.
4. Fourth, drilling and other OLAP adjustment are performed on the target and contrasting classes, based on the
user's instructions to adjust the levels of abstractions of the resulting description, as necessary.
5.5. MINING CLASS COMPARISONS: DISCRIMINATING BETWEEN DIFFERENT CLASSES
19
birth country age range
gpa
count%
Canada
20-25
good
5.53%
Canada
25-30
good
2.32%
Canada
over 30 very good 5.86%
other
over 30
excellent 4.68%
Prime generalized relation for the target class: Graduate students
birth country age range
Canada
15-20
Canada
15-20
gpa
fair
good
count%
5.53%
4.53%
Canada
25-30
good
5.02%
other
over 30 excellent 0.68%
Prime generalized relation for the contrasting class: Undergraduate students
Table 5.7: Two generalized relations: the prime target class relation and the prime contrasting class relation.
5. Finally, the resulting class comparison is presented in the form of tables, graphs, and/or rules. This visualization
includes a contrasting measure (such as count%) which compares between the target class and the contrasting
class. For example, only 2.32% of the graduate students were born in Canada, are between 25-30 years of age,
and have a \good" GPA, while 5.02% of undergraduates have these same characteristics.
2
5.5.2 Presentation of class comparison descriptions
\How can class comparison descriptions be visualized?"
As with class characterizations, class comparisons can be presented to the user in various kinds of forms, including
generalized relations, crosstabs, bar charts, pie charts, curves, and rules. With the exception of logic rules, these
forms are used in the same way for characterization as for comparison. In this section, we discuss the visualization
of class comparisons in the form of discriminant rules.
As is similar with characterization descriptions, the discriminative features of the target and contrasting classes
of a comparison description can be described quantitatively by a quantitative discriminant rule, which associates a
statistical interestingness measure, d-weight, with each generalized tuple in the description.
Let qa be a generalized tuple, and Cj be the target class, where qa covers some tuples of the target class. Note
that it is possible that qa also covers some tuples of the contrasting classes, particularly since we are dealing with
a comparison description. The d-weight for qa is the ratio of the number of tuples from the initial target class
working relation that are covered by qa to the total number of tuples in both the initial target class and contrasting
class working relations that are covered by qa . Formally, the d-weight of qa for the class Cj is dened as
d weight = count(qa 2 Cj )=mi=1count(qa 2 Ci);
(5.7)
where m is the total number of the target and contrasting classes, Cj is in fC1 ; : : :; Cm g, and count(qa 2 Ci ) is the
number of tuples of class Ci that are covered by qa. The range for the d-weight is [0, 1] (or [0%, 100%]).
A high d-weight in the target class indicates that the concept represented by the generalized tuple is primarily
derived from the target class, whereas a low d-weight implies that the concept is primarily derived from the contrasting
classes.
Example 5.11 In Example 5.10, suppose that the count distribution for the generalized tuple, \birth country =
\Canada" and age range = \25-30" and gpa = \good"" from Table 5.7 is as shown in Table 5.8.
The d-weight for the given generalized tuple is 90/(90 + 210) = 30% with respect to the target class, and 210/(90
+ 210) = 70% with respect to the contrasting class. That is, if a student was born in Canada, is in the age range
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
20
status
birth country age range gpa count
graduate
Canada
25-30
good 90
undergraduate
Canada
25-30
good 210
Table 5.8: Count distribution between graduate and undergraduate students for a generalized tuple.
of [25, 30), and has a \good" gpa, then based on the data, there is a 30% probability that she is a graduate student,
versus a 70% probability that she is an undergraduate student. Similarly, the d-weights for the other generalized
2
tuples in Table 5.7 can be derived.
A quantitative discriminant rule for the target class of a given comparison description is written in the form
8X; target class(X) ( condition(X) [d : d weight];
(5.8)
where the condition is formed by a generalized tuple of the description. This is dierent from rules obtained in class
characterization where the arrow of implication is from left to right.
Example 5.12 Based on the generalized tuple and count distribution in Example 5.11, a quantitative discriminant
rule for the target class graduate student can be written as follows:
8X; graduate student(X) ( birth country(X) = \Canada" ^ age range = \25 30" ^ gpa = \good"[d : 30%]:(5.9)
2
Notice that a discriminant rule provides a sucient condition, but not a necessary one, for an object (or tuple) to
be in the target class. For example, Rule (5.9) implies that if X satises the condition, then the probability that X
is a graduate student is 30%. However, it does not imply the probability that X meets the condition, given that X
is a graduate student. This is because although the tuples which meet the condition are in the target class, other
tuples that do not necessarily satisfy this condition may also be in the target class, since the rule may not cover all
of the examples of the target class in the database. Therefore, the condition is sucient, but not necessary.
5.5.3 Class description: Presentation of both characterization and comparison
\Since class characterization and class comparison are two aspects forming a class description, can we present both
in the same table or in the same rule?"
Actually, as long as we have a clear understanding of the meaning of the t-weight and d-weight measures and can
interpret them correctly, there is no additional diculty in presenting both aspects in the same table. Let's examine
an example of expressing both class characterization and class discrimination in the same crosstab.
Example 5.13 Let Table 5.9 be a crosstab showing the total number (in thousands) of TVs and computers sold at
AllElectronics in 1998.
location item TV computer both items
Europe
80
240
320
North America 120
560
680
both regions
200
800
1000
n
Table 5.9: A crosstab for the total number (count) of TVs and computers sold in thousands in 1998.
Let Europe be the target class and North America be the contrasting class. The t-weights and d-weights of the
sales distribution between the two classes are presented in Table 5.10. According to the table, the t-weight of a
generalized tuple or object (e.g., the tuple `item = \TV"') for a given class (e.g. the target class Europe) shows how
typical the tuple is of the given class (e.g., what proportion of these sales in Europe are for TVs?). The d-weight of
5.5. MINING CLASS COMPARISONS: DISCRIMINATING BETWEEN DIFFERENT CLASSES
location item
n
Europe
North America
both regions
TV
count t-weight d-weight
80
25%
40%
120 17.65%
60%
200
20%
100%
computer
count t-weight d-weight
240
75%
30%
560 82.35%
70%
800
80%
100%
21
both items
count t-weight d-weight
320
100%
32%
680
100%
68%
1000
100%
100%
Table 5.10: The same crosstab as in Table 4.8, but here the t-weight and d-weight values associated with each class
are shown.
a tuple shows how distinctive the tuple is in the given (target or contrasting) class in comparison with its rival class
(e.g., how do the TV sales in Europe compare with those in North America?).
For example, the t-weight for (Europe, TV) is 25% because the number of TVs sold in Europe (80 thousand)
represents only 25% of the European sales for both items (320 thousand). The d-weight for (Europe, TV) is 40%
because the number of TVs sold in Europe (80 thousand) represents 40% of the number of TVs sold in both the
target and the contrasting classes of Europe and North America, respectively (which is 200 thousand).
2
Notice that the count measure in the crosstab of Table 5.10 obeys the general property of a crosstab (i.e., the
count values per row and per column, when totaled, match the corresponding totals in the both items and both regions
slots, respectively, for count. However, this property is not observed by the t-weight and d-weight measures. This is
because the semantic meaning of each of these measures is dierent from that of count, as we explained in Example
5.13.
\Can a quantitative characteristic rule and a quantitative discriminant rule be expressed together in the form of
one rule?" The answer is yes { a quantitative characteristic rule and a quantitative discriminant rule for the same
class can be combined to form a quantitative description rule for the class, which displays the t-weights and d-weights
associated with the corresponding characteristic and discriminant rules. To see how this is done, let's quickly review
how quantitative characteristic and discriminant rules are expressed.
As discussed in Section 5.2.3, a quantitative characteristic rule provides a necessary condition for the given
target class since it presents a probability measurement for each property which can occur in the target class.
Such a rule is of the form
8X; target class(X) ) condition1 (X)[t : w1] _ _ conditionn (X)[t : wn ];
(5.10)
where each condition represents a property of the target class. The rule indicates that if X is in the target class,
the possibility that X satises conditioni is the value of the t-weight, wi, where i is in f1; : : :; ng.
As previously discussed in Section 5.5.1, a quantitative discriminant rule provides a sucient condition for the
target class since it presents a quantitative measurement of the properties which occur in the target class versus
those that occur in the contrasting classes. Such a rule is of the form
8X; target class(X) ( condition1 (X)[d : w1 ] _ _ conditionn (X)[d : wn ]:
The rule indicates that if X satises conditioni , there is a possibility of wi (the d-weight value) that x is in the
target class, where i is in f1; : : :; ng.
A quantitative characteristic rule and a quantitative discriminant rule for a given class can be combined as follows
to form a quantitative description rule: (1) For each condition, show both the associated t-weight and d-weight;
and (2) A bi-directional arrow should be used between the given class and the conditions. That is, a quantitative
description rule is of the form
8X; target class(X) , condition1 (X)[t : w1; d : w1] _ _ conditionn (X)[t : wn; d : wn]:
0
0
(5.11)
This form indicates that for i from 1 to n, if X is in the target class, there is a possibility of wi that X satises
conditioni ; and if X satises conditioni , there is a possibility of wi that X is in the target class.
0
22
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
Example 5.14 It is straightfoward to transform the crosstab of Table 5.10 in Example 5.13 into a class description
in the form of quantitative description rules. For example, the quantitative description rule for the target class,
Europe, is
8X; Europe(X) , (item(X) = \TV ") [t : 25%; d : 40%] _ (item(X) = \computer") [t : 75%; d : 30%] (5.12)
The rule states that for the sales of TV's and computers at AllElectronics in 1998, if the sale of one of these items
occurred in Europe, then the probability of the item being a TV is 25%, while that of being a computer is 75%. On
the other hand, if we compare the sales of these items in Europe and North America, then 40% of the TV's were sold
in Europe (and therefore we can deduce that 60% of the TV's were sold in North America). Furthermore, regarding
computer sales, 30% of these sales took place in Europe.
2
5.6 Mining descriptive statistical measures in large databases
Earlier in this chapter, we discussed class description in terms of popular measures, such as count, sum, and average.
Relational database systems provide ve built-in aggregate functions: count(), sum(), avg(), max(), and min().
These functions can also be computed eciently (in incremental and distributed manners) in data cubes. Thus, there
is no problem in including these aggregate functions as basic measures in the descriptive mining of multidimensional
data.
However, for many data mining tasks, users would like to learn more data characteristics regarding both central
tendency and data dispersion. Measures of central tendency include mean, median, mode, and midrange, while
measures of data dispersion include quartiles, outliers, variance, and other statistical measures. These descriptive
statistics are of great help in understanding the distribution of the data. Such measures have been studied extensively
in the statistical literature. However, from the data mining point of view, we need to examine how they can be
computed eciently in large, multidimensional databases.
5.6.1 Measuring the central tendency
The most common and most eective numerical measure of the \center" of a set of data is the (arithmetic)
mean. Let x1; x2; : : :; xn be a set of n values or observations. The mean of this set of values is
Xn
x = n1 xi:
i=1
(5.13)
This corresponds to the built-in aggregate function, average (avg() in SQL), provided in relational database
systems. In most data cubes, sum and count are saved in precomputation. Thus, the derivation of average is
straightforward, using the formula average = sum=count.
Sometimes, each value xi in a set may be associated with a weight wi , for i = 1; : : :; n. The weights reect
the signicance, importance, or occurrence frequency attached to their respective values. In this case, we can
compute
Pn wixi
x = Pi=1
(5.14)
n w :
i=1 i
This is called the weighted arithmetic mean or the weighted average.
In Chapter 2, a measure was dened as algebraic if it can be computed from distributive aggregate measures.
Since avg() can be computed by sum()/count(), where both sum() and count() are distributive aggregate
measures in the sense that they can be computed in a distributive manner, then avg() is an algebraic measure.
One can verify that the weighted average is also an algebraic measure.
Although the mean is the single most useful quantity that we use to describe a set of data, it is not the only,
or even always the best, way of measuring the center of a set of data. For skewed data, a better measure of
center of data is the median, M. Suppose that the values forming a given set of data are in numerical order.
5.6. MINING DESCRIPTIVE STATISTICAL MEASURES IN LARGE DATABASES
23
The median is the middle value of the ordered set if the number of values n is an odd number; otherwise (i.e.,
if n is even), it is the average of the middle two values.
Based on the categorization of measures in Chapter 2, the median is neither a distributive measure nor an
algebraic measure | it is a holistic measure in the sense that it cannot be computed by partitioning a set of
values arbitrarily into smaller subsets, computing their medians independently, and merging the median values
of each subset. On the contrary, count(), sum(), max(), and min() can be computed in this manner (being
distributive measures), and are therefore easier to compute than the median.
Although it is not easy to compute the exact median value in a large database, an approximate median can be
computed eciently. For example, for grouped data, the median, obtained by interpolation, is given by
P f)l
n=2
+
(
median = L1 + ( f
)c:
(5.15)
median
where L1 is the lower class
P boundary of (i.e., lowest value for) the class containing the median, n is the number
of values in the data, ( f)l is the sum of the frequencies of all of the classes that are lower than the median
class, and fmedian is the frequency of the median class, and c is the size of the median class interval.
Another measure of central tendency is the mode. The mode for a set of data is the value that occurs most
frequently in the set. It is possible for the greatest frequency to correspond to several dierent values, which
results in more than one mode. Data sets with one, two, or three modes are respectively called unimodal,
bimodal, and trimodal. If a data set has more than three modes, it is multimodal. At the other extreme,
if each data value occurs only once, then there is no mode.
For unimodal frequency curves that are moderately skewed (asymmetrical), we have the following empirical
relation
mean , mode = 3 (mean , median):
(5.16)
This implies that the mode for unimodal frequency curves that are moderately skewed can easily be computed
if the mean and median values are known.
The midrange, that is, the average of the largest and smallest values in a data set, can be used to measure the
central tendency of the set of data. It is trivial to compute the midrange using the SQL aggregate functions,
max() and min().
5.6.2 Measuring the dispersion of data
The degree to which numeric data tend to spread is called the dispersion, or variance of the data. The most
common measures of data dispersion are the ve-number summary (based on quartiles), the interquartile range, and
standard deviation. The plotting of boxplots (which show outlier values) also serves as a useful graphical method.
Quartiles, outliers and boxplots
The kth percentile of a set of data in numerical order is the value x having the property that k percent of
the data entries lies at or below x. Values at or below the median M (discussed in the previous subsection)
correspond to the 50-th percentile.
The most commonly used percentiles other than the median are quartiles. The rst quartile, denoted by
Q1, is the 25-th percentile; and the third quartile, denoted by Q3 , is the 75-th percentile.
The quartiles together with the median give some indication of the center, spread, and shape of a distribution.
The distance between the rst and third quartiles is a simple measure of spread that gives the range covered
by the middle half of the data. This distance is called the interquartile range (IQR), and is dened as
IQR = Q3 , Q1:
(5.17)
We should be aware that no single numerical measure of spread, such as IQR, is very useful for describing
skewed distributions. The spreads of two sides of a skewed distribution are unequal. Therefore, it is more
informative to also provide the two quartiles Q1 and Q3, along with the median, M.
24
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
unit price ($) number of items sold
40
275
43
300
47
250
..
..
74
360
75
515
78
540
..
..
115
320
117
270
120
350
Table 5.11: A set of data.
One common rule of thumb for identifying suspected outliers is to single out values falling at least 1:5 IQR
above the third quartile or below the rst quartile.
Because Q1 , M, and Q3 contain no information about the endpoints (e.g., tails) of the data, a fuller summary
of the shape of a distribution can be obtained by providing the highest and lowest data values as well. This is
known as the ve-number summary. The ve-number summary of a distribution consists of the median M,
the quartiles Q1 and Q3 , and the smallest and largest individual observations, written in the order
Minimum; Q1 ; M; Q3; Maximum:
A popularly used visual representation of a distribution is the boxplot. In a boxplot:
1. The ends of the box are at the quartiles, so that the box length is the interquartile range, IQR.
2. The median is marked by a line within the box.
3. Two lines (called whiskers) outside the box extend to the smallest (Minimum) and largest (Maximum)
observations.
Figure 5.4: A boxplot for the data set of Table 5.11.
When dealing with a moderate numbers of observations, it is worthwhile to plot potential outliers individually.
To do this in a boxplot, the whiskers are extended to the extreme high and low observations only if these
values are less than 1:5 IQR beyond the quartiles. Otherwise, the whiskers terminate at the most extreme
5.6. MINING DESCRIPTIVE STATISTICAL MEASURES IN LARGE DATABASES
25
observations occurring within 1:5 IQR of the quartiles. The remaining cases are plotted individually. Figure
5.4 shows a boxplot for the set of price data in Table 5.11, where we see that Q1 is $60, Q3 is $100, and the
median is $80.
Based on similar reasoning as in our analysis of the median in Section 5.6.1, we can conclude that Q1 and
Q3 are holistic measures, as is IQR. The ecient computation of boxplots or even approximate boxplots is
interesting regarding the mining of large data sets.
Variance and standard deviation
The variance of n observations x ; x ; : : :; xn is
1
2
Xn
X
X
s2 = n ,1 1 (xi , x)2 = n ,1 1 [ x2i , n1 ( xi)2 ]
i=1
(5.18)
The standard deviation s is the square root of the variance s2 .
The basic properties of the standard deviation s as a measure of spread are:
s measures spread about the mean and should be used only when the mean is chosen as the measure of center.
s = 0 only when there is no spread, that is, when all observations have the same value. Otherwise s > 0.
P
Notice that variance and standard
deviation are algebraic measures because n (which is count() in SQL), xi
P
(which is the sum() of xi ), and x2i (which is the sum() of x2i ) can be computed in any partition and then merged
to feed into the algebraic equation (5.18). Thus the computation of the two measures is scalable in large databases.
5.6.3 Graph displays of basic statistical class descriptions
Aside from the bar charts, pie charts, and line graphs discussed earlier in this chapter, there are also a few additional
popularly used graphs for the display of data summaries and distributions. These include histograms, quantile plots,
Q-Q plots, scatter plots, and loess curves.
A histogram, or frequency histogram, is a univariate graphical method. It denotes the frequencies of
the classes present in a given set of data. A histogram consists of a set of rectangles where the area of each
rectangle is proportional to the relative frequency of the class it represents. The base of each rectangle is on
the horizontal axis, centered at a \class" mark, and the base length is equal to the class width. Typically, the
class width is uniform, with classes being dened as the values of a categoric attribute, or equi-width ranges
of a discretized continuous attribute. In these cases, the height of each rectangle is the relative frequency (or
frequency) of the class it represents, and the histogram is generally referred to as a bar chart. Alternatively,
classes for a continuous attribute may be dened by ranges of non-uniform width. In this case, for a given
class, the class width is equal to the range width, and the height of the rectangle is the class density (that is,
the relative frequency of the class, divided by the class width). Partitioning rules for constructing histograms
were discussed in Chapter 3.
Figure 5.5 shows a histogram for the data set of Table 5.11, where classes are dened by equi-width ranges
representing $10 increments. Histograms are at least a century old, and are a widely used univariate graphical
method. However, they may not be as eective as the quantile plot, Q-Q plot and boxplot methods for
comparing groups of univariate observations.
A quantile plot is a simple and eective way to have a rst look at data distribution. First, it displays all
of the data (allowing the user to assess both the overall behavior and unusual occurrences). Second, it plots
quantile information. The mechanism used in this step is slightly dierent from the percentile computation.
Let x(i), for i = 1 to n, be the data ordered from the smallest to the largest; thus x(1) is the smallest observation
and x(n) is the largest. Each observation x(i) is paired with a percentage, fi , which indicates that 100fi% of
the data are below or equal to the value x(i). Let
fi = i ,n0:5 :
26
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
Figure 5.5: A histogram for the data set of Table 5.11.
These numbers increase in equal steps of 1=n beginning with 1=2n, which is slightly above zero, and ending with
1 , 1=2n, which is slightly below one. On a quantile plot, x(i) is graphed against fi . This allows visualization
of the fi quantiles. Figure 5.6 shows a quantile plot for the set of data in Table 5.11.
Figure 5.6: A quantile plot for the data set of Table 5.11.
A Q-Q plot, or quantile-quantile plot, is a powerful visualization method for comparing the distributions
of two or more sets of univariate observations. When distributions are compared, the goal is to understand
how the distributions dier from one data set to the next. The most eective way to investigate the shifts of
distributions is to compare corresponding quantiles.
Suppose there are just two sets of univariate observations to be compared. Let x(1) ; : : :; x(n) be the rst data
set, ordered from smallest to largest. Let y(1) ; : : :; y(m) be the second, also ordered. Suppose m n. If m = n,
then y(i) and x(i) are both (i , 0:5)=n quantiles of their respective data sets, so on the Q-Q plot, y(i) is graphed
against x(i) ; that is, the ordered values for one set of data are graphed against the ordered values of the other
set. If m < n, the y(i) is the (i , 0:5)=m quantile of the y data, and y(i) is graphed against the (i , 0:5)=m
quantile of the x data, which typically must be computed by interpolation. With this method, there are always
m points on the graph, where m is the number of values in the smaller of the two data sets. Figure 5.7 shows
a quantile-quantile plot for the data set of Table 5.11.
5.6. MINING DESCRIPTIVE STATISTICAL MEASURES IN LARGE DATABASES
27
Figure 5.7: A quantile-quantile plot for the data set of Table 5.11.
A scatter plot is one of the most eective graphical methods for determining if there appears to be a relation-
ship, pattern, or trend between two quantitative variables. To construct a scatter plot, each pair of values is
treated as a pair of coordinates in an algebraic sense, and plotted as points in the plane. The scatter plot is a
useful exploratory method for providing a rst look at bivariate data to see how they are distributed throughout
the plane, for example, and to see clusters of points, outliers, and so forth. Figure 5.8 shows a scatter plot for
the set of data in Table 5.11.
Figure 5.8: A scatter plot for the data set of Table 5.11.
A loess curve is another important exploratory graphic aid which adds a smooth curve to a scatter plot in
order to provide better perception of the pattern of dependence. The word loess is short for local regression.
Figure 5.9 shows a loess curve for the set of data in Table 5.11.
Two parameters need to be chosen to t a loess curve. The rst parameter, , is a smoothing parameter. It
can be any positive number, but typical values are between 1=4 to 1. The goal in choosing is to produce a t
that is as smooth as possible without unduly distorting the underlying pattern in the data. As increases, the
curve becomes smoother. If becomes large, the tted function could be very smooth. There may be some
lack of t, however, indicating possible \missing" data patterns. If is very small, the underlying pattern is
tracked, yet overtting of the data may occur, where local \wiggles" in the curve may not be supported by
the data. The second parameter, , is the degree of polynomials that are tted by the method; can be 1
or 2. If the underlying pattern of the data has a \gentle" curvature with no local maxima and minima, then
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
28
locally linear tting is usually sucient ( = 1). However, if there are local maxima or minima, then locally
quadratic tting ( = 2) typically does a better job of following the pattern of the data and maintaining local
smoothness.
Figure 5.9: A loess curve for the data set of Table 5.11.
5.7 Discussion
We have presented a set of scalable methods for mining concept or class descriptions in large databases. In this section,
we discuss related issues regarding such descriptions. These include a comparison of the cube-based and attributeoriented induction approaches to data generalization with typical machine learning methods, the implementation of
incremental and parallel mining of concept descriptions, and interestingness measures for concept description.
5.7.1 Concept description: A comparison with typical machine learning methods
In this chapter, we studied a set of database-oriented methods for mining concept descriptions in large databases.
These methods included a data cube-based and an attribute-oriented induction approach to data generalization for
concept description. Other inuential concept description methods have been proposed and studied in the machine
learning literature since the 1980s. Typical machine learning methods for concept description follow a learning-fromexamples paradigm. In general, such methods work on sets of concept or class-labeled training examples which are
examined in order to derive or learn a hypothesis describing the class under study.
\What are the major dierences between methods of learning-from-examples and the data mining methods presented here?"
First, there are dierences in the philosophies of the machine learning and data mining approaches, and their
basic assumptions regarding the concept description problem.
In most of the learning-from-examples algorithms developed in machine learning, the set of examples to be
analyzed is partitioned into two sets: positive examples and negative ones, respectively representing target
and contrasting classes. The learning process selects one positive example at random, and uses it to form a
hypothesis describing objects of that class. The learning process then performs generalization on the hypothesis
using the remaining positive examples, and specialization using the negative examples. In general, the resulting
hypothesis covers all the positive examples, but none of the negative examples.
A database usually does not store the negative data explicitly. Thus no explicitly specied negative examples
can be used for specialization. This is why, for analytical characterization mining and for comparison mining
in general, data mining methods must collect a set of comparable data which are not in the target (positive)
class, for use as negative data (Sections 5.4 and 5.5). Most database-oriented methods also therefore tend to
5.7. DISCUSSION
29
be generalization-based. Even though most provide the drill-down (specialization) operation, this operation is
essentially implemented by backtracking the generalization process to a previous state.
Another major dierence between machine learning and database-oriented techniques for concept description
concerns the size of the set of training examples. For traditional machine learning methods, the training set
is typically relatively small in comparison with the data analyzed by database-oriented techniques. Hence, for
machine learning methods, it is easier to nd descriptions which cover all of the positive examples without
covering any negative examples. However, considering the diversity and huge amount of data stored in realworld databases, it is unlikely for analysis of such data to derive a rule or pattern which covers all of the
positive examples but none of the negative ones. Instead, what one may expect to nd is a set of features or
rules which cover a majority of the data in the positive class, maximally distinguishing the positive from the
negative examples. (This can also be described as a probability distribution).
Second, distinctions between the machine learning and database-oriented approaches also exist regarding the
methods of generalization used.
Both approaches do employ attribute removal and attribute generalization (also known as concept tree ascension) as their main generalization techniques. Consider the set of training examples as a set of tuples. The
machine learning approach thus performs generalization tuple by tuple, whereas the database-oriented approach
performs generalization on an attribute by attribute (or entire dimension) basis.
In the tuple by tuple strategy of the machine learning approach, the training examples are examined one at
a time in order to induce generalized concepts. In order to form the most specic hypothesis (or concept
description) that is consistent with all of the positive examples and none of the negative ones, the algorithm
must search every node in the search space representing all of the possible concepts derived from generalization
on each training example. Since dierent attributes of a tuple may be generalized to various levels of abstraction,
the number of nodes searched for a given training example may involve a huge number of possible combinations.
On the other hand, a database approach employing an attribute-oriented strategy performs generalization
on each attribute or dimension uniformly for all of the tuples in the data relation at the early stages of
generalization. Such an approach essentially focuses its attention on individual attributes, rather than on
combinations of attributes. This is referred to as factoring the version space, where version space is dened
as the subset of hypotheses consistent with the training examples. Factoring the version space can substantially
improve the computational eciency. Suppose there are k concept hierarchies used in the generalization and
there are p nodes in each concept hierarchy. The total size of k factored version spaces is p k. In contrast,
the size of the unfactored version space searched by the machine learning approach is pk for the same concept
tree.
Notice that algorithms which, during the early generalization stages, explore many possible combinations of
dierent attribute-value conditions given a large number of tuples cannot be productive since such combinations
will eventually be merged during further generalizations. Dierent possible combinations should be explored
only when the relation has rst been generalized to a relatively smaller relation, as is done in the databaseoriented approaches described in this chapter.
Another obvious advantage of the attribute-oriented approach over many other machine learning algorithms is
the integration of the data mining process with set-oriented database operations. In contrast to most existing
learning algorithms which do not take full advantages of database facilities, the attribute-oriented induction
approach primarily adopts relational operations, such as selection, join, projection (extracting task-relevant
data and removing attributes), tuple substitution (ascending concept trees), and sorting (discovering common
tuples among classes). Since relational operations are set-oriented whose implementation has been optimized
in many existing database systems, the attribute-oriented approach is not only ecient but also can easily be
exported to other relational systems. This comment applies to data cube-based generalization algorithms as
well. The data cube-based approach explores more optimization techniques than traditional database query
processing techniques by incorporating sparse cube techniques, various methods of cube computation, as well
as indexing and accessing techniques. Therefore, a high performance gain of database-oriented algorithms over
machine learning techniques, is expected when handling large data sets.
30
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
5.7.2 Incremental and parallel mining of concept description
Given the huge amounts of data in a database, it is highly preferable to update data mining results incrementally
rather than mining from scratch on each database update. Thus incremental data mining is an attractive goal for
many kinds of mining in large databases or data warehouses.
Fortunately, it is straightforward to extend the database-oriented concept description mining algorithms for
incremental data mining.
Let's rst examine extending the attribute-oriented induction approach for use in incremental data mining.
Suppose a generalized relation R is stored in the database. When a set of new tuples, DB, is inserted into the
database, attribute-oriented induction can be performed on DB in order to generalize the attributes to the same
conceptual levels as the respective corresponding attributes in the generalized relation, R. The associated aggregation
information, such as count, sum, etc., can be calculated by applying the generalization algorithm to DB rather
than to R. The generalized relation so derived, R, on DB, can then easily be merged into the generalized relation
R, since R and R share the same dimensions and exist at the same abstraction levels for each dimension. The
union, R [ R, becomes a new generalized relation, R . Minor adjustments, such as dimension generalization or
specialization, can be performed on R as specied by the user, if desired. Similarly, a set of deletions can be viewed
as the deletion of a small database, DB, from DB. The incremental update should be the dierence R , R,
where R is the existing generalized relation and R is the one generated from DB. Similar algorithms can be
worked out for data cube-based concept description. (This is left as an exercise).
Data sampling methods, parallel algorithms, and distributed algorithms can be explored for concept description
mining, based on the same philosophy. For example, attribute-oriented induction can be performed by sampling a
subset of data from a huge set of task-relevant data or by rst performing induction in parallel on several partitions
of the task-relevant data set, and then merging the generalized results.
0
0
5.7.3 Interestingness measures for concept description
\When examining concept descriptions, how can the data mining system objectively evaluate the interestingness of
each description?"
Dierent users may have dierent preferences regarding what makes a given description interesting or useful.
Let's examine a few interestingness measures for mining concept descriptions.
1. Signicance threshold:
Users may like to examine what kind of objects contribute \signicantly " to the summary of the data. That is,
given a concept description in the form of a generalized relation, say, they may like to examine the generalized
tuples (acting as \object descriptions") which contribute a nontrivial weight or portion to the summary, while
ignoring those which contribute only a negligible weight to the summary. In this context, one may introduce a
signicance threshold to be used in the following manner: if the weight of a generalized tuple/object is lower
than the threshold, it is considered to represent only a negligible portion of the database and can therefore
be ignored as uninteresting. Notice that ignoring such negligible tuples does not mean that they should be
removed from the intermediate results (i.e., the prime generalized relation, or the data cube, depending on
the implementation) since they may contribute to subsequent further exploration of the data by the user via
interactive rolling up or drilling down of other dimensions and levels of abstraction. Such a threshold may also
be called the support threshold, adopting the term popularly used in association rule mining.
For example, if the signicance threshold is set to 1%, a generalized tuple (or data cube cell) which represents
less than 1% in count of the number of tuples (objects) in the database is omitted in the result presentation.
Moreover, although the signicance threshold, by default, is calculated based on count, other measures can be
used. For example, one may use the sum of an amount (such as total sales) as the signicance measure to
observe the major objects contributing to the overall sales. Alternatively, the t-weight and d-weight measures
studied earlier (Sections 5.2.3 and 5.5.2), which respectively indicate the typicality and discriminability of
generalized tuples (or objects), may also be used.
2. Deviation threshold. Some users may already know the general behavior of the data and would like to
instead explore the objects which deviate from this general behavior. Thus, it is interesting to examine how to
identify the kind of data values that are considered outliers, or deviations.
5.8. SUMMARY
31
Suppose the data to be examined are numeric. As discussed in Section 5.6, a common rule of thumb identies
suspected outliers as those values which fall at least 1:5 IQR above the third quartile or below the rst
quartile. Depending on the application at hand, however, such a rule of thumb may not always work well. It
may therefore be desirable to provide a deviation threshold as an adjustable threshold to enlarge or shrink
the set of possible outliers. This facilitates interactive analysis of the general behavior of outliers. We leave the
identication of outliers in time-series data to Chapter 9, where time-series analysis will be discussed.
5.8 Summary
Data mining can be classied into descriptive data mining and predictive data mining. Concept description
is the most basic form of descriptive data mining. It describes a given set of task-relevant data in a concise
and summarative manner, presenting interesting general properties of the data.
Concept (or class) description consists of characterization and comparison (or discrimination). The
former summarizes and describes a collection of data, called the target class; whereas the latter summarizes
and distinguishes one collection of data, called the target class, from other collection(s) of data, collectively
called the contrasting class(es).
There are two general approaches to concept characterization: the data cube OLAP-based approach
and the attribute-oriented induction approach. Both are attribute- or dimension-based generalization
approaches. The attribute-oriented induction approach can be implemented using either relational or data
cube structures.
The attribute-oriented induction approach consists of the following techniques: data focusing, gener-
alization by attribute removal or attribute generalization, count and aggregate value accumulation, attribute
generalization control, and generalization data visualization.
Generalized data can be visualized in multiple forms, including generalized relations, crosstabs, bar charts, pie
charts, cube views, curves, and rules. Drill-down and roll-up operations can be performed on the generalized
data interactively.
Analytical data characterization/comparison performs attribute and dimension relevance analysis in
order to lter out irrelevant or weakly relevant attributes prior to the induction process.
Concept comparison can be performed by the attribute-oriented induction or data cube approach in a
manner similar to concept characterization. Generalized tuples from the target and contrasting classes can be
quantitatively compared and contrasted.
Characterization and comparison descriptions (which form a concept description) can both be visualized in
the same generalized relation, crosstab, or quantitative rule form, although they are displayed with dierent
interestingness measures. These measures include the t-weight (for tuple typicality) and d-weight (for tuple
discriminability).
From the descriptive statistics point of view, additional statistical measures should be introduced in describ-
ing central tendency and data dispersion. Quantiles, variations, and outliers are useful additional information
which can be mined in databases. Boxplots, quantile plots, scattered plots, and quantile-quantile plots are
useful visualization tools in descriptive data mining.
In comparison with machine learning algorithms, database-oriented concept description leads to eciency and
scalability in large databases and data warehouses.
Concept description mining can be performed incrementally, in parallel, or in a distributed manner, by making
minor extensions to the basic methods involved.
Additional interestingness measures, such as the signicance threshold or deviation threshold, can be
included and dynamically adjusted by users for mining interesting class descriptions.
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
32
Exercises
1. Suppose that the employee relation in a store database has the data set presented in Table 5.12.
name
gender department age years worked
residence
salary # of children
Jamie Wise
M
Clothing
21
3
3511 Main St., Richmond $20K
0
Sandy Jones
F
Shoe
39
20
125 Austin Ave., Burnaby $25K
2
Table 5.12: The employee relation for data mining.
2.
3.
4.
5.
6.
(a) Propose a concept hierarchy for each of the attributes department, age, years worked, residence, salary
and # of children.
(b) Mine the prime generalized relation for characterization of all of the employees.
(c) Drill down along the dimension years worked.
(d) Present the above description as a crosstab, bar chart, pie chart, and as logic rules.
(e) Characterize only the employees is the Shoe Department.
(f) Compare the set of employees who have children vs. those who have no children.
Outline the major steps of the data cube-based implementation of class characterization. What are the major
dierences between this method and a relational implementation such as attribute-oriented induction? Discuss
which method is most ecient and under what conditions this is so.
Discuss why analytical data characterization is needed and how it can be performed. Compare the result of
two induction methods: (1) with relevance analysis, and (2) without relevance analysis.
Give three additional commonly used statistical measures (i.e., not illustrated in this chapter) for the characterization of data dispersion, and discuss how they can be computed eciently in large databases.
Outline a data cube-based incremental algorithm for mining analytical class comparisons.
Outline a method for (1) parallel and (2) distributed mining of statistical measures.
Bibliographic Notes
Generalization and summarization methods have been studied in the statistics literature long before the onset of
computers. Good summaries of statistical descriptive data mining methods include Cleveland [7], and Devore [10].
Generalization-based induction techniques, such as learning-from-examples, were proposed and studied in the machine
learning literature before data mining became active. A theory and methodology of inductive learning was proposed
in Michalski [23]. Version space was proposed by Mitchell [25]. The method of factoring the version space described
in Section 5.7 was presented by Subramanian and Feigenbaum [30]. Overviews of machine learning techniques can
be found in Dietterich and Michalski [11], Michalski, Carbonell, and Mitchell [24], and Mitchell [27].
The data cube-based generalization technique was initially proposed by Codd, Codd, and Salley [8] and has
been implemented in many OLAP-based data warehouse systems, such as Kimball [20]. Gray et al. [13] proposed
a cube operator for computing aggregations in data cubes. Recently, there have been many studies on the ecient
computation of data cubes, which contribute to the ecient computation of data generalization. A comprehensive
survey on the topic can be found in Chaudhuri and Dayal [6].
Database-oriented methods for concept description explore scalable and ecient techniques for describing large
sets of data in databases and data warehouses. The attribute-oriented induction method described in this chapter
was rst proposed by Cai, Cercone, and Han [5] and further extended by Han, Cai, and Cercone [15], and Han and
Fu [16].
There are many methods for assessing attribute relevance. Each has its own bias. The information gain measure is
biased towards attributes with many values. Many alternatives have been proposed, such as gain ratio (Quinlan [29])
5.8. SUMMARY
33
which considers the probability of each attribute value. Other relevance measures include the gini index (Breiman
et al. [2]), the 2 contingency table statistic, and the uncertainty coecient (Johnson and Wickern [19]). For a
comparison of attribute selection measures for decision tree induction, see Buntine and Niblett [3]. For additional
methods, see Liu and Motoda [22], Dash and Liu [9], Almuallim and Dietterich [1], and John [18].
For statistics-based visualization of data using boxplots, quantile plots, quantile-quantile plots, scattered plots,
and loess curves, see Cleveland [7], and Devore [10]. Ng and Knorr [21] studied a unied approach for dening and
computing outliers.
34
CHAPTER 5. CONCEPT DESCRIPTION: CHARACTERIZATION AND COMPARISON
Bibliography
[1] H. Almuallim and T. G. Dietterich. Learning with many irrelevant features. In Proc. 9th National Conf. on
Articial Intelligence (AAAI'91), pages 547{552, July 1991.
[2] L. Breiman, J. Friedman, R. Olshen, and C. Stone. Classication and Regression Trees. Wadsworth International
Group, 1984.
[3] W. L. Buntine and Tim Niblett. A further comparison of splitting rules for decision-tree induction. Machine
Learning, 8:75{85, 1992.
[4] Y. Cai, N. Cercone, and J. Han. Attribute-oriented induction in relational databases. In G. Piatetsky-Shapiro
and W. J. Frawley, editors, Knowledge Discovery in Databases, pages 213{228. AAAI/MIT Press, 1991.
[5] Y. Cai, N. Cercone, and J. Han. Attribute-oriented induction in relational databases. In G. Piatetsky-Shapiro
and W. J. Frawley, editors, Knowledge Discovery in Databases, pages 213{228. AAAI/MIT Press Also in Proc.
IJCAI-89 Workshop Knowledge Discovery in Databases, Detroit, MI, August 1989, 26-36., 1991.
[6] S. Chaudhuri and U. Dayal. An overview of data warehousing and OLAP technology. ACM SIGMOD Record,
26:65{74, 1997.
[7] W. Cleveland. Visualizing data. In AT&T Bell Laboratories, Hobart Press, Summit NJ, 1993.
[8] E. F Codd, S. B. Codd, and C. T. Salley. Providing OLAP (on-line analytical processing) to user-analysts: An
IT mandate. In E. F. Codd & Associates available at http://www.arborsoft.com/OLAP.html, 1993.
[9] M. Dash and H. Liu. Feature selecion for classicaion. In Intelligent Data Analysis, volume 1 of 3, 1997.
[10] J. L. Devore. Probability and Statistics for Engineering and the Science, 4th ed. Duxbury Press, 1995.
[11] T. G. Dietterich and R. S. Michalski. A comparative review of selected methods for learning from examples.
In Michalski et al., editor, Machine Learning: An Articial Intelligence Approach, Vol. 1, pages 41{82. Morgan
Kaufmann, 1983.
[12] M. Genesereth and N. Nilsson. Logical Foundations of Articial Intelligence. Morgan Kaufmann, 1987.
[13] J. Gray, A. Bosworth, A. Layman, and H. Pirahesh. Data cube: A relational operator generalizing group-by,
cross-tab and sub-totals. In Proc. 1996 Int. Conf. Data Engineering, pages 152{159, New Orleans, Louisiana,
Feb. 1996.
[14] A. Gupta, V. Harinarayan, and D. Quass. Aggregate-query processing in data warehousing environment. In
Proc. 21st Int. Conf. Very Large Data Bases, pages 358{369, Zurich, Switzerland, Sept. 1995.
[15] J. Han, Y. Cai, and N. Cercone. Data-driven discovery of quantitative rules in relational databases. IEEE
Trans. Knowledge and Data Engineering, 5:29{40, 1993.
[16] J. Han and Y. Fu. Exploration of the power of attribute-oriented induction in data mining. In U.M. Fayyad,
G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy, editors, Advances in Knowledge Discovery and Data
Mining, pages 399{421. AAAI/MIT Press, 1996.
[17] V. Harinarayan, A. Rajaraman, and J. D. Ullman. Implementing data cubes eciently. In Proc. 1996 ACMSIGMOD Int. Conf. Management of Data, pages 205{216, Montreal, Canada, June 1996.
35
36
BIBLIOGRAPHY
[18] G. H. John. Enhancements to the Data Mining Process. Ph.D. Thesis, Computer Science Dept., Stanford
Univeristy, 1997.
[19] R. A. Johnson and D. W. Wickern. Applied Multivariate Statistical Analysis, 3rd ed. Prentice Hall, 1992.
[20] R. Kimball. The Data Warehouse Toolkit. John Wiley & Sons, New York, 1996.
[21] E. Knorr and R. Ng. Algorithms for mining distance-based outliers in large datasets. In Proc. 1998 Int. Conf.
Very Large Data Bases, pages 392{403, New York, NY, August 1998.
[22] H. Liu and H. Motoda. Feature Selection for Knowledge Discovery and Data Mining. Kluwer Academic Publishers, 1998.
[23] R. S. Michalski. A theory and methodology of inductive learning. In Michalski et al., editor, Machine Learning:
An Articial Intelligence Approach, Vol. 1, pages 83{134. Morgan Kaufmann, 1983.
[24] R. S. Michalski, J. G. Carbonell, and T. M. Mitchell. Machine Learning, An Articial Intelligence Approach,
Vol. 2. Morgan Kaufmann, 1986.
[25] T. M. Mitchell. Version spaces: A candidate elimination approach to rule learning. In Proc. 5th Int. Joint Conf.
Articial Intelligence, pages 305{310, Cambridge, MA, 1977.
[26] T. M. Mitchell. Generalization as search. Articial Intelligence, 18:203{226, 1982.
[27] T. M. Mitchell. Machine Learning. McGraw Hill, 1997.
[28] J. R. Quinlan. Induction of decision trees. Machine Learning, 1:81{106, 1986.
[29] J. R. Quinlan. C4.5: Programs for Machine Learning. Morgan Kaufmann, 1993.
[30] D. Subramanian and J. Feigenbaum. Factorization in experiment generation. In Proc. 1986 AAAI Conf., pages
518{522, Philadelphia, PA, August 1986.
[31] J. Widom. Research problems in data warehousing. In Proc. 4th Int. Conf. Information and Knowledge Management, pages 25{30, Baltimore, Maryland, Nov. 1995.
[32] W. P. Yan and P. Larson. Eager aggregation and lazy aggregation. In Proc. 21st Int. Conf. Very Large Data
Bases, pages 345{357, Zurich, Switzerland, Sept. 1995.
[33] W. Ziarko. Rough Sets, Fuzzy Sets and Knowledge Discovery. Springer-Verlag, 1994.
Contents
6 Mining Association Rules in Large Databases
6.1 Association rule mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.1.1 Market basket analysis: A motivating example for association rule mining . . . . . . . . . . . .
6.1.2 Basic concepts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.1.3 Association rule mining: A road map . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.2 Mining single-dimensional Boolean association rules from transactional databases . . . . . . . . . . . .
6.2.1 The Apriori algorithm: Finding frequent itemsets . . . . . . . . . . . . . . . . . . . . . . . . . .
6.2.2 Generating association rules from frequent itemsets . . . . . . . . . . . . . . . . . . . . . . . . .
6.2.3 Variations of the Apriori algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.3 Mining multilevel association rules from transaction databases . . . . . . . . . . . . . . . . . . . . . .
6.3.1 Multilevel association rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.3.2 Approaches to mining multilevel association rules . . . . . . . . . . . . . . . . . . . . . . . . . .
6.3.3 Checking for redundant multilevel association rules . . . . . . . . . . . . . . . . . . . . . . . . .
6.4 Mining multidimensional association rules from relational databases and data warehouses . . . . . . .
6.4.1 Multidimensional association rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.4.2 Mining multidimensional association rules using static discretization of quantitative attributes
6.4.3 Mining quantitative association rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.4.4 Mining distance-based association rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.5 From association mining to correlation analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.5.1 Strong rules are not necessarily interesting: An example . . . . . . . . . . . . . . . . . . . . . .
6.5.2 From association analysis to correlation analysis . . . . . . . . . . . . . . . . . . . . . . . . . .
6.6 Constraint-based association mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.6.1 Metarule-guided mining of association rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.6.2 Mining guided by additional rule constraints . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
3
3
3
4
5
6
6
9
10
12
12
14
16
17
17
18
19
21
23
23
23
24
25
26
29
2
CONTENTS
c J. Han and M. Kamber, 1998, DRAFT!! DO NOT COPY!! DO NOT DISTRIBUTE!!
September 15, 1999
Chapter 6
Mining Association Rules in Large
Databases
Association rule mining nds interesting association or correlation relationships among a large set of data items.
With massive amounts of data continuously being collected and stored in databases, many industries are becoming
interested in mining association rules from their databases. For example, the discovery of interesting association
relationships among huge amounts of business transaction records can help catalog design, cross-marketing, lossleader analysis, and other business decision making processes.
A typical example of association rule mining is market basket analysis. This process analyzes customer buying
habits by nding associations between the dierent items that customers place in their \shopping baskets" (Figure
6.1). The discovery of such associations can help retailers develop marketing strategies by gaining insight into which
items are frequently purchased together by customers. For instance, if customers are buying milk, how likely are
they to also buy bread (and what kind of bread) on the same trip to the supermarket? Such information can lead to
increased sales by helping retailers to do selective marketing and plan their shelf space. For instance, placing milk
and bread within close proximity may further encourage the sale of these items together within single visits to the
store.
How can we nd association rules from large amounts of data, where the data are either transactional or relational?
Which association rules are the most interesting? How can we help or guide the mining procedure to discover
interesting associations? What language constructs are useful in dening a data mining query language for association
rule mining? In this chapter, we will delve into each of these questions.
6.1 Association rule mining
Association rule mining searches for interesting relationships among items in a given data set. This section provides an
introduction to association rule mining. We begin in Section 6.1.1 by presenting an example of market basket analysis,
the earliest form of association rule mining. The basic concepts of mining associations are given in Section 6.1.2.
Section 6.1.3 presents a road map to the dierent kinds of association rules that can be mined.
6.1.1 Market basket analysis: A motivating example for association rule mining
Suppose, as manager of an AllElectronics branch, you would like to learn more about the buying habits of your
customers. Specically, you wonder \Which groups or sets of items are customers likely to purchase on a given trip
to the store?". To answer your question, market basket analysis may be performed on the retail data of customer
transactions at your store. The results may be used to plan marketing or advertising strategies, as well as catalog
design. For instance, market basket analysis may help managers design dierent store layouts. In one strategy, items
that are frequently purchased together can be placed in close proximity in order to further encourage the sale of such
items together. If customers who purchase computers also tend to buy nancial management software at the same
time, then placing the hardware display close to the software display may help to increase the sales of both of these
3
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
4
Hmmm, which items are frequently
purchased together by my customers?
milk cereal
bread
Market analyst
Customer 1
milk eggs
bread
sugar
bread
Customer 2
butter
milk
Customer 3
...
sugar eggs
...
Customer n
SHOPPING BASKETS
Figure 6.1: Market basket analysis.
items. In an alternative strategy, placing hardware and software at opposite ends of the store may entice customers
who purchase such items to pick up other items along the way. For instance, after deciding on an expensive computer,
a customer may observe security systems for sale while heading towards the software display to purchase nancial
management software, and may decide to purchase a home security system as well. Market basket analysis can also
help retailers to plan which items to put on sale at reduced prices. If customers tend to purchase computers and
printers together, then having a sale on printers may encourage the sale of printers as well as computers.
If we think of the universe as the set of items available at the store, then each item has a Boolean variable
representing the presence or absence of that item. Each basket can then be represented by a Boolean vector of values
assigned to these variable. The Boolean vectors can be analyzed for buying patterns which reect items that are
frequent associated or purchased together. These patterns can be represented in the form of association rules. For
example, the information that customers who purchase computers also tend to buy nancial management software
at the same time is represented in association Rule (6.1) below.
computer ) nancial management software
[support = 2%; confidence = 60%]
(6.1)
Rule support and condence are two measures of rule interestingness that were described earlier in Section 1.5.
They respectively reect the usefulness and certainty of discovered rules. A support of 2% for association Rule (6.1)
means that 2% of all the transactions under analysis show that computer and nancial management software are
purchased together. A condence of 60% means that 60% of the customers who purchased a computer also bought the
software. Typically, association rules are considered interesting if they satisfy both a minimum support threshold
and a minimum condence threshold. Such thresholds can be set by users or domain experts.
6.1.2 Basic concepts
Let I =fi1 , i2 , :::, im g be a set of items. Let D, the task relevant data, be a set of database transactions where each
transaction T is a set of items such that T I . Each transaction is associated with an identier, called TID. Let A
be a set of items. A transaction T is said to contain A if and only if A T . An association rule is an implication
of the form A ) B, where A I , B I and A \ B = . The rule A ) B holds in the transaction set D with
support s, where s is the percentage of transactions in D that contain A [ B. The rule A ) B has condence c
6.1. ASSOCIATION RULE MINING
5
in the transaction set D if c is the percentage of transactions in D containing A which also contain B. That is,
support(A ) B) = ProbfA [ B g
(6.2)
confidence(A ) B) = ProbfB jAg:
(6.3)
Rules that satisfy both a minimum support threshold (min sup) and a minimum condence threshold (min conf) are
called strong.
A set of items is referred to as an itemset. An itemset that contains k items is a k-itemset. The set fcomputer,
nancial management softwareg is a 2-itemset. The occurrence frequency of an itemset is the number of
transactions that contain the itemset. This is also known, simply, as the frequency or support count of the
itemset. An itemset satises minimum support if the occurrence frequency of the itemset is greater than or equal to
the product of min sup and the total number of transactions in D. If an itemset satises minimum support, then it
is a frequent itemset1. The set of frequent k-itemsets is commonly denoted by Lk 2 .
\How are association rules mined from large databases?" Association rule mining is a two-step process:
Step 1: Find all frequent itemsets. By denition, each of these itemsets will occur at least as frequently as a
pre-determined minimum support count.
Step 2: Generate strong association rules from the frequent itemsets. By denition, these rules must satisfy
minimum support and minimum condence.
Additional interestingness measures can be applied, if desired. The second step is the easiest of the two. The overall
performance of mining association rules is determined by the rst step.
6.1.3 Association rule mining: A road map
Market basket analysis is just one form of association rule mining. In fact, there are many kinds of association rules.
Association rules can be classied in various ways, based on the following criteria:
1. Based on the types of values handled in the rule:
If a rule concerns associations between the presence or absence of items, it is a Boolean association rule.
For example, Rule (6.1) above is a Boolean association rule obtained from market basket analysis.
If a rule describes associations between quantitative items or attributes, then it is a quantitative association
rule. In these rules, quantitative values for items or attributes are partitioned into intervals. Rule (6.4) below
is an example of a quantitative association rule.
age(X; \30 , 34") ^ income(X; \42K , 48K") ) buys (X ; \high resolution TV ")
(6.4)
Note that the quantitative attributes, age and income, have been discretized.
2. Based on the dimensions of data involved in the rule:
If the items or attributes in an association rule each reference only one dimension, then it is a singledimensional association rule. Note that Rule (6.1) could be rewritten as
buys (X ; \computer ") ) buys (X ; \nancial management software ")
(6.5)
Rule (6.1) is therefore a single-dimensional association rule since it refers to only one dimension, i.e., buys.
If a rule references two or more dimensions, such as the dimensions buys, time of transaction, and customer category, then it is a multidimensional association rule. Rule (6.4) above is considered a multidimensional association rule since it involves three dimensions, age, income, and buys.
1 In early work, itemsets satisfying minimum support were referred to as large. This term, however, is somewhat confusing as it has
connotations to the number of items in an itemset rather than the frequency of occurrence of the set. Hence, we use the more recent
term of frequent.
2 Although the term frequent is preferred over large, for historical reasons frequent k -itemsets are still denoted as L .
k
6
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
3. Based on the levels of abstractions involved in the rule set:
Some methods for association rule mining can nd rules at diering levels of abstraction. For example, suppose
that a set of association rules mined included Rule (6.6) and (6.7) below.
age(X; \30 , 34") ) buys (X ; \laptop computer ")
(6.6)
age(X; \30 , 34") ) buys (X ; \computer ")
(6.7)
In Rules (6.6) and (6.7), the items bought are referenced at dierent levels of abstraction. (That is, \computer"
is a higher level abstraction of \laptop computer"). We refer to the rule set mined as consisting of multilevel
association rules. If, instead, the rules within a given set do not reference items or attributes at dierent
levels of abstraction, then the set contains single-level association rules.
4. Based on the nature of the association involved in the rule: Association mining can be extended to correlation
analysis, where the absence or presence of correlated items can be identied.
Throughout the rest of this chapter, you will study methods for mining each of the association rule types described.
6.2 Mining single-dimensional Boolean association rules from transactional databases
In this section, you will learn methods for mining the simplest form of association rules - single-dimensional, singlelevel, Boolean association rules, such as those discussed for market basket analysis in Section 6.1.1. We begin by
presenting Apriori, a basic algorithm for nding frequent itemsets (Section 6.2.1). A procedure for generating strong
association rules from frequent itemsets is discussed in Section 6.2.2. Section 6.2.3 describes several variations to the
Apriori algorithm for improved eciency and scalability.
6.2.1 The Apriori algorithm: Finding frequent itemsets
Apriori is an inuential algorithm for mining frequent itemsets for Boolean association rules. The name of the
algorithm is based on the fact that the algorithm uses prior knowledge of frequent itemset properties, as we shall
see below. Apriori employs an iterative approach known as a level-wise search, where k-itemsets are used to explore
(k+1)-itemsets. First, the set of frequent 1-itemsets is found. This set is denoted L1 . L1 is used to nd L2 , the
frequent 2-itemsets, which is used to nd L3, and so on, until no more frequent k-itemsets can be found. The nding
of each Lk requires one full scan of the database.
To improve the eciency of the level-wise generation of frequent itemsets, an important property called the
Apriori property, presented below, is used to reduce the search space.
The Apriori property. All non-empty subsets of a frequent itemset must also be frequent.
This property is based on the following observation. By denition, if an itemset I does not satisfy the minimum
support threshold, s, then I is not frequent, i.e., ProbfI g < s. If an item A is added to the itemset I, then the
resulting itemset (i.e., I [ A) cannot occur more frequently than I. Therefore, I [ A is not frequent either, i.e.,
ProbfI [ Ag < s.
This property belongs to a special category of properties called anti-monotone in the sense that if a set cannot
pass a test, all of its supersets will fail the same test as well. It is called anti-monotone because the property is
monotonic in the context of failing a test.
\How is the Apriori property used in the algorithm?" To understand this, we must look at how Lk,1 is used to
nd Lk . A two step process is followed, consisting of join and prune actions.
1. The join step: To nd Lk , a set of candidate k-itemsets is generated by joining Lk,1 with itself. This set
of candidates is denoted Ck . The join, Lk,1 1 Lk,1, is performed, where members of Lk,1 are joinable if they
have (k , 2) items in common, that is, Lk,1 1 Lk,1 = fA 1 B jA; B 2 Lk,1; jA \ B j = k , 2g.
6.2. MINING SINGLE-DIMENSIONAL BOOLEAN ASSOCIATION RULES FROM TRANSACTIONAL DATABASES7
2. The prune step: Ck is a superset of Lk , that is, its members may or may not be frequent, but all of the
frequent k-itemsets are included in Ck . A scan of the database to determine the count of each candidate in Ck
would result in the determination of Lk (i.e., all candidates having a count no less than the minimum support
count are frequent by denition, and therefore belong to Lk ). Ck , however, can be huge, and so this could
involve heavy computation. To reduce the size of Ck , the Apriori property is used as follows. Any (k-1)-itemset
that is not frequent cannot be a subset of a frequent k-itemset. Hence, if any (k-1)-subset of a candidate
k-itemset is not in Lk,1 , then the candidate cannot be frequent either and so can be removed from Ck . This
subset testing can be done quickly by maintaining a hash tree of all frequent itemsets.
AllElectronics database
TID List of item ID's
T100 I1, I2, I5
T200 I2, I3, I4
T300 I3, I4
T400 I1, I2, I3, I4
Figure 6.2: Transactional data for an AllElectronics branch.
Example 6.1 Let's look at a concrete example of Apriori, based on the AllElectronics transaction database, D, of
Figure 6.2. There are four transactions in this database, i.e., jDj = 4. Apriori assumes that items within a transaction
are sorted in lexicographic order. We use Figure 6.3 to illustrate the APriori algorithm for nding frequent itemsets
in D.
In the rst iteration of the algorithm, each item is a member of the set of candidate 1-itemsets, C1. The
algorithm simply scans all of the transactions in order to count the number of occurrences of each item.
Suppose that the minimum transaction support count required is 2 (i.e., min sup = 50%). The set of frequent
1-itemsets, L1 , can then be determined. It consists of the candidate 1-itemsets having minimum support.
To discover the set of frequent ,2-itemsets,
L2 , the algorithm uses L1 1 L1 to generate a candidate set of
jL j
2-itemsets, C2 3 . C2 consists of
1
2
2-itemsets.
Next, the transactions in D are scanned and the support count of each candidate itemset in C2 is accumulated,
as shown in the middle table of the second row in Figure 6.3.
The set of frequent 2-itemsets, L2 , is then determined, consisting of those candidate 2-itemsets in C2 having
minimum support.
The generation of the set of candidate 3-itemsets, C3, is detailed in Figure 6.4. First, let C3 = L2 1 L2 =
ffI1; I2; I3g; fI1; I2; I4g; fI2; I3;I4gg. Based on the Apriori property that all subsets of a frequent itemset
must also be frequent, we can determine that the candidates fI1,I2,I3g and fI1,I2,I4g cannot possibly be
frequent. We therefore remove them from C3, thereby saving the eort of unnecessarily obtaining their counts
during the subsequent scan of D to determine L3 . Note that since the Apriori algorithm uses a level-wise search
strategy, then given a k-itemset, we only need to check if its (k-1)-subsets are frequent.
The transactions in D are scanned in order to determine L3 , consisting of those candidate 3-itemsets in C3
having minimum support (Figure 6.3).
No more frequent itemsets can be found (since here, C4 = ), and so the algorithm terminates, having found
all of the frequent itemsets.
2
3
L1 1 L1 is equivalent to L1 L1 since the denition of Lk 1 Lk requires the two joining itemsets to share k , 1 = 0 items.
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
8
C1
Scan D for
count of each
candidate
,!
C2
Generate C2
candidates from
L1
,!
C3
Generate C3
Itemset
candidates from fI2,I3,I4g
L
2
,!
C2
Itemset Sup.
fI1,I2g 2
fI1,I3g 1
fI1,I4g 1
fI2,I3g 2
fI2,I4g 2
fI3,I4g 3
,!
Scan D for
count of each
candidate
,!
Itemset Sup.
fI1g
2
fI2g
3
fI3g
3
fI4g
3
,!
Scan D for
count of
each candidate
Itemset
fI1,I2g
fI1,I3g
fI1,I4g
fI2,I3g
fI2,I4g
fI3,I4g
L1
Compare candidate
support with
minimum support
count
Itemset Sup.
fI1g
2
fI2g
3
fI3g
3
fI4g
3
fI5g
1
C3
Itemset Sup.
fI2,I3,I4g 2
Compare candidate
support with
minimum support
count
,!
L2
Itemset Sup.
fI1,I2g 2
fI2,I3g 2
fI2,I4g 2
fI3,I4g 3
L3
Compare candidate Itemset Sup.
support with
fI2,I3,I4g 2
minimum support
count
,!
Figure 6.3: Generation of candidate itemsets and frequent itemsets, where the minimum support count is 2.
1. C3 = L2 1 L2 = ffI1,I2g, fI2,I3g, fI2,I4g, fI3,I4gg 1 ffI1,I2g, fI2,I3g, fI2,I4g, fI3,I4gg =
ffI1; I2; I3g; fI1; I2; I4g; fI2; I3;I4gg.
2. Apriori property: All subsets of a frequent itemset must also be frequent. Do any of the candidates have a
subset that is not frequent?
{ The 2-item subsets of fI1,I2,I3g are fI1,I2g, fI1,I3g, and fI2,I3g. fI1,I3g is not a member of L2, and so
it is not frequent. Therefore, remove fI1,I2,I3g from C3.
{ The 2-item subsets of fI1,I2,I4g are fI1,I2g, fI1,I4g, and fI2,I4g. fI1,I4g is not a member of L2, and so
it is not frequent. Therefore, remove fI1,I2,I4g from C3.
{ The 2-item subsets of fI2,I3,I4g are fI2,I3g, fI2,I4g, and fI3,I4g. All 2-item subsets of fI2,I3,I4g are
members of L2 . Therefore, keep fI2,I3,I4g in C3 .
3. Therefore, C3 = ffI2; I3; I4gg.
Figure 6.4: Generation of candidate 3-itemsets, C3 , from L2 using the Apriori property.
6.2. MINING SINGLE-DIMENSIONAL BOOLEAN ASSOCIATION RULES FROM TRANSACTIONAL DATABASES9
Algorithm 6.2.1 (Apriori) Find frequent itemsets using an iterative level-wise approach.
Input: Database, D, of transactions; minimum support threshold, min sup.
Output: L, frequent itemsets in D.
Method:
1)
2)
3)
4)
5)
6)
7)
8)
9)
10)
11)
L1 = nd frequent 1-itemsets(D);
for (k = 2; Lk,1 6= ; k++) f
Ck = apriori gen(Lk,1 , min sup);
for each transaction t 2 D f // scan D for counts
Ct = subset(Ck ; t); // get the subsets of t that are candidates
for each candidate c 2 Ct
g
c.count++;
Lk = fc 2 Ck jc:count min supg
g
return L = [k Lk ;
procedure apriori gen(Lk,1 :frequent (k-1)-itemsets; min sup: minimum support)
1) for each itemset l1 2 Lk,1
2)
for each itemset l2 2 Lk,1
3)
if (l1 [1] = l2 [1]) ^ (l1 [2] = l2 [2]) ^ ::: ^ (l1 [k , 2] = l2 [k , 2]) ^ (l1 [k , 1] < l2 [k , 1]) then f
4)
c = l1 1 l2 ; // join step: generate candidates
5)
if has infrequent subset(c;Lk,1 ) then
6)
delete c; // prune step: remove unfruitful candidate
7)
else add c to Ck ;
8)
g
9) return Ck ;
procedure has infrequent subset(c: candidate k-itemset; Lk,1 : frequent (k , 1)-itemsets); // use prior knowledge
1) for each (k , 1)-subset s of c
2)
if s 62 Lk,1 then
3)
return TRUE;
4) return FALSE;
Figure 6.5: The Apriori algorithm for discovering frequent itemsets for mining Boolean association rules.
Figure 6.5 shows pseudo-code for the Apriori algorithm and its related procedures. Step 1 of Apriori nds the
frequent 1-itemsets, L1 . In steps 2-10, Lk,1 is used to generate candidates Ck in order to nd Lk . The apriori gen
procedure generates the candidates and then uses the Apriori property to eliminate those having a subset that is
not frequent (step 3). This procedure is described below. Once all the candidates have been generated, the database
is scanned (step 4). For each transaction, a subset function is used to nd all subsets of the transaction that
are candidates (step 5), and the count for each of these candidates is accumulated (steps 6-7). Finally, all those
candidates satisfying minimum support form the set of frequent itemsets, L. A procedure can then be called to
generate association rules from the frequent itemsets. Such as procedure is described in Section 6.2.2.
The apriori gen procedure performs two kinds of actions, namely join and prune, as described above. In the join
component, Lk,1 is joined with Lk,1 to generate potential candidates (steps 1-4). The condition l1 [k , 1] < l2 [k , 1]
simply ensures that no duplicates are generated (step 3). The prune component (steps 5-7) employs the Apriori
property to remove candidates that have a subset that is not frequent. The test for infrequent subsets is shown in
procedure has infrequent subset.
6.2.2 Generating association rules from frequent itemsets
Once the frequent itemsets from transactions in a database D have been found, it is straightforward to generate
strong association rules from them (where strong association rules satisfy both minimum support and minimum
10
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
condence). This can be done using Equation (6.8) for condence, where the conditional probability is expressed in
terms of itemset support:
[ B) ;
confidence(A ) B) = Prob(B jA) = support(A
(6.8)
support(A)
where support(A [ B) is the number of transactions containing the itemsets A [ B, and support(A) is the number
of transactions containing the itemset A.
Based on this equation, association rules can be generated as follows.
For each frequent itemset, l, generate all non-empty subsets of l.
For every non-empty subset s, of l, output the rule \s ) (l , s)" if
the minimum condence threshold.
support(l)
support(s)
min conf, where min conf is
Since the rules are generated from frequent itemsets, then each one automatically satises minimum support. Frequent itemsets can be stored ahead of time in hash tables along with their counts so that they can be accessed
quickly.
Example 6.2 Let's try an example based on the transactional data for AllElectronics shown in Figure 6.2. Suppose
the data contains the frequent itemset l = fI2,I3,I4g. What are the association rules that can be generated from l?
The non-empty subsets of l are fI2,I3g, fI2,I4g, fI3,I4g, fI2g, fI3g, and fI4g. The resulting association rules are as
shown below, each listed with its condence.
I2 ^ I3 ) I4,
confidence = 2=2 = 100%
I2 ^ I4 ) I3,
confidence = 2=2 = 100%
I3 ^ I4 ) I2,
confidence = 2=3 = 67%
I2 ) I3 ^ I4,
confidence = 2=3 = 67%
I3 ) I2 ^ I4,
confidence = 2=3 = 67%
I4 ) I2 ^ I3,
confidence = 2=3 = 67%
If the minimum condence threshold is, say, 70%, then only the rst and second rules above are output, since these
are the only ones generated that are strong.
2
6.2.3 Variations of the Apriori algorithm
\How might the eciency of Apriori be improved?"
Many variations of the Apriori algorithm have been proposed. A number of these variations are enumerated
below. Methods 1 to 6 focus on improving the eciency of the original algorithm, while methods 7 and 8 consider
transactions over time.
1. A hash-based technique: Hashing itemset counts.
A hash-based technique can be used to reduce the size of the candidate k-itemsets, Ck , for k > 1. For example,
when scanning each transaction in the database to generate the frequent 1-itemsets, L1 , from the candidate
1-itemsets in C1, we can generate all of the 2-itemsets for each transaction, hash (i.e., map) them into the
dierent buckets of a hash table structure, and increase the corresponding bucket counts (Figure 6.6). A 2itemset whose corresponding bucket count in the hash table is below the support threshold cannot be frequent
and thus should be removed from the candidate set. Such a hash-based technique may substantially reduce
the number of the candidate k-itemsets examined (especially when k = 2).
2. Scan reduction: Reducing the number of database scans.
Recall that in the Apriori algorithm, one scan is required to determine Lk for each Ck . A scan reduction
technique reduces the total number of scans required by doing extra work in some scans. For example, in the
Apriori algorithm, C3 is generated based on L2 1 L2 . However, C2 can also be used to generate the candidate
3-itemsets. Let C30 be the candidate 3-itemsets generated from C2 1 C2 , instead of from L2 1 L2 . Clearly, jC30 j
will be greater than jC3j. However, if jC30 j is not much larger than jC3j, and both C2 and C30 can be stored in
6.2. MINING SINGLE-DIMENSIONAL BOOLEAN ASSOCIATION RULES FROM TRANSACTIONAL DATABASES11
H2
Create hash table, H2
bucket address
using hash function
bucket count
h(x; y) = ((order of x) 10 bucket contents
+(order of y)) mod 7
,!
0
1
2
3
4
5
6
1
1
2
2
1
2
4
fI1,I4g fI1,I5g fI2,I3g fI2,I4g fI2,I5g fI1,I2g fI3,I4g
fI2,I3g fI2,I4g
fI1,I2g fI3,I4g
fI1,I3g
fI3,I4g
Figure 6.6: Hash table, H2 , for candidate 2-itemsets: This hash table was generated by scanning the transactions
of Figure 6.2 while determining L1 from C1. If the minimum support count is 2, for example, then the itemsets in
buckets 0, 1, and 4 cannot be frequent and so they should not be included in C2.
main memory, we can nd L2 and L3 together when the next scan of the database is performed, thereby saving
one database scan. Using this strategy, we can determine all Lk 's by as few as two scans of the database (i.e.,
one initial scan to determine L1 and a nal scan to determine all other large itemsets), assuming that Ck0 for
k 3 is generated from Ck0 ,1 and all Ck0 s for k > 2 can be kept in the memory.
3. Transaction reduction: Reducing the number of transactions scanned in future iterations.
A transaction which does not contain any frequent k-itemsets cannot contain any frequent (k + 1)-itemsets.
Therefore, such a transaction can be marked or removed from further consideration since subsequent scans of
the database for j-itemsets, where j > k, will not require it.
4. Partitioning: Partitioning the data to nd candidate itemsets.
A partitioning technique can be used which requires just two database scans to mine the frequent itemsets
(Figure 6.7). It consists of two phases. In Phase I, the algorithm subdivides the transactions of D into n
non-overlapping partitions. If the minimum support threshold for transactions in D is min sup, then the
minimum itemset support count for a partition is min sup the number of transactions in that partition. For
each partition, all frequent itemsets within the partition are found. These are referred to as local frequent
itemsets. The procedure employs a special data structure which, for each itemset, records the TID's of the
transactions containing the items in the itemset. This allows it to nd all of the local frequent k-itemsets, for
k = 1; 2; : : :, in just one scan of the database.
A local frequent itemset may or may not be frequent with respect to the entire database, D. Any itemset
that is potentially frequent with respect to D must occur as a frequent itemset in at least one of the partitions.
Therefore, all local frequent itemsets are candidate itemsets with respect to D. The collection of frequent
itemsets from all partitions forms a global candidate itemset with respect to D. In Phase II, a second scan
of D is conducted in which the actual support of each candidate is assessed in order to determine the global
frequent itemsets. Partition size and the number of partitions are set so that each partition can t into main
memory and therefore be read only once in each phase.
PHASE II
PHASE I
Transactions
in D
Divided D into
n partitions
Find the frequent
itemsets local to
each partition
(1 scan)
Combine all
local frequent
itemsets to form
candidate itemset
Find global
frequent itemsets
among candidates
Figure 6.7: Mining by partitioning the data.
5. Sampling: Mining on a subset of the given data.
(1 scan)
Frequent
itemsets in D
12
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
The basic idea of the sampling approach is to pick a random sample S of the given data D, and then search
for frequent itemsets in S instead D. In this way, we trade o some degree of accuracy against eciency. The
sample size of S is such that the search for frequent itemsets in S can be done in main memory, and so, only
one scan of the transactions in S is required overall. Because we are searching for frequent itemsets in S rather
than in D, it is possible that we will miss some of the global frequent itemsets. To lessen this possibility, we
use a lower support threshold than minimum support to nd the frequent itemsets local to S (denoted LS ).
The rest of the database is then used to compute the actual frequencies of each itemset in LS . A mechanism
is used to determine whether all of the global frequent itemsets are included in LS . If LS actually contained
all of the frequent itemsets in D, then only one scan of D was required. Otherwise, a second pass can be done
in order to nd the frequent itemsets that were missed in the rst pass. The sampling approach is especially
benecial when eciency is of utmost importance, such as in computationally intensive applications that must
be run on a very frequent basis.
6. Dynamic itemset counting: Adding candidate itemsets at dierent points during a scan.
A dynamic itemset counting technique was proposed in which the database is partitioned into blocks marked by
start points. In this variation, new candidate itemsets can be added at any start point, unlike in Apriori, which
determines new candidate itemsets only immediately prior to each complete database scan. The technique
is dynamic in that it estimates the support of all of the itemsets that have been counted so far, adding new
candidate itemsets if all of their subsets are estimated to be frequent. The resulting algorithm requires two
database scans.
7. Calendric market basket analysis: Finding itemsets that are frequent in a set of user-dened time intervals.
Calendric market basket analysis uses transaction time stamps to dene subsets of the given database. An
itemset that does not satisfy minimum support may be considered frequent with respect to a subset of the
database which satises user-specied time constraints.
8. Sequential patterns: Finding sequences of transactions associated over time.
The goal of sequential pattern analysis is to nd sequences of itemsets that many customers have purchased in
roughly the same order. A transaction sequence is said to contain an itemset sequence if each itemset is
contained in one transaction, and the following condition is satised: If the ith itemset in the itemset sequence
is contained in transaction j in the transaction sequence, then the (i + 1)th itemset in the itemset sequence is
contained in a transaction numbered greater than j. The support of an itemset sequence is the percentage of
transaction sequences that contain it.
Other variations involving the mining of multilevel and multidimensional association rules are discussed in the
rest of this chapter. The mining of time sequences is further discussed in Chapter 9.
6.3 Mining multilevel association rules from transaction databases
6.3.1 Multilevel association rules
For many applications, it is dicult to nd strong associations among data items at low or primitive levels of
abstraction due to the sparsity of data in multidimensional space. Strong associations discovered at very high
concept levels may represent common sense knowledge. However, what may represent common sense to one user,
may seem novel to another. Therefore, data mining systems should provide capabilities to mine association rules at
multiple levels of abstraction and traverse easily among dierent abstraction spaces.
Let's examine the following example.
Example 6.3 Suppose we are given the task-relevant set of transactional data in Table 6.1 for sales at the computer
department of an AllElectronics branch, showing the items purchased for each transaction TID. The concept hierarchy
for the items is shown in Figure 6.8. A concept hierarchy denes a sequence of mappings from a set of low level
concepts to higher level, more general concepts. Data can be generalized by replacing low level concepts within the
data by their higher level concepts, or ancestors, from a concept hierarchy 4 . The concept hierarchy of Figure 6.8 has
4 Concept hierarchies were described in detail in Chapters 2 and 4. In order to make the chapters of this book as self-contained as
possible, we oer their denition again here. Generalization was described in Chapter 5.
6.3. MINING MULTILEVEL ASSOCIATION RULES FROM TRANSACTION DATABASES
13
all(computer items)
computer
software
computer
printer
accessory
home
laptop
educational
financial
color
wrist
b/w
pad
management
IBM
Microsoft
mouse
HP Epson
Canon
Ergo-
Logitech
way
Figure 6.8: A concept hierarchy for AllElectronics computer items.
four levels, referred to as levels 0, 1, 2, and 3. By convention, levels within a concept hierarchy are numbered from top
to bottom, starting with level 0 at the root node for all (the most general abstraction level). Here, level 1 includes
computer, software, printer and computer accessory, level 2 includes home computer, laptop computer, education
software, nancial management software, .., and level 3 includes IBM home computer, .., Microsoft educational
software, and so on. Level 3 represents the most specic abstraction level of this hierarchy. Concept hierarchies may
be specied by users familiar with the data, or may exist implicitly in the data.
TID
1
2
3
4
5
...
Items Purchased
IBM home computer, Sony b/w printer
Microsoft educational software, Microsoft nancial management software
Logitech mouse computer-accessory, Ergo-way wrist pad computer-accessory
IBM home computer, Microsoft nancial management software
IBM home computer
. ..
Table 6.1: Task-relevant data, D.
The items in Table 6.1 are at the lowest level of the concept hierarchy of Figure 6.8. It is dicult to nd interesting
purchase patterns at such raw or primitive level data. For instance, if \IBM home computer" or \Sony b/w (black
and white) printer" each occurs in a very small fraction of the transactions, then it may be dicult to nd strong
associations involving such items. Few people may buy such items together, making it is unlikely that the itemset
\fIBM home computer, Sony b/w printerg" will satisfy minimum support. However, consider the generalization
of \Sony b/w printer" to \b/w printer". One would expect that it is easier to nd strong associations between
\IBM home computer" and \b/w printer" rather than between \IBM home computer" and \Sony b/w printer".
Similarly, many people may purchase \computer" and \printer" together, rather than specically purchasing \IBM
home computer" and \Sony b/w printer" together. In other words, itemsets containing generalized items, such as
\fIBM home computers, b/w printerg" and \fcomputer, printerg" are more likely to have minimum support than
itemsets containing only primitive level data, such as \fIBM home computers, Sony b/w printerg". Hence, it is
easier to nd interesting associations among items at multiple concept levels, rather than only among low level data.
2
Rules generated from association rule mining with concept hierarchies are called multiple-level or multilevel
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
14
level 1
min_sup = 5%
level 2
min_sup = 5%
computer [support = 10%]
laptop computer [support = 6%]
home computer [support = 4%]
Figure 6.9: Multilevel mining with uniform support.
level 1
min_sup = 5%
level 2
min_sup = 3%
computer [support = 10%]
laptop computer [support = 6%]
home computer [support = 4%]
Figure 6.10: Multilevel mining with reduced support.
association rules, since they consider more than one concept level.
6.3.2 Approaches to mining multilevel association rules
\How can we mine multilevel association rules eciently using concept hierarchies?"
Let's look at some approaches based on a support-condence framework. In general, a top-down strategy is
employed, where counts are accumulated for the calculation of frequent itemsets at each concept level, starting at
the concept level 1 and working towards the lower, more specic concept levels, until no more frequent itemsets can
be found. That is, once all frequent itemsets at concept level 1 are found, then the frequent itemsets at level 2 are
found, and so on. For each level, any algorithm for discovering frequent itemsets may be used, such as Apriori or its
variations. A number of variations to this approach are described below, and illustrated in Figures 6.9 to 6.13, where
rectangles indicate an item or itemset that has been examined, and rectangles with thick borders indicate that an
examined item or itemset is frequent.
1. Using uniform minimum support for all levels (referred to as uniform support): The same minimum
support threshold is used when mining at each level of abstraction. For example, in Figure 6.9, a minimum
support threshold of 5% is used throughout (e.g., for mining from \computer" down to \laptop computer").
Both \computer" and \laptop computer" are found to be frequent, while \home computer" is not.
When a uniform minimum support threshold is used, the search procedure is simplied. The method is also
simple in that users are required to specify only one minimum support threshold. An optimization technique
can be adopted, based on the knowledge that an ancestor is a superset of its descendents: the search avoids
examining itemsets containing any item whose ancestors do not have minimum support.
The uniform support approach, however, has some diculties. It is unlikely that items at lower levels of
abstraction will occur as frequently as those at higher levels of abstraction. If the minimumsupport threshold is
set too high, it could miss several meaningful associations occurring at low abstraction levels. If the threshold is
level 1
min_sup = 12%
level 2
min_sup = 3%
computer [support = 10%]
laptop (not examined)
home computer (not examined)
Figure 6.11: Multilevel mining with reduced support, using level-cross ltering by a single item.
6.3. MINING MULTILEVEL ASSOCIATION RULES FROM TRANSACTION DATABASES
level 1
15
computer & printer [support = 7%]
min_sup = 5%
level 2
min_sup = 2%
laptop computer &
b/w printer
[support = 1%]
laptop computer &
color printer
[support = 2%]
home computer &
b/w printer
[support = 1%]
home computer &
color printer
[support = 3%]
Figure 6.12: Multilevel mining with reduced support, using level-cross ltering by a k-itemset. Here, k = 2.
set too low, it may generate many uninteresting associations occurring at high abstraction levels. This provides
the motivation for the following approach.
2. Using reduced minimum support at lower levels (referred to as reduced support): Each level of
abstraction has its own minimum support threshold. The lower the abstraction level is, the smaller the corresponding threshold is. For example, in Figure 6.10, the minimum support thresholds for levels 1 and 2 are 5%
and 3%, respectively. In this way, \computer", \laptop computer", and \home computer" are all considered
frequent.
For mining multiple-level associations with reduced support, there are a number of alternative search strategies.
These include:
1. level-by-level independent: This is a full breadth search, where no background knowledge of frequent
itemsets is used for pruning. Each node is examined, regardless of whether or not its parent node is found to
be frequent.
2. level-cross ltering by single item: An item at the i-th level is examined if and only if its parent node at the
(i , 1)-th level is frequent. In other words, we investigate a more specic association from a more general one.
If a node is frequent, its children will be examined; otherwise, its descendents are pruned from the search. For
example, in Figure 6.11, the descendent nodes of \computer" (i.e., \laptop computer" and \home computer")
are not examined, since \computer" is not frequent.
3. level-cross ltering by k-itemset: A k-itemset at the i-th level is examined if and only if its corresponding
parent k-itemset at the (i , 1)-th level is frequent. For example, in Figure 6.12, the 2-itemset \fcomputer,
printerg" is frequent, therefore the nodes \flaptop computer, b/w printerg", \flaptop computer, color printerg",
\fhome computer, b/w printerg", and \fhome computer, color printerg" are examined.
\How do these methods compare?"
The level-by-level independent strategy is very relaxed in that it may lead to examining numerous infrequent
items at low levels, nding associations between items of little importance. For example, if \computer furniture"
is rarely purchased, it may not be benecial to examine whether the more specic \computer chair" is associated
with \laptop". However, if \computer accessories" are sold frequently, it may be benecial to see whether there is
an associated purchase pattern between \laptop" and \mouse".
The level-cross ltering by k-itemset strategy allows the mining system to examine only the children of frequent
k-itemsets. This restriction is very strong in that there usually are not many k-itemsets (especially when k > 2)
which, when combined, are also frequent. Hence, many valuable patterns may be ltered out using this approach.
The level-cross ltering by single item strategy represents a compromise between the two extremes. However,
this method may miss associations between low level items that are frequent based on a reduced minimum support,
but whose ancestors do not satisfy minimum support (since the support thresholds at each level can be dierent).
For example, if \color monitor" occurring at concept level i is frequent based on the minimum support threshold of
level i, but its parent \monitor" at level (i , 1) is not frequent according to the minimum support threshold of level
(i , 1), then frequent associations such as \home computer ) color monitor" will be missed.
A modied version of the level-cross ltering by single item strategy, known as the controlled level-cross
ltering by single item strategy, addresses the above concern as follows. A threshold, called the level passage
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
16
level 1
min_sup = 12%
level_passage_sup = 8%
level 2
min_sup = 3%
.
computer [support = 10%]
laptop computer [support = 6%]
home computer [support = 4%]
Figure 6.13: Multilevel mining with controlled level-cross ltering by single item
threshold, can be set up for \passing down" relatively frequent items (called subfrequent items) to lower levels.
In other words, this method allows the children of items that do not satisfy the minimum support threshold to
be examined if these items satisfy the level passage threshold. Each concept level can have its own level passage
threshold. The level passage threshold for a given level is typically set to a value between the minimum support
threshold of the next lower level and the minimum support threshold of the given level. Users may choose to \slide
down" or lower the level passage threshold at high concept levels to allow the descendents of the subfrequent items
at lower levels to be examined. Sliding the level passage threshold down to the minimum support threshold of the
lowest level would allow the descendents of all of the items to be examined. For example, in Figure 6.13, setting the
level passage threshold (level passage sup) of level 1 to 8% allows the nodes \laptop computer" and \home computer"
at level 2 to be examined and found frequent, even though their parent node, \computer", is not frequent. By adding
this mechanism, users have the exibility to further control the mining process at multiple abstraction levels, as well
as reduce the number of meaningless associations that would otherwise be examined and generated.
So far, our discussion has focussed on nding frequent itemsets where all items within the itemset must belong to
the same concept level. This may result in rules such as \computer ) printer" (where \computer" and \printer"
are both at concept level 1) and \home computer ) b/w printer" (where \home computer" and \b/w printer" are
both at level 2 of the given concept hierarchy). Suppose, instead, that we would like to nd rules that cross concept
level boundaries, such as \computer ) b/w printer", where items within the rule are not required to belong to the
same concept level. These rules are called cross-level association rules.
\How can cross-level associations be mined?" If mining associations from concept levels i and j, where level j is
more specic (i.e., at a lower abstraction level) than i, then the reduced minimum support threshold of level j should
be used overall so that items from level j can be included in the analysis.
6.3.3 Checking for redundant multilevel association rules
Concept hierarchies are useful in data mining since they permit the discovery of knowledge at dierent levels of
abstraction, such as multilevel association rules. However, when multilevel association rules are mined, some of the
rules found will be redundant due to \ancestor" relationships between items. For example, consider Rules (6.9) and
(6.10) below, where \home computer" is an ancestor of \IBM home computer" based on the concept hierarchy of
Figure 6.8.
home computer ) b =w printer ;
[support = 8%; confidence = 70%]
(6.9)
IBM home computer ) b =w printer ;
[support = 2%; confidence = 72%]
(6.10)
\If Rules (6.9) and (6.10) are both mined, then how useful is the latter rule?", you may wonder. \Does it really
provide any novel information?"
If the latter, less general rule does not provide new information, it should be removed. Let's have a look at how
this may be determined. A rule R1 is an ancestor of a rule R2 if R1 can be obtained by replacing the items in R2 by
their ancestors in a concept hierarchy. For example, Rule (6.9) is an ancestor of Rule (6.10) since \home computer"
is an ancestor of \IBM home computer". Based on this denition, a rule can be considered redundant if its support
and condence are close to their \expected" values, based on an ancestor of the rule. As an illustration, suppose
that Rule (6.9) has a 70% condence and 8% support, and that about one quarter of all \home computer" sales are
for \IBM home computers", and a quarter of all \printers" sales are \black/white printers" sales. One may expect
6.4. MINING MULTIDIMENSIONAL ASSOCIATION RULES FROM RELATIONAL DATABASES AND DATA WAREHOUSE
Rule (6.10) to have a condence of around 70% (since all data samples of \IBM home computer" are also samples of
\home computer") and a support of 2% (i.e., 8% 14 ). If this is indeed the case, then Rule (6.10) is not interesting
since it does not oer any additional information and is less general than Rule (6.9).
6.4 Mining multidimensional association rules from relational databases and data
warehouses
6.4.1 Multidimensional association rules
Up to this point in this chapter, we have studied association rules which imply a single predicate, that is, the predicate
buys. For instance, in mining our AllElectronics database, we may discover the Boolean association rule \IBM home
computer ) Sony b/w printer", which can also be written as
buys(X; \IBM home computer") ) buys(X; \Sony b=w printer");
(6.11)
where X is a variable representing customers who purchased items in AllElectronics transactions. Similarly, if
\printer" is a generalization of \Sony b/w printer", then a multilevel association rule like \IBM home computers
) printer" can be expressed as
buys(X; \IBM home computer") ) buys(X; \printer"):
(6.12)
Following the terminology used in multidimensional databases, we refer to each distinct predicate in a rule as a
dimension. Hence, we can refer to Rules (6.11) and (6.12) as single-dimensional or intra-dimension association
rules since they each contain a single distinct predicate (e.g., buys) with multiple occurrences (i.e., the predicate
occurs more than once within the rule). As we have seen in the previous sections of this chapter, such rules are
commonly mined from transactional data.
Suppose, however, that rather than using a transactional database, sales and related information are stored
in a relational database or data warehouse. Such data stores are multidimensional, by denition. For instance,
in addition to keeping track of the items purchased in sales transactions, a relational database may record other
attributes associated with the items, such as the quantity purchased or the price, or the branch location of the sale.
Addition relational information regarding the customers who purchased the items, such as customer age, occupation,
credit rating, income, and address, may also be stored. Considering each database attribute or warehouse dimension
as a predicate, it can therefore be interesting to mine association rules containing multiple predicates, such as
age(X; \19 , 24") ^ occupation(X; \student") ) buys(X; \laptop"):
(6.13)
Association rules that involve two or more dimensions or predicates can be referred to as multidimensional association rules. Rule (6.13) contains three predicates (age, occupation, and buys), each of which occurs only once in
the rule. Hence, we say that it has no repeated predicates. Multidimensional association rules with no repeated
predicates are called inter-dimension association rules. We may also be interested in mining multidimensional
association rules with repeated predicates, which contain multiple occurrences of some predicate. These rules are
called hybrid-dimension association rules. An example of such a rule is Rule (6.14), where the predicate buys
is repeated.
age(X; \19 , 24") ^ buys(X; \laptop") ) buys(X; \b=w printer"):
(6.14)
Note that database attributes can be categorical or quantitative. Categorical attributes have a nite number
of possible values, with no ordering among the values (e.g., occupation, brand, color). Categorical attributes are also
called nominal attributes, since their values are \names of things". Quantitative attributes are numeric and have
an implicit ordering among values (e.g., age, income, price). Techniques for mining multidimensional association rules
can be categorized according to three basic approaches regarding the treatment of quantitative (continuous-valued)
attributes.
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
18
0-D (apex) cuboid; all
()
1-D cuboids
(age)
(income)
(buys)
2-D cuboids
(age, income)
(age, buys)
(age, income, buys)
(income, buys)
3-D (base) cuboid
Figure 6.14: Lattice of cuboids, making up a 3-dimensional data cube. Each cuboid represents a dierent group-by.
The base cuboid contains the three predicates, age, income, and buys.
1. In the rst approach, quantitative attributes are discretized using predened concept hierarchies. This discretization occurs prior to mining. For instance, a concept hierarchy for income may be used to replace the
original numeric values of this attribute by ranges, such as \0-20K", \21-30K", \31-40K", and so on. Here,
discretization is static and predetermined. The discretized numeric attributes, with their range values, can then
be treated as categorical attributes (where each range is considered a category). We refer to this as mining
multidimensional association rules using static discretization of quantitative attributes.
2. In the second approach, quantitative attributes are discretized into \bins" based on the distribution of the data.
These bins may be further combined during the mining process. The discretization process is dynamic and
established so as to satisfy some mining criteria, such as maximizing the condence of the rules mined. Because
this strategy treats the numeric attribute values as quantities rather than as predened ranges or categories,
association rules mined from this approach are also referred to as quantitative association rules.
3. In the third approach, quantitative attributes are discretized so as to capture the semantic meaning of such
interval data. This dynamic discretization procedure considers the distance between data points. Hence, such
quantitative association rules are also referred to as distance-based association rules.
Let's study each of these approaches for mining multidimensional association rules. For simplicity, we conne our
discussion to inter-dimension association rules. Note that rather than searching for frequent itemsets (as is done
for single-dimensional association rule mining), in multidimensional association rule mining we search for frequent
predicatesets. A k-predicateset is a set containing k conjunctive predicates. For instance, the set of predicates
fage, occupation, buysg from Rule (6.13) is a 3-predicateset. Similar to the notation used for itemsets, we use the
notation Lk to refer to the set of frequent k-predicatesets.
6.4.2 Mining multidimensional association rules using static discretization of quantitative attributes
Quantitative attributes, in this case, are discretized prior to mining using predened concept hierarchies, where
numeric values are replaced by ranges. Categorical attributes may also be generalized to higher conceptual levels if
desired.
If the resulting task-relevant data are stored in a relational table, then the Apriori algorithm requires just a slight
modication so as to nd all frequent predicatesets rather than frequent itemsets (i.e., by searching through all of
the relevant attributes, instead of searching only one attribute, like buys). Finding all frequent k-predicatesets will
require k or k + 1 scans of the table. Other strategies, such as hashing, partitioning, and sampling may be employed
to improve the performance.
Alternatively, the transformed task-relevant data may be stored in a data cube. Data cubes are well-suited for the
mining of multidimensional association rules, since they are multidimensional by denition. Data cubes, and their
computation, were discussed in detail in Chapter 2. To review, a data cube consists of a lattice of cuboids which
6.4. MINING MULTIDIMENSIONAL ASSOCIATION RULES FROM RELATIONAL DATABASES AND DATA WAREHOUSE
are multidimensional data structures. These structures can hold the given task-relevant data, as well as aggregate,
group-by information. Figure 6.14 shows the lattice of cuboids dening a data cube for the dimensions age, income,
and buys. The cells of an n-dimensional cuboid are used to store the counts, or support, of the corresponding npredicatesets. The base cuboid aggregates the task-relevant data by age, income, and buys; the 2-D cuboid, (age,
income), aggregates by age and income; the 0-D (apex) cuboid contains the total number of transactions in the task
relevant data, and so on.
Due to the ever-increasing use of data warehousing and OLAP technology, it is possible that a data cube containing
the dimensions of interest to the user may already exist, fully materialized. \If this is the case, how can we go about
nding the frequent predicatesets?" A strategy similar to that employed in Apriori can be used, based on prior
knowledge that every subset of a frequent predicateset must also be frequent. This property can be used to reduce
the number of candidate predicatesets generated.
In cases where no relevant data cube exists for the mining task, one must be created. Chapter 2 describes
algorithms for fast, ecient computation of data cubes. These can be modied to search for frequent itemsets during
cube construction. Studies have shown that even when a cube must be constructed on the y, mining from data
cubes can be faster than mining directly from a relational table.
6.4.3 Mining quantitative association rules
Quantitative association rules are multidimensional association rules in which the numeric attributes are dynamically
discretized during the mining process so as to satisfy some mining criteria, such as maximizing the condence or
compactness of the rules mined. In this section, we will focus specically on how to mine quantitative association rules
having two quantitative attributes on the left-hand side of the rule, and one categorical attribute on the right-hand
side of the rule, e.g.,
Aquan1 ^ Aquan2 ) Acat,
where Aquan1 and Aquan2 are tests on quantitative attribute ranges (where the ranges are dynamically determined), and Acat tests a categorical attribute from the task-relevant data. Such rules have been referred to as
two-dimensional quantitative association rules, since they contain two quantitative dimensions. For instance,
suppose you are curious about the association relationship between pairs of quantitative attributes, like customer age
and income, and the type of television that customers like to buy. An example of such a 2-D quantitative association
rule is
age(X; \30 , 34") ^ income(X; \42K , 48K") ) buys (X ; \high resolution TV ")
(6.15)
\How can we nd such rules?" Let's look at an approach used in a system called ARCS (Association Rule
Clustering System) which borrows ideas from image-processing. Essentially, this approach maps pairs of quantitative
attributes onto a 2-D grid for tuples satisfying a given categorical attribute condition. The grid is then searched for
clusters of points, from which the association rules are generated. The following steps are involved in ARCS:
Binning. Quantitative attributes can have a very wide range of values dening their domain. Just think about
how big a 2-D grid would be if we plotted age and income as axes, where each possible value of age was assigned
a unique position on one axis, and similarly, each possible value of income was assigned a unique position on the
other axis! To keep grids down to a manageable size, we instead partition the ranges of quantitative attributes into
intervals. These intervals are dynamic in that they may later be further combined during the mining process. The
partitioning process is referred to as binning, i.e., where the intervals are considered \bins". Three common binning
strategies are:
1. equi-width binning, where the interval size of each bin is the same,
2. equi-depth binning, where each bin has approximately the same number of tuples assigned to it, and
3. homogeneity-based binning, where bin size is determined so that the tuples in each bin are uniformly
distributed.
In ARCS, equi-width binning is used, where the bin size for each quantitative attribute is input by the user. A
2-D array for each possible bin combination involving both quantitative attributes is created. Each array cell holds
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
20
70-80K
60-70K
income
50-60K
40-50K
30-40K
20-30K
<20K
32
33
34
35
36
37
38
age
.
Figure 6.15: A 2-D grid for tuples representing customers who purchase high resolution TVs
the corresponding count distribution for each possible class of the categorical attribute of the rule right-hand side.
By creating this data structure, the task-relevant data need only be scanned once. The same 2-D array can be used
to generate rules for any value of the categorical attribute, based on the same two quantitative attributes. Binning
is also discussed in Chapter 3.
Finding frequent predicatesets. Once the 2-D array containing the count distribution for each category is
set up, this can be scanned in order to nd the frequent predicatesets (those satisfying minimum support) that also
satisfy minimum condence. Strong association rules can then be generated from these predicatesets, using a rule
generation algorithm like that described in Section 6.2.2.
Clustering the association rules. The strong association rules obtained in the previous step are then mapped
to a 2-D grid. Figure 6.15 shows a 2-D grid for 2-D quantitative association rules predicting the condition buys(X,
\high resolution TV") on the rule right-hand side, given the quantitative attributes age and income. The four \X"'s
correspond to the rules
age(X; 34) ^ income(X; \30 , 40K")
age(X; 35) ^ income(X; \30 , 40K")
age(X; 34) ^ income(X; \40 , 50K")
age(X; 35) ^ income(X; \40 , 50K")
)
)
)
)
buys (X ; \high
buys (X ; \high
buys (X ; \high
buys (X ; \high
resolution
resolution
resolution
resolution
TV ")
TV ")
TV ")
TV ")
(6.16)
(6.17)
(6.18)
(6.19)
\Can we nd a simpler rule to replace the above four rules?" Notice that these rules are quite \close" to one
another, forming a rule cluster on the grid. Indeed, the four rules can be combined or \clustered" together to form
Rule (6.20) below, a simpler rule which subsumes and replaces the above four rules.
age(X; \34 , 35") ^ income(X; \30 , 50K") ) buys (X ; \high resolution TV ")
(6.20)
ARCS employs a clustering algorithm for this purpose. The algorithm scans the grid, searching for rectangular
clusters of rules. In this way, bins of the quantitative attributes occurring within a rule cluster may be further
combined, and hence, further dynamic discretization of the quantitative attributes occurs.
The grid-based technique described here assumes that the initial association rules can be clustered into rectangular
regions. Prior to performing the clustering, smoothing techniques can be used to help remove noise and outliers from
the data. Rectangular clusters may oversimplify the data. Alternative approaches have been proposed, based on
other shapes of regions which tend to better t the data, yet require greater computation eort.
A non-grid-based technique has been proposed to nd more general quantitative association rules where any
number of quantitative and categorical attributes can appear on either side of the rules. In this technique, quantitative
attributes are dynamically partitioned using equi-depth binning, and the partitions are combined based on a measure
of partial completeness which quanties the information lost due to partitioning. For references on these alternatives
to ARCS, see the bibliographic notes.
6.4. MINING MULTIDIMENSIONAL ASSOCIATION RULES FROM RELATIONAL DATABASES AND DATA WAREHOUSE
Price ($) Equi-width
(width $10)
7
[0, 10]
20
[11, 20]
22
[21, 30]
50
[31, 40]
51
[41, 50]
53
[51, 60]
Equi-depth
(depth $2)
[7, 20]
[22, 50]
[51, 53]
Distance-based
[7, 7]
[20, 22]
[50, 53]
Figure 6.16: Binning methods like equi-width and equi-depth do not always capture the semantics of interval data.
6.4.4 Mining distance-based association rules
The previous section described quantitative association rules where quantitative attributes are discretized initially
by binning methods, and the resulting intervals are then combined. Such an approach, however, may not capture the
semantics of interval data since they do not consider the relative distance between data points or between intervals.
Consider, for example, Figure 6.16 which shows data for the attribute price, partitioned according to equiwidth and equi-depth binning versus a distance-based partitioning. The distance-based partitioning seems the most
intuitive, since it groups values that are close together within the same interval (e.g., [20, 22]). In contrast, equi-depth
partitioning groups distant values together (e.g., [22, 50]). Equi-width may split values that are close together and
create intervals for which there are no data. Clearly, a distance-based partitioning which considers the density or
number of points in an interval, as well as the \closeness" of points in an interval helps produce a more meaningful
discretization. Intervals for each quantitative attribute can be established by clustering the values for the attribute.
A disadvantage of association rules is that they do not allow for approximations of attribute values. Consider
association rule (6.21):
item type(X; \electronic") ^ manufacturer(X; \foreign") ) price(X; $200):
(6.21)
In reality, it is more likely that the prices of foreign electronic items are close to or approximately $200, rather than
exactly $200. It would be useful to have association rules that can express such a notion of closeness. Note that
the support and condence measures do not consider the closeness of values for a given attribute. This motivates
the mining of distance-based association rules which capture the semantics of interval data while allowing for
approximation in data values. Distance-based based association rules can be mined by rst employing clustering
techniques to nd the intervals or clusters, and then searching for groups of clusters that occur frequently together.
Clusters and distance measurements
\What kind of distance-based measurements can be used for identifying the clusters?", you wonder. \What denes a
cluster?"
Let S[X] be a set of N tuples t1 ; t2; ::; tN projected on the attribute set X. The diameter, d, of S[X] is the
average pairwise distance between the tuples projected on X. That is,
d(S[X]) =
PN PN
i=1
j =1 distX (ti [X]; tj [X]) ;
N(N , 1)
(6.22)
where distX is a distance metric on the values for the attribute set X, such as the Euclidean distance or the
Manhattan. For example, suppose that X contains m attributes. The Euclidean distance between two tuples
t1 = (x11; x12; ::; x1m) and t2 = (x21; x22; ::; x2m) is
Euclidean d(t1 ; t2) =
v
um
uX
t
(x1i
i=1
, x2i)2 :
(6.23)
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
22
The Manhattan (city block) distance between t1 and t2 is
Manhattan d(t1; t2) =
m
X
i=1
jx1i , x2ij:
(6.24)
The diameter metric assesses the closeness of tuples. The smaller the diameter of S[X] is, the \closer" its tuples
are when projected on X. Hence, the diameter metric assesses the density of a cluster. A cluster CX is a set of tuples
dened on an attribute set X, where the tuples satisfy a density threshold, dX0 , and a frequency threshold, s0 ,
such that:
d(CX ) dX0
jCX j s0 :
(6.25)
(6.26)
Clusters can be combined to form distance-based association rules. Consider a simple distance-based association
rule of the form CX ) CY . Suppose that X is the attribute set fageg and Y is the attribute set fincomeg. We want
to ensure that the implication between the cluster CX for age and CY for income is strong. This means that when
the age-clustered tuples CX are projected onto the attribute income, their corresponding income values lie within
the income-cluster CY , or close to it. A cluster CX projected onto the attribute set Y is denoted CX [Y ]. Therefore,
the distance between CX [Y ] and CY [Y ] must be small. This distance measures the degree of association between CX
and CY . The smaller the distance between CX [Y ] and CY [Y ] is, the stronger the degree of association between CX
and CY is. The degree of association measure can be dened using standard statistical measures, such as the average
inter-cluster distance, or the centroid Manhattan distance, where the centroid of a cluster represents the \average"
tuple of the cluster.
Finding clusters and distance-based rules
An adaptive two-phase algorithm can be used to nd distance-based association rules, where clusters are identied
in the rst phase, and combined in the second phase to form the rules.
A modied version of the BIRCH5 clustering algorithm is used in the rst phase, which requires just one pass
through the data. To compute the distance between clusters, the algorithm maintains a data structure called an
association clustering feature for each cluster which maintains information about the cluster and its projection onto
other attribute sets. The clustering algorithm adapts to the amount of available memory.
In the second phase, clusters are combined to nd distance-based association rules of the form
CX1 CX2 ::CXx ) CY1 CY2 ::CYy ,
where Xi and Yj are pairwise disjoint sets of attributes, D is measure of the degree of association between clusters
as described above, and the following conditions are met:
1. The clusters in the rule antecedent each are strongly associated with each cluster in the consequent. That is,
D(CYj [Yj ]; CXi [Yj ]) D0 , 1 i x; 1 j y, where D0 is the degree of association threshold.
2. The clusters in the antecedent collectively occur together. That is, D(CXi [Xi ]; CXj [Xi]) dX0 i 8i 6= j.
3. The clusters in the consequent collectively occur together. That is, D(CYi [Yi]; CYj [Yi]) dY0 i 8i 6= j, where dY0 i
is the density threshold on attribute set Yi .
The degree of association replaces the condence framework in non-distance-based association rules, while the
density threshold replaces the notion of support.
Rules are found with the help of a clustering graph, where each node in the graph represents a cluster. An edge
is drawn from one cluster node, nCX , to another, nCY , if D(CX [X]; CY [X]) dX0 and D(CX [Y ]; CY [Y ]) dY0 . A
clique in such a graph is a subset of nodes, each pair of which is connected by an edge. The algorithm searches for
all maximal cliques. These correspond to frequent itemsets from which the distance-based association rules can be
generated.
5
The BIRCH clustering algorithm is described in detail in Chapter 8 on clustering.
6.5. FROM ASSOCIATION MINING TO CORRELATION ANALYSIS
23
6.5 From association mining to correlation analysis
\When mining association rules, how can the data mining system tell which rules are likely to be interesting to the
user?"
Most association rule mining algorithms employ a support-condence framework. In spite of using minimum
support and condence thresholds to help weed out or exclude the exploration of uninteresting rules, many rules that
are not interesting to the user may still be produced. In this section, we rst look at how even strong association
rules can be uninteresting and misleading, and then discuss additional measures based on statistical independence
and correlation analysis.
6.5.1 Strong rules are not necessarily interesting: An example
\In data mining, are all of the strong association rules discovered (i.e., those rules satisfying the minimum support
and minimum condence thresholds) interesting enough to present to the user?" Not necessarily. Whether a rule is
interesting or not can be judged either subjectively or objectively. Ultimately, only the user can judge if a given rule
is interesting or not, and this judgement, being subjective, may dier from one user to another. \behind" the data,
can be used as one step towards the goal of weeding out uninteresting rules from presentation to the user.
\So, how can we tell which strong association rules are really interesting?" Let's examine the following example.
Example 6.4 Suppose we are interested in analyzing transactions at AllElectronics with respect to the purchase
of computer games and videos. The event game refers to the transactions containing computer games, while video
refers to those containing videos. Of the 10; 000 transactions analyzed, the data show that 6; 000 of the customer
transactions included computer games, while 7; 500 included videos, and 4; 000 included both computer games and
videos. Suppose that a data mining program for discovering association rules is run on the data, using a minimum
support of, say, 30% and a minimum condence of 60%. The following association rule is discovered.
buys (X ; \computer games ") ) buys (X ; \videos ");
[support = 40%; confidence = 66%]
(6.27)
= 40%
Rule (6.27) is a strong association rule and would therefore be reported, since its support value of 104;;000
000
4;000
and condence value of 6;000 = 66% satisfy the minimum support and minimum condence thresholds, respectively.
However, Rule (6.27) is misleading since the probability of purchasing videos is 75%, which is even larger than 66%.
In fact, computer games and videos are negatively associated because the purchase of one of these items actually
decreases the likelihood of purchasing the other. Without fully understanding this phenomenon, one could make
unwise business decisions based on the rule derived.
2
The above example also illustrates that the condence of a rule A ) B can be deceiving in that it is only an
estimate of the conditional probability of B given A. It does not measure the real strength (or lack of strength) of
the implication between A and B. Hence, alternatives to the support-condence framework can be useful in mining
interesting data relationships.
6.5.2 From association analysis to correlation analysis
Association rules mined using a support-condence framework are useful for many applications. However, the
support-condence framework can be misleading in that it may identify a rule A ) B as interesting, when in fact, A
does not imply B. In this section, we consider an alternative framework for nding interesting relationships between
data items based on correlation.
Two events A and B are independent if P(A) ^ P(B) = 1, otherwise A and B are dependent and correlated.
This denition can easily be extended to more than two variables. The correlation between A and B can be
measured by computing
P(A ^ B)
P(A)P(B) :
(6.28)
24
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
game game row
video 4,000 3,500 7,500
video 2,000 500 2,500
col 6,000 4,000 10,000
Table 6.2: A contingency table summarizing the transactions with respect to computer game and video purchases.
If the resulting value of Equation (6.28) is less than 1, then A and B are negatively correlated, meaning that each
event discourages the occurrence of the other. If the resulting value is greater than 1, then A and B are positively
correlated, meaning that each event implies the other. If the resulting value is equal to 1, then A and B are
independent and there is no correlation between them.
Let's go back to the computer game and video data of Example 6.4.
Example 6.5 To help lter out misleading \strong" associations of the form A ) B, we need to study how the
two events, A and B, are correlated. Let game refer to the transactions of Example 6.4 which do not contain
computer games, and video refer to those that do not contain videos. The transactions can be summarized in a
contingency table. A contingency table for the data of Example 6.4 is shown in Table 6.2. From the table, one
can see that the probability of purchasing a computer game is P(game) = 0:60, the probability of purchasing a
video is P(video) = 0:75, and the probability of purchasing both is P(game ^ video) = 0:40. By Equation (6.28),
P(game ^ video)=(P (game) P(video)) = 0:40=(0:75 0:60) = 0.89. Since this value is signicantly less than 1,
there is a negative correlation between computer games and videos. The nominator is the likelihood of a customer
purchasing both, while the denominator is what the likelihood would have been if the two purchases were completely
independent. Such a negative correlation cannot be identied by a support-condence framework.
2
This motivates the mining of rules that identify correlations, or correlation rules. A correlation rule is of the
form fe1 ; e2; ::; emg where the occurrences of the events (or items) fe1 ; e2; ::; emg are correlated. Given a correlation
value determined by Equation (6.28), the 2 statistic can be used to determine if the correlation is statistically
signicant. The 2 statistic can also determine negative implication.
An advantage of correlation is that it is upward closed. This means that if a set S of items is correlated (i.e.,
the items in S are correlated), then every superset of S is also correlated. In other words, adding items to a set
of correlated items does not remove the existing correlation. The 2 statistic is also upward closed within each
signicance level.
When searching for sets of correlations to form correlation rules, the upward closure property of correlation and
2 can be used. Starting with the empty set, we may explore the itemset space (or itemset lattice), adding one item
at a time, looking for minimal correlated itemsets - itemsets that are correlated although no subset of them is
correlated. These itemsets form a border within the lattice. Because of closure, no itemset below this border will
be correlated. Since all supersets of a minimal correlated itemset are correlated, we can stop searching upwards.
An algorithm that perform a series of such \walks" through itemset space is called a random walk algorithm.
Such an algorithm can be combined with tests of support in order to perform additional pruning. Random walk
algorithms can easily be implemented using data cubes. It is an open problem to adapt the procedure described here
to very lary databases. Another limitation is that the 2 statistic is less accurate when the contingency table data
are sparse. More research is needed in handling such cases.
6.6 Constraint-based association mining
For a given set of task-relevant data, the data mining process may uncover thousands of rules, many of which are
uninteresting to the user. In constraint-based mining, mining is performed under the guidance of various kinds
of constraints provided by the user. These constraints include the following.
1. Knowledge type constraints: These specify the type of knowledge to be mined, such as association.
2. Data constraints: These specify the set of task-relevant data.
6.6. CONSTRAINT-BASED ASSOCIATION MINING
25
3. Dimension/level constraints: These specify the dimension of the data, or levels of the concept hierarchies,
to be used.
4. Interestingness constraints: These specify thresholds on statistical measures of rule interestingness, such
as support and condence.
5. Rule constraints. These specify the form of rules to be mined. Such constraints may be expressed as metarules
(rule templates), or by specifying the maximum or minimum number of predicates in the rule antecedent or
consequent, or the satisfaction of particular predicates on attribute values, or their aggregates.
The above constraints can be specied using a high-level declarative data mining query language, such as that
described in Chapter 4.
The rst four of the above types of constraints have already been addressed in earlier parts of this book and
chapter. In this section, we discuss the use of rule constraints to focus the mining task. This form of constraintbased mining enriches the relevance of the rules mined by the system to the users' intentions, thereby making the
data mining process more eective. In addition, a sophisticated mining query optimizer can be used to exploit the
constraints specied by the user, thereby making the mining process more ecient.
Constraint-based mining encourages interactive exploratory mining and analysis. In Section 6.6.1, you will study
metarule-guided mining, where syntactic rule constraints are specied in the form of rule templates. Section 6.6.2
discusses the use of additional rule constraints, specifying set/subset relationships, constant initiation of variables,
and aggregate functions. The examples in these sections illustrate various data mining query language primitives for
association mining.
6.6.1 Metarule-guided mining of association rules
\How are metarules useful?"
Metarules allow users to specify the syntactic form of rules that they are interested in mining. The rule forms can
be used as constraints to help improve the eciency of the mining process. Metarules may be based on the analyst's
experience, expectations, or intuition regarding the data, or automatically generated based on the database schema.
Example 6.6 Suppose that as a market analyst for AllElectronics, you have access to the data describing customers
(such as customer age, address, and credit rating) as well as the list of customer transactions. You are interested
in nding associations between customer traits and the items that customers buy. However, rather than nding all
of the association rules reecting these relationships, you are particularly interested only in determining which pairs
of customer traits promote the sale of educational software. A metarule can be used to specify this information
describing the form of rules you are interested in nding. An example of such a metarule is
P1 (X; Y ) ^ P2 (X; W) ) buys(X; \educational software");
(6.29)
where P1 and P2 are predicate variables that are instantiated to attributes from the given database during the
mining process, X is a variable representing a customer, and Y and W take on values of the attributes assigned to
P1 and P2, respectively. Typically, a user will specify a list of attributes to be considered for instantiation with P1
and P2. Otherwise, a default set may be used.
In general, a metarule forms a hypothesis regarding the relationships that the user is interested in probing
or conrming. The data mining system can then search for rules that match the given metarule. For instance,
Rule (6.30) matches or complies with Metarule (6.29).
age(X; \35 , 45") ^ income(X; \40 , 60K") ) buys(X; \educational software")
(6.30)
2
\How can metarules be used to guide the mining process?" Let's examine this problem closely. Suppose that we
wish to mine inter-dimension association rules, such as in the example above. A metarule is a rule template of the
form
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
26
P1 ^ P2 ^ : : : ^ Pl ) Q1 ^ Q2 ^ : : : ^ Qr
(6.31)
where Pi (i = 1; : : :; l) and Qj (j = 1; : : :; r) are either instantiated predicates or predicate variables. Let the number
of predicates in the metarule be p = l + r. In order to nd inter-dimension association rules satisfying the template:
We need to nd all frequent p-predicatesets, Lp .
We must also have the support or count of the l-predicate subsets of Lp in order to compute the condence of
rules derived from Lp .
This is a typical case of mining multidimensional association rules, which was described in Section 6.4. As shown
there, data cubes are well-suited to the mining of multidimensional association rules owing to their ability to store
aggregate dimension values. Owing to the popularity of OLAP and data warehousing, it is possible that a fully
materialized n-D data cube suitable for the given mining task already exists, where n is the number of attributes
to be considered for instantiation with the predicate variables plus the number of predicates already instantiated in
the given metarule, and n p. Such an n-D cube is typically represented by a lattice of cuboids, similar to that
shown in Figure 6.14. In this case, we need only scan the p-D cuboids, comparing each cell count with the minimum
support threshold, in order to nd Lp . Since the l-D cuboids have already been computed and contain the counts of
the l-D predicate subsets of Lp , a rule generation procedure can then be called to return strong rules that comply
with the given metarule. We call this approach an abridged n-D cube search, since rather than searching the
entire n-D data cube, only the p-D and l-D cuboids are ever examined.
If a relevant n-D data cube does not exist for the metarule-guided mining task, then one must be constructed
and searched. Rather than constructing the entire cube, only the p-D and l-D cuboids need be computed. Methods
for cube construction are discussed in Chapter 2.
6.6.2 Mining guided by additional rule constraints
Rule constraints specifying set/subset relationships, constant initiation of variables, and aggregate functions can be
specied by the user. These may be used together with, or as an alternative to, metarule-guided mining. In this
section, we examine rule constraints as to how they can be used to make the mining process more ecient. Let us
study an example where rule constraints are used to mine hybrid-dimension association rules.
Example 6.7 Suppose that AllElectronics has a sales multidimensional database with the following inter-related
relations:
sales(customer name, item name, transaction id),
lives(customer name, region, city),
item(item name, category, price), and
transaction(transaction id, day, month, year),
where lives, item, and transaction are three dimension tables, linked to the fact table sales via three keys, customer name, item name, and transaction id, respectively.
Our association mining query is to \nd the sales of what cheap items (where the sum of the prices is less than
$100) that may promote the sales of what expensive items (where the minimum price is $500) in the same category
for Vancouver customers in 1998". This can be expressed in the DMQL data mining query language as follows,
where each line of the query has been enumerated to aid in our discussion.
1)
2)
3)
4)
5)
mine associations as
lives(C; ; \V ancouver") ^ sales+ (C; ?fI g; fS g) ) sales+ (C; ?fJ g; fT g)
from sales
where S.year = 1998 and T.year = 1998 and I.category = J.category
group by C, I.category
6.6. CONSTRAINT-BASED ASSOCIATION MINING
6)
7)
8)
27
having sum(I.price) < 100 and min(J.price) 500
with support threshold = 0.01
with condence threshold = 0.5
Before we discuss the rule constraints, let us have a closer look at the above query. Line 1 is a knowledge type
constraint, where association patterns are to be discovered. Line 2 specied a metarule. This is an abbreviated
form for the following metarule for hybrid-dimension association rules (multidimensional association rules where the
repeated predicate here is sales):
lives(C; ; \V ancouver")
^ sales(C; ?I1; S1 ) ^ . .. ^ sales(C; ?Ik ; Sk ) ^ I = fI1 ; : : :; Ik g ^ S = fS1 ; : : :; Sk g
) sales(C; ?J1 ; T1) ^ .. . ^ sales(C; ?Jm ; Tm ) ^ J = fJ1 ; : : :; Jm g ^ T = fT1; : : :; Tm g
which means that one or more sales records in the form of \sales(C; ?I1; S1 ) ^ . .. sales(C; ?Ik ; Sk )" will reside at
the rule antecedent (left-hand side), and the question mark \?" means that only item name, I1 , . . . , Ik need be
printed out. \I = fI1; : : :; Ik g" means that all the I's at the antecedent are taken from a set I, obtained from the
SQL-like where-clause of line 4. Similar notational conventions are used at the consequent (right-hand side).
The metarule may allow the generation of association rules like the following.
lives(C; ; \V ancouver") ^ sales(C; \Census CD"; )^
sales(C; \MS=Office97"; ) ) sales(C; \MS=SQLServer"; );
[1:5%; 68%]
(6.32)
which means that if a customer in Vancouver bought \Census CD" and \MS/Oce97", it is likely (with a probability
of 68%) that she will buy \MS/SQLServer", and 1.5% of all of the customers bought all three.
Data constraints are specied in the \lives( ; ; \V ancouver")" portion of the metarule (i.e., all the customers
whose city is Vancouver), and in line 3, which species that only the fact table, sales, need be explicitly referenced.
In such a multidimensional database, variable reference is simplied. For example, \S.year = 1998" is equivalent to
the SQL statement \from sales S, transaction R where S.transaction id = R.transaction id and R.year = 1998".
All three dimensions (lives, item, and transaction) are used. Level constraints are as follows: for lives, we consider
just customer name since only city = \Vancouver" is used in the selection; for item, we consider the levels item name
and category since they are used in the query; and for transaction, we are only concerned with transaction id since
day and month are not referenced and year is used only in the selection.
Rule constraints include most portions of the where (line 4) and having (line 6) clauses, such as \S.year =
1998", \T.year = 1998", \I.category = J.category", \sum(I.price) 100" and \min(J.price) 500". Finally, lines
7 and 8 specify two interestingness constraints (i.e., thresholds), namely, a minimum support of 1% and a minimum
condence of 50%.
2
Knowledge type and data constraints are applied before mining. The remaining constraint types could be used
after mining, to lter out discovered rules. This, however, may make the mining process very inecient and expensive.
Dimension/level constraints were discussed in Section 6.3.2, and interestingness constraints have been discussed
throughout this chapter. Let's focus now on rule constraints.
\What kind of constraints can be used during the mining process to prune the rule search space?", you ask.
\More specically, what kind of rule constraints can be \pushed" deep into the mining process and still ensure the
completeness of the answers to a mining query?"
Consider the rule constraint \sum(I.price) 100" of Example 6.7. Suppose we are using an Apriori-like (level-
wise) framework, which for each iteration k, explores itemsets of size k. Any itemset whose price summation is not
less than 100 can be pruned from the search space, since further addition of more items to this itemset will make
it more expensive and thus will never satisfy the constraint. In other words, if an itemset does not satisfy this rule
constraint, then none of its supersets can satisfy the constraint either. If a rule constraint obeys this property, it is
called anti-monotone, or downward closed. Pruning by anti-monotone rule constraints can be applied at each
iteration of Apriori-style algorithms to help improve the eciency of the overall mining process, while guaranteeing
completeness of the data mining query response.
Note that the Apriori property, which states that all non-empty subsets of a frequent itemset must also be
frequent, is also anti-monotone. If a given itemset does not satisfy minimum support, then none of its supersets can
28
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
1-var Constraint
Sv, 2 f=; ; g
v2S
SV
SV
S=V
min(S ) v
min(S ) v
min(S ) = v
max(S ) v
max(S ) v
max(S ) = v
count(S ) v
count(S ) v
count(S ) = v
sum(S ) v
sum(S ) v
sum(S ) = v
avg(S )v, 2 f=; ; g
(frequency constraint)
Anti-Monotone Succinct
yes
yes
no
yes
no
yes
yes
yes
partly
yes
no
yes
yes
yes
partly
yes
yes
yes
no
yes
partly
yes
yes
weakly
no
weakly
partly
weakly
yes
no
no
no
partly
no
no
no
(yes)
(no)
Table 6.3: Characterization of 1-variable constraints: anti-monotonicity and succinctness.
either. This property is used at each iteration of the Apriori algorithm to reduce the number of candidate itemsets
examined, thereby reducing the search space for association rules.
Other examples of anti-monotone constraints include \min(J.price) 500" and \S.year = 1998". Any itemset
which violates either of these constraints can be discarded since adding more items to such itemsets can never satisfy
the constraints. A constraint such as \avg(I.price) 100" is not anti-monotone. For a given set that does not satisfy
this constraint, a superset created by adding some (cheap) items may result in satisfying the constraint. Hence,
pushing this constraint inside the mining process will not guarantee completeness of the data mining query response.
A list of 1-variable constraints, characterized on the notion of anti-monotonicity, is given in the second column of
Table 6.3.
\What other kinds of constraints can we use for pruning the search space?" Apriori-like algorithms deal with other
constraints by rst generating candidate sets and then testing them for constraint satisfaction, thereby following a
generate-and-test paradigm. Instead, is there a kind of constraint for which we can somehow enumerate all and only
those sets that are guaranteed to satisfy the constraint? This property of constraints is called succintness. If a rule
constraint is succinct, then we can directly generate precisely those sets that satisfy it, even before support counting
begins. This avoids the substantial overhead of the generate-and-test paradigm. In other words, such constraints are
pre-counting prunable. Let's study an example of how succinct constraints can be used in mining association rules.
Example 6.8 Based on Table 6.3, the constraint \min(J:price) 500" is succinct. This is because we can explicitly
and precisely generate all the sets of items satisfying the constraint. Specically, such a set must contain at least
one item whose price is less than $500. It is of the form: S [ S , where S =
6 ; is a subset of the set of all those
1
2
1
items with prices less than $500, and S2 , possibly empty, is a subset of the set of all those items with prices > $500.
Because there is a precise \formula" to generate all the sets satisfying a succinct constraint, there is no need to
iteratively check the rule constraint during the mining process.
What about the constraint \min(J:price) 500", which occurs in Example 6.7? This is also succinct, since we
can generate all sets of items satisfying the constraint. In this case, we simply do not include items whose price is
less than $500, since they cannot be in any set that would satisfy the given constraint.
2
Note that a constraint such as \avg(I:price) 100" could not be pushed into the mining process, since it is
neither anti-monotone nor succinct according to Table 6.3.
Although optimizations associated with succinctness (or anti-monotonicity) cannot be applied to constraints like
\avg(I:price) 100", heuristic optimization strategies are applicable and can often lead to signicant pruning.
6.7. SUMMARY
29
6.7 Summary
The discovery of association relationships among huge amounts of data is useful in selective marketing, decision
analysis, and business management. A popular area of application is market basket analysis, which studies
the buying habits of customers by searching for sets of items that are frequently purchased together (or in
sequence). Association rule mining consists of rst nding frequent itemsets (set of items, such as A
and B, satisfying a minimum support threshold, or percentage of the task-relevant tuples), from which strong
association rules in the form of A ) B are generated. These rules also satisfy a minimum condence threshold
(a prespecied probability of satisfying B under the condition that A is satised).
Association rules can be classied into several categories based on dierent criteria, such as:
1. Based on the types of values handled in the rule, associations can be classied into Boolean vs. quantitative.
A Boolean association shows relationships between discrete (categorical) objects. A quantitative association is a multidimensional association that involves numeric attributes which are discretized dynamically.
It may involve categorical attributes as well.
2. Based on the dimensions of data involved in the rules, associations can be classied into single-dimensional
vs. multidimensional.
Single-dimensional association involves a single predicate or dimension, such as buys; whereas multidimensional association involves multiple (distinct) predicates or dimensions. Single-dimensional association shows intra-attribute relationships (i.e., associations within one attribute or dimension);
whereas multidimensional association shows inter-attribute relationships (i.e., between or among attributes/dimensions).
3. Based on the levels of abstractions involved in the rule, associations can be classied into single-level vs.
multilevel.
In a single-level association, the items or predicates mined are not considered at dierent levels of abstraction, whereas a multilevel association does consider multiple levels of abstraction.
The Apriori algorithm is an ecient association rule mining algorithm which explores the level-wise mining
property: all the subsets of a frequent itemset must also be frequent. At the k-th iteration (for k > 1), it forms
frequent (k + 1)-itemset candidates based on the frequent k-itemsets, and scans the database once to nd the
complete set of frequent (k + 1)-itemsets, Lk+1.
Variations involving hashing and data scan reduction can be used to make the procedure more ecient. Other
variations include partitioning the data (mining on each partition and them combining the results), and sampling the data (mining on a subset of the data). These variations can reduce the number of data scans required
to as little as two or one.
Multilevel association rules can be mined using several strategies, based on how minimum support thresholds are dened at each level of abstraction. When using reduced minimum support at lower levels, pruning
approaches include level-cross-ltering by single item and level-cross ltering by k-itemset. Redundant multilevel (descendent) association rules can be eliminated from presentation to the user if their support and
condence are close to their expected values, based on their corresponding ancestor rules.
Techniques for mining multidimensional association rules can be categorized according to their treatment
of quantitative attributes. First, quantitative attributes may be discretized statically, based on predened
concept hierarchies. Data cubes are well-suited to this approach, since both the data cube and quantitative
attributes can make use of concept hierarchies. Second, quantitative association rules can be mined where
quantitative attributes are discretized dynamically based on binning, where \adjacent" association rules may
be combined by clustering. Third, distance-based association rules can be mined to capture the semantics
of interval data, where intervals are dened by clustering.
Not all strong association rules are interesting. Correlation rules can be mined for items that are statistically
correlated.
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
30
Constraint-based mining allow users to focus the search for rules by providing metarules, (i.e., pattern tem-
plates) and additional mining constraints. Such mining is facilitated with the use of a declarative data mining
query language and user interface, and poses great challenges for mining query optimization. In particular, the
rule constraint properties of anti-monotonicity and succinctness can be used during mining to guide the
process, leading to more ecient and eective mining.
Exercises
1. The Apriori algorithm makes use of prior knowledge of subset support properties.
(a) Prove that all non-empty subsets of a frequent itemset must also be frequent.
(b) Prove that the support of any non-empty subset s0 of itemset s must be as great as the support of s.
(c) Given frequent itemset l and subset s of l, prove that the condence of the rule \s0 ) (l , s0 )" cannot be
more than the condence of \s ) (l , s)", where s0 is a subset of s.
2. Section 6.2.2 describes a method for generating association rules from frequent itemsets. Propose a more
ecient method. Explain why it is more ecient than the one proposed in Section 6.2.2. (Hint: Consider
incorporating the properties of Question 1b and 1c into your design).
3. Suppose we have the following transactional data.
(INSERT TRANSACTIONAL DATA HERE).
Assume that the minimum support and minimum condence thresholds are 3% and 60%, respectively.
(a) Find the set of frequent itemsets using the Apriori algorithm. Show the derivation of Ck and Lk for each
iteration, k.
(b) Generate strong association rules from the frequent itemsets found above.
4. In Section 6.2.3, we studied two methods of scan reduction. Can you think of another approach, which trims
transactions by removing items that do not contribute to frequent itemsets? Show the details of this approach
in pseudo-code and with an example.
5. Suppose that a large store has a transaction database that is distributed among four locations. Transactions in
each component database have the same format, namely Tj : fi1 ; : : :; im g, where Tj is a transaction identier,
and ik (1 k m) is the identier of an item purchased in the transaction. Propose an ecient algorithm to
mine global association rules (without considering multilevel associations). You may present your algorithm in
the form of an outline. Your algorithm should not require shipping all of the data to one site and should not
cause excessive network communication overhead.
6. Suppose that a data relation describing students at Big-University has been generalized to the following generalized relation R.
6.7. SUMMARY
31
major
French
cs
physics
engineering
philosophy
French
chemistry
cs
philosophy
French
philosophy
philosophy
French
math
cs
philosophy
philosophy
French
engineering
math
chemistry
engineering
French
philosophy
math
status
M.A
junior
M.S
Ph.D
Ph.D
senior
junior
senior
M.S
junior
junior
M.S
junior
senior
junior
Ph.D
senior
Ph.D
junior
Ph.D
junior
junior
M.S
junior
junior
age
nationality
gpa count
30
Canada
2.8 3.2
3
15 20
Europe
3.2 3.6 29
25 30 Latin America 3.2 3.6 18
25 30
Asia
3.6 4.0 78
25 30
Europe
3.2 3.6
5
15 20
Canada
3.2 3.6 40
20 25
USA
3.6 4.0 25
15 20
Canada
3.2 3.6 70
30
Canada
3.6 4.0 15
15 20
USA
2.8 3.2
8
25 30
Canada
2.8 3.2
9
25 30
Asia
3.2 3.6
9
15 20
Canada
3.2 3.6 52
15 20
USA
3.6 4.0 32
15 20
Canada
3.2 3.6 76
25 30
Canada
3.6 4.0 14
25 30
Canada
2.8 3.2 19
30
Canada
2.8 3.2
1
20 25
Europe
3.2 3.6 71
25 30 Latin America 3.2 3.6
7
15 20
USA
3.6 4.0 46
20 25
Canada
3.2 3.6 96
30
Latin America 3.2 3.6
4
20 25
USA
2.8 3.2
8
15 20
Canada
3.6 4.0 59
Let the concept hierarchies be as follows.
status :
major :
age :
nationality :
ffreshman; sophomore; junior; seniorg 2 undergraduate.
fM:Sc:; M:A:;Ph:D:g 2 graduate.
fphysics; chemistry; mathg 2 science.
fcs; engineeringg 2 appl: sciences.
fFrench; philosophyg 2 arts.
f15 20; 21 25g 2 young.
f26 30; 30 g 2 old.
fAsia; Europe; U:S:A:;Latin Americag 2 foreign.
Let the minimum support threshold be 2% and the minimum condence threshold be 50% (at each of the
levels).
(a) Draw the concept hierarchies for status, major, age, and nationality.
(b) Find the set of strong multilevel association rules in R using uniform support for all levels.
(c) Find the set of strong multilevel association rules in R using level-cross ltering by single items, where a
reduced support of 1% is used for the lowest abstraction level.
7. Show that the support of an itemset H that contains both an item h and its ancestor ^h will be the same as the
support for the itemset H , ^h. Explain how this can be used in cross-level association rule mining.
8. Propose and outline a level-shared mining approach to mining multilevel association rules in which each
item is encoded by its level position, and an initial scan of the database collects the count for each item at each
concept level, identifying frequent and subfrequent items. Comment on the processing cost of mining multilevel
associations with this method in comparison to mining single-level associations.
9. When mining cross-level association rules, suppose it is found that the itemset \fIBM home computer, printerg"
does not satisfy minimum support. Can this information be used to prune the mining of a \descendent" itemset
such as \fIBM home computer, b/w printerg"? Give a general rule explaining how this information may be
used for pruning the search space.
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
32
10. Propose a method for mining hybrid-dimension association rules (multidimensional association rules with repeating predicates).
11. (INSERT QUESTIONS FOR mining quantitative association rules and distance-based association rules).
12. The following contingency table summarizes supermarket transaction data, where hot dogs refer to the transactions containing hot dogs, hotdogs refer to the transactions which do not contain hot dogs, hamburgers refer
to the transactions containing hamburgers, and hamburgers refer to the transactions which do not contain
hamburgers.
hamburgers
hamburgers
col
hot dogs hotdogs row
2,000
500 2,500
1,000
1,500 2,500
3,000
2,000 5,000
(a) Suppose that the association rule \hot dogs ) hamburgers" is mined. Given a minimumsupport threshold
of 25% and a minimum condence threshold of 50%, is this association rule strong?
(b) Based on the given data, is the purchase of hot dogs independent of the purchase of hamburgers? If not,
what kind of correlation relationship exists between the two?
13. Sequential patterns can be mined in methods similar to the mining of association rules. Design an ecient
algorithm to mine multilevel sequential patterns from a transaction database. An example of such a pattern
is the following: \a customer who buys a PC will buy Microsoft software within three months", on which one
may drill-down to nd a more rened version of the pattern, such as \a customer who buys a Pentium Pro will
buy Microsoft Oce'97 within three months".
14. Prove the characterization of the following 1-variable rule constraints with respect to anti-monotonicity and
succinctness.
a)
b)
c)
d)
1-var Constraint Anti-Monotone Succinct
v2S
no
yes
min(S) v
no
yes
min(S) v
yes
yes
max(S) v
yes
yes
Bibliographic Notes
Association rule mining was rst proposed by Agrawal, Imielinski, and Swami [1]. The Apriori algorithm discussed
in Section 6.2.1 was presented by Agrawal and Srikant [4], and a similar level-wise association mining algorithm was
developed by Klemettinen et al. [20]. A method for generating association rules is described in Agrawal and Srikant
[3]. References for the variations of Apriori described in Section 6.2.3 include the following. The use of hash tables
to improve association mining eciency was studied by Park, Chen, and Yu [29]. Scan and transaction reduction
techniques are described in Agrawal and Srikant [4], Han and Fu [16], and Park, Chen and Yu [29]. The partitioning
technique was proposed by Savasere, Omiecinski and Navathe [33]. The sampling approach is discussed in Toivonen
[41]. A dynamic itemset counting approach is given in Brin et al. [9]. Calendric market basket analysis is discussed
in Ramaswamy, Mahajan, and Silberschatz [32]. Mining of sequential patterns is described in Agrawal and Srikant
[5], and Mannila, Toivonen, and Verkamo [24].
Multilevel association mining was studied in Han and Fu [16], and Srikant and Agrawal [38]. In Srikant and
Agrawal [38], such mining is studied in the context of generalized association rules, and an R-interest measure is
proposed for removing redundant rules.
Mining multidimensional association rules using static discretization of quantitative attributes and data cubes
was studied by Kamber, Han, and Chiang [19]. Zhao, Deshpande, and Naughton [44] found that even when a cube is
constructed on the y, mining from data cubes can be faster than mining directly from a relational table. The ARCS
system described in Section 6.4.3 for mining quantitative association rules based on rule clustering was proposed by
Lent, Swami, and Widom [22]. Techniques for mining quantitative rules based on x-monotone and rectilinear regions
6.7. SUMMARY
33
were presented by Fukuda et al. [15], and Yoda et al. [42]. A non-grid-based technique for mining quantitative
association rules, which uses a measure of partial completeness, was proposed by Srikant and Agrawal [39]. The
approach described in Section 6.4.4 for mining (distance-based) association rules over interval data was proposed by
Miller and Yang [26].
The statistical independence of rules in data mining was studied by Piatetski-Shapiro [31]. The interestingness
problem of strong association rules is discussed by Chen, Han, and Yu [10], and Brin, Motwani, and Silverstein [8].
An ecient method for generalizing associations to correlations is given in Brin, Motwani, and Silverstein [8], and
briey summarized in Section 6.5.2.
The use of metarules as syntactic or semantic lters dening the form of interesting single-dimensional association
rules was proposed in Klemettinen et al. [20]. Metarule-guided mining, where the metarule consequent species an
action (such as Bayesian clustering or plotting) to be applied to the data satisfying the metarule antecedent, was
proposed in Shen et al. [35]. A relation-based approach to metarule-guided mining of association rules is studied in
Fu and Han [14]. A data cube-based approach is studied in Kamber et al. [19]. The constraint-based association
rule mining of Section 6.6.2 was studied in Ng et al. [27] and Lakshmanan et al. [21]. Other ideas involving the use
of templates or predicate constraints in mining have been discussed in [6, 13, 18, 23, 36, 40].
An SQL-like operator for mining single-dimensional association rules was proposed by Meo, Psaila, and Ceri [25],
and further extended in Baralis and Psaila [7]. The data mining query language, DMQL, was proposed in Han et
al. [17].
An ecient incremental updating of mined association rules was proposed by Cheung et al. [12]. Parallel and
distributed association data mining under the Apriori framework was studied by Park, Chen, and Yu [30], Agrawal
and Shafer [2], and Cheung et al. [11]. Additional work in the mining of association rules includes mining sequential
association patterns by Agrawal and Srikant [5], mining negative association rules by Savasere, Omiecinski and
Navathe [34], and mining cyclic association rules by Ozden, Ramaswamy, and Silberschatz [28].
34
CHAPTER 6. MINING ASSOCIATION RULES IN LARGE DATABASES
Bibliography
[1] R. Agrawal, T. Imielinski, and A. Swami. Mining association rules between sets of items in large databases. In
Proc. 1993 ACM-SIGMOD Int. Conf. Management of Data, pages 207{216, Washington, D.C., May 1993.
[2] R. Agrawal and J. C. Shafer. Parallel mining of association rules: Design, implementation, and experience.
IEEE Trans. Knowledge and Data Engineering, 8:962{969, 1996.
[3] R. Agrawal and R. Srikant. Fast algorithm for mining association rules in large databases. In Research Report
RJ 9839, IBM Almaden Research Center, San Jose, CA, June 1994.
[4] R. Agrawal and R. Srikant. Fast algorithms for mining association rules. In Proc. 1994 Int. Conf. Very Large
Data Bases, pages 487{499, Santiago, Chile, September 1994.
[5] R. Agrawal and R. Srikant. Mining sequential patterns. In Proc. 1995 Int. Conf. Data Engineering, pages 3{14,
Taipei, Taiwan, March 1995.
[6] T. Anand and G. Kahn. Opportunity explorer: Navigating large databases using knowledge discovery templates.
In Proc. AAAI-93 Workshop Knowledge Discovery in Databases, pages 45{51, Washington DC, July 1993.
[7] E. Baralis and G. Psaila. Designing templates for mining association rules. Journal of Intelligent Information
Systems, 9:7{32, 1997.
[8] S. Brin, R. Motwani, and C. Silverstein. Beyond market basket: Generalizing association rules to correlations.
In Proc. 1997 ACM-SIGMOD Int. Conf. Management of Data, pages 265{276, Tucson, Arizona, May 1997.
[9] S. Brin, R. Motwani, J. D. Ullman, and S. Tsur. Dynamic itemset counting and implication rules for market
basket analysis. In Proc. 1997 ACM-SIGMOD Int. Conf. Management of Data, pages 255{264, Tucson, Arizona,
May 1997.
[10] M. S. Chen, J. Han, and P. S. Yu. Data mining: An overview from a database perspective. IEEE Trans.
Knowledge and Data Engineering, 8:866{883, 1996.
[11] D.W. Cheung, J. Han, V. Ng, A. Fu, and Y. Fu. A fast distributed algorithm for mining association rules. In
Proc. 1996 Int. Conf. Parallel and Distributed Information Systems, pages 31{44, Miami Beach, Florida, Dec.
1996.
[12] D.W. Cheung, J. Han, V. Ng, and C.Y. Wong. Maintenance of discovered association rules in large databases:
An incremental updating technique. In Proc. 1996 Int. Conf. Data Engineering, pages 106{114, New Orleans,
Louisiana, Feb. 1996.
[13] V. Dhar and A. Tuzhilin. Abstract-driven pattern discovery in databases. IEEE Trans. Knowledge and Data
Engineering, 5:926{938, 1993.
[14] Y. Fu and J. Han. Meta-rule-guided mining of association rules in relational databases. In Proc. 1st Int.
Workshop Integration of Knowledge Discovery with Deductive and Object-Oriented Databases (KDOOD'95),
pages 39{46, Singapore, Dec. 1995.
[15] T. Fukuda, Y. Morimoto, S. Morishita, and T. Tokuyama. Data mining using two-dimensional optimized
association rules: Scheme, algorithms, and visualization. In Proc. 1996 ACM-SIGMOD Int. Conf. Management
of Data, pages 13{23, Montreal, Canada, June 1996.
35
36
BIBLIOGRAPHY
[16] J. Han and Y. Fu. Discovery of multiple-level association rules from large databases. In Proc. 1995 Int. Conf.
Very Large Data Bases, pages 420{431, Zurich, Switzerland, Sept. 1995.
[17] J. Han, Y. Fu, W. Wang, K. Koperski, and O. R. Zaane. DMQL: A data mining query language for relational
databases. In Proc. 1996 SIGMOD'96 Workshop Research Issues on Data Mining and Knowledge Discovery
(DMKD'96), pages 27{34, Montreal, Canada, June 1996.
[18] P. Hoschka and W. Klosgen. A support system for interpreting statistical data. In G. Piatetsky-Shapiro and
W. J. Frawley, editors, Knowledge Discovery in Databases, pages 325{346. AAAI/MIT Press, 1991.
[19] M. Kamber, J. Han, and J. Y. Chiang. Metarule-guided mining of multi-dimensional association rules using
data cubes. In Proc. 3rd Int. Conf. Knowledge Discovery and Data Mining (KDD'97), pages 207{210, Newport
Beach, California, August 1997.
[20] M. Klemettinen, H. Mannila, P. Ronkainen, H. Toivonen, and A.I. Verkamo. Finding interesting rules from large
sets of discovered association rules. In Proc. 3rd Int. Conf. Information and Knowledge Management, pages
401{408, Gaithersburg, Maryland, Nov. 1994.
[21] L. V. S. Lakshmanan, R. Ng, J. Han, and A. Pang. Optimization of constrained frequent set queries with 2variable constraints. In Proc. 1999 ACM-SIGMOD Int. Conf. Management of Data, pages 157{168, Philadelphia,
PA, June 1999.
[22] B. Lent, A. Swami, and J. Widom. Clustering association rules. In Proc. 1997 Int. Conf. Data Engineering
(ICDE'97), pages 220{231, Birmingham, England, April 1997.
[23] B. Liu, W. Hsu, and S. Chen. Using general impressions to analyze discovered classication rules. In Proc. 3rd
Int.. Conf. on Knowledge Discovery and Data Mining (KDD'97), pages 31{36, Newport Beach, CA, August
1997.
[24] H. Mannila, H Toivonen, and A. I. Verkamo. Discovering frequent episodes in sequences. In Proc. 1st Int. Conf.
Knowledge Discovery and Data Mining, pages 210{215, Montreal, Canada, Aug. 1995.
[25] R. Meo, G. Psaila, and S. Ceri. A new SQL-like operator for mining association rules. In Proc. 1996 Int. Conf.
Very Large Data Bases, pages 122{133, Bombay, India, Sept. 1996.
[26] R.J. Miller and Y. Yang. Association rules over interval data. In Proc. 1997 ACM-SIGMOD Int. Conf. Management of Data, pages 452{461, Tucson, Arizona, May 1997.
[27] R. Ng, L. V. S. Lakshmanan, J. Han, and A. Pang. Exploratory mining and pruning optimizations of constrained associations rules. In Proc. 1998 ACM-SIGMOD Int. Conf. Management of Data, pages 13{24, Seattle,
Washington, June 1998.
[28] B. O zden, S. Ramaswamy, and A. Silberschatz. Cyclic association rules. In Proc. 1998 Int. Conf. Data Engineering (ICDE'98), pages 412{421, Orlando, FL, Feb. 1998.
[29] J.S. Park, M.S. Chen, and P.S. Yu. An eective hash-based algorithm for mining association rules. In Proc.
1995 ACM-SIGMOD Int. Conf. Management of Data, pages 175{186, San Jose, CA, May 1995.
[30] J.S. Park, M.S. Chen, and P.S. Yu. Ecient parallel mining for association rules. In Proc. 4th Int. Conf.
Information and Knowledge Management, pages 31{36, Baltimore, Maryland, Nov. 1995.
[31] G. Piatetsky-Shapiro. Discovery, analysis, and presentation of strong rules. In G. Piatetsky-Shapiro and W. J.
Frawley, editors, Knowledge Discovery in Databases, pages 229{238. AAAI/MIT Press, 1991.
[32] S. Ramaswamy, S. Mahajan, and A. Silberschatz. On the discovery of interesting patterns in association rules.
In Proc. 1998 Int. Conf. Very Large Data Bases, pages 368{379, New York, NY, August 1998.
[33] A. Savasere, E. Omiecinski, and S. Navathe. An ecient algorithm for mining association rules in large databases.
In Proc. 1995 Int. Conf. Very Large Data Bases, pages 432{443, Zurich, Switzerland, Sept. 1995.
BIBLIOGRAPHY
37
[34] A. Savasere, E. Omiecinski, and S. Navathe. Mining for strong negative associations in a large database of
customer transactions. In Proc. 1998 Int. Conf. Data Engineering (ICDE'98), pages 494{502, Orlando, FL,
Feb. 1998.
[35] W. Shen, K. Ong, B. Mitbander, and C. Zaniolo. Metaqueries for data mining. In U.M. Fayyad, G. PiatetskyShapiro, P. Smyth, and R. Uthurusamy, editors, Advances in Knowledge Discovery and Data Mining, pages
375{398. AAAI/MIT Press, 1996.
[36] A. Silberschatz and A. Tuzhilin. What makes patterns interesting in knowledge discovery systems. IEEE
Trans. on Knowledge and Data Engineering, 8:970{974, Dec. 1996.
[37] E. Simoudis, J. Han, and U. Fayyad (eds.). Proc. 2nd Int. Conf. Knowledge Discovery and Data Mining
(KDD'96). AAAI Press, August 1996.
[38] R. Srikant and R. Agrawal. Mining generalized association rules. In Proc. 1995 Int. Conf. Very Large Data
Bases, pages 407{419, Zurich, Switzerland, Sept. 1995.
[39] R. Srikant and R. Agrawal. Mining quantitative association rules in large relational tables. In Proc. 1996
ACM-SIGMOD Int. Conf. Management of Data, pages 1{12, Montreal, Canada, June 1996.
[40] R. Srikant, Q. Vu, and R. Agrawal. Mining association rules with item constraints. In Proc. 3rd Int. Conf.
Knowledge Discovery and Data Mining (KDD'97), pages 67{73, Newport Beach, California, August 1997.
[41] H. Toivonen. Sampling large databases for association rules. In Proc. 1996 Int. Conf. Very Large Data Bases,
pages 134{145, Bombay, India, Sept. 1996.
[42] K. Yoda, T. Fukuda, Y. Morimoto, S. Morishita, and T. Tokuyama. Computing optimized rectilinear regions
for association rules. In Proc. 3rd Int. Conf. Knowledge Discovery and Data Mining (KDD'97), pages 96{103,
Newport Beach, California, August 1997.
[43] T. Zhang, R. Ramakrishnan, and M. Livny. BIRCH: an ecient data clustering method for very large databases.
In Proc. 1996 ACM-SIGMOD Int. Conf. Management of Data, pages 103{114, Montreal, Canada, June 1996.
[44] Y. Zhao, P. M. Deshpande, and J. F. Naughton. An array-based algorithm for simultaneous multidimensional
aggregates. In Proc. 1997 ACM-SIGMOD Int. Conf. Management of Data, pages 159{170, Tucson, Arizona,
May 1997.
Contents
7 Classication and Prediction
7.1 What is classication? What is prediction? . . . . . . . . . . . . . . . . . .
7.2 Issues regarding classication and prediction . . . . . . . . . . . . . . . . . .
7.3 Classication by decision tree induction . . . . . . . . . . . . . . . . . . . .
7.3.1 Decision tree induction . . . . . . . . . . . . . . . . . . . . . . . . . .
7.3.2 Tree pruning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.3.3 Extracting classication rules from decision trees . . . . . . . . . . .
7.3.4 Enhancements to basic decision tree induction . . . . . . . . . . . .
7.3.5 Scalability and decision tree induction . . . . . . . . . . . . . . . . .
7.3.6 Integrating data warehousing techniques and decision tree induction
7.4 Bayesian classication . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.4.1 Bayes theorem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.4.2 Naive Bayesian classication . . . . . . . . . . . . . . . . . . . . . .
7.4.3 Bayesian belief networks . . . . . . . . . . . . . . . . . . . . . . . . .
7.4.4 Training Bayesian belief networks . . . . . . . . . . . . . . . . . . . .
7.5 Classication by backpropagation . . . . . . . . . . . . . . . . . . . . . . . .
7.5.1 A multilayer feed-forward neural network . . . . . . . . . . . . . . .
7.5.2 Dening a network topology . . . . . . . . . . . . . . . . . . . . . . .
7.5.3 Backpropagation . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.5.4 Backpropagation and interpretability . . . . . . . . . . . . . . . . . .
7.6 Association-based classication . . . . . . . . . . . . . . . . . . . . . . . . .
7.7 Other classication methods . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.7.1 k-nearest neighbor classiers . . . . . . . . . . . . . . . . . . . . . .
7.7.2 Case-based reasoning . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.7.3 Genetic algorithms . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.7.4 Rough set theory . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.7.5 Fuzzy set approaches . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.8 Prediction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.8.1 Linear and multiple regression . . . . . . . . . . . . . . . . . . . . .
7.8.2 Nonlinear regression . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.8.3 Other regression models . . . . . . . . . . . . . . . . . . . . . . . . .
7.9 Classier accuracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7.9.1 Estimating classier accuracy . . . . . . . . . . . . . . . . . . . . . .
7.9.2 Increasing classier accuracy . . . . . . . . . . . . . . . . . . . . . .
7.9.3 Is accuracy enough to judge a classier? . . . . . . . . . . . . . . . .
7.10 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
3
3
5
6
7
9
10
11
12
13
15
15
16
17
19
19
20
21
21
24
25
27
27
28
28
28
29
30
30
32
32
33
33
34
34
35
2
CONTENTS
c J. Han and M. Kamber, 1998, DRAFT!! DO NOT COPY!! DO NOT DISTRIBUTE!!
September 15, 1999
Chapter 7
Classication and Prediction
Databases are rich with hidden information that can be used for making intelligent business decisions. Classication and prediction are two forms of data analysis which can be used to extract models describing important
data classes or to predict future data trends. Whereas classication predicts categorical labels (or discrete values),
prediction models continuous-valued functions. For example, a classication model may be built to categorize bank
loan applications as either safe or risky, while a prediction model may be built to predict the expenditures of potential customers on computer equipment given their income and occupation. Many classication and prediction
methods have been proposed by researchers in machine learning, expert systems, statistics, and neurobiology. Most
algorithms are memory resident, typically assuming a small data size. Recent database mining research has built on
such work, developing scalable classication and prediction techniques capable of handling large, disk resident data.
These techniques often consider parallel and distributed processing.
In this chapter, you will learn basic techniques for data classication such as decision tree induction, Bayesian
classication and Bayesian belief networks, and neural networks. The integration of data warehousing technology
with classication is also discussed, as well as association-based classication. Other approaches to classication, such
as k-nearest neighbor classiers, case-based reasoning, genetic algorithms, rough sets, and fuzzy logic techniques are
introduced. Methods for prediction, including linear, nonlinear, and generalized linear regression models are briey
discussed. Where applicable, you will learn of modications, extensions and optimizations to these techniques for
their application to data classication and prediction for large databases.
7.1 What is classication? What is prediction?
Data classication is a two step process (Figure 7.1). In the rst step, a model is built describing a predetermined
set of data classes or concepts. The model is constructed by analyzing database tuples described by attributes. Each
tuple is assumed to belong to a predened class, as determined by one of the attributes, called the class label
attribute. In the context of classication, data tuples are also referred to as samples, examples, or objects. The
data tuples analyzed to build the model collectively form the training data set. The individual tuples making
up the training set are referred to as training samples and are randomly selected from the sample population.
Since the class label of each training sample is provided, this step is also known as supervised learning (i.e., the
learning of the model is `supervised' in that it is told to which class each training sample belongs). It contrasts with
unsupervised learning (or clustering), in which the class labels of the training samples are not known, and the
number or set of classes to be learned may not be known in advance. Clustering is the topic of Chapter 8.
Typically, the learned model is represented in the form of classication rules, decision trees, or mathematical
formulae. For example, given a database of customer credit information, classication rules can be learned to
identify customers as having either excellent or fair credit ratings (Figure 7.1a). The rules can be used to categorize
future data samples, as well as provide a better understanding of the database contents.
In the second step (Figure 7.1b), the model is used for classication. First, the predictive accuracy of the model
(or classier) is estimated. Section 7.9 of this chapter describes several methods for estimating classier accuracy.
The holdout method is a simple technique which uses a test set of class-labeled samples. These samples are
3
CHAPTER 7. CLASSIFICATION AND PREDICTION
4
a)
Classification
Algorithm
Training
Data
Classification
Rules
name
age
income
credit rating
Sandy Jones
< 30
low
fair
AND income=high
Bill Lee
< 30
low
excellent
THEN
Courtney Fox
30 - 40
high
excellent
Susan Lake
> 40
med
fair
Claire Phips
> 40
med
fair
Andre Beau
30 - 40
high
excellent
credit_rating=excellent
...
...
...
IF age 30-40
b)
Classification
Rules
Test
New
Data
Data
name
age
income
credit rating
Frank Jones
> 40
high
fair
Sylvia Crest
< 30
low
fair
Anne Yee
...
30 - 40
...
high
...
excellent
...
(John Henri, 30-40, high)
Credit rating?
excellent
Figure 7.1: The data classication process: a) Learning: Training data are analyzed by a classication algorithm.
Here, the class label attribute is credit rating, and the learned model or classier is represented in the form of
classication rules. b) Classication: Test data are used to estimate the accuracy of the classication rules. If the
accuracy is considered acceptable, the rules can be applied to the classication of new data tuples.
randomly selected and are independent of the training samples. The accuracy of a model on a given test set is the
percentage of test set samples that are correctly classied by the model. For each test sample, the known class label
is compared with the learned model's class prediction for that sample. Note that if the accuracy of the model were
estimated based on the training data set, this estimate could be optimistic since the learned model tends to overt
the data (that is, it may have incorporated some particular anomalies of the training data which are not present in
the overall sample population). Therefore, a test set is used.
If the accuracy of the model is considered acceptable, the model can be used to classify future data tuples or
objects for which the class label is not known. (Such data are also referred to in the machine learning literature
as \unknown" or \previously unseen" data). For example, the classication rules learned in Figure 7.1a from the
analysis of data from existing customers can be used to predict the credit rating of new or future (i.e., previously
unseen) customers.
\How is prediction dierent from classication?" Prediction can be viewed as the construction and use of a
model to assess the class of an unlabeled object, or to assess the value or value ranges of an attribute that a given
object is likely to have. In this view, classication and regression are the two major types of prediction problems
where classication is used to predict discrete or nominal values, while regression is used to predict continuous or
7.2. ISSUES REGARDING CLASSIFICATION AND PREDICTION
5
ordered values. In our view, however, we refer to the use of predication to predict class labels as classication and
the use of predication to predict continuous values (e.g., using regression techniques) as prediction. This view is
commonly accepted in data mining.
Classication and prediction have numerous applications including credit approval, medical diagnosis, performance prediction, and selective marketing.
Example 7.1 Suppose that we have a database of customers on the AllElectronics mailing list. The mailing list
is used to send out promotional literature describing new products and upcoming price discounts. The database
describes attributes of the customers, such as their name, age, income, occupation, and credit rating. The customers
can be classied as to whether or not they have purchased a computer at AllElectronics. Suppose that new customers
are added to the database and that you would like to notify these customers of an uncoming computer sale. To send
out promotional literature to every new customer in the database can be quite costly. A more cost ecient method
would be to only target those new customers who are likely to purchase a new computer. A classication model can
be constructed and used for this purpose.
Suppose instead that you would like to predict the number of major purchases that a customer will make at
AllElectronics during a scal year. Since the predicted value here is ordered, a prediction model can be constructed
for this purpose.
2
7.2 Issues regarding classication and prediction
Preparing the data for classication and prediction. The following preprocessing steps may be applied to the
data in order to help improve the accuracy, eciency, and scalability of the classication or prediction process.
Data cleaning. This refers to the preprocessing of data in order to remove or reduce noise (by applying
smoothing techniques, for example), and the treatment of missing values (e.g., by replacing a missing value
with the most commonly occurring value for that attribute, or with the most probable value based on statistics).
Although most classication algorithms have some mechanisms for handling noisy or missing data, this step
can help reduce confusion during learning.
Relevance analysis. Many of the attributes in the data may be irrelevant to the classication or prediction
task. For example, data recording the day of the week on which a bank loan application was led is unlikely to
be relevant to the success of the application. Furthermore, other attributes may be redundant. Hence, relevance
analysis may be performed on the data with the aim of removing any irrelevant or redundant attributes from
the learning process. In machine learning, this step is known as feature selection. Including such attributes
may otherwise slow down, and possibly mislead, the learning step.
Ideally, the time spent on relevance analysis, when added to the time spent on learning from the resulting
\reduced" feature subset, should be less than the time that would have been spent on learning from the
original set of features. Hence, such analysis can help improve classication eciency and scalability.
Data transformation. The data can be generalized to higher-level concepts. Concept hierarchies may be
used for this purpose. This is particularly useful for continuous-valued attributes. For example, numeric values
for the attribute income may be generalized to discrete ranges such as low, medium, and high. Similarly,
nominal-valued attributes, like street, can be generalized to higher-level concepts, like city. Since generalization
compresses the original training data, fewer input/output operations may be involved during learning.
The data may also be normalized, particularly when neural networks or methods involving distance measurements are used in the learning step. Normalization involves scaling all values for a given attribute so that
they fall within a small specied range, such as -1.0 to 1.0, or 0 to 1.0. In methods which use distance measurements, for example, this would prevent attributes with initially large ranges (like, say income) from outweighing
attributes with initially smaller ranges (such as binary attributes).
Data cleaning, relevance analysis, and data transformation are described in greater detail in Chapter 3 of this
book.
Comparing classication methods. Classication and prediction methods can be compared and evaluated according to the following criteria:
CHAPTER 7. CLASSIFICATION AND PREDICTION
6
age?
<30
no
>40
yes
student?
no
30-40
yes
yes
credit_rating?
excellent
yes
fair
no
Figure 7.2: A decision tree for the concept buys computer, indicating whether or not a customer at AllElectronics
is likely to purchase a computer. Each internal (non-leaf) node represents a test on an attribute. Each leaf node
represents a class (either buys computer = yes or buys computer = no).
1. Predictive accuracy. This refers to the ability of the model to correctly predict the class label of new or
previously unseen data.
2. Speed. This refers to the computation costs involved in generating and using the model.
3. Robustness. This is the ability of the model to make correct predictions given noisy data or data with missing
values.
4. Scalability. This refers to the ability of the learned model to perform eciently on large amounts of data.
5. Interpretability. This refers is the level of understanding and insight that is provided by the learned model.
These issues are discussed throughout the chapter. The database research community's contributions to classication and prediction for data mining have strongly emphasized the scalability aspect, particularly with respect to
decision tree induction.
7.3 Classication by decision tree induction
\What is a decision tree?"
A decision tree is a ow-chart-like tree structure, where each internal node denotes a test on an attribute, each
branch represents an outcome of the test, and leaf nodes represent classes or class distributions. The topmost node
in a tree is the root node. A typical decision tree is shown in Figure 7.2. It represents the concept buys computer,
that is, it predicts whether or not a customer at AllElectronics is likely to purchase a computer. Internal nodes are
denoted by rectangles, and leaf nodes are denoted by ovals.
In order to classify an unknown sample, the attribute values of the sample are tested against the decision tree.
A path is traced from the root to a leaf node which holds the class prediction for that sample. Decision trees can
easily be converted to classication rules.
In Section 7.3.1, we describe a basic algorithm for learning decision trees. When decision trees are built, many
of the branches may reect noise or outliers in the training data. Tree pruning attempts to identify and remove
such branches, with the goal of improving classication accuracy on unseen data. Tree pruning is described in
Section 7.3.2. The extraction of classication rules from decision trees is discussed in Section 7.3.3. Enhancements of
the basic decision tree algorithm are given in Section 7.3.4. Scalability issues for the induction of decision trees from
large databases are discussed in Section 7.3.5. Section 7.3.6 describes the integration of decision tree induction with
data warehousing facilities, such as data cubes, allowing the mining of decision trees at multiple levels of granularity.
Decision trees have been used in many application areas ranging from medicine to game theory and business. Decision
trees are the basis of several commercial rule induction systems.
7.3. CLASSIFICATION BY DECISION TREE INDUCTION
7
Algorithm 7.3.1 (Generate decision tree) Generate a decision tree from the given training data.
Input: The training samples, samples, represented by discrete-valued attributes; the set of candidate attributes, attribute-list.
Output: A decision tree.
Method:
1) create a node N ;
2) if samples are all of the same class, C then
3) return N as a leaf node labeled with the class C ;
4) if attribute-list is empty then
5) return N as a leaf node labeled with the most common class in samples; // majority voting
6) select test-attribute, the attribute among attribute-list with the highest information gain;
7) label node N with test-attribute;
8) for each known value ai of test-attribute // partition the samples
9) grow a branch from node N for the condition test-attribute=ai;
10) let si be the set of samples in samples for which test-attribute=ai; // a partition
11) if si is empty then
12)
attach a leaf labeled with the most common class in samples;
13) else attach the node returned by Generate decision tree(si , attribute-list - test-attribute);
2
Figure 7.3: Basic algorithm for inducing a decision tree from training samples.
7.3.1 Decision tree induction
The basic algorithm for decision tree induction is a greedy algorithm which constructs decision trees in a top-down
recursive divide-and-conquer manner. The algorithm, summarized in Figure 7.3, is a version of ID3, a well-known
decision tree induction algorithm. Extensions to the algorithm are discussed in Sections 7.3.2 to 7.3.6.
The basic strategy is as follows:
The tree starts as a single node representing the training samples (step 1).
If the samples are all of the same class, then the node becomes a leaf and is labeled with that class (steps 2
and 3).
Otherwise, the algorithm uses an entropy-based measure known as information gain as a heuristic for selecting
the attribute that will best separate the samples into individual classes (step 6). This attribute becomes the
\test" or \decision" attribute at the node (step 7). In this version of the algorithm, all attributes are categorical,
i.e., discrete-valued. Continuous-valued attributes must be discretized.
A branch is created for each known value of the test attribute, and the samples are partitioned accordingly
(steps 8-10).
The algorithm uses the same process recursively to form a decision tree for the samples at each partition. Once
an attribute has occurred at a node, it need not be considered in any of the node's descendents (step 13).
The recursive partitioning stops only when any one of the following conditions is true:
1. All samples for a given node belong to the same class (step 2 and 3), or
2. There are no remaining attributes on which the samples may be further partitioned (step 4). In this case,
majority voting is employed (step 5). This involves converting the given node into a leaf and labeling it
with the class in majority among samples. Alternatively, the class distribution of the node samples may
be stored; or
3. There are no samples for the branch test-attribute=ai (step 11). In this case, a leaf is created with the
majority class in samples (step 12).
CHAPTER 7. CLASSIFICATION AND PREDICTION
8
Attribute selection measure. The information gain measure is used to select the test attribute at each node
in the tree. Such a measure is referred to as an attribute selection measure or a measure of the goodness of split. The
attribute with the highest information gain (or greatest entropy reduction) is chosen as the test attribute for the
current node. This attribute minimizes the information needed to classify the samples in the resulting partitions and
reects the least randomness or \impurity" in these partitions. Such an information-theoretic approach minimizes
the expected number of tests needed to classify an object and guarantees that a simple (but not necessarily the
simplest) tree is found.
Let S be a set consisting of s data samples. Suppose the class label attribute has m distinct values dening m
distinct classes, Ci (for i = 1; : : :; m). Let si be the number of samples of S in class Ci. The expected information
needed to classify a given sample is given by:
I(s1 ; s2; : : :; sm ) =
m
X
, p log (p )
i=1
i
2
(7.1)
i
where pi is the probability than an arbitrary sample belongs to class Ci and is estimated by si /s. Note that a log
function to the base 2 is used since the information is encoded in bits.
Let attribute A have v distinct values, fa1 ; a2; ; av g. Attribute A can be used to partition S into v subsets,
fS1 ; S2 ; ; Sv g, where Sj contains those samples in S that have value aj of A. If A were selected as the test
attribute (i.e., best attribute for splitting), then these subsets would correspond to the branches grown from the
node containing the set S. Let sij be the number of samples of class Ci in a subset Sj . The entropy, or expected
information based on the partitioning into subsets by A is given by:
E(A) =
P
Xv s j + + smj I(s
1
j =1
s
1
j ; : : :; smj ):
(7.2)
The term vj=1 s j +s+smj acts as the weight of the j th subset and is the number of samples in the subset (i.e.,
having value aj of A) divided by the total number of samples in S. The smaller the entropy value is, the greater the
purity of the subset partitions. The encoding information that would be gained by branching on A is
1
Gain(A) = I(s1 ; s2 ; : : :; sm ) , E(A):
(7.3)
In other words, Gain(A) is the expected reduction in entropy caused by knowing the value of attribute A.
The algorithm computes the information gain of each attribute. The attribute with the highest information gain
is chosen as the test attribute for the given set S. A node is created and labeled with the attribute, branches are
created for each value of the attribute, and the samples are partitioned accordingly.
Example 7.2 Induction of a decision tree. Table 7.1 presents a training set of data tuples taken from the AllElectronics customer database. (The data are adapted from [Quinlan 1986b]). The class label attribute, buys computer,
has two distinct values (namely fyes, nog), therefore, there are two distinct classes (m = 2). Let C correspond to
1
the class yes and class C2 correspond to no. There are 9 samples of class yes and 5 samples of class no. To compute
the information gain of each attribute, we rst use Equation (7.1) to compute the expected information needed to
classify a given sample. This is:
9 log 9 , 5 log 5 = 0:940
I(s1 ; s2 ) = I(9; 5) = , 14
2
14 14 2 14
Next, we need to compute the entropy of each attribute. Let's start with the attribute age. We need to look at
the distribution of yes and no samples for each value of age. We compute the expected information for each of these
distributions.
for age = \<30":
for age = \30-40":
for age = \>40":
s11 = 2
s12 = 4
s13 = 3
s21 = 3
s22 = 0
s23 = 2
I(s11 ; s21) = 0.971
I(s12 ; s22) = 0
I(s13 ; s23) = 0.971
7.3. CLASSIFICATION BY DECISION TREE INDUCTION
rid
1
2
3
4
5
6
7
8
9
10
11
12
13
14
age
<30
<30
30-40
>40
>40
>40
30-40
<30
<30
>40
<30
30-40
30-40
>40
income
high
high
high
medium
low
low
low
medium
low
medium
medium
medium
high
medium
student
no
no
no
no
yes
yes
yes
no
yes
yes
yes
no
yes
no
credit rating
fair
excellent
fair
fair
fair
excellent
excellent
fair
fair
fair
excellent
excellent
fair
excellent
9
Class: buys computer
no
no
yes
yes
yes
no
yes
no
yes
yes
yes
yes
yes
no
Table 7.1: Training data tuples from the AllElectronics customer database.
Using Equation (7.2), the expected information needed to classify a given sample if the samples are partitioned
according to age, is:
5 I(s ; s ) + 4 I(s ; s ) + 5 I(s ; s ) = 0:694:
E(age) = 14
11
21
14 12 22 14 13 23
Hence, the gain in information from such a partitioning would be:
Gain(age) = I(s1 ; s2) , E(age) = 0:246
Similarly, we can compute Gain(income) = 0.029, Gain(student) = 0.151, and Gain(credit rating) = 0.048. Since
age has the highest information gain among the attributes, it is selected as the test attribute. A node is created
and labeled with age, and branches are grown for each of the attribute's values. The samples are then partitioned
accordingly, as shown in Figure 7.4. Notice that the samples falling into the partition for age = 30-40 all belong to
the same class. Since they all belong to class yes, a leaf should therefore be created at the end of this branch and
labeled with yes. The nal decision tree returned by the algorithm is shown in Figure 7.2.
2
In summary, decision tree induction algorithms have been used for classication in a wide range of application
domains. Such systems do not use domain knowledge. The learning and classication steps of decision tree induction
are generally fast. Classication accuracy is typically high for data where the mapping of classes consists of long and
thin regions in concept space.
7.3.2 Tree pruning
When a decision tree is built, many of the branches will reect anomalies in the training data due to noise or outliers.
Tree pruning methods address this problem of overtting the data. Such methods typically use statistical measures
to remove the least reliable branches, generally resulting in faster classication and an improvement in the ability of
the tree to correctly classify independent test data.
\How does tree pruning work?" There are two common approaches to tree pruning.
In the prepruning approach, a tree is \pruned" by halting its construction early (e.g., by deciding not to
further split or partition the subset of training samples at a given node). Upon halting, the node becomes a
leaf. The leaf may hold the most frequent class among the subset samples, or the probability distribution of
those samples.
When constructing a tree, measures such as statistical signicance, 2 , information gain, etc., can be used to
assess the goodness of a split. If partitioning the samples at a node would result in a split that falls below a
prespecied threshold, then further partitioning of the given subset is halted. There are diculties, however,
CHAPTER 7. CLASSIFICATION AND PREDICTION
10
age?
<30
30-40
>40
income
student credit_rating
Class
income
student credit_rating
Class
income
student credit_rating
Class
high
no
fair
no
high
no
fair
yes
medium
no
fair
yes
high
no
excellent
no
low
yes
excellent
yes
low
yes
fair
yes
medium
no
fair
no
medium
no
excellent
yes
low
yes
excellent
no
low
yes
fair
yes
high
yes
fair
yes
medium
yes
fair
yes
medium
yes
excellent
yes
medium
no
excellent
no
Figure 7.4: The attribute age has the highest information gain and therefore becomes a test attribute at the root
node of the decision tree. Branches are grown for each value of age. The samples are shown partitioned according
to each branch.
in choosing an appropriate threshold. High thresholds could result in oversimplied trees, while low thresholds
could result in very little simplication.
The postpruning approach removes branches from a \fully grown" tree. A tree node is pruned by removing
its branches.
The cost complexity pruning algorithm is an example of the postpruning approach. The pruned node becomes
a leaf and is labeled by the most frequent class among its former branches. For each non-leaf node in the tree,
the algorithm calculates the expected error rate that would occur if the subtree at that node were pruned.
Next, the expected error rate occurring if the node were not pruned is calculated using the error rates for each
branch, combined by weighting according to the proportion of observations along each branch. If pruning the
node leads to a greater expected error rate, then the subtree is kept. Otherwise, it is pruned. After generating
a set of progressively pruned trees, an independent test set is used to estimate the accuracy of each tree. The
decision tree that minimizes the expected error rate is preferred.
Rather than pruning trees based on expected error rates, we can prune trees based on the number of bits
required to encode them. The \best pruned tree" is the one that minimizes the number of encoding bits. This
method adopts the Minimum Description Length (MDL) principle which follows the notion that the simplest
solution is preferred. Unlike cost complexity pruning, it does not require an independent set of samples.
Alternatively, prepruning and postpruning may be interleaved for a combined approach. Postpruning requires
more computation than prepruning, yet generally leads to a more reliable tree.
7.3.3 Extracting classication rules from decision trees
\Can I get classication rules out of my decision tree? If so, how?"
The knowledge represented in decision trees can be extracted and represented in the form of classication IFTHEN rules. One rule is created for each path from the root to a leaf node. Each attribute-value pair along a given
path forms a conjunction in the rule antecedent (\IF" part). The leaf node holds the class prediction, forming the
rule consequent (\THEN" part). The IF-THEN rules may be easier for humans to understand, particularly if the
given tree is very large.
7.3. CLASSIFICATION BY DECISION TREE INDUCTION
11
Example 7.3 Generating classication rules from a decision tree. The decision tree of Figure 7.2 can be
converted to classication IF-THEN rules by tracing the path from the root node to each leaf node in the tree. The
rules extracted from Figure 7.2 are:
IF age = \<30" AND student = no
THEN buys computer = no
IF age = \<30" AND student = yes
THEN buys computer = yes
IF age = \30-40"
THEN buys computer = yes
IF age = \>40" AND credit rating = excellent THEN buys computer = yes
IF age = \>40" AND credit rating = fair
THEN buys computer = no
2
C4.5, a later version of the ID3 algorithm, uses the training samples to estimate the accuracy of each rule. Since
this would result in an optimistic estimate of rule accuracy, C4.5 employs a pessimistic estimate to compensate for
the bias. Alternatively, a set of test samples independent from the training set can be used to estimate rule accuracy.
A rule can be \pruned" by removing any condition in its antecedent that does not improve the estimated accuracy
of the rule. For each class, rules within a class may then be ranked according to their estimated accuracy. Since it
is possible that a given test sample will not satisfy any rule antecedent, a default rule assigning the majority class is
typically added to the resulting rule set.
7.3.4 Enhancements to basic decision tree induction
\What are some enhancements to basic decision tree induction?"
Many enhancements to the basic decision tree induction algorithm of Section 7.3.1 have been proposed. In this
section, we discuss several major enhancements, many of which are incorporated into C4.5, a successor algorithm to
ID3.
The basic decision tree induction algorithm of Section 7.3.1 requires all attributes to be categorical or discretized.
The algorithm can be modied to allow for continuous-valued attributes. A test on a continuous-valued attribute A
results in two branches, corresponding to the conditions A V and A > V for some numeric value, V , of A. Given
v values of A, then v , 1 possible splits are considered in determining V . Typically, the midpoints between each pair
of adjacent values are considered. If the values are sorted in advance, then this requires only one pass through the
values.
The basic algorithm for decision tree induction creates one branch for each value of a test attribute, and then
distributes the samples accordingly. This partitioning can result in numerous small subsets. As the subsets become
smaller and smaller, the partitioning process may end up using sample sizes that are statistically insucient. The
detection of useful patterns in the subsets may become impossible due to insuciency of the data. One alternative
is to allow for the grouping of categorical attribute values. A tree node may test whether the value of an attribute
belongs to a given set of values, such as Ai 2 fa1; a2; : : :; ang. Another alternative is to create binary decision trees,
where each branch holds a boolean test on an attribute. Binary trees result in less fragmentation of the data. Some
empirical studies have found that binary decision trees tend to be more accurate that traditional decision trees.
The information gain measure is biased in that it tends to prefer attributes with many values. Many alternatives
have been proposed, such as gain ratio, which considers the probability of each attribute value. Various other selection
measures exist, including the gini index, the 2 contingency table statistic, and the G-statistic.
Many methods have been proposed for handling missing attribute values. A missing or unknown value for an
attribute A may be replaced by the most common value for A, for example. Alternatively, the apparent information
gain of attribute A can be reduced by the proportion of samples with unknown values of A. In this way, \fractions"
of a sample having a missing value can be partitioned into more than one branch at a test node. Other methods
may look for the most probable value of A, or make use of known relationships between A and other attributes.
Incremental versions of decision tree induction have been proposed. When given new training data, these
restructure the decision tree acquired from learning on previous training data, rather than relearning a new tree
\from scratch".
Additional enhancements to basic decision tree induction which address scalability, and the integration of data
warehousing techniques, are discussed in Sections 7.3.5 and 7.3.6, respectively.
CHAPTER 7. CLASSIFICATION AND PREDICTION
12
7.3.5 Scalability and decision tree induction
\How scalable is decision tree induction?"
The eciency of existing decision tree algorithms, such as ID3 and C4.5, has been well established for relatively
small data sets. Eciency and scalability become issues of concern when these algorithms are applied to the mining of
very large, real-world databases. Most decision tree algorithms have the restriction that the training samples should
reside in main memory. In data mining applications, very large training sets of millions of samples are common.
Hence, this restriction limits the scalability of such algorithms, where the decision tree construction can become
inecient due to swapping of the training samples in and out of main and cache memories.
Early strategies for inducing decision trees from large databases include discretizing continuous attributes, and
sampling data at each node. These, however, still assume that the training set can t in memory. An alternative
method rst partitions the data into subsets which individually can t into memory, and then builds a decision
tree from each subset. The nal output classier combines each classier obtained from the subsets. Although this
method allows for the classication of large data sets, its classication accuracy is not as high as the single classier
that would have been built using all of the data at once.
rid
1
2
3
4
credit rating
excellent
excellent
fair
excellent
age
38
26
35
49
buys computer
yes
yes
no
no
Table 7.2: Sample data for the class buys computer.
credit_rating
rid
age
rid
rid
buys_computer
excellent
1
26
2
1
yes
5
excellent
2
35
3
2
yes
2
fair
3
38
1
3
no
3
excellent
...
4
...
49
...
4
...
4
...
no
...
6
...
0
node
1
2
3
4
5
Disk Resident -- Attribute List
6
Memory Resident -- Class List
Figure 7.5: Attribute list and class list data structures used in SLIQ for the sample data of Table 7.2.
More recent decision tree algorithms which address the scalability issue have been proposed. Algorithms for
the induction of decision trees from very large training sets include SLIQ and SPRINT, both of which can handle
categorical and continuous-valued attributes. Both algorithms propose pre-sorting techniques on disk-resident data
sets that are too large to t in memory. Both dene the use of new data structures to facilitate the tree construction.
SLIQ employs disk resident attribute lists and a single memory resident class list. The attribute lists and class lists
generated by SLIQ for the sample data of Table 7.2 are shown in Figure 7.5. Each attribute has an associated
attribute list, indexed by rid (a record identier). Each tuple is represented by a linkage of one entry from each
attribute list to an entry in the class list (holding the class label of the given tuple), which in turn is linked to its
corresponding leaf node in the decision tree. The class list remains in memory since it is often accessed and modied
in the building and pruning phases. The size of the class list grows proportionally with the number of tuples in the
training set. When a class list cannot t into memory, the performance of SLIQ decreases.
SPRINT uses a dierent attribute list data structure which holds the class and rid information, as shown in
Figure 7.6. When a node is split, the attribute lists are partitioned and distributed among the resulting child nodes
7.3. CLASSIFICATION BY DECISION TREE INDUCTION
13
credit_rating
buys_computer
rid
age
buys_computer
rid
excellent
yes
1
26
y
2
excellent
yes
2
35
n
3
fair
no
3
38
y
1
excellent
...
no
...
4
...
49
...
n
4
...
...
Figure 7.6: Attribute list data structure used in SPRINT for the sample data of Table 7.2.
accordingly. When a list is partitioned, the order of the records in the list is maintained. Hence, partitioning lists
does not require resorting. SPRINT was designed to be easily parallelized, further contributing to its scalability.
While both SLIQ and SPRINT handle disk-resident data sets that are too large to t into memory, the scalability
of SLIQ is limited by the use of its memory-resident data structure. SPRINT removes all memory restrictions, yet
requires the use of a hash tree proportional in size to the training set. This may become expensive as the training
set size grows.
RainForest is a framework for the scalable induction of decision trees. The method adapts to the amount of main
memory available, and apply to any decision tree induction algorithm. It maintains an AVC-set (Attribute-Value,
Class label) indicating the class distribution for each attribute. RainForest reports a speed-up over SPRINT.
7.3.6 Integrating data warehousing techniques and decision tree induction
Decision tree induction can be integrated with data warehousing techniques for data mining. In this section we
discuss the method of attribute-oriented induction to generalize the given data, and the use of multidimensional
data cubes to store the generalized data at multiple levels of granularity. We then discuss how these approaches
can be integrated with decision tree induction in order to facilitate interactive multilevel mining. The use of a data
mining query language to specify classication tasks is also discussed. In general, the techniques described here are
applicable to other forms of learning as well.
Attribute-oriented induction (AOI) uses concept hierarchies to generalize the training data by replacing lower
level data with higher level concepts (Chapter 5). For example, numerical values for the attribute income may be
generalized to the ranges \<30K", \30K-40K", \>40K", or the categories low, medium, or high. This allows the user
to view the data at more meaningful levels. In addition, the generalized data are more compact than the original
training set, which may result in fewer input/output operations. Hence, AOI also addresses the scalability issue by
compressing the training data.
The generalized training data can be stored in a multidimensional data cube, such as the structure typically
used in data warehousing (Chapter 2). The data cube is a multidimensional data structure, where each dimension
represents an attribute or a set of attributes in the data schema, and each cell stores the value of some aggregate
measure (such as count). Figure 7.7 shows a data cube for customer information data, with the dimensions income,
age, and occupation. The original numeric values of income and age have been generalized to ranges. Similarly,
original values for occupation, such as accountant and banker, or nurse and X-ray technician, have been generalized
to nance and medical, respectively. The advantage of the multidimensional structure is that it allows fast indexing
to cells (or slices) of the cube. For instance, one may easily and quickly access the total count of customers in
occupations relating to nance who have an income greater than $40K, or the number of customers who work in the
area of medicine and are less than 40 years old.
Data warehousing systems provide a number of operations that allow mining on the data cube at multiple levels
of granularity. To review, the roll-up operation performs aggregation on the cube, either by climbing up a concept
hierarchy (e.g., replacing the value banker for occupation by the more general, nance), or by removing a dimension
in the cube. Drill-down performs the reverse of roll-up, by either stepping down a concept hierarchy or adding a
dimension (e.g., time). A slice performs a selection on one dimension of the cube. For example, we may obtain a
data slice for the generalized value accountant of occupation, showing the corresponding income and age data. A
dice performs a selection on two or more dimensions. The pivot or rotate operation rotates the data axes in view
CHAPTER 7. CLASSIFICATION AND PREDICTION
14
Finance
Medical
Government
Occupation
> 30K
Income
30K-40K
> 40K
< 30 30-40
> 40
Age
Figure 7.7: A multidimensional data cube.
in order to provide an alternative presentation of the data. For example, pivot may be used to transform a 3-D cube
into a series of 2-D planes.
The above approaches can be integrated with decision tree induction to provide interactive multilevel mining
of decision trees. The data cube and knowledge stored in the concept hierarchies can be used to induce decision
trees at dierent levels of abstraction. Furthermore, once a decision tree has been derived, the concept hierarchies
can be used to generalize or specialize individual nodes in the tree, allowing attribute roll-up or drill-down, and
reclassication of the data for the newly specied abstraction level. This interactive feature will allow users to focus
their attention on areas of the tree or data which they nd interesting.
When integrating AOI with decision tree induction, generalization to a very low (specic) concept level can result
in quite large and bushy trees. Generalization to a very high concept level can result in decision trees of little use,
where interesting and important subconcepts are lost due to overgeneralization. Instead, generalization should be to
some intermediate concept level, set by a domain expert or controlled by a user-specied threshold. Hence, the use
of AOI may result in classication trees that are more understandable, smaller, and therefore easier to interpret than
trees obtained from methods operating on ungeneralized (larger) sets of low-level data (such as SLIQ or SPRINT).
A criticism of typical decision tree generation is that, because of the recursive partitioning, some resulting data
subsets may become so small that partitioning them further would have no statistically signicant basis. The
maximum size of such \insignicant" data subsets can be statistically determined. To deal with this problem, an
exception threshold may be introduced. If the portion of samples in a given subset is less than the threshold, further
partitioning of the subset is halted. Instead, a leaf node is created which stores the subset and class distribution of
the subset samples.
Owing to the large amount and wide diversity of data in large databases, it may not be reasonable to assume
that each leaf node will contain samples belonging to a common class. This problem may be addressed by employing
a precision or classication threshold. Further partitioning of the data subset at a given node is terminated if
the percentage of samples belonging to any given class at that node exceeds this threshold.
A data mining query language may be used to specify and facilitate the enhanced decision tree induction method.
Suppose that the data mining task is to predict the credit risk of customers aged 30-40, based on their income and
occupation. This may be specied as the following data mining query:
mine classication
analyze credit risk
in relevance to income, occupation
from Customer db
where (age >= 30) and (age < 40)
display as rules
7.4. BAYESIAN CLASSIFICATION
15
The above query, expressed in DMQL1 , executes a relational query on Customer db to retrieve the task-relevant
data. Tuples not satisfying the where clause are ignored, and only the data concerning the attributes specied in the
in relevance to clause, and the class label attribute (credit risk) are collected. AOI is then performed on this data.
Since the query has not specied which concept hierarchies to employ, default hierarchies are used. A graphical user
interface may be designed to facilitate user specication of data mining tasks via such a data mining query language.
In this way, the user can help guide the automated data mining process.
Hence, many ideas from data warehousing can be integrated with classication algorithms, such as decision tree
induction, in order to facilitate data mining. Attribute-oriented induction employs concept hierarchies to generalize
data to multiple abstraction levels, and can be integrated with classication methods in order to perform multilevel
mining. Data can be stored in multidimensional data cubes to allow quick accessing to aggregate data values. Finally,
a data mining query language can be used to assist users in interactive data mining.
7.4 Bayesian classication
\What are Bayesian classiers"?
Bayesian classiers are statistical classiers. They can predict class membership probabilities, such as the probability that a given sample belongs to a particular class.
Bayesian classication is based on Bayes theorem, described below. Studies comparing classication algorithms
have found a simple Bayesian classier known as the naive Bayesian classier to be comparable in performance with
decision tree and neural network classiers. Bayesian classiers have also exhibited high accuracy and speed when
applied to large databases.
Naive Bayesian classiers assume that the eect of an attribute value on a given class is independent of the
values of the other attributes. This assumption is called class conditional independence. It is made to simplify the
computations involved, and in this sense, is considered \naive". Bayesian belief networks are graphical models, which
unlike naive Bayesian classiers, allow the representation of dependencies among subsets of attributes. Bayesian belief
networks can also be used for classication.
Section 7.4.1 reviews basic probability notation and Bayes theorem. You will then learn naive Bayesian classication in Section 7.4.2. Bayesian belief networks are described in Section 7.4.3.
7.4.1 Bayes theorem
Let X be a data sample whose class label is unknown. Let H be some hypothesis, such as that the data sample X
belongs to a specied class C. For classication problems, we want to determine P(H jX), the probability that the
hypothesis H holds given the observed data sample X.
P(H jX) is the posterior probability, or a posteriori probability, of H conditioned on X. For example, suppose
the world of data samples consists of fruits, described by their color and shape. Suppose that X is red and round,
and that H is the hypothesis that X is an apple. Then P(H jX) reects our condence that X is an apple given that
we have seen that X is red and round. In contrast, P(H) is the prior probability, or a priori probability of H.
For our example, this is the probability that any given data sample is an apple, regardless of how the data sample
looks. The posterior probability, P (H jX) is based on more information (such as background knowledge) than the
prior probability, P(H), which is independent of X.
Similarly, P(X jH) is the posterior probability of X conditioned on H. That is, it is the probability that X is
red and round given that we know that it is true that X is an apple. P(X) is the prior probability of X. Using our
example, it is the probability that a data sample from our set of fruits is red and round.
\How are these probabilities estimated?" P (X), P(H), and P(X jH) may be estimated from the given data, as we
shall see below. Bayes theorem is useful in that it provides a way of calculating the posterior probability, P (H jX)
from P (H), P (X), and P(X jH). Bayes theorem is:
jH)P(H)
P (H jX) = P(XP(X)
(7.4)
In the next section, you will learn how Bayes theorem is used in the naive Bayesian classier.
1 The use of a data mining query language to specify data mining queries is discussed in Chapter 4, using the SQL-based DMQL
language.
CHAPTER 7. CLASSIFICATION AND PREDICTION
16
7.4.2 Naive Bayesian classication
The naive Bayesian classier, or simple Bayesian classier, works as follows:
1. Each data sample is represented by an n-dimensional feature vector, X = (x1 ; x2; : : :; xn), depicting n measurements made on the sample from n attributes, respectively A1 ; A2; ::; An.
2. Suppose that there are m classes, C1 ; C2; : : :; Cm . Given an unknown data sample, X (i.e., having no class
label), the classier will predict that X belongs to the class having the highest posterior probability, conditioned
on X. That is, the naive Bayesian classier assigns an unknown sample X to the class Ci if and only if :
P (CijX) > P(Cj jX) for 1 j m; j 6= i.
Thus we maximize P(CijX). The class Ci for which P(CijX) is maximized is called the maximum posteriori
hypothesis. By Bayes theorem (Equation (7.4)),
jCi )P(Ci) :
P(CijX) = P(XP(X)
(7.5)
3. As P(X) is constant for all classes, only P(X jCi)P(Ci ) need be maximized. If the class prior probabilities are
not known, then it is commonly assumed that the classes are equally likely, i.e. P(C1) = P(C2) = : : : = P(Cm ),
and we would therefore maximize P (X jCi ). Otherwise, we maximize P(X jCi)P(Ci). Note that the class prior
probabilities may be estimated by P (Ci) = ssi , where si is the number of training samples of class Ci, and s is
the total number of training samples.
4. Given data sets with many attributes, it would be extremely computationally expensive to compute P(X jCi ). In
order to reduce computation in evaluating P(X jCi ), the naive assumption of class conditional independence
is made. This presumes that the values of the attributes are conditionally independent of one another, given
the class label of the sample, i.e., that there are no dependence relationships among the attributes. Thus,
P(X jCi) =
Yn P(x jC ):
k=1
(7.6)
k i
The probabilities P(x1jCi); P (x2jCi); : : :; P(xnjCi) can be estimated from the training samples, where:
(a) If Ak is categorical, then P(xk jCi) = ssiki , where sik is the number of training samples of class Ci having
the value xk for Ak , and si is the number of training samples belonging to Ci.
(b) If Ak is continuous-valued, then the attribute is assumed to have a Gaussian distribution. Therefore,
x,
, Ci
P (xkjCi) = g(xk ; Ci ; Ci ) = p 1 e Ci ;
(7.7)
2Ci
where g(xk ; Ci ; Ci ) is the Gaussian (normal) density function for attribute Ak , while Ci and Ci
are the mean and variance respectively given the values for attribute Ak for training samples of class Ci .
5. In order to classify an unknown sample X, P(X jCi )P(Ci) is evaluated for each class Ci . Sample X is then
assigned to the class Ci if and only if :
(
)2
2 2
P (X jCi )P(Ci) > P(X jCj )P(Cj ) for 1 j m; j 6= i.
In other words, it is assigned to the class, Ci, for which P(X jCi)P(Ci) is the maximum.
7.4. BAYESIAN CLASSIFICATION
17
\How eective are Bayesian classiers?"
In theory, Bayesian classiers have the minimum error rate in comparison to all other classiers. However, in
practice this is not always the case owing to inaccuracies in the assumptions made for its use, such as class conditional
independence, and the lack of available probability data. However, various empirical studies of this classier in
comparison to decision tree and neural network classiers have found it to be comparable in some domains.
Bayesian classiers are also useful in that they provide a theoretical justication for other classiers which do not
explicitly use Bayes theorem. For example, under certain assumptions, it can be shown that many neural network
and curve tting algorithms output the maximum posteriori hypothesis, as does the naive Bayesian classier.
Example 7.4 Predicting a class label using naive Bayesian classication. We wish to predict the class
label of an unknown sample using naive Bayesian classication, given the same training data as in Example 7.2 for
decision tree induction. The training data are in Table 7.1. The data samples are described by the attributes age,
income, student, and credit rating. The class label attribute, buys computer, has two distinct values (namely fyes,
nog). Let C1 correspond to the class buys computer = yes and C2 correspond to buys computer = no. The unknown
sample we wish to classify is
X = (age = \<30", income = medium, student = yes, credit rating = fair).
We need to maximize P (X jCi )P(Ci), for i = 1, 2. P(Ci), the prior probability of each class, can be computed
based on the training samples:
P (buys computer = yes) = 9=14 = 0:643
P (buys computer = no) = 5=14 = 0:357
To compute P (X jCi), for i = 1, 2, we compute the following conditional probabilities:
P(age = \<30" j buys computer = yes)
= 2=9 = 0:222
P(age = \<30" j buys computer = no)
= 3=5 = 0:600
P(income = medium j buys computer = yes) = 4=9 = 0:444
P(income = medium j buys computer = no) = 2=5 = 0:400
P(student = yes j buys computer = yes)
= 6=9 = 0:667
P(student = yes j buys computer = no)
= 1=5 = 0:200
P(credit rating = fair j buys computer = yes) = 6=9 = 0:667
P(credit rating = fair j buys computer = no) = 2=5 = 0:400
Using the above probabilities, we obtain
P(X jbuys computer = yes) = 0:222 0:444 0:667 0:667 = 0:044
P(X jbuys computer = no) = 0:600 0:400 0:200 0:400 = 0:019
P(X jbuys computer = yes)P(buys computer = yes) = 0:044 0:643 = 0:028
P(X jbuys computer = no)P(buys computer = no) = 0:019 0:357 = 0:007
Therefore, the naive Bayesian classier predicts \buys computer = yes" for sample X.
2
7.4.3 Bayesian belief networks
The naive Bayesian classier makes the assumption of class conditional independence, i.e., that given the class label
of a sample, the values of the attributes are conditionally independent of one another. This assumption simplies
computation. When the assumption holds true, then the naive Bayesian classier is the most accurate in comparison
with all other classiers. In practice, however, dependencies can exist between variables. Bayesian belief networks
specify joint conditional probability distributions. They allow class conditional independencies to be dened between
subsets of variables. They provide a graphical model of causal relationships, on which learning can be performed.
These networks are also known as belief networks, Bayesian networks, and probabilistic networks. For
brevity, we will refer to them as belief networks.
CHAPTER 7. CLASSIFICATION AND PREDICTION
18
a)
b)
FamilyHistory
Smoker
LungCancer
Emphysema
PositiveXRay
Dyspnea
FH, S
FH, ~S
~FH, S
~FH, ~S
LC
0.8
0.5
0.7
0.1
~LC
0.2
0.5
0.3
0.9
Figure 7.8: a) A simple Bayesian belief network; b) The conditional probability table for the values of the variable
LungCancer (LC) showing each possible combination of the values of its parent nodes, Family History (FH) and
Smoker (S).
A belief network is dened by two components. The rst is a directed acyclic graph, where each node represents
a random variable, and each arc represents a probabilistic dependence. If an arc is drawn from a node Y to a
node Z, then Y is a parent or immediate predecessor of Z, and Z is a descendent of Y . Each variable is
conditionally independent of its nondescendents in the graph, given its parents. The variables may be discrete or
continuous-valued. They may correspond to actual attributes given in the data, or to \hidden variables" believed to
form a relationship (such as medical syndromes in the case of medical data).
Figure 7.8a) shows a simple belief network, adapted from [Russell et al. 1995a] for six Boolean variables. The
arcs allow a representation of causal knowledge. For example, having lung cancer is inuenced by a person's family
history of lung cancer, as well as whether or not the person is a smoker. Furthermore, the arcs also show that the
variable LungCancer is conditionally independent of Emphysema, given its parents, FamilyHistory and Smoker. This
means that once the values of FamilyHistory and Smoker are known, then the variable Emphysema does not provide
any additional information regarding LungCancer.
The second component dening a belief network consists of one conditional probability table (CPT) for each
variable. The CPT for a variable Z species the conditional distribution P(Z jParents(Z)), where P arents(Z)
are the parents of Z. Figure 7.8b) showns a CPT for LungCancer. The conditional probability for each value of
LungCancer is given for each possible combination of values of its parents. For instance, from the upper leftmost
and bottom rightmost entries, respectively, we see that
P (LungCancer = Y es j FamilyHistory = Y es; Smoker = Y es) = 0:8, and
P(LungCancer = No j FamilyHistory = No; Smoker = No) = 0:9.
by
The joint probability of any tuple (z1 ; :::; zn) corresponding to the variables or attributes Z1 ; :::; Zn is computed
P (z1; :::; zn) =
Yn P(z jParents(Z ));
i=1
i
i
(7.8)
where the values for P(zi jParents(Zi)) correspond to the entries in the CPT for Zi .
A node within the network can be selected as an \output" node, representing a class label attribute. There may
be more than one output node. Inference algorithms for learning can be applied on the network. The classication
process, rather than returning a single class label, can return a probability distribution for the class label attribute,
i.e., predicting the probability of each class.
7.5. CLASSIFICATION BY BACKPROPAGATION
19
7.4.4 Training Bayesian belief networks
\How does a Bayesian belief network learn?"
In learning or training a belief network, a number of scenarios are possible. The network structure may be given
in advance, or inferred from the data. The network variables may be observable or hidden in all or some of the
training samples. The case of hidden data is also referred to as missing values or incomplete data.
If the network structure is known and the variables are observable, then learning the network is straightforward.
It consists of computing the CPT entries, as is similarly done when computing the probabilities involved in naive
Bayesian classication.
When the network structure is given and some of the variables are hidden, then a method of gradient descent can
be used to train the belief network. The object is to learn the values for the CPT entries. Let S be a set of s training
samples, X1 ; X2; ::; Xs. Let wijk be a CPT entry for the variable Yi = yij having the parents Ui = uik . For example,
if wijk is the upper leftmost CPT entry of Figure 7.8b), then Yi is LungCancer; yij is its value, Yes; Ui lists the parent
nodes of Yi , namely fFamilyHistory, Smokerg; and uik lists the values of the parent nodes, namely fYes, Yesg. The
wijk are viewed as weights, analogous to the weights in hidden units of neural networks (Section 7.5). The weights,
wijk , are initialized to random probability values. The gradient descent strategy performs greedy hill-climbing. At
each iteration, the weights are updated, and will eventually converge to a local optimum solution.
The method aims to maximize P(S jH). This is done by following the gradient of lnP(S jH), which makes the
problem simpler. Given the network structure and initialized wijk, the algorithm proceeds as follows.
1. Compute the gradients: For each i; j; k, compute
s P(Y = y ; U = u jX )
@lnP (S jH) = X
i
ij i
ik d
@wijk
w
ijk
d=1
(7.9)
The probability in the right-hand side of Equation (7.9) is to be calculated for each training sample Xd in S.
For brevity, let's refer to this probability simply as p. When the variables represented by Yi and Ui are hidden
for some Xd , then the corresponding probability p can be computed from the observed variables of the sample
using standard algorithms for Bayesian network inference (such as those available by the commercial software
package, Hugin).
2. Take a small step in the direction of the gradient: The weights are updated by
wijk
jH) ;
wijk + (l) @lnP(S
@w
ijk
(7.10)
(S jH )
where l is the learning rate representing the step size, and @lnP
@wijk is computed from Equation (7.9). The
learning rate is set to a small constant.
3. Renormlize
P the weights: Because the weights wijk are probability values, they must be between 0 and 1.0,
and j wijk must equal 1 for all i; k. These criteria are achieved by renormalizing the weights after they have
been updated by Equation (7.10).
Several algorithms exist for learning the network structure from the training data given observable variables. The
problem is one of discrete optimization. For solutions, please see the bibliographic notes at the end of this chapter.
7.5 Classication by backpropagation
\What is backpropagation?"
Backpropagation is a neural network learning algorithm. The eld of neural networks was originally kindled
by psychologists and neurobiologists who sought to develop and test computational analogues of neurons. Roughly
CHAPTER 7. CLASSIFICATION AND PREDICTION
20
input
hidden
output
layer
layer
layer
x_1
x_2
x_i
w_ij
w_kj
O_j
O_k
Figure 7.9: A multilayer feed-forward neural network: A training sample, X = (x1; x2; ::; xi), is fed to the input
layer. Weighted connections exist between each layer, where wij denotes the weight from a unit j in one layer to a
unit i in the previous layer.
speaking, a neural network is a set of connected input/output units where each connection has a weight associated
with it. During the learning phase, the network learns by adjusting the weights so as to be able to predict the correct
class label of the input samples. Neural network learning is also referred to as connectionist learning due to the
connections between units.
Neural networks involve long training times, and are therefore more suitable for applications where this is feasible.
They require a number of parameters which are typically best determined empirically, such as the network topology
or \structure". Neural networks have been criticized for their poor interpretability, since it is dicult for humans
to interpret the symbolic meaning behind the learned weights. These features initially made neural networks less
desirable for data mining.
Advantages of neural networks, however, include their high tolerance to noisy data as well as their ability to
classify patterns on which they have not been trained. In addition, several algorithms have recently been developed
for the extraction of rules from trained neural networks. These factors contribute towards the usefulness of neural
networks for classication in data mining.
The most popular neural network algorithm is the backpropagation algorithm, proposed in the 1980's. In Section 7.5.1 you will learn about multilayer feed-forward networks, the type of neural network on which the backpropagation algorithm performs. Section 7.5.2 discusses dening a network topology. The backpropagation algorithm is
described in Section 7.5.3. Rule extraction from trained neural networks is discussed in Section 7.5.4.
7.5.1 A multilayer feed-forward neural network
The backpropagation algorithm performs learning on a multilayer feed-forward neural network. An example
of such a network is shown in Figure 7.9. The inputs correspond to the attributes measured for each training sample.
The inputs are fed simultaneously into a layer of units making up the input layer. The weighted outputs of these
units are, in turn, fed simultaneously to a second layer of \neuron-like" units, known as a hidden layer. The hidden
layer's weighted outputs can be input to another hidden layer, and so on. The number of hidden layers is arbitrary,
although in practice, usually only one is used. The weighted outputs of the last hidden layer are input to units
making up the output layer, which emits the network's prediction for given samples.
The units in the hidden layers and output layer are sometimes referred to as neurodes, due to their symbolic
biological basis, or as output units. The multilayer neural network shown in Figure 7.9 has two layers of output
units. Therefore, we say that it is a two-layer neural network. Similarly, a network containing two hidden layers is
called a three-layer neural network, and so on. The network is feed-forward in that none of the weights cycle back
to an input unit or to an output unit of a previous layer. It is fully connected in that each unit provides input to
each unit in the next forward layer.
Multilayer feed-forward networks of linear threshold functions, given enough hidden units, can closely approximate
any function.
7.5. CLASSIFICATION BY BACKPROPAGATION
21
7.5.2 Dening a network topology
\How can I design the topology of the neural network?"
Before training can begin, the user must decide on the network topology by specifying the number of units in
the input layer, the number of hidden layers (if more than one), the number of units in each hidden layer, and the
number of units in the output layer.
Normalizing the input values for each attribute measured in the training samples will help speed up the learning
phase. Typically, input values are normalized so as to fall between 0 and 1.0. Discrete-valued attributes may be
encoded such that there is one input unit per domain value. For example, if the domain of an attribute A is
fa0 ; a1; a2g, then we may assign three input units to represent A. That is, we may have, say, I0 ; I1; I2, as input units.
Each unit is initialized to 0. If A = a0, then I0 is set to 1. If A = a1 , I1 is set to 1, and so on. One output unit
may be used to represent two classes (where the value 1 represents one class, and the value 0 represents the other).
If there are more than two classes, then 1 output unit per class is used.
There are no clear rules as to the \best" number of hidden layer units. Network design is a trial by error process
and may aect the accuracy of the resulting trained network. The initial values of the weights may also aect the
resulting accuracy. Once a network has been trained and its accuracy is not considered acceptable, then it is common
to repeat the training process with a dierent network topology or a dierent set of initial weights.
7.5.3 Backpropagation
\How does backpropagation work?"
Backpropagation learns by iteratively processing a set of training samples, comparing the network's prediction for
each sample with the actual known class label. For each training sample, the weights are modied so as to minimize
the mean squared error between the network's prediction and the actual class. These modications are made in the
\backwards" direction, i.e., from the output layer, through each hidden layer down to the rst hidden layer (hence
the name backpropagation). Although it is not guaranteed, in general the weights will eventually converge, and the
learning process stops. The algorithm is summarized in Figure 7.10. Each step is described below.
Initialize the weights. The weights in the network are initialized to small random numbers (e.g., ranging from
-1.0 to 1.0, or -0.5 to 0.5). Each unit has a bias associated with it, as explained below. The biases are similarly
initialized to small random numbers.
Each training sample, X, is processed by the following steps.
Propagate the inputs forward. In this step, the net input and output of each unit in the hidden and output
layers are computed. First, the training sample is fed to the input layer of the network. The net input to each unit
in the hidden and output layers is then computed as a linear combination of its inputs. To help illustrate this, a
hidden layer or output layer unit is shown in Figure 7.11. The inputs to the unit are, in fact, the outputs of the
units connected to it in the previous layer. To compute the net input to the unit, each input connected to the unit
is multiplied by its corresponding weight, and this is summed. Given a unit j in a hidden or output layer, the net
input, Ij , to unit j is:
Ij =
Xw
i
ij Oi + j
(7.11)
where wij is the weight of the connection from unit i in the previous layer to unit j; Oi is the output of unit i from
the previous layer; and j is the bias of the unit. The bias acts as a threshold in that it serves to vary the activity
of the unit.
Each unit in the hidden and output layers takes its net input, and then applies an activation function to it,
as illustrated in Figure 7.11. The function symbolizes the activation of the neuron represented by the unit. The
logistic, or simoid function is used. Given the net input Ij to unit j, then Oj , the output of unit j, is computed as:
Oj = 1 + 1e,Ij
(7.12)
This function is also referred to as a squashing function, since it maps a large input domain onto the smaller range
CHAPTER 7. CLASSIFICATION AND PREDICTION
22
Algorithm 7.5.1 (Backpropagation) Neural network learning for classication, using the backpropagation algorithm.
Input: The training samples, samples; the learning rate, l; a multilayer feed-forward network, network.
Output: A neural network trained to classify the samples.
Method:
1) Initialize all weights and biases in network;
2) while terminating condition is not satised f
3) for each training sample X in samples f
4)
// Propagate the inputs forward:
5)
for each hidden or output layer unit j
6)
Ij =
i wij Oi + j ; //compute the net input of unit j
7)
for each hidden or output layer unit j
1
8)
Oj =
1+e,Ij ; // compute the output of each unit j
9)
// Backpropagate the errors:
10)
for each unit j in the output layer
11)
Errj = Oj (1 , Oj )(Tj , Oj ); // compute the error
12)
for each unit j in the hidden layers
13)
Errj = Oj (1 , Oj ) k Errk wjk ; // compute the error
14)
for each weight wij in network f
15)
wij = (l)Errj Oi ; // weight increment
16)
wij = wij + wij ; g // weight update
17)
for each bias j in network f
18)
j = (l)Errj ; // bias increment
19)
j = j + j ; g // bias update
20)
gg
P
P
2
Figure 7.10: Backpropagation algorithm.
of 0 to 1. The logistic function is nonlinear and dierentiable, allowing the backpropagation algorithm to model
classication problems that are linearly inseparable.
Backpropagate the error. The error is propagated backwards by updating the weights and biases to reect the
error of the network's prediction. For a unit j in the output layer, the error Errj is computed by:
Errj = Oj (1 , Oj )(Tj , Oj )
(7.13)
where Oj is the actual output of unit j, and Tj is the true output, based on the known class label of the given
training sample. Note that Oj (1 , Oj ) is the derivative of the logistic function.
To compute the error of a hidden layer unit j, the weighted sum of the errors of the units connected to unit j in
the next layer are considered. The error of a hidden layer unit j is:
Errj = Oj (1 , Oj )
X Err w
k
k jk
(7.14)
where wjk is the weight of the connection from unit j to a unit k in the next higher layer, and Errk is the error of
unit k.
The weights and biases are updated to reect the propagated errors. Weights are updated by Equations (7.15)
and (7.16) below, where wij is the change in weight wij .
wij = (l)Errj Oi
(7.15)
7.5. CLASSIFICATION BY BACKPROPAGATION
23
weights
w_0
bias
x_0
w_1
x_1
f
output
w_n
x_n
input
weighted
activation
vector X
sum
function
Figure 7.11: A hidden or output layer unit: The inputs are multiplied by their corresponding weights in order to
form a weighted sum, which is added to the bias associated with the unit. A nonlinear activation function is applied
to the net input.
wij = wij + wij
(7.16)
\What is the `l' in Equation 7.15?" The variable l is the learning rate, a constant typically having a value
between 0 and 1:0. Backpropagation learns using a method of gradient descent to search for a set of weights which
can model the given classication problem so as to minimize the mean squared distance between the network's class
predictions and the actual class label of the samples. The learning rate helps to avoid getting stuck at a local
minimum in decision space (i.e., where the weights appear to converge, but are not the optimum solution), and
encourages nding the global minimum. If the learning rate is too small, then learning will occur at a very slow
pace. If the learning rate is too large, then oscillation between inadequate solutions may occur. A rule of thumb is
to set the learning rate to 1=t, where t is the number of iterations through the training set so far.
Biases are updated by Equations (7.17) and (7.18) below, where j is the change in bias j .
j = (l)Errj
(7.17)
j = j + j
(7.18)
Note that here we are updating the weights and biases after the presentation of each sample. This is referred
to as case updating. Alternatively, the weight and bias increments could be accumulated in variables, so that the
weights and biases are updated after all of the samples in the training set have been presented. This latter strategy
is called epoch updating, where one iteration through the training set is an epoch. In theory, the mathematical
derivation of backpropagation employs epoch updating, yet in practice, case updating is more common since it tends
to yield more accurate results.
Terminating condition. Training stops when either
1. all wij in the previous epoch were so small as to be below some specied threshold, or
2. the percentage of samples misclassied in the previous epoch is below some threshold, or
3. a prespecied number of epochs has expired.
In practice, several hundreds of thousands of epochs may be required before the weights will converge.
CHAPTER 7. CLASSIFICATION AND PREDICTION
24
x_1
1
w_14
w_15
4
w_46
w_24
x_2
6
2
w_25
w_56
w_34
x_3
3
5
w_35
Figure 7.12: An example of a multilayer feed-forward neural network.
Example 7.5 Sample calculations for learning by the backpropagation algorithm. Figure 7.12 shows a
multilayer feed-forward neural network. The initial weight and bias values of the network are given in Table 7.3,
along with the rst training sample, X = (1; 0; 1).
x1 x2 x3 w14 w15 w24 w25 w34 w35 w46 w56 4 5 6
1 0 1 0.2 -0.3 0.4 0.1 -0.5 0.2 -0.3 -0.2 -0.4 0.2 0.1
Table 7.3: Initial input, weight, and bias values.
This example shows the calculations for backpropagation, given the rst training sample, X. The sample is fed
into the network, and the net input and output of each unit are computed. These values are shown in Table 7.4.
Unit j
4
5
6
Net Input, Ij
0:2 + 0 , 0:5 , 0:4 = ,0:7
,0:3 + 0 + 0:2 + 0:2 = 0:1
(0:3)(0:33) , (0:2)(0:52) + 0:1 , 0:19
Output, Oj
1=(1 + e0:7) = 0:33
1=(1 + e,0:1) = 0:52
1=(1 + e,0:19) = 0:55
Table 7.4: The net input and output calculations.
The error of each unit is computed and propagated backwards. The error values are shown in Table 7.5. The weight
and bias updates are shown in Table 7.6.
2
Several variations and alternatives to the backpropagation algorithm have been proposed for classication in
neural networks. These may involve the dynamic adjustment of the network topology, and of the learning rate or
other parameters, or the use of dierent error functions.
7.5.4 Backpropagation and interpretability
\How can I `understand' what the backpropgation network has learned?"
A major disadvantage of neural networks lies in their knowledge representation. Acquired knowledge in the form of
a network of units connected by weighted links is dicult for humans to interpret. This factor has motivated research
7.6. ASSOCIATION-BASED CLASSIFICATION
Unit j
6
5
4
25
Errj
(0:55)(1 , 0:55)(1 , 0:55) = 0:495
(0:52)(1 , 0:52)(0:495)(,0:3) = 0:037
(0:33)(1 , 0:33)(0:495)(,0:2) = ,0:022
Table 7.5: Calculation of the error at each node.
Weight or Bias
w46
w56
w14
w15
w24
w25
w34
w35
6
5
4
New Value
,0:3 = (0:9)(0:495)(0:33) = ,0:153
,0:2 = (0:9)(0:495)(0:52) = ,0:032
0:2 = (0:9)(,0:022)(1) = 0:180
,0:3 = (0:9)(0:037)(1) = ,0:267
0:4 = (0:9)(,0:022)(0) = 0:4
0:1 = (0:9)(0:037)(0) = 0:1
,0:5 = (0:9)(,0:022)(1) = ,0:520
0:2 = (0:9)(0:037)(1) = 0:233
0:1 + (0:9)(0:495) = 0:546
0:2 + (0:9)(0:037) = 0:233
,0:4 + (0:9)(,0:022) = ,0:420
Table 7.6: Calculations for weight and bias updating.
in extracting the knowledge embedded in trained neural networks and in representing that knowledge symbolically.
Methods include extracting rules from networks and sensitivity analysis.
Various algorithms for the extraction of rules have been proposed. The methods typically impose restrictions
regarding procedures used in training the given neural network, the network topology, and the discretization of input
values.
Fully connected networks are dicult to articulate. Hence, often, the rst step towards extracting rules from
neural networks is network pruning. This consists of removing weighted links that do not result in a decrease in
the classication accuracy of the given network.
Once the trained network has been pruned, some approaches will then perform link, unit, or activation value
clustering. In one method, for example, clustering is used to nd the set of common activation values for each
hidden unit in a given trained two-layer neural network (Figure 7.13). The combinations of these activation values
for each hidden unit are analyzed. Rules are derived relating combinations of activation values with corresponding
output unit values. Similarly, the sets of input values and activation values are studied to derive rules describing
the relationship between the input and hidden unit layers. Finally, the two sets of rules may be combined to form
IF-THEN rules. Other algorithms may derive rules of other forms, including M-of-N rules (where M out of a given
N conditions in the rule antecedent must be true in order for the rule consequent to be applied), decision trees with
M-of-N tests, fuzzy rules, and nite automata.
Sensitivity analysis is used to assess the impact that a given input variable has on a network output. The
input to the variable is varied while the remaining input variables are xed at some value. Meanwhile, changes in
the network output are monitored. The knowledge gained from this form of analysis can be represented in rules such
as \IF X decreases 5% THEN Y increases 8%".
7.6 Association-based classication
\Can association rule mining be used for classication?"
Association rule mining is an important and highly active area of data mining research. Chapter 6 of this book
described many algorithms for association rule mining. Recently, data mining techniques have been developed which
apply association rule mining to the problem of classication. In this section, we study such association-based
CHAPTER 7. CLASSIFICATION AND PREDICTION
26
Identify sets of common activation values for each hidden node, H_i:
for H_1: (-1,0,1)
for H_2:
O_1
O_2
(0,1)
for H_3: (-1, 0.24, 1)
H_1
H_2
H_3
Derive rules relating common activation values with output nodes, O_j:
IF (a_2 = 0 AND a_3 = -1) OR
I_1
I_2
I_3
I_4
I_5
I_6
I_7
(a_1 = -1 AND a_2 = 1 AND a_3 = -1) OR
(a_1 = -1 AND a_2 = 0 AND a_3 = 0.24)
THEN O_1 = 1, O_2 = 0
ELSE O_1 = 0, O_2 = 1
Derive rules relating input nodes, I_i, to output nodes, O_j:
IF (I_2 = 0 AND I_7 = 0) THEN a_2 = 0
IF (I_4 = 1 AND I_6 = 1) THEN a_3 = -1
IF (I_5 = 0) THEN a_3 = -1
...
Obtain rules relating inputs and output classes:
IF (I_2 = 0 AND I_7 = 0 AND I_4 = 1 AND I_6 = 1) THEN class = 1
IF (I_2 = 0 AND I_7 = 0 AND I_5 = 0) THEN class = 1
Figure 7.13: Rules can be extracted from training neural networks.
classication.
One method of association-based classication, called associative classication, consists of two steps. In the
rst step, association rules are generated using a modied version of the standard association rule mining algorithm
known as Apriori. The second step constructs a classier based on the association rules discovered.
Let D be the training data, and Y be the set of all classes in D. The algorithm maps categorical attributes to
consecutive positive integers. Continuous attributes are discretized and mapped accordingly. Each data sample d in
D then is represented by a set of (attribute, integer-value) pairs called items, and a class label y. Let I be the set
of all items in D. A class association rule (CAR) is of the form condset ) y, where condset is a set of items
(condset I) and y 2 Y . Such rules can be represented by ruleitems of the form <condset, y>.
A CAR has condence c if c% of the samples in D that contain condset belong to class y. A CAR has support s if
s% of the samples in D contain condset and belong to class y. The support count of a condset (condsupCount) is
the number of samples in D that contain the condset. The rule count of a ruleitem (rulesupCount) is the number
of samples in D that contain the condset and are labeled with class y. Ruleitems that satisfy minimum support are
frequent ruleitems. If a set of ruleitems has the same condset, then the rule with the highest condence is selected
as the possible rule (PR) to represent the set. A rule satisfying minimum condence is called accurate.
\How does associative classication work?"
The rst step of the associative classication method nds the set of all PRs that are both frequent and accurate.
These are the class association rules (CARs). A ruleitem whose condset contains k items is a k-ruleitem. The
algorithm employs an iterative approach, similar to that described for Apriori in Section 5.2.1, where ruleitems
are processed rather than itemsets. The algorithm scans the database, searching for the frequent k-ruleitems, for
k = 1; 2; ::, until all frequent k-ruleitems have been found. One scan is made for each value of k. The k-ruleitems are
used to explore (k+1)-ruleitems. In the rst scan of the database, the count support of 1-ruleitems is determined,
and the frequent 1-ruleitems are retained. The frequent 1-ruleitems, referred to as the set F1 , are used to generate
candidate 2-ruleitems, C2 . Knowledge of frequent ruleitem properties is used to prune candidate ruleitems that
cannot be frequent. This knowledge states that all non-empty subsets of a frequent ruleitem must also be frequent.
The database is scanned a second time to compute the support counts of each candidate, so that the frequent 2ruleitems (F2) can be determined. This process repeats, where Fk is used to generate Ck+1, until no more frequent
ruleitems are found. The frequent ruleitems that satisfy minimum condence form the set of CARs. Pruning may
be applied to this rule set.
7.7. OTHER CLASSIFICATION METHODS
27
The second step of the associative classication method processes the generated CARs in order to construct the
classier. Since the total number of rule subsets that would be examined in order to determine the most accurate
set of rules can be huge, a heuristic method is employed. A precedence ordering among rules is dened where a
rule ri has greater precedence over a rule rj (i.e., ri rj ) if (1) the condence of ri is greater than that of rj , or
(2) the condences are the same, but ri has greater support, or (3) the condences and supports of ri and rj are
the same, but ri is generated earlier than rj . In general, the algorithm selects a set of high precedence CARs to
cover the samples in D. The algorithm requires slightly more than one pass over D in order to determine the nal
classier. The classier maintains the selected rules from high to low precedence order. When classifying a new
sample, the rst rule satisfying the sample is used to classify it. The classier also contains a default rule, having
lowest precedence, which species a default class for any new sample that is not satised by any other rule in the
classier.
In general, the above associative classication method was empirically found to be more accurate than C4.5 on
several data sets. Each of the above two steps was shown to have linear scale-up.
Association rule mining based on clustering has also been applied to classication. The ARCS, or Association
Rule Clustering System (Section 6.4.3) mines association rules of the form Aquan1 ^ Aquan2 ) Acat, where Aquan1 and
Aquan2 are tests on quantitative attribute ranges (where the ranges are dynamically determined), and Acat assigns a
class label for a categorical attribute from the given training data. Association rules are plotted on a 2-D grid. The
algorithm scans the grid, searching for rectangular clusters of rules. In this way, adjacent ranges of the quantitative
attributes occurring within a rule cluster may be combined. The clustered association rules generated by ARCS
were applied to classication, and their accuracy was compared to C4.5. In general, ARCS is slightly more accurate
when there are outliers in the data. The accuracy of ARCS is related to the degree of discretization used. In terms
of scalability, ARCS requires a constant amount of memory, regardless of the database size. C4.5 has exponentially
higher execution times than ARCS, requiring the entire database, multiplied by some factor, to t entirely in main
memory. Hence, association rule mining is an important strategy for generating accurate and scalable classiers.
7.7 Other classication methods
In this section, we give a brief description of a number of other classication methods. These methods include
k-nearest neighbor classication, case-based reasoning, genetic algorithms, rough set and fuzzy set approaches. In
general, these methods are less commonly used for classication in commercial data mining systems than the methods
described earlier in this chapter. Nearest-neighbor classication, for example, stores all training samples, which may
present diculties when learning from very large data sets. Furthermore, many applications of case-based reasoning,
genetic algorithms, and rough sets for classication are still in the prototype phase. These methods, however, are
enjoying increasing popularity, and hence we include them here.
7.7.1
k
-nearest neighbor classiers
Nearest neighbor classiers are based on learning by analogy. The training samples are described by n-dimensional
numeric attributes. Each sample represents a point in an n-dimensional space. In this way, all of the training samples
are stored in an n-dimensional pattern space. When given an unknown sample, a k-nearest neighbor classier
searches the pattern space for the k training samples that are closest to the unknown sample. These k training
samples are the k \nearest neighbors" of the unknown sample. \Closeness" is dened in terms of Euclidean distance,
where the Euclidean distance between two points, X = (x1 ; x2; :::; xn) and Y = (y1 ; y2; :::; yn) is:
v
u
uXn
d(X; Y ) = t (xi , yi ) :
2
i=1
(7.19)
The unknown sample is assigned the most common class among its k nearest neighbors. When k = 1, the
unknown sample is assigned the class of the training sample that is closest to it in pattern space.
Nearest neighbor classiers are instance-based since they store all of the training samples. They can incur
expensive computational costs when the number of potential neighbors (i.e., stored training samples) with which to
compare a given unlabeled sample is great. Therefore, ecient indexing techniques are required. Unlike decision tree
28
CHAPTER 7. CLASSIFICATION AND PREDICTION
induction and backpropagation, nearest neighbor classiers assign equal weight to each attribute. This may cause
confusion when there are many irrelevant attributes in the data.
Nearest neighbor classiers can also be used for prediction, i.e., to return a real-valued prediction for a given
unknown sample. In this case, the classier returns the average value of the real-valued labels associated with the k
nearest neighbors of the unknown sample.
7.7.2 Case-based reasoning
Case-based reasoning (CBR) classiers are instanced-based. Unlike nearest neighbor classiers, which store train-
ing samples as points in Euclidean space, the samples or \cases" stored by CBR are complex symbolic descriptions.
Business applications of CBR include problem resolution for customer service help desks, for example, where cases
describe product-related diagnostic problems. CBR has also been applied to areas such as engineering and law, where
cases are either technical designs or legal rulings, respectively.
When given a new case to classify, a case-based reasoner will rst check if an identical training case exists. If one
is found, then the accompanying solution to that case is returned. If no identical case is found, then the case-based
reasoner will search for training cases having components that are similar to those of the new case. Conceptually,
these training cases may be considered as neighbors of the new case. If cases are represented as graphs, this involves
searching for subgraphs which are similar to subgraphs within the new case. The case-based reasoner tries to combine
the solutions of the neighboring training cases in order to propose a solution for the new case. If incompatibilities
arise with the individual solutions, then backtracking to search for other solutions may be necessary. The case-based
reasoner may employ background knowledge and problem-solving strategies in order to propose a feasible combined
solution.
Challenges in case-based reasoning include nding a good similarity metric (e.g., for matching subgraphs), developing ecient techniques for indexing training cases, and methods for combining solutions.
7.7.3 Genetic algorithms
Genetic algorithms attempt to incorporate ideas of natural evolution. In general, genetic learning starts as follows.
An initial population is created consisting of randomly generated rules. Each rule can be represented by a string
of bits. As a simple example, suppose that samples in a given training set are described by two Boolean attributes,
A1 and A2, and that there are two classes, C1 and C2. The rule \IF A1 and not A2 THEN C2 " can be encoded as
the bit string \100", where the two leftmost bits represent attributes A1 and A2 , respectively, and the rightmost bit
represents the class. Similarly, the rule \if not A1 and not A2 then C1 " can be encoded as \001". If an attribute has
k values where k > 2, then k bits may be used to encode the attribute's values. Classes can be encoded in a similar
fashion.
Based on the notion of survival of the ttest, a new population is formed to consist of the ttest rules in the
current population, as well as ospring of these rules. Typically, the tness of a rule is assessed by its classication
accuracy on a set of training samples.
Ospring are created by applying genetic operators such as crossover and mutation. In crossover, substrings
from pairs of rules are swapped to form new pairs of rules. In mutation, randomly selected bits in a rule's string
are inverted.
The process of generating new populations based on prior populations of rules continues until a population P
\evolves" where each rule in P satises a prespecied tness threshold.
Genetic algorithms are easily parallelizable and have been used for classication as well as other optimization
problems. In data mining, they may be used to evaluate the tness of other algorithms.
7.7.4 Rough set theory
Rough set theory can be used for classication to discover structural relationships within imprecise or noisy data. It
applies to discrete-valued attributes. Continuous-valued attributes must therefore be discretized prior to its use.
Rough set theory is based on the establishment of equivalence classes within the given training data. All of
the data samples forming an equivalence class are indiscernible, that is, the samples are identical with respect to
the attributes describing the data. Given real-world data, it is common that some classes cannot be distinguished
7.7. OTHER CLASSIFICATION METHODS
29
C
upper approximation of C
lower approximation of C
Figure 7.14: A rough set approximation of the set of samples of the class C using lower and upper approximation
sets of C. The rectangular regions represent equivalence classes.
in terms of the available attributes. Rough sets can be used to approximately or \roughly" dene such classes.
A rough set denition for a given class C is approximated by two sets - a lower approximation of C and an
upper approximation of C. The lower approximation of C consists of all of the data samples which, based on the
knowledge of the attributes, are certain to belong to C without ambiguity. The upper approximation of C consists of
all of the samples which, based on the knowledge of the attributes, cannot be described as not belonging to C. The
lower and upper approximations for a class C are shown in Figure 7.14, where each rectangular region represents an
equivalence class. Decision rules can be generated for each class. Typically, a decision table is used to represent the
rules.
Rough sets can also be used for feature reduction (where attributes that do not contribute towards the classication of the given training data can be identied and removed), and relevance analysis (where the contribution or
signicance of each attribute is assessed with respect to the classication task). The problem of nding the minimal
subsets (reducts) of attributes that can describe all of the concepts in the given data set is NP-hard. However,
algorithms to reduce the computation intensity have been proposed. In one method, for example, a discernibility
matrix is used which stores the dierences between attribute values for each pair of data samples. Rather than
searching on the entire training set, the matrix is instead searched to detect redundant attributes.
7.7.5 Fuzzy set approaches
Rule-based systems for classication have the disadvantage that they involve sharp cut-os for continuous attributes.
For example, consider Rule (7.20) below for customer credit application approval. The rule essentially says that
applications for customers who have had a job for two or more years, and who have a high income (i.e., of more than
$50K) are approved.
(7.20)
IF (years employed >= 2) ^ (income 50K) THEN credit = approved:
By Rule (7.20), a customer who has had a job for at least 2 years will receive credit if her income is, say, $51K, but
not if it is $50K. Such harsh thresholding may seem unfair. Instead, fuzzy logic can be introduced into the system
to allow \fuzzy" thresholds or boundaries to be dened. Rather than having a precise cuto between categories or
sets, fuzzy logic uses truth values between 0:0 and 1:0 to represent the degree of membership that a certain value has
in a given category. Hence, with fuzzy logic, we can capture the notion that an income of $50K is, to some degree,
high, although not as high as an income of $51K.
Fuzzy logic is useful for data mining systems performing classication. It provides the advantage of working at a
high level of abstraction. In general, the use of fuzzy logic in rule-based systems involves the following:
Attribute values are converted to fuzzy values. Figure 7.15 shows how values for the continuous attribute
income are mapped into the discrete categories flow, medium, highg, as well as how the fuzzy membership or
truth values are calculated. Fuzzy logic systems typically provide graphical tools to assist users in this step.
For a given new sample, more than one fuzzy rule may apply. Each applicable rule contributes a vote for
membership in the categories. Typically, the truth values for each predicted category are summed.
CHAPTER 7. CLASSIFICATION AND PREDICTION
30
fuzzy
membership
1.0
_
0.5
-
low
medium
high
somewhat
low
|
10K
|
20K
borderline
high
|
30K
|
40K
|
50K
|
60K
|
70K
income
Figure 7.15: Fuzzy values for income.
The sums obtained above are combined into a value that is returned by the system. This process may be done
by weighting each category by its truth sum and multiplying by the mean truth value of each category. The
calculations involved may be more complex, depending on the complexity of the fuzzy membership graphs.
Fuzzy logic systems have been used in numerous areas for classication, including health care and nance.
7.8 Prediction
\What if we would like to predict a continuous value, rather than a categorical label?"
The prediction of continuous values can be modeled by statistical techniques of regression. For example, we may
like to develop a model to predict the salary of college graduates with 10 years of work experience, or the potential
sales of a new product given its price. Many problems can be solved by linear regression, and even more can be
tackled by applying transformations to the variables so that a nonlinear problem can be converted to a linear one. For
reasons of space, we cannot give a fully detailed treatment of regression. Instead, this section provides an intuitive
introduction to the topic. By the end of this section, you will be familiar with the ideas of linear, multiple, and
nonlinear regression, as well as generalized linear models.
Several software packages exist to solve regression problems. Examples include SAS (http://www.sas.com), SPSS
(http://www.spss.com), and S-Plus (http://www.mathsoft.com).
7.8.1 Linear and multiple regression
\What is linear regression?"
In linear regression, data are modeled using a straight line. Linear regression is the simplest form of regression.
Bivariate linear regression models a random variable, Y (called a response variable), as a linear function of another
random variable, X (called a predictor variable), i.e.,
Y = + X;
(7.21)
where the variance of Y is assumed to be constant, and and are regression coecients specifying the Yintercept and slope of the line, respectively. These coecients can be solved for by the method of least squares,
which minimizes the error between the actual line separating the data and the estimate of the line. Given s samples
or data points of the form (x1 ; y1), (x2 ; y2), .., (xs ; ys), then the regression coecients can be estimated using this
method with Equations (7.22) and (7.23),
Psi (xi , x)(yi , y)
= Ps
;
(xi , x)
=1
i=1
2
(7.22)
7.8. PREDICTION
31
= y , x;
(7.23)
where x is the average of x1; x2; ::; xs, and y is the average of y1 ; y2 ; ::; ys. The coecients and often provide
good approximations to otherwise complicated regression equations.
X
Y
3
8
9
13
3
6
11
21
1
16
30
57
64
72
36
43
59
90
20
83
years experience salary (in $1000)
Table 7.7: Salary data.
100
Salary (in $1000)
80
60
40
20
0
0
5
10
15
Years experience
20
25
Figure 7.16: Plot of the data in Table 7.7 for Example 7.6. Although the points do not fall on a straight line, the
overall pattern suggests a linear relationship between X (years experience) and Y (salary).
Example 7.6 Linear regression using the method of least squares. Table 7.7 shows a set of paired data
where X is the number of years of work experience of a college graduate and Y is the corresponding salary of the
graduate. A plot of the data is shown in Figure 7.16, suggesting a linear relationship between the two variables, X
and Y . We model the relationship that salary may be related to the number of years of work experience with the
equation Y = + X.
Given the above data, we compute x = 9:1 and y = 55:4. Substituting these values into Equation (7.22), we get
,9:1)(57,55:4)+:::+(16,9:1)(83,55:4) = 3:7
= (3,9:1)(30,55(3:,4)+(8
9:1) +(8,9:1) +:::+(16,9:1)
= 55:4 , (3:7)(9:1) = 21:7
Thus, the equation of the least squares line is estimated by Y = 21:7 + 3:7X. Using this equation, we can predict
that the salary of a college graduate with, say, 10 years of experience is $58.7K.
2
Multiple regression is an extension of linear regression involving more than one predictor variable. It allows
response variable Y to be modeled as a linear function of a multidimensional feature vector. An example of a multiple
regression model based on two predictor attributes or variables, X1 and X2 , is shown in Equation (7.24).
2
2
2
CHAPTER 7. CLASSIFICATION AND PREDICTION
32
Y = + 1 X1 + 2 X2
The method of least squares can also be applied here to solve for , 1 , and 2 .
(7.24)
7.8.2 Nonlinear regression
\How can we model data that does not show a linear dependence? For example, what if a given response variable
and predictor variables have a relationship that may be modeled by a polynomial function?"
Polynomial regression can be modeled by adding polynomial terms to the basic linear model. By applying
transformations to the variables, we can convert the nonlinear model into a linear one that can then be solved by
the method of least squares.
Example 7.7 Transformation of a polynomial regression model to a linear regression model. Consider
a cubic polynomial relationship given by Equation (7.25).
Y = + 1 X + 2 X 2 + 3 X 3
(7.25)
To convert this equation to linear form, we dene new variables as shown in Equation (7.26).
X1 = X
X2 = X 2
X3 = X 3
(7.26)
Equation (7.25) can then be converted to linear form by applying the above assignments, resulting in the equation
Y = + 1 X1 + 2 X2 + 3 X3 , which is solvable by the method of least squares.
2
In Exercise 7, you are asked to nd the transformations required to convert a nonlinear model involving a power
function into a linear regression model.
Some models are intractably nonlinear (such as the sum of exponential terms, for example) and cannot be
converted to a linear model. For such cases, it may be possible to obtain least-square estimates through extensive
calculations on more complex formulae.
7.8.3 Other regression models
Linear regression is used to model continuous-valued functions. It is widely used, owing largely to its simplicity.
\Can it also be used to predict categorical labels?" Generalized linear models represent the theoretical foundation
on which linear regression can be applied to the modeling of categorical response variables. In generalized linear
models, the variance of the response variable Y is a function of the mean value of Y , unlike in linear regression,
where the variance of Y is constant. Common types of generalized linear models include logistic regression and
Poisson regression. Logistic regression models the probability of some event occurring as a linear function of a
set of predictor variables. Count data frequently exhibit a Poisson distribution and are commonly modeled using
Poisson regression.
Log-linear models approximate discrete multidimensional probability distributions. They may be used to
estimate the probability value associated with data cube cells. For example, suppose we are given data for the
attributes city, item, year, and sales. In the log-linear method, all attributes must be categorical, hence continuousvalued attributes (like sales) must rst be discretized. The method can then be used to estimate the probability of
each cell in the 4-D base cuboid for the given attributes, based on the 2-D cuboids for city and item, city and year,
city and sales, and the 3-D cuboid for item, year, and sales. In this way, an iterative technique can be used to build
higher order data cubes from lower order ones. The technique scales up well to allow for many dimensions. Aside
from prediction, the log-linear model is useful for data compression (since the smaller order cuboids together typically
occupy less space than the base cuboid) and data smoothing (since cell estimates in the smaller order cuboids are
less subject to sampling variations than cell estimates in the base cuboid).
7.9. CLASSIFIER ACCURACY
33
training
derive
estimate
set
classifier
accuracy
data
test set
Figure 7.17: Estimating classier accuracy with the holdout method.
7.9 Classier accuracy
Estimating classier accuracy is important in that it allows one to evaluate how accurately a given classier will
correctly label future data, i.e., data on which the classier has not been trained. For example, if data from previous
sales are used to train a classier to predict customer purchasing behavior, we would like some estimate of how
accurately the classier can predict the purchasing behavior of future customers. Accuracy estimates also help in
the comparison of dierent classiers. In Section 7.9.1, we discuss techniques for estimating classier accuracy, such
as the holdout and k-fold cross-validation methods. Section 7.9.2 describes bagging and boosting, two strategies for
increasing classier accuracy. Section 7.9.3 discusses additional issues relating to classier selection.
7.9.1 Estimating classier accuracy
Using training data to derive a classier and then to estimate the accuracy of the classier can result in misleading
over-optimistic estimates due to overspecialization of the learning algorithm (or model) to the data. Holdout and
cross-validation are two common techniques for assessing classier accuracy, based on randomly-sampled partitions
of the given data.
In the holdout method, the given data are randomly partitioned into two independent sets, a training set and a
test set. Typically, two thirds of the data are allocated to the training set, and the remaining one third is allocated
to the test set. The training set is used to derive the classier, whose accuracy is estimated with the test set
(Figure 7.17). The estimate is pessimistic since only a portion of the initial data is used to derive the classier.
Random subsampling is a variation of the holdout method in which the holdout method is repeated k times. The
overall accuracy estimate is taken as the average of the accuracies obtained from each iteration.
In k-fold cross validation, the initial data are randomly partitioned into k mutually exclusive subsets or \folds",
S1 ; S2 ; :::; Sk, each of approximately equal size. Training and testing is performed k times. In iteration i, the subset
Si is reserved as the test set, and the remaining subsets are collectively used to train the classier. That is, the
classier of the rst iteration is trained on subsets S2 ; ::; Sk, and tested on S1 ; the classier of the section iteration
is trained on subsets S1 ; S3 ; ::; Sk, and tested on S2 ; and so on. The accuracy estimate is the overall number of
correct classications from the k iterations, divided by the total number of samples in the initial data. In stratied
cross-validation, the folds are stratied so that the class distribution of the samples in each fold is approximately
the same as that in the initial data.
Other methods of estimating classier accuracy include bootstrapping, which samples the given training instances uniformly with replacement, and leave-one-out, which is k-fold cross validation with k set to s, the number
of initial samples. In general, stratied 10-fold cross-validation is recommended for estimating classier accuracy
(even if computation power allows using more folds) due to its relatively low bias and variance.
The use of such techniques to estimate classier accuracy increases the overall computation time, yet is useful for
selecting among several classiers.
CHAPTER 7. CLASSIFICATION AND PREDICTION
34
C_1
new data
sample
C_2
data
.
combine
class
votes
prediction
.
C_T
Figure 7.18: Increasing classier accuracy: Bagging and boosting each generate a set of classiers, C1; C2; ::; CT .
Voting strategies are used to combine the class predictions for a given unknown sample.
7.9.2 Increasing classier accuracy
In the previous section, we studied methods of estimating classier accuracy. In Section 7.3.2, we saw how pruning
can be applied to decision tree induction to help improve the accuracy of the resulting decision trees. Are there
general techniques for improving classier accuracy?
The answer is yes. Bagging (or boostrap aggregation) and boosting are two such techniques (Figure 7.18). Each
combines a series of T learned classiers, C1; C2; ::; CT , with the aim of creating an improved composite classier,
C .
\How do these methods work?" Suppose that you are a patient and would like to have a diagnosis made based
on your symptoms. Instead of asking one doctor, you may choose to ask several. If a certain diagnosis occurs more
than the others, you may choose this as the nal or best diagnosis. Now replace each doctor by a classier, and you
have the intuition behind bagging. Suppose instead, that you assign weights to the \value" or worth of each doctor's
diagnosis, based on the accuracies of previous diagnoses they have made. The nal diagnosis is then a combination
of the weighted diagnoses. This is the essence behind boosting. Let us have a closer look at these two techniques.
Given a set S of s samples, bagging works as follows. For iteration t (t = 1; 2; ::; T ), a training set St is sampled
with replacement from the original set of samples, S. Since sampling with replacement is used, some of the original
samples of S may not be included in St , while others may occur more than once. A classier Ct is learned for each
training set, St . To classify an unknown sample, X, each classier Ct returns its class prediction, which counts as
one vote. The bagged classier, C , counts the votes and assigns the class with the most votes to X. Bagging can
be applied to the prediction of continuous values by taking the average value of each vote, rather than the majority.
In boosting, weights are assigned to each training sample. A series of classiers is learned. After a classier
Ct is learned, the weights are updated to allow the subsequent classier, Ct+1, to \pay more attention" to the
misclassication errors made by Ct. The nal boosted classier, C , combines the votes of each individual classier,
where the weight of each classier's vote is a function of its accuracy. The boosting algorithm can be extended for
the prediction of continuous values.
7.9.3 Is accuracy enough to judge a classier?
In addition to accuracy, classiers can be compared with respect to their speed, robustness (e.g., accuracy on noisy
data), scalability, and interpretability. Scalability can be evaluated by assessing the number of I/O operations
involved for a given classication algorithm on data sets of increasingly large size. Interpretability is subjective,
although we may use objective measurements such as the complexity of the resulting classier (e.g., number of tree
nodes for decision trees, or number of hidden units for neural networks, etc.) in assessing it.
\Is it always possible to assess accuracy?" In classication problems, it is commonly assumed that all objects
are uniquely classiable, i.e., that each training sample can belong to only one class. As we have discussed above,
classication algorithms can then be compared according to their accuracy. However, owing to the wide diversity
7.10. SUMMARY
35
of data in large databases, it is not always reasonable to assume that all objects are uniquely classiable. Rather,
it is more probable to assume that each object may belong to more than one class. How then, can the accuracy
of classiers on large databases be measured? The accuracy measure is not appropriate, since it does not take into
account the possibility of samples belonging to more than one class.
Rather than returning a class label, it is useful to return a probability class distribution. Accuracy measures
may then use a second guess heuristic whereby a class prediction is judged as correct if it agrees with the rst or
second most probable class. Although this does take into consideration, in some degree, the non-unique classication
of objects, it is not a complete solution.
7.10 Summary
Classication and prediction are two forms of data analysis which can be used to extract models describing important data classes or to predict future data trends. While classication predicts categorical labels (classes),
prediction models continuous-valued functions.
Preprocessing of the data in preparation for classication and prediction can involve data cleaning to reduce
noise or handle missing values, relevance analysis to remove irrelevant or redundant attributes, and data
transformation, such as generalizing the data to higher level concepts, or normalizing the data.
Predictive accuracy, computational speed, robustness, scalability, and interpretability are ve criteria for the
evaluation of classication and prediction methods.
ID3 and C4.5 are greedy algorithms for the induction of decision trees. Each algorithm uses an information
theoretic measure to select the attribute tested for each non-leaf node in the tree. Pruning algorithms attempt
to improve accuracy by removing tree branches reecting noise in the data. Early decision tree algorithms
typically assume that the data are memory resident - a limitation to data mining on large databases. Since then,
several scalable algorithms have been proposed to address this issue, such as SLIQ, SPRINT, and RainForest.
Decision trees can easily be converted to classication IF-THEN rules.
Naive Bayesian classication and Bayesian belief networks are based on Bayes theorem of posterior
probability. Unlike naive Bayesian classication (which assumes class conditional independence), Bayesian
belief networks allow class conditional independencies to be dened between subsets of variables.
Backpropagation is a neural network algorithm for classication which employs a method of gradient descent.
It searches for a set of weights which can model the data so as to minimize the mean squared distance between
the network's class prediction and the actual class label of data samples. Rules may be extracted from trained
neural networks in order to help improve the interpretability of the learned network.
Association mining techniques, which search for frequently occurring patterns in large databases, can be
applied to and used for classication.
Nearest neighbor classiers and cased-based reasoning classiers are instance-based methods of classication
in that they store all of the training samples in pattern space. Hence, both require ecient indexing techniques.
In genetic algorithms, populations of rules \evolve" via operations of crossover and mutation until all rules
within a population satisfy a specied threshold. Rough set theory can be used to approximately dene
classes that are not distinguishable based on the available attributes. Fuzzy set approaches replace \brittle"
threshold cutos for continuous-valued attributes with degree of membership functions.
Linear, nonlinear, and generalized linear models of regression can be used for prediction. Many nonlinear
problems can be converted to linear problems by performing transformations on the predictor variables.
Data warehousing techniques, such as attribute-oriented induction and the use of multidimensional data cubes,
can be integrated with classication methods in order to allow fast multilevel mining. Classication tasks
may be specied using a data mining query language, promoting interactive data mining.
Stratied k-fold cross validation is a recommended method for estimating classier accuracy. Bagging
and boosting methods can be used to increase overall classication accuracy by learning and combining a
series of individual classiers.
CHAPTER 7. CLASSIFICATION AND PREDICTION
36
Exercises
1. Table 7.8 consists of training data from an employee database. The data have been generalized. For a given
row entry, count represents the number of data tuples having the values for department, status, age, and salary
given in that row.
department status age
sales
sales
sales
systems
systems
systems
systems
marketing
marketing
secretary
secretary
senior
junior
junior
junior
senior
junior
senior
senior
junior
senior
junior
31-35
26-30
31-35
21-25
31-35
26-30
41-45
36-40
31-35
46-50
26-30
salary
45-50K
25-30K
30-35K
45-50K
65-70K
45-50K
65-70K
45-50K
40-45K
35-40K
25-30K
count
30
40
40
20
5
3
3
10
4
4
6
Table 7.8: Generalized relation from an employee database.
2.
3.
4.
5.
6.
7.
Let salary be the class label attribute.
(a) How would you modify the ID3 algorithm to take into consideration the count of each data tuple (i.e., of
each row entry)?
(b) Use your modied version of ID3 to construct a decision tree from the given data.
(c) Given a data sample with the values \systems", \junior", and \20-24" for the attributes department,
status, and age, respectively, what would a naive Bayesian classication of the salary for the sample be?
(d) Design a multilayer feed-forward neural network for the given data. Label the nodes in the input and
output layers.
(e) Using the multilayer feed-forward neural network obtained above, show the weight values after one iteration
of the backpropagation algorithm given the training instance \(sales, senior, 31-35, 45-50K)". Indicate
your initial weight values and the learning rate used.
Write an algorithm for k-nearest neighbor classication given k, and n, the number of attributes describing
each sample.
What is a drawback of using a separate set of samples to evaluate pruning?
Given a decision tree, you have the option of (a) converting the decision tree to rules and then pruning the
resulting rules, or (b) pruning the decision tree and then converting the pruned tree to rules? What advantage
does (a) have over (b)?
ADD QUESTIONS ON OTHER CLASSIFICATION METHODS.
Table 7.9 shows the mid-term and nal exam grades obtained for students in a database course.
(a) Plot the data. Do X and Y seem to have a linear relationship?
(b) Use the method of least squares to nd an equation for the prediction of a student's nal exam grade
based on the student's mid-term grade in the course.
(c) Predict the nal exam grade of a student who received an 86 on the mid-term exam.
Some nonlinear regression models can be converted to linear models by applying transformations to the predictor
variables. Show how the nonlinear regression equation Y = X can be converted to a linear regression equation
solvable by the method of least squares.
7.10. SUMMARY
37
X
Y
72
50
81
74
94
86
59
83
65
33
88
81
84
63
77
78
90
75
49
79
77
52
74
90
mid-term exam nal exam
Table 7.9: Mid-term and nal exam grades.
8. It is dicult to assess classication accuracy when individual data objects may belong to more than one class
at a time. In such cases, comment on what criteria you would use to compare dierent classiers modeled after
the same data.
Bibliographic Notes
Classication from a machine learning perspective is described in several books, such as Weiss and Kulikowski
[136], Michie, Spiegelhalter, and Taylor [88], Langley [67], and Mitchell [91]. Weiss and Kulikowski [136] compare
classication and prediction methods from many dierent elds, in addition to describing practical techniques for
the evaluation of classier performance. Many of these books describe each of the basic methods of classication
discussed in this chapter. Edited collections containing seminal articles on machine learning can be found in Michalksi,
Carbonell, and Mitchell [85, 86], Kodrato and Michalski [63], Shavlik and Dietterich [123], and Michalski and Tecuci
[87]. For a presentation of machine learning with respect to data mining applications, see Michalski, Bratko, and
Kubat [84].
The C4.5 algorithm is described in a book by J. R. Quinlan [108]. The book gives an excellent presentation
of many of the issues regarding decision tree induction, as does a comprehensive survey on decision tree induction
by Murthy [94]. Other algorithms for decision tree induction include the predecessor of C4.5, ID3 (Quinlan [104]),
CART (Breiman et al. [11]), FACT (Loh and Vanichsetakul [76]), QUEST (Loh and Shih [75]), and PUBLIC (Rastogi
and Shim [111]). Incremental versions of ID3 include ID4 (Schlimmer and Fisher [120]) and ID5 (Utgo [132]). In
addition, INFERULE (Uthurusamy, Fayyad, and Spangler [133]) learns decision trees from inconclusive data. KATE
(Manago and Kodrato [80]) learns decision trees from complex structured data. Decision tree algorithms that
address the scalability issue in data mining include SLIQ (Mehta, Agrawal, and Rissanen [81]), SPRINT (Shafer,
Agrawal, and Mehta [121]), RainForest (Gehrke, Ramakrishnan, and Ganti [43]), and Kamber et al. [61]. Earlier
approaches described include [16, 17, 18]. For a comparison of attribute selection measures for decision tree induction,
see Buntine and Niblett [15], and Murthy [94]. For a detailed discussion on such measures, see Kononenko and Hong
[65].
There are numerous algorithms for decision tree pruning, including cost complexity pruning (Breiman et al. [11]),
reduced error pruning (Quinlan [105]), and pessimistic pruning (Quinlan [104]). PUBLIC (Rastogi and Shim [111])
integrates decision tree construction with tree pruning. MDL-based pruning methods can be found in Quinlan and
Rivest [110], Mehta, Agrawal, and Rissanen [82], and Rastogi and Shim [111]. Others methods include Niblett and
Bratko [96], and Hosking, Pednault, and Sudan [55]. For an empirical comparison of pruning methods, see Mingers
[89], and Malerba, Floriana, and Semeraro [79].
For the extraction of rules from decision trees, see Quinlan [105, 108]. Rather than generating rules by extracting
them from decision trees, it is also possible to induce rules directly from the training data. Rule induction algorithms
38
CHAPTER 7. CLASSIFICATION AND PREDICTION
include CN2 (Clark and Niblett [21]), AQ15 (Hong, Mozetic, and Michalski [54]), ITRULE (Smyth and Goodman
[126]), FOIL (Quinlan [107]), and Swap-1 (Weiss and Indurkhya [134]). Decision trees, however, tend to be superior
in terms of computation time and predictive accuracy. Rule renement strategies which identify the most interesting
rules among a given rule set can be found in Major and Mangano [78].
For descriptions of data warehousing and multidimensional data cubes, see Harinarayan, Rajaraman, and Ullman [48], and Berson and Smith [8], as well as Chapter 2 of this book. Attribution-oriented induction (AOI) is
presented in Han and Fu [45], and summarized in Chapter 5. The integration of AOI with decision tree induction is
proposed in Kamber et al. [61]. The precision or classication threshold described in Section 7.3.6 is used in Agrawal
et al. [2] and Kamber et al. [61].
Thorough presentations of Bayesian classication can be found in Duda and Hart [32], a classic textbook on
pattern recognition, as well as machine learning textbooks such as Weiss and Kulikowski [136] and Mitchell [91]. For
an analysis of the predictive power of naive Bayesian classiers when the class conditional independence assumption is
violated, see Domingosand Pazzani [31]. Experiments with kernel density estimation for continuous-valued attributes,
rather than Gaussian estimation have been reported for naive Bayesian classiers in John [59]. Algorithms for
inference on belief networks can be found in Russell and Norvig [118] and Jensen [58]. The method of gradient
descent, described in Section 7.4.4 for learning Bayesian belief networks, is given in Russell et al. [117]. The example
given in Figure 7.8 is adapted from Russell et al. [117]. Alternative strategies for learning belief networks with hidden
variables include the EM algorithm (Lauritzen [68]), and Gibbs sampling (York and Madigan [139]). Solutions for
learning the belief network structure from training data given observable variables are proposed in [22, 14, 50].
The backpropagation algorithm was presented in Rumelhart, Hinton, and Williams [115]. Since then, many
variations have been proposed involving, for example, alternative error functions (Hanson and Burr [47]), dynamic
adjustment of the network topology (Fahlman and Lebiere [35], Le Cun, Denker, and Solla [70]), and dynamic
adjustment of the learning rate and momentum parameters (Jacobs [56]). Other variations are discussed in Chauvin
and Rumelhart [19]. Books on neural networks include [116, 49, 51, 40, 19, 9, 113]. Many books on machine learning,
such as [136, 91], also contain good explanations of the backpropagation algorithm. There are several techniques
for extracting rules from neural networks, such as [119, 42, 131, 40, 7, 77, 25, 69]. The method of rule extraction
described in Section 7.5.4 is based on Lu, Setiono, and Liu [77]. Critiques of techniques for rule extraction from
neural networks can be found in Andrews, Diederich, and Tickle [5], and Craven and Shavlik [26]. An extensive
survey of applications of neural networks in industry, business, and science is provided in Widrow, Rumelhart, and
Lehr [137].
The method of associative classication described in Section 7.6 was proposed in Liu, Hsu, and Ma [74]. ARCS
was proposed in Lent, Swami, and Widom [73], and is also described in Chapter 6.
Nearest neighbor methods are discussed in many statistical texts on classication, such as Duda and Hart [32], and
James [57]. Additional information can be found in Cover and Hart [24] and Fukunaga and Hummels [41]. References
on case-based reasoning (CBR) include the texts [112, 64, 71], as well as [1]. For a survey of business applications
of CBR, see Allen [4]. Examples of other applications include [6, 129, 138]. For texts on genetic algorithms, see
[44, 83, 90]. Rough sets were introduced in Pawlak [97, 99]. Concise summaries of rough set theory in data mining
include [141, 20]. Rough sets have been used for feature reduction and expert system design in many applications,
including [98, 72, 128]. Algorithms to reduce the computation intensity in nding reducts have been proposed in
[114, 125]. General descriptions of fuzzy logic can be found in [140, 8, 20].
There are many good textbooks which cover the techniques of regression. Example include [57, 30, 60, 28, 52,
95, 3]. The book by Press et al. [101] and accompanying source code contain many statistical procedures, such as
the method of least squares for both linear and multiple regression. Recent nonlinear regression models include
projection pursuit and MARS (Friedman [39]). Log-linear models are also known in the computer science literature
as multiplicative models. For log-linear models from a computer science perspective, see Pearl [100]. Regression trees
(Breiman et al. [11]) are often comparable in performance with other regression methods, particularly when there
exist many higher order dependencies among the predictor variables.
Methods for data cleaning and data transformation are discussed in Pyle [102], Kennedy et al. [62], Weiss
and Indurkhya [134], and Chapter 3 of this book. Issues involved in estimating classier accuracy are described
in Weiss and Kulikowski [136]. The use of stratied 10-fold cross-validation for estimating classier accuracy is
recommended over the holdout, cross-validation, leave-one-out (Stone [127]), and bootstrapping (Efron and Tibshirani
[33]) methods, based on a theoretical and empirical study by Kohavi [66]. Bagging is proposed in Breiman [10]. The
boosting technique of Freund and Schapire [38] has been applied to several dierent classiers, including decision
tree induction (Quinlan [109]), and naive Bayesian classication (Elkan [34]).
7.10. SUMMARY
39
The University of California at Irvine (UCI) maintains a Machine Learning Repository of data sets for the development and testing of classication algorithms. For information on this repository, see http://www.ics.uci.edu/~mlearn/
MLRepository.html.
No classication method is superior over all others for all data types and domains. Empirical comparisons on
classication methods include [106, 37, 135, 122, 130, 12, 23, 27, 92, 29].
40
CHAPTER 7. CLASSIFICATION AND PREDICTION
Bibliography
[1] A. Aamodt and E. Plazas. Case-based reasoning: Foundational issues, methodological variations, and system
approaches. AI Comm., 7:39{52, 1994.
[2] R. Agrawal, S. Ghosh, T. Imielinski, B. Iyer, and A. Swami. An interval classier for database mining applications. In Proc. 18th Int. Conf. Very Large Data Bases, pages 560{573, Vancouver, Canada, August 1992.
[3] A. Agresti. An Introduction to Categorical Data Analysis. John Wiley & Sons, 1996.
[4] B. P. Allen. Case-based reasoning: Business applications. Comm. ACM, 37:40{42, 1994.
[5] R. Andrews, J. Diederich, and A. B. Tickle. A survey and critique of techniques for extracting rules from
trained articial neural networks. Knowledge-Based Systems, 8, 1995.
[6] K. D. Ashley. Modeling Legal Argument: Reasoning with Cases and Hypotheticals. Cambridge, MA: MIT Press,
1990.
[7] S. Avner. Discovery of comprehensible symbolic rules in a neural network. In Intl. Symposium on Intelligence
in Neural and Bilogical Systems, pages 64{67, 1995.
[8] A. Berson and S. J. Smith. Data Warehousing, Data Mining, and OLAP. New York: McGraw-Hill, 1997.
[9] C. M. Bishop. Neural Networks for Pattern Recognition. Oxford, UK: Oxford University Press, 1995.
[10] L. Breiman. Bagging predictors. Machine Learning, 24:123{140, 1996.
[11] L. Breiman, J. Friedman, R. Olshen, and C. Stone. Classication and Regression Trees. Wadsworth International Group, 1984.
[12] C. E. Brodley and P. E. Utgo. Multivariate versus univariate decision trees. In Technical Report 8, Department
of Computer Science, Univ. of Massachusetts, 1992.
[13] W. Buntine. Graphical models for discovering knowledge. In U.M. Fayyad, G. Piatetsky-Shapiro, P. Smyth,
and R. Uthurusamy, editors, Advances in Knowledge Discovery and Data Mining, pages 59{82. AAAI/MIT
Press, 1996.
[14] W. L. Buntine. Operations for learning with graphical models. Journal of Articial Intelligence Research,
2:159{225, 1994.
[15] W. L. Buntine and Tim Niblett. A further comparison of splitting rules for decision-tree induction. Machine
Learning, 8:75{85, 1992.
[16] J. Catlett. Megainduction: Machine Learning on Very large Databases. PHD Thesis, University of Sydney,
1991.
[17] P. K. Chan and S. J. Stolfo. Experiments on multistrategy learning by metalearning. In Proc. 2nd. Int. Conf.
Information and Knowledge Management, pages 314{323, 1993.
[18] P. K. Chan and S. J. Stolfo. Metalearning for multistrategy and parallel learning. In Proc. 2nd. Int. Workshop
on Multistrategy Learning, pages 150{165, 1993.
41
42
BIBLIOGRAPHY
[19] Y. Chauvin and D. Rumelhart. Backpropagation: Theory, Architectures, and Applications. Hillsdale, NJ:
Lawrence Erlbaum Assoc., 1995.
[20] K. Cios, W. Pedrycz, and R. Swiniarski. Data Mining Methods for Knowledge Discovery. Boston: Kluwer
Academic Publishers, 1998.
[21] P. Clark and T. Niblett. The CN2 induction algorithm. Machine Learning, 3:261{283, 1989.
[22] G. Cooper and E. Herskovits. A bayesian method for the induction of probabilistic networks from data. Machine
Learning, 9:309{347, 1992.
[23] V. Corruble, D. E. Brown, and C. L. Pittard. A comparison of decision classiers with backpropagation neural
networks for multimodal classication problems. Patern Recognition, 26:953{961, 1993.
[24] T. Cover and P. Hart. Nearest neighbor pattern classication. IEEE Trans. Information Theory, 13:21{27,
1967.
[25] M. W. Craven and J. W. Shavlik. Extracting tree-structured representations of trained networks. In D. Touretzky and M. Mozer M. Hasselmo, editors, Advances in Neural Information Processing Systems. Cambridge, MA:
MIT Press, 1996.
[26] M. W. Craven and J. W. Shavlik. Using neural networks in data mining. Future Generation Computer Systems,
13:211{229, 1997.
[27] S. P. Curram and J. Mingers. Neural networks, decision tree induction and discriminant analysis: An empirical
comparison. J. Operational Research Society, 45:440{450, 1994.
[28] J. L. Devore. Probability and Statistics for Engineering and the Science, 4th ed. Duxbury Press, 1995.
[29] T. G. Dietterich, H. Hild, and G. Bakiri. A comparison of ID3 and backpropagation for english text-to-speech
mapping. Machine Learning, 18:51{80, 1995.
[30] A. J. Dobson. An Introduction to Generalized Linear Models. Chapman and Hall, 1990.
[31] P. Domingos and M. Pazzani. Beyond independence: Conditions for the optimality of the simple bayesian
classier. In Proc. 13th Intl. Conf. Machine Learning, pages 105{112, 1996.
[32] R. Duda and P. Hart. Pattern Classication and Scene Analysis. Wiley: New York, 1973.
[33] B. Efron and R. Tibshirani. An Introduction to the Bootstrap. New York: Chapman & Hall, 1993.
[34] C. Elkan. Boosting and naive bayesian learning. In Technical Report CS97-557, Dept. of Computer Science
and Engineering, Univ. Calif. at San Diego, Sept. 1997.
[35] S. Fahlman and C. Lebiere. The cascade-correlation learning algorithm. In Technical Report CMU-CS-90-100,
Computer Science Department, Carnegie Mellon University, Pittsburgh, PA, 1990.
[36] U. M. Fayyad, G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy (eds.). Advances in Knowledge Discovery
and Data Mining. AAAI/MIT Press, 1996.
[37] D. H. Fisher and K. B. McKusick. An empirical comparison of ID3 and back-propagation. In Proc. 11th Intl.
Joint Conf. AI, pages 788{793, San Mateo, CA: Morgan Kaufmann, 1989.
[38] Y. Freund and R. E. Schapire. A decision-theoretic generalization of on-line learning and an application to
boosting. Journal of Computer and System Sciences, 55:119{139, 1997.
[39] J. Friedman. Multivariate adaptive regression. Annalsof Statistics, 19:1{141, 1991.
[40] L. Fu. Neural Networks in Computer Intelligence. McGraw-Hill, 1994.
[41] K. Fukunaga and D. Hummels. Bayes error estimation using parzen and k-nn procedure. In IEEE Trans.
Pattern Analysis and Machine Learning, pages 634{643, 1987.
BIBLIOGRAPHY
43
[42] S. I. Gallant. Neural Network Learning and Expert Systems. Cambridge, MA: MIT Press, 1993.
[43] J. Gehrke, R. Ramakrishnan, and V. Ganti. Rainforest: A framework for fast decision tree construction of
large datasets. In Proc. 1998 Int. Conf. Very Large Data Bases, pages 416{427, New York, NY, August 1998.
[44] D. Goldberg. Genetic Algorithms in Search, Optimization, and Machine Learning. Addison-Wesley: Reading,
MA, 1989.
[45] J. Han and Y. Fu. Exploration of the power of attribute-oriented induction in data mining. In U.M. Fayyad,
G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy, editors, Advances in Knowledge Discovery and Data
Mining, pages 399{421. AAAI/MIT Press, 1996.
[46] J. Han, Y. Fu, W. Wang, J. Chiang, W. Gong, K. Koperski, D. Li, Y. Lu, A. Rajan, N. Stefanovic, B. Xia,
and O. R. Zaane. DBMiner: A system for mining knowledge in large relational databases. In Proc. 1996 Int.
Conf. Data Mining and Knowledge Discovery (KDD'96), pages 250{255, Portland, Oregon, August 1996.
[47] S. J. Hanson and D. J. Burr. Minkowski back-propagation: Learning in connectionist models with non-euclidean
error signals. In Neural Information Processing Systems, American Institute of Physics, 1988.
[48] V. Harinarayan, A. Rajaraman, and J. D. Ullman. Implementing data cubes eciently. In Proc. 1996 ACMSIGMOD Int. Conf. Management of Data, pages 205{216, Montreal, Canada, June 1996.
[49] R. Hecht-Nielsen. Neurocomputing. Reading, MA: Addison Wesley, 1990.
[50] D. Heckerman, D. Geiger, and D. Chickering. Learning bayesian networks: The combination of knowledge and
statistical data. Machine Learning, 20:197, 1995.
[51] J. Hertz, A. Krogh, and R. G. Palmer. Introduction to the Theory of Neural Computation. Addison Wesley:
Reading, MA., 1991.
[52] R. V. Hogg and A. T. Craig. Introduction to Mathematical Statistics, 5th ed. Prentice Hall, 1995.
[53] L. B. Holder. Intermediate decision trees. In Proc. 14th Int. Joint Conf. Articial Intelligence (IJCAI95),
pages 1056{1062, Montreal, Canada, Aug. 1995.
[54] J. Hong, I. Mozetic, and R. S. Michalski. AQ15: Incremental learning of attribute-based descriptions from
examples, the method and user's guide. In Report ISG 85-5, UIUCDCS-F-86-949,, Department of Computer
Science, University of Illinois at Urbana-Champagin, 1986.
[55] J. Hosking, E. Pednault, and M. Sudan. A statistical perspective on data mining. In Future Generation
Computer Systems, pages 117{134, ???, 1997.
[56] R. Jacobs. Increased rates of convergence through learning rate adaptation. Neural Networks, 1:295{307, 1988.
[57] M. James. Classication Algorithms. John Wiley, 1985.
[58] F. V. Jensen. An Introduction to Bayesian Networks. Springer Verlag, 1996.
[59] G. H. John. Enhancements to the Data Mining Process. Ph.D. Thesis, Computer Science Dept., Stanford
Univeristy, 1997.
[60] R. A. Johnson and D. W. Wickern. Applied Multivariate Statistical Analysis, 3rd ed. Prentice Hall, 1992.
[61] M. Kamber, L. Winstone, W. Gong, S. Cheng, and J. Han. Generalization and decision tree induction: Ecient
classication in data mining. In Proc. 1997 Int. Workshop Research Issues on Data Engineering (RIDE'97),
pages 111{120, Birmingham, England, April 1997.
[62] R. L Kennedy, Y. Lee, B. Van Roy, C. D. Reed, and R. P. Lippman. Solving Data Mining Problems Through
Pattern Recognition. Upper Saddle River, NJ: Prentice Hall, 1998.
[63] Y. Kodrato and R. S. Michalski. Machine Learning, An Articial Intelligence Approach, Vol. 3. Morgan
Kaufmann, 1990.
44
BIBLIOGRAPHY
[64] J. L. Kolodner. Case-Based Reasoning. Morgan Kaufmann, 1993.
[65] I. Kononenko and S. J. Hong. Attribute selection for modeling. In Future Generation Computer Systems, pages
181{195, ???, 1997.
[66] K. Koperski and J. Han. Discovery of spatial association rules in geographic information databases. In Proc.
4th Int. Symp. Large Spatial Databases (SSD'95), pages 47{66, Portland, Maine, Aug. 1995.
[67] P. Langley. Elements of Machine Learning. Morgan Kaufmann, 1996.
[68] S. L. Lauritzen. The EM algorithm for graphical association models with missing data. Computational Statistics
and Data Analysis, 19:191{201, 1995.
[69] S. Lawrence, C. L Giles, and A. C. Tsoi. Symbolic conversion, grammatical inference and rule extraction for
foreign exchange rate prediction. In Y. Abu-Mostafa and A. S. Weigend P. N Refenes, editors, Neural Networks
in the Captial Markets. Singapore: World Scientic, 1997.
[70] Y. Le Cun, J. S. Denker, and S. A. Solla. Optimal brain damage. In D. Touretzky, editor, Advances in neural
Information Processing Systems, 2, pages San Mateo, CA: Morgan Kaufmann. Cambridge, MA: MIT Press,
1990.
[71] D. B. Leake. CBR in context: The present and future. In D. B. Leake, editor, Cased-Based Reasoning:
Experience, Lessons, and Future Directions, pages 3{30. Menlo Park, CA: AAAI Press, 1996.
[72] A. Lenarcik and Z. Piasta. Probabilistic rough classiers with mixture of discrete and continuous variables.
In T. Y. Lin N. Cercone, editor, Rough Sets and Data Mining: Analysis for Imprecise Data, pages 373{383.
Boston: Kluwer, 1997.
[73] B. Lent, A. Swami, and J. Widom. Clustering association rules. In Proc. 1997 Int. Conf. Data Engineering
(ICDE'97), pages 220{231, Birmingham, England, April 1997.
[74] B. Liu, W. Hsu, and Y. Ma. Integrating classication and association rule mining. In Proc. 1998 Int. Conf.
Knowledge Discovery and Data Mining (KDD'98), pages 80{86, New York, NY, August 1998.
[75] W. Y. Loh and Y.S. Shih. Split selection methods for classication trees. Statistica Sinica, 7:815{840, 1997.
[76] W. Y. Loh and N. Vanichsetakul. Tree-structured classicaiton via generalized discriminant analysis. Journal
of the American Statistical Association, 83:715{728, 1988.
[77] H. Lu, R. Setiono, and H. Liu. Neurorule: A connectionist approach to data mining. In Proc. 21st Int. Conf.
Very Large Data Bases, pages 478{489, Zurich, Switzerland, Sept. 1995.
[78] J. Major and J. Mangano. Selecting among rules induced from a hurricane database. Journal of Intelligent
Information Systems, 4:39{52, 1995.
[79] D. Malerba, E. Floriana, and G. Semeraro. A further comparison of simplication methods for decision tree
induction. In D.Fisher H. Lenz, editor, Learning from Data: AI and Statistics. Springer-Verlag, 1995.
[80] M. Manago and Y. Kodrato. Induction of decision trees from complex structured data. In G. PiatetskyShapiro and W. J. Frawley, editors, Knowledge Discovery in Databases, pages 289{306. AAAI/MIT Press,
1991.
[81] M. Mehta, R. Agrawal, and J. Rissanen. SLIQ: A fast scalable classier for data mining. In Proc. 1996 Int.
Conf. Extending Database Technology (EDBT'96), Avignon, France, March 1996.
[82] M. Mehta, J. Rissanen, and R. Agrawal. MDL-based decision tree pruning. In Proc. 1st Intl. Conf. Knowledge
Discovery and Data Mining (KDD95), Montreal, Canada, Aug. 1995.
[83] Z. Michalewicz. Genetic Algorithms + Data Structures = Evolution Programs. Springer Verlag, 1992.
[84] R. S. Michalski, I. Bratko, and M. Kubat. Machine Learning and Data Mining: Methods and Applications.
John Wiley & Sons, 1998.
BIBLIOGRAPHY
45
[85] R. S. Michalski, J. G. Carbonell, and T. M. Mitchell. Machine Learning, An Articial Intelligence Approach,
Vol. 1. Morgan Kaufmann, 1983.
[86] R. S. Michalski, J. G. Carbonell, and T. M. Mitchell. Machine Learning, An Articial Intelligence Approach,
Vol. 2. Morgan Kaufmann, 1986.
[87] R. S. Michalski and G. Tecuci. Machine Learning, A Multistrategy Approach, Vol. 4. Morgan Kaufmann, 1994.
[88] D. Michie, D. J. Spiegelhalter, and C. C. Taylor. Machine Learning, Neural and Statistical Classication. Ellis
Horwood, 1994.
[89] J. Mingers. An empirical comparison of pruning methods for decision-tree induction. Machine Learning,
4:227{243, 1989.
[90] M. Mitchell. An Introduction to Genetic Algorithms. MIT Press, 1996.
[91] T. M. Mitchell. Machine Learning. McGraw Hill, 1997.
[92] D. Mitchie, D. J. Spiegelhalter, and C. C. Taylor. Machine Learning, Neural and Statistical Classication. New
York: Ellis Horwood, 1994.
[93] R. Mooney, J. Shavlik, G. Towell, and A. Grove. An experimental comparison of symbolic and connectionist
learning algorithms. In Proc. 11th Int. Joint Conf. on Articial Intelligence (IJCAI'89), pages 775{787, Detroit,
MI, Aug. 1989.
[94] S. K. Murthy. Automatic construction of decision trees from data: A multi-disciplinary survey. Data Mining
and Knowledge Discovery, 2:345{389, 1998.
[95] J. Neter, M. H. Kutner, C. J. Nachtsheim, and L. Wasserman. Applied Linear Statistical Models, 4th ed. Irwin:
Chicago, 1996.
[96] T. Niblett and I. Bratko. Learning decision rules in noisy domains. In M. A. Bramer, editor, Expert Systems
'86: Research and Development in Expert Systems III, pages 25{34. British Computer Society Specialist Group
on Expert Systems, Dec. 1986.
[97] Z. Pawlak. Rough sets. Intl. J. Computer and Information Sciences, 11:341{356, 1982.
[98] Z. Pawlak. On learning - rough set approach. In Lecture Notes 208, pages 197{227, New York: Springer-Verlag,
1986.
[99] Z. Pawlak. Rough Sets, Theoretical Aspects of Reasonign about Data. Boston: Kluwer, 1991.
[100] J. Pearl. Probabilistic Reasoning in Intelligent Systems. Palo Alto, CA: Morgan Kauman, 1988.
[101] W. H. Press, S. A. Teukolsky, V. T. Vetterling, and B. P. Flannery. Numerical Recipes in C, The Art of
Scientic Computing. Cambridge, MA: Cambridge University Press, 1996.
[102] D. Pyle. Data Preparation for Data Mining. Morgan Kaufmann, 1999.
[103] J. R. Quinlan. The eect of noise on concept learning. In Michalski et al., editor, Machine Learning: An
Articial Intelligence Approach, Vol. 2, pages 149{166. Morgan Kaufmann, 1986.
[104] J. R. Quinlan. Induction of decision trees. Machine Learning, 1:81{106, 1986.
[105] J. R. Quinlan. Simplifying decision trees. Internation Journal of Man-Machine Studies, 27:221{234, 1987.
[106] J. R. Quinlan. An empirical comparison of genetic and decision-tree classiers. In Proc. 5th Intl. Conf. Machine
Learning, pages 135{141, San Mateo, CA: Morgan Kaufmann, 1988.
[107] J. R. Quinlan. Learning logic denitions from relations. Machine Learning, 5:139{166, 1990.
[108] J. R. Quinlan. C4.5: Programs for Machine Learning. Morgan Kaufmann, 1993.
46
BIBLIOGRAPHY
[109] J. R. Quinlan. Bagging, boosting, and C4.5. In Proc. 13th Natl. Conf. on Articial Intelligence (AAAI'96),
volume 1, pages 725{730, Portland, OR, Aug. 1996.
[110] J. R. Quinlan and R. L. Rivest. Inferring decision trees using the minimum description length principle.
Information and Computation, 80:227{248, March 1989.
[111] R. Rastogi and K. Shim. Public: A decision tree classifer that integrates building and pruning. In Proc. 1998
Int. Conf. Very Large Data Bases, pages 404{415, New York, NY, August 1998.
[112] C. Riesbeck and R. Schank. Inside Case-Based Reasoning. Hillsdale, NJ: Lawrence Erlbaum, 1989.
[113] B. D. Ripley. Pattern Recognition and Neural Networks. Cambridge: Cambridge University Press, 1996.
[114] S. Romanski. Operations on families of sets for exhaustive search, given a monotonic function. In Proc. 3rd
Intl. Conf on Data and Knowledge Bases, C. Beeri et. al. (eds.),, pages 310{322, Jerusalem, Israel, 1988.
[115] D. E. Rumelhart, G. E. Hinton, and R. J. Williams. Learning internal representations by error propagation. In
D. E. Rumelhart J. L. McClelland, editor, Parallel Distributed Processing. Cambridge, MA: MIT Press, 1986.
[116] D. E. Rumelhart and J. L. McClelland. Parallel Distributed Processing. Cambridge, MA: MIT Press, 1986.
[117] S. Russell, J. Binder, D. Koller, and K. Kanazawa. Local learning in probabilistic networks with hidden
variables. In Proc. 14th Joint Int. Conf. on Articial Intelligence (IJCAI'95), volume 2, pages 1146{1152,
Montreal, Canada, Aug. 1995.
[118] S. Russell and P. Norvig. Articial Intelligence: A Modern Approach. Prentice-Hall, 1995.
[119] K. Saito and R. Nakano. Medical diagnostic expert system based on PDP model. In Proc. IEEE International
Conf. on Neural Networks, volume 1, pages 225{262, San Mateo, CA, 1988.
[120] J. C. Schlimmer and D. Fisher. A case study of incremental concept induction. In Proc. 5th Natl. Conf.
Articial Intelligence, pages 496{501, Phildelphia, PA: Morgan Kaufmann, 1986.
[121] J. Shafer, R. Agrawal, and M. Mehta. SPRINT: A scalable parallel classier for data mining. In Proc. 1996
Int. Conf. Very Large Data Bases, pages 544{555, Bombay, India, Sept. 1996.
[122] J. W. Shavlik, R. J. Mooney, and G. G. Towell. Symbolic and neural learning algorithms: An experimental
comparison. Machine Learning, 6:111{144, 1991.
[123] J.W. Shavlik and T.G. Dietterich. Readings in Machine Learning. Morgan Kaufmann, 1990.
[124] A. Skowron, L. Polowski, and J. Komorowski. Learning tolerance relations by boolean descriptors: Automatic
feature extraction from data tables. In Proc. 4th Intl. Workshop on Rough Sets, Fuzzy Sets, and Machine
Discovery, S. Tsumoto et. al. (eds.), pages 11{17, University of Tokyo, 1996.
[125] A. Skowron and C. Rauszer. The discernibility matrices and functions in information systems. In R. Slowinski,
editor, Intelligent Decision Support, Handbook of Applications and Advances of the Rough Set Theory, pages
331{362. Boston: Kluwer, 1992.
[126] P. Smyth and R.M. Goodman. Rule induction using information theory. In G. Piatetsky-Shapiro and W. J.
Frawley, editors, Knowledge Discovery in Databases, pages 159{176. AAAI/MIT Press, 1991.
[127] M. Stone. Cross-validatory choice and assessment of statistical predictions. Journal of the Royal Statistical
Society, 36:111{147, 1974.
[128] R. Swiniarski. Rough sets and principal component analysis and their applications in feature extraction and
seletion, data model building and classication. In S. Pal A. Skowron, editor, Fuzzy Sets, Rough Sets and
Decision Making Processes. New York: Springer-Verlag, 1998.
[129] K. Sycara, R. Guttal, J. Koning, S. Narasimhan, and D. Navinchandra. CADET: A case-based synthesis tool
for engineering design. Int. Journal of Expert Systems, 4:157{188, 1992.
BIBLIOGRAPHY
47
[130] S. B. Thrun et al. The monk's problems: A performance comparison of dierent learning algorithms. In
Technical Report CMU-CS-91-197, Department of Computer Science, Carnegie Mellon Univ., Pittsburgh, PA,
1991.
[131] G. G. Towell and J. W. Shavlik. Extracting rened rules from knowledge-based neural networks. Machine
Learning, 13:71{101, Oct. 1993.
[132] P. E. Utgo. An incremental ID3. In Proc. Fifth Int. Conf. Machine Learning, pages 107{120, San Mateo,
California, 1988.
[133] R. Uthurusamy, U. M. Fayyad, and S. Spangler. Learning useful rules from inconclusive data. In G. PiatetskyShapiro and W. J. Frawley, editors, Knowledge Discovery in Databases, pages 141{157. AAAI/MIT Press,
1991.
[134] S. M. Weiss and N. Indurkhya. Predictive Data Mining. Morgan Kaufmann, 1998.
[135] S. M. Weiss and I. Kapouleas. An empirical comparison of pattern recognition, neural nets, and machine
learning classication methods. In Proc. 11th Int. Joint Conf. Articial Intelligence, pages 781{787, Detroit,
MI, Aug. 1989.
[136] S. M. Weiss and C. A. Kulikowski. Computer Systems that Learn: Classication and Prediction Methods from
Statistics, Neural Nets, Machine Learning, and Expert Systems. Morgan Kaufman, 1991.
[137] B. Widrow, D. E. Rumelhart, and M. A. Lehr. Neural networks: Applications in industry, business and science.
Comm. ACM, 37:93{105, 1994.
[138] K. D. Wilson. Chemreg: Using case-based reasoning to support health and safety compliance in the chemical
industry. AI Magazine, 19:47{57, 1998.
[139] J. York and D. Madigan. Markov chaine monte carlo methods for hierarchical bayesian expert systems. In
Cheesman and Oldford, pages 445{452, 1994.
[140] L. A. Zadeh. Fuzzy sets. Information and Control, 8:338{353, 1965.
[141] W. Ziarko. The discovery, analysis, and representation of data dependencies in databases. In G. PiatetskyShapiro W. J. Frawley, editor, Knowledge Discovery in Databases, pages 195{209. AAAI Press, 1991.
&( *' )+-,/.1032*4658 !7*9(#4:"$0: ;<=.1>/.17@?4:2@4BAC'='C'=''D''''D'''D''=''D'''D''''D''='C'='''D'''D'''='C'=''D'''' % E
&(' FHG3(& ' ?F(IJ'@) ;#4LK1VLM2@N4:[email protected]@2@7X>P.1<:5O2@0Q7@92Y;#4:4Z0Q;#.T<:>J2@>N[RS4:[email protected]>J.12@[email protected]?<Q4:2@2@0:4D2Y;'4\!']^'D;_'.14:'9('D<:2@>'R'=0:',(;a'D`b'9J'.1'D7@2@0$'?a'KTMZ'5O'D7@9'4:0Q'=;#<:'C2@>'=Rc''''D'D'''''D'D'''''='='C'C'='='''D'D'''''''' Ud
(&(& '' F(F('e'eFE f$no>2@0Q>J;#.1<:<Qgh?S.T7Yghi$4B.T5<:.12X.17@;kN[7@;#gh4p.1<Q2j'=.Tk'C7@'=;#4l''D'D'''''''D'D'''''D'D'''='='''D'D'''''D'D'''''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D'''''''' mq
(&(& '' F(F(''eUd y3rs.1Kh<:W[2X.T2*k>/[email protected];#7$4Zt1KhKT<OMzNW[2@>J2Y{.17$;tNv.10$>J?N[IJ<O;#.140:2@'DKTiu'4O5#'.1'7@;'DNv'gh.1'<:2X'D.Tk'7@'=;#4w''D'D'''''D'D'''''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D'''''''
' )|x
&(&('' UEH}l.1#5Q< .T0:2@0:0:;#2@RbKbKh><Q2@2*>~_RD.10:WS2@Kb;>0:,KTKMzNW^4.#'OKh'<3'=5O7@'C9'=4:0Q';#<:'D2@>'R['WS';#0Q'D,'KN'4c'D'''='='''D'D'''''D'D'''''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D'''''''
'
))hF)
&(&('' U/U/@'e' F) 3.T7X.T<:4:0:4:2@0Q2X5#2*Kb.T>72@IJ>.1RD<Q0:W[2@0:;#2@0:Kb,>K2@>NRD4WS2@>[;7j0:.T,<:KRbN;4_N(\.1b0Biu.TW[kJ.1;4Q.1;#>(44
\.TM <:>JKhN^WbiubW[i$WS;N;KbN2jKhN2X4cN4'D0QKS''='C}='=s'}='rL'D''''D'D'''''='='C'C'='='''D'D'''''''
'
))Fd
&(' d&(s' 2*d(;'@B< ) .1<O5Q,}L2XRh5#Rb.177*KbWSWS;#;#0Q<O,.1K0Q2*Ngb4S;6'.1>J'N['=N'C2@g'=2*4Q'2@gh'D;6',(2*';<B'.1'D<O5Q',2X'5#.1'D7'5O7@'=94:'0Q;#'D<:2@'>R''D'D'''''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D'''''''
'
))mm
&(&('' d(d('e'eFE on f:L6D\\[email protected]:;#>J<Q5O2@;>N[RSf$0:;4Q<B2*.1>(0QRS2@gh6;asI;<QN;#4:9J;5O>2@>0O.1RS0Q2*.Tgb>J;#NS43'7@9'D4Q0:';#'<Q2@>'DR'9'4:2@'>RS'D's'=2@;#<B'C.T'=<B5Q',2@';#4'D'''''D'D'''''='='C'C'='='''D'D'''''''
'
))&q
&(' m&(&(VL'' ;#d(m(>''@U) 4Q2@0$?hV$i kJs3n .T}=4:;3]PN^}=o5OrC7@!9\14Q}-0:;#<QNrD2*;#>(\(>RS}4Q2@WS0$,?h;2@i$0:;#kJ,<B.T.TK4:<BN;5Q4SN,2X5O'5#[email protected]'7z4Q'0:5O;#7@'D9<Q2@4Q'>0:R;#'<QWS2*'D>(;#R'0Q,'=.1K7@'RbNDKh'DkJ<:2@'.T0Q4:,';W
NC'DKh9'>4:'2@>5O'KbR>'DN>'?;>J5O'=0Q.1;'CW[N'=2X<Q5;#'RhWS'2@KbK'D>N4';7*2@'>2*'D0QR ,a'4Q''9'='=5O'C'C2@;#'='=>''0:7@?D'D'D,(''2*'Rb', ''''FFh|)
&(&('' m(m('e'eFE NV;#> GLr4:2@f:0$? !L\J'L'\J<B3N'D;7@'<:92@4Q>'0:RS;#'=<Q2*'C>(KhR'=2@>'kJ0:.14'D4QG;'N[K'Khf:'N>P;#'D>N0:';#2>M'?[4Q2@'D0$0:?,';DN'=2@34:'0Q7@9<:'D2@4:k'0Q9;#'<:0Q2@2@'D>Kh>RS'M'90:>J'<:9/5O'D0Q5O2*0:'Kb9><Q'=4;'C'='='='''''''D'D'D'''''''D'D'D'''''''='='='C'C'C'='='=''''D'D'D''''''''''''FFhFhEF)
&(' q&(' <Qq(2X'@Nb) iuk/.14:G;_Nf:r685 7* 9(4:\0:}l;<:2@>0OR.10QWS2*4Q;0:2X0:5#,.TK7Nf$4>MKh'D<QW'.T'0:2@'Kh>S'D''<Q2XN'D'}6I('=I'<:K'D.h'5Q,''D'D'''''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D''''''''F1FhUd
&(&('' q(q('e'eFE +._f:gb¡;3 6 7@94:\/0Q3;#<7*9(\4:30:;7@9<:2@4Q>0:R;#<Q,2@>2@RhR,9i¢N4:2@2@>W[R;#>4:._2@ghKb;#>[email protected];#074Q0QIJ<B.1.h>(58;=4$M'DKb<:'W'.T0:'D2@Kh'> ''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D''''''''FhFh&m
&(&('' &
^
]
K
N
;
Y
7
$
i
J
k
T
.
:
4
;
^
N
5
O
@
7
9
Q
4
:
0
#
;
Q
<
*
2
(
>
S
R
S
W
;
:
0
,
K
N
£
4
'
'
'
D
'
'
'
D
'
'
=
'
'
D
'
'
'
D
'
'
'
'
D
'
'
=
'
C
'
=
'
'
'
D
'
'
'
D
'
'
'
=
'
C
'
=
'
'
D
'
'
'
'
'
h
F
x
x&(L' 9x(0Q'@)7*2@;#<6.T0B>J.1.10Q7@2@?4:0:4:2X@2 #5 4P.T7!'.1'I'DI(<:'K.b'5Q'=,S'CM Kh'=<3'Kh9'D0Q'7*2@;#'<6'N;#'D0:';58'0:2@'DKh>¤''='='''D'D'''''D'D'''''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D''''''''FhEhx|
&(&('' x(x('e'eFE VLVL2@;#4:g0O2X.1.1>J0Q582@KhO; >iuk/i$kJ.14:.1;_4QN^;NKhKb990Q7@0:2*7@;2@<
;#<6NN;0:;;0:5O;0Q5O2@0QKh2@Kh> >c'''''D'D'''='='''D'D'''''D'D'''''''D'D'''='='C'C'='='''''D'D'''''D'D'''''='='C'C'='='''D'D''''''''EEhF)
&('*)_|9(WSW.T<:?¥'''D' ''D'''='C'=''D''''D'''D''=''D'''D''''D''='C'='''D'''D'''='C'=''D''''EhE
)
F
¦§
¨C©ª¨D©«
¿Á¾ ÀÂ!ÃÄhÅÆÄhÅÇÆÈÁÂ!ÉÄhÊSËÌ1Í1Î!ÏÐÐÐ(Î!ÑaÒÓaÔÕÖ×ÖÑØcÙØDÕÚØDÛ3ÜÖ×ÖÑØcÙØDÕÑÝOÞÕ6ÒDÝOß6àÕ6ásÖXÖ
ÓDâãâäOåæTç(Îæhèèè
¬ ¯®±°²´³¤µ ¶
·¸ ¤¹ º »¥·¼ ½=
é êQë ìîíLïðòñ:óÆôõQö6óbð÷!øùïzúLïõ$û6óñ:ó(ü
G ,;D#_I(<:K5O2*;#464Q.4D5OK1KbM7*Rh@;<Q58Kh0:92@KhI(>^2*>(K1RSM.N.14:;#0O0L.DK1KbMkhOI;,5O?0Q464:2X0Q5#,J.17.106Kh<.T<:.1;k4Qý#0:þX<Bÿa.bþ 5O0Khkh0QKO;_Kh5O0:>4L;D2*.T>>0QKSKh0Q5O,7X;#.1<4:4Q;#42@0:K1,M2@>[ý#þX0:ÿ,;Dþ 4OD.1W[Khkh;=85O;7@5O90:4Q40:;#2@46<5#.1.T>J7*N[@;N.1<:; 1þ@ýOý#þXÿ1" þ 6'0Q} K
0:,(;63Khkh7@984Q;0:5O;#0:<64.T2@>>J.1Kb7@0:?,4:;#2@43<62*58467*9(.T4:>^0:;2*<:W[4'oIJ}wKb<:0O5O.17@9>4Q00:,;#<9WKTMz.TN>S.1.h0O.5O0QKh2@gkh2@O0$;_?5O'z0:46o5#.1.T<:7@>S?[k/2*>^;60Q5Q<:,;[email protected]0:;,N^KK5ONKb7*t@;Kh58>0:;2@gh7@;#;[email protected]?<Q>.14643,(Kh>K1-;Rb0:<:KSKb9NIS2@4Q0:2@2@>>RhW9(.T2*4Q>,S?ak/.1;#I0$I(37*2X;#5#;#.T>Æ0:2@5#Kh.1>(0Q44 '
.1.1>/>/NÆ.17@?N4:Kh2@4Rb4,Jt.TKh4<kJkJ;#;;0$>Z;#;2XN>ò;7*.1?>(2*9W^4Q;.1N[7@4=2*>.T>J>N 9W[I7X;#.1<:>Kb0:94_4t!.1kI? I5O7@2XKb5#>.T0:0:2@2@>Kh9>Kh4_9t12@4Q>J7@?P5O7@9J2@WSN2@I><QRCK1g[email protected]>0QR0:;#4Q<Q9>k<Q5O;Kh5O>Kb4ORh5O>2@Kh2@0:92@4Kb>!5Ot7X.1N(4Q.14:0B2 .5#.1.T>/0:[email protected]@>Æ?4:2@4O45Qtb,2@;#WWS.1;Rb4;Z'SI(3<:K7@95O4Q;#0:4Q;#4$<i
2@N>2@RJ4:0Qtb<:W[email protected]< 0Qb2@Kh;#>S0<:I/;.14:;0:0Q.T;#<B<:5Q>(,!46t/.1;#0B>J5TNv'Z2*no>0Q?S;#<:5O;#7@94Q0:4:2@0Q>;#RS<:2@>5OKbR/<:t<QKh;#>(7X.1;=0:2@5#Kb.T>>S4
2X.TNWS;#>Kb0:>2MRD?SN58.1<:0OK1.a6.TN0:;0:N[<[email protected]>J9Nv0:;4:4IJ'.Tf$<:>[4Q;Dk9<:;#4QRb2*>(2@Kh;#>4:4_4_tJt5O.17@>J9Nv4Q0:0:;#,<Q2*;#>(<QR;OMKbW<:;h._?Dt/N,2@;4B7*5OI[K1gbW;#<Z.T<K1hgb;;#0:<B;#.T<Q7@4 7
k2@N>2@2@4BKh4:2@587@RbKbK1,ghRh0o;#?<th2*>2@N060Q2@Ka4:5#0:.T4Q2@>P0:>J<:589/kJ05O;C0:Rh99<:<QKb4:;#9;46NI2@4>0:KS2@,(>S;#N<:0Q;#;#,<Q>;#2@0gh2@<=;D2@>58I9I/7X4:.TKh0Q>KhI06WS9.T7X;.T>J<Z0:N^[email protected]>>4:4_;#2@'zW^43.1.17@>J79N^0O4Q._0:;#5Q{,J<[email protected]>><BKbRa.hWS58W^0:2@;#;#._<Q4_?a2*t~.15#; [email protected]:KD9(;#Rb4:,0:Kh;#Kb<Q7@WS2*IS~;a;#2@>[<RbRb0:;#,<:>Kb;L;#94L2jIN4;#2*>kJ0Q0:,^.T2 4:4:;5#2@N[WS.T0:Kh2@2@7XKh>^.1><IKTM 9(9M <B>J.15Q5O,J<Q0Q;.12*.14QKb432@>J>K1.1RM!7@2@[email protected]0Q0:.T2@;#7X>J.1<QN[><47XR'o.1.1>Jf$2@>>N
9,4Q2@Rh;,S2*>Æ._gb.1;#>´<B.T;Rh.T;<:5O0:,Æ7X.12@KbW±k4:5O;Kb<:4:gh0_.1tJ0Q.12@Kh4o> ZN;#[email protected]0B.1.T43kJ.10:4Q,;h;Ltz2X.TN>J;#>N 0:22*> 5#0:.T,0:;2@Kh>2XNKT;#>M!0QRh2 <QKh5#9.1I0Q2*43KbK1> M!KT,(MZKh9Rh<Q4QKh;#49I(2@>S4D.aK1MZ5O2@W[0$?Kh0Q.hKh5#<658Kh2@><BN4Q92*>(<BRa.T>J0Q5OKD;,I/KhKh9(7@4:2X;5O?^0$?,IJKh;h7XNt;gh<:.T4D7@9;h2@th0:.T,Æ>JN.
MRh0:9,(;>/Kh; Rh5O5Q0:<O,[email protected]><B,(.ht 2j585580:7*.1;#9(7<Q4:7@2*0:K4Q;0:5#<2X.15O0Q.T4D2@>JKhKT.1>!M7@'?;4:f$.h02@5Q46,ÆW^5#.T._5O7@>P?9.T4:k/0Q7@;a4:;#K6<9t!,(4Q.T;;#>JN´7@ISN^.15O0Q4=7XK.1.4:M4QK4Q20BM5O?D.T9>J4LNNbKKhi:5O>[email protected]>;IJ;C>.10:0Q<QK40:Kh2XKh5O7>90:7X0:KS.T,(<R;4:.1+-;#2@0>^+-K12@>M+4:5O2@7@Rh9M,Kb4:00Q<;#2@2*<:>>4L0:MK[KhMKb<Q0:W<,M;a.190Q<QN2@0:Kh2*,4Q>=0:;<QN<2*2*k(4O.T95O>JK10:.12@ghKh7@;?> <:4:?2@K14_'!MZ'}LN}[email protected]:.;N<:t(>J.10:0O.TKS.60:2@KbW[ghk;#4:2@7@>;?<:2@t>gh2@;R0
WN;#._0Q?;5O4:0Q;;<:N gh;587*.19(464:0:.C;<:I4<Q' ;#I<:K5O;4:4:2@>R^4Q0:;#I^M Kh<Kh0Q,;#<6.T7*RbKh<Q2*0Q,WS4_th4Q9J5Q,P.1465O7X.14Q4:2 5#.T0:2@Kh>P.T>JN^5:,/.1<B.b5O0:;<:2@~.10Q2@Kh>!t(KhI/;#<B.T0:2@>RKh>^0Q,;
IJW.T.bIJ5QV;#,<Q.12@4S>0O;6.D4O5#[email protected];[email protected]:<:4Q;#>0:<Q;#2@;><QN-2*R/>(thRa2@>ù4QIJ2@4.1W0Q.2j.1.T?h>7!Kb?ÆN9.1>5OKh0ORD.1>4OkJM5O;#.T2@<:4:;#;;h>>Jt(0:5O2k;´2@5KhI7@NKh<:K2@Rb4B5O?5O;#tT2@;_IWN7@2@[email protected]>>< ;Rhh4^9;#0Q>/.12@>N>J;#RJNù<t.1gI/>J2@;#RhNv<:Kh2@K<Q4:KhKN92XKb5#43.1>!N7@t4_;#tghWS;2@0:7*,PKbKbI4:N0QWS7*2 ?´;;>2@<:0_> ;#'!>0:G0,,(;#; W[;#<:J;DI;#,J7X.1N.1<Q44Q;=;#KT.C46M.17X.1N>/<:.TNRb0B;.´N>2 W[9;#W2*<Q>(;#kJ2*>>(;0<RJ0:tK1;M!4:5Q0B,<Q.T;#>0:4:2X2@;`b4:.T0Q92X<B;#5O5Q4_4, 't
2@L>PN2@}L.1>0O4Ra.D0Q.´W[KDk2*0:>(<O,(.12*;6>(>JRD,5Q,¤9<:Rh;#K1;4Q;MD.1.14:W[<O0O5Q.1Kh,!0:9' 2@>4Q0:0:2X45O4KTtM [email protected]:;#5O<[email protected]*;_>/5O.10:7@;?Nv4:2@2@4>,JN.1.T4[0B.1kJk/;.1;#4:>w;44Qt0:5O9J7@9N4Q2*;_0:;#N <6;O.T{>J0:.1;#7@>(?4:4:2@2@gh4;#,J7@?ù.T4MKb<:;_<S5O;#W>.T0:7@>?S?Æk/?h;;5O.TKb<:WS4t
;M.K5O,92@Rh4:4Q,2@7@>?R.hW^[email protected]@;>7@0:? KbIKb2X> 5
N.17@2@4Q4:K0O.1kJ>J;#58;;O>Piuk/k.14:9;_2@N7@0Z582@>[7*9(4:W0:;.1<6>?.1>J4:.T0O7*.1?0:4Q2@4Q2*4_0:'!2X5#[email protected]:>J0Q.T;#<67@?.14Q>/[email protected]@?K14:M0$2@40:.1K<QKh;=7@4I/.hkJ5 .Th4:.1;RbNv;#Kh4>SKh<bi$4QWS?4Q;_0:.1;#>W[4_4ttb4Qi$9JWS5Q,;_N.1Kh462XNb4_i:t .T7@>J9N4_t4Q;#gh;<B.17/t/Kh.10Q>J,N^;#<3}WS;#0Q' ,KN4,J._gb;
NK ;#f$4>Æ>W^Kh0C.h <:5Q;#,7@2@?´>" ;DKh/>´7@ ;t(.TI<:<B<:>.T;2@0:N>,; R/;#J<Ctz>5O;0:7@,JN 9.T4Q5O>0:7X;#.T<4:4:.1;>/4 (.1þ.T7@?>J4:NÆ[email protected] 0:4Q;#4$>Æ1i$7jÿ .T<QkJ;O;M;#O7*;_ý#<Q4aN´'[0Qf$0:K><B.T2@>J 2@>R^;O{J_.1WS"uI( 7*;4' ((Kh1<1z" 0:" ,( 2*4Ct'<:.[;s.TRh>4:<QKhKh7@2>9btIÆ;S2*05OKT7XM
[email protected]:kh.[2 O;M 5#Kh5O.T0Q<:0:4W 2@KhM>!KhK1<QtM WS5O7@4D94Q.^10:;#5O<Q7X" 2*.1 >(4QR 4
KhRh>(;Kh7*?^WS2;M0:<:2@062X52@4=N2@N4:0O;.14B5O>J<Q582*;hk/'6.1k37@Kh;>/k5O?P;#I.[0Q9J5O.1Kh7>J5O587@;#9I4Q00:';#<QG2*>(,(R2*45ONKb>2 4:;2@4:<:0Q4L4MK1<:KbMW 0$Z5OKSKh>58KhgbWS;#>I/0:Kh2@Kh>(>J;#.T>7z0:45O\7@9B4Q) 0:3;#<Q2*2@0>R^N2@4B5O,K1gb2X5:;#, <:4LWS0:,;.T;4:9.1I<Q;#I46<QKh4QI2*W[<[email protected]:.T;<:2@0$5O?7X.1kJ4:4Q.T;#4:4;tN^.T>JKb>N
7@uK1F -f$2@2@>P0>M 0:NKh;#.T<:<OW[0B5O.C7X.14WS4:N4L;#2@4:>4B2@582@WS><:2@RJ2@I7Xtb0:.1I/2@<QKb2@;#0$>Kh?D4I4:M7@0Q;Kh2*<7@,J7!;._.T.bgbI5Q;=,Ik/7@5O2@;#;#7X;#.14> 4Q' 44:t0:.19/43N2@?>S2*>(5OR7X.1WS4:4Q2;#0Q5#,.1K0QN2@Kh43>!MKh'<3G;O,;65ORb2@9;#>2XN0;#.17@2@>J>N[;3K1; M!;4:0Q5O<:0Q2@2*ggb2@;a>5OR7@9MKb4Q<0:;#,<[email protected],>/.12@>7@?0:4:<[email protected]@7X>.14Q44:2@W[2*7X.T<:2@0$?=_.Tý >JOý#N '
E
!"$# #&%('*)+",- /.01"
2 3
54 76
4 86
9:%-";-=<>8' ?"
U
¦ ©ª Á¦ z«©ª =¨ o« :«
}=158ÿ 0:2@gh;L0:,ý ;WS;#O4Lý K1M<:;#4Q;.1<O85Qý ,´MK5O94Tt Kh>Pþ 0Q,;1þXý ÿ ý8þ þ Yþ K158MZ7*9(5O4:7@0:9;4Q<:0:2@;#><QR2@>0:R^;5QWS,>(;#2j0Q`b,9K;N44tt(.10:>J,N;W[; ;#;0:,(5O0:K2@Ngb4;#>MKb;#4Q< 4a587*KT9(M 4:0:W[;<:;#2@0:>,(RKNÿa4þ MKb<=5O7@9ÿ 4Q0:;#<Qþ2*>(R
#2*>(þ R2*46.5QL,[email protected]>^7@7*7j;.T><:RhRb2@;=>RN.T/0B;#.17Xk/N^.1K14:;M4<:' ;#4Q;.1<O5:,´,;#<Q;D2@0:4I/Kh0Q;#>0:2X.17.1II7@2X5#.T0:2@Kh>43I/Kh4:;C0:,;#2@<K1>^4:I/;5O2X.T7!<:;_`h9(2*<Q;#WS;>0Q4'
3
@
7
9
Q
4
:
0
#
;
Q
<
G,;M Kh7@7@K12*>(R.T<:;0$?I2X5#.17<Q;`b92@<:;#W[;#>0:4KTMo587*9(4:0:;<:2@>R2@>PN.10O.DW[2*>(2*>(RJ'
)b' ,K1Z; gh;#<_"t ".O 7X.T\3<:]PRh;.1N>.T? 0B.15Ok/[email protected]:0:;;#<QW^2@>._R ?D5O.1Kh7@Rb>Kh0B<:.T2@2@0Q>a,WSW[432*7@7@Z2@KhKb>< 4PKT3M ;#Kb7@kh7O2@;>P5O0Q4Q4W'33.17@7*79(N4:0:.1;0O<:.S2@>4QRD;#0:Kb4> 5O.Kh>ý 0BT.Tÿ 2@>2@>RSKTM7@;#.L4Q4DRb2*0:gb,J;#.T>> 7X.1Fb<Q|hRh|[;NN.1.10O0O.S.64QKb;#kh03O;W5O0Q._4 ?
7*;_.hN[0:Kk2X.14Q;N[<:;#4Q97@0:4'sK1w5#.1>^3;DN;#gh;7*KbIP5O7@94:0Q;#<:2@>R^.17@RhKb<:2@0:,W[40:,J.T06.1<:;C,2@Rh,7@?4B5#.T7j.Tk7@;2*>[7X.1<:Rb;DN.10O.1kJ.T4:;#4OA
F(' kJ .14Q;"N " # >9 WS;#<Q2X5#(.1 7 N".T 0B.'" ZK131;#gh!;#^<_t6# W^.1> ?.1SI(I7@_2j51.1"0:2@Kbz>_4W \D._]?Æ.1<Q;>`b?[email protected]<:7@;ÆRhKb5O<:7@2@90:,(4:0QWS;#<:4=2@>.TR <:;PKh0QN,;#;#4Q2@<^Rh>0$?;NIJ;0:4KÆKT5OMa7@9N4:.10Q0O;#.<t2@>4Q9J0:;#5Q<Q, gh.1.T74i
k2@>J.1<Q?t5#.T0:;#RbKh<Q2j5.17 >(KhWS2@>J.T7 #th.T>JN[Kh<BN2*>/.17!N.T0B.tKb<WS2{0:9<Q;#43K1Mz0Q,;#4Q;aN.10O.0$?IJ;#4_'
E(' 9J"$5O7@2XN/;.T>1 Kh<Z]P.T> ,J.T0:_0B.Th> N2*4Q"0B .Tc>J5O;6 W[;" .114Q9<:1;4' }6z7@ RhKb<:2@\P0:,]PW[.14!>kJ?ò.T4:58;7*N9(4:Kb0:>;<:4:2@>9JR5Q,S.1N7@Rb2@4QKh0B<:.12@>/0Q,5O;6WSW[4a;N.1;#4Q0:9;#<Q<:WS;#4o2@0:>;#;P>JN5O7@90QK 4Q0:J;#>J<Q4Nk/4QI.1,4:;_;#N<Q2X5#Kb.1> 7
5O.17@7@9Rh4:Kb0Q<:;#2@<:0:4,W[42@0:,´,4:2X2@5QWS,2@5#7X.1.T<> 4QN2*~;#;S0Q;.15O>J0NÆ5O7@N9;4:0Q>;#4:<:2@40$?K1' Ms.1<QK1kZ2@0:;<Bgh.T;#<:<_?[tz.^4:,J5O.T7@IJ9;h4Q'0:;#<5OKh9(7jN k/;K1M6.1>?P4:,/.1I/;h'f$0D2@42@WSI/Kh<:0O.1>060QKPN;#gh;7*KbI
U/' .17@Rh"Kb<:" 2@Æ0:,W[41<:;`b/9z2@"<Q1; 9Æ4:;#<Q!4Z0QK2*>(JI 905O;#Æ<Q0B.12@"> IJ.T<B.TWSa;# 0Q ;#<:4/2@¤> 587*9(4:!0:;<Z_.1>J Æ.T7@?"4Q2@ 4 "4Q 9J5Q,S.140Q,;1 >Æ9W_k/;#h<! KT\´MN]P;4:.12@><:;?-N5O587@7*99(4Q4:0:0:;#;<Q<:2*4>(R '
G;#4:,I/;a;[email protected]@7@4Q?[0:;#M<QKh2*>(<6RSN(.1<:;0B4:.v94:7@0:;#4D0Q4D.T<:5O;DKh>KT0BM.T0:2@;#>>P2@>`bRa92@,(0:2*;CRb,4:;#i:>N4Q2@WS2@0:2@;#gh>;D4Q2@0QKhKS>[email protected]>7JIKb9(kh0O;IJ5O.10Q<O4.1'LWSG;,0:2@;#4<Q4>'Kh0L]PKh.1>>7@?[?SIJk(.19<O<B.1NWS;>;40:;#9<Q4=4:;#.1<Q<Q4;Dtk(,J9.T0=<BN[.T7*0:4QK^KNW;#0:. ;h<:;#WS42@0Q>,;b; t
`h9/.17@2@0$?K1M 587*9(4:0:;<:2@>RSN25O97@00QK 5OKb>0:<:Kb7$'
d(' ;# <:<QKh"> ";##Kb946 N.T0B.' KbWS";6 5Oc7@94Q0:/;#"u<Q2*>( R .T7*RbKh <Q\2*0Q,] WSKh44:0^.T<:<Q;6;4Q.1;#7i$>Z4Q2*Kb0Q<:2@gh7XN ;60QNKD.10O4:.19/kJ5:,P.T4:N;#4P.T0B5O.DKb.T>>J0O.1N2@>-W^._Kb?90:7*7@;[email protected];#<:N4[0QKaKh<[5O7@WS94Q2@0:4:;#4Q<Q2*>(46RJK1tM!9(I/> KKh><K1`b9J>!.17@t2@0$Kb?< '
m(' N.10O#.t/;h#'" RJ_'@" t/0:"X,S;4B.TWS ;D 4Q;#/0 K1M
N( .10B.(
t" ,;#z>´LI1<Q;#4:/;#>z0Q; N´\Kh2@W[0:,Æ;6N5O27@9;#4:0Q<Q;#;#<:>2@0>RKh<B.1N7@;#Rb<:Kh2@<:>2@Rb0Q,4=WS0QK^44:.19J<:;5Q,Æ4Q;#.1>> 4Q2*0Q.T2@7*ghRb;6Kh<Q0Q2*Ka0Q,0QW,;6tKbW^<BN._;?S<ZRbKT;#M >2@;#><OI.19(0:;0
N<B.TW.10Q2X5#.17@7@?=N2 ;#<:;>035O7@94:0Q;#<:4_'f$02@4z2@W[IJKb<:0B.T>0!0:KDN;gh;#[email protected]@RbKh<:2@0Q,WS4,2X5Q,.1<:;2@>4Q;#>4Q2*0Q2@gh;30:K0:,;Kb<BN;<K1M2@>I90_'
q(' 5O7@9" 4:0Q;#<:2@>" R Æ.17@ RhKb" <:J2@0:,W[X"×4 # .T\/<:;P}lRbNK.1K0ONÁ.1kJ.1.T04:;,JKh.T<6>JN.7@2@N>.TRÆ0B.7@K1 .1<QN;#2@,W[Kh;#9(>4:;D4:2@KbW^>J._.1? 765ONKb.T>0B.(0B.1tZ2@>[2@>4:gh;#Kbgb7@g;#<B2@>.T7R´NKh2*>(W[7*?ù;#>0$4QZ2*KbKÆ>40QKKb<60Q.1,0:<:0Q;#<:;Æ2@kN92@0QWS;#4;'>]P4:[email protected]>(>4? '
N.190OW^.D.1Kb>DkhO;#;?b5O;#0Q44.12*>[<:;,Rb2@RhK,^KNN.T2@WS0O;#9J>N4Q2@RbKh2*>J>(.TR=70Q4Q,IJ;6.h`b58;h9Jt.1;#7@2@4Q0$IJ?D;_KT5O2XM.15O7@7@7@9?4Q5O0:;#Kb<Q>2@4:>2XRN;#M<QKb2@<>9RaI0Q,J0:K.100Q,N<:.T;#0B;.CN2*>[2@WS,;#2@>(Rh,^4:2@KhN>2@WS4_';#f$>04Q2@2@4ZKh>J5Q,J.T.T77*4Q@IJ;#>(.h58Rh;a2@>5#R6.1>[0QKakJ5O;7@9gb4Q;#0:<:;#? <
4:IJ.T<:4:;.1>JN[,2@Rh,(7*?4 h;#3;N'
&(' K1 M=/5OKb#>_4:10Q<B.1" !2@> 0:4_' J9(IIJKb4:;[0:,J1.T"0D ?hKb\9<Z;O.TKb7kÆiu32*4CKh<Q0:7jKÆN[.15:,(IKI(Kb7*2X4:5#;[.T0:0:2@,Kh;[>(47*KW5#.T._0:?2@Kh>>(;#46;_N^M Kh0:<aK[.^IJRb;#<¢2@ghMKh;#<Q>ÆW >95O7@W94:k/0Q;#;#<D<:2@>KTM
R^>9;>/N;#.1<69gh0Q.TKh<:W^[email protected](0:42X55#2@>J.14QN, 4
4:.10B>J.TN 0:2@Kh,>(2@Rh4 ,
}._G6?´]^>4 ;#0$32@>Kh< .458tZ2*0$?.T>J'NGK 589N4:;0Q5OKh2XWSN;D;<9I/<:Kh;`b>^90Q2@,<:;2@4WSt;#?b>Kh0:9[4WI/;#._<?S<:5O;#7@Rb92@4QKh0:>ò;#<L.T,4SKh95OKh4Q>(;#,4:0:Kb<O7j.1N2@4>0:4_,'Æ2@7*} ;D5O5QKb,J>.14:7@2X7@N;#;><:Rb2@>2*>(RRP0:,(0B.T;a4 Æ5O2@0$2@? 4a40QK <Q2@gh/;#>J<QN 4
Rh<:Kb9I4KTM N.T0B.2@0:,^RhKKNS587*9(4:0:;<:2@>Rk/;#,J._g2@Kh<6.1>/NS4O.10Q2*4¢M?2@>Ragh.T<:2@Kh9(4
5OKb>4:0Q<B.T2*>0Q4'
x(' 9!4B.T_k7@ ;hz'1G_,J .T06"X2@X4" t/O5O7@94:0QP;#<:2@>R^ W"._ "?O >(\/;#;N^4:;0Q<:KS43k/W;D._0:?62@;;8N^{I/9(;IP5O05O2@7@0:9,P4Q0:4Q;#IJ<Q;2*>(58RD2 <:5D;#4Q4Q9;#W7@0:4.T>0QK0Q2XkJ56;2@>2@>0:;0:<:;#I<QI<Q;#<:0B;.T0B0:.12@k(Kh7*>;b4Dt5O.TKb>JWSN^I.1<QI;#I,7@;#2X>(5#.T4:2@0:k2@Kh7@;h>th4_.T'3>Jf$N 0
2*42@W[IJKb<:0B.T>00:K4Q0:9JN?[,K1.1>.TII7@2X5#.10Q2@Kh>SRbK.T7JW^._?a2@> J9(;#>J5O;D0Q,;D4Q;#7@;5O0:2@Kb>KTMZ5O7@94:0Q;#<:2@>RW[;#0:,KN4_'
K1WSM6;N0:+-,[email protected],a4_.T'^0Q>J,NP+Æ;#4:,(;;LK10:<:l,;`b;#0:>ù9,(2@;#<Q4:?;#0QWS9J5N;#.1?´>>Æ0Q;[email protected]> 2@5QJ>a,ò9W[;58>J2*7*>/9(5O4:;N0:t#;58Kb<:7*92@9(><4:R´0:4:;0Q<:WS9J2@>N;#RP?0Q,K1W[KM!NP;#5O0:7@2@,9>K4:0QNN;#4_;#<'S0O.1.12@>J7$;.Tt!587*2@Kh?>J>J4Q582*N7*49/tIN3<Q2@K>;5OR^;#I;IJ<:N;#.144Q<Q;#0:.1>2@40:0 [email protected]>(7@2*7@Rh>(K1;#R>4;W['<B.1;#730:2@,(<:5#4QK.10N0Qtb;#4ZRhtKb;,<:4Q2@2@;#0:~<B9J.1.T0QN<B2@? Kh5Q,>ÆN2X25#K1.1M6;#73<:5OWS;7@>9;0o4Q0:0:0$,;#?<QKI/2*N>(;#4_R 4 t
4:N2@;#Kb>(>J4:.12@0$7?b4QiuIJkJ.h.T5O4:;;N .1>JWSN^;#N0Q,2@4BK58N944:t(4LRhgh<:.12XNb<:2Xi$.TkJ0:.T2@Kh4:;>N[4oK1WSMZ;N0:,2 K;N<:4_;#tJ>06.1>/W[NS;#W[0:,(KKNN;#47'iuk/.14:;_NSW[;#0:,(KN4'+Æ;.17@4:K;8{(.TWS2@>;5O7@94:0Q;#<:2@>R[2*>^,2@Rb, N2*W[;#>i
éê [û D÷ó Lï!ðïñ:ú ôõ:ö6óbð÷!ø(ñ:ú ïú6ïõ$û6óñ:ó
f$4:>P9/5:0Q,Æ,[email protected]>´4:;_.15O>J0:.T2@Kh7*?>4QtJ2*4_3'6;D4Q90:I(9JIJNKb? 4:;0:,0:;D,J.T0$?0=I/.S;#4N(.1K10BMZ.vN4:.T;#0B0.0QKS,(k/2j5Q; ,^5OK17@9M 0:4Q;#0:;#<L<QK;N´55O95OKh<>2@0B> .T2@5O>7@494:´0Q;#Kb<:2@kh>OR^;5O.10Q>J4D.T7@?,4Q2X2@5Q46,P.1W>JN^._?,(K1<Qw;#I<:0Q;KS4:;#I><Q0D;#II/<:;#K<:5O4Q;Kh4:>44_0:t!,,(;#KhW 94QM ;#Kh4< t
A@CBED
?P1-' 1<:)
PQ /.01",
SR." L#0/<:).T" UQ:VU-=<> &R W%?R8XS
Y"$#
AFHG3I
AJCK
AFB
5BLJNM
&O
Q#0
W,"E#Z Y"$ [P
#\]P=<>">%-Q [PN-7<
E
/^_
?`
? U.\"
?a
cb
a4
7de
f
g
4
Cj
ih
6
6
ah
kb
7d
*d
i
E
Cl
m
n
&m
(h !o\m
qp ib
N
?r
m
s
im
A4
S6
?t
vu
[
b
7
?d
7d
-
t
Eih
-
Cw
\dx
m
7y L
E4
T
C
6
gz
vu
A
&{
N
&{
>|
}
U~
9]
U
L
+
-© ªo«Æ§ L© :¨
¦ «©ª :¨ ¨ « :«
d
NNK.T0B5O.9W[4:0Q;#<:>9J0:584_0:t95O<QKb;#94' >0:<Q2*;4t;#0O51'Z]P.T2@>aW[;#WSKb<:?biuk/.14:;_Na5O7@94Q0:;#<Q2@>Ra.17@RbKh<:2@0Q,WS40$?I(2j5.17@7@?DKhI/;#<B.T0:;LKh>S;2*0Q,;#<3K1M0:,;sMKh7@7@K12@>R60$3K
)b' u.1(7@4QK 5#.TÆ7@7*;_NP_1ÿ" Khý < #ÿ ýKh< #þ #þ Cý8ý #tb4:9J5Q, #.T\34
G.T,Rh;h2@4t,(<:;#;#I(2@Rh<:,;#4Q0;#t>30:4;#2@Rh´,Kh0tkhORb;;#58>J0:N4;t<4:t9/<O5:.h,Æ5O;b.1tJ4.1I/>/;#N<:4Q4:KhK>Kb4_>!t'G2@0:,, ;4:0Q<:9J158"0:9<Q;D2@4
2*>[0:,;MKh<QWcK1M<:;#7X.10Q2@Kh>J.T70B.1k(7*;btKh< (i$k?bi SW^.10Q<:2{ PKbkhO;5O0Q4 ^gh.1<:2X.Tk7@;#4 t.144:,(K1>2@> u&'@) #'
G3I
iI
UMAD
CCB
Cj
9m
4
4
0BO
AJCK
AF5O ;!B
Q-'
?"P< XS'*)7X= [-'*"
Y"S $Z3" Y"*#&<
CBEJNM
&O
<:$ZP<:Z&S"6
Y
c=<[<: ['*Z8<>" 6
U
]4:
_S
7?7?777??7
7?g:
S6
i
u&('@)
£
£
£
4
?6
7?
7?7?777??7
76
¢£
7?g
7?1
k4
i7? 8
¤
7?¡i?
F(' MKh<6"$_.T#7*" /ÆIJ".T×2*<Q14"XK1#M PÆKbkh_O1;" 5O0Q4'Kbf$< 02@4KTM0:;#>^<Q;#I<:;4:;#>ý 0:;_N´k?S.T> \!G(iu,k2@?b43i 4:0QKh0B<:.1;k(467*;D.D.T5O4Kh7@4:7@;,5OK10Q2@Kh>^>Sk/KT;#M!7@K1ID<:K_t {2@WS2@0Q2*;4z0Q,J.10.1<Q;=._gh.T2*7X.Tk7@;
uuFE | )) uE | OF |
u&('eF
'' '' ''
) OF
|
,;#<:; -|t33;D2*43,J0:._,(gb;=;6W[0Q,;;D.14QW9<:.T;_0:N<Q2Y{"2@Z> $1&'eF ' ]^Kh;< .14Q9"$<:;46" ÆK1M"XN(2@4:" 4QO2*W[k/2@7j;#.T0$<:Z2@0$;?a;#>P.T<:;aKhkhN82@;4O5O5O0:94 4:4Q;.1N^>/0QN ,<:Kb'Z9Rh2@,>JKb5O;900:,(2*44Q;5O0Q2*Kb>!' #t.T>JN
G4:2@>J,58;;N0Q.1,0O.D;SW^<QK1.10:4 <Q2{a.T>J2@4NÆK15OMKb0Q;#7*9(>WS5>.17@47@;K1NSM6. 0Q, ;M Kh<:W[;#<D <Q;#WI<:.T;0:4:<:;#2>{!0t1N,2 ;;#<:<Q;;#.T>40a0:,;#>;0QN2*0Q2@2@4:;#4:42@W[to2*7X.T,<:2@7*2@;0$?0QW,J.1.10C0Q<:K12{aM60:2@4Z,(;S5#[email protected]*;_0Q0:NS;#<. <:/;#I( <:;#4Q;#>0S0:,(W^;S.14B0:.T<QWS2{; t
;#W>.T0:2@0:0$<Q?2Y{!'ztb] 2@0
.15#>.T?S> 5OJ7@9<:4:4Q0Q06;#<:k/2@;D>RS0:<O.T.17@>Rh4¢KhM<QKh2@<Q0:WS,W[;Nv4!2*Kh>I/0Q;#K <O.1.0:;CN2@Kh4Q4:>S2@WS.[email protected]@4:<Q4:2*2@0$W[?W^2*7X.T.1<:0:2@<Q0$?2{ Wk/.1;OM0QKb<:2<:{!;a'.Tf IMzI0Q7@,?;=2*>(N(Ra.10B4Q.9J5Q.1, <Q;587*I9(<:4:;#0:4Q;;#<:>2@>0:;RN .T2*7@>RhKh0Q<Q,2@0:;L,MW[Kh<Q4W
' K1M .N.T0B.
,K1#þ 30:7@,9;S4Q0:;#`b<Q9J4a.TKTþ7*2@M
0$?[Kbý6khK1OM6Kh;<5O5O7@0Qý#94SþX4:ÿ0Q.1;#<:þ <:;S2@>#58RPþKhWS5#.TI(>Æ90:kJ;;N´.1þ k/4Q.14:4:;#;_4Qý#4:NÆ';Nù+ÆKh>ÆkJ;.T0Q0Q,4:,;;#;#N 2@><DKh4QN> 2*W[2@[email protected]:<:42@0:,2@;#K1$4Lþ
Kh<a0:,(N;S2*4QN4:2@2@4:WS#4:þ 2@2@W[7X.12*<Q7Xý#[email protected]:t<:2@;#2@0$4,?S'2X5QKTf$, >ÆM
Kb5#0Qkh.T,O> 2@;4a5Ok/4Q0Q;S;4 5O5O5#0:[email protected]>>Æ>!gbtkJ;#<:;SZ0Q;; 58N´Kh/WS0:<:K 4:I(09TN0:þ@;ýO2@4Bý8N 58þ×ÿa9M Kh4:þ 4<
Kh5OKbkhW8;k5O0:2@>J4.1N0Q;#2*Kb4O5O><:42@k/KT;MzN^0:,(k;#?P4:;þ gh.1<Q2j.Tk7@$;ý 0$?IJ3;#4_gh' .T<:2X.1k(7*;4tk? #þ sgh.1<:2X.Tk7@;#4tbk? 1ÿþ 1þ t.T>JN $þ $ý 3gh.1<Q2X.1k7@;#4_thKb<
éê Zê:ë -ñ:óóñ ñ:õ:ïøñ ðñQ÷óPïú óñ cñQõ:ïøñ¢ðñQ÷ó ÷!ïóö6ø(ñ:ú ðí6÷ ö6ïõQñ$ð1û ôõQö6óbð÷!øñQú
]^"u;_.T4:" Æ9<Q;#" X41K1"XM Tþ@ýOý8þ×ÿaþ 2@#4Zþ .>KbKb< >>T;#þ@ýORý#.1þXÿa0:2@gbþ ;Z>þ9Wk/;#<0Q,J.1þ 02@4ý65O5#[email protected]>Æ;6kJ0QKa;|L94Q;N´,;#0:> K^WS.1>J;_.1N 4:a9(<:.1;<Q;0:,>;S;.1`b<39J;.T.b7*2@5:0$,?[KbK10:M6,5O;7@<9t4:.10Q>J;#<:N2@>k/R/;'D5OKbf$WS>´;#Rh4;#7X>.T;<:<BRh.1;7$< t
,;#VL> 2@4:0:4Q,2*;#W[?^[email protected]._<Q<Q;=2@0:W[2@;#4ZKh<Q5#;=.T>PN2 k/;#;D<:Kh;#>k0_0O'.12@>;N[k?S4Q2@WSI7@;64Q9khO;580:2@gh;<B.T0:2@>Rh4W^.hN;k?.4Q;#06KTMKhk4Q;#<:gb;#<:4Kh<L;O{IJ;<:0:4Kb>,(K1wW9J5Q,
5O.1;#4C<Q0BW.T2*.1> 0Q,Kb;#khW^O;.15O0:0Q2X5O4S4_Nt/22*4C;#0:<CK M<Q.TKh>WKh0Q,;;#.b<5Qt,4:9/Kh5:0Q,,;#<_.1'4Dk(2*KbKb<a7@Kh;8Rh{(?.TtWS5OKhIW[7@;hIt92@>0Q;#<4QK[email protected];#7Z>J584O;h5O2@t;#Kb>J<D5O;bItZ,Kb?>4:;^2X5O4W'^._}L?P7@0:<O;#.1<Q0Q>J;S.1,0Q2*K1gb;#7@?58t7*KbN4:2@;[4:4:Kh2@W[>;[2*7X.T4:<:92@kh0:2@O;#;_45O05#t3.1>Æ4:9/k/5:, ;
5OKb/WS11I9(0Q;Nv" JM <:Kbk/W;#0$5O3Kb;#<:<:;#;>´7j.T0$0:Z2@KhK[>^gh5O.1K<Q;O2j.Tk5O7@;#2@;#4 >Æ0:4_'.T>JN 2@gh^;#> 2@4=^N;KhJkh>O;_;5ON 0:4s2@> MKhu<6&(5O' E 7@9#t/4Q0:;#<Q,2@;#><QRJ; t(Æ0:,.T;>JIJN .T<B.1W[.1<Q;#;a0:<Qgh2X.T5 <:2X.1k(7*;h4= /N;#4O5O<:2@k2@>R^0Q ,;aKbkhÆO;5O0Q!4 t
[email protected];>JKTN M MKb.T<Z<:0Q;D,;0Q,×;D0:,^WSKh;_kh.1O>S;_5Ogh0.T' 7@9;#4K1M .T>JN Jt(<:;#4QIJ;580:2@gh;#7@?t.1>JN 2@40:,;gh.17@9;KTM MKb<Z0Q,; ×0:,PKbkhO;5O0_t .T>JN 2@40Q,;
u&('eE
MGkKb?S,<6;W[W>Kh9Kh4:7@03>(0:2@IJ4:[email protected]<O;0Q.12*5OWS4QKh0:<Q;2X<:5#0:;#.T<:7X2X7.15 [email protected] >Ph.1Kb#Rb<6ÿ ;#4.t(W4:9J.T5Q0:,P<Q2Y{S.146KT(M
$þ5OKb<:<:5#t/;.T7j> .T}=0:.12@Kh7@4:t/>(K.14>Jt/k/N[;,92@4:7@;; 7@N94_2*' >2@4L4:9Kh4:W[;N ;DM.1KbI<6I.S7@2X5#5O.TKb0:<:2@<:Kh;>7j.T4_0:'2@Khr>Kh'60Q2Xn5O;DKb0:0:,Æ,/.15O0 K;O2@5O42@;#9>4Q0:;4DNP.T2@<:>^;D4:I0O<Q.1K10Qg2*4Q2jN0:2X;5ON 4
Cj
m
m
[
4
¥Q8'?"P¦<[XS'*)7XSQ-'
?"P¦<
<§$ZP¦<§Z&"6
A
+
>
¢£
¨ 4 i© 76
¨ 4 i© 76
¨ 4 © -6
¨ 4:© 76
¨ 4§© -6
¨ 4:ª©>«-6
f
¨ 4:ª©ª 6A
£
+4
£
£
£
4
-6
¤
7?7?
Eª
m
¨ 4§ª©>«6A
¬«
¨ 4
«-©Sª 6
-6
*b;0ym9N
3ym9N
¬
!PQ$"$17< [Q#9PQ?"
®!P ["*#&<
1<:)+PSQ7"
®xP ["*#&<
#&<"$*=
X ?P"
>|
±
²
s' #0$)
U
¥
1 W<§)
¶
²
+#0Q
\³´
U
#0
¯°QS #0
aµ
1X
S7< [Q=X *P"
t
U
1<§)PQ7"®!P ["*#&<
¨ 4:ª©>«-6
[m
1 1<:)]PQ7"®!P ["*#&<
]ª
¥«
»Y
L¸
A¸
»¶¼
¹
U·
¹
¦
94
86
¹
º¸
$
N
7ym9\m
k¹
½¸
i
cª
1¼
cª
¾¿4§¸\©¹&6À
Ä
Âo
Âo
4 1
Á
Á
4 1;Ã
Ã
¿Ç-." Y#9PQ$"$17< [Q#
6 Å Ä
» Y
64 1¼UÃ
Á
WÂo
»
4 i1¼
¼ 6
Ã
4
»Y¼ 6ÅoÆ
L¾
¥È
»
-6
m
¦ ©ª Á¦ z«©ª =¨ o« :«
>Kb>3IJ.1Kb<O>.1gbW[;#<:;#4Q0:2@<QKh2j>Æ5L5OM KhKh<:<QW<:;#9(7X.T7j0:. 2@Khu>P&(' U5OKa;O5.15O> 2@;#kJ>;[0Q49t 4:;_N 0:KÆ#\5OKhW[I90Q;N2@4:4Q2@[email protected]<:2@0$?P5OK;O5O2@;#>0Q4t #t M<:KbW;#2@0:,;<IJ.1<O.1WS;0:<:2X5Kb<
B)
hF
u&(' U
.1<Q2@2@;D0:gh,;gh>;.<:gh4:?.10Q<:<:NKb2X2*.T>4Qk4:R2@7@WS;#>4;#2@7XR.1.T2@< 0:0:#,S2@' gh;6.58,(Kh2*<:Rb<Q,;#7XIJ.1Kb0Q2*4:Kb2@0:> [email protected];6<:;65OKh.T<Q4:<:4:;#[email protected]>0Q;2@KhN>!.tb0:N,2@4:2@4Q42*W[.14Q2@4:[email protected]<:>2@0$43?6.a5OKN;O2@4Q4:2@5OWS2@;#2@>7X.10<Q0Q2*0$,J?.10o5OK2*4;O5O7@5OKb2@4:;#;>0:03K0:,J) .T0ZWS2@4Z;.T5O>7@Kb2@>4:;6R0Q0:KD,/.1~#0;#<Q0QKJ,'o;yZgh.1.1<Q<Q2j2j.T.Tkk7@7@;#;#44
>;#Rf$.1>P0Q2*gb4QKh;DW[5OKh;a<Q<:.1;#I7XI(.10Q7*2X2@5#Kh.T>P0:[email protected]<Q>(;4.Tt/4:94Q4:2*;Rb<:>4;N[W0:._,(?;DI4B<Q.T;OWSM;#;6<D,(0QK^2*Rb,S94:4Q;S2*W[5OKb2@7j>.Tgh<:;#2@0$<Q?D4:2@Khgh>.T7*9(MKh;h<Q' W97X. $&'ed t/,;#<:;gh.T<:2X.1k(7*;462@0:,Æ.[,2@Rh,PI/Kh4Q2*0Q2@gh;DKb<
)
u&('ed
}65#.T7@>0Q;#k/<:>J;D.T90:2@4Qgh;;N^7*?0QtKa90Q4Q<B;#.1<:>(4L4$WMKb._<:?DW 7@2 kJh;#;L0$30:K;#;#9> 4:;a0:,.v;Dý#0$þX3ÿKþ 5OK#þ ;O5O2@;#>0:4_#' þ 2@>4Q0:;.bNSKTM .N2@4:4Q2*W[[email protected]<:2@0$?D5OK;O5O2@;#>0' Kb<:W97X. u&('em
)
u&('em
.0:L,(Rh;D2@rsgh0:;;#Kh>a7@0:;#2XI(5O5O7@,;9Kh4:0Q>0Q,J;#;C.1<:0o2@>>>9(RKhW02@4!kJ.13;#7@<7KhKTKT<QM4:MZ;30Q.,0:,J;IJ.T;#gh>a<Q.14:<Q9(Kb2X>P4:.1;#k7@2@7@;#4;#4Q4K14tbM4:0Q,(4:;#2@Kh>P>J95O7X9;N4Q2@;#k/0!7@;;#,(4:2j2*4LN>/;#2*5O>^47@9J0:0QN,,;;3;aN95O2@4:7@>;89M4Q0:90:,(7;#;6<Q2@>2*5O>(M7@Kb9RS<:4:W^K10Q;#M.1<:I/2@0:>2@;#KbRaKh>6I(.T7*I>J;<Q.1K1.h7@g?5#2X5O4:N2@Kb4_;_<B'!NN}-2@k>?=RghKb.T0Q<:0:K2X,.1;0:k(,<7*;;ogh2*.1<0:<Q,J5Q2j.T.T,J0k.17@2@<O;#4.h45OWS' 0Q;#;<:.TKb2@><!4:0Q2@;O>2X{J5ORh4.17@t/W[;#4:4Q9/4!I5:7@0Q;h,K t
[email protected]:Rb;#;h<Qt/2*>(,RS;#2@IRh,<QK058t(;#Z4:4_;'2*Rb,0t.1>JN[4QKSKh>'69J5Q, 2@>JN^KTM Q0:<O.14:, Sgh.1<Q2X.1k7@;4:,Kb97XN[kJ;Rh2@gh;>~;#<:K^3;#2@Rh,0t(;O{J5O7@9JN2@>RS2@03M<QKhW0Q,;
éê Zê úoð÷!ø ïõ 1óôïzõQ÷ ïøñ:ï 6õQ÷!ó
G94Q,;2@N 4!4QM;Kh5O<D0Q2*5OKbKb> WSNI2*9(4O5O0:92@>4Q4:RS;#40Q,þ ;SN2@4:4Q2@WS$ý [email protected]<:2@0$?KTM
#þ KbkhO8;ý 5O0Q.14a>/NN;#0:4O,5O;<:2*2@<k/4:;0ONù.1>JkN? .T<B2*>N0Q2@~;#.T<:gh0:[email protected]$>4B'5.1f$0!7@;0QN ,;#gh>a.1<:N2X;.T4Bk5O7@<Q;#2*4k/'C;#4ZG58,Kh;#WS4:;[W[WSKh>6;.TN4:2@94Q0B<Q.1;#4>/5O2@;Z>J5OW[7@9J;N.1;4Q90Q<:,;;4
Yþ B t.11>/" N P þ .T<:;^ý 5OKhþ >T0:þ@2@ý>9Kb94aOý#W[' ;.14Q9<:;WS;#>0:4CK1M=.^<QKh9Rb,7@? 7@2@>;.T<a4O5#.17@;h'´G3?I(2j5.17;O{J.TWSI7@;#4D2@>J587*9/N;
3;#2@RhG,,06;C.1WS>JNv;.T,4:;#92@<QRh;#,WS0_t;#7X>.10L0Q2*90Q>9J2@N06;9.14Q>J;N[N´7@5#Kh.1>>ÆRb2@. 0:9J;N5O;05O0:K,(Kh; <ON5O2@7@>J9.14Q0:0Q;#;#<Q4 2@>;hRP' RJ.1'@>Jth.T7*,(?4Q;#2*> 4_' 5O7@(9Kh4Q<L0:;#;O<Q{J2*>(.1RW[,IKh7@;h9tJ4Q;#5Q4,J.Tt>.1Rh>J2@>N[R[3WS;.1;0Q.T,4:;#9<<Q;#0:WS;WS;#>I/0;#<B9.T>(0:2*90Q<Q4;ht/' 4:9/5:,
.15O7@495Q4Q,J0:;#.1<Q>2*>(RbR2@>4QR0:<QM9J<QKh5OW 0:9(<:WS;h';#0Qf$;#> <:4LRh0:;#K[>;2*<B>/.15:7$,(t;#;84L{MI(Kh<:<L;#4Q,4:;#2@>2@RhR ,0.vt/ghKb.1<<:M2X<Q.TKhkW 7@;D2@>P2@7@Kh4:RbW^<B.T.1WS7@7@;#4<0Q9KS>I/2@0:Kh4L9>JN2@7*467@M ;Kh.b<6N^30:;#K^[email protected],0_7Xt.T<:WRh;._<6?<[email protected];.b>N^Rh;C0:K^MKb.<60:gb,/;#.1<:?P0ghN.12 <Q2j;#.T<:k;#7@>;h0 t
9G.1>/>,N2@2@0Q440:t,2@460Q9,4ZIJ;D.T.L<:N7X0:.1.12X5O0O<Q9(.DRh7j;#4Q.T<,<:;7@Kh?^9(;7j958N[4:0Z;8k/KbM;9>a74:0Q0B,.T;,>J;N<:> ;#.T4Q<B9RbN2*7@2@gb0:~#2@;#;>>PNRa'Z>58K[7*9(0OI4:.10:<:>J;2@NKb<:[email protected]< ><BRDN>2@4Q~#K10:2@<:>9/R7@5O;0:WSN9Rh;_<Q;D;h.1'34:KT9(MZG<:0:K6;#,W[,;;#;#N7@>IS.T0:40B._.gb.1'DKh0:0Q2Xs;#NDWSK1NZI(;#;I/0:gh43;#;#>J0:<_KNt;#Rh2@>J>P2@5Ogb;D4:;=KbKb.1WS>a7@7/;a0Qgh,.T.1;6I<Q2jI5Q.T,7@k2XKh5#7@2X;#.15O40Q;2*.1KbKT>^>M 4W[;t(`bIJ;9J.1;.1Kh4Q79I3<:7@;;;#WS2@WRh;#,._>0_? 0 '
2@kJ>.T0:4 ;#h>;0:0:[email protected]>J7*.17@7@I?Æ7X._
?h;#.T<>05#.T0:>JKÆ[email protected];;#4W[t(KhKh<Q>;;3W^;#._2@?aRh,7@02 h;L0QK0:K.ÆRh5O2@;#gb<:;60O.1WS2@>-Kb<:;L4Q;#Z0^;#K12@RbMD,gh0.10Q<QKa2j.T0Qk,7@;#;D4gh0:.T,J<:.T2X.1>-k7@Kh;L0Q,,;#;#2@<:Rh4_,' 0' (Kh<;O{J.1W[I7@;ht,(;#>w5O7@94Q0:;#<Q2*>(R
WS;_.1G4:K^9(<:4:;#0OW[.1>J;#>N0:.T43<BNMKb2@~#<
;.W[gh;.T.1<:2X4Q.19k<:7@;; WS;#t/>0:0:,4_t!2@46Kb5#>.T;S>5Qk/,Kh;2XIJ5O;[;<$2@M4=Kb<:0QWSK ;_5ONKb>.Tgb43;#M<:Kh07@7@0:K1,(;4'Kh<:2@Rb2*>/.17WS;.T4:9<Q;#WS;>0Q40:KP9>(2*0Q7@;#4:4gh.1<Q2j.Tk7@;#4'[2@gh;#>
)b'.17X5O97X.10Q;0:,; Æ / z_ " " / t t
)
u&('eq
,;#<:;
.1<Q; WS;.T4:9<Q;#4K1M !t/.1>JN 2@4Z0Q,;Sÿ gh.17@9;6KTM !t(2u' ;h'@t
#'
F('.17X5O97X.10Q;0:,; " h ÆJ#1 Æ! t15#.17@7@;N O J1 t.143M Kh7@7@K14t
u&('e&
G0:,,;D;6W[W[;;.1.1>^>S.1.Tkk4Q4:KhKb7@7*99(0Q0:;;6NN;#;#gg2j2X.T.10:0Q2@2@KhKh>>!tt 0:,;DtbN2@4Z;#gW[2X.1Kh0Q<:2@;3Kh<:>Kb43kM9<QKh4Q0Wc0:KD0Q,Kb;D90:W[7@2@;;#.1<:43> 0:,/2$.1' ;h>'@t 0:,(;=4Q0B.T>JN.1<ONS.TN<:;D;g>2X.TKb0:02@Kh4B>!`b9Jt .T<:;'N+-t(,,;#;#>J>^58;a5OKh0QW[,;DI;90:2@;>5OR0
K1MZKbþ 90:u7@þ 2@;#<:4'32@4K14:3Kb;#WSgh;#;#<_t,J0Q.T,06;a<Q.h;NNgh9J.15O>;_0BN.T'Rh;6GKT,Mz;#<:9;[email protected]><:R;0:WS,;CKb<:WS;D;<Q.TKh>k9.14Qk(0D4:KhWS7@9;_0Q.1;D4:9(N<:;#;#g42X.1K10:M2@KbN>S2@4:I/2@4;#<:0:4Q,J2*.TKb0>!0:t,4Q;C9J5Q~O,iu4O5O.1Kh4<Q0:;#,4;^K1Mÿ Kh9T0Qþ 7*2@;#<Q46ONý K>Kb0
kJ;58KhWS;0QKK4:W^.17@7$th,(;#>J5O;D0Q,;Kh90Q7@2*;<:4<:;W.12@>^N;#0:;_5O0B.Tk7@;h'
A@CBED
(4
AFHG3I
AJCK
AFB
5BLJNM
&O
¨ 4§¸\©¹&6
&6
g¾¿4§¸\©¹&6
¨ 4§¸\©¹36À
4
¾¿4§¸\©¹&66É
Ã
4
36
4
-6
Æ
E4
6
Y4
¨ 4:¸\©¹&6À
1
-6
Ã!Ê ¾;4:¸\©¹&6 Ê
1<:)cPQ?"
®!P ["*#&<NË4§ª©:«-6
Ë4:ª©>«-6À
v
¿4
¨ 4§ª©>«6
-6
Ã
4
-6
o
+
>|
:|
Î
&Ï
:Ð
NHÏ
u
y
+Ô
iÍ
Ñ
#&<"*$=
X ?P1"S/
ÒÓZP* [8"S#&¯AÔs#TRT7< <#
¥Ì
#TÕQÖ
-'*"
Õ Ó
<>#0P"
!
;4
S6
7
L
¦
L
×
1
U¸
m
$
]
Ë
g: ©
Æ1Æ
© i-
c
A
&
4 Ê :EÃ
A¸
-
Ù m
8Ë
»
NÊ$ØÊ Å EÃ
»
?7 ØaÊ -/Ã
_Ê*Ø
Y"S#
»Y
&m
Ù-y
Ú*
Ó¸
»Y
NÊ 6
»
4
g:
4
Ø
Å
Ø
?7 Ø
-6
i- 6
1
Ã
Ë
»Y
4
-6
Æ
&Ë
8Û
k4
Ê 1EÃ
»
Ê6
Ü
Y"S [#8' ?QZ8<>"
-"* [=<
Q#
-© ªo«Æ§ L© :¨
¦ «©ª :¨ ¨ « :«
q
I/;#<$M}sKb0O<:M.10:W >J;#<N(4:.14Q0O0B.1<B.TN>J>J2*N~_N.T.1.1<B0:<ON2@KbN2@~>P2@~.T.1W0:0Q2@Kh2@._Kh>^?[>!4QtKh,Kb<6Kh<W^97X._N[2*?S0Qk/,>;=KhKb9(7@0;O0M kJ04:0B;0:.TK>J94QN9;O.T4:M;#<B9<QN7o42@~'2*>´.T0:.S2@Kh>[I/.12*<:>P0Q2X5O5O;9<:7X0B.1.T<2@> .1I.TII7@I2X5#[email protected]#0:.12@0QKh2@>!Kh'>4_Gt,Z9;D45O0QKb,WS; I5Q9,0QKb;62X5O0Q;,;aK1MZN2@4:4Q,(2@;#WS0:,2@7X;.1<a<:[email protected]$?>JN Kb,<K14:2@WS0Q2K i
7XK1.1M!<QKb2*0$kh? O;5Ok/0Q;#40$'3G;#;#,>^;<:0:;D,(.1;=<QKb;6kh.LO;M5O;#0Q-4'.1I(I2@gb<:K;#>S.h5Q2@,>;#0:43;#<Q0:ghKa.1N7i$; 4BJ5#.T>7*2@;_>NRDgh0Q.1,<:;=2X.TNk2*4Q7@;#0B4.Ttb>J0:5O,;62@4k/;#2@430$30$?;#I;#>^2X5#.1Kh7@kh7@8?D;kJ5O0:.T4_4:';N[G,Kh;6>W[0Q,Kh;D4Q0zN2@I/4:Kh0O.1I(>J95O7X.1;L<kJN;2@0$4:Z0O.1;#>J;>5O;L;_WS.h5Q;,^.T4:IJ9.1<Q2@;<
2@4 " ! "u( t1,2X5Q,2@46N; J>;NP.T4
u&('ex
,;#}L<Q; >Kh0Q,;#<3;#7@7Yi >K1>SW[;##0:t<Q.T2X5>JN 2@4
#t/.1<:;0$3K i:N2@WS;#>(4:2@Khth>JN.T; 7J/N>.T;0BN^.CkKh? khO;580:4'
_ / " # "u_ u&'@)_|
M9>/5Ono0:Kh2@Kh0Q>,\ 0:,;69/5O7@2jN;.1>[email protected]>/5O;6.1>JN] .1>,J.T0:0O.1>N2@4:0B.T>J5O;L4B.10Q2@4$M?D0Q,;M Kh7@7@K12*>(RW.10Q,;#W^.10:2X5<:;_`h9(2*<Q;#WS;>0Q4K1M!.N2@4:0O.1>J5O;
)b'
|(\!G,(2*44Q0B.T0:;#4L0:,J.T06N2@4:0B.T>J5O;D2@4.>Kh>(>;#R.T0:2@gh;>9Wk/;#<
F(' -|\G,(2*44Q0B.T0:;#4L0:,J.T00:,;DN2@4:0O.1>J58;DK1M.1>^KhkhO;_5O060QKa2@0:4Q;#7M2*46|
E('
#\G,2@44:0B.T0:;#4L0:,J.T06N2@4:0O.1>J5O;C2*46.C4:?W[WS;#0Q<:2X5oM9>J580:2@Kh> .T>JN
U/' a2@4>KWSKb<:;60Q,J.1>^W^. 2@>\RDG.,N2@4;#0:2@Kb469. <K1ghþ ;<6.1>?=Kh0Qþ ,;#<6I/Khþ2@>0 !,' 2X5:,^4Q0B.10Q;#460Q,J.10RbKh2@>RN2@<:;580:7@?[M<:KbWcIJKb2@>0 o0:KI/Kh2@>0
" " "u( 2@4.Rh;#>(;#<B.T7*2@~.T0:2@Kh>[K1Mk/Kh0:,P9/5O7@2jN;.1>PN2@4:0O.1>J58;.T>JN^]P.1>(,J.10Q0B.1>[email protected]>/5O;h'f$02@46N; J>(;NP.14
u&'@)b)
,;#f <QM; ;.b5:2@, 46.Cgh.1IJ<:Kb2X.T4:k2@0:7@2@;6gh;L2@462@>.10Q4Q;#4:Rh2@Rh;><;_'NPf$0.<:;ZI;<:2*;#Rb4Q,;#06>0:.h45#5O0:Kb,(<B;N2@] >R[.1>0:,JK.T2@0:0:0O4.1>I/;#N<O2*5O4Q;#[email protected]>J;N5O;2@WS,I/;#Kh> <Q0B.1>/l5O;h)btt0Q.1,>J; N[9Jþ 5O7@2XN;S.T>9/N5O2@7@4Q2j0BN.1;>/.15O> ;DN2*4Q,0B;#.T> >J5O;aw5#.TF(> '
k/;a5OKhW[I90Q;NS.T43MKh7@7@K14'
u&'@)_F
+Æ;#2@Rh,0Q2*>(Ra5#.1>´.17@4:KkJ;D.TII7@2@;N[0:K0:,;a] .1>,J.T0:0O.1>.T>JN^]^2@> hK14 2!N2@4:0B.T>J5O;#4_'
éê Zê Æñ:úLïzøû ïøñQï Lõ:÷ó
Gþ ,2@44:;580:2@Kh#þ>SN;84Bý#5O' <Q2*k/;#43,K1Æ0:KD5OKbWSI9(0:;0Q,;6N2@4:4Q2*W[[email protected]<:2@0$?k/;#0$Z;;#>KhkhO;_5O0:4ZN;#4B5O<Q2@kJ;Nvk?=;2*0Q,;#<ý 1ÿÿ #þ Kh< _ý 1ÿÿ þ
2@|462@I>J}<QN;#2X4:5#;.T>" 0:z0_;#'(4L10: ,[email protected]0;#(>^0:1,"0:;D,(;aI/ .1gh0:.T2@,J;#<:2X.1>.1406kKbN7@;>K7@;#ý#?S4Lÿ 0$>3KhK0_'4:G0ON.1<:;#0:;4B;.T584<:0:\2@2@k>|2@R>KbRk<D2@>J.[)h.TtIJ<:?.T,(0:gh2@;#;#.1<:><Q;a02X.1t(|vkMKbWS7@;#<646;[email protected]>>44Q430B2Y.1M0:>/,J0:5O,.T;h06;t? 0:)C,(.T;D2*<:>/;DghN.12@2X><Q5#2j0:.1.T;0Qk<:;#gh7@4;6.10:72@i$,J464B.T5#.106.Tk(7@0:4:;,(;#NS>;a5#0IJ.Tt.T>P.T0:>J2@7@;#;N´>.h06N[)4QWS0QWSK;K .TWSh>2@;#44:4_7@0:tJ;,J.b.TN,(062@>2*7@2@R;0
5O7@94QL0:;#><Q;2*>(.1RSI<:I;<Q4:K9.b7@0:5:4_,'2@G40Q,Ka;<:5O;OKbMWSKb<:I;h9t/0QW[;6;#.D0:,NK2@4:N4Q432@WS4:I/2@7X;.15O<:2 2@0$5?L0:WK.1k0Q<:2@>J2{D.T<:M?<QKhN(W.10B0:.,;L.1<QRh;2@gh>;#;>5O;#k(4Q2*4B>/.T.1<:<:?^?MNKb.T<60B5O.Kh'W[f MzI.197@0Q72*>(k(Ra2*>/N.12@<:4:?4Q2*ghW[.1<[email protected]<:k2@7@0:;#2@;#4Z4_.T' <:;0Q,Kh9Rb,0
K1;`bM9J.1.T47Z,/)L._gMKb2@><RCkJ0:Kb,0:;,^4BKh.TkhWSO;_;5O0:34 ;#[email protected],>J0Ntb3;6t ,JL._2@gb4;=0:,.D;DF >iuk9?bWi¢FCk/;#5O<3Kh>K10:M2@>gh.1Rb<Q;#2X>J.15Ok?7@;#0O43.10:k,J7@;h.Tt06G;.T`[email protected];67&)L'@)hMKhtb<Kb,kh;#O<Q;;5OC0 2@4Zk(0Q9,0;0:>,J9.TW0=kJ.T;<:<;DK1|CM!MghKh.T<<:2XKb.1khkO7@;;#5O4o0 0:,Jt .T0
2@;46`b9J0Q,.T;a7z|>9MKhW<k/k/;#Kh<L0QK1,MZKbghkh.TO<:;2X5O.10Qk4 7@;#4.T0Q>J,JN .10';`bG9J,(.T;D70:|KbM0BKb.1<7>Kh9khOW;k/580 ;#<3K1k(M9gh0.1;<:2X`b.T9Jk.17@7;#4Z)2@4M Kh<6tKbkh,O;;#5O<:0; t.1>JN 2@460Q,;>9(' WkJ;#<LK1MZgh.T<:2X.1k(7*;40:,J.T0
0:,(;#<:}c;D2@k(4'a2*>/>.1K2@<:WS?I(2@<:7Xgh;O.1M.1<Q;<:2@<:0$2X;#.T?a>JkkJ587@;a;a.T4:2@Kb;4 >N Kh >´,(2j4:5QÆ?,[W[KhWS910O";#5O[0QKh<:W[2Y2XM5L;6k/k4:Kh2@,(>J0:Kh,Æ.19<Q?KT7XN[[email protected]:;D<:4D2X.15O4QKk(0B.1N7*;0Q;_46;#NP42@4=.1.1465#<:;[.T|C7@7*;Kh;_`b<DN 9J)b.1" ' 7@7@?P6>(gh1;D.T" 7*4:9/!9J.15Qk,^7@;";OÆ{J.1.1>J" W[NÆ(I15#7@"X.T;=#<: <Q5O?ÆKb2@9> 0:7X,N0Q;,Jk/.14O;S0L.1WSÿ0:,;;3<Q;#;#.T4:2@>J9RhN ,7@0D0_t!Nÿ0QK,J;#4.10D>2@Kb2@4_> 0 t
G3I
iI
UMAD
CCB
0BO
AJCK
AF5O ;!B
CBEJNM
&O
¬4
6
UÝ
:
Þ
¦
¨ 4:ª©>«6½×ß
cªNâ4 © ©
Å
:
Æ?Æ7Æ
©
6
4 Ê
-à Ê Å
Ã
¶«¥â4 à © à ©
Å
Ul
Æ Æ7Æ
7
ã
d
¨ 4§ª©>«6A
Ê i
ØáÊ Å
© à 6
7? ØÊ i
Ø
[
pä;
-à Å Ê$Ø
Ã
-6
8à Ê
Ã
4
-6
4
?6
Æ
?`
¨ 4:ª©ª 6A
i`
¨ 4:ª©>«-6A
¨ 4
«©ª 6
¨ 4:ª©>«-6vç
¨ 4§ª©Sè\6 Ø
N`
¨ 4§èo©>«6
«
<§ [#&%Z&
#0"é$Z 1<:)
p0b
4
Æ
?7 ØáÊ i
¨ 4:ª©>«-6væ
l
8à Ê Å
Ã
;
8à Ê*ØåÊ i Å
Ã
-à Å Ê Å
Ã
Uª
Cè
*p Ó
¨ 4§ª©:«-6a4 Ê Ã
à=Ê êØÊ Å
à Å Ê êØ
Ã
?7 ØáÊ
UÃ
cì
ë ©
à0Ê ê 6
ê
+ìE
+ì/
ÖÓ" 1%7R-<"
¨ 4:ª©>«6½
ß
í
Ê [Ã
à=Ê Å
í
Ø
Å Ê Å
Ã
>|
[î
ï
eÏ
à Å ÊÅ
Ø
77 Ø
í
à\Ê Å
gÊ
EÃ
4
-6
Æ
Ñ
$)
º"¦<: [P
U $)
º"¦<§ [P
' #0*)Y= [-'*"
9
ºQ=Õ"*
8
¥ð
;ª
¶« gñ
Eª
cª
Lª
¶«
gm9m
A
5« \ò
¨
/«
/+×ð
Ø
ñ
Ø
ò
Ø
¨
Y"
%-"$#08"$
N
[m
¬V?" º"
&
¦ ©ª Á¦ z«©ª =¨ o« :«
A@CBED
Kb) khO;5O0 | 4:9W
AFHG3I
AJCK
AFB
5BLJNM
&O
v«
hK khO;580 4:9|) W
G.Tk7@;=&'@)b\!}l5OKb>0:2@>Rh;>J5O?^0B.Tk7@;MKb<k2@>J.1<Q?gh.1<:2X.Tk7@;#4'
5Q5O,JK;O.1>(Rh5O;62@;#>0L,(;#2*4>S0Q4Q,Kh; WS#;" Kb<Z.17@ 7KTÆM!0:, ;Lzk" 2@>J.1<Q?agh .T<:2X.1k(" 7*;!4Z .1t<QN;=; 5OJK>N;;N^N[2@>N2 u&;'@<:)_;#E>#0:'7@?' Kb<2@>gh.1<:2X.T>04:2@[email protected]<Q2@0:2@;#4t_0Q,;6W[Kh4:03;#7@7i >K1>
u&'@)_E
.0:1,(>/;N }
<B.1<Qk;#2@4:>J03$.Tþ Kh<:?^>(;hKhghth9.1k<Q0O?S2j5O.TKh)kW[7@;D;h;#4' 2@RJ4 KT'@tJM . N2@4:Æ;_.Tý#4:;þ$1þ " 8ý u2t'MZ.Tno0Q>J,?SNC;5O0:KhKh,9>;0OghKb5O;Kh0:>,W[0Q;#2@Kh;#<34>!ktK1?a3MZ| ;60Q,4Q;h;a,J' R/.14Q0B'*7@t7.T0:5O;#K4aN;.T<:0:;,;>KbWS$06þ Kb;4:#`b0'9J2@G.TW[7@,7*IJ?^;[email protected]<:WS0BRh.T<:I/>;Kh0z;#<QWSKb0B9.T;#>0B>580_0Kht/KTWS4:M 9J;b0$5Q3th,ÆK.1,) 42X5Q4 0:,S,u.;2@43I/9Kh_4:4Qý#9/2@þ 0:.1$2@þ7@gh7@? ;
W5#.T.T>ò0B5Q.h, 580:9J2@4.T7*@0:?P,;k/> ;5858KhKh>>4Q4Q2j2jNN;#;#<:<:;;NùNùW[.14aKh<:. ;:4Q92@Rh>J>.T2 <:?´5#.Tgh>.10a<Q2j0Q.T,Jk.17@;>ùJ'[0:,JG.T0a,;KTM=4Q2*0$W[[email protected]~#<:;#2@0$<Q?SKh4 k/.1$.P4:;_NÆ>(;#KhR>Æ.T0:2@4Qgh9J;5Q,W^gh.1.T0B<:5Q2X, .1k'Æ7@;#49J2@4a5Q,ò5#.T. 7@7*;_:Nk2@>J .T/<:? "P gh.T<:12X".1(k!7@;
u&(" Æ'@)#U" (th1"O,( ;#<:' ;0:Kb,(<D;=>>Kb9>W2@>k/gh;#.T<<:KT2X.1Mz>>0;R4:[email protected][0Q2@2*gh7X.T;6<:W^2@0:[email protected];#0O4_5:tJ,(0Q;#,4;St W[tKh2*44Q0=5OKb3>;#4:7@2X7Ni ;#<Q>;K1N[9>Æ>5O2@WSK;OI/Kh5O<Q2@0B;#.T>>0[email protected]>J0:Nv,0:; ,943 2*432@Rh >Kb<:;Nv 2@>S0:,(" ;=!5O KbtWSNI; 9J0O>.1;_0QN2*Kb2@>!> '
u&'@)U
N;#4O5O+-<:2@k/,(;;#N>kJ2*>^Kb0:,;5O4Q0Q?2@W[Kh> WS&(;#' 0QF(<:'e2XdD55#.T.1>J>^Nk/.1;D4Q?.1W[IWSI7@;#2@;0QN<:2X' 5k2@>J.T<:?gh.1<Q2j.Tk7@;#4K5#5O9<32@>0:,;L4B.1W[;
N(.10B.4:;#0_t0:,;W[2Y{;NCgh.1<Q2X.1k7@;#4.1I(I<:K.h5Q,
0:4:,(?W[; .TWS0:;#0:z<Q0Q2@<: k2XP590:.1;0Q4 0:<:2@kT9(ÿ "$0:_;h#t/" Æ.1>J"N[×0:1,("X#;D <:;#W^ .1C2@>2@>RD.10Q"0:<Q82*k(ý 19 0:;#4.1O1ý<Q" ; .T4:?WS8ý W[h9(;#t/0:I<Q.1IJ2X>J51Kb'N 4:;L0:8,Jý .T0Z(t.LIJ,.10Q;#2*<Q;; >0oT<:;ÿ 5OKb<[email protected]>Pk(7*Kh;bkhthOG;_5O.10$k(i$7*2X;Nt&'eF(t 58Kh>0B.T2@2*4=>(.4
ð
Lª
ñ
ð
ð
¨
ò
ò
Ø
ñ
¨
Ø
m9
d
m
8ó
¦
ð
¥4
&õCö÷Y.Q
1< "6
ò
ñ
Ø
ò
4
-6
¨
Ø
¿4
Tõ°ö÷#0">%-7< ="6
1< "
-z v4
+4
06
øÌ
&Í
$Í
Y
§
ù
-
-
8ó
o
¨
36
ñ
¨ 4§ª©:«-6À
im9
Ø
Ø
ñ
Y.Q
xÌ
Ý
§
-6
¬<>" <
06
4
gm9m
+#0">%-7< ="
[m
Ø
¨
A
k4
¨ 4:ª©>«-6ô
ñ
Ø
ò
gú
û
j
m
$b
ð
ò
Ø
ñ
Ø
Ø
4
ò
36
ú
c#0 º"¦¯Ó%-"*#0-"*¯gV?"$"*¯°PQZ8%7R-¯v<>" <[Xü¯Ó<" < Xý¯A<" S< Xþ
2<>" <[X[ÿ
#0 º"
o%"*#0-"*
>J.TWS; Rh;#>JN;#< M;#gh;< 58Kh9Rb, 0:;#4Q0$i#) 0Q;#4:0¢i¢F 0:;4:0$i:E 0Q;#4:0¢iuU
][email protected] 5 <:? ]] rr r rrr rr rrr
'' '' '' '' '' '' '' ''
G.1k7@;=&('eF\}<:;#7X.10Q2@Kh>J.T7J0O.1k7@;D5OKh>0O.12@>2@>RWSKh4Q0:7@?k2@>J.1<Q?S.10:0Q<:2@k90Q;#4'
N5OK2@4:;O0O(.1Kh>J5O<2@58;#;D.1>4:kJ0s?;W[M0$KhZ<QWSW;#;#;90Q> <:7X2X. Kb5kh$.1&O0Q;'@0:)#5O<QU0Q2*4k(#t90QI/0:,;3.1;D0:[email protected];#7@>2@94:0Q0B;#4 .T4_>Jt12@7@5O4;#;D05Ok/Kh0:,;#W[0$;3Igh9;#.T;#0:7@>P;_9N;#;_4 kJ.hl5Q.T,P4:;.1IJN^>J.TN Kb2*<3> 7@K1?SMk/;0:Kb,>4:;C;#0Q0o0:,,0:;aK<Q;#.T)h;D4:th?IJ.TWS.T>J0:W[NC2@;#0:;#>,0:0:<Q;4_2j53t gh..Tghb7*.T9(5 <:; 2X.1tck(] 7*;k/.14;<:'?^4:}=;.105>J5O0:
NKhKD<Ob2N|*2@'W´>RSth94Q0QI(,KIJKhKb0:9(,4:7j;;Nv0:.kJ,/h;b.15#t05.10Q,<BN ;
|F | ) ) ¤| EbE
u&'@)_d
)) ) ) ) ¤| mbq
#
u&'@)_m
u&'@)_q
) ) ) F F ¤| qbd
G.1>/,N;#4Q] ;a.1W[<:?^;.1.14Q9<Q;=<:;0QWS,;D;#>W[0:4Kh4:4Q0o9Rh7*2 Rbb;#;#4:7@0?0Q0:,JK.1,J0 ._h2gb@;=W ..T4:>J2@W[N^2*]P7X.T.1< <QN?P2*4Q.1;<:.1;C4Q;h9' >7@2 h;#7@?S0QK,J._gh;.4:2@[email protected]<N2@4:;.T4:;h'LM30:,;D0Q,<:;;aIJ.T0:2@;#>0:4_t .h5 ;4
;4
S6
&6
¨ 4«-ð3ò g© »
¨ 4
«ð&ò g©>«-ª »
¨ 4
«ª »
© »
ñ
ð&È -6À
ð
ñ
Ø
ñ
6
ð&È 86
ò
Ø
ð
ñ
ñ
Ø
Ø
Ø
ò
Ø
Ø
4
-6
4
-6
Æ
Ø
-6
Ø
ò
ñ
1
1
Ø
4
Æ
Ø
ò
Ø
Ø
ò
Ø
Ø
ð
Ø
ò
Ø
Ø
Æ
-© ªo«Æ§ L© :¨
¦ «©ª :¨ ¨ « :«
x
éê Zê cñ:úLïzõ ø 6ñQú6ïõïú øïðñ óôïõ:÷ ïzø(ñ:ï 6õQ÷!ó
G4B5,.12@7@4;N^4:;gh58.T0:<:[email protected]>k7@N;#2@4_4O' 5O94:4Q;#4,K1l0QK5OKbWSI90Q;a0Q,;SN2@4:4Q2@[email protected]<:2@0$?k/;#0$3;#;#>ÆKhkh8;5O0:4N;#4B58<:2@kJ;_NÆk?P>KbWS2@>J.17$tKb<BN2@>J.T7ut.T>JNP<O.10Q2*KTi
Æ" 1" };O{J.1 W[IÆ7@;h"t/ÿ (1" o 2@46.2@4a>.^KhW[Rb;#2*>/>;#.1<[email protected]@~<:.12X.10Qk2*Kb7@>;L0:KT,JM6.T0:0,W;[._k?2@>J,J.1._<Qgh?P;htgh.14O._<Q2X?.1t k/7@gh;;2*>Æ4:0O.10Q,J0:;.140C\ 2*05#.1>Æ0O. h;Kb>ÆWSKb<:J;þ 0:,J.Tt/>Æ.1>J0$N ZKP4Q0B#.T' 0:;#4_' (Kh<
2@4:>I/0:;;#5ORb2 ;#;#0<:5C4_0:t!Kh,<O4Q;CN9J;#5Q><Q, 9(2*>(W.TRJ4 kJ' ;#)b<3tK1FMt4Q'#0B'_.1'#0Qt ;#46
KT'DM .rsKh>0QKb2jWS58;a2@>J0Q.T,J7.1gh0.14:<Q9/2j.T5:,Æk7@;62@>k/0:;;Rh
;#<Q4'.TG<:,;;D94Q4:0B;_.TN0:;#O494:5#0L.1>^MKbk/<=;aN.TN0B;#.[>Kb,J0:.T;>JN Nk7@2@?[>RS7@;#0:.10Q>J;#N´<:4_NtJK[4Q?>WKhkJ0Kb<:7*;4_Ith<:Kb;#<64Q;#.>04:;#0L.T>K1? M
u&('@)G& ,\ ;^N2@4:4Q2*W[[email protected]<:2@0$?^kJ;0$Z;#;>ò0$3K´KhkhO;580:4 .1>JN 5#.1>ùkJ;P5OKbWSI90Q;N´94Q2*>(R 0Q,; " Æ " .TII<:K.h5Q,ò.T4a2@>
u&'@)_&
0:,(,;=;#<Q0Q;Kh0O.17/>2@469(W0Q,kJ;;#><39(K1WM!ghkJ.T;#<:<2X.1KTk(M=7*;ÿ 4'+Æ;#O2@ý Rh,2$0:'4;b'*5#t(.10:>[,;CkJ;D>9(.TW4:4:2@kJRb;#><L;NK1MZ0QghKa.T2@<:>J2X.158<:k(;7*.T;4:43;DMKh0Q<L,;6; ,2X;5:,5O0LZK1.TM >JN tKh<3.1<Q0:;[email protected]>^4Q4:0:2@,(Rh;a>[4ORh.1<QWS;.1;0Q;#4Q<0B.1Z0Q;; 2*#Rbt,.10Z>J0QN Ka0Q,2@;4
W.T0Brs5Q,Kh;#WS42@2@>J>[.T7gh.1gh<:.12X<Q.T2jk.T7@k;#7@4Z;#4=,/._5g.1>´2@>RkJ;.;#7X>/.1<Q5ORhK;#N<;N´>9kW? k/.;#<37X.TK1<:MzRh4Q;0B.T>0:9;#W4_' k/;#<6KTM
.14Q?W[WS;#0Q<:2X5Lk2@>J.1<Q?Pgh.1<Q2X.1k7@;#4Lk?P5O<Q;.10Q2@>R .>(;#
k2@>J.1<Q?
gh0:,/.1.1<Q2X03.14:[email protected];L0:M;Kh2@<L4Z;4Q.h;#5Q0,P0:K^KTM)h0:t,; ,(2*7@;>0Q,Kh;W[<:2@;#>JW^.17/.14:2@>0O.12@>0:;R4k' 2@>JKb.1<=<Q?.1>^gh.1Kb<Q2jkh.TOk;7@5O;#04Z.T<:2@0:;6, 4Q;#.0Rb0:2@Kgh;#|>P' 4Q(0BKh.T<30:;;O{Jgh.1.1W[7@9I;h7@t(;h0:t1,0Q;DKak(;#>/2*>/5O.1K<:N?^;gh0:.T,<:;2X.1>kKb7@WS;2@<:>J;I.17<:;#gh4Q.T;#<:>2X0:.12@k>7@R ;
ÿ th0Q,#; t.k2@>J^.T<:gh?[.1<Qgh2X.1.1<:[email protected];3k2*7@43;a4:5#;.10Z> 0QKkJ;)bth5O<:;_,.12@0:7@;_;N 0:,(MKh;6<L<:;;W.h5Q.1,´2@>K12@M>RL0:,M; Kb9J<gbgh; .T5O<:Kb2X.17@Khk<:7@4L;#437@2*.14Q<:0:;L;N 4:;#.103k/0:K1Kgh;h|''GKb,<=;.TN>P2@4:4:Kh2@khW[O;_2*7X5O.T0<:2@,J0$?=._g5O2*K>(;ORS0:58,(2*;;>5O03KbM7@KhKh<<
0:,(2*43M Kh<:W K1M;#>J5OKN2@>RS5.1>^kJ;D5#.T7X5O97X.10Q;N[94:2@>R0Q,;WS;#0Q,KN46N2@4B5O9(4:4:;_N^2@> ;5O0:2@Kb> &('eF'eE'
" (1" }2@> .v"uWS;1.T>_2@>JR1M 97!" 4Q;`b 9;#>J15O";b 'SL <BN<Q;#2@>J4:;.TW7ghk.17@;#<Q42j.T.6k7@>(;#Kh4=WS.T2@<:>J;.Tgh71;#gh<Q.1?P<Q2j9.Tk4Q;O7@M;h9t_7;O{JM Kh5O;#<I<:03;#Rb0:,/2@4:.10:0;<:0:2@,>; R^ 4:9kh4:80O;.15O0:0:;2@4gbK1;MJ.10Q4Q,4:;;#4QKh4:<OW[N2@;#>J>.10:74DghKT.TM
7*9(`b;Z9J.1.1<Q7@;2@0:2@Kh;#<B4LN0:;#,J<:;.TN 0
5#.1.T4Q4:>2@>4:0OKh.103>k/0t;=.1W[4:4Q;K.15O4Q2X9.1<:0:;_;bNtz.TKh>Jkh8N^;5OM 90:2@7@gb7u'L;#7@?} ' /Kb<Z!_;8"{(.T WSJI7@;h tTJI <:KTM" ;#z4:4Q(2@ Kh>J.T71"<B .1> 4.17@K<QK;K14=M0Q7@;#2 h>S;;#.>94:W[;0D;#<BK1.TM
0:58;KhNv>2@0:>S2@>.D9Kh4Q;9(`b49N(;#>.10B0:.[2X.17KTM
Kb<B.1N>´;<9t> 4:9/>5:,PK1.T> 4
4B<B5.T.1> 7@;h2@t>0:R,/2*.1>0.L2@4IJtT0:.1,<Q0:;L2X5O<:9;#7X7X.1.T0Q<z2@gh4QIJ;3KbKh<:<B0N2@;#4<:2@K1>M RD0:;#KT>M!WS0:,Kb;<:;gh.T;#4Q7@94:;#;#>[email protected];#4:0Q4Q,J;#.1>>0:2X0:.1,(7;6k(9.h5O00Q>9JKb.10z7gh0Q,.T;#7@92@<;#4.h5OK10QM!9J.L.17IJW^.1<Q.10:2XRb5O>92@7X0:.19J<NW[;b' ;.14QKb9<<:;O;h{J'¤.1WSLI(<BN7*;b2@>Jt10:.T,7;gh.1<Q;#<Q2j7X.T.1k0Q2*7@gb;#;4
W>9._W?^k/.1;#7@<Z4:K^KTM k/5O;7X.TKh4:k4:;0O.142@'3>G;N ,;M<QghKh.1W7@9;#0:43,(;SK1MN.12@4B>^5O<QKh;#<O0:N2@~2@>J.T0:.12@7/Khgh>´.1<QK12XM.1k2@>7@;=0Q;#5<:.1gh>^.T7iukJ4O;5#.1W^7@;.1NPI`bI/9J;N.T>0Q0:K 2@0:2@;#4_ký#?P' 4:I(Kb7*<Z2@0Q;80:{(2@>.TRSWS0QI,7@;;htbgh4:.19(7@I9IJ;CKb<B4:.1;D>(0QRh,J;.12@06>.T0:K>S.Kb<BJN>(2@>J2*0Q.T; 7
gh.1<Q2XG.1k,7@;; 0:<Q;,J.1.T0QWS4;#>04:K10BM3.TKh0:;#<B4_N'32*>/G.1,7;#gh4:.1;C<Q2jKh.T<BkN7@;#;#<:46;2@N 4D4:`b0B9.T2@0:0:;#;44:N2@;WSJ2@>(7X.1;D<0:0Q,K^;0:<O,J.1.T> 0=2@KT>MZRP2@>) 0:;#<Qgh .17iu4O' 5#.17@;N gh.1<Q2X.1k7@;#4L,;#>Æ5OKhW[I90:2@>R[0:,;N2@4$i
4:5O2@KbW[WS2*I7X.T9<:0O2@0$.1?0Q2*kJKb>;#0$3;#2@0:;#,^>^<:Kb;#kh4QOIJ;;_5O5O0Q04'Z0:K 9I2*I/>Khgb4:Kh;L7@gh0:,J;#4o.T00:,;2*M 4oKhKh7@7@>K1;LK12*>(MzR=.4Q4Q0:;#;#0I(4K1' M!Kb<BN2@>J.T7Jgh.T<:2X.1k7@;#43N;#4B58<:2@k2@>R SKbkhO;5O0Q4'oG,;=N2@4Q4:2@[email protected]<Q2*0$?
)b'3G;.h,5Q;, gh.17@9;k?SKTM 2@0Q46M Kh5OKh<<Q0:<:,;#;4QIJ×Kb0:,>JNKh2@kh>8RS;5O<O0.12@> 4 t th.1>JN ),J.T4 Kh' <BN;#<:;Nv4:0O.10:;4tb<:;#I<Q;#4:;>0Q2@>Ra0Q,;3<B.1> 2@>R) ';#I7X.b5O;
"!
#
F('gh.12@>J<:2X5O.T;6k;_7@;D.h5QKh,S>Kb0:K%<BN$e2@|_>Ji#.T)7J&zgh4Q.TK^<:2X0:.1,Jk.T7@06;;5#.b.15:>[,´,Jgh._.1gh<Q;62X.1.CkN7@;D2 ,J;#.T<Q;#4>;0`b>9J9.1W73kJ;#;2@<RhK1,M0'4:0OG.10:,;2@44t5#[email protected]>´2@43kJK1;SM0Q;#.b>5Q,>2@;;#58gh;#;4:N 4O.1k<:?^?^<:0Q;#KDIW7X.b.T5O2@Ia>RS0Q,0Q;6,<O;.1><B.TRb> ;6K1M!;_.h5QK1, M
0:,; ji$0:,^KhkhO;_5O02@>0Q,; i$0:, gh.1<:2X.Tk7@;6k?
)
u&'@)_x
)
E('4BV65#[email protected]*4:;_2@N^[email protected]<Q<Q2j2*.T0$?Dk7@5#;#.T4>^tb90:4Q,2*>(;#>R kJ;D5O0:KbKWS<QI;#I9<Q0Q;#;4:N;#>9(04:2@0:>,(RS; .1^>?gh.1KT7@Mz90:;L,(M;Kb<ZN2*0Q4Q,0B; .T>J×0:5O,^;DW[Khkh;8.1;4Q5O90<:' ;#46N;#4B5O<Q2@kJ;N 2*>P;_5O0:2@Kh>P&(' F('eFLMKh<32@>0:;#<Qgh.17i
G3I
iI
UMAD
>|
CCB
á½²
0m
C
AJCK
AF5O ;!B
U
CBEJNM
&O
Ð
orÏ
Ñ
A
\m
0BO
/
º¦.
PQQ
8
U"7¯A)-"$
QÖ
s
¯%S""*#&¯g. #TÕ
9'*Z"
ª
4
2«
[m9
d
m
-6
¨ 4§ª©:«-6
»
Ã
©
4
Y7<PR" ;4
»
ª
«
?6
-6
Y
»
E
A
Y.
PQQ
)-"*QÖ
E
c)-"*1QÖ
-
¿
; -
0
t i
¿ -
Ó
8
1
N
¶
]#&Õ
L¸
-©
©
Æ1Æ
°¸
A
Y
¸
ܸ
Cª
¬¸
1
È 1
1
i
-©
©
Æ?Æ7Æ
-©
©
Æ1Æ
+È 1
cª
;¸
Ú*1
Ú 1
c¸
È 1
Ã
;Ã
cª
4
Æ
-6
)|
¦ ©ª Á¦ z«©ª =¨ o« :«
A@CBED
AFHG3I
AJCK
AFB
5BLJNM
&O
( " O 1" }2@W1.T0:;#_7@" ?CBMKh7@7@(K1 2@>R0:,1;" M Kh<:WW9(7j.. h;#4.DI/Kh4Q2@0:2@gh;WS;_.14:9(<:;#W[;#>0Kh>P.C>Kh>7@2@>;.T<Z4O5#.17@;ht(4:9J5Q,P.146.T>^;O{IJKb>;#>0:2X.174O5#.17@;ht/.1II(<:K_{i
(*)+-,/. (*)0+,
u&'eFb|
K1MZ,.C;#<Q<B; .b([email protected]:>/.h2N5O0Q2*1
gb;6.T;#<:7@;;#W[IJKb;#4:>2@00:2@' gb;=5OKb>4:0O.1>0:4_'
GZ?I2X5#.T7J;O{J.TWSI7@;#432@>J5O7@9JN;0:,(;=Rb<:K10Q,KTM .kJ.b5O0:;<:2X.IJKbI97X.10Q2@Kh>!tbKh<30:,;N;5#._?
G,;<:;a.T<:;0:,<Q;#;DW[;#0:,KN40QKa,/.1>JN7@;<B.T0:2@K1i$4B5.17@;N[gh.1<Q2j.Tk7@;#4oMKh<5OKhW[I90Q2*>(Ra0Q,;DN2@4:4:2@W[2*7X.T<:2@0$?Dk/;#0$Z;;#>PKhkh8;5O0:4_'
)b'3Gz7*2 b<Q;;#.17@?030:<B,J.T0:.T2@0K1i$0:4B,5;.17@4B;5N.17@gh;.TW<:2X.1._k(?7*;kJ4Z;a7@2Nh2*;4Q0:2@Kb><:0:0:;#;_<QNgh'.17i$4B5#.T7*;_Ngh.1<Q2X.1k7@;#4_'!G,2@4_th,K13;#gb;#<t2@43>Kh0394:9/.17@7@?S.RhKKNS5Q,Kb2j58;=4Q2@>J5O;2@02@4
F('3M}6KhI<QWI7@9? 7X. J1¤" 7@KhÆR " _1'G, ; J Ægh.1_"7@9J;# 460Q5#K .T>^.[kJ<O;D.10:0Q2@<:KT;iu.T4O5#0:;.1N7@;N´[email protected]><:0:2X;.1<:[email protected]; 7i$gh.1,J7@9._g;N2@>tRS.T46gh.TN7*;#9(4B; 58<:2@kJ;_NPM Kh2@<>PKhkh;O5O;_0Q5O2@0Kh> 3&(k'?PF('e9(F4:'2@>rRPKh0Q0Q2X,5O;;
0:N,J;#.TI/0;#>JMNKb2@<S>R[4:KbKhWS>S;^0Q,<B.T;a0:2@NK1; i$J4B5>.12@0:7@;2@KhNÁ>^gh.1.1>J<:N^2X.T.TkI7@;#I47@t32X5#Kh.1>(0Q2*; Kb>!W^' ._?.17@4:K.TII7@? 7*KbR1i$7@KhR´0:<B.T>4$M Kh<:W^.10Q2*Kb>!tKb<SKb0:,;#<^0Q<B.1>(4$MKb<:W.T0:2@Kh>(4t
E('3Gz<Q;.10 .1465OKb>0:2@>9Kh94Kb<BN2@>J.T7 N(.10B..T>JN[0:<Q;.100Q,;#2@<6<O.1> 46.142@>0:;<:gh.17i$gh.17@9;N'
G.1I(,I;[email protected]:0:0:2@;Kb<6>!0$' 3KWS;#0Q,KN46.1<Q;=0Q,;DW[Kh4:0; ;580:2@gh;ht.T7*0Q,Kh9(Rh,S0Q,;a5Q,Kb2j58;DK1MWS;0:,KN[94:;_N^W._?kJ;N;#I/;#>JN;#>0DKb>^0:,;DRb2@gh;#>
éê Z4ê 3 5Pïzø(ñ:ï 6õQ÷!ó c4ñ 66÷ lð1û C÷!ó
0$?;IJu58þ 0:;b2@t$Khý >4,&;#<:'eTF(;[' ' FL0:s,0Q;KaK14:Z;S&;'eF0$gh?';#UI/<_;#tN42@2@4B>W5O9W^._4Q?^4:.1;>N[kJ?P;,<:K1;;_2* .10Q,760Q;#KaN<^.T5O0Bþ Kh.1W[k/.1I4:9;0Q4;t$ý0:Kb,kh;6O;NT5O2@0Qt4Q4S4:ý [email protected]ÿa<Q2@; 7Xÿ .1N<Q2*;#0$4B#?L5Oþ <QkJ2@;kJ#0$;þ ZN ;#;k>?ÆKb.ù_khýOÿa1;ÿ5Oþ 0Q4
ÿ N;#C4Bþ5OK1<QM62@kJghþ;.1N[<Q2Xk.11?kt 7@gh;.11<:0$ÿ?2X.TIJþk;7@4;#'Æ4K1f$M>ù0:1,(Rhþ ;6;#>4B;.Tt!<BWS.1Kb7$;< t
k/.^;#N0$Z.1L0O;>.1;#kJ;> .T.1Kb4:I;SkhIO5#<Q;.TK5O>.b0Q465:,[5OKTKhMz2@>4WS0O0:.1K22@{> Rh;<QN[email protected]<:M
2X;.10Q.bk,5Q7@,;;L4:0$2?2@{ >JI/N;#gh4_.TK1' <:M!2X.1ghk(.T<:7*;C2X.10$k?7@I/;#4o;#4D0:Kh7@Rb2@4:;#0Q0:;,(NÆ;#<.1t(k/IJK1;#gh<¢;bMKh'a<Q+ÆWS2@;>RD>;#.;_N4Q;#IJ.[.1WS<O.1;#0Q0Q;,58K7*N^9(4:0:0:KP;<65O.1Kb>JWS.TI7*?9(4Q0:2*;4 M0:Kh,<;S;_N.h2@5Q4Q,S4:[email protected]@<:7X2X.1.1<Qk2*0$7@?;
0$4:?;IJIJ.1;b<O'a.10:G;,(5O2*47@92@4:4L0Q;#M<=;.T.T4:>[email protected]@7@;a?4:22@MZ40QI/,;#;#<4Q;Sgh.1.1<Q>J2j.T.Tk7*?7@;64Q;#0$4D?NI/;#;D<:2@gb2@;S7*/.1RhRh;<Q>;#;#;<B.T.Tk0:7@;a;a.T<QRh;#4:<Q9;#;[email protected]('7*;<QK1;#34:9;#7@gh0Q;4<' t2*> <:;.T7Z.1II(7*2X5#.T0:2@Kh>(4t/2@0=2@49>7@2 h;7*?[0:,J.T0a.
4:N9/2 5:,Æ;#}
<:;#0QWS>;5Q0Kb,gh<:>;D.12X`b<QI(2X9.1<:;h;OktM7@;;#I<B4<:.1Kb2@k(>IJ7*0:;SKbKS4:.T;.IN´I4Q2*k<Q>(K? Rh.h7@5Qu;DVL,´N9J2@2@4654:b4:0:2@;#K^W[<DI2*;#7X<Q0D.TK<:.15O2@0$7$;#?a'4:4)W^xb.1mh.17@70Qd <:6gh2{v.1.1<Q>/.T2X.1NP>JkN^;O7@;D{k0Q<Q0$;#2@?>J>I/NRh;#46;4DN´.T0:7*KbkRh? 0:;#,0Q4;C,7;#WS.1<_9t!;M.TI/W^>;#[email protected]<$>M>PKhR1<:M.19(W[>/7JN2@gh>.TRSs<:Kh2X.[.19k4:4Q2@7@4:>;#;#4Rh;#97@Kb;>5O0:KS7@)9xb4:.xh0Q;#|5O<aKb#tWS.T5O>JWSKh.1WKb7@?>k(4:2*2@4B>(45#'D;#.T467@L;D0Q>,K1;; M
0:,(;D2@>9(0QI;#IJ<:Kbgh.T4:;780:$e|,/[email protected])03&:' 0:,;DN.T0B.C4:;#05OKh>0B.T2@>4 [gh.1<Q2X.1k7@;#43K1MWS2{;ND0$?I/;h'G,(;N2*4Q4:2@[email protected]<Q2@0$? ok/;#0$Z;;#>PKhkh8;5O0:4 .1>JN D2@4
N; />;NP.T4
9: <; : ;
u&'eF()
9 : <;
,;#<Q;D0:,(;D2@>JN2X5#.10QKh=< 9: ; ¤|C2YM;#2@0:,;< B) Kh< 2@4WS2@4:4Q2*>(R 2$' ;b'*t0Q,;#<Q;D2@4>KaW[;.14Q9<:;WS; ;#>03K1Mzgh.T<:2X.1k(7*; [MKb<ZKbkhO;5O0
3Kh<LKhkhO;_5O0 #tKb< uF
|S.T>JNPgh.T<:2X.1k(7*; <´; 2@4=.T4:?WSW[;#0:<Q2X56k(2*>/.1<:? /Kh0Q,;#<Q2*4Q;ht 9: c)b'G,;5OKh>0:<Q2@k90:2@Kb>PK1M
gh.1<Q2X.1k7@; 0:K0:,(;aN2@4:4Q2*W[[email protected]<:2@0$?Dk/;#0$3;#;#> .T>JN t : t2@465OKbWSI9(0:;N[N;#I/;#>JN;#>0Kh>^2@0:430$?IJ;b\
)b'3f M 2*4k(2*>/.1<:?Kb<>KhW[2@>J.17$\ : <; ¤|D2M
tKb0:,;#<Q2@4:; : ; )h'
F('3f M 2*42@>0:;<:gh.17i$kJ.14Q;N\ : ; GIH ?<JD> ??AJ@ B B 00 ?DG CEBF> J?<J B t,;#<:; ^<:9>(46K1gh;<6.17@7J>(Kh>W[2*4Q4:2@>RDKbkhO;5O0Q4MKb<gh.1<Q2j.Tk7@; '
E('3f M 2*4Kb<BN2@>J.T7Kh<<O.10:2@KTiu4O5#.17@;N\5OKbWSI90Q;0:,;<B.T> 4 .T>JN LMK@ BB 00 t.1>/NS0Q<:;.T0 .142@>0:;#<Qgh.17iu4O5#.17@;N'
N2 ;#G<:;#,>90L4_tJ0$?0Q,I/;S;#4_N' 2@4:4Q2@[email protected]<:2@0$?kJ;0$Z;#;>ÆKhkhO;580:4a5#.T> k/;5OKhW[I90:;_N^;#gh;> ,;>Æ0:,;gh.1<Q2j.Tk7@;#4=N;#4B5O<Q2@k2@>R^0:,;KhkhO;_5O0:4a.T<:;K1M
'
0y
[\y
T
È
©
4
-6
1
1
\
7dm
1
¦h m
&4 i1 6
c¸
ºª
i1
1
¦
i1
¦
>|
Ñ
9²
o
U~
#&<"$*=
X ?P"
S=<
$)
Y"<: [P' #0$)7¯; $)
Q7X ?P"
º"¦<§ [P' #0$) Ó#\Q
#0 ¯¥QS #0
1,7<:Z3"
1
4
86
94
86
¨ 4:ª©>«6
Eª
¶«
¨ 4§ª©:«-6À
Á
=Âo
Á
à
ª
E«-6
;4 86
i1
;4 76
sª
½¸
¨
¨
à
à
à
¨
¶«
i
à
4
E¸
;¸
L¸
½¸
à
Âo
¨
à
c4
8à$
8à$
½¸
i1
©
g`
à
¨
-à*
à

1
LÈ 1
L¸
Ú 1
Ú 1
?6
c¦ 6©ª D§ QP 6© #§¨
§ SR UT(§ ¦ z«©ª :¨ VR ª© D§ «
)h)
éê WHôï!ð÷ øñYXï!ðñ ú cï[Z øôõQö6óbð÷!øñQú c÷ðí 6ó
Gk/Kh,0:;#,Æ<Q;SKb>;O{0Q2@4:,0;.^0$?7XIJ.1<:;RbKT;aMs>N(9.1W0B. k/;#._<gh.1K12@M=7X.158k7*9(7@;D4:0:.1;>J<:2@N >R Kh>´.T7*0:Rb,(Kh;S<Q2*0QIJ,.TWS<:0:42X5O2@9(>Æ7j.T0Q<,;I97@2*<:0QI/;#Kh<B4Q.T;0:9.T<Q>J;h'[N G.TI,I;7@2X5Q5#,.1Kb0Q2@2jKh58;>!'CK1M6f M=5O7@5O97@94:0Q4:;#0Q<:;#2@<a>R.1>/.T.17@7@Rh?Kh4:<Q2@2@40:,2*4W94QN;;#NI/;#.T>J4aN.4
NN;#2@4B4O585O7*<:Kb2@4:I;h0Q'2@gh;Kh<L;O{I7@Kh<O.10:Kb<:?^0:KKb7ut/2@062@4I/Kh4:4Q2@k7@;D0:K^0:<Q?^4:;#gb;#<B.T7Z.17@RhKb<:2@0:,(WS4Kh> 0:,;4B.TWS;DN.10O.[0:KS4Q;#;,J.T060:,(; N.T0B.vW._?
f$>[Rh;#>;<B.17$t(W.#OKb<Z5O7@94Q0:;#<Q2*>(RSWS;0:,KN45#.1>^k/;a5O7X.14Q4:2 J;N[2@>0:K0:,;MKh7@7@K12@>RD5#.10Q;#RhKb<:2@;#4'
)b' (1" " /!" Æ '
;0:,.h2@;35Qgh,;#MKb>^[email protected]*.aK1<Q0:N2@[email protected]:>2@0BKhR.T>CkJ<Q;.1<:;#`b4QI;69<Q2@K1<:;#M;#4:W[;^>;#0QKh>4
kh0:8.L4_;\ 5O5O7@0:O94L) 4:0QKh;#;<<.bNt5Q,.1.10O>/Rh.DNa<:0QKb 99II7@;#W4_tJ'9.C4:G0IJ,J5O.1.TKh<Q0!>0:0B2@[email protected]:t12@2@Kh>S2@0>(.12*5O>(07X.1RD7@4:;4QWS.12 4QJ;#0;#0Q4Kh,>K0:,;3N;Kh5OkhNKh8.T>(;0B4:5O.0:0<Q2@t9J>.T5O0:>J0QK4N DvuRbF IJ<:Kb.1;9<Q.b0:I5Q2@0:4,2@tTKbKh>kh,4ZO2X;KT5:58,CM!0Z0:0:W,Kh;DRb9;#N4Q0:0!.T,(0Bk/;#.(;#<t7@4BKh.T>0:,R2@;#4$0Q<:M K?;
;O{J2*.h7@7/5OkJ0Q7*;C?[kKh<:>2@;;CJRh?^<:KbN92@4BI!5O'9(rs4:4:Kh;_0:NP2X5O7X;.10Q0Q;#,J<.12@0L>S0:0Q,,;2@464:;_5:5O,/Kh.1>JIN 0Q;#<:<;_' `h9(2*<Q;#WS;>02@43<:;#7X. {;_N^2@>4QKhW[;M9~~#?SIJ.T<:0Q2*0Q2@Kh>2@>R0:;5Q,>(2j`b9;46,2X5Q,
9Rh<:4:2@Kb;#gh4D9;#I> .T> 0:Ktþ .10:,(>(;aKh0:u>þ,(9;#<W'k/G;#,<;LK1uM3Rhþ ;#IJ>(.1;#<Q<B0:.T2@0:7 2@5OKh<Q>(2@þ 0:46;#0:<QsK^2*Kb>S5OKh,KT>(2XMz5Q4:,P0:.<Q9J.1Rh0:5OK0Q0_K;#t!NWS.IJI(IJ.10:.T4<Q0:<:0:2@0Q0:K[2*2@0QKb2@2@Kh>WS>2@>I2@>R<QRK12*gh4oW[;60:;#,J0Q0:,.T,;D0ZKKbIJN^kh.TO5O<:;<Q0Q;2*5O0Q.10Q2@40QKh;#>2*4a>2@>.10QR>,;6k2*?S>(4O.12*WS0QW[2X.1K1;
7g5OIJ2@>[email protected]<:4Q0:0:Kb2@;#0Qkh<62*OKb;.T>5O<:2@0Q; >4LRJBM'35O<:7@Kbf$Kh0W4Q; 0:D,(Kb;#>Kb> ;<
<:;#2@7X>J.1N0Q4;N^K1Mz0QKKb0:;,.h;5Q<=,P5OKb<Q2*0:0Q,;#;#<:<_2X.CtMKb,< ;8<:9J;N.T4=Rh2@Kb>khRO;0:,(5O0Q;a46`bKT9JMo.1N7@2@2 0$?a;#<QKT;#Mz>IJ0=.T5O<:7@0Q92*0Q4Q2@0:Kh;#><Q44_' .T<:; ¢Mu.1<6.TIJ.1<Q0 Kb<gh;#<Q? N2 ;#<Q;#>0'3G,;#<Q;a.1<Q;Dgh.1<Q2*Kb94
GzK1M6K^0:.h,(5Q;,2@I/;#Khgb4Q;D4:2@Rhk7@7@Kh;Sk/.1I/7!.1<:Kb0QI2@0:0:2@2@KhW^>.14_7@'´2@0$?af$>2@4:>P0Q;IJ.h.TN<:t30Q2*W[0Q2@KhKh>4:0D2@>.TRTIiukJI.T7@2X4:5#;.1N 0Q2*5OKb7@>94a4:0Q.b;#N<:2@Kh>IR^03KhKh>(9;S7XN[K1M<:;0$`bZ9K 2@<QIJ;aKb0QI,9;7X.1;O<{,J,.1;#9(94:<Q0:2@4:2@gb0:2X;D5[;#WS>9;WS0:,;K<BN.14_0Q2@\ Kh>PB) KTDMo0Q.T,7@; 7
uF :Lÿ 0Q,;Sýa :.1ÿ 7@RhKb<:12@0:þ ,(Wý=.1t/7@RbKh,<:;#2@<Q0Q;,W ;_.ht(5Q,ò,5O;#7@<:9;4Q0:;_;#.h<5Q,2@4D5O<Q7@;#9I4:0Q<Q;#;#<D4:;#2@>40Q;<:N;#I(<:k;#?Æ4Q;#0:>,0:;[;NùWSk;?P.T>Kh4>(gh;a.1KT7@9M
;0Q,KT;M6Kh0:,kh;[O;_Kh5O0:kh4DO;7@58K0:5#4.T0:2@;>ÆN 0:>,;;^.T5O<D7@90:,4:0Q;S;#< 58;#>.T0:>J;#N <
K1WSMZ;0QN,2@;S9W5O7@94Q4:2*0Q~;#;<N 'vNG.1,0O.1;#4:kJ;.T4:,(;#;#4_9' <:2@(4Q0:Kh2X< 5J5O>J7@9N4:2@0Q>;#RÆ<:2@>5OR^7@94QW[0:;#;#<Q0:4S,KN2@40:, 3Kh5OKh< PW[ZI7@;;O7*{ M4QKb,J< .1JI/>J;#[email protected]>>JR[N 4:IMKh,<;<:5O2X5#[email protected]:7i$0Q4:;#,J<:[email protected]>IJRÆ;_NÆgb;#5O<:7@?Æ94:7X0Q.T;#<:<:Rh4;^2@> N.14Q0OW.P.14Q7@;#70:0Q4_K t
IJ2*>^.1<Q0:;2@0:5O2@0QKh2@Kh>(> 2*>(&(R1i$' U/kJ'.14Q;N[WS;#0Q,KN46>;;NP0QKSk/;D;O{0:;>JN;N'D.T<:0:2@0Q2*Kb>2@>R1i$kJ.T4:;NP587*9(4:0:;<:2@>RSW[;#0:,(KN4=.1<Q;D4:0Q9JN2@;N 2@> N;#I0Q,
F(' " 1 " Æ '
}WS;#,0Q,2@;#K<ONa.1<O5#5:.T,(>S2j5k/.173;6WS5O7X.1;#0Q4Q,4:2 KJNÆ;N[5O<:.1;4.Tk/0:;#;#4S2@>.RD;#,2@2@0Q;#,<B;#.T< <B5Q,2X5#.1176ÿ N;5OKh$W[þ IJ
KbKh4:< 2@0:T2@Kbþ > þjý8KTþ M60:th,k/;[.14:Rh;_2@Ngh;#Kh>Æ>4Q,;#K10 K1M=0:,(N;6.T0B,. 2@;#<OKh.1kh<BO5Q;,582X0:5#4.T'´7 N}c;5O,(Kh2*W[;<BIJ.1<OKb5Q4:,2@0:2X2@5#Kb.1> 7
2*.^434:M ;#KhI/<:W[.1<B;.TN0:;^'GRh<Q,Kh; 9I'^f$10aÿ 4Q9J5#5O$;#þ 4Q4:2@gh;7*?ùWS;#<QRhtJ;#.T4C7*4Q0:K ,;[5.1Kh7@7@kh;ON[;580:0:,4; Kh<CRh<:KbT9ÿ [email protected];I(I0:K´<:KKh.h>5Q,!;St.T4Q>0B.TKh<:0Q0:,4L;#<to2@0:9,S>0:;[email protected],P7*oKhK1khM68;0:5O,(0;SM KhRh<:<QW[Kh92@>I(R4
.1<:;CWS;#<QRh;tN[.17@2@4:>K0:5#K.1Kh7@7@>(;N; 0Q,0Q,; ;D0:KbIWSKb4:07@;#gb.T;#I7!IKT<QMK.h0Q5Q,,!;DtT,4:0B2@;#.T<O<:.10Q<O4z5:,?2@0Q#, t/Kb.T7*<6b90:,>;0:2@Kb7!kh.vO;0:5O;#0Q<Q4WS2@2@>D>J0:.1,(0Q2@;ZKh4O>.1WS58Kh;3>JN5O7@2@90Q2*4:Kb0Q>^;#<,'Khf$7X>N;4_.h'Z5QG,,(4:; 9J515Oþ ;#_4:þ@4Qý#2@þ gh;
2*0:0Q;#;#<Q<BWS.T0:2@>[email protected]>[email protected]>S585O7*Kb9(>J4:N0:;2@0:<2@Kh2*>[4C4:,IKh7@7X2@N0D4_9' IÆ2@>0:KP4QW.T7*@;#<5O7@94:0Q;#<:4_t39>0:2@7;#gb;#>0:9J.T7*@?´;.h5Q,ùKhkhO;580a2@4D2@>ÆKh>(;S5O7@94:0Q;#<toKh<D9>0Q2*7.
G5OKh,2@4Q;#2@0<B4.T<:<B2@2@5QRh0:,,2X2XNKb5#[email protected]$7?0WS3K1MKh;#<:0Q0:<Q,,?K;C2*N>(,4R2@;#4:.T<B9 kJ.T<BKb;#5Q9,<C02XM5#.D<:.1Kb5O7W KbWSW0Q;#k,0Q2@,;>JK.1MuN[.h0QKh582*0=<:42X.T0Qk/,J7hKh>.10Q0C,^9WKh0:>J,k/;5O;#;S<bK1.[;#M!?S4QN0:0Q2;#KI ;#2@0:<Q46;#WS>4Q0Z;#9J<Q5#5QRh,5O;;Kh4:2XKh45O<D;kJ44Q;_tI5#[email protected]*4o09LZ4Q;a;#2*4D7@2@7J0N.TKb7@4;>.b0:;h,(Nt;42@h00:K;#5?.14QW>Æ0:K.1>2@7@0:;#7@4;#gb<;#W^<D5O.1Khk/2@W[>D;II99<Q>JKh0ON.1kKb0:7@2@>;#KbW ;h> '
kJ;5.194Q;a2@05#.1>>(Kh065OKb<:<:;_5O0;#<:<QKh>;#Kb94=N;5O2@4:2@Kh>(4'
f$.10 RhRb5.17@Kh>WSkJ;;6<[email protected];6>[email protected];#<:Kb2@0Q9,4!Wc0QKD.15O>JKhN[W0:k,(2@;#>>P;2@<:0:; ;J<B>.12@0Q>2@ghRS;30Q<:,;#;D7@K<Q5#;#.14:0Q92@Kh7@0L>9.14:>J2@>NCR,2@2@0:;#;<B<B.T.1<B0Q5Q2@,gh2X;5#.T<:7;#[email protected]#Rb.T7*0:Kb2@WSKh>!;#'3<O.10QKh2*KbW[>6;6k4O? 5#J.17X<Q.14:k(07*9(;D4:5O2@>7@9R64Q,(0:;#2*<Q;2@<B>.1R<O5Q.T,7*2XRb5#K1.1i7
<:5O2@7@0:9,4:W[0Q;#4<:2@t>4QR[9J5QWS, ;#.T0Q4=,KnoNf:4
.T<:;4:.10Q9J>JNNP2@;N^L2@6>^;t(5O,J0Q._2*Kbgh>P;k/&;#'ed;#'>ÆN;#gb;#7@KhI/;N^kJ.T4:;N Kh>^4:9/5:,´.1>P2@>0:;#Rb<B.T0:;NP.TII<QK.h5Q,!'s2*;<B.1<O5Q,2X5#.17
E(' "# J# Æ '
KhWS]^>;#Kh7@0Q?^4Q,0K4:IIJN,(.14<Q;#,J0:<:2@2X._0:5#[email protected];Z7Y>(i$k/4:2*,/>(;#;#R.1>PI/W[;NN ;#;#gb0:58,;#7*7@K9(KhN4:I/0:4;;<:N[email protected]>J0:4:;#NP;<[Nv;Kh>JKhkh>5OOKh;0:9(,(58>0:;4^0Q;#><akJKh.10QN2*4Q2Kb;>Nù5OK19(KhM >7*0$?^0:,(.1ý#; 0Dþ NN12@2@'4B4:580OGK1.1,gh>J;;#5O<Q;^Rh2*>(;#k/>(R;#;#0$5O<B[email protected];#7J4Q;#2X0:>¤N;#;<Q.4DKhkh2*K1O4oM
;0:58.TKa0:<:4k5O'¤Kb2@0Q><B0:.19J2@<Q>5Q?^9, ;4:,JWSRh.T<Q;#IJK10Q;#,4_2*K'a>(NR=34S0Q7@5#,9.T;64Q> 0:Rb;#2@<Q/gh2*>J>(;#N>R
2uWS5O'7@;h92@'@>4:t/0Q2@MWa;#Kh<Z<9(4QWlK;.h7*>5QKb,9>WRDNk/.T.10B4;#.[<0:,(K1I/;6MKhI/N2@>;#Kh0=>2@>4Q0:2*0$42@?0Q'L,2@>> 9J95Q.[W, Rhk/.2@;#gb<WS;#K1> ;M0:58Kh,7*khK9(ON^4:;0:58;5#0:<.143t> Kh0:kJ<,(;D;N.19(>0O4:;#.L;2@RhN^IJ,Kb0Qk/2*K >Kh0Q<:J4,(7@0QK;#2@K>D<6N Kb0Q,K19M6; 06.[:>>KbRh;2@2@4:2*ghRb; ;#,>´kJKbKb9<B<:.b0:,7@N2@K2@;#9K<:4D4N #,Jt.T;O.1{J4>/5ONP0:;#KP;NN5O2@44BKh5O>4:K1Kh0Ogb.1W[;#2@<=>;580:.17*,(9(0<:4:;#7@0:;4Q;,.1<:4QKh40a7XNK1. M t
.1<:k(2*0Q<B.T<:?S4Q,J.1I/;h'
ON
G3I &I9B
B
C
î
CF5O \B
oA
O
°
B
t²
CF
AJCK
AFCO ¿
&
A@
Ua²
C
/C
C·
Nm
?dN
A
¶çx
A4 ?6
¶4 -6
{
W<>"*S=< "¿S"*Q7PS=<
Q#<"PR&# [é*ZT"
Ì
+Ì
Í
$Í
4 76
\X º"#
?`
4 -6
\X Y"S8Q [
Cw
d
m
?dN
;7%7%=1Q Y"$7< ="
7%7%=1Q Y"$7< "c¦.-.0Q?8PR
L
="
+Ì'Q7< <>Q ;XZ7.-Í
Y4
.-.\SQ7-P¦R
/
¿
6
]
¬Ì$<Q.XS8QÖA#Í
&
Þ4
6
;
C
E
¦
Cj
gy km
?dN
Ó-"*#
1<:)
4
S6
Y
YÌ
&Í
¬4
6
"
)F
¦ ©ª Á¦ z«©ª =¨ o« :«
2*V=5O47@9n3.´4:0Q3;#N<=;#}>.Trl4Q>J2*0$.12@?b7@4?i$kJ4:[email protected]$4Q'?;NùVLI2X;#5#WS>.14Q7;#2*0Q0$N,?b;Ki$>kJN´4:.12@0$4Q?b;,NPiuk/2X5Q5O.1,ò7@4:9;_5O4QNP0:Kb;#WSW[<Q2@I;#>0:9R,0QK;#WS4N^;#.10Q,>,(K2j.1N5Q9(46,PRh.1WSRb<Q<:;;K1>4:0:0Q4D9/;NÆN5O2@7@;95O7@N^4Q90:4Q;#2@>0:<Q;#4a<Q2*.h;_>(5#5ORÆ580:2@KhKhKh<B>P<BNN2*&(>(;#<:'RSm(2@>' 0:RK^M.^Kh<N;#.1>9(4Q0:2*Kh0$?^W^0Q.1,0Q<:2j5;#4Q.1,>/KhNÆ7XN'2@>0:;#<O.hG5Of:0Q2*gb ;
U/'\ 1" /# Æ '
}±0:,;#Rb>´<:2XI/Nbi$;#kJ<$M.1Kb4Q<:;W[N^4W[.T;#7@0:7!,K1KMNP0:,(`b; 9J.T5O>7@90:2@4Q~#0:;#;#4<Q2@>0:,(R^;aKhKbI/kh;#O<B;.T5O0:0D2@Kh4Q>IJ4.h58Kb;a> 2@0Q>,0:;aK^Rb. <:2XJN >2@4:0Q0:;a<Q9J>5O90QW9<:k/; ;#<62u'KT;hM
'@t/5OKh;#7@>´7@460:,(; ,(2j`b5Q9J, .TM>Kh0Q<Q2@W~#;N .4:RbIJ<:.b2XN^5O; 4:#0Q'<:9JG58,0:9;<QW;h'.T2@f$> 0
Kh.hkhNOgh;.T58>0:0O4.1tRb.T;a>JKTNSM6N0:;,IJ2@;#4a>/.TNI;#I><:0KKh.h>5Q,Æ7@?2@Kh4D>^2@0:0Q4C,Mu;.1>4Q0D9(WI<QkJK;#58<3;#4:K14QMZ2*>(5OR;7*@0Q42*W[2@>S;a;_.h5Q,(, 2j5QN,Æ2@WS2@4D;0$>?4:I2@Kh2X>5#.T2@7*>[@?P0:,2@>J;aN`b;#IJ9J;.T>J>N0:2@;#~#>;0N[K14:M6I/.h0:,(5O;h;S' >9Wk/;#<K1M=N.T0B.
G,f:2X5:r6,P¤.T<:2@;4.kJKb0$0:?,^I2XRh5#<Q.12X7/Nb;Oiu{Jk/.1.1W[4:;_IN7@;Z.T>JKTN^Mz.DN;#Rb><:2X4QNb2@0$i$?hkJi$.1kJ4Q.T;4:N;NWS'3;#0Q,<:K2XNbNi$'kJ.T4:;f:N^¡5O67@9ù4Q0:.1;#>J<Q2*Nv>(R+WS._gh;#;O0Qi:,3K7@N94
4:0Q.T;#<:<Z;D.14Q<Q0:;69JN0$32*;_KaNS5O2@7@>P94Q0:;;#58<Q2*0:>(2@KhRS>P.1&7@Rh'eq(Kb'<:2@0:,W[4
d(' ! J Æ '
}0:,J.TW[0KWSNK;#7Niu;#kJ7$.T'4:}l;N´W[W[K;#N0:;#,(7Kiuk/N .14:,;_?NSI/Kh.10Q7@Rb,Kh;#<:4Q2@2*0Q~,;#Wc4S.PWW[._?KN7@K;#5#7.1M0QKb;a<a5O;[email protected]:, 0Q;#<:K14M6k0:?,(; 58Kh58>7*9(4Q4:0:0:<:;9/<:5O40:t2@>.TR^>JN.NJ;#>/>N4Q4a2*0$0Q?[,M;^9(>JkJ5O;0:4:2@0 Kb>J00Q,JKT.1M600:<Q,; ;PJ;N58.T0:0B4D.^0Q,0QK;
4:[email protected]:0:0Q2X;#.1<:74NkJ2@4:.T0Q4:<:;2@Nk9Kb0Q>2@Kh4:>P0O.1KT>JMZN0:.T,<B;SNN(4Q0B.1.10B0Q.v2@4:IJ0:2XKb5O2@4_>t0Q0B4. ' 2@>R f$0DQ>.1Kh7@4:2@K[4:; 7*D;_.hKhN<4Kb90:K^0:7@2@.[;#<Q
4._2@>?^0QKDK1M.h.15#5O9Kb0Q9Kh>W0Z.T.10:>/2X5#N.T7*0:@,?S9N4;?0:2@;#;#<Q7XWSN2@2@>>R2@><:RKbk0:,(9;4:0>5O9(7@9W4Q0:kJ;#;#<Q<L2*>(K1R M
WS;#0Q,KN4']^KN;7Yi$kJ.T4:;N^5O7@94Q0:;#<Q2*>(RWS;#0Q,KN46.1<Q;=4Q0:9JN2*;_N^2@>;580:2@Kh>P&'e&('
0:.1KI(I58[email protected]:.14Q0:2Y;S2@M Kb?5O>7@4Z.´94QW^Rh0:;#2@._gh<Q?a2@;#>> ,/R ._.1gh.T7@;DRh7@RhKb5OKh<:7@<Q92@0:2@4:0:,(0Q,W;#W[<:2@>4=.TRS42@>5890:<:>;2@Rh0:2X`b;#<B<Q.T92X0:;#.;^7@?0:,(,k/;2X;#5:7@,^Kh2XN>(<Q;_Rh;.12@`b4>9R´K12@<:M=0:;DK´4Q0Q;#,Khgh;>;<B7@2*?Æ.1>70QKh;#5O>(Rh7@9<O; .14:0:0Q582@;#7*Kb9(<:>2@4:>0:;KTR´<:Mz2@WS>4Q;#R;gh0:;#,W[<OK.1;#N70:4_,(5Ot7@K94:Nù4:K´0Q5#;#0:.1<:,/2@0Q>.1;#R[Rh0Kb0:2*<:0;?5Q'2@,4a>4Q2XKh`b9(W[9<:0:;#;#,(4_0:;#' 2@<:WSW[;Kh4a<:;bNt24:Kb5OWS97@;0
.17@RbKhf$<:>ù2@0Q0:,,WS;v4MKh7@,(7@K12j5Q,^2@>2@R^>0:4:;#;Rb5O<B0Q.12@0QKh;>4_0:,tZ;32X;SN;;8.T{(4.TWSK1M2@>4:;#;gb;#;<B.b.T5Q7z,5OK17@9M4Q0:0:,;#<Q;^2@>.1RSk/K1W[gh;#; 0:,JKghN;^4_5O' 7@94:0Q;#<:2@>RÆW[;#0:,KN42@>N;#0O.12@7$' +Æ;^.17@4:K´2@>0:<:KN9/5O;
é]ê ^[ïzøðñ¢ðñ úLñ:ú c÷ðí 6ó
2@IJ>.T2@0:<:ghKa0:;2@>0Q2*KbIJ.>.TN2@<:>0Q.12*RP0O0Q.12@5OKhkJ<:>.T2@0Q44:;#;u<:K12@KhM >t!KhKTkhMth0:O;#;_>5O,(0:;#54_<:.1tJ;[email protected]@;;>/N.bNS5:,[. tIJý#0QþX.1,ÿ<Q;0:þ 2@>0:2@9(#KbþW>kJ<:;#;#I<3<QK1;#Mz4:$;58þ >7*9(0Q4=4:t0:.D;4Q9J<:58465Q7*,9(0QKD4:.10:M;4aKh<<:N'W´2*G4Q0Bt,(.T.C;=>JIJ5O5O;[email protected]<:4Q0:4Q0:2@KP0Q;#2*<QKb0:46>,[email protected]><:0;sRa0:M.T,Kh7*;[<QRbWSKhKh<Q;kh2*NC0QO,;0:58WlKC0:4DKhKbI<:R0Q2@2*.10:W[,(>2*2@2@>Æ~#~#;
;#4.P.T0Q>S5O,7@Kb9;kh4QKh0:Okh;#;<O5O;_0Q.12*5Ogb<Q0:;;4
:4Q2@[email protected]< /t1,;#<Q;.14L0:,;KbkhO;5O0Q46K1MZN2 ;#<:;>05O7@94:0Q;#<:4.1<Q; ON2@4:4Q2*W[[email protected]< 2@>^0:;#<QWS43K1M0:,;DN.T0B.TkJ.14Q;.T0:0Q<:2@k90Q;#4'
é]ê ê:ë _ õ:ïóóñ:ôïõ Lïøðñ$ðñ úLñ:ú c÷ðí 6ó a` c÷!ïú6ó´ïú L` c÷ ñ Ló
G ,Æ; WSKb/4:" 063 ;#I7@<:7iKbIJ>KbK14:;N[>Pk.T? >JN 47=58.TKh9WSMW^W[.1Kh>S>[email protected]?>/9N4:;_sN´Kh9IJ4Q.14:<Q;#0:;2@0:92@cKh>()_2*>(xhR&bq WS#t;#.10Q,>/KNSN0Q4=,.T;#2@<:<;gh .1<QÆ2X.10:2@Kb>4' I<:KbIJKb4:;N´k? u]P.b5#¡L9;#;#>¤)xbmhq tJ.T>JN
/" J# " / bc Æ( Æ
G<:;,4:9;S7@0:b2@i$>WSR[;[email protected]>>0Q<B4. .1i¢5O7@Rh7@9Kb4Q<:0:2@0:;#,<W4Q2@WS0O. [email protected];#<:42@0$0:?,2@;42@,>2@IRh9(,S0=I/,(.1;#<B<:.T;WS.T4;#0Q0:;#,<;Dt2@>t!0:.1;<$>/i:NP5O7@9IJ4:.T0Q<:;#0Q<62*0Q4Q2@Kh2*W[>[email protected].[<:2@4:0$;#?D0C2@K14M 7@K1DKh'kh3O;7@9580:4:40Q;#2*<6>4Q0Q2*KW[´[email protected]<:7@92@0$4:?D0Q;#2@<:464W[4:K^;.10:4Q,/9.1<:0D;_NS0Q,2@> ;
<:;R.1G<ON^,;60:K.T7@Rh0:,(Kh;S<Q2@0:ÿ ,W^I<QghK.15O7@;#9;;N46K1M.T0:4,M;Kb7*Kh@K1kh8;4_5O\ 0:4L2@2@<:>4Q00Qt,2@;D0<B5O.T7@9>J4:N0QKh;#<W[t/7@?=,4Q2X;#5Q7@,P;5O5#0Q46.1>^Dk/KT;M!0:g,2@;#;3Kb;khN^O;.15O40Q4Z0Q,;a,2X5O5Q7@,94Q;0:.b;#5:< ,4 <Q;#I<Q;#4:;#>0.=587*9(_4:0:þ ;<Z/W[' ;.1>
KhkJ<.T4:5O;;#N´>0:Kb;#> <_' 0Q,(; Kh<N2*;4Q.b0B.T5:,ù>J5OK1;Mk/0:;#,0$;Z<Q;;#;#W>Æ.T0:2@,>;2@>KbRSkhOKb;kh5OO0D;5O.T0Q>J4NPtZ.T0Q>,;SKb5Okh7@O9;4Q5O0:0;#<D2@4aW[.1;4Q.14:2@>Rh'>(;f$N´0=0Q0:,KP;#>Æ0Q,5O;SKh5OW[7@9I4Q90:0Q;#;#<40:0:KP,;,(>2j;#5Q
,ÆWS2@0;[email protected]>[0:,MKh;<W[;.bKh5Q4Q, 0=4Q5O2@7@WS94Q2@0:7X;#.1<_<' t
G,2@4I<QK58;#4:42@0:;#<O.10Q;#469>0Q2*7/0:,(;a5O<:2@0Q;#<:2@Kh>[M9(>J5O0:2@Kb> 58Kh>gh;#<QRh;#4_'G3?I2X5#.17@7@?tT0:,;D4O`b9J.1<Q;Nbi$;#<:<QKh<=58<:2@0:;#<Q2@Kh>^2@494:;NtJN; />;NP.T4
d
u&'eFbF
?AfFg[@
=e
W,9;#7@0:<Q2X; N2@W2@;#4=>(0Q4:,2@Kh;>JI/.T7Kh#2@'/>G06,2@> 2@4
4Q58IJ<:.h2@0:58;#;<Q2@<:Kh;#>^I<Q0:;#<Q4:2*;;>40Q0:2@K>R W0Q. ,b;;Rh0:,2@gh;;#>´<Q;#4:Kh9kh7@80Q;2*>(5O0RStS.1>/5ON7@94Q0:;#<Q2*4=4.10Q46,58;KhWSWS;I/.T.h>^5O0K1.1M6>J5ON[[email protected]:0Q43;#4:< ;#I/h .1<B.Tk/0:;aKh0Q.T, 4IJKb.T4:>J4Q2*N k(7*;b'G.1,<Q;;
Gb5O7@i$,9WS;D4Q0:;;#.1.T<Q7@>Rb443Kh.T<:I<:2@<:0Q;aK,585OWcKh;WSN.190:I/<:0Q.h;;#5OWS2@04I(5O4:0:7@9Kh439JW[0:NKW46N.10:;#,/<Q0:[email protected];~#<:06;WSN.1<Q2@2@>>;D;D<B.Tv2@0:Rh,IJ9;.1<Q<6<Q;D0:32@&0:;#'@2@)hKh7@7!'>(4:4Z;0QIJ,J.1.1<O03.10:WS;_N[2@>M2@<:WSKbW2~#;3Kb0:>,;D;.14B>`bKb9J0:.T,<:;;<N'3iu;#G<Q<:,Kb;D<W[M9;#>/0:5O,0:K2@KhNv>2*'4Lf$<:0;#7XZ.TKb0:2@< gh;#4Z7@?34O;#5#7@7.17X.1,k(;#7*;D>^.T0Q>J,N ;
A@CBED
§oy m
AFHG3I
AJCK
AFB
5BLJNM
&O
?dN
¬
4
Cl
N
y 9m
?6
?dN
¬
{
Ì
*Í
!
¶
UH²
/C
/4 ¶çxg6
1<:)UV$Z�P¦< [Q#
Ì
Í
c~
]Ì
/ײ
/C
\³
Í
gв
U
gв
§
ym
d
4
ym
+4
To §
:Ny N/
-6
-6
§n
Ed
ym
¿m
?dN
°
º"#
7z Ì=P"*#&<"$;Q:V¥%= 1<§)Í
Ü
s
Á
Âo
Á
Ê
Ã
»
Ȧ
6
?Ê
Å ©
4
4
]
»Y
-6
© #© #§¨ :¨ kR ª© D§ «
)E
ÓlXãnmÍoXåprÊ qÂjs/Â@æ"t4uDv:Ê^Ì1ÄhÅäwaxzyF{uD|]}U{~F8~
D]4yF}E
n~4]]
DA~4{
D4yA{}*{~~F{
[4yF{=
D4{44yA{YF44{
ÝQÅ[âDå IxzyF{=F}n{
YF44{4u~A~~Q~n~4{
DQ~F
{4
ØâåâDå ¡4{8
¢u£QA44{4¤8yQy}}¥{=4yF{=4¦n~4{|]{44
D=]4{]
§
ÈùÌ1å p[mÇ x8yA{uD|}*{~AI~D
]4yA}¨}U{}U{4{2~z©
j
¤8
ji
G3I iID\BLF
O O
5O ;
A@
C
~44Q~]j¬YyF
D4{Uu£
{4=~84yA{]~¢YF44{{4{4®
4{{~
± 4{ « ~4]
{~Yy
D4{z4
U4yA{=YF44{4
*¤8yQy4yA{=
4{8z4yF{=}*
4]}j~
n~4{
D4yA{=}*{~~F{
4yA{=
4{44yF{=YA44{®
An~4{4yF{=YA44{}*{~AnE {DF~~4{U4yA{=}*{~~F{
4yA{=
4{4E
z{~QyYF44{®
F]j[F
Yy~FD{D®
ª«
¯«
°«
²<«
³«
´
2@Rh9<Q;D&'@)h\bi$WS;.T>4
.T7@RhKh<Q2@0:,W´'
+
+
+
+
+
+
+
+
+
2@Rh9(<:;D&'eF\37@94:0Q;#<:2@>RKTM .C4:;#0LK1MI/Kh2@>0:43kJ.14Q;N^Kh>[0:,;biuW[;.1>(4ZW[;#0:,KN
;O0:,(;5O2@0:;#Kh>0O0.172@>^>9IW<:Kk/5O;#;#<L4Q4:K12@>MRPKhkh7X.TO;<:Rh580:;D4tN.T 0B.v2*44:0Q;#,0Q4D;kJ>;_95#W.19kJ4Q;;a<=0QKT,M
;5O7@5O9Kh4QW[0:;#I<Q94t0B.T.10:>/2@KhNa>/¶D.17!2@45OKb0:WS,;I7@>;O9{W2@0$?k/;#K1<6MKT0:,(M
; [email protected];#<B7*Rb.TKh0:2@<QKh2*0Q>,4_Wc'r2@4UKh<Qµ W.T7*A@¶?ttJ¸· ,(;#<:; ´.T>J2@N 4
¶· 'G,;WS;0:,KNKTM0:;>0Q;#<:W[2@>J.10Q;#46.10.7@K5.17KhI(0:2@W9W '
54:#I/.T4:;;S5OG2M2@,?^>Æ;D4QbKhti$WS0:WS,(;S;_;6.1.T>>I943IWWS7@2Xk/5#;#;#.10Q<Z0Q,2@KKTKhMzN>t5O4_7@t,94:K14:9J30Q5Q;#;#,<:gh4_;t.1<2@4DtJ>5.b.1,N>P;gh>òk/.1>/;DN5O.1.T;=I0B5#.^I.T7@>S2@;2@N[k/0:,;Kh>(4:5;#7*.1?;#0:>P;Rh.T,(Kh4
;#<Q2X>P.5#.1N0:7,(2@4B;D.1.b0QNWS0:gh<:;[email protected]>9(>S0B0:.TKT;#Rh4M ;h.'.1<QG5O;S7@,92@;D4Q>0:ghb;#Khi$<WS7@gb2@46;;.TNN>'; 4JG>(W[,;;#N;[0:'3,>KG;N5O,;2@2@4:4434:2@W>0$Kh? ._03?M4:Kh>9<DKh2@0O09(.14:kk/;#7@;D<Q;4a0QM ,0QKhK;<
KhN9(2@4B0:587@K12@;#gh<6;#<QN2*>(.10OR.D5OI/7@9Kh4Q2@>0:;#0:<Q44=4Q2@>J2@5O0Q;a,.C>(Kh4:W^>i:.15O7@Kh7J>>gb9;OW{Pk/4:,J;#<3.TIJK1;#M4_4:t9/Kh5:<6,P58N7*9(.T4:0B0:.;<:5#4D.T>^KTM 4:9gb;#k<:4Q?P0B.TN>2 0Q2X.1;#7@<:7@;?>02*> 4QJ2*~9;h;#'6>J58]^;DKb0:<:,;#;K1gbW[;#<;t/.1>[2@0[email protected]@4:9;;h>' 4:2@0:2@gb;D0:K[>Kh2@4:;D.T>JN
0:,(;D }94:5#;5Oz<6Kh <OP3NKh2@ >9ºRD7X¹ N0QK=7@2 9h}LI;L7@I/Rh0:KhKhKS<Q4Q2@5O;a0:7@,90QW
,4Q0:;#;#<:&<L;' UJ0:.1,'@<Q)h;;at_3Kb.kh;6O4Q;;#.1065O<Q0QkKT462@M0:2@<B>Kh.T0:kh<:KO2@7@;?a0:58,0:5Q<Q4,;#K;7@KKh5854Q7*.1;69(0:4:E;_0:N^;Kh<:kh2@4> O' ;_.5O0:<:4 ;58W^0B.1.1>(< Rhb7@;; N.Tk46? 4Q,K1>^.T2*>40:!,2@;LRb92*>(<:2*;a0Q2X&(.1'e7F0:'Z,<Q;#;#;=0D58 7*9(l4:0:;E(<
t5O0:;,/>.10Q06;#<:2@4_4_'t
GN2@,4:0Q;#<:>´2@k;9.b0Q5:2@,Kh>[KhkhMKhO<Q;WS580=4Z2@.4N4Q2@2@7*4:,(0:Kh<Q2@9k;#90Q0:0:;_;N^;#>J0:K[582*<O0:5O,7@;;N^5Q,kKh?4Q;#N> Kh0:5O0Q7@;9N^4Q0:5O;#9<a<QNghKh;hWt.1.T42@>4Q4Z,K1k/.14:>S;_N^2@> Kh>P2@Rh9,(<Q2j;5Q, &('eFa587*9(. 4:#0:' ;<58;#>0:;#<2@460Q,;a>(;.1<Q;#4:0_'=9/5:,Æ.
KhkJ>[.T4:0:;G,Nv,;Kh2@Kb4 >khO2@;>J,5OND0Q2X5Q46KT, MJ2@>S58Rh7*<Q9(0QKh,4:90:;DI(;<65O2*>(7@95OR=;#4:>0Q;#0:2@<;#7@'3<3792@4I;#0:N7X,(.1.1;0Q0Q2@;gh>;;0:,.10:<Q;6K;#5O4:0Q7@0_,9'Z;#4Q4Q0:;=;#9/<35:>(,^5O;#;# .L>0:<:58;#;O;#<Qi:>4N0:'32@;#4:G<Q0Q4<:,Jt/[email protected]@O4_2*;_Kbt15O>0:0:,4M;Kh.1<QW[<:WS;;4<Q.1;O>C.Li¢N>gh2*.1;#4Q-7@0:9<Q2*;34Qk(2@K197*,(M0:Kh;;9N[.h;#5Q0Q,S0QKa0:;5O0Q7@;#,9>/;D4Q0:5O;#5:2@<B,(<5OKh2@7@44:;;Nv<:> ;_k5#5O?.17@7X95ON4:9.T0Q7X4:;#.T,<60:;;NN[NvKb5OWkJ9.1.1<Q4Qgh2@;>;hN 4 t
.144QG,K1,2@4>^I2@<Q> K58;#2@4:Rh49(<:<:;#;DI/&;'e.TF0:4k t',(2j5Q,Æ7@;.bN40:K 2*Rb9<:;S&('eFS5 'gb;#>0:9J.T7@7*?t/>K^<:;Oi:N2@4:0Q<:2@k90Q2@Kh>ÆK1M30:,;KbkhO;5O0Q4a2@>Æ.1>? 5O7@94Q0:;#<
,J.TIIJ;>4=.T>JN[0:,;I<QK58;#4:40:;<:WS2@>J.T0:;#4_'G,; J>J.T7!5O7@94:0Q;#<:4D.1<Q;0:,;D<Q;#4:9(7*0KTM0:,;D5O7@94Q0:;#<Q2*>(RI<:K5O;#4Q4'
K12@4DMz0:NKG2*4Q,J4:2@;<QWS<:4:;[email protected]<:<QI;2@I0$`h?7@?9(t_2*.10Q.^>J;N,(.32*0QM;,;#<BÆ;6.1<O4Qgh5Q0:,.T<B.T<:2X5#2X0:.1.1;#>[email protected];#4Rh4K1RbM0:7*KaKb0:,WS5;3.1;#7Xb<O5Oiu.19W[0Q7X2*.1Kb;0Q.1>P;6>(.15O47@7@WS9RhKb4:;#0Q<:0Q;#2@,0:<,KWSW N6;_.10:,(K´>2j4_5QN'!,a;#}L0:N;>2 <:WS2*;#><2@0Q>2*;#>;<:;#0Q0:4Q,,(0:;Z2@;>4QR>;#9(7@4:;W0Q5O<B0QkJ.12*Kb0Q;#;#<>DRhKTK1?MsM2@5O>,(7@2@92j0:4Q5Q2X0:,.T;#7h<QKT4 M0:WS.T;#>[>J;N´.T?>2*0:4;K t7jN0:J,4>/;3RhNÆK5#.1K.17XN>´5O9<:2*7X;#>(.T4Q2*0:90Q2@7@2XKh0:.1> 4 7
5O7X.14Q4:2 5#.T0:2@Kh>t.1>JN[0:,(;#>P94Q;=2@0Q;#<B.T0:2@gh;<:;7*K5#.T0:2@Kh>^0QK2*W[I<:K1gb;0:,;D5O7X.T4:4:2 5.10:2@Kb>!'
a)
b)
c)
º4§
S6
Y
Ý
T{
im9
gú
Y
1
/4
+
Ì Ø
Í36
86
(
06
+
$6
/
)#U
¦ ©ª Á¦ z«©ª =¨ o« :«
A@CBED
AFHG3I
AJCK
AFB
5BLJNM
&O
ÓlXãnmÍoXåpÊrqÂjs/ÂYÏ»xzyF{uD|]}U{A
AI~
D]4yF}E
D8~4]]
Fn~4{
D4yA{={4Q~
D4{4
ÝQ[Å âDå IxzyF{=F}n{
YF44{4u~A~~Q~n~4{
DQ~F
{4
Øâå âDå ¡4{8
¢u£QA44{4¤8yQy}}¥{=4yF{=4A}¨
4yA{4]}j~]]{
¢~j4yA{
D4{484
*4yA{QF{~4{48}*{A
§
ÈùÌ1å p[mÇ x8yA{uD|}*{F
F~
D]4yF}}*{}*{4{2~8E
j
¤8
¾D¿DÀÁ¿F¾D¿nÁÃDÄ2ÅÆÇÇÈÉ u ÇÀÊÉÅDÂFÈ2¾ÈËÂDÆÉ%ÁÌÁÂnÁ¾ÃÍÉDÎFÇAÁÎFÈ[Ï
¿FÉÑɾDÂ
¾ÈÈAÁÓDÌËɾÅÆÔÇÀÊÉÅDÂ2ÂFÇËÂDÆÉ%ÅÃÕÈDÂFÉD¿ÖÅÇD¿¿FÉÈÑÇÌFÎnÁYÌFÓÂFÇËÂDÆÉ
ÌɾD¿FÉÈDÂ
ÍÉDÎFÇAÁÎÏ
žÃÅÕþDÂFÉÂDÆɸÇÀÊÉÅDÂnÁØFÉÙDÕÌÅDÂnÁÇÌ¢ÚÛDÆÁÅÆÔÁÈËÂDÆÉ"ÈÕÍÔÇDÙ"ÎnÁÈÈAÁÍÁþ¿nÁÂFÁÉDÈ
ÇDÙܾÃÃÖÂDÆÉ"ÇÀÊÉÅDÂFÈÂFǸÂDÆÉAÁ¿aÌɾD¿FÉÈDÂ
ÍÉDÎFÇAÁÎÏ
ÈDÛF¾Ñ"ÂDÆÉ
ÍÉDÎFÇAÁÎ"ÞÜÀFÄ̡ܾÇÀÊÉÅD¸ßSÁÙÜÈÕÅÆܾ%ÈDÛF¾Ñ"¿FÉDÎDÕÅÉÈ
ÂDÆɸÇÀÊÉÅDÂnÁØFÉÙDÕÌÅDÂnÁÇÌ¢Ï
ÕÌFÂnÁÃÌÇ%ÅƾÌFÓFÉ[Ï
¼½
Ðn½
Òn½
× ½
Ýn½
nà ½
´
2@Rh9(<:;D&'eE\bi$WS;NKh2XN4Z.T7*RbKh<Q2*0Q,W '
5O7@92@0:4Q,Æ}L0:;#>5#<S.1Kh0Q0Q5#;#,.TRh;#0:Kb;#<^Rb<:2XKhgh5#<Q.1.T2j<Q7Z52j.1.TKb76>kh0ON;.T0:5O0BKò0Q. 4tkiu.1?´W[>JN;<:;.1I9>7X4:4.h2@>5O2@2@4^R´>R´ .0:M ,<:;;^`b9W[;#;>/ .15O>W[?b4Ciu;#kJK10:.T,(M=4:K;5ONùN 7@9WSk4Q0:? ;#;#<Q0Qu4,sK9JN^2*.10Q0:>,K R¤W[9)I KxbN(Nxh.1;#& 0:4;t9W[4Q,(2@K2j>5QNRP,¤;#46>;OKT;#{Ms0:;#58>/7*N9(N2@4:4:4^0:4Q;2@0:WS<:,4;Æ2@'[7X.1bG<:i$2@,0$WS?^;S;WSb.T>i$;_WS4.14:;_IJ9(.1.1<:><O;#4.h4N.10:2@>JKRbN´W N0Q;,0Q.1K; 7
b i$WSz K/N ;#J4L#WS o;#0Q, KW[N46;#0:5#,(.TK> Nk/' ;a2@>0:;Rh<B.T0:;N 0:K587*9(4:0:;<aN.10O.2@0:, WS2{;N>9W[;#<:2X5D.T>JNP5#.T0:;#RbKh<:2X5#.T7gh.17@9;#4_tJ,(2j5Q,P2@45#.17@7@;N^0Q,;
;O;{.b0:5:;,[}L>JIJ>NKbKh4D2@0Q>0Q,,03;#;a<S0:Kbghi$.D.TWS<:5O2X;[email protected]>4:>00Q46;#0:<6I/K.1.hb<B5.bi$5OWSKhN<O2@;_RhN.1Wc2@>>Ra42@> 0Q2@4SKD.[5#4:NKb.12WS7@7@;;;N <:3;#>;#02@] Rh
,0._$?<Q;#\3{IIJf$<:>;;584Q4:0B0:;#;.1>.b0Q0:2@N^2@Kh>>wK1R[M
]P0:.T,4:. ;L4Q{2*IRb2*W[<:>Kb2@2@kJ>~R.1.1k(0Q;2*2*Kb.b7@2@>5:0$,´?D.1KTI/7@M!KhRhWS2@Kb><:0;#2@W0:0:,(Kk/W;#.[<:4QkN,? ;2@NI!u2X'5#.Tf$.1>^0:9;<Q.1N´2@>0:~#5OKb;#7@0:9>,4Q;#0:<3);#xh<_3xbtKhd 2@0=<BNt.1th4Q0Q4:,,2@Rh;#2X>(5Q<:, ;4
.1<Q;D}
>K<:;_4:0Q5O<:;#2X>5O006k/; KhKh9(<:>J0CNKh.1>´<Q2@;#4B45#.TkJ7*;2@>0$ZRP;#b;>i$WS5O;[email protected]>4Q0:4D;#<Q.147@'oRbKhG<:,2@0Q;#,<:W ;8MKht(<QI;h<:t/Kb>IJ;#Kb¤4:;NWS;k.T? >4
uno.T<B<:.h;DN0Q7*,;?;#>Pt J5O._Kb?WS?I.h9N0Qt!;.TN[>JkJN´.14Q;;#N[2@>JKh.´>^)3xb;#xh2@& Rh#,t0:2@;4DN[kJW[.T4:;;.1N´4Q9Kb<:>;#4_'.T>
2X0:N,(;;6.<:;KTRhMz2@2XKhN>;#4o>0:0:,J2M.T?0
2@>.TRD<:;6<Q;#NRh2@2@4BKb5>.14<BN(K1.1Mk0:7@,;h;D'}-N.TI/0B.Kh2@0:>,/0.12@064 .1T<Qþ@;Dý 5OKhW[I<:;#s4Q2Y4:M2@k2@0:7@4;htW[<Q;#;#RhW2@Khk/>(;#4<:4Q0:,,[email protected]2@>W.D94:5O07@9k/4:;D0Q;#W^<.12@4Z2@>.10B4O.15O2@;#><Q;_0BND.12@2@>>S;_NW^t.1.12@>J>NWS4Q9J;WS5Q,Kh.<Q?I/t1Kh.T2@>J>N 0
2@2@5#40:.T4>Æ4Q19kJÿ WS;W^[email protected]ýO5#ý#<:[email protected]þ ~#<B;_NLNa;_2NÆ5OM7@[email protected]4Q>J0:2*N ;#4L<Q>Kh2@>>KhR067@?^MN;0:2*.T4O,(0:5#;9.1<Q<O4:; N9.1W[.1k(>JW7*;CN[.1k<Q2Mz92@~#0.C;N^k/IJ;#Kb5O7@2*7@Kh>9>034:Rb0Q2@;#464Z<:0:2@>>KS;R 2*.v0Q,M;0:;#[email protected]<6Rh0Q,9N03<:2@4O;4:5#9.1KTk<OMZN5O4:[email protected]/k4Q5:7@0:,;;#<_>Nt!Kb2*4O.1<
5#>J.15ON <OKbNWS4:;9JIN´5Q<Q, ;#I/4:Kh.4Q2@2@>4Qk90:7@4;hk t584:.17*,(9(>JKh4:Nv90:;7X4:N<D9J5Q2@kJ4,P;4:.C9<Q;#W[IJ0BKb.TW2*2*>(>.103;<QN 2@4:~#,;Kb.SN99I/7XN4QKh2*2@>(k/>R;0
0:0:,(9(;<:1>58þ 4KhWS.4:I(;þ <:^5O;#Kb4Qÿ >J4:[email protected]þ 7@^;6<:?bI/ÿ iuW[Kh#2@ÿ>;#WS0:4Kb.11<:>J'?NvGkJ0:,.1,4Q;6;;2@N^0:I/;Kh.1<B7@[email protected]>0QRb0:2@43gh<:2@;=0:,(58,Wc7*2X9(5Q4:,S2@0:>;W0Q<:K2@9>.C4QRS0W.1<:7@;#[email protected]><:2@>S2@WS0Q,2@;#>WlW[W^Kh.1<:2@?b2@7@>a7i$kJ2@W[>J.15O4Q;#7@;9JWSNNKb;L.1<:7@?DKhRb>Kh2@>[<:7@?2@0Q0:,0Q,,W
;L;62*0:0Q4QKS;#9<BWS.h.T5Q0:W^2@,[email protected];D;#<:gb2@5O;~#7@;_90:Na4Q,0:;D5O;#7@<694O5#4Q.T.10:>J;#7X.1.T<Q7@2@k?>2@4:R7*2@2@4_0$M?t;' .T.T0:>J9N<Q;#0Q4,9(K14M
' 1#_" /" /# ´_ " /z b=c Æ /" Æ
GN2@,4:0Q;^Kh<Qb0DiuW[0:,;;S.1>(N42*4Q.T0:7@<QRh2*k(Kh9<Q2@0:0:2@,KhW>´K12@4DMN4Q;#.1>0O.4:2@'0Q2*gbf$>;4Q0:0:;KP.bKbN´9K10:7@M2@;#0B<Q. 4D2@4:>2@>JR[5O;^0:,.1;>ÆW[Kb;kh.1O> ;5Ogh0.17@92@;0:,´K1M4:Kh0:W[,;;aKb;8kh{O0Q;<:5O;#0QW[4D;#2@7@> ? .^7X.T5O<:7@Rh9;4Q0:gh;#.T<[email protected];a4DW^.[._<:?^;OM ;#4:<:9;#k>/4Q5O0B;^.T>IJ0QKb2X.12*>7@7@0_? t
Kh5O7@>(9;4Q0:W;#<_._'?^G0B,. h9;S40:.[,<:;;#I(IJ<:.1;#<Q4Q0:;#2@0:>[email protected]>0Q2@2@>ghRS;^W[Khkh;#O0:;_,5OK0DNP2@> 5.1. >´5O4:7@0:92@4:7@70Q;#kJ<;t5#I/.T;#7@<$7*M;_KbN <:W[.Æ;ÿ NPk/.1T4:þ ;_1NPtKb>,2X0Q5Q,, ;a2@4DI(<:0Q2@,>J;5O2@WSI7@Kb;4:K10DM5OWS;#>2@0:><[email protected]@7@2Y?P~#2@7@>KR5#.10:0Q,(;;aN´4QIJ9KbW 2@>KT0M
2@>0Q,.;
WSN2@4:;4Q0:2@,WSK 2@N7X.1' <:2@0Q2*IJ;.14<QkJ0:2@;#0:0$2@3Kh>Æ;#;#.1><Q;_Kh.h95Q>/,NPKhW[khO;;_N5OKh0Z2X.1N>/4 3ND2@42@.^0:,Cb2*i$0QWS45O;_KhN<QKh<:2X;#N4Q4IJKb0$?>JI/N;S2@>5ORD7@9<Q4:;O0QM;#;#<:<Q2@;#>>JRP5O;.1I/7@RbKhKh2@<:>2@00Qt_,W ,'2X5Qf$,D0 MJKb>/<:W[N4a4!´0:,(5O;7@9kJ4:.10Q4Q;#2*<:44DKT2@MJ> 0:,´;6KhkhiuW[O;_;5O0:N4DKh2XkN? 4
Jf$0<Q4:0Q0 ,;#J>>JN2@0:2@;#><ORa.10Q.L2*gb<Q;#;#7@I?a<:;<Q4:;#;#I>7X0B.h.T580:;#2@4ZghKb;>Kb;khK1O;M5O0:0 ,(;Bÿ WS;N1Kbþ 2XN4!MKhk<?;Kh.b>5:,^;KT5OM7@90Q4:,0Q;;#<>'oKhG>iu,W[;;2@>NKh2@0:2X2XN.1474Q.T;#4z0Z7@KbKT>M!RDWS.1;4N0QKh,2XN;4z0:58KbKh0B9.17/7XNN2@k/4:;=0B.T.1>J<Q5Ok;L2@0:K1<OM.10:<:,2@7@;?D<Q4Q;#;#4:7@9;5O7@0Q0:2*;_>(NR '
5O7@94QG0:;#,<Q;2*>(NRS;#[email protected]@2@7@W[;N^I<:.1K17@RhgbKb;N<:2@' 0:,WK1M/}=]2@43I<:;4:;#>0:;_NP2@> 2@Rh9(<:;=&('eE'G,;D.17@RhKb<:2@0:,W
.10Q0:;#W[I0:430:KN;#0Q;#<:W[2*>(;vIJ.1<Q0:2@0:2@Kb>4M Kh<
.15O7@>/9Kh.14Qkh7@0:?O;#;~#<Q582@2*>>(0:4RRS'o.T`h}7*9/oM.10Q0:7@;#,2@<0$;?a2@>I/2@2@4ZKh0:2X4Q5#.14:.T2@7/7Xk5O4:7@9;;a7*7X;_.1I/5O0Q.10:;2@2@NvKh<:4D>^MKhKTKT<MZM ;_Kh .hkh5Q8,^;)5O4:0:n9J4. 5Q,P4:9/h5O5:Kht(,ÆW0:,0Qk(,J;D2*.1>/.10C.17@Rb0:KhKh2@>Kb<:;>!2@0Q'/,KhGW
khO,;_<:;65O;#0DI/k/;;#2@4a4:.1060Q.[;5QN,WS7@Kb?^;2X5ON0:;<QKh2*2XK1;NP4M!I/.10:K>/Kh2@NPW>0:0Q.43,h;2*;6>[Kh.CKh0Q>,kJ;L;#;<D0:2@0:0:2@;;#4<=<O.1>5Q0:Kh,2@0_KbKh'>S2X5OG;2@4
,KT5Q;Mz,WSKbW[4:;_;#;N>P.1Kh4Q2X.T9N4Z<:4;0Qk,K1? ; M
4
ym9N
y
7
-6
g
4
06
!4
-6
4
L
86
?PSS8-'*"
g`
ºPQ /.0"
['*"
-`
S"¦< #0"
#
Y #
&
Y" YQ*)
YA
?y d
:n
Ed
ym
o §
/m
?dN
·
½
l
4
Y"-Q [
6
/
/4 Y"-Q
$6
]
»
?¨
ª ¨ Ë
9
© #© #§¨ :¨ kR ª© D§ «
ji
G3I iID\BLF
O O
5O ;
A@
)d
C
+
+
+
+
+
+
+
+
a)
+
b)
c)
2@Rh9<Q;D&' UJ\37@94:0Q;#<:2@>RKTMo.C4:;06K1MIJKb2@>0Q4kJ.14Q;N^Kb>S0:,(;abi$WS;NKb2XN4WS;0:,KN
WSK1M;_4QN9JKh5Q2X, N4358KhMKbWS<I(0:9,0B;C.T>0:2@;OKh{>S05O2*Kb0Q;#9<B7X.TN[0:2@kJKh;D>,('Z2*GRb,!,(';a5OKh4Q06KTMo.v4:2@>Rb7*;2@0:;<B.10Q2@Kh>^2@4Uµ $ #' (Kh<7X.T<:Rh;gh.T7*9(;#46KTM ´.1>/NPt0Q,;5OKh4Q0
0:,(;D }94:5#;5Oz<6Kh <OP3NKh2@ >9@RD7X% N0QK=7@2 9h}LI;L7@I/Rh0:KhKhKS<Q4Q2@5O;0:7@,90:W
,4Q0:;#;#<Q&<L; ' UJ0:.T,'eF<:;;t_3Kb.kh;6O4Q;.1;#5O0D<Q0Qk46K12@0:M2@<B>Kb.T0:kh<:K2@O7@;?a0:5O,0D5Q<Q,;#7@K;KKh5#584Q.T7*;60:9(;4:EN^0:;Kh2@<:kh> 4O' ;_.v5O0:<:4 ;580BW^.1>(.1Rh< b7@;S;N.14Lk? 4:,K1>´.T2@> 40:,2*;LRb92*>(<:;2*0Q2X&.1' 7UJ0:',<Q;#;#;=0D58 7*9(l4:0:;E(<
t/5O0:;,J>.T0Q0=;#<:2@4_4_'t
GN2@,4:0Q;#<:>´2@k;9.b0Q5:2@,Kh>[KhkhMKhO<Q;WS580=4Z2@.4N4Q2@2@7*4:,(0:Kh<Q2@9k;#90Q0:0:;_;N^;#>J0:K[582*<O0:5O,7@;;N^5Q,kKh?4Q;#N> Kh0:5O0Q7@;9N^4Q0:5O;#9<a<QNghKh;hWt.1.T42@>4Q4Z,K1k/.14:>S;_N^2@> Kh>P2@Rh9,(<Q2j;5Q, &('eFa587*9(. 4:#0:' ;<58;#>0:;#<2@460Q,;a>(;.1<Q;#4:0_'=9/5:,Æ.
0:kJ,(.T;D4:;GKhNv,khOKh2@4;_>5O0:2@4>J,NC2@2X>^5QK1, 0:M!,58Rb;a7*<:9(Kh584:9(7*0:9(;I4:<62@0:>5O;R;#<>'60:s;#2*7@<37;#R2@9(4.TI <B0:NN,(.T2@;>0:;L>R;0:0Q.1,K<Q;;#0:4:5O,0_7@;#9'Z4Q4:;a0Q9/;#>(<
5:;#,^58l;#.L>5O0:<:;#;#;O>i:<QN40:;'2@4:<:G0Q4<:t,/[email protected]O0Q2*;2*4_Kb58t1>0:0:4D,(MKh.1;6<Q<QWSWS;D;_<:4;ON.Li:KhN>2X2@NC;#4:0Q-K1<:M2@k4Q;[email protected]*,(0Q5Q;Kh,N 958;#0:7*0Q9(K0:4:;0:0:,(;;#<>/;a5O2*5Q4o2@,<B<:5OKh;7@4Q;5#;#Nv.T> 7Xk[email protected]:;4:;#N,<D;kJNN[.TKb4:5OW;9N.1<Qgh2@Kb>;h> 4 t
.144QG,K1,2@4>^I2@<Q> K58;#2@4:Rh49(<:<:;#;DI/&;'.TUD0:4k t',(2j5Q,Æ7@;.bN40:K 2*Rb9<:;S&(' U5 'gb;#>0:9J.T7@7*?t/>K^<:;Oi:N2@4:0Q<:2@k90Q2@Kh>ÆK1M30:,;KbkhO;5O0Q4a2@>Æ.1>? 5O7@94Q0:;#<
,J.TIIJ;>4=.T>JN[0:,;I<QK58;#4:40:;<:WS2@>J.T0:;#4_'G,; J>J.T7!5O7@94:0Q;#<:4D.1<Q;0:,;D<Q;#4:9(7*0KTM0:,;D5O7@94Q0:;#<Q2*>(RI<:K5O;#4Q4'
2@WS> J;0:9G,;,K>J;6N5O;'N ]^iuW[kKh?S;<QN;#KhKhK19(gh2XN0:;7@4<2@t;#WS<:2@064L;#0Q.TKh,7*<6K4QKaKbND0:>(2@,4;#;;W[<6N;OKh4L{<Q9;Z0:<Q4:<Q;#;#KhWS<Lk0:;C9K4Qgh0Z4Q.1IJ0Q7@,J9;58;#.12Y4>SM ? 0Q,Jiu.1W[t>P0:;,W[.1;>;4>.192@>>W'Z0:k/,;#;LK1<3IK1;#<:M;#gb4Q;#5O;#7@<9>Jt(4:5O2*0Q;0Q;#46<:KT4_IM ' <Q>KKb5O2@;#4:4:;[email protected]>>/R^N2*Kh49W[0Q7*Kh2@;#<Q<Q;458k/Kh;4:5#0Q.17@?9(4:0Q;D,J.1.L>^WS0Q;,N;aKbb2XNDi$WS2@4;[email protected];#>4Q44
é]ê ê ^Sïøðñ$ðñ ú6ñQú ÷ðí LóPñ:úõQïzø ÷ Lïðï Lïzó÷ó #ø ` ÷ oñ 6ó ð á_"âWäãåWäçæ
}¤7X.1<Q0$Rh?;I(N2j5.1.10O7!.b4:i$;WS0:4;'NGKhK2XNN4;IJ.1.17(<Q0:2@2*0:0Q2@,DKb>7X.1.1<QRh7@Rb;#Kh<<:[email protected],0OWl.64Q7@;#2 0:h4_;6t/.}ý 1]ÿ 3YKhþ < :i$43kJ; .T4:;;5ON0:2@W[gb;#;#7@0:?,KMKbN<Zt14Q5#W.T7@7*.1;_7@ND7JN(.10B.C}4:;} 0:4t($5Ok7@99034:0Q2@;#0
<:2@N>KRC;#47j.T>(<:RbKh;Z03.14B5#I.TI(7*7*;L2X5#Z.T;0:2@7*Kh/>(M Kh4 <
.146GN,;#;Lgb;#2X7@NKh;I/.;KTN^Mzk? }=7s.T}-9MW2@4
.T.T>S4.1MKb>J7*N^@K1s4_Kh\9f$4Q>4:;#4:;#0Q9;.hcN[)_KTxhM!xh0B| . #' 2@>R0:,(;=,(Kh7@;4:;#03K1MzN(.10B.C2@>0:Ka5OKb>4:2XN;<B.10Q2@Kh>!tbKh>7@?.4:W^.17@7I/Kh<Q0:2@Kh>
K10:,(M3;a0:,4O;.1WS<Q;I(.17*7;LN2@4.T0B4:.[;#7@;2@45O0Q5Q;,N´Kb4:2@>P;#>Æ.C.1Mu4D.12@.[<:7@?[<:;<BI.1<:>/;#4QN;#Kh>W 0B.T0:W[email protected];>>KTMZ;#<_0:t,2*;S06N(58Kh.1<:0B<Q.(;t5O0Q.17*>J? Nù<:;#ÿ I<Q;#4:1;þ >0Qý=4D.10:<Q,(; ;a5Q,Kb,4:Kb;#7@>´;MN(<Q.1Kh0BW.4Q0Q;#,02@t46.14B>J.TWSN[I0:,(7@;D;D9(<:;#4:2@I(><:R;#4Q/;#>}0B]Æ.10Q2@'ghf ; M
Kh4B.TkhWS8;I5O0:7@;#4 4W[KTM6;0:N,Kh;^2XNN4 Z.10O5Q.S,Kb4Q4:;#;#0>t3.1I2*I(7@77*2@0Q;#,4D;#/<:;8}MKh] <Q;DKhkJ>Æ;;4Q.b2*W[5:,ù[email protected]<.TWS0:KI0Q7@;h,t!Kh4Q.T;D>JN´5:,(RhKh2@4:gb;;#>^4DM0:<:,(Kb;SWck/0:;#,(4:;D05O7@,9Kh4:7@0Q;;#<:N2@>.1R´0O..14:4;#0_0:'Z,;Kb9}0:I9(}0'^N<B}6._44L;O{WI/9;7@5O0:0:2@;_IN7@; t
,;#}G<Q;,;[}wèù; 52@4.1;>0:5O,0:N;2@gb;4:.1;#2@>7/~#;#;C4Q2@4PK10:Mz,K10QM=7X,.1;D<QRh4O;#.1}=<ZWSN(I(.1} 7*0B;b.tN[4:;#;#IJ0Q2@4Z4;>J0Q0:,N,J4S;D.T>S>Kb9>/W}=0Qk/,]Æ;^;#<3'b4BGK1.1M,W[;658I7*9(5O7@Kb;4:WS0:;4:2@<:I~#47@;ht;O'-{.T2@>J0$rs?DN KhK1P0QM2j582@;;43.b0:5:0Q,,[,J;D.12@0:00Q;#Kh<O/0O.1}=.10:72@]pKb>>94QW>;K1.1k/ <O;#5:<Z,(kJKT;#;M458KhIJMWSKbKb<a2*;>4I0Q0Q,4µ ';^$kJè ;4:0 WS;NKh 2XN#4 t
.1W[}Kh>RD}.5#Rb.12@gh>(;#>>^Kh0 NJ.10O>/.N4:0:;#,(0_;=tk/,;#4Q;#0=<Q;5O.17@4694Q0:;#<Q}=2*>(R}¤2YMz4:.T;_>.1?<B5Q4B,.1;W[43IMKh7@;<3N0:,WS;L;_kJN;Kh4:2X06N2@4ZWS>(;_KhN06Kh.12XNW[4ZKh.T>WSRKb0Q>,R;0:kJ,;#;C4Q06ý [WS;NKb4O2XN.14W[' I(7@Kh;Z<3KT;OM!{J0:.1,W[;[email protected];h0Otb.D2YMz4Q;#.T0> '
Kh0:,(kh;68;k/5O;#0 4:µ05O7@2*9434:Kh0Q;#>(<:;62@>K1R/M!'!0QG,;,(2*WS4o;2*4oNKh;O{J2XN.h45O0Q2@7*>?0:0:,(,(;=;k/0:;#<B.b4Q06N;#K SWSM;_KbN<Kh;O2XN45Ok(2@;#9>J0Z582@?03'2@}-4Z>RbKbK0ZK4QN;#7@5O;7@5O90Q4Q;0:NP;#<QN2*>(9RD<Q2@kJ>.1RD4Q4B;.TNWSKbI>a7@2@4O>.1R/W[thI7@;#4}2*}¤7@7>Kb2*07@7>>(;;#5Ogh;;#4:4B< .T/<:2@>J7@?N
<:;I<:G;#K^4Q;#>2@WS0DI.<QRhK1ghK;DKN0Q,58;7*9(`b4:0:9J;.T<:7*2@2@>0$?PRK1.1M>/N´0:,4B;C5#.T7j,.TKhk7@2@;=7@2*0$N(?^.10BKT.M=4Q;#06}=2Ms0:,}a;t!4B.T.T>WSKh0QI,7@;L;#<a2*4587*k(9(2j4:.T0:4:;;<:N2@>' RÆ.17@RhKb<:2@0:,W 5.17@7@;NÆ}}=rL u37@94Q0:;#<Q2*>(R
[email protected]<:KhRb<:;Z2@0Q}L,[email protected]>J5#.1NP0Q2*5OKbKb>W4!kk/[email protected]>4:;#;_4ND0Q9,I/;DKh4B>.TWS}=I7@rL2@>NRKhW[0:;5Q2@~#,;>(N2j`b9;;.T<B5Q, 2@0:,
/.T}4I]Æ<:Kb'IJKbK14:3;NC;#ghk;? <t/$r9>[email protected]>/;DND6.T}>S)}xbx1t U 'f$}=0s2@4z}=.17@r64QK= .6NKiu;#W[46>;NKbKh0=2XN5OKb4> 0$J?I/>;;
2@0:4Q;#7MZ0:K^.1>?^4B.1W[I7@;=.T0=.1>?^Rh2@gb;#>^0:2@WS;h's+-,2@7@;}=s}l,J.T4=. ({;_N^4B.TWSI7@;D.10L;#gh;#<Q?P4:0O.1Rb;DK1MZ0Q,;D4Q;.1<O5:,t!}}=rL
Ý
¬4 \4§
im9
Ã
6 Å 6 U
½
s
gú
1
/4
Ì Ø
+
Í36
86
A
(
06
+
$6
/
&{
:|
Uײ
UC
i
á
1
Ñ
0³k A²
gÐ=²
? /.0 #&%
4
NU
!4
S6
86
º"8Q [
¿4
6
¬4
Å
\4:
Ø
66
Ã
*"*"P¦<>"
v
N
v
4
06
c4
36
1
¬
&
) m
¦ ©ª Á¦ z«©ª =¨ o« :«
4:<:N;_;<OI.1._<B7X.h5Q,45O2@2@>>.ÆR^R´4O..1.SW[4:Rb2@I<B>.T7@Rh;SI7@;, WS2@0:;_,,(N;#Kh4:<:Kb;2XNWS;#2@gb;^46;#5#<B<:?´.T.T>J7@7*>N;_KNSKbNWS0Q;,>;2@;#44Q4S.[#2@þ I/> Kh0Q;;#.h>35Q0:,-K12X.1M4Q70:0:4:;#,KbI¤;7@95OK10:9MD2@<:Kh<Q0Q>;#,tJ>;P2$0D' 4:;h5O;_'@7@t!.19<B.v4:5Q0Q,!4:;#;#<:'0D2@>GKTR/Ms',; G,WS587*;9(;_>4:N0:9Kh;W2X<:N2@>kJ4_'R;<GIK1,<:MK;S>5O5O;#;7@2@4:9Rh4P4:,0Qk/5#;#.1Kh<:>Á2@<Q>46R^kJ0:;PKKbkk/I(0B<:;D.T;#2*4Q<O>(;#.1;>>JN 0:N;Kb.NWSM0:.T;7@? 4<
0:I<Q<Q2@K;58NP;#4:2@4L4^<:4:;#0O4Q.10:<Q<:0:2X4S5O0Q.1;N´R.1k2@> ?Po.Kh0:IJ,(.T;#<B<:.1W[2@4:;#;^0:;0Q<,';Pf M
5O9.v<:<QkJ;#;>0:00:;5O<D7@9>4Q;#0:2@;#Rh<Q,2@k/>KhRÆ<LI2*<:4sKMNKh9/9(5O>J;#N4tJ. 7@K}=5#.1s7}=Kbr6I0:2@WWS9K1W´gh;'^4f0:M=KS0:0Q,(,;;7@>K;#5#[email protected],k/KhKhI<0Q2*4LW>9(KW N; [email protected]>JM KhN^90Q>J,N; t
;O2@0:{;#I/<O}.1;#<:0Q2@2*WSKb}>;r6>2@ >ò0O.17@4Q7@0B?P.1<Q}=4:0:,(4^sK1}=>Æ2@r60:, 0:KP>2@4a;#k/ ;SkJ.TW[4:<B2X.TKh5#>J.T<:N;7*@Kh?´; W[7@;7@2*?>(5O0Q;4Q2*.1gb;#<Q;^7@7*;?´5O0:0:,JI;_.T<QN¤>ÆKhI/>kJKhKKb<:N0Q0:;#2@,òKh4^>J/[email protected]>ò}7Z] 0Q4QK;.1.10Q<O>J,5Q,-NÆ;^>MKb9(<SW}=.ÆkJs;#>}a<C;'K1M=G7*Kb,Kkh;^5#O.T;5O765OKh0QW[Kb4I'ùI0:92@f$W0O0a.190:4QW´2@,KbKh>J'ò9(.17j7N 5OkJKb}=WS;^IW[}7@;O;#r6{>2@0:0$2@?^Kh,/>K1.1;_M4SN´;#k/gh0:,J;#;#;#<Q.T>? 0
.1> }KhkhO};58r6060:,/5#.1.T06>S4Qk/IJ;6;_5O92 J4Q;;#N4D,0QK K1¤J>JWN9J0Q5Q,,^;60:W[,Kh;C4:Kh0kh>JO.T;0:58906<O0:.1<Q7/9>7@?^9WkJkJ;#7@;Kb<z>KTRhMz4L5O0:7@K94:0:0Q,(;#;<:45O9(7@94:2@4Q>0:;#R<_ý#'=þ }=s}=r6^.T7*#4QþK;#/>J.Tk,7@2X;#5:4,0:2@,4Z;a.NI;#<:0:Kb;IJ580:;#2@<QKh0$>´?K1K1MM
MKhk99(? <Q0:0:7@$,2@;#;4:<:<=0Q4_;#t2@<W[2$[t ' ;hI7L'@<:t<:K10:2@gb;#,;Rb;DN[;#I/7zkKh.T?^2@>J>;O
N 0:{4ê6I0Q7@9Æ,JKb.1<:)2@06>xbNxhRKd 4:I/>' .1Kh0:02X.Tk/7z;#[email protected]>0BR.0Q4QKS0:<Q.19J>5O0:?S9(5O<:7@;#94_4Qt!0:4Q;#9J<_'c5Q, G.T4=,;D I/é ;#iu0Q<¢<:MKh;#;<Q4Wt!.1.T>/>J5ON^;4:K1KbMWS0:,;L;DMK5O9}=4Q2@>RS}0Qr6;5Q^,.1>7@2XRb`bKh9<:;#2@40Qt,W.145#<:.T;#>I/Khk/<Q;#0:;;#>N
éëê 3 ì¤ñ:÷øïøôí6ñQôïõ c÷ðí 6ó
}WS;,0:,2@;#K<ON.146<B5Q5#,.T2X>P5#.Tk/7=;5O7@M994Q<Q0:0:;#,<Q;#2@><DRÆ5O7XWS.T4:;#4:0Q2 J,;_KN^NÆ2@3>0QKhKS< .14RbRhk7@?ùKhW[Rh;#<:Kb<B.T90:I2@gh2@>;6RÆ.T>JNN^.10ON.P2@gKb2@kh4QO2*gb;;5O0Q,4S2@;#2@><B.T0:K<B5Q,. 2X5#0:.1<Q7;#;P5O7@9K14:MD0Q;#5O<:7@92@>4:R/0Q;#t<:N4_';#I/;#>J2@N;#<B2@>.T<BR[5Q,Kh2X>P5#.T7=,5O;7@0:9,4Q;#0:;#<<Q0Q2*>(,R;
,WS2@;#;<O0:.1,<BK5QN[,2X4:5#9 .T7;#N<Q;465OKbM <:WSKhW I/Kh2*4:0Q2@460Q2*Kb2@>J>.T2*k42@M7*Kh2@0$<Q?WS0:;KNsI/2@>a;#<$.M Khk/<:WKh0Q0:.hKhNWvO9iu9(4:0QI6WSKh;#<>0:0KbIKbi¢>JN5OK1;a.>W[Mu.1;#4Q<:,Rb2@;=Kh>!Kb'<G4:I,7@;Z2@06`bN9J;.1587@2@2*0$4Q?62@KhKT>^MJ2@.46IN9Kh<Q>;Z;b,('
2*;s<B;.15O<O;#5Q>,0L2X5#4:.10:79/5ON7@92@;#4Q460:;#,J<Q._2*>(gbR;
k/;#;#>P;#W[I,J.T4:2@~#2@>R0:,;2@>0:;#Rb<B.10Q2@Kh>SKTM,2@;#<B.T<B5Q,2X5#.17!.TRhRb7*KbWS;#<O.10Q2*Kb>a2@0Q,2@0Q;#<B.T0:2@gh;<:;7*K5#.T0:2@Kh>[WS;#0Q,KN4'
éëê 3Zê:ë W õ c÷!øïðñ 3÷ïú 6ñ 6ñQóñ Z÷ í6ñQ÷!øïøô(í6ñ:ôïõôõ:öLóhð÷øñ:ú
f$>^Rh;#>(;#<B.T7ut(0:,;<:;a.T<:;0$ZK0$?I/;#4K1M,2@;#<O.1<O5:,(2j5.17z587*9(4:0:;<:2@>RWS;0:,KN4_\
)b' 0: ,;#4QJ;= .TÆ0:KhW[12X5_5O" 7@J9 4:0Q;#<:" 4312@>0: K67X.T" <:Rh; <Z.1 >JNC#_7X.1<Q1Rh";#<Z58\7*f$9(034:0:4:;0B<:.T43<:0Q94Z>k0:?[email protected]@7X7.h0:5O,2@>;LRDKh;_kh.hO5Q;,S580:Kb4Zkh.TO<:;;5O032@> 2@>.L2*4Q0Q2*4>(RhK17@;
>S587*5O9(7@4:90:4Q;0:<Z;#<6Kb<.T>J9N>0:0:2@,7;2@0z>S4OWS.10Q;2*4<:JRh;#;44
2*5O>[;#<:0:0O,.1;2@>P2*<0QN;#;<:JW[>(2*2*>/0Q.12@Kh0:>S2@Kb>KTM5OkJKb;#>J0$N32@0:;#2@;#Kh>>i¢'
5O7@]94QKh0:;#4:0L<,4Q2*2@W[;#<[email protected]<B5Q<:,2@0$2X?h5#'.T7z5O7@94Q0:;#<Q2*>(RSWS;0:,KN4k/;#7@Kh>R[0:K0Q,2@4=5#.T0:;#RbKh<:?'3G,;#?PN2 ;#<6Kb>7@?
.1>JKbN[<;O2@{J4=.1.TWS7*4QI(KS7*;[email protected];k0:7@,;K2@N>P5#b.1i:7@7@;7@N94}6'3CGr6,;D W[;#}L0:,(RhRbK7*N[KbWS94Q;#;#<O46.10Q0Q2*,gb;[;zrsý8þ ;#4:0Q2*>(R þ 2@42*WS>0Q;<:0:K,NK9JN5Ot;_N,2@>;<:4;7;.1.h95QM, W^5O.17@9>4Q.10:>J;#<ND2@s4Kh<:9;I4Q4:<:;#;#;4Q9;#>-0:;)_N´xhxbk| ?
.17@7_ý 0:O,ý ;3NIJ.1.10O2@<.KTIJMzKbN2*>.10Q0O46.D2@I/>^Kh0:2@,>0:;a4358kJ7*9(;4:7*Kb0:;><Rht2@>.1RC>JN[0:Ka0Q,N;D2 4:;#2@<:W[;>2*7X06.T<:582@7*0$9(?a4:0:k/;;#<:0$43'3;#}6;#>´DrL0$ZK5OW[7@9;#4Q<:0:Rb;#;#<Q4D40Q2@,4;WS>;K.TN4:9;#4<Q;N[2$' ;hk'@?[t12@0:>J,N;C2@g4:2X2@[email protected]<QKh2*kh0$?O;_K15OM0:40Q,Kb;<
5O7@94:0Q;#<:4 60Q,J.10,/._gh;60Q,;D7@;.T4:06N2@4:4Q2@[email protected]<:2@0$?a.T>JNRbK;#46Kb>S2@>P.D>Kb>JN;#4O5O;#>JN2*>(RMu.T4:,2@Kh>'
F(' 2*0[" 2@>"$0Q#KÆ" J4: W^.1"7@7@;#1< .T>JN " 4QW .17@7@;#<#_I2@;15O";#4^\/9f$>00Q2*N7LK;;#.h45Q0:,-,;LKbkh<:;#O;gb5O;#0[<:4Q;DMKbk<:W[?44:0O.ù.1<:0Q5O2@7@>9Ra4:0Q;#<^2@0QKh,> .17@2@70:4SKbkhK1O;5O>Á0Q4Kh2@<>S9Kh>>(0:;=2@7L5O7@2*90[4Q0:4B;#.T<_0:t2@4 4:J9(;k 4 N2@58g;#2X<:[email protected]>2@>R
0:5O;#7@9<QWS4:0Q;#2@>J<:4.10Q2@2@4aKh>Æ.TkJ5OK1Khgb>J;SN2*.P0Q2@Kh5O;#>!<Qt0B.14Q9J2@>Æ5Q,ò0Q,.T<:4 ;#4Q.P,KhN7X;#Nù4:2@<:N;_2@4:NÆ0B.T>>J95OW;h'´k/;#VL<2*K1gM=2@4:2@5Ogb7@9;a4QW[0:;#<Q;#40:,2*K4CNKh4k.10O.1<:;2@>>(;N´Kh0DKbRb<D;#0:>,;#;^<O.1N7@7@2@? 4:0O._.1gh>J.T5O2*;[7X.TkJk;7@;a0$Z.1;#>J;N´><O0$.13<QK ;#7@? 5O7@Kh,J4Q._;#gb4:;0
kJ5O7@;#9;4:> 0Q;#.1<:I2@>I(R[7*2@;WSN;#N0Q,9K;N0:tK5#0:.1,(7@7@;;N^N2YVLf$58}=9rs7@0$?a} KTuMzVLW2@g. 2@4Q2j2*.C>(R}6.C>/.1<:7@2@?Rb4:,2@04 Nt;2*5842*4Q2@2@>Kh0:>S<QKKTNMz9J4Q5OI;7@N 2*0Q0:2*>2@>R47=.1.T09.DMW^,(2*.1Rb>S,S.17@>/;#gbN;#s7$'!Kh}l94QN4:;#2@g;92@4:c2@gh;)_xh,(xb2*;| <B#.1t<O.T5Q>J,N[2X5#.12@4 7
.17@4:[email protected]@;2@>i¢7@94_'
k/0:,(;#;a0$Z]^N;2@;;#4:<:>0ORh.12@>J5O>7@5O9RÆ;4Q0:KTk/;#M;#<Q0$4=5O[email protected];#<Q4Q;#;D0:>´;#.1<Q0$434^ZMK2*Kb47*IJ@KTK1KbM2@0:>;4_0Q>-t14 PkJ,.1;#.14Q<Q>J;; NN Kbí >ò' 2@430Q,0:,; ;NW[2@4Q0B;.1.1>/>v5OM;PKh<k/5O;#7@0$9Z4:;0Q;#;#>wU< h 5O7@9t 4Q0:;#<Q2@44'0Q,G;,>; 9(WkJ2jN;#;#<37@?K1M9IJ4QKb;2@N >0QWS4Z2@;_a> .14:h 9(<:;#t4v.T>JMKhN <N2@4:0O.1í >J5O2@;4
A@CBED
AFHG3I
AJCK
AFB
5BLJNM
&O
#0" W%?R'SQ
?z
N`
E
RTQZ"¦<[<"EPQ?"
®!P ["*#&<
+4
-6
;²
/C
&
ÞA
Y\
½²
0m
:Ï
U
d
;d
:Ï
:Ï
/
>
¿4
36
c4
-6
#&%=1"X #&Õ
P$1Q ?" <
E4
6
Cj
¬d
d
o
:
r4
»
A
S6
4
-6
¿
G 1
G ðYH
I
¨
Hñ ¼
¨
G=H ?
¨
¨
h
4h
4 h
4 h
4
h
©h
© h
© h
à 6
à 6
à 6
à 6
©
ª[
»
)
Ê »¶ Ã
fFg ]î ï Ff g C
ð
Ã
íÊ
»¿à Ê
Ff gò@ Á ï Ff g§C Ê
í
Ff g ]î ï fFg§C Ê Ã Ê
7É&4: à 6
»
Ê
Á
Ã
íÊ
Ê
Ã
Ê
:ª ¦ #¦ ÔRPª© C§ =«
Oó
G3I &I@CO AF5BLF
A@5O BLJ
A@
)q
C
a)
b)
2@Rh9<Q;D&'ed\37@94:0Q;#<:2@>RKTM .4:;06K1MIJKb2@>0Q4kJ.14Q;N[Kh>^0:,(; :}LRhRh7@KbWS;#<O.10:2@gb;
rs;#4:0Q2*>(R WS;0:,KN
,2@0:2@4;#<O K1.1<B5Q>!z,'2X5#PG.T7
,O;#58ô >´7*9(4:0:0:,(9;;SI<:2@I/5O>Kh7@R´94Q4:;WS0Q;#0:;#<:,0Q4;#,<Q.1K; <QN;a.Tt!<:W[5#;.T;#.7*<:@;Rb4QN´;;#NP0D}6K14QC0:M3;#r6KhIkhiukO;?b58tiu0:4Q340:;#Kh7@IK< 5.b4a.15#0:5O.T;_Kb4NP<BMN2@Kb>2@7*>@K1RP.v<:0Q4_;KS'5O0O4Qf$.1Kh>>WS2@Rb0:;7@2X;S.1I7@[email protected]<Q?2*46>/tJ4Q5O;,2@ghIK1;#7@<Q;a? >´4QKb9J2*kh>5Q,O;!5O.12@0Rb492@WS4D<:;a;#I<Q&(7XRh.h'e2@d5O>;_'LRN´}60Q2*,>Æ>;S0Q.1K [email protected]@4:Kh5O0QWS7@;#9<:;4Q4<B0:;#.1<0Q2@2@0:ghK1, ;M
0:,(2$' ;S;h'@tbWS2@>2*0Q2@,^WWS9W2@>2@Wa9J9(5OWl7@2XN;.T9J>ò5O7@2XNN2@;4:.T0O.1>>JN582@;S4:0Ok/.1;#>J0$58Z; ;;#4Q>2*>(0QRh,7@;6;Kb5Okh7@KbO4:;;#5O4Q0605OKh7@9kh4QO0:;;#58<Q0:4=4.T2*<:>Æ; 0QJ,<:;4Q058WS7*9(;#4:0:<Q;Rh<;' Nv2@>2@0QRhKa9(<:0$;3K&('eKhd khO;58064Q,5OK17@94:40Q;#0:<:,J4_.T'Z0DG0:,(,2*;^45O5O7@7@9Kh4Q4Q;#0:;#4:0<
WS.17@7;<:0QRh,2@;>RKhkhI(O<:;K585O0:;#4=4Q.T4=<:<Q;D;#I/W[;;#.1<:0QRb4;tN.1>J2@>N[0:K0:,(Kh; >(;=5O7@k(Kb4:2*RS;#4Q5807*9(587*4:9(0:;4:<0:;' <:4D.1<Q;DM9(<:0:,(;#<WS;#<QRh;Nt/.14L4:,K1>P2@> 2@Rh9<Q;a&'ed L.1>JN #'6gb;#>0:9J.T7@7*?t
[email protected]:2*}I>(7@2*2@0QN0:2X0Q2*.1g2*7@>(7@2@?4:R2@tgb0Q.1;a,7@73;S,2@0:5O;#,7@<O9;^.14Q<OKb0:5:;#kh,(<QO2j4 5;.15O.b0Q765#[email protected]<O<:N4Q;[0:2@;#>I<QR^7X2*.h>(0:5ORPKP;_NÆWS0Q,2@;#>;0Q,WKbK>N. ;{t2*5O5#W[email protected]@97@4Q;W0:NÆ;#<_ 'VL9Jf$G5O}=7@,(2XrsN;#;}>.1>0Q$,V6N;P2@2*g4Q5O0B2@7@4:.T92X>J.4:5O0Q;#;}L<>Jk/[email protected];#4a7@0$?Z4Q4:I;2@7@4;#2*#>0t.h0Q3,5#Kh5O;<Kb<B5O4DN7@Kb2@2@>4:>Æ;#R´4Q0Q0D0:,K´>;S;#4:<Q2@KbRh;#WS,gh;#k/;<QKh4:I<Q;^2*<Q>(2@Kh>JR<O5ONKb2@;#Ikh<_7@O'P;h;t5OG0Q4:4a9/,J5:.T2@,> 0
0:;,(.b;S5:,´5O7@5O97@94:0Q4:;#0Q<;#'<2*432@RhM 99(<:<:0Q;,;#&<6'ed 4QI7@2@065#.T.h> 5#5Ok/Kb<B;Ng2@>2@;#R[Z0:;_KN 0Q.T,4=;D0Q4B,.T;WS<:;;4:5O9<:2@7@0:0D;<:KT2XMZ.'0:,; 2@Rh/9<:<Q4:;a04Q&I'ed 7@2*0_'.1G>J,N 2@[email protected]:>^;#<kJ;C4:Ig7@2@2@0:;#0Q32@>;RSNPI.T<Q4K4:5O>J;#.T4:4I4:<:,(;KhIJ0:;4.T0:KT4_Mztz4:.T9/>J5:,N
4:I(7*2@0Qf$>Æ0:2@>;#RJ2@0Q',;#<gb;#.1>Rh0:[email protected]*WS@?;t<B;#.1gh0Q;2@gh<:?;D58Kb7*<a9(4:N0:2@;g<62*4Q2@gh2@;7@7!,5OKh2@;#><O0B.1.T<B2@5Q>S,2XKh5#>(.T7*7
?S58.7*9(4Q4:2@0:>;Rh<:2@7@>;6RJKbtkhKbO;>5O;0_' 5.1>Æ4:I/;5O2M?Æ0Q,;N;#4:2@<:;_N>9Wk/;#<K1M=587*9(4:0:;<:4S.14.
0:>;9<:WWSk/2@>J;#.T<Z0:KT2@KhMZ>S5O7@589Kh4:>J0Q;#N<:2@4_0Q'2*Kb>4:K0:,J.T0Z0Q,;,2@;#<B.T<B5Q,2X5#.T7!5O7@94:0Q;#<:2@>RI<:K5O;4:462@7@7/0:;#<QWS2@>J.10Q;,;#>[0:,;I<QK58;#4:4L<:;.b5:,(;#40:,;DN;4:2@<:; N
4:4:;I(7*7*;_2@G0_5O0:tJ,2@0QKh;,>Æ;,KT2@I;#Ms<:<OK.158Kh<B5O5Q;#<:,<Q4Q;4a2X5#5O.1.T00L7ZWS5O0:7@,;#9<Q;4QRh0:>;;#;O<QKh{2*>(<0LR4:4:I(0:W[;7*2@IÆ;#00:I/,(KhK2*7@2@N7>tJ30:40QKh,'< Kh9(9/RhKb5:,´>P,4:0:.^2@,(WS;aNI;_>7@5O;;h2@t(4:2@K17*Kh?^M>´0Q;#Rb2@>´;#4>;#58;#>J<:<[email protected]:Kb0:2X5#;_9.TNÆ>70:5O;#kJ7@<Q9;_4 5#4:.10QN;#92<:4Q4_;S'5O9(KbG7*>J0Q,[email protected];#;S4D0L.[2*.14_06Rht/<QW^2*Kh0L9. I´2@2@7*>K1MRS>Kh;#5Okh<QgbO2*;#0Q;_<2X5O5#0:9.14D>J72@NN4K[;WS582*4Q;,J2@<:Kh.1Rh>0L;_4NP
M Kb.TKh<4<
4:4:NKbI(KbWS7*>2@0;;>I4Q;0:<:;;#;#I!Ng462@t(KhW0Q9(K4:._7@;O?D?S{J7@>.1;W[Kb.b<N2*>(IJ0Q;6Ka;<$.17@MK1>JKb-N[<:W ;#`bgh9JKh.T.1kh7*7@O9/2@;0$.158?a0:06;D5O4:[email protected]4QRh.10:KI(;#K<QI4N[2@'>>Ra]^9(k/WKh;#<Q0$kJ;#3K1;#gh<3;#;#;K1><Mt58Kh0:7*,(kh9(O;64:;_0:WS5O;0:<:;4L40:'3Kh,<6KGNS5O,7@99N44QK0:;W[;#4Z<Q;#4><:' KbRb0Z;64OKh5#<.17@4Q;I7@32@06;#7@N7J;4Q5O2*2@>/4:5O2@Kb;>0:4,t;2MzN>(;Kh5O2@04:2@Kb>S2@4:;K1M;#>WSKb;#9<QRhRh,P;Kb.T0<
50:O,(7@9;4QL0:M;#Kh><Q7@;P2*7@>(K1RÆI(<:2@>KhW[Ra2*0Q4Q2@,4:92@k>Kb4Q0:R ;,5O;#N0:<S2@2@<QKb;58>5O7*9(40:2@'4:Kb0:>-;G<:,(2@0:>; KÆRÆJ2@WS0:<Q;_4:0_5:I(,(tz<:>K15#gh.T2X`h;[7@7*9(;_0:;#NP,4;´nMKhf:5O<7@9W4:0QC9;#<:7@t 0:2@J>2@IR<Q7@4:;0`hI9/IJ,J.1.1.T7@<Q2@0:4:0$2@;P?0:2@5OKbK17@>MD944:,0QKh2@;#;#kh<:<O2@O>.1;<OR/585:0:',(4D2j} 5,.12@;#76M <O;#W[.1c<O;#5:0:,(4:,(9/2j5K5:.1,Nù7@7@?2@W[49(;#0:0:4:KÆ,2@>K2@R^>N0:40:;<QRh.1;#<B<Q;.T;^0:4:;P0Q2*><:9J0Q,(<:5O2*K;0Q9N<B.19J<:<O;5O5Q4 ;_,N.T2X5#>[email protected]>N 7
0:k,(?ò;#> .´.15OI(;#<[email protected]*;2@>4Kh0:{,(;;#Nù<=5O>7@99W4Q0:;#k/<Q;#2@<a>RKTM=.T7*<QRb;#KhI<Q<:2*;0Q4:,;#WS>0B4o.T0:0:K2@ghM;´Kh<:I/W Kh2@><:; 0:J4>(.1;>JN Nù587*0:9(,(4:;#0:> ;<:4:4,'s<QG2*> ,;D44:0Q;_,5O;#KhW >JN0:t K15[email protected]@<O;NÆN^0:,(6; 65Os;#>t0:<:;;<SI<:K1;#M4Q;#0:>,0:;P4D5O;[email protected], 0:;#5O<[7@9k4Q?ò0:;#.<
4:I/;5O}2 J]P;_NÆM <B.h580:rD2@Kht/>!;O'^{IG7@Kh,(<Q;;#460:,N2@?<BN>J.1tW[5#.12X7@57@;WSNÆKN;7*2@= >7Rt!2@>^W[,;#2@<:;#Rb<B;#.T4a<B5Q5O,7@2X95#4Q.T0:7z;#<Q5O47@9kJ4Q0:.1;#4Q<Q;2*NÆ>(RJKb' >Æ0:,;#2@<D2@>0:;<$i:5OKh>>(;5O0:2@g2@0$?'^G,(;MKb9<:0Q,!t5#.17@7@;N
éëê 3Zê ãS_"ì ÆïõQïzúLô÷ hð÷!ø(ï!ðñ Z»÷ ã ÷ Lö6ôñ:ú lïú L_ õQö6óbð÷!øñQú ö6óñ:ú õì¤ñ:÷øïøôíLñ:÷!ó
}694Q>2*>(2@R>0:s;<:2@;#;#<B4Q.T0:2@<B>5QR,2@2*;#>4 0Q;#
Rh<O.T.14 0:;_NN;#gh,;#2@7@;#Kb<BIJ.T;<BN5Q,k2X?5#.147ö/5O,[email protected]>(0:RJ;#th<Q2*L>(RD.1WWS. ;#0Q<:,2@K4:,N>/th.15#>[email protected]*;_>JNaNnof:2@g>? )xhun3xbm.17X.T'!>Jf$05O;2@Nv>0:f$<:0:K;#N<O.19/0:5O2@;#gb4;60$3;KDN5O9/Kh5O>J2@>58;#RDI.10:>J4_t N3 7@9#_4Q0:;#1<Q"2*>(R
:RhKK_N[z4:1I/ ;#.1;>JNPN .Tø>JN^÷ù5O_7@914:0Q ;#<:2@>R4O5#.17X1.T"k 2@7*2@0$÷?2@>_7X.T1<:Rh=;_N1.10O .1#kJt1.T.14:>J;#N4_'94:f$;#04*2@4ù.1ú 7@4:KRbK.1K4N .M4:Kh9(<3WS2@>JW5O<:.T;<:WS2@~#;#;>[email protected]!4Q0:.1;#>J<N^<:;NI?<:>J;#4Q.T;#WS>0B2X5#.T.T0:7J2@Kh5O>7@90Q4:K=0Q;#.h<:5Q2@>,R[2@;#gbK1; M
2@>J5OKb} WS2@> Ra#N_.T0B1.C"IJKb2@>:0Q4(' 1¤ø÷ 2@4P. 0:<Q2@I7@;#0^4:9W[W.1<Q2@~#2@>RÆ2@>MKh<QW.T0:2@Kh>-.1k/Kh9(04Q9k5O7@94:0Q;#<:4ÆKTM I/Kh2@>0:4_' 2@gh;#>û i
c)
Ý
im9
+Ì
-Í
gú
s
4
?6
]ð&6
/
+
4
ò$6
6
Yñ$6
+ò*6
¬
C
–$6
ð&6
;
\
i
:|
ïÎ
H³Lï
NqÎ
>Ï
N
/
U
U
/
4
S6
4
Y4
h
âh
6
-6
o
<§""
¨
) &
N2@WS;>4:2@Kh>/.17/IJKb2*>0Q4 !ü # @2 > .C4:9(k 5O7@94Q0:;#<_t Æ2@46N; J>(;NP.14
C
¦ ©ª Á¦ z«©ª =¨ o« :«
A@CBED
AFHG3I
AJCK
AFB
5BLJNM
&O
u&'eFbE
,;#<Q; 2*4L0:,;>9Wk/;#<K1MZI/Kh2@>0:4L2@>P0:,;C4:9k5O7@94:0Q;#<t ÿ8þ è 2@4L0:,;7@2*>(;.1<4Q9W Kb> rI/Kh2@>0:4_t2$' ;h'@t ü þ t.1>JNËè¢èÁ2@460Q,;
4B`b9J.Tù <:;Dhý4Q9W þ K1M N(.10B.I/oKh2@2@4>0:;#4_4Q4:t;#2$>' ;b0:'*2Xt .T7*@?[4:9W[ü þ W.1' <Q?a4Q0B.T0:2@4:0Q2j584MKb<0:,;D5O7@94Q0:;#<_\Z0Q,;D~#;<:K1i$0:,t J<Q4:0t.T>JN[4:;5OKb>JN^W[KhWS;>0Q4K1M0Q,;
4:;O9(k 5O5O2@7@;#9>4Q0Q0:7*;#?[<34:M 2@<:>JKh5OW;C2*4Q030B.T4:0:9(2@WS4:0Q2jW5.1.T7<:2@I/~#Kh;#2@43>0:0,(K1;=M2@g>2@M;#KhD<:W^'f$.100Q<:2*Kb;#Rb> 2@4:.T0:kJ;Kb<:4905O<:0:9J,(58;=2j.T4Q7J9W[k5O;[email protected]:90Q;#<:;<:4WSK1;#M>0:I/4KhM2@Kh><0:435OKb2@>WS4:0QI;9(.h0:N^2@>KTR=Mz584Q7*0:9(Kh4:<Q0:2@;><:RS4.1.1>J7@7/NCIJ9Kb0:2*>2@7@0Q2@~#4;#' 44Q0:Kb<B.1Rb;
} ÷-_1 [email protected],;2*Rb,0$i$kJ.17X.1>/5O;NC0:<:;;6,2X5Q,a4Q0:Kb<:;#430:,;6587*9(4:0:;<:2@>RM;_.10:9(<:;#4_'f$0,J.14o0$ZKIJ.T<B.1W[;#0:;<:4\k<O.1>J5Q,2@>RLMu.b5O0:Kb<
1.1>JN 0:,<Q;#4:,(Kh7XN D'ÆG,;Sk(<B.1>/5:,(2*>(RPMu.b5O0:Kb<a4QIJ;_5O2 J;#4S0Q,;^W. {2@W9W>9Wk/;#<aKTM=5Q,2@7jN<:;#>!' G,;^0:,<Q;#4:,Kb7XNI/.1<B.TWS;#0Q;#<
4:5#I/.T>;5O2 5:J,/;.14 >Rb0Q;S,; 0:,(W^;._4:{2@~#2@Wa;S9(KTWM
0Q,N;2j.T0:WS<Q;#;#;h0Q';#<SGKT,Ma;4:9(>kKh>5O7@iu97@;4Q.0:;#M
<Q>4 K4QN0:;Kb4D<:;4:N¤0QKh<:.1;[0[4:0:9,W[;Æ47@;K1. M6Ma0:>,(K;#2@N<a;#4_5Q'c,2@7jnN<:?w;#> 5Q,J4 .Th£>Rhý2@>4Rùt!.T0:>J,N´;´0:0:,,(9<:4_;#t4Q,4:Kh97XW[NÁWgh.T.1<:7@92@~#;P;DKb0Q,>;;
2@>MKbG<:W,;D.T0:no2@Khf:>.1k/Kh9(.107@Rh0:Kb,<:;#2@0:2@<6,(W±5Q,2@,/7XN.1<:4;0:>!,(' ;6M Kh7@7@K12*>(RD0$ZKI,J.T4:;#4_\
K1Mz0QJ,#;a N.T\!0B.C5#0:.T,J>a.T0N0:.T<Q0B2*.1;k/46.10:4:K;oI(0:K<:;#k4Q9;#<:2@7XgbN;a.10Q>,;2@>2*2@>(0:2X,.1;#71<:2@;>>i$0WS5O;7@WS94:Kh0Q<Q;#?
<:2@>Rv4Q0:0:<Q<Q;#9J;h5Ot10:9(,<:;2X5QK1,aMz5#0Q.T,>D;ak/N;.Tg0B.(2*;' Z;NC.14!.W9(7*0Q2iu7@;#gb;#7 58KhWSI(<:;#4Q4:2@Kh>
J#¸ ¹ \}6II(7*?S. 4:;#7@;580:;N 5O7@94Q0:;#<Q2@>RS.17@RhKb<:2@0:,(Wc0:K5O7@94:0Q;#<0:,;7@;. Mz>KN;#4LK1M0:,;a i$0:<Q;#;h'
Kh>>(K;hN(';Kh}
._<M0QIJ;#,J<6Kb.12@2@>4Q>0;4Q;#2@)b<:4t0Q2@2@0:Kh>,(>^4:"; ;#<Q2@460:ù;ú7XN .1<Q0:RhK^;#<Ls0:,(0:2@46,J;S.Tk5O>P97@Kh2@0:7@4:,0=;;C4:N0D?0:,7@>/;<Q.1. ;#WSM
4:,;#2XKb5#>.T7X0QNP7@<:7*? ?Sgh.T.T7*4:4D9(9(;hkNt.15O0Q7@0O9,.4Q;#0:I/>P;#Kh< 0Q2@#,>'[;D0:4Df 7@M
;.1._0Q<QM3,;a;S>2@>KN4QN2X;#.1;a<:W[0Q.1;>/;#N0:NS'D;<=I/GKhKT,4QM
94:0Q2@4_k,t7@;0:?^,(4:Kh;a9(0Qk W[,5O;#7@;#<690:4Q,>(0:KK;#N^<N;#4:[email protected]<Q<:>;;CN´2*4:>/I2@>5O7@<:2@0;#0QW[',;}s;#>M7@;0:0B;._.T<M7
0:4:,(2@~#;D;2@KT>M
4:;#0Q<Q,0:Ô;2@Kh> ùú K1Mz0Q,L;Dk>? ;5Q,JIJ.1Kb>(2*Rh>2@0_>tRS0:,(0Q;D,;2@>0:M,(Kh<:<Q;#W4Q,.TKh0:2@7XKhN>'.1f k/MKh0:9,0;2@4Q02*~2@;46I/K1MZ.14:0Q4Q,;;N^WS0QK1;#
W[.TKh<BN<Q?S40Q0:,,/;D.10<:K2@4=Kb06>(;#K1;MN0Q;,N ;DM0:Kh<Q<L;#;h4:'0QKhL<:2@>>;aR^5#0Q.T,> Ô; 5Qù,J.1ú >(Rh;Ds0Q,2@;4
7XG.1,<QRh;;#<<Q;#0:k,/9.12@>Æ7XNP0:I(,(<:;aK4Q5O2*;#~4Q;4aK12@46MI/0:,;#;<¢MKhW^<QWS.12@;>^N WSk;#?PW[kKh9<:2@?7XNt2@0:>,(RS;#>.[.[>;#4:
W.T0:7@<Q7*;#;;<6Mgh<Q.1Kh7@W9;C0:K1,(M;0:7*,;_<Q._;#MZ4:,>KbK7XNN´;4D2*4K14QMZIJ0Q;,58;2 /Kh;7XNN^.T0Q>J<:;#NP;b'0Q,G;%,ù9ú4t0Q,;LI2@4<QK<:58;#;#k4:9(42*7@K10_M '
<:4:;I(k7*2@902@2@7X>[N2@>0:,R;0:5O,Kh;C>0:4Q<:0:;<Q;D9J5O2@0:4=2@KbN>SKb>K1;Mzn2*0Qiu,0QKh<:9(;#;040:'3,G;D,>(;#;<Q5O;O;#M4QKh4:<Q2@;h0$?PtM KhK1<Mk<Q;9(.h2*N7XN2@>2@>RSR.T0Q7@,7;60:,0Q;D<:;#I/;ht/Kh2@N>.10:0O4_.'3,JG.T,4Z2@40QKD2*4kJ4Q;2@WS<Q;[email protected]<O0Q9K4:0o0:,Kh;D>J5O2@;b>'Z4Q;#<:Kb0Q2@WSKh> ;3,.T;#>J9N[<Q2*>4Q0:K2XN5O;4
.1N>/.T0BN.WS' ;0:,KN4Z.T<:;.17@4:KD2@>0:<QKN9J5O;N[0QKaN;.T72*0Q,Kh90Q7@2*;<:4.1>JN2@WSI(<:K1gh;30:,(;=`b9J.17@2@0$?K1Mz 0:<:;;#46k?.hNN2@0Q2*Kb>J.17(4B5#.T>4K1M!0Q,;
Æ}sno0Q<:f:M;#0:;C;#<D2*>P ù0:<:,/0:[email protected];#<Q4:4;#;D;0QF(K2@46' I(k<:9(K2*N7@0_9Jt 5O;[.T>0:? ,;587*9(k/4:;#0:4Q;0a<:2@5O>7@9RP4:0Q.1;#7@Rh<:4Kb<:2@0:2@,(0:,PW 0Qt,4:;S9/5:._,Æ[email protected](7*0$;?I(<Q;#2j54:Kb.197!<BI/5O.1;<:40Q'[2@0:+-2@Kh>2@0:2@>,´R^7*[email protected][7@Rh2*Kb0Q;<:N^2@0:,(.1W W[tKh5#9.1>>´0K1kJM;W94Q.T;2@NP>W[2@;#0QWS, Kb0Q<:,?; t
}
0:.1K> 4:M 2*2@9W[><:Rb0QIJ7*,;Kb;#<:<64O0O5#[email protected][>>´0
I58K1<:KhM
K1>gbN(4Q;Z.12jN0Q0B,.;#<B;a4Q.T;#`b0:[email protected]?>´7@2*2@;0$2@7j46?N'!4=0:K[.KWSk/0:[email protected],(>4:;2@2XW5C58Kh2YRh~WSK;6KI(0:N^9,(0B;a5O.T7@0Q90:2*2@4:W[Kh0Q>S;#;<:5O2@<:>Kb;WSR/`bt!9I.12@7@<:>J;O;_{NN^2@0$KhM?Kb><6K1;DMzf Kbb0Q<6,a;DW['(.1f$Kh0=7@<:Rh;D.TKbI<:.b2@IN0:7@,(N2@W±;#2@0:4=2@[email protected]>/W.1µ 7!944O 7@5#0:.12#iu>(tI(4,J5.1,(.14Q;#;=> <:; 5O7@Kh9I4Q0Q0:2@2*;#43Kb<Q>J0:2*>(,.1R;D7@7@? >0Q;395QWkJ,;C>k/2X9;#`b<34:9;K1;hN M \
Khkh8;5O{0:4LI/;#0:<:K2@W[k/;a;#>5O0:7@4694Q,/0:._;#gh<Q;;N4:' ,K1>´0:,;7@2@>;.1<4O5#.17X.1k(2*7@2@0$?SKTMZ0:,(; .T7*RbKh<Q2*0Q,W 2*0Q, <Q;#4:I/;5O00:K^0Q,;a>9Wk/;#<LK1MZI/Kh2@>0:4D.1>/NPRbKKN
0:2@`b>^KC9J.12*4:0Q,J7@[email protected]$?4:IJ2@~#;hK1;bt/M tn58.=7*f:9( 4:0:;i$<:0:2@<Q>N;#R;6K;K1>46MzK>0QN,Kb;;D0NNIJK.1;#;#0O<¢4M.Kh>'<QKbW0ZK1.1337@;#;#7@gh._7!;?k/<4 t;585#4QKh.T2@>J<:9<Q5O4:;#;;C4:I/;2*Kh.h0>/5Q9(,[NS4:;#>0Q4LKKD0:N.,;;D>J2*>^.1>(0QKh9 0:<B2@.TKbiu7J>S0Q5O<:K17@;#9M;D4Q<O0:5#.h;#.TN<_>'Z2@9Kb]^4>KbKb7@?a<:<6;#,(NK1Kh2Xgb.17X;#NWS<tb.D;20:M!7@;#2@0:<3WS,0:;62@KS0Q5O;5O7@ND9Kb>4Q>0:90:;#<:W<QKb467!k/.10Q;#<Q,<3;;DK1>M!k/Kh;#Kh0>94Q0Q>JI<:N(2@,;#.1;#4=<:<Q?[N2X5#9K1.1; M7
.5O7@94Q0:;#<_'
éëê 3Zê _ »ã _ õQö6óbð÷!øñQú ÁóñQú ã Lø÷!ó÷!úoðïðñ Z÷!ó
;#]^>J,Kb582@W4:;0aK15O)_MZ7@xh9Kbxb4Q9& 0:0:#;#7@tb<Q2@2@;#2@>><:4_R0:;#'6Rb.T}L<[email protected]> Kh0Q;#<Q2@42@>0:0:,,;2@W[<:;#;#<O44Q.10:;#<B2@5Q2@>0:,R^,2X;#5#WS<C.T7!;#Mu0Q.1._,gb>JKKhNvN<:4DIJtJ.155O<Q.17@0:97@2@7@4Q0:;0:2@NP;#Kb<Q>4a2@>6Ra[email protected], 7@Rb4QKh$I3<:2@,7@0Q9;#,<Q4:WS2j0Q5;#4.1<:7[email protected]>>/4:R^,/N.1K1I/4:gh;S2@;><B.1R^5O>JKb6N´WS4Q;#2*I(43W[<:0:;#2@,4Q7j;.T;#<>I0B4:<Q.12@Kh~#0Qk2@;#gh4_7@;#;#tW4 Kh#<atK1kM!.T? <:M$;._$ghMKh<O<Q9.12@Rb,J>2*.(Ra7@;t 5OL2@7@>9.14Q4Q0Q0:0:,;#Kh<Q;Rb462zI.T<:2@;>J0:4$N, i
4:I(,;#<:L2X5#6.T7 4:,J;#WS.TIJI;[email protected]?>/4NS.L4Q>2@WSK1gh2@7X;#.17/<,4:2@2@;#~#<O;#.14_<B' 5Q,2X5#.T7J5O7@94Q0:;#<Q2*>(R .T7*RbKh<Q2*0Q,W0:,/.10Z.bNKhI0Q4Z.W[2jN(N7@;Rh<QKh9>JNCk/;#0$Z;;#>^0:,;65O;>0Q<:Kb2jNiukJ.T4:;N
I/.1>/KhN2@>0:0:4D,(;=.1<Q.1; 7@7i$5QIJ,KbKb2*4:>;#0>´;O{0:K[0:<Q<:;#;#WSI;<Q;#44:';f$>>(04:0:.^;_.h5ON7@9KT4:0QM!;#9<4:'C2@>GR,.;#4Q4Q;2*>(<:Rh;#7@I;=<Q;#5O4:;;>>0Q0O<:Kb.10Q2jNv2*gb0:;KIJ<:Kb;#2@I(><:0Q;#4=4Q;#.T><:0=;.DRh;#5O>7@9;<B4Q.10:;#0Q<_;tJN´. k? {J;N<:4Q0D>94:W;#7@;k/58;#0:<2@>KTR^M!<:Z;#;I(7*<:;#i$4B4Q5#;#.T>0:0B0Q.1;#0Q<:2@;ghN;
hý!â4©Ëÿ8þ èC©èè6
WÂo
c
4
WÂo
Å
AZ <"$ #&%ÓV?"=<§Z&S"
c
&
Nz
·
d
·
d
C
¬û
4
6
C
!<:S""
4
6
!<:S""
á<:S""
á<:S""
Ø
C
C
C
94
¬4 +6
C
C
[î
³
U
U
~
>Ï
a4
6
-6
¥
4
6
-6
:ª ¦ #¦ ÔRPª© C§ =«
Oó
G3I &I@CO AF5BLF
A@5O BLJ
A@
)x
C
+
+
+
+
+
+
+
+
+
+
+
+
+
+
b)
a)
+
+
+
+
+
+
+ +
+
+
+ +
+
+
2@Rh9<Q;&('em\37*9(4:0:;<:2@>RK1M.4:;#0KTMIJKb2*>0Q4Zk?L6
MuI/0:.b,(Kh5O;a2@0:>Kb.10:< 7@4Rh#'MKb<:<:KhG2@0:W,(,(;aW 0Q,5O' 7@;94:5O0Q7@;#9<:4:4C0Q;#<D2*.10Q,P>JN 0:,(0:; ,;5O> 7@Kb4Q4:,;#4Q<:0=2@> I/.12@>2@<6RKT0:MZ,(<:;#;#W I(<:0Q;#K14Q
;#>.T0B<B.1N^0Q2@0Qgh,;; I/58Kh;#2@>>0:0:;#4=<D.TKT<:M;0:0:,,;;5O5O7@7@994:4Q0Q0:;#;#<D<Q4Dk?P0:,J..T0=4QIJ.T;<:;582 /WS;;#N <QRhM<B;.bNP5O0:.T2@06Kb> ;.b5Q4Q, ,<:4Q2@0:> ;#I´2@>K1R M
4:2@4I(,WS;#LKb<:._2X<:5#g;6.T2@<Q7>KhR´4:k,/9(WS.14:I/0Kb;#<:0:4D;[K.10:Kb>J,J9NP.T0:>ò7@._2@;#gbKb<QKh>462X;^N.1>J4Q<:2@;#N[>I(Rh2X<:N7@;#;O;#4Qi$>;#7@>2*0:> 20BJS.1;0Q46;2@gh5O;´;7@95OIJ0_4:'0QKb;#2*G><:40,,J;DIJ._;4:g<,(2@<:>5O2@RD>7@9>4Q2@0:Kb>;#>RS<^i$4:,.1I;7@,7@7*K1I(;4=<:2X4 5#N.1.T7WSL4:,JI/6.T;#>^IJ;0:4=0:,K.1;>/.b; NSN#O;95O4Q2X0:N04C;ZK1ghM;#.T7@Kh7<:92X0Q.10QKÆ>J7@2*58;0:;=<:,42@;P's>[GRb4:;#2@,~#Kh;#;hW[<:' ;8;#M0:Kh<Q<Q?Æ;ht!K1MD6>LKb> i
2@0:4 KJ?G<:2@4Q;#K067XN,JIJ.T0Q.T>J,<:N0Q;a2*7@0Q;ZN2@Kh;7X.T4:>2@<:;<:RhN^;;3N .TN>J5O.17@N[0O9.14:;kJ0Q.h;#.T5Q<:4:,P4_;#' 4_IJt.T<:0QL2*0Q62@Kh^>^;#2@W[4[email protected]<Q?0:4!2X.1.=7@7@58? Kh58W7*9(k4:2@0:>J;.T<:0:;2@NKh's>LGK1MJ,<O;D.1>JIJN.T<:Kb0:W2X.T7!4B.T5OWS7@9I4:0Q7@;#2@><:4DR.1.1>J<Q;DNC0:IJ,(.1;#<Q> 0:2@0:5O2@7@Kb9>4Q0:2@>;#<QRJ;\/NP}2@>^<O.1.>JN4:;Kh5OWlKb>J4ON .1W[IJ.1I4Q7@;4
IJU .T<:0:G;#2@7@0Q,2@2*WS;´Kb>S2@W>J4O.T.1.0:WSO;KhI(<Kh7*9;4Q0Q0:L7@;#2*I;0Q<:4K 4DSK1kMa?PIJ0Q.T<O,<:.1;0Q>J2*0QN2@KhKbL>W 64_th4Oc;.1.bWS.T5Q,7@I(Rh7*KhKT2@><QMz2@R/4Q0:2*,\6~W ;2M
. .1<Q5O; t7@9uk4:E <Q0Q2@;#; <DIJJ.T?-Rh<:<Q0QK1Kb2j.T97@4D0:7*?7@2@0:>K5O;7@K^9N-4Q4:0:[email protected];#K14[<DIJMtKh.T;7@<:7@7*K10Q2@W[2*0Q2@42*Kh>/\ >.1430:B;C)2@>^2*0Q0 KN<B$._d D58.ù7*5O9(7@<B4:9.T0:4Q;>J0:<a;#N<QKbIJ4W .Tt<:M 0QKh4B2j<3.1.TW[74:Kh5OIW[7@97@; ; 4:0Qh;#t<:4_utZF )b. t
I<Q,K;#58<Q;#;64:40Q,K1;M!W4Q,9<:7@2@0:> 2@I2@7@>;R<:;#WI(<:9;#7@4Q0:;#2@I>7@0B;3.10Q<:2@;#ghI;#<Q4;#4:5#;.1>I(0O0:.190Q<Q2*;6gb;a0:,(I/;Kh4:2@>,J0:.T43IJ0:;K1KTM .10Q<O,N;6435O0:7@,9;4:0QRh;#<O< ._g.T2*>J0$?SN 58u;#m >0:W^;#<L.1k< D?SN..TM0B<O.L.h5O0Q2@2*0:Kb,>S0:KT,M ;6358Khth<:4Q<QIJ;#;_4:5OI/2 JKh>/;N^N2@k>?SRa5O.7@994Q4Q0:;#;#<< t
7X.1k/;#s7@4;#' <:;D3;I<:;4:;#>0=.T>^;O{J.1WSI(7*;L0:K4:,K1¤,K16LÆ3Kh< 4_'
7@2 h;6 0Q2@KS<:4Qz5O07@ t9P4:dh0Q|^;#<6Kbkh0Q,O;;D95OIKb0QI/4 khKhO.T;4Q<:;5O;0Q460:4B,.T2@;#>WS<Q0:;SK[email protected]$;<QZN´; K.1.v5O4C7@4:94:;#4:,0D0QK1;#KT<:MZ4_>ÆKh' kh2@>8;5O!0:2@4Rb97@K<:5#;^.1&0Q;'emN 2*>Æ'S.G<Q,(;5O;#0O>Æ.1>0:,Rb7*;;4:;^<:;KhRhkh2@KhO;_>!5O'D0:4;#.10<Q;IJ
.1<Q0:F2@t/0:2@0QKh,J>(.1;0N´2@42@>t/2@0:0:,(2X.1;a7@7@9?S4Q;#2@><D0:3KPKh0$937XNK
5ON7@2@94:0O4Q.10:;#>J<Q584;htL';.h.h5Q,-5Q,^5O5OKh7@>90O4:.10Q;#2@><Z2@<Q>;#RÆI<QFh;#d 4:;#IJ>Kb0O.12*>0:2@0Qgb4;=' 2@4+ÆW^;S.1I/< h.1<:;0QN2X.1k7@?7@?.5O4:7@W^94:.10Q7@;#7<S58<:0QKh,4Q;^4tIJ.T.14Z<Q0:4Q2@,0:K12@Kh>(>42@2*> >0QKò2@Rh)_9| <Q;65O7@&9'em4Q0:;##<Q4^'GkJ,.1;#4Q;4Q;Nù<:Kh;#>I<Q;#WS4:;2@>>[email protected]*gb7;#W[46;.1.1<Q> ;
4:.1,(>/2YN^M 0:;MKbN<:W0QK1
0$3.T<BKN45O7@0Q9,4Q;=0:;#58<Q;#4>'C0:;#G<3,K19(M4Rht<O0Q._,g;a2@0$Kb?DkhkO?;5O.s0Q4aM<B.1.b<Q5O;a0:2@I/Kh.1> <:0Q32@0:[email protected]>4:;_,(N^K12@>>0QKS2*> 0$3K2@Rh5O9(7@9<:;64Q0:&;#'e<Qm 4t#'2@G0:, ,;0:?,;5#.TKhI90:0Q9(7@2*<:;;6<:40Q,<:;6;#W[4Q,JK1.1ghI/;;NtJK1M!.140Q,4Q;6,K15O7@9> 4Q0:;#2@> <
2@Rh9<Q;&('em #'
f$4:039/5:4B,Æ5#.TL.17*;4640QùZ,;D;#I7@7(<:4:K2@M~#KhN;<39/K15O7X.1M3;#<Q4D0:Rh,,;6;2@NRb<B.T, .T0B>J.1`bNk/9JKh.1.TW 4:7@2*;0$4?S4B.T58WS7*2*9(0QI,4:7@0:Kh;h;9(t(<:04D0:,[email protected];>^5O><:0:2 9,W;5O2@k/;O>{;#R2@<4:5O0QK17@;#9M
>J4QN5O0:;;#;#4:<QK12@2*<:>(MZ;_RSNKb9`h5O0:9/7@[email protected]@;#7@4Q2@<Q0:0$4;#?tJ<Q'!458tKhWS.1L>JI(6N 7*´;80:{,>;4:;,/;4:.1N,I/4=<Q;#2@.=>4MK1;#2*MZ>(-R5O7@99M4Q<O4:;#.h0Q<$5O;#i$0Q<:4:2*4CI/Kb;>5O2*2 Z0QJ,P';_NPNL2 IJ>.T;;#<B<Q.T`h;#WS>9(0;#;#4:0Q4:0Q;#2@2*~#Kb<:;h4_> 't
2@; 4D;0:,(5O0;K14:M
;#>5Q4Q,[email protected]:2@>gRh2*0$2@>?´R[K1IJM.10:<O,(.1;#W[4:;[;#0:IJ;#.1<Q4<O.1'WSf$0;0:4:;#,(<QK14D0:4K^.T0:7@,(0:;S,Kb<:9;Rh4:9,P7@0:4Q4CKhW[K1M=;[email protected]<O0:.1;#W[<Q2*;#>(0:RJ;#'[<Q4D}±5#.14Q>´;#>kJ4Q;2*0Q2@ghg.12@<Q0$2@?Æ;N^.1>J.T2@7@0:?,4QKb2@4=90,/.12@WS4DIJk/.b;#;#5O0:>ù2@>IR<:K10:g,2X;N;`bN9J.1Kh7@2@>Æ0$?^0Q,K1; M
5O7@94Q0:;#<Q2*>(RJt0Q,;DIJ.T<B.TWS;#0Q;#<Z4Q;#0:0Q2@>RS2@>SRb;#>;#<O.17NK;#46,J._gb;=.4Q2*Rb>2 5#.T>032@> J9;>J5O;DKb>0Q,;D<Q;#4:97@0Q4'
c)
d)
94
S6
i
v
{
UË
;
¥Ë7É$
4 76
\4 86
+Ë ¿4 86
cË7É$0ì
4 &6
7`A4 -6
?`
¶4 -6
Lì
Ý
im9
U+
gú
1
9
ð36
º
Eñ$6
/ò$6
¨ 6
&{
Fh|
¦ ©ª Á¦ z«©ª =¨ o« :«
A@CBED
AFHG3I
K-nearest Neighbor Graph
AJCK
AFB
5BLJNM
&O
Final Clusters
Data Set
Construct
Partition
Merge
a Sparse Graph
the Graph
Partitions
2@Rh9(<:;D&'eq\}]PrD\2@;#<O.1<B5Q,2X5#.T7z5O7@94Q0:;#<Q2@>RkJ.14Q;N^Kb> biu>(;.1<Q;#4:0L>;#2@Rh,k/Kh<:4.1>JN[N?>J.1W[2X53WSKN;#7@2@>R
2@2@4>0:4:;#9}L<¢2@i¢0Q>5O;KbKhN[>0Q,>M;#Kb;<z<6580:.T5O2@Rhg7@9Rb2*0$4:7*?Kb0Q;#WSK1<:2@M/;#><O0$R^.1Z0QKD5#2*gb.15O;0Q7@;#9,Rh4Q2@Kb;#0:<:;#<B2X.T<Q5#4
<B.15Q.T7,R2X.1.15#0Q.T2@0:>7<:4Q2@5Ok0z7@99(.L4Q0:0:9;#;#4_4Q<Q'Z;#2*<$>(f$i$0R=4:I/W[.1;7@5O;Rb2.1KhJ4Q<:;92@N[0Q<:,;4QWw460B.10:N,(0Q2X;#;D53gb4:;#2*>2@7@WSKh0QI/;#2@<$;7Xi:.1N5O<QKh2@k0$>(? ?D>$K1;5OM0Q90$2*Zg,J2@.(KS0$t?D5OL7@W[9.14QK4:0:0QN;#Kh;#<QRb47$2htk.1>J?^,(ND;#5O<:Kh;W[,0Q2@IJWl,.1;<Q)2@2@xb>>xh0QRD;#x <$0:i:,(t5O5#;aKb.T>.17@>7Rb;Rh5O<:0Q;2@R=g.12@70$0Q? ; t
K1>M9W0$Zk/K;#<Z5O7@KT9MZ4Q0:5O;#Kh<QW[4 WSh Kh>.T>J>N ;#2@hRb,k/.1Kh<Q<Q;4NkJ; ;J0$Z>;;#N[;>Pk?0$Z0:K,(;=I/Kh>2@9>W0:4 k/;#<3.1K1>JMzN 5O<QKh4Q4' 7*2@> 43kJ;0$Z;#;>P0:,;L0$ZK5O7@94Q0:;#<Q4t.1>JN 3.1<:;0Q,;
5OKb>J5O;#I0L= K17 M4:J,/<:.14Q0a<:;_5ON^Kb>>4:;#0Q2@<:Rh9J,5Ok/0QKh4 <Q4.vt4:.1IJ>/.TNS<:4Q0Q;,;#Rh>P<B.TI/I;#, <¢MMKh<:<QKbW W .C.S,Rb2@;#2@gh<B;#.T> <B5Q,N(2X.15#0B.T.[7z4Q5O2*7@W[94Q2@0:7j;#.T<Q<:2*2@>(0$?RSW[email protected]<:<:22@{0:,9(W 4:2@>KhRP>S.[0Q,4:;D2@[email protected]<Q<Q4:2*;D0$?Rb<B0:.1,(I(<:;#,!4Q' ,Kh7XNÆ.1>/NP0Q,;
éëê 3Zê _"ìkW aâ *W£í6ñQ÷!øïøô(í6ñ:ôïõDôõQö6óbð÷!øñQú ïzõ øñ¢ðí ö6óñ:ú sû6ú6ï cñQô 6÷!õQñ:ú
}65O7@9>(4QKh0:0:;#,(<Q;#2*>(<RJ2@t>,J0Q;#.T<:4;4:kJ0:;2@>;#>RÆN5O;7@9gh4Q;#0:7@;#Kh<QI/2*;>(NR k.T? 7*Rb7=Kh<Q.T2*<:0Q?,IW 2@4tt5#6.T.T7@7*>S;_NÆ.1>JN 7L}=9] W.T!< B)xbrCxhx t#',f$>2X5:2*,ù0Q4;O5O{7@I97@4:Kh0Q<Q;#;#<:42@>NR?I>/<:.1KWS5O;2X4:5C4t(WS0$ZKNKD;#5O7@2@7@>9R[4Q0:;#2*>Æ<Q4
,(.T2*<:;;L<B.1WS<O5Q;#,<Q2XRh5#;.1N 7
25OMDKb>0:,>;P;5O2@0Q>2@g0:;2@0$<$?^i:5O.1Kh>J>N[>(;5O5O7@0:Kh2@4:g;2@>0$?-;#4:4L.1>JK1N-MKh58kh7*KbO;4:58;#0:>(46;#4:4 2@0Q,I(2@<:>K_{0:,2@WS;D2@5O0$7@? 94Q0:kJ;#;<Q0$4Z'3;#G;,>w;0$WS3K;#<QRh5O;L7@9I4:0Q<:;#K<:5O4´;#4Q.146<:kJ; .T,4:;2@RhN[,Kb7@?Æ>S<:0:;,(7j;.T0:N;?N >/.10:KWS2X0Q53,W[;PK2@>N0:;#;#7<QM$>J.h.15O7L2@7@2@2@>0B.10Q0Q;#;#<$4i
0:2@4,(;4:I/N;2*5O4O2 5OJK1;ghN;'<:?K1M!>/.10:9(<B.17.1>/N,KbWSKhRb;#>;#Kb94Z5O7@94Q0:;#<Q4t/.1>JN2@0.1II7@2@;#40QK .T7@70$?IJ;#4KTMzN.10O.a.T4Z7@Kb>RD.14.D4Q2*W[[email protected]<:2@0$?LM9>J580:2@Kh>
Khkh68;L5Ols0:4}=.T2@]P>>JN0$3KP5O= 7@9r 74:0Q'2@;#4a<:4 N6;#L<Q2*lgb,;;Nù<:.1;>/.TkJNÆ4a.14Q<:;;Nù7j.T=0:Kh;>Æ7aNùt0Q4O,0:5:,;^,(;;#KhWSRbk<:;#4QKh;#49(<:gh2@IRb.T>0:._2@KhghKh<Q;#>ù;S<O.1K10:Rh,(M62@;>0:,(R[2@>;WSM Kh3;#<:;0QW^,. K.1>(0QN2*;#t!Kb4:>.T4>J.1KTNPk/M6Kh<Q0$;#9(Z7X0a.1K´0Q0Q;,,N´2@;P;#4B<B.15Q.T,Rh<BRb;#5Q,W[<:;#2X5#R;#.T4D.17
0Q2@;SRh5O7@>(2@9>Kh4Q0:<:0:;#;;#<¢<Qi¢0:2@5O,(>Kb;R>2*>.1>;7@MRh58Kh0:Kb<Q2@<:Wg2@2*0:.10$,(?ù0QWS2@KhK14> M \
.1k/Kh9(0s0:}=,]P;a587*Kb4:;#>(;#r 4:4LJK1<QMz4:00$39KS4Q;#4[email protected]:<B;#.T<Q46I,aI/,.12@7@<:;0Q2@;#0:WS2@KhI>,/2@>.1R4:[email protected]~#7@2@Rh>KbRC<:2@Kh0:>^,(Ww0:,0Q;K2*<582@7*>9(0:4:;0:<$;i:<Z5OKh0Q,>;6>(;N5O.10:[email protected]@2*0$0Q?;#' WS42@>0QKD.67X.T<:Rh;3>9Wk/;#<!KTM <Q;#7X.10:2@gb;#7@?
4:<:W^;IJ.1;[email protected]:4:;9Nk7*?5O7@5O9Kb4QW0:;#k<Q42@>'^2@>GRZ,0Q;#Kh>ùRb;#2@0:0=,9(;4:<;#0:4,;.14:>Æ;6.15ORb7@9Rh4Q7@0:Kh;#W[<Q4;#'<B.TG0:K=2@ghN;D;0:,(;#2*<Q;WS<B.12@<O>5Q;3,2X0:5#,.1;37ZIJ58.17*9(2@<Q4:4!0:;K1<:M/2@>WSR Kh4Q.T0!7*Rb4QKh2*W[<Q2*0Q2@7j,.TW <J4Q90QKk5OJ7@9>J4:N´0Q;#0:<:,(4_;t2*Rh0;#0B>. 9h2@;#>4;S2@>5O0:7@K=94Q.b0:5#;#5O<QKb4a9k>? 0
k/0:,(Kh;#0:WS,4Q0:;#,(7@;Zgh;#2@>4_'0:;#G<¢i¢,589Kh>46>2@06;_5ON0:2@Kg;#2@40$? >Kb.T4!063N;#;#I/7@7;#.T>J4N 0:,Kh;6> 5O.7@Kb4Q4:0B;#.1>0Q;2X4:514t/KT9MJ4:;#0:<¢,iu;64Q958I7*9(I4:7@0:2@;;N^<:4tbW[;#K4QIJN;;#587$2jt.T.17@>J7*?CN 0:,5#.1;3> 2@>.T0Q9;#<:0:>/KbW.17J.T5Q0:,J2X5#.T.1<B.h7@7@58?a0:;#.b<QN2*4Q.10:I2X5O0L40:KTKMJ0Q0:,,(;a;62@5O>7@90:;4:<:0Q>J;#<:.T4 7
5Q,J.1<O}L.h4=5O0Q4Q;#,<:K12@4Q0:2X>´5O42*> K1M!0:2@,Rb;a9<:58;7*9(&4:0:'eq;t<:46k/s;#}=2@>]PRW[;#<:Rb;r
N' <:;I<:;#4Q;#>0:42@0:4KbkhO;5O0Q4DkJ.14Q;N´Kh> 0:,;S5OKbWSW[Kh>7@?94:;NÆiu>;_.1<:;4:0D>;2*Rb,kJKb<
Rhk/<O;#.10$ZI, ;;#>.1II(0$Z<:KKù.b5Qgh,!;#'P<Q0:2X5O;#.h4 5Q,ùKhghkh;#8<Q;0:5O;O0:{ 4 #K1tM2Ma0:,Kb;^>b;Piu>(Kh;kh.18<Q;;#5O4:0P02@>4;.T2*RbWS,KbkJ>KbR<aRb0Q,<B.1;ÆI(,ÆbiuW[<:;#KhI4Q<Q0;#4:4:;2@>WS0Q4[email protected]<N(Kh.1kh0BO. ;_5OKh0:kh4PO;KT58Ma0tZ0:,(.T; >JN´Kb0:0:,,(;#;#<_<:'
;^;OG{,2@4:;Æ0Q4 biu.T>(>;.1;<QN;#Rb4:;0
>N;#;#0Q2@Rb;#,<:W[k/Kh2@><L;RhN[<O.1kI?S, 0:,(;ae N5#;#.T>I4Q0:2@9(0$?S<:;#K14M0:0Q,(,; ;5O<:Kb;#>JRb5O2*Kb;#I(>^0=2*>^KTM>,;#2X2@5QRh,^,k/0:,Kh<:2@4,(KKbKkhN^O;N5O0L?>J<:;#.T4QWS2jN2X;#5#4.1'37@7@?f$>P\!G.,(N;D;#>>4Q;#;D2@Rh<:,;k/Rh2@KhKh<Q>!,t(K0:K,N ;<B>.h;N2*2*Rb9(,4kJK1KbMZ<:,.SKNK.TN[0B.2*46I/NKh; 2@J>>0;2@N 4
>JN;#.T>(<:<:4:K12@0$?b7@iu? kJ.T.T4:>J;NN 2*WS>Æ;#.[0Q,4:KIJN.T<:7@24Qh;S;=<:V;Rhn32@Kh>!3t}=0:,rC;t>;,2*2XRb5Q,,SkJKb<:2@,7@7Kk/K;=NP2@2@>4D0:<QNK; N/9J>5O;;NÆN W[2*>^Kh<Q;D;5O0Q2@2XKhN>P;#7@?&''em3.1Kh>JW[N[IJ.1,<Q2X2*5Q>(,^R94:2*;#0Q4, .D0Q,Rb;[email protected]>;;7 2*RbN,; kJJKb><:;,N´KKkN?
0:N,(;#;D>(4:;2@N0$s?Rb}=t ;#4]P'oe G5#,J.T.1I00:9(2@r 4<:t;#0Q4DN,;W[;0:;#;Kh<QN<QWS;DRb2@;D>J>;#.1K140QM9.0Q<B,.TN;^7;#>>4:2@;#4QWS;D2@Rb2@<:,7X;#.1k/Rb<QKh2@2*Kh<Q0$?,>^KkJ0:K;#;#N>/0$'a3N46;#]^;#0Q>ÁKbKa<:;#3;K1.h;#gb5Q2@,-Rh;#<,tIJ00:.TWS,2@<a;SKb<:KTN;LM;0:>5O,J4:7@[email protected]$4Q>?P0:;#0QKT<Q,JMZÖ4 .10:03h ,K1;MZ.T<Q.C;#>JRh4:äN [email protected] >P<:4Q2@;D4=.h<:<Q5;#;5ORb5OKh2@Kb<OKh<BN>!N2@>';NùR 0Q.1KÆ40:0:,(,;a;2*<3;#<Q2@;#Rh7X.1,0Q02*gbK1; M
2@>0:;#G<¢i¢,5OKb;´><:>;;7j58.T0:0:2@2@ggh2*;´0$? 2@>0:;#<¢i¢h 5OKb>h >;580:.T2@g>J2*N[0$? 0:,;2*<h<Q;#7X.1h 0Q2*gb[;Dk/5O7@;#Kh0$4:Z;;>;#;#>4:4 0$*ZhK-5Oh 7@94Qh0:;#<Q#"4 ' h .1>/»N h 2@4^N; J>;_N.14P0Q,; .Tk4:Kb7@90:;´2@>0Q;#<$i
5OKb>>;5O0Q2@g2@0$?Æk/;#0$3;#;#»> h .T>JÔN h >Kh<QW.T7*2@~#;_NP2@0:,Æ<Q;#4:I/;5O0[0:KP0Q,;^2@>0Q;#<:>/.1732*>0Q;#<$i:5OKh>(>;5O0Q2*g2@0$?ÆK1M0:,(;0$3K 5O7@94Q0:;#<Q4 h
;4
-6
Å
ª
\4 © à 6
¬ à
â
Þ´
H³
U
v4
4
A
U²
/e
²
²qC
/
86
6
7`
4
6
1
¾
&4
©
à 6
E¾
!T4
¾
à
©
à 6
¬4
©
à
à 6
à
ª¨6« #© =«(ª ¦ z«©ª :¨ kRPª© C§ =«
.1>/N2h 'G,J.T02@4t
"
#%$½B
G3I 8I
&O UM
A
AJCK
AFCO ¿
A@
F)
C
à
u&'eFTU
h ,tJ;#<Q.T; >JN[d£4:h 2@WSgò2@@7Xî.1g§<QC 7*?tF2@4Ld0:h ,; Kh<Ud£h 6KT3M0:2@4,;0:,5O;v7@9ý84:þ 0Q;#<D5OCKh>þ 0OýD.12@ÿ>þ2@>RkJKb0:, þ@ý .1>JN 2$' ;h'@t0:4:,K[;D0:,J3.T;#062@Rh0Q,,0Q;a;N[5O7@4:994QW 0:;#<K12@M46;kN<QRbK ;#b46;#0Q>P,[email protected]>00:KI/.1h <:0Q2@0:.T2@>JKh>N
0:,(;DGRh<O,.1;[I<:,^;#[email protected]>0:0:2@Kgh;P0$Z5OK7@Kh<:4QKb;#9>g Rh;#@ 4Q,4S7@?k/;;#`b0$39J.T;#g 7!;#C>wIJ.T. <:0QIJ4 #.1' 2@<K1MD5O7@94:0Q;#<:4ah .T>JN¡h t Uh h h #t2@4SN; J>;N .140Q,;P.1k4QKh7@90Q;5O7@Kh4Q;#>;#4Q4
k/;#0$Z;;#>Üh .T>JNah >Kb<:W.T7@2*~;N2@0:,S<Q;#4:I/;5O0C0:K0:,;D2@>0:;<:>J.T7!5O7@Kh4:;>;#4:4KTMz0:,(;D0$ZK5O7@94Q0:;#<Q4øh .T>JNah 'G,/.102@4t
è g
@ C
u&'eFbd
Uh h h
>g C > è g
> gò@E> è g
@ > g @ > -> g C >
C
> g @ > -> g C >
,;#<Q; è g @ C 2*4C0:,;^._gh;#<O.1Rh;3;#2@Rh,0K1M60Q,;;NRb;#40:,/.10a5OKb>>;580agb;#<:0Q2j58;#4a2@>¡h 0QKPgh;#<Q0:2X5O;#42@Ô> h t.1>JN è g @ Kb<
è g 32@40:,;D._gb;#<B.TRh;Z;2*Rb,0K1Mz0Q,;D;NRh;#40Q,J.10k/;#7@Kh>R0QK0:,;W[2*>i¢5O9(0Zk2@4Q;5O0:Kb<6KTM 5O7@94Q0:;#*
< h Kh< h #'
C
$
f
L
0
J
,
1
.
L
4
J
k
#
;
;
>
Q
4
,
1
K
P
>
:
0
/
,
1
.
=
0
s
=
}
P
]
o
!
r
J
,
1
.
L
4
S
W
b
K
:
<
;
J
I
1
K
3
#
;
D
<
1
.
0
N
@
2
B
4
O
5
1
K
b
g
#
;
:
<
@
2
>
S
R
T
.
:
<
k
@
2
Q
0
B
<
1
.
Q
<
^
?
:
4
J
,
0:2@>^,/.10:>,;V=3n3Kh<:34Q06}5#rò.14Q.T;h>J' N66s' sK1Z;gh;#<_t10:,;I(<:K5O;#4Q4:2@>Ra5OKb4:0MKb<z,(2*Rb,aN2@WS;>4:2@Kh>/.17hN.T0B.LW._?0O.T. IJh;=; N´µ 5O7@94Q0:;#<Q0:4D2@W[2@>;!M ,(Kh2*< Rbv, Kh`bkh9JO.1;_7@5O2@0$0:?4
éê -÷ú6óñ$ð1û 6ïó÷ ôõ:öLóbð÷øñ:ú c÷ðí 6ó
G>;KS580:N42@4B<:5O;#K1Rbgb2@;#Kh<6>45O7@94Q2@0:0:;#,[<Q4=4:92@0Q58, 2*;>.T0Q<:7@k?S2@0Q,<B.12@Rh<Q,^?SN4Q,J;#.1>I/4Q2@;h0$t?SN2@;#>>0:KS4Q2@0$5O?h7@i$9kJ4Q.T0:;#4:<Q;46NPKh58<67*9(584:7*0:9(;4:<:0:2@;><:R46WSKbkh;O0:;,5OK0Q46N4kJ.T,J4:._;gbN ;KhkJ>P;#;N> ;#>N4Q;2@gh0$?;#7@KhM9I/>/;N5O0:t(2@Kh>^,2XN5Q2@,4:0Q;<:2*2@0Qk,9;#0Q<2*Kb5O>!Kh' >i
éê ê:ë óö Scæô_"ñ:÷Wäúð õ$ûc=W íLñ 6í ÷!úL6ó÷ñ$ð1ú6û óñ$6ð1û ïó÷ ôõ:öLóhð÷øñ:ú c÷ðí 6ïó÷ úcô úLú6÷!ô/ð÷ ±ø(÷ ñ ú6ó ñ¢ðí
VN;#nZgb(;#7@3KhI/}=;r N^kuVL?;# >(4:4:0:2@;0$?b<t[i¢n37L.1<:4Q2@;;#N-Rh;7utIJ(.T.10:>J2X.1N7;<=[email protected]>/4:N0Q;#êL<:2@9>RÆB)KTxbM6xh}6m #I'I(G7*2X,5#.T;a0:.12@Kh7@Rb>(Kh4a<:2@0Q,2@0:W
, Rhr<:KbK12*4Q; 4<Q;#2@[email protected]>N4;#>4:2@0:2@0$,S?bi$4QkJ9.14Q;5ON2@;#>5O0:7@7@9?[4:0Q,;#2@<:Rh2@>,PRN;#.T>7*Rb4QKh2@0$<Q?S2*0Q2@,>W 0:K t
4:5O;7@9064QGK10:M;#,<QN;L4a;#kJ>.1.1>J4Q4Q2@N 0$2X?h56Ni:2X5O2@N4BKb5O;_>K1.D>gbKT;;#M5O<:0Q4DN;;#N5O>(7@9IJ4:4Q2@Kb0$0:?b2*;#><Qiu0QkJ4D4.TK1' 4:M
;N^.T<:5Ok7@2@90Q4Q<B0:.1;#<Q<Q?^2@>4:R,J.T2@4
IJ;.T432@>PMKh4:7@[email protected]0:42X.1\ 7(NKh.1<30O;.1.bkJ5:.T,^4:;KbkhO2@;0:5O,P0>[email protected]:;h5O'L7@9}±4:0Q5O;#7@<9t(4Q0:0:,;#;<C>2*4;#2@NRb; ,Jk/>(Kh;<QN ,K.TK4DN.K1WM.D. {Rb2*2@WSgh;#.T> 7
<B.bN2@}L9>=4 KbkhO;$5O5#0_.1t17@7@;N 2@0:,2@>#.3þ Rh2@gh;#><O.hN2@394,J.T40:5OKSKh>5OKb0O.1>2@0O>.12@2@>>PR3.1>03K7@7@;;#.14:4Q4060:.,J.TWS>[email protected]>2@W[Wa2@9(>Wl2@W>99WW>k/9;#W<Zk/KTMz;#</KbK1khMO;>5O;#0Q2@4Rh,k/ Kh<Q,[KK¶ NL#Kb' khO;5O0Q4 4 [U¶ t
2@465#.1}L7@7@> ;N^Kbkh. O;5O/0 1´ 2@4 "1 _ 2@0Q,<Q;# 4:I/" ;#5O 0:10QK .<O.h N2@9X 4 ML<QKh.1W >JN[Kh.khOWS;582@0>2@Wa9(Wl2@0:,´>9<:;W4:I/k/;;#5O<Z0KT0:MzK I/Kh.[2@><B.b0:4N2@ 94 [D.1¶>/N #' .[WS2@>2@W9Wc>9Wk/;#<
K1>M9WI/Khk/2@;#><Z0:4 KTM IJKb[2*>U0Q¶4t 2*>Æ[.[4:;#¶ 0Ch' K1MKhkhO;580:4 2M ´2@42@0:,2@>´0:,; ¢i$>;#2@Rh,k/Kh<:,(KKN^KTM v,2X5Q,5OKh>0B.T2@>4D.107@;.14Q0.[W[2*>(2*W9(W
5MQ<Q,JKh.1W 2@}L>[>SK1MzKhkhKb8kh2@;0:O,^5O;0 5O<:0QS;#4 4Q2@IJ4 ;_!5Ot0'#'#0:K'_t "6# .1Q>/t 1N2 !D[ .TX>J¶ bN 'M<QKhW
KhSkh84Q;9J5O5Q0 ,^0:,J.T2@0:0,MKb<Q;#<=4:)I/;5O00QK t.1>J
N [.TU>J¶N 62@>S.C2@4:4;#0N2@KT<:M!;58Kh0:kh7@O?S;_5ON0:;#4 >
4Q2@0$?h2Mi$<:0:;_,.h;#5Q<Q,J;.12*k(47*;.
Khkh8;}L5O>S0 .Khkh8;c5O0 4Q^9J5Q2@4,P0:,/.10#" k/#Kh 0:, /^z.1>J N _ .1<Q;0QKaNKb;#>khO4:2@;0$5O?b0 i$<:C;.b5:2@,/0:,S.1k<Q7@;#;4:I/M<Q;Kh5OW 00Q. K [email protected]:,^>JaN <:; 4:I/;[5O0¶0:LK 2@>.T.C>JaN4:;0 K1Mz[Kbkh¶Ob;'5O0Q4 2M!0:,;#<Q;D2@4
.T>
2@<:4 ;_.hN5Q2*,J<Q.1;k(5Oz0Q7*7*;[P?ÆM<QNKh;#W>(4:f$2@0$> ?b'´iu<Q;2@Rh.h2@95QWS,J<Q;[email protected]&(<:7@'e;S7@&?ht/tM <:kJKh.1rW 4Q.T;>JN´N¡Kht>´è.1>/.S.1N <:Rb;^ 2@ghN;#2*;#> 4 >4Q2@2@0$>J<:?h;#Ni$I2@<:<:<Q;_;_;#.h4:5O5Q;0:,J7@>? .10Qak(;Nù7*N;v;#kM>?P<:4:Kb2@0:W0$,?bi$;<:µ ;<B.bZ.b5:N.T,/2@>J9.1N¡4k7@K1µ;MZtM 0Q<:,Kh;SW .T5O>J2@<BNÔ58'P7*èl;s4t.TK1.1<:Z;^>J;N gh.1;#7@7@7
<_;#t 0 N;# >4:2*2@4[0$?b>i:Kb¶5O0aKh>N
>(;#;>E5O4Q0:[t 2@;_0$ ?hNi '
¾
&44h ©h
Å
'&
]"=%"¦XSP$Z8<
(
à
4
*)*"¬Q:V
6
1<
4
Ê
dh'&
gò@ î g§C( Ê
dh g @ Ê$ØaÊ dh g C
"h ah à
Ê
à 6À
#&XSP*Z8<5'
4
Ê6
-
36
?"P<Q¶4
S6
à v¾
à 6
¦
º4
©
,+
à 6À
,+
3
+
.
-/. 10 . 2
Ø
3
à
4
+
±
54
CÐÑ
N
±!ï
H³
/a²
'8
4
.
à 6
¬4: Å 6
4
/C
CÐÑ
+
à
54
-6
.
-/. 0 . 2
6
.
©
à
¾
+
º4
N
/!²
/C×Ñ
Nq
g
o
N
76
4
?6
4
86
%9
N
79*X#0"
E4 6/4
<;
+ ¬ U
W%?R'SQRTQ7Q7$6
aª[
aª
@?
A
@9
C
;
aª
gy SË?6
SË76
>9
cì
5ì
A9
¥ç
ªç!
aª[
;
SË
B9
Uì
T
aª[
ED
SË
o¾
9
¶4
=?
SË
?
ì
2
D
9
Uì
ì
Y
gú
d
d
gy
×
im9
gy
aª
SË
A
Ý
SË76
Ó4 aª[
=9
4
SË
?
;4 aª
:9
4 S6
9
3
!?
aª[
SË
aª[
Sˬ
6
Y`
A¾
1<:. ;4Q7j?.TWSrs0:2@KhWSKh0:>2X;'5O0:;<:2X510Q,J'.10L>N7@;#?->(4:5O2@0$Kh?Æ<Q;Æ<:;Kh.bkh5QO,J;_.15Ok0:4P2@7@[email protected]$?P<Q; 2@4aW0Q9(,0:;S9J.T0Q<B7*@.T?Æ>4:N2@0:;#2@>gb4Q;S2@0$?-5O7@Kh<:4:;9(.b<:5Q;^,J.1K1kM=7@;hN'c2@<Q;VL5O0;#>(N4:;#2@>0$?-4Q2*0$5O?ÆKh><Q;>(.h;5Q5O,J0:[email protected]@2@0$7@?2*0$ts?,t!K1.TZ>J;NÆgh;#0Q<_,t62@4D2@4<:;#. 7X.T0:4:2@?KhWS>4QW[,2@;#IÆ0:<Q2@2X45
FhF
¦ ©ª Á¦ z«©ª =¨ o« :«
A@CBED
AFHG3I
AJCK
AFB
5BLJNM
&O
Q
M
P
R
S
O
!2@Rb9<:;D&'e&(\zVL;#>4Q2@0$?S<:;_.h5Q,J.1k(2*7@2@0$?S.1>/NN;#>4:2@0$?^5OKh>>(;5O0:2@g2@0$?S2@>PN;#>4Q2@0$?hi$kJ.T4:;N^5O7@94Q0:;#<Q2*>(R
<:;_.h5Q}n3,J.1.14Qk(;2*Nù7@2@ 0$Kh?">t#.T 0:>J,N[;^J;#>ghKb;#<Q0:?^2@Kh>ùKhkhK1OMD;#58_N0;# >>Kh4Q2@062*4P0$?b5O.ùKbi$<:>;4:0B;#.b.10P5Q2@,J>KT.1;_MvkNS2@N7@2@2@>P;#0$>?.14:t2@>0$.Æ?S?bi:N5O5O7@;#Kh9>>4Q4:>(0:2@;#0$;<L?b5Oi$0:2@kJ;_4 N.14Q;1KhNþ@khý 85O;' 7@5O90:4:4´0Q;#<:2@,>2XR5Q,w.T7*2@Rb4^Kh<QW2*0Q. ,{W 2*W^t._V7nZ(2@30:,¤}=rD<:;#to4QIJ2@4 ;58N0Æ;gh0:K-;#7@KhNI/;#;>Nù4Q2@0$M ?hKhi<
5O.7@9I/4QKh0:2@;#><Q0 2*>(´R5ONKh.T>0B0O..12@2@>>P46.W[NKh.1<Q0O;=.1kJ0Q,J.T.14:;h>%'3 f$0=5Q[,;_5¶ b4Lt.0:,>; ;#
¢iu>5O;7@2*9Rb4:,0Q;#kJ<Kb<:,2*K0QK, NKT.TM 4=;_.h.[5Q,P5OKhI/<Q;aKh2@Kb>kh0O2*;>^5O00Q,2@4=;a5ON<Q.T;0B.1.10Qk/;N.14:';bf$'Z0Lf 0:M,0Q;#,>´; 2@¢0:iu;#>(<O;#.12@0QRh2*,gbkJ;#7@Kb?P<:,5OKKhK7@7@N[;5OK10Q4M
N5O7@2@9<:;_4Q0:5O;#0:7@<Q? 4'3NG;>,4:;2@0$I?b<:iuK<Q;5O.h;4:5Q4,J.T0:k;#<Q7@;aWSKb2@>Jkh.TO0:;;#5O40Q4M,<QKh;>W >(0:K,;#>4Q;#;S¤5OKhIJ<QKb;a2*>Kb0khO5#;.15O>^0Q4k/t;a.h,N(2XN5Q,P;N[W0:KS._?.T2@>>?SghKb587*7*gb9(;4:0:0:;,<;' WS;#<QRh;DKTM
.M ;#lN;#>4Q2@0$?hi$<:;_.h5Q,J.1k(7*;
éê ê ¡^ §_Ôæ ø L÷!øñQú ¨^ ñ:úoðó 6÷úðñ Bû ðíLû÷ _ õQö6óbð÷!øñQú æZðøö6ô/ðöLø÷
}62@>7@I0Q9,0CKh9IJRb.1,^<O.10:WS,;;0:N;#;#<Q>4t4Q2@4:0$9/?hi$5:kJ, .T.14:;4 NP58.17*9(>/4:ÔN 0:; <:2@>RP[.17@¶ RhbKbt<:2*2@0C0:,(4:W 0:2@7@th7VIn39(0:430:}=,rC;t <Q;#54:.1I/> Kh>N2@4Q4O2@k5OK12@7*gh2@0$;#?´<5O0:7@KP94:9(0Q4:;#;#<<Q4Khkh0:OKP;_5O4Q0:;#47@;5O02@0:,^RhK0:K,(N´;aIJ4Q;#.17@<O;.15OWS0:2@Kb;0:>P;#<DK1Mgh4:.TKb7@9WS;#;4
2@>Æ9J5QKh,P<ONI/;#.1<<B.T0:KWS;#J0Q>J;#NÆ<4:5O;Kb0:<:0:<:2@;_>5ORb04=5O.T7@<:9;D4Q0:9;#4Q<Q9J4'´.17@7@}=?S58I(0:<:9J;#.T0Q7*0$@??t!,/0Q.1,<B2@N[4D0Q2@4aK0QN,;#;S0Q;#I(<:W[<:Kh2@k(>7*;h;tW ;4:.TI/4:;4Q5OK[email protected]@?0:;MN Kb<<:2@;0:.T,Æ7iuW3Kh.T<Q>7j?PNtKh,0Q2@,Rh;#,^<N5O2@7@WS94:;#0Q>(;#<:4:2@2@>KhRÆ>J.T.17 7@N(Rh.1Kb0B<:.2@0:,(4Q;#WS0:4_4' '
IJ]^NK.TKb<:;#4:0:40a2@0Q>(2*.TKhKb7*0>Rb43Kh;#gh<QK12*;M!0Q>,0:WS,(;O{;42*4QN(.10Z.1<Q0B.L;.Rhgh4:7@;#Kh;#<Q0Qk/? 4.1'Z7h4Q];#I/>.1Kh4:<B<:[email protected];WS2*K1gbgh;;#;#0Q<_0:;#tKP<,4:4Q2@;#9JRh0Q5Q,0:,Æ2@i¢>NRIJ2@W[.1M Kh<O;#.1<>W[4:2@;#,Kb0:>J2X;#5Q.1<C,a7bgh0Q<:,.1;.T7@;97!<:;#N;#4_4Q.1\90O4:[email protected]@2@4QRhK1;#M,0:0:4.=7@?PKT58M7*9(0:N;#4:2 >[0:;;,J<:<:2@;#._>>ghRa0;L.Tgh4:7*;#;#Rb0Q<QKh0:?<Q2@>2*4 0QRhb,4C;#W¤ZW;_WN._?^._N?D7@2*;4QN0:.h;#<QN´4O2*5Ok(<:0Q92@Kk/0:2@;6gbKh;#>0:<:,(t?Æ;Z.T>JN2@>2N0:<Q0Q;#2*,<:>(;#;#4:><:2X;05
5O7@94QG0:;#K6<Q2*K1>(gbRS;#<B4:580QKh<:WS9J58;o0:90:,<Q; [email protected]5#2Y5O958<O9.10:7@0$;?7*?t1'.6587*9(4:0:;<Kh<ON;#<:2@>RW[;#0:,KNt15#.T7@7*;_NaGf: uL<BN;#<:2@>RaKb2*>0Q4!GK6f:N;>0Q2M?D0:,(;
37@94Q0:;#<Q2*>(R
Kh0:KS<O0QN<:N9J;#;#<Q5O>2*0Q>(94:R62@<:0$; ?bM Khi$kJ<,J.1.1.14Q49;0QkJNPKh;W^;#5O>[email protected]:N4Q2X0:;#5;#gb<Q.1;#2*>/>(7@KhNDRSI/2@;5O>KhN0:<Q;#k<:<O;#? .h4Q5OIJ0Q}6Kb2@gh>J> ;Nh;#2@5O>7@<Q94:RS04:0Qt0Q;#KSno<Z<:.D.1;#>/9k(.1>(<:K7@2*?R/.b4:tN[2@764<B'<Q.1G2@>(;#,(RhRh;#2*;47/K15O.1M7@>J9IJN4Q.10:;#<O.T.1<o>JWSKhN<B;;#N0:<;#;#<:<)2@xb>4Qxh;#RD0:x 0Q5O#2*Kb'>(>f$Rh0O04.1'5O2@Kh>W[42@I>9MKb0:;<:4zW.1.T>0:[email protected]>LRbWS,;#2X>5Q,a0:;_2@N=458;7*`b9(94:0:2@gh;.1<:2@7@>;#>R1i0
N5OKb;#>>(>no4:2@;0$?D5O?b0Q;Oiu;{JkJNù.1.TW[4:4:;;#N^2@0Q>42@5O>7@9R64Q2@N0:0:,Æ;#;#<Q>46<:4Q;2@4:0$?hI/2@0:i$;kJ,[5O.T0:<:4[4:;#;4Q0:NIJKÆ;_5O5O7@.^9064Q7@0Q0:K1K ;#Z<Q.C;2@><a,[email protected];#,7@>Rb;4QKh<
2@0$<:N?2@0Q;'^,>W G4:2@,0$t#? V;<:n3;O2$M' Kb;h3<:'@t;h}=to.DrC2@7@>ÆK1th3KbKh;#><B<ZN;
;#gh5<a.T.17@>0Q9KP;3;.TIM4:Kh<Q2@<K7@?=NZ9J4Q;#5O.T;6;P<:;0QN,J5O;#.1Kh>0W[4QM2@KbI0$?h<7@;#i$.=kJ0:;#.T587@Kh4:?;>Nù5O4QKh0B5O>.17@>0O9.10 4:2@0Q>;#;<:Nv4[2*>^2@¶ 0:N8,;#iugh>. .T4Q2@7@0$94:?h;#;h0i t
K1NM;#>(N4:2@2@4:0$0B?b.Tiu>J<Q;5O.h;5QIJ,J.1.T<Ok.17@W[;D;#0:2@;#0:<Q,^4t/<:;#Kh4Q>(IJ;a;_5O>0;;0:NPK0:0Q,K^;D4:;#7@K17@;35O;#04:00Q,3;aghKb.Tkh7@9O;;5O2*0Q4 4JM>Kb<62@4Q,I;<QKN 58J;#4:<Q4Q4:2*0_>(' R2@> .v4:I/;5O2 5Kb<BN;#<4QK0Q,J.10L0:,;Khkh8;5O0,2X5Q,P2@4
nG3,.14Q; ;N[/Kh1>^ 0:,"u2@4_2XN ;.(t0$KTZM K.1>[gh.TKh7@9kh;6O;_>5O;0 ;SN^2@0:43K0:,k/;L;D4:4:W^0QKh.1<:7@;_7@N[;#4:M0ZKhN<32*;4Q0B.b.T5:>J, 5OKh; khOí ;kJ580;#\0$3;#;#> 1þ@ý .T>JNS.T3>S.1Kh>JkhN 8;5O02@>S2@0:þ4 Yþ ¢iu>(;#T2@þ@Rhý ,kJKb<:#,' KKN4:9/5:,
0:0:,/,(;a.10 5O^Kh<Q3;Oi:KhN92@4:7X0BN.Tk/>J;D5O;D.a2@4658KhL<:;Cr6KhVkh O;58f:0r62*V0Q,^' <:;#4QIJ;580=0QK Yí2YM0:,2@43>;#2@Rh,k/Kh<2@465OKb>0O.12@>;Nv2@>0Q,; ¢iu>;2*Rb,kJKb<:,KKNKTM !'L0Q,;#<:2@4Q;ht
2@0:46,(;DNG2@<:<:;,;.b58; 5Q0:,J7@1?P.1k N2@;#7@>2@0$4Q?b2*i¢0$N?b" 2@i$4Q<:" 0BO;.1.b>/5Q,J5O;6.1"kKT#7@Mo;.T M >S<:Kh KbW khKTOMZ.;.15O2Y0>^M ^. Khkh2@O462*;_0Q.5O,S0 5O<Q^Kh;#<Q4:;DI/2@Kh;0:5Okh,^0O;_<Q0:;#5OK 4:0I/'3. ;f 2@5OM 460. 60:KS2@rL4.TV=>>Kb Kh0=!0Q,.f:;#rL5O<LKbKh<:V;DkhO' Kb;kh58O0 ;.5O0_2*t4;#0Qgb,;#;D> 4Q.TW06.10:7@,(7@;#;=4Q0
Rb;#N>2@4Q;#0B<O.1.1>/0Q2*5O>(;DR4:9/N2@5:4:, 0O.10:>J,J58.T; 0 _t
<:;[email protected]:5Q,^G,J,<:.1;;k(4:2*I/=7@2@;0$ 5O?b0Gi¢N0:f:2*KS4Q0B .T.T>>J.T?S5O7*;RbNKh2*M <Q4QKh2*0B<D0Q.T,>J;W.b5O;5Q5O,Y<Qí;Kh.14:khW^0Q8;#;[email protected]@;#'Æ>P<Kh0Q,J9/<ON.15:,ù;#>^<:2@0:2@>>,(R[M;DKhK1<QRhWM
;#>(..T;#0:N(<[email protected]:>[email protected]>2@kJRS4.1N4Q4:;h92@4:t!0O.b.158N>J2*;N58>;2@0:0C2@oKhM>/MKb<:<D.1Kb7@Wc;O7@?a{0:0:4Q<O,(0:.hKh2*5O4<Q0Q2@Kb>2*Kb<BRS>N;0QKT,<'M=; .1587@Kh7
<:;8Ni¢;#N>2@4:4Q2@0B0$.1?b>/i$kJ5O;S.14Q.1;>JNN 5O.7@94:4Q90:;#2@0B<Q.T2@>kRh7@;4
0:4:,(0Q<:;a9JG58<Q;0:,9.h;P<Q5Q;,J5ON [email protected]@0:>J7*2@;#N^0$<¢?biu5Oi$KbI7@<B97@NKh4:;0Q03<:;#2@M<:>Kb;_R<N'.vKT]^Ma4:2@.Æ;#WS0:,(NI(K.17*;DN0O.´4=F i¢.14:N;#<Q2@;D0^W[.15#;#[email protected]>4:> K4:2@KbNk/>J;#;P.1gb7!;#I7@N<:Kh;.TI/4:0B;;#.v>N[0:4:M;_;#KbNw0_<Zt!g.T>J2@;#,Nù2X5Q2@9,P>>JRIN<Q5O;#;#7@<Q94:4:;4:0Q>0QK;#0QK4<:NÁ2@>.vR[RhRh<O4:;#.10:>(I<Q;#9J,<B2X5O.T5#0Q7.T97@K1<:7*;#?gh4L';#<QMgKb2*<Kb;<al,2@;ORh.1{J,^k/.TKhWSN92@WSI07@;h,;#>tK14Q!2@Kh2@Rb0Q>J,9.T; <:7 ;PNN(.T.1&0B0B'ex.(.v' 2@2@44
gy ;#0Q
@9
Ó
54
aª[
:|
+}+Î
L³
U
A9
A9
SË
aª[
?"
}¬HÎ3
>
U
SË
k
¶4
76
¬4
i
86
=9
E &yS
A
9
SË
½
LPQS"¦XS
A
aª
'96
4
>9
<#0P"
"S8PR-' W<§)7XS
<>#0P"
'9
>9
Ü
A
d
gyS
Ó
v
A9
A
A9
½
A9
Þ
v
ª¨6« #© =«(ª ¦ z«©ª :¨ kRPª© C§ =«
"
#%$½B
G3I 8I
&O UM
A
AJCK
AFCO ¿
A@
FhE
C
2@Rh9<Q;&('ex\37*9(4:0:;<6Kh<ON;#<Q2*>(R2*>^Gf:
<:9(>iuno0Q;2@WS5#.T;Z95O4:Kb;WSKTMJI0:7@;O,{;32@4:0$?D0Q<:.19J4580:0:9,/<O.1.107/K1;M `[email protected]7@3;#>J}=5OrC;3'hK1M/IJ0:,.T;0:2X.172@>JGNf:;8{a2@>.TR7@Rh4QKh0:<:<Q9/2@0:5O,0:W¤9<Q;#0:K45#V=.1n3>k/3;Z}9(rD4:;t1N0Q,0QK6;
M9<:0QG,f:;#<;#>(.1,[email protected]>JKh<:582@;60Q,2@0:Ww4I/,/;#.1<$4MKb0:<:,W^;3.14B.T>JWS5O;b; '
éê ê aû_"â *_ õQö6óbð÷!øñQú Lïó÷ ú 6÷ú6óñ$ð1û 6ñ:óbðøñ 6öðñ ú #ö6úLô/ðñ ú6ó
kV90Qr62@GKh,>[;M96W[>J ;#580:0:,[email protected]>P>N[4_.1t2@4k(,JkkJ.1<:4.1;#4Qk/g;2X;#N^.1;#0Q>´Kb2@>KhN>[0Q;#,ghMKh;;<67*KbMKbVIJ7@;_7*K1N^rsk4:2@2@>? 0$RC?buiu2jk/N[email protected];>4:.1>(;_4_;#NP\ kB9) <Q!3Rs0:.1,4:>/0B;C2N 2*<:> 7L2@J>;#9R 2@;#W >Jt58.)_;Dxh5OK1xb7@9M& 4:#;0Q' .b;#5:<:,´2@>R[N.1WS0O.;#0QIJ,KbK2*N>0kJ5#.T.14:> ;N^kJKb;D> W[.KN4:;;#067@;K1NMZM NKh;<:>W^4:[email protected]$7@?P7@?DN92@4:4Q0Q2*>(<:2R i
.ÆN;#W^4O5O<:.12@0Qk/,;#;#4PW0Q.T,0:;P2X5#.T2@WS7MIJ9(.b>J5O5O00:2@K1KbMa>!.t5#N.1.T7@7@0B;.´NI/þ Kh2@>02@0:,2@> 2@0:u4Sþ >(;#[email protected],>JkJN Kb<:0Q,,K;PKN 2@> J$9F ;v>J5O0:;,;PM9K1>Jgb5O;#0Q<[email protected]@>w7=N5#;#.T>(>-4:2@k/0$? ; K14Q;#MD;#0:>,;´.14N.1. 0O.´M94:>JIJ58.b0:2@5OKh; > 5.1>-,2Xk/5Q, ;
WSWK.T0:N,;;7*;_WNP.1.10Q2X>J5#.T.17@7@?7@?0Q2X5#k.1?P7@7@?2XN;#.T>4=0:0Q2M,?;2@>4:R9(WN;#>K1M4:2@0$2*>? J.T90:;#0Q>J<B.h58;580:MKh9<Q>J4t5O0Q2@Kh,>;4<:;SK1MN;#.1>(7@74:2@N0$?.10O..T0:I/0Q<BKh.h2@58>0:0:Kh4 <Q4a.1>/.1<QN ;au7@E K=5#.T5877*9(W4:0:. ;{<:42@WS5#.C.1>´K1M0:,0:,;>Æ;K1kJgb;;#<BN.T;#7@0Q7 ;#N<:W[;#>2*4:>(2@;0$N?
M9>/5OG0:2@,Kh; >"' : _" / K1MZ.[N.10O.IJKb2*>0 ý bt,(;#<:;ý 2@46. i:N2@WS;#>(4:2@Kh>J.T7M;.T0:9<Q;a4QIJ.h58;ht/2*4.kJ.14Q2X5LM9>J580:2@Kh>
A\ ý
t,2X5Q,^2*4N; />;N^2@>^0:;#<QWS43K1MZ.CkJ.14Q2j5L2@> J9(;#>J5O;M 9>J5O0Q2*Kb> + t
+
u&'eFbm
+ +
f$. >SI(<:2@>JYþ 5O2@I7@;ht10Qþj,ý ;2*> J9;#>J58;6$M þ 9>J(5Ot0Q.[2*Kbý >5#.T>Sk/;D.1>C.Tþ <:k2@0Q<B.1<Q?M9>J580:$2@þ Kh>!(ttbk902@04Q,Kh9(7jNvkJ;<Q; J;O{2@gh;D.1>/N4:?W[WS;#0Q<:2X51'f$05#.1>^k/;
|) . ¶ ) )
u&'eFbq
H K ð Kh<6. hýOý#þ Pþ
$þ t
)0
u&'eFb&
H
54
[î
F
F³
±
U×Ñ
o¡
¡
4
Ñ
r
36
4
-6
C4 76
HG
# ÓZ"*#0P"YV$Z�P¦<
T{
Q#
&{
g`E4 -6
T{
LK
¸
>J'M
I
¾
3N
Yh
?`
>J
[
LK
T{
S<#\PS"vV*Z3#\P< [Q#
QP
[#
:R
ê
á¸
+¸
4
© -6
4
-6
4
-6
4
-6
Æ
{
OG
*é*Z";ÖÓ="
¸
WVUZ
¨
&{
¸
ÒÓZP* [8"S#s
>J
4 86
# vZ"$#\PS"vV*Z3#\P< [Q#
4
¨ 4
ª ¸
TS
© -6
Sè
U
© -6
È í
Û
ª[Ë
OG
# vZ"$#0P"5V$Z�P< [Q#
QX
¸
RZYY
4
© -6A
'[]\ ^ 0`_%acb
b5d b
F1U
¦ ©ª Á¦ z«©ª =¨ o« :«
A@CBED
AFHG3I
AJCK
AFB
5BLJNM
&O
2@Rh9<Q;D&'@)|(\zVL;#>4Q2@0$?M9>/5O0:2@Kh>^.1>JN^N;>4:2@0$?bi¢.T0:0Q<B.h580:Kh<
N;#4O5OG<:2@,k/; ;N k?^#.D" #4Q ;#06:KTM! M;__.1" 0:J9( <:;D2@4agb;N5O; 0:/Kb><:4 ;N.T4a0Q! ,;S4Q9WKTM6#2*> J9ý ;#>Jh58t(;0:,M9;D>/N5O;#0:>(2@Kh4:2@>(0$4a?KTM9(M=>J.15O7@0:7Z2@KbN>.T0B2@.^46I/N;KhJ2@>>0:;4_NP' .T4t2@gh;>¡ N.10O.^KhkhO;_5O0:4
u&'eFbx
+
+? @
(Kh<;O{J.1W[I7@;htb0:,;DN;#>(4:2@0$?[M9>J5O0Q2@Kh>S,(2j5Q,^<:;4:97@0:4sM<:KbWc0:,(;aD.19(4:4:2X.T>S2@> J9;>J5O;M9(>J5O0:2@Kb> u&('eFh& o2@4t
)0
u&'eEb|
H
H
[email protected]@Rb5#.1Kh(7<:<:2@W0QKb,W ._W {2@0Qt1W,Rb; 9.L2XNKTN;#M;>(N[0Q4:,k2@;0$??ùK10:ghM,9;#;C<O>J.15ORh7@0Q<[email protected]>!;#2@>t;#>4QKb2@00$>t?^; 5#M.T5#9>^.T>J>wkJ580:;D2@NKh9(; >!/4:';>N^;(Kh0Q0QK<,;.N;#5O0:Kh;#><QWS0:12@þ >2@>9;Kb90:K1,(4=Ma;a.T.´>JNNP;#M>9(N4Q>J2@2 5O0$?h0:;#2@i:<:Kb.1;#>w0Q>0:0Q<O.12j.h.T>J5OkNù0Q7@Kh;D0Q<,2@K1> ; MZJ9.C;4:>J;#ý85O0Lþ;CK1MM9N>J.15O0O0Q.2@KhIJ>!Kbt/2*.>0Q,42@,' 7*2X5Q5O,-7@2@W2@4Sk0Q2@>,R;
n3.14Q;NbKbý >0:3,2*;#464Q;.>4QKh90Qk2*4QKb;#>U0 4tThkJKbk/0:;#, 2@>RSN;#>4Q2@0$?hi$;O{0:<O.h5O0Qh;ý Nt/.12@>/0:,^N 2@0:46#Nþ ;>4:2@0$$?[ý M9>J580:2@Khh>[ý >K57@;#.14:>4Lk/0:;=,J.TN> ; /.>0Q;,N<:M;Kh4:,<:W^Kb7j.1N 7@7@?'(Kh} 0:,(;#<:2@4:;
;O.12${>/' 0:;hNS<O'@.htb0Q5O2Y,M0Q;D;NNN;#t(>;#>4Q2@4Q2*0$2@0Q?0$,a?SM0Q9M ,9>J;6>J5O0Q5ON2@0Q;#Kh2*>(>SKb4:>2@2@0$43M?DKb7@;#<M 4:9;4>J.h0Q5O5Q,J0Q,^2*.1Kb>I/>Kh>2@#>Kt062@7@0Z;#.14:7@2@Kh44>0Q.1RC,J>[.10:>SKh,9;D.0QI/7*0:[email protected],;#0:<_<Q,^;#'4:}62@,43Kb> >7XN KJ7@;#tþ 4:.T4L>J0:ND,J0Q.T$,>ý ;#<QJ;6' ;O{2@4:h0Qý4
[email protected]
0:.C, 4: ;#0M<:KTKbMWlh ;4_.bth5:;,.b<Q5Q;#,Rhk/2@Kb;#>a2@>0QRKaN.1;#>>Kb4Q0:2@,0$?h;<i
4:.1Kb>/7@N´2jNùV7*KW^5#rL.T.17@0:2*,(0$!?b;#6i$WkJ .T.10:4Q,J2X;5#N^.1.147W[0QMKb,;#0:9;[,>JKMNKhN.T7@4_7@0:K1t2@Kh$>F2@>tZLR^.12@0>/WN,J.#.18Rb4DKh;#<a>RbK;#.b<OKN.1N´gh7@[email protected]~#5O>;#7@90B4[.T4QRh0:Kh;#;#0:<Q4,(2*;#>(2@<>òRP5OI5O7@Kb9<:KbWS4QIJ0:IJ;#;<Q.T<:2@0:<:>2@2@R;#4:Kb4C>ÆW[MKb;#<a0:2@,N0:K,.1N0OW^4_.[t.14:2@;#>>J0Q? 5O4a7@9J5O7@N92@2*0:4Q>(,´0:R ;#7X<QIJ.12@><Q.TRhR<:;0Q2*.10Q.17@2@RhWSKhKb>Kb<:i$92@kJ0:>,(.10:4QWS4L;N4K1\t3M,>O)2@Kh;#2@<O4:.12@;b0a<Bt 5Q,/,$E .12X5#4S.T2@7$. 0 t
9.15O;#7@4Q7@7@;#K17@4D42@Rh4=><Q.^2X.CNP5O0:5OKb<Q;#WS;#7@;O7@46IJi$kJ.bk.15O9(4Q06;0=W^NPKb>.1.h0Q7@5?,5O;#;#bW4:;#4L;#.T4:I0:0Q2X4D<:5#9J.T2@>5O7 0QM N9Kh;<:<:4B;bW^5Ot <Q.1.T2*0QI(>J2*0:KbN2@>SKh0Q>Æ,.1k/9KT4KhM
[email protected]<Q2@kRh42@<Q0:4:2j<[email protected]<:>5O2@;#2 7@7@?^7@54=4:.1,J0Q>,J.T0:.17@IJ?C0;NÆMuN.1K4Q580:7*.b;#9(<5O4:0:0:0Q9/;,J<:.1.147@7@>[? 2*> 4:58KhKh,W[>2@Rh;0B, .T2@2*> >PNJ2@W[N9.T;#;#>0B>.v0Q4:[email protected]!Kb>J.12*.1>7@7Rh0Q4KbN<:.1.T2@0O0:>J.S,(N^WS4QW^;#40:t_.14_4Q>Jtz9J.T.T5QRh>J, ;#N 4.T4Z0QU ,2@L03;#4:2@2@;40
MuIJ.T.T4:<B0:.1;W[<Z0Q;#,J0:;.1< >SùVn3.1>JN 3}=>Kbr 2*4Qk;a?0Q,.s<:Mu;.h4:5O,0QKbKh7j<N KTJM!t!9.TI>J0:NPK0QU,d;'4:;#7@K1;35O0Q;#2@ghKh;#>Æ<_tK10:M3,4:;9JW[5Q,Æ;#0:IJ,(.TK<BNC.1W[>;#;#;_0:N;4
<:45.1W<:;8._M?[974:2@4:Rh;>7*;_2 5O0:[email protected]>>0:7@KT?^M 0Q2@>,J;69I/;#.1>/<B5O.T;WS0:;#,0Q;;#<:`b4_9Jt.1N7@;#2@>0$?^4:2@0$K1? M
5O7@94Q0:;#<Q2*>(RS<:;4:97@0:4_'
éê -øñ Lïó÷ ôõQö6óbð÷!øñQú c÷ðí 6ó
}l5O;#7@Rb7@4<:2XNbi$,kJ2X.15Q,4Q;MN^Kb<:.1WcII(.C<:KRh.b<:5Q2XNv,4:9(0:4:<Q;#9J45O0QW99<:;a7@0:2.Ti$>J<:;#N4QKh0Q,7@9;#0Q>^2*KbI/>a;#Rb<$M<:Kb2XN^<:W[N4
.10O.T.7*/4:0:0Q,(<:;=9J5OKb0QIJ9;<:<B;b.1'0Qf$2@Kh0 >J43<:4Q2@>S0D`h4:9/9/5:.1,P>0:.C2@~#Rh;#<Q42jN0Q,4Q;D0:<Q4Q9JIJ5O.h0:5O9(;C<:;h2*>'30QGKS,. ;JW>.T2@0:2@;> >.b9NWgh.1k/>;#0B<.TRhK1; M
K1KhM>(7*0:?,(;
Kb>^.TI0:I,<:;DK.h>5Q9,W2*4k/;#2@0:<34K1MuM.T4:5O0;#7@I7@4<QK2*>^58;#4:;4Q.b2*5Q>(, RaN0Q2*2*W[W[;#;>4Q2*,Kb2X>5:,2@>2@40Q0$,?;DI(2j`b59J.1.17@7@>?=0:2@2@~#>J;_NNS;#IJ4Q;IJ>J.hN58;h;#>' 0KTM 0Q,;Z>9Wk/;#<K1MN.10O.6KbkhO;5O0Q4k90N;IJ;#>/N;#>0
Þh
T{
?e
©
Æ?Æ7Æ
©
Lg
¸
fJ
>e
Âo ¸
Á
¦
4 6
&{
LX g
¸
RZYY
4 6A
Á
9%S8 ["*#&<
x8"$#
1j
2P"*#&<"$XS8" ½#0"YP$Z <"$
kj
-6
4
-6
-6
9?' 1<:S*)7X SR."EP$Z <"$
fl
W<§)=<[<:S8P<Q
&{
s7' 1<:S$)7X RT¦.T"/P$Z <"$
nl36
4
+4
WÂo h[]\ ^ 0`_%b aib
b/d
C
-" A#0"P*Z <>"*
4
Æ
ml0`
P"*#&<"$X
Yz
@l
4 ?6
A4 -6
A4 -6
4 36
ol
¥Û
qp
r
5Ð=Ñ
&{
o
Ua²
&{
UC
v
¿
1s
«ª ¦ z«©ª :¨ ûRPª© C§ =«
t#:$AB
G3I I!UFCO
A
AJ5K
AF5O ;
A@
Fhd
C
!2@Rb9<:;D&'@)b)h\{J.1WSI(7*;4ZKTM 5O;#>0Q;#<$i:N; J>(;NÆ5O7@94:0Q;#<:4.1>JN^.T<:k2@0:<O.1<Q?hi$4:,/.1I/;N^5O7@94:0Q;#<:4
0:.,(Rh;<QRh2XNbKb<:2XiZWSN.1;35O>J;#0$N^?7@7@I4 Nb2X;#5#+>(.14:7._2@;80$gh?b{(;iu.T[email protected]:I4Q;7@0:N;3;#<_K1.1t1MI0:I,,<Q;LK2X5Q.bRh, 5:<Q,v2j58N7*9(MiuKhkJ4:<60:.T;4:58<:;7*49(NKb4:.T0:kh;IO<:I;2@5O><Q0QKR4Z.h2@5Q9>^,[4Q2@,2*>>/2@RDRh5O,[email protected]:NN;62@._WSgh;;#G7*>(;f:4:0!rL2@Kh0:<O>J.1.Tt1>7J4¢NM,Kh.T2X<Q0B5QWl.C,4:;OW[IJ{.bI;#5O0:7@Kh;h,<Q'K;#N 4Zb4Q.10B>J.TN0:2@4:0Q2j5f:.1¡7/2*6>sMKhth<QW,.12X0Q5Q2@,Kh>D<:;#4QI0:Kh<Q;#<Q4:;;N>2@0Q> 4
éê Zê:ë æ *W æ3ðï!ðñQóhðñQôïzõ ú ø cïðñ ú -øñ W Lø ïôí
]^G9f:>rL0Q~P )uxhxbG q .T'0:2@4:f$0Q> 2X5#0Q.1,732@4af:r3.1MI(KbI<:W^<:K.1.h0:5Q2@,!Kbt> 0:,;<Q2X4QN IJ.12@0Q4 2j.T. 7Z.1Rh<Q<Q;2XNb.[iuk/[email protected]:N;_2@NÆg2jNW;9NP7@0:2@2>i$0:<:K^;#4QKh<Q;[email protected]*Kb>> Rh9(.T7jI.TI<a<Q5OK;#.h7@5Q7@4, '[NG;#gh,;;#7*<QKb;SIJ.1;_<QN;k9? 4:9J.T+7@7*? .1>4:R/;#[tgb;#
<B.T.T>7ZR 7@;#gb.T>J;#7@N 4
K1;.bM5:4Q,S9J5Q58,P;#7@7<:;.T580Z0B.1.L>(,Rh2@9Rh7X,.1<7*;5Ogh;#;#7@77@4=2@45OI/Kb.1<:<Q<:;#0Q4:2@0:I/2@KhKh>J>;_NND2*>(0QRK0QMKSKh<QNW±2 .L;<:>;#9>W06k/7@;#;#gb<;#K17@46M!KT5O;#M 7@<Q7@4Z;#4:.1Kb07@90Q0:,2@;Kh>P>;O.T{>J0N^7@K10:3,(;#;#<4:;a7@;#58gb;#;#7@7$7*4s'z]^MKhKb<QW <:;#K1.gb;#,(<2*tb;<[email protected]<OI/5Q,Kh2X<Q5#0B.1.17>04:0QI<:2@9J;585O0:;#943<QK1;hM\
4:2@>^0O.1;0Q.h2*4Q5Q0:,^2X5#Rh.T<Q72j2*N^>M5OKh;<Q7*W!.T.1<:0Q;D2@KhI(>!<:t_;4:5O9/Kb5:WS,PI.T9(4Z0:;W[N^;.1.1>/>!NStbW4Q0:. Kb{!<:;t1N[WSk/2@>!;OthMKh58<QKh;a9>.0`bt(94:0O;#.1<Q?S>[email protected]<B4:N[9k(NWS;#g2@2X0:.10Q0:;2@NKb>!0QKSth;.D0B514Q'/?.14Q4:0:4Q;#KW´5O2X' .10:;_NS2@0Q,S0:,(;.T0:0Q<:2@k90Q;=gh.T7@9;#4
2@,Rh;9<Q4Q;D;#0&'@K1)MF4:4Q0B,.TK10:2@4:0Q462X5O.4$i$,[email protected];#4Q<O;.1Nù<B5Q,IJ2X.15#<O.T.17!W[4Q0:;#<:0:9/;#5O<Q4D0:92@<Q>J;D5O7@M 9JKhN<;4DG0:f:,r6;v
MKh5O7@7@7@K194Q0:2@;#><QRJ2*>(\LRJ0:' ,(;S.10:0Q<:2@k90Q;Oi$2*>/N;#I/;#>JN;#>0IJ.T<B.TWS;#0Q;#<t
G
.1>/NS.10Q0:<Q12*þjk(ý 9#0:þ;Oi:Nu;#þ I/;#[>J0:N,J;#.T>00=0:I/,.1;D<B.T.1WS0Q0:;#<Q2*0Qk(;#9<:4_0:t;gh.1O7@9ÿ ;L2@>S#0:t ,(;584:;#[email protected]>JMKbN7*.T@<BK1N^4_Nt1;#4:g9J2X.15Q,[email protected]> 4 t #ÿ W[2*>(þ2*W9#ÿW t t W$þ . {t2@WKb< 9W #t1.T>J2NMz0Q0Q,,#;; t
0:9N,(2@4Q4:;;#0Q<a<:kJ2@2kKbM690:0Q0:0Q,Kb2@KhW;S>PN7@2@2@;#44:gb0Q9;#<:2@7> k5O9;#>0Q7@K12*7@Kb4a>Æ>.1<Q#0$;?'IJ+-5#;[.T7X,(2*5O4;#9>P7X.1>(0:0Q,(K1;N; > NN.T2*k/<Q0B;;O.v5OM0QKb2*7*4<:? ;#7@,JKM.T<Q.hKh>JNW NÆ;N KbN2*<D.T>0B0QKh.Kk('C0B0:.1,G2@;a>,;_;N(N´.1gh0Bk.1.T7@?´kJ9.1;C,4Q?;hK1IJt/M Kb0:T,0:þ@,;ý ;#4:#4Q;2@þ 4a0=0QKT$;#Mþ 4:0QIJÆ4a.1<O5O4Q.1Kb9JWS95Q,ò7X;NP0:.1;#k/4<Q;4t ;#2@iu0:t0Q,;#;4:<0_t ' .Tb4:t4Q2*.1Rb<O>.1;WSN´t ;k0:;#?P<Q4D0Q,K1K1; MM
,.[2@Rh,,(2@Rh;#,<D;7@<D;#gh7@;#;gh7Z;#5O73;#7@5O7@;#4D7@7Z5#.15#>Æ.T>Æk/kJ;;S;.15OKb4Q2@WS7*?´I5O9(Kh0:W[;N^Ik/9.10:;_4:N^;_N´M<QKhKh>ÆW0:,(0Q,;a;W^IJ.#.1O<OKh.1<QW[2@0$;#? 0:;#N<Q2*44Q0:K1<Q2*Mk(0:9,0:;2@Kh7@> K130$?;#I/<;#7*4;ghK1;#MZ7Z2@580Q;#4a7@7*5O4_Kh'<Q<:G;#,4QIJ;Kb0$>J?NIJ2@;>RPKTMs7@K1N32@4Q;#0:<<:2@7@k;#9(gh;#0:2@73Kh5O>´;#7@K17@4M
I0:,(7@9<:;#4D4Q,.[Kh0:7X,N^<Q;#0Q;#4:,(4:0_Kht7XN0:,(J;a7@0:N;#2@<Q4:2@0Q><:2@R^k9I0Q<:2*KKb5O>S;#4Q0$4?'I/;Df MK10:M,(0:;S,;N2@,4:0:2@Rh<Q2@,^k97@;#0:gb2@Kb;#>7!45O;#K17@MZ7!2@0Q4,;4Q;#7@0K10:ZK ;#<7@;#gb;#7ZJ5O' ;#7@7ZN2*4O.1Rb<:;#;2@0:, ;.h5Q,ÆKh0Q,;#<a.T>JN Mu.12@7@460Q,;
Rh9<Q4Q2X9JNb.1Giu7@k/,7@?.1;4:5O;_4QKb0BN.1>0Q`[email protected]:2@0:;>2X<:5#4?S.T.7.1>(2@4Q>4:WM3Kh.1;#<Q7@<:W7/2@>>.TR90:2@WWSKh>kJ;#;0Q5O<,KhK7@K17@NSMZ;5O5O5#0Q;#.T;7@N[>S7@4'k/;2@7*KbKh<9k/0Q;;7*.h2@gh>5Q;#,;_<QN?S58;#.197@437z4Q;OM2@KbM>^97*@70:K1,(.1; 04_'.15O9(><:4Q2*<:Z<Q;4:;>0_<:0t2@>Kh7XRS>._?h;`b;5#9<.1t;#>P<Q32*;;aN4;#'5#0Q.T;#}7X<:5OW[[email protected]>I0Q;=i:;DN.K10:,7X._;>!?bt;#5O<ZKb4Q0B> 0Q.TKa0:N2@4Q4:;#0B0Q>/.T2j58<:5O40;a2*2@>>2@M0:0:Kh;,!<Q<:tbWgh.1.17 ,0Q2@2XKh5QKb,> <
M;#2@0694Q0:<Q<Q2@0:;W,.h;.T5Q<6,0:;;#5ON4Kh>0Q<B4Q,.12X;aN>(;#Rhk/<B; Kh.TC0Q0:0:2@K1KhKbM>WIt<:.T7jKb._>JkJ?bN;#.1<0:k,'32@7@;}2@0$N?P0L;#0:;#0:,,/I/[email protected];#4<00:7X2@0:._WS,?h2@;b;4<t5O2YIM;#<:7@0QK7,5O2@; ;4a4:`b4:<Q2@9;#>7@;;#R<:gh?^.1>4:2@7@I/07;;O0:5O{JK´2 .T0:5#WS,.T;P2@0:>2@Kh;3`b>´90:,;#2@<Q46;L?W[<:'Æ;#7@;#G;#0ght(,(.T<:;S>;#00Q2@<:95O<Q<:;#;#>´7@7@7@;#40:gh,Kb.1;C>>07@<:?;#5O'Rb;#G2*7@Kb7@,4>2@44K1I2*7@M<Q7K<:k/;58;#7*;^;4:gh4<:.1;#<Q>W[;#0=IJK1;_5Ogh.1;;7*0:N @44LM9(0:<:>,JKh0Q.TW 2@0 7
WS.1>/;NS;#0<Q;#0:0:,(9(;6<:>P<:;_`h0Q,9(;D2*<Q;#<:WS;4:9;>7@0:0o4LK10:M,J0:.T,0;WS`h9(;#;;#0Z<:? 0Qb,Kh;0:<:,(;;#`b<:92@2@<:4:;;bWSt<:;#;#>0Q0<:2@K1;#Mgh;0Q,0Q;D,;6`h9(N;#.1<:0O?.' 0:,/.10Mu.T7@72@>0QK0:,;<Q;#7@;#gh.1>05O;#7@7@4tNKM9<Q0:,;<ZI<QK5O;#4:4Q2@>R
G,;.1I(I<:K.h5Q, K ;<:4D4Q;#gh;#<O.17Z.bNgh.1>0O.1Rh;4=K1gb;#<4:KbWS;DKb0:,;#<D5O7@94Q0:;#<Q2@>RPWS;0:,KN4_\ O) L0:,;Rh<Q2XNbiuk/.14:;_N 5OKbWSI9(0B.10Q2@Kh>^2@4
?`
qp
°}kÎ
g`
urå³
¥Î C$
4
i²
vr
Þ~U~
6
Þ4
-6
ø4¦PQZ&#&<6
»
<:).T"¬Q:V;
S<: ['*Z8<
4 º"#-6 ˬ4
06
Q#
»
ª[
4
;#\Q Y ¯
6
Z&#
V?Q
»
ð
4
6
N"¦,S.Q#0"*#&< [
\6
g
¥
<§
'$Z8< [Q#
¿
fw
»
ÜË
L#0Q#0"¥4
»
ª[
»
ð
Å
k
9Ì7#0Q#0">Í
N
E
&
½4
?6
g`
0`
;4 ?6
Fhm
¦ ©ª Á¦ z«©ª =¨ o« :«
A@CBED
AFHG3I
AJCK
AFB
5BLJNM
&O
1st layer
(i-1)-st layer
i-th layer
2@Rh9<Q;D&'@)F(\},2@;#<B.T<B5Q,2X5#.T7!4:0Q<:9J580:9<Q;DMKb<6Gf:r65O7@94:0Q;#<:2@>R
[email protected]>S>/N0Q,u;6E:þZRb<:.C2XNW5O.;#O7@7$Kht<2@>J.hNN4Qgh;#2*I/.1>/>;#5O>J0B;.TN0:Rh;,;>;30K14:MKT0OMz0:.1,0Q`b2*;L94Q0:;#WS2X<:5#?;#.T0Q7,$2@K>F NoMKh0:2@<Q4Z,W;L0Q.T,Rh0:;<:2@2XKh;ON>4Q4Q5O0:0:<:2@Kh;#9/<Q>J5O;5O0:N?[92@<Q>DK1;M!;Mu0Q.b.b,5:5O;,S2@7*2@WS580O;#.1;#7@0:0Q7;,<Q4;#KIJIN.1<Q\z;#<O4:.1;#7@G7@>;#f:0Q7/r64I¤0:<:,K;3Rh5OK;#4:4Q9;#4:4W[2@>0QW,RS<:.T.TKb<:>J9?NRh2@,[>2@>JM0:Kb5O,<:<:;W;WSN.T.1;#0:0O2@>Kh.10B>LkJ.T.T7JK14:9(MJ;I0Q,KhN;6>/.T5O0:N;[email protected]>0Q0BR K.
5O KbWS2@4I90:,0Q;;0:0Q,Kh;0B.T4Q70B.1>0Q92@4:W0:2Xk/5#;#.T<7JI/K1M.1<BKh.TkhWSO;;#580Q0:;#4<:'[4oK1}M!M 0:0:,(;#<D;Rb58;#;#7@>7*4_;#t<O.1.T0Q>J2*>(NRP,(;#0:>J,5O;;,(0:2*,(;<B;6.10:<O2@5QW[,2X;
5#.15OKb73WS4:0QI<:9J7@;O5O{0Q2@90$<:?D;bKTtM!0:Rh,;#;^>`h;<B9(.1;#0Q<:2@?´>RaI<:5OK7@95O4Q;0:4:;#4:<Q2@>46R 2@> 0:2@µ WS; 2@#4øtbµ,;#<:; t
K1M,Kb;#kh<Q;O;¤5O0Q42*4o' 0:,;L0:Kh0O.17/>9WkJ;<K1M!Rb<:2XN5O;#7@[email protected]:,(;67@K1Z;4:07@;#gb;#7$th,2X5Q,2@4Z9(4:9J.T7*@?DW9/5:,4QW.T7*@;#<0Q,J.1> Ætb0:,(;60:Kb0B.T7J>9Wk/;#<
K1M2@7@I7Js<Qk/KK1;D5OZ;#N;#4:;#gb4CI/;#;#<>JtT2*7@4:N72@;#>J2@>>J5O0;5O<QKh;>[G.14Qf:0:;Dr6,4:; 9(Rbk9<B4:.14:0O;#>.14o9>W7X0:.T2X.1<:92@7@7@0$7@0:??a2iuKT<Q,;#Mz4:K10QKb3,7@9;#;gb0:7*2@;#K1Kh<3>t(;#2Y.1M4QI00QI(,7*<:;;DKgh.b;#k/75QKh,DKT0:0QMz0:KhK0:W ,(I/;=;#7@<$;#RbMgh<:Kb2X;#<:N7W
K14Q0:M5O<Q7@0:9J9,(5O4:;D0:0Q9(;#Rh<<:<Q;h2j.1'3N[>Jf .T4QMz0:7*?<:0Q9/,4Q2*;5O4_0:t_Rh90:<O<Q,.1;;>2@9`b49J7X.10:.1K<Q7@2*K2@[email protected]<Qgh4:;#;hG<Qt/?f:2@r60J¤>(W;h5O._t7@?90:,4Q<Q0:;;;#N<Q5O9J2*Kh>(5O4QR;0
0:.1,(>/; NJ0:>,(;D;#2@`b<Z9J>.T;7*2*2@Rb0$,?DkJKTKbMz<:5O2@>7@9Ra4:0Q5O;#;<67*@43.1>/0:Ka.17@58?Kh4:>2@44Q'!0:<:] 9/Kh5O0<:;0:K1,gh;;#<_IJt.T<:G;#>f:0r65O;#7@7$N'!K}L;#4Z4
>(.CKh<:0Z;5O4:9Kb>7@04:t2XN0Q,;<;60:4Q,,J;L.1I/4:;#IJ4.T0:KT2XM!.17/0:,<:;L;#7X.T<:;#0:4Q2@Kh9>7@0:4Q2@,>2@RI5OkJ7@9;0$4:Z0Q;#;#<:;46>.T0Q<:,;6;=2@4Q5QKh,0:2@,(7XN;#0:<Q2X;#51> t
0:7@K1,/Z.10;<2@40:t/,.1;D7@7`b0:9J,.1;D7@2@[email protected]>/0:;#N<.bk/5#Kh5O99>/<O.hN5O.1?[<Q2*;K146M0:.1,(<:;C;;#582@7*0:9(,4:;#0:;<L<:,4DKhN<Q;#2@~#4QKhI>2@0:0B;D.T70Q,Kh;L<gbMu.1;#4Q<:00Q2jI5.1<:K7$t5O;#.14Q>J4:N[2@>>R[KS0:2@NWS2j.T;RhKTKbM>J.10Q,7/;DkJKb.19I>JI(N<:K.T.b<:?^5Q,!2@'4
N;#0:;580:;N'sG,2@4W._?
é*ZT"*$)7X #\-">.T"*#0-"*#&<
g`\4 -6
\`
4 86
¬4 k6
%
º4 ;6
>
Y
g`
C
é ê Zê ì ï Z÷_ õ:ö6óbð÷!ø %_ õ:ö6óbð÷!ø(ñ:ú ö6óñ:ú ï Z÷!õQ÷ðÆðøïú6ó ø ï!ðñ ú
+,._2Xgh5Q;_, 3/7*<:9(4:4:0o0:;4:<9tW[NW;#gb.1;#<Q7@2@Kh~#I/;;0:NP,;k?N.1u0O.L,k;#?C2 2*,W[KhIJ7@;#Kb4Q4:7j.T2@>WSR2$.Lt3W,J9.T7@0:0:2X0:N;<*2@OW;#;S;#>.T4Q>J2*KbN¸>J.1ö/7_,JRh.T<Q>2XNDR 4Q)_0:xh<:9/xb5O& 0:#9t/<Q2@;64=Kb.v>DW0:,9;67@0:N(2i$.1<:0B;#[email protected]:2@5OKb;b>St.T5O>J7@9N4:0Q0:;#,(<:;#2@>>RP0:<O.1.1I(>I4¢M<:KhK<Q.hWS5Q, 4
0:,(;Df$Kh>´<Q2*0:Rb,2@>[email protected](.TMI;I.T<Q0:K9.h<Q5Q;=,!4QtIJ;.h.h585Q;D,ÆkRh?S<Q2XN ._5Ogh;;#7*7@3;#04:9(0Q<BWS.1W>(4$.TMKb<:2@<:~#W;#4.T0Q>J,N ;SJ2M>J>(N^<:KhNW^;#>.14Q0Q;D2*Kb<:>S;RhKT2@MsKh>.[4Rh2@<Q>^Kh90:,(IÆ;=KT0QMZ<B.TI/>Kh4:2@>4¢M0:Kh4D<QWS,;N[2X5Q,´4:I/W.h5O.1;hI ' 2*>0QK0Q,;S5O;#7@7$t!.T>JN
0:5O,(7@92*4o4Q0:4:;#9<aW[.TW>J.1.17@<Q??4:2@2*4_>'6MKhf$<Q>´W0:.1,0Q;2@KhRh>6<Q2X0$N^?I4:2X0Q5#<:.T9J7@5O7*0Q? 9J<:;b0:4t2@0:>,0:;K>W^9.1WS2@>D;#<QWS2X5#;.1WS7.1Kh0:<Q0Q?<:2@MkKb9<0QW;#49K17@0:M
2i$.v<:;#4:4QIJKh.T7@90:0Q2X.12*Kb7>Kb
khO._;gb5O;#0D7@;#5#0.T>0:<O.1k/>;a4¢M<QKh;#<QIW±<Q;#4:.T;#>J>N0Q;0:NÆ,;k4Q? 9k. 4Q;`b9;#>0
>9WS+;[<:._2Xgb5#;#.1,7@7!;#;#.T0<:0:;0:0Q<O<:;[email protected]>5Q94¢,ÆM0QKh;#;#<Q4W7@t(;#0:WS,2@4=;;L>.vM0;4:.TKT2@0:RhM
9>J0Q<Q.T,;D7;ghI;_gh<:5O;K0:585OKb0:;#<6Kh4Q<4:2@>5O2@7@KbRP7J<:k/<:0Q;;;D4:5QI/Kh,Kh>(>>J;=2X`bNI/94Kh;0:2@>K^0:,J03Kb.T2*>>^0;N0Q,>;;5O9KhWS(W[i¢;#NIJ<Q2@2XKbW[5#4:.1;#;#74D>.14:.v0Q2@0:Kb4:<Q>J2@2*Rhk(.1>J79.TM0:;7;h.1t2*0Q>Kh90Q< <:K;DN4Q2 IJ.h;#58<:;h;#'>' 0L(MKh<Q<D;`b.19>´;#>JKh5Okh?´8;4:5O9(0DkkJ.12@0:>/, N4'
G,;Df$>´._
gh._;gb7*;;#0Z7@;#W[0D0QK<BN.1;#>(7!4$.1MKb7@4:<:KW 3tKh4:IJ< .T40:2XKb.1> 7N(.Ti:[email protected];#<:>;S4Q5O2@KhKb>J>.Tgb7J;#<:4Q0Q2*Rb;NÆ>J.12@7@>430:kK^?0Q,.1I(;IM7@<:?;_2@`h>9(RC;#>JKh>5O?;Oi:NN2@KbWSW;.T>2*4:>2@Kh'a>/3.17/Kh>0:<Bgb.TKh>7@94$M 0:Kh2@Kb<:W>PP2@0:0Q,2*W[.1;#>Æ4' .1I(I<:KbI<:2X.10Q;
h3;7@<:9>4:;#0Q7;#<:M49>J5#.15O0Q>^2@Kh0Q>P,;#<Q>P;#4:k/9;7@0Q2j4=N2@;#> >0:.v2 J0:;<ON[.1>k4¢? MKhJ<QWS>/N;2@N[>R4:I/0:.h,5O;D;N;>,4:;#;D<Q;<Q;#0:Rh,2@;DKb>>/4.10:2@>9(<B0Q.1,7;5O7@0:9<O.14Q0:>;#4¢<QM4DKh<Q2@WS>P;0:N[,(;aNKhNW^.10O.1.2@>!k/' ;5OKbWS;DW[Kh<:;DN2@4Q0:2@>Rh9(2*4Q,J.1k(7*;b'
,J.T0$i$+4:,J._.TgbIJ;#; 7@;#J07@0:0:<B;#.T<Q4Z>4$;#M W[Kh<:IW,J.TI4:2@<Q~#K1;3g2j<:N;#Rb;#4a2*Kb0Q>,4;M ,Kh;7@7@<:K1;0:2*,>(;RI/2*Kh>2@0Q>;#0:<:43;#4Q5O0:7@2@9>4:R 0Q;#M<;t.Tk0:99(<Q0;#4:42@' W97@2@0B<:.T4:0_>t;#Kb2@0D94:I7@<:?K10:g;#2X>/NN;#40:KC9>4:94Q9II/I(;#<:<:;#g4Q42@4:;ZN ;. 5Oh7@9;#<o4Q0:2*;#><QM2@Kh><QRJW' .1G0Q2@Kh,>;
qp
:|
\Ï
_³
U
4
x6
/
\Ï
8$
1
²
-6
;
¶
¥
¿V?"7<:Z3"
"SP¦<Q
CV?"=<§Z&S" 9
;
]
Y
9
5
1s
«ª ¦ z«©ª :¨ ûRPª© C§ =«
t#:$AB
G3I I!UFCO
A
AJ5K
AF5O ;
A@
Fhq
C
2*Rb9<:;D&('*)_E\}4B.TWSI7@;K1MF_i:N2@WS;#>(4:2@Kh>J.T7M ;.10Q9<:;4:I/.h5O;h' 2*Rb9<:;2@43M<QKhW,(;#2 ,(Kh7@;#4:7X.TWS2$th3,J.T0:0:;<*O;#;.1>JNaö/,J.T>R B)_xhxh& #'
2@2@>>,0:2@,k;#2@0:2@Kb<[<:4okJKbMKh9<3>J0:N,(.T;6<:?I/' Kh2@G>0:,439(0:4,Jt.TN06;#.1><:4Q;L; ><QKh;#0Rh2@5OKb7@>Kh4Q4;2@>ò;#>Kh0Q,9(;PRh,!Kb'<:2@GRh,2@>[email protected];_;.1.T0:>9(43<:0:;P,;4QIJ5O.h7@5O9;´4:0Q;#.h<:5O4L0S2*.T>[40:,.1;D0Q0:<ON.h.T5O0B0Q.Kh<:.14v90QMKhKhW^<.1>(0:;2X.15#<Q.Tk7@7*?ù?IJ4Q0BKb.12@>/>N0Q4SKh.19(>J0
N .T>J.TN 4
Kh7@5O;#7@9(gh;0:.T;7@7*<62@4;#0:<:KT,(4_Ms';=.b<Q]^5#;#5ORhKb92@<:Kb<O;#>.hK15O46gb?;#.1' <<QtKh!0:92@,(>J>J;.TN[7@W7*0Q?,9t;#7@2@W 0:0L2iu'2*<Q4;#4:gb;Kb;#587@<:Kh9? >J0:2@NMuKh.1t(>^4Q0:0,I;0:<QKPKh7@I/K1.13;#I<:i$I(0$IJ?Æ7*.1?^4QKT4 M
J._7@gh0:._;#;#gh7@<Q;#;407*;90Q0=4:<B;.10QN<B>(.T4$2*>M>[Kb4$M<:0:KbW ,<:;CW.1
>/5#._NP.Tgb>Æ4Q;#9J7@;#,5Q0Z;#,7@0QI<B.S.TN>I(;#4$<:0QMK;Kb5O5O<:;#0:W 4Q2@>4 R5#.T2@0:7*>,;S.1.T9(7@5O4:0:7@KSKh9W^4Qk/0:;#.1;<Q0Q4S2jI/5;#.1.1<$7@0DM7@Kb?DN<:<:2W[;#W[;#;<:NPK1;#>gh2@> 0;
IJ.T<B.1G7@7@,;#;7$' ._gh;#7@;#0¢iuk/.14:;_N587*9(4:0:;<:2@>RS.17@RbKh<:2@0Q,W5#.T>k/;Kh90Q7@2*>(;N^.143MKb7*@K14_\
J1" G,;._gh;#7@;#0¢iukJ.T4:;N^5O7@94Q0:;#<Q2@>R.T7*RbKh<Q2*0Q,WMKh<W9(7*0Q2iu<Q;#4:Kb7*9(0:2@Kh>5O7@94:0Q;#<:2@>Rk?[
._gb;#7@;#00:<O.1>4¢MKh<QW '
F b G,(;6M ;.10Q9<:;gh;_5O0:Kb<:4K1MW97@0:2XN2@W;#>4Q2*Kb>J.17N.T0B.KbkhO;5O0Q4'
zA b 37@94:0Q;#<:;N KhkhO;580:4'
zb G,;C
._gb;#7@;#0$i$kJ.14Q;N^5O7@94:0Q;#<:2@>RS.T7@RhKh<Q2@0:,W
2@42@WSI7@;#W[;#>0:;N.T43MKh7@7@K14'
v
1
4
86
v
Y
\
1y
?dm
_ú \úû
u 7
l
?dN
z|{~}
z}
z©}
L~
QEZZ~LL~F~
QLLQ~
Q<
¡¢F£~¤¡LQ¥Q~Z¦§§¨~FLL<
ª
~FFZ«QQ§Z¦Q~zZ¡|Q}W
FL~¨Z
¥Q~Z¦Q¨ZZ~FL<¬7§
Q|~F¡~Q¤Z¡L
Q§¡Z¡L¨~«°
Q<
²~Q³¨¡³F§~Q¡L~¦Q´ZL|¨~FZ¡|Q,µ
z¯®<}
z±}
G,;a(58KhKh<3WS;O{JI(.19W[0B.TI0:7@2@;hKht>J.T7J2*R/5O'KbWS&'@I)E7@;O{4:,2@0$K1?aKT4Mz.0Q,4B;a.1W[.17@IRb7@Kh;<:2@K10QMZ,F_W
i:N2*2@4WSµ ;> 4:2@Kh>/t.17,M;#;_<:.1;0:9( <:;D2@44QIJ0Q.h,5O;;btJ>9(W,(;#kJ<:;#;D<3;_K1.hM5Q,PKbkhI/O;Kh5O2@>0Q460Z2@2@>S>^0Q0:,,;a;N2@W.T0B.T.1Rhk/;L.1<:4:;#;bI' <Q;#4:;>0Q4
0:4B,(5.1;67@;#M ;4.1M0Q<Q9Kh<:W ;Jgh.1>(7@; 9;4B4Z5#KT.TM!7*;DKh)>;L0QKhKkh58OK;.1580<Q4:2*; >[0:4B,5#.T;L7*;4:IJE .T0:'!2X.1}70N;.T.b0B5Q.C,a4:7@;#;#0Qgb4;#' 7$t14:2@9RJk'iu&kJ'@.T)>JUDN4:,!K1 $43._0:gh,(;#;=<O.1<QRb;#; 4:9(7*2*044QKT,M!K1
._> gb;#.T7@0!;#030Q,0:;Z<B.T9(>I4$IJM Kh;<:<$W[i$7*;84ZM0Z.10`b9JN.h2 N;#<B<:.1;#>>0_0 t
4:7@K19(Zk;iuk/<$i$.17*>J;8MN^0
!`b9J .bN,<B.TKh><Q2@0~#tJKh.T>>J0BN.T7J4Q;_9NkRhi$;#kJ4 .1>/2@N44:L,( K1$>5OKh.1<Q0>;#0Q<:,4 ;92@4II/4:,(;#K1<$i$<:2@> Rb,.T060`b0:,9J;.bN7@K1<B.T3>;#0<$ti$<:4:2@9(Rhk,iu0k/`b.19J>J.hN[N6<O.1 >0'gb;#<:0Q2X5#.17;NRh;4 32@44:,K1>^.100Q,;
Rh,JK.TK>J+N^N7@;#5O._7@4^gb9;4:Kh30Q9;#7@0Q9<:7@2@4:2*>;0QRS;#<:4<.TtL2*7@4Rh.1Kh>J.^<QNù2@Rh0:,2@<Q4S2jW[N2@iu4>kJ\4Q.T;#f$4:>0;4:NÆ,[email protected]*.T>Jgb>JN; NÆ7@;#0Q4NKÆ;#7X.1>(0:,<Q4:Rh2@;´0$;D?bKhiuN<OkJ.TN.T0B;#4:.1<^;4QNù;#K10:MD4L.17@2@;ORh>KbI<:9(5O2@2@0:0;#,('>W 0:7@G'?,t+;´N2@._4B4:gh5O0QK19J;gb3N;#?-7@<:944Q.10:5O7@;#4Q7@<D9Kò4:5O0Q5OKb;#Kb><:WS4LMKbIJ<:.TWS2@<:0:;#,P44.1+<Q2@k0:,._2@0:gb<B.T;.T7@3<:7?[7@0:9,4:4:,J;0Q;#.T<Q<SIJ;;h`bt(92@4:2@0:<:9J,¤;#5W[5On;#;#f:4:>4¢M0:947@C7@K1? M t
`b9J.1}7@2@0$?}' r6S.T>JNVnZ(3}=rDt.1>/N4:,K1430:,J.T0+._gh;_37*9(4:0:;<Kh90QIJ;<$MKb<:WS4o0:,;#4Q;WS;#0Q,KN42@>kJKb0:,;O582*;>J5O?S.1>/NS5O7@94Q0:;#<Q2*>(R
º4 +6
Ó
H4
U4
76
E4
-6
4
6
?6
4
r4
6
S6
Fh&
¦ ©ª Á¦ z«©ª =¨ o« :«
A@CBED
AFHG3I
AJCK
AFB
5BLJNM
&O
,2@Rh;92 <Q,;aKb&7@;#'@)#4:U/7X.1\ZW[]^2$th9(37*0Q,J2iu.1<Q0Q;#0:4:;#Kb<@7*O9(;#0:;[email protected]>[>JNaK1Mö/0:,J,.1;C>(MR ;.TB0:)9xb<Qxh;D& #4:I/' .h5O;2@> 2@Rh9(<:;a&('*)_E.106. 4B5.17@;S) (k 4O5#.17@;aF 5 4O5#.17@;aE(' 2*Rb9<:;2@4M <:KhW
(
4
86
-` 06
i` $6
U
86
é ê Zê _"â
_ õQö6óbð÷!øñQú líLñ í Lñ c÷ú6óñ oú6ïõó Lïô÷
}6.1>/>(NSKh0:Rb,(<:;#2XNb< i$58kJ7*.19(4Q4:;0:N^;<:5O2@>7@9R 4:0Q.T;#7*<:Rb2@Kh><QR2*0QW[,W ;#0:t,(KN'f:¡=f$0L2*43RhtKNK;#Nvgh;M7*KhKb<IJ;_5O7@N´94Qk0:? ;#<Q2*>(}LRSRh<O,._2@
Rh,^.T7N;#2@WS0a;#.T>(7u'´4:2@Kh)>Jxb.Txh7& #N(t[email protected]@>^>Kb7j0:.T,<:;Rb<a;=2@N>.T0:0B;#.1Rbk/<B.T.10:4:;;N4' tN;#>(4:2@0$?biukJ.T4:;N
I/IJ.TKh0:2@>0:;0:<:42@gb>'P;#4L>VK1..TM0B0:7X.P,.1<Q;D5ORh7@N;9.T4Q4:0B0:;;#.0=<Q2@4QKT>;#Mz0R 'W2XN9;7@0Q>2j0QN2 J2*W;#4;>0:4:,2@;[Kh>/4:.1IJ7J.TN<:4:.T;^0B..1>JI/N´Kh2@>0Q,0:4_;t0:58,(<:K1;a6NN.1;0ON .I4:IJ7X.h.b5O5O;;[email protected](>J4:N´9J.T,7*;#@?>/5O>;PKb0N2@94B>5OK12MgbKb;#<:<:WS47@0:?,;[K5#K15Ogh9;#I<[email protected];7@N 7ZNk?^2@4Q0:0Q<:,2@k;a9(N0:.T2@Kh0B>.
5O7@94Q}0:;#<L9f:>2*¡=462@L0.2@ù4W^IJ._.1{<Q2@0:WS2@0:.12@Kh72>(4:M;40:06,(0:,K1;M; M5O<BKh.b>(5Oi¢0:N>2@2*;KbW[5O>P0Q;#;K1>N M4Q2*0:NKbKb;#>J0B>.1.T4:77z;CNN9.T.T>0B0B.[email protected]:4_4:I/I/' Kh.h2@5O>;D0:42@>5O0:KhK>0O>(.1Kh2@>>i$;K1N^gh;#2@>^<Q7X.10:I,(I;a2@9>>(R2*<:0;_;85O{(0B.T58;#>;RhN94a7X.T.T<>P92@>>2@I0:4_9t0L2XNWS;#K>0:N2 ;#J7;I/4=.1N<B;#.T>(WS4:;;#0Q9;#<>'s2@0:} 4_t
}6.1>/I(N <:2@KhJ<Q>J2zf:N¡=.147@LRb5OùKh7@9<:2@IJ4:0Q0Q;#,;#<¢W<:M4Kh<QM2@WSKh><343.1WSW7@72@>94:2@97@>0:k(2XRaN4:[email protected]:4Q5O;#K;#>[email protected]:M6>[email protected]>[,7J;5O<:7@99Kh7@4:<Q;#0Q2@4_Rh;#' <:2@>J2@>.1R7N2@>^.T0B0$.^3Ka4QIJ4Q.h0:58;#;hIt4_\94:2@>R´.P5#.1>/N2XN.10Q;Rh;#>;<B.10Q2@Kh>ÆWS;0:,KN 4:2@[email protected]<L0:KP0Q,;
5OKb>>}L;2@>ò<:5O4Q0Q02@;W[thN´IJNKb;#f:<:>¡=0B4Q.T;DL>0D9P>,2X2@N;#0:9;4><Q2@2@0Q>P4:2 0:J.12X;#5[7@4z7/0:584:,/97*9(.1k(4:0S4:0:IJ;.b<:435O;#f:k4¡?DK1LNMc;2*0:>;#.h0Q<Q;#NWS<:Kb;#2@I4Q>0:0:2@4_4>' R62@4N;#0:>(,4:; ;}69>I2@<Q0Q2*4!Kb<:2@>a2I.17@<Q72@>J0:,(5O2@;ZI4Q7@;^9k2*4:>ùI/.h,5O2@Rh;#4o,-K1NMJ2@2@WS>0:;;#><Q4:;#2@4:Kh0Q>/4Z.1.17Z>/5ON7@90:,4Q0:;;#> <Q2@N>;RJ0:\ ;#<QWS2@>P2@> R
2@b14Zi:þ×ÿN>(2@KhWS06;#ý#N>(þ ;#4:>(2@Kh4:;h>Jt(.T2*7 0QN4
þ ;#Z58>Khþj4:ý <:;C<Q;#94:I/>ýKh2@0:>/46N5#[email protected]>>^RSkJbý ;i$0:Rh,^;N>62@;#WS<Bþ .T;#ý 0:>(;4:N 2@KhM>J<QKh.TW7ý69>$þ 2@0$5# .1) >(i:>) NKh2@0WS1k/þX;#ÿ;D>4Q.a2@Kh5#ý8>J.Tþ .T>J7JNN2XN;#/ý>.T0:4Q;=;DNKh;#>('!>;#G4:4;C' ,/9.103>2@2*04_'th2GM!,.1;><:?;OMK1KbM!<:;h0:,(t/; .17@u7/ 0:,;D) 5#.Ti$0:>J,N92XN>.12@0Q0Q;4
0:,/.106;_5O5OK1f:Khgb¡=>J;#NL<=th.5O.T7@99f:0:¡4:Kb0Q6;#W<6 .TKT0:RhMZ2X5#;5O.1>Kh7@;#>7@<B? >(.TJ;0:5O;#>J0:43N;_4WSNP4:2@N9>;#k(2@>WS4:IJ4Q.T;D.b7 5O9N;#>;434B2@0QK15O4<QM2*M0:I(Kb,0:<Z;2@Kh;,>C.b2@5QRbM,Kh,<;#584:0Q7*0,9(;
N4:0:2@58;W[7*<9(;#4:.T>0:>J4:;N2@<:Kb4Z>J0Q.T,.14!;#7@2@>M 0$Kh?67@N7@4QK1;#9J0:;#5Q4,<QWS'/0:f$,J2@0 >.TJ;#0z4<:,(4QW[0Z2*RbN2@, >;#2@0QNWS;#;#<:>.1W[74:2@2*5O0$>(K1?a;#gh458;7*<0:9(,M4:;3Kb0:;<ZW<:;43. .b{;O5Q{2@, WS2*4Q5O0.T7@792@>D<Q4:;#0Q0:Rh;#,(2@<KhKh' >(4:;4
4:f$039(k4B5#4:IJ.T7*.b;5O4Z;#4_7@2@'6>;f$0.T<:2@7@4?D2@>4:2@;0:,>4:0Q2@,0:2@;6gb;D4Q2*~0:K;6K10Q,M!;D2@>KhI(<O9N0Z;#<L.1>/K1NMz<Q,J;.15O43Kb<BRhNK4KN2@>^4B5#2*>(.TI7X.19k062@[email protected]@0$>/?N.TN4ZK0Q;,46;6>>Kb906WIk/<Q;#;#4:<9K1W[MzN;2*4:W[KhW[;#>;D4Q2*5#Kb.1>>4Kb2@>>2X5#0:,.17!;N(N.1.10B0O..N2@42*4Q2@0:>J<Q5O2*k(<:;_9.10:4:2@Kh;_N>''
K13;#gb;#<t(0:,;a.b5#5O9<O.h5O?^KTMz0:,(;587*9(4:0:;<:2@>RS<Q;#4:9(7*0W^._?ak/;aN;Rh<B.bN;NP.T0Z0Q,;D;O{I/;#>4Q;aKTMz4:2@W[I7@2j582*0$?CK1Mz0Q,;DW[;#0:,KN'
qp
[î
L¶¨F³
;Î
U
5Ð=
²
3~
4
86
»
k
öV+
º"*#
[Q#\gZ&# 1<
L-"*# ?"¯< RT"*#
?Q¬"
W< A.\SQ:7"SP¦<
¡4
#Y4
Ã
Ã
?6¦XS
Y"$#
Q#0 §.-P"
E4
76
o
v
Ã
76
\X
Ƨ ª «ª ¦ «©ª :¨ kR ª© D§ «
Fhx
éê é L÷!õ Lïzó÷ côõ:öLóhð÷øñ:ú c÷ðí 6ó
0:I]^,(<QK;KhkJNN(;#.T.17ki$0BkJ2@.7*.12@0$.14Q?S>/;NSNN2@580:4Q7*,(0:9(<:;64:2@k0:WS;9(<:K0:2@2@>NKhR;>7u4_'WS' f$;030:2*,43KK1NM 40:;#W^>[. kJb.1;Z4Q9;N[4Q;KhK1>Mz0:5O,(;#;<Q0B.T.T4:2*>[4Q9WSWSKIN0Q2@;#Kh7@4>M 0:Kh,/<.10Q03,0:;=,5O;[email protected]:0B;#.<Q4=.1.T<:;L>JNRh;#.1>(0Q;#0:<B;#.TW[0:;IN[00:kK?SKh.DI(W[0:2@WS2{2@0Q~#9;3<:;0:,KT; MzJ903>/kJN;#;#<:0$7@3?;#2@>;#> R
G,;[' WSKN;#7i$kJ.14Q;N´5O7@94:0Q;#<:2@>R´WS;#0Q,KN4,J._gh;0$3KPW.OKh<D.1I(I<:K.h5Q,;#4_\^ý uþ@ý $þ
.T>JN
("$#_" J
3]^7@Kb94:4:00Q;#K1<:M2@>ZR´Kb<2@>ÆKbW> .b585:Kh,(>J2*>(5O;;I7*0;_.1M<:Kb>(<:W^2*>(RP.10:2@2@Kb4a> 9.b4Q9JN.1Kh7@I7@?P0.C<Q;OIM;#<:Kb<Q<:kJ;.1N k2@0Q7@K2@0$?b.Tiu4DkJ.T94:>;4QN[9I/.1I;#<:I(g<:2@K4:.b2@>5QRÆ,!t7@;.T,<:2X>5Q2@,S>RP94QKb;#<46I58Kh<QKh>JkJ5O;.TIk02@7@2*u0$5O?7@9WS4Q0:;_;#.1<Q4:2@9(><:R ;#W[M;#Kh><QW0:4.Ttb0:4:2@9/Kh5:>!, '
.15OKb4^>J5#5O.1;#0QI;#0QRh4KbKh<:?ù<65O97@90:2@4Q7@0:2@0$;#?Æ<Q4694:;2@0:N ,^2*I> <QKhkJ!.T2@4Qk,2@7*;#2@<0$?)_Nxh;#&b4Oq 5O<:[email protected]>J0Q2*N Kb>u4' ;#>>J.T<:2$t!.1>(Rh7@;#?.1>/N 2@4:,(;#< )_xh&hx #t MKh<S5O7@94Q0:;#<Q2@>Rò.T>JNù<:;#I<Q;#4:;>0Q4
Kh>Æ,;#5#(<Q.TKh; 0:<3;#0QRb;OK{JKh<:.1I2XW[5#9(.T0SI7Z7@2@;hN> th.T0B0:.,';´nf$,+¤02@;#9<B4Q.Tn;#<B4a5Q,Kb?>2@' 4:;,(WS;#G<a,;.T)_;P4:xh9WS&h<Qq ;h;0:t!I/,5#K;#.T<$Nù7*M@Kb;,JN<:W[.14[4
4:.C;#gb0:;#Kb<BI.Ti¢7NK17*$2@þW[>!þ 2*t0O1.19t0Q>0:2*K^Kb4Q9>4BIJ45O';Kb<:<:g;2@2@4:;<:;4Q.bN05Qt(t,Æ2@2@>J0[>5O;#<:2*;4WS7@k/?P;#.1>2@4:>0B;_4:.TN-;7!<:5OKb0:7X;_>ò.1NÆ4Q0Q4:>,2 K;Æ5#N.T.1;0:4:[email protected]>J>[WSN´K1I(MN0:;#582@0QKhKh;#>ù>J<:5OW[0:;,JI2@>.T0:;40
I,<QK1Kh3kJ;#.Tghk;2@<7*t2@0$>?[email protected]:7@<:2@k._?9(40:2@Kh0Q<:>94[;Kh4Q> 2*>/4:5O;;IJ5O.1Kb<O<:.1<Q0:;#;Æ7X.1.10:0Q2@Kb0:<Q>Æ2*k(kJ9;#0:0$;#34^;#.1;#><Q;P.14:0Q0O0:.1<:0:2@k2@4Q9(0:0:2X5#;#.147@7@K1?M0Q2@;#>J>ÆN;#;OIJ{2@;4:>J0QN4'P;#>]^0^KbK1<:MD;#K1;gb.b;#5:,Á<tKh0Q,0:,(;;#<I'¤<:KbkJG.1,k(2@2*47@2@0$.T? 4:4QN92@WS4Q0:I<:2@0Qk2@Kh9(>0:2@Kh2@4_> t
<:.1;0QI0:<Q<:2*;#k(4Q9;#>0:;#0B4L.T0:,J2@Kh._>Ægh;KT.Mo587j.T7*9(<:Rb4:0:;=;<:>4D9WW^k/. ;#h<3;4ZK1M2@0=gh`b.197@92@0Q;;D4;O4:{2@>JIJ5O;;D>0Q4:,2@gh;#;2@<60:0QK[2@WS9I;=N.T.1>J0QN[;a4:.1IJ>J.bN 5O;a4:0:5OKbKb<:WS;0:I,7@;O;{5O2@0:7@92@;#4Q40:;#N<Q;#4I/'L;#G>JN,2@46>Kb2@460;#Kh4Q>IJ7@?;_5OKh2X.1>^7@7@0Q?,4Q;DKS>9W,;k/> ;#<0Q,K1; M
.10Q0:2@<Q4:2*,(k(;#9<S0:;#)4_xbt&hkq 90a0Q.T,[email protected]:KP02@Kb46> k(0Q9,2@7*;S0L>0:K^9W2XNk/;#;#><0:2K1M?PMgh5O.17@97@94Q0:;#;#4<Q4DMKh2@<D4;_>.hKh5Q0L,,.1;#0Q2@0:Rh<:,2@k0$i$9(kJ0:.T;h7j' .T>J(5O9;<:N 0Q,MKb;#<Q<6WS4 bKh;#<Q3;ht;N´0:,2@;>II9<[email protected]@2*t/0$?bi$,kJ2X.15Q4Q, ;N W^0:._<:?;; 5#.T4Q99J4:5Q;,ò0Q,.T;4
0:2@W[}L;=>.1>/Kh0QNS,4Q;#IJ<3.h4:58?;4:0Q58;#KhWWSI(5#.T7*;87*@{;2@N0$?0:KS}=N;Rhf$<BG.bN$;aN;#<O>.1>/W^.1.1<:2$0:t2X5#!.T.T7@7*>?Rh' 7@;#?.1>JN 2@4:,(;#<=)_xh&bx MKh<o2*>/5O<:;#W[;#>0B.T7J5O7@94:0Q;#<:2@>RK1Mz58Kh>0:2@>9Kh9(4 Kb<
<:.1;_0Q.10:<Q7!2*ghk(.T97@0:9;D;2@N >P3;_N.h.15Q0O,P.'>f$K0N4:;a0QKh.T<:>J;N[4=.94:5O;Kh4>.0:2@>W[9KKbN92 4J;>NSKh<Q5W.10:.T;7JRhNKh2@<Q4:?^0Q<:92@k0:92@7@0Q2@0$2*Kb?S> WS2u;_' .1;h4:'@tb9(WS<:;;.T>,2X.T5Q>J,[email protected]>^>/N2@>.10Q<O;#NRh<ON.1;#7gK12j.Tgh0:;#2@<Kh> 5OKh>M0:Kb2@<Z>9;_.hKb5Q9,^462*.1>/0QN0:<:2@g2@k2XN9(9/0:;#.14 7
2@0:>,4:90Q4L;.h2@0ZN 2@K14M3>4:Kb90W 4:[email protected];#k<7@;N2@M4BKb5O<6<Q;#5O0:7@;^94:.10Q0:;#0Q<:<:2@2@>kR90Q7X.T;#<:4DRh.1;[email protected]> 0B.TkJ.14Qn;+¤N(.10Bn6.(' 'K13;#gh;#<_t2@064Q9 ;<:40:,;4:2@[email protected]<3I<QKhk7@;#W .T4no+wn.T>JN
94Q;#46}L0Q9,0:;aK3n37j._.T?h4:;#4 4Q2j$.T3>^,;#4:;#0B.T4Q;#0:W2@4:0Q.T2X>5#.17!.T>J.TN^>J.17@?0:94:2@0Q43~0:)_Kxh;#xb4Qm 0:32@W[email protected]:I;67@;#0QW,;D;>>0Q94
W.[k/nZ;#<3._?bK1;#M 4:2X58.T7*9(> 4:0:58;7*9(<:44:'0:;<:2@>R^WS;#0Q,KN[kJ.14Q;N^Kh> WS2{0:9<Q;6WSKN;7*4_'3f$0
z1(Z / Æ J
G2@> ,)_;Dxhk/&;#)b4Q'!0 f$0>5#K1.T>S>^k/;=>;g92@;#<B3.T7z;>(NS;#.T0$Z4
Kb.C< >^Kb.1>I7@2*I>(<Q;K.1.b<35:,I<:2*K_>PO;5O5O7@0Q92*4QKb0:>;#<QM2@<Q>KhRSW[email protected]> ] i¢N2@W[4:;#;#7MX>i$4:Kh2@<QKbR>J.1.1>(72*~2@>2*>(I(R90ZM;4Q.1IJ0Q.h958<:;=;CKbW>0:.1KaI .CI7@K1<QKhZI/;#Kh<¢iu4QKb;<BNPNk;< a? 760$?KbI(,2jKh5.1>(7@;#7@>?
F_i:9JN582@7*WS2XN;;_>.14:>^2@Kh4:>/;#.1>(7 4:; <:L;#Rb2@>S97X0Q.1,<3;D7j.TKh0:<Q0Q2@Rh2j582@;6>J.1K17/Mz4:58I/;#.h7@7*5O4_;h'' 9J5Q,P.W.TII2@>R2@4Z9(4:;N[0:K2XN;#>0:2M?5O7@94Q0:;#<Q4K1Mz;7*;WS;#>0:430:,/.10.1<:;L4:2@[email protected]< 2*>S.T>
éê öðõQñ:÷!øÆïúLïzõ¢û6óñ:ó
yK1M;#<QN?S.10OKT.DM0:Kb;#kh>Oth;0Q5O,0Q4;#<:t(;C;O,{2X2*5:4Q,P0
.TN(<:.1;0B.CRh<QKhKhkh4:84Q;7@?S5O0:N42 ;#,(<Q2j;#5Q>,^03NMKa<:Kb>(WcKh0Kh5O<Kh2@W[>J58IKh7@>?D4Q2*4Q2@0:0:;#,S>00Q,;62@0:Rb,[;#>0:;#,<O;.17<Q;#k/W;#,J.T._2*>(g2*2@>(KhR=<34QKh;#<306WSKTMzKNN;#[email protected]!.T0:<:,;D;D5#[email protected]@;0B.(N 'z9/5:þ ,^O4Qý;#0:K14 M
0:,(;aLN9.10O0Q.D7*2@;#4Q<Q;#4a0' 5OKb97XNPk/;S5#.19(4:;N´k?´WS;.T4:9<Q;#WS;#>0LKh<;O{;5O90Q2@Kh>Æ;#<Q<:Kh<Kh<k?P2@>,;<:;#>0N.10O.Sgh.T<:2X.1k(2*7@2@0$?' (Kh<;O{J.1W[I7@;ht0Q,;
4B;#N.TW[2@4:7X.1I(I<:7j7@?._K1??hK1;#KTM;#MZ430:,.D2@>P;SI/.a;#5Q,<:5O4Q2@KbKh;OWSM> ;OIJ4{.T.1;>Rh5O?9;D' 0Q.T2@gh4 ;K1xbSxhx;<D5OKbK19M
7X.^N5Ok/Kb;aWS5#IJ.T.T9>4:;? N 58kKh9?^7XN.DI(>J<:.1Kh0QRb9<B<B.T.TW 7*@?^N4:;80OMu.1.1>J9N´7@03Kb4:9;#0Q0D0:[email protected]>4aR[.TK1> M Kb.T>^90:97@2@>;#<D<:;_.15OW[Kh<OKhN>;RN´0Q.1,Rh;;b'4B.T7X.1K1<:32@;#;#4gh;#KT<_M
t0Q0Q,,;;
:2@>Kb0:>;#]P;<Q;#IJ.T4:0L;><:?0:4:KSKbN> ..T0B49.[>4Q;#WSKh<2@'o2@4Q>;G2@>58,KhRa9(94.T7XtN7@RhKbKhk/9<Q;a0:2@7@0:[email protected],;#><W[KhN0Q4
,;#.T0Q;#<:;<;5OI/0:0:2@;#Kb<:<:?> 4Q2@Kh>.1> R[>J4N^0:KS4:.T2@Rb>J;>J7*.12@[email protected][?7 J4:2*>/2@'43.1f$2*0:>S46;W^.TKb>S9.10:2@>7@>?2@0:;#;#<:5#<Q4L.1;#4QKh4:;#0Q<42@>t(WSR0:,2@>N;[email protected]~#0:WS2@7@>2@;#Ra2@<Q>4Z0Q2@>,0QRD,;;#0O2*WS>.14J4Q9;#'7@;#gh>J;#584;aW[KT2@MZRhKh,900QkJ7@2*;D;<:KT4M!'IJ.1<QK10:32X5O;#9gb7X;#.T<< t
Kh<0:L;7*9;80Qi¢5O7*2@Kb;#WS<W[W2@9>>(2@2j>5R.10:,[email protected]>P4:;#2XN<Qg;D2j58.1;#I(4It37@2j2@5>ò.10:5O2@9(Kb4:>0:4Kb'WSf$062@~#5#;.1N >^Wk/.T;< 9h;4:;0:2@N >R[2*>vMKhM<B< .T9JJN^>JNN2*;#>(0QRP;5O4:0:I/2@Kb;#>^>JNM2@Kh>< R´Jk/>J;#N,J2*>(._Rg2@9Kh<>9K14:M=9J;8.T{70Q9<:4B;#.TW[Rh;#;7@?K1MZ<Q5O2X5:<Q,ù;NKh2@06<5#IJ.TK<BNKb4<
¡R
G3IG&I
#:$AB
C
´
AJ
C
A
>Ð=Ñ
AJCK
AF5O ;
o
A@
/ײ
C
/C
5
<>=<
< [PÓ¦.-.\SQ7-P¦R
!#0"*Z&SÓ#0"¦<:ÖÓQÕs¦.X
.0Q?8PR
^
d
4
36
4:
-6
4§
86
ø4
86
ÞP7<">%Q$)Z-< 1<§)
!
+
4§
+4
866
á4
Y
6
-6
C4
+4
\6
&
E4
$b; p
-6
d
L
4
\6
U4
»
6
v4
?6
5·
QZ8<§ ["*
L
Nz
Ã
T{
Ì
Nz
Nz
1Í
½
¿
hE |
¦ ©ª Á¦ z«©ª =¨ o« :«
I/;#KhIL7@9;h0Qt(7*Kh2@;#<<32@>SWSW[2@>2@;>NRD2X5#5#.T.T7!>^.1>JkJ.T;D7*?N4Q;#2*4O4o5OM<:Kb2@k/< ;JNP>/.TN42@>\R92@gh>;9>S4:9/..14:7;#<:0;4:KTI/M KhN>.T4Q0B;a.C0QIJKSKb5O2*>;#<:0Q0O4 .1P2@>^.TWS>JN[;N0:2j,58;2*>(>;69KhW<k/0Q;#<:;<.TKT0:MzW[Kh;#9(>0:07@2@t;#;#<:0O4651' t J>JN[0QKhI[Kb90:7@2@;#<
I/4:9(Khk2@>I0:<:43Kbk7@,;#WS2X5:,^4_\ .1B<Q);=Z5ONKb;>J4:>2XN;D;#<O.1,Jk.T7@?^06NN.12@4:0O4:.a2@W[5.12*7X>^.T<kJM;D<QKh5OW
Kb>0:4:,2XN;;<Q<:;#;WNP.T.T2*4>(2@2*>J>(5ORKhN(>(.14:2@0B4:.(0Q'!;#>G0,(Kh;=<Kb;O9{J0:5O7@;#2@;#I(<0:2@W[Kh>J2@>.T2@7!>2@R>I.C<:KbRhk2@gb7@;#;#W>N5#.T.T0B>S.k/4Q;6;#0 g/2@;#.1Z>JN;_NuF .T4Z/0$3>JNK
.1>^;OG,58;2*;I(><:0Khk(W[7*;;#W±0:,(KKTMzNvN0:;KJW[>(2*2*>(>(RD;6Kh0:9,(0Q;=7@2*Kb;9<0:2@7@42@;#><QKh4>4:0QKS<:2@Ng;2j.T/7$>'J;f NMz' .<:;#Rb<:;#4Q4:2@Kh>^WSKN;72@49(4:;N MKh<ZN(.10B.WSKN;#7@2@>RJt1.T>J.17@?4:2@4K1M!<Q;#4:2XN9J.T7@4
0:IJ5#,(.T.T>;#<:?S0:2XRh5OW[2@9(gb7j2*;aRb.T,<6Rb0zKKbKk/>N´;;D,k;#2X4Q9N0:0D2@NW;#.>^.T5O0:Kb2@2@>KhW> 0:k<QM2@;#Kh>J>J<a.1N0QN(t([email protected]:>S;0B..TKT4:M
Kb:>J;ON{.12@0:WS7$<Qt;#;KhWS><4:;Kb2@>Kh0:>[;#,4:;4gh<
J.15O'7@9?;#5OG7@4L2X,5WS;5Q2@0B,JRh.T.1,4 >03ÆRbkJ;#k/;C4;'o5O;OKh{+-W[0:<:,;;;#WS>[0:<Q;hW2j'L5 9}6?´7@0:7@4:2i:K/N,t2@;#WN> ; ;#J>J>4:>J2@2@>NKbR[2*>J>(.1KhRP79NKh0Q.T7@92*0B0Q;.7@<:2*46;2@46<D2@> .12@>>/5.1.10Q7@0:2*?W[;~#Rh;;aKhN<Q4Qt2X;#5#><:.12@Kb7;#0
4_NtZ.T.T>.T0B?.4
<:;_`h9(+Æ2*<Q;L;#464Q2*;#7@7/IJ;O.T{J<B.1.10QW[;a2*5O>(Kb;6>2@4:>2XNN;#;<O0B.1.10Q2@2*7Kb>!0:,' ;2@4:4Q9;#4M Kh<6N; />2@>RS.1>JNvWS2@>2@>RDKb90:7@2@;#<Q4'
.I1<Q7@Kh;a0QGgb4;#,<:;? ,W[;#Mu<Q.1Kh;a4Q4Q00.1I.TKhI/>Jk.1gN^<:2@Kh;; >90Q4;7@5O?.10Q>/2@KhghN9;S0QK17*.1M?0Q0L2@;#>>>RKh`b0Qgh92X.15O2@2@7@0:>9;R;#; 4N5O;.TKb580B90:.v2@7XghNS2*;>/k/5O;Kh._>IJ?4Q;42@4:<$MM0:Kh;;58<>J0:5OKb7@2@?^9;#0:4gh7@'[email protected];#7@s<Z2XNK1NZ;#gh0:.1;#;gb7@589;#0:;<2@4ZKht>^2@0:>S,.12@<Q<:4=;; .1N7@K2@0$;?4D'!>f$_Kh0þ@0ý .12@I7@Y7 þI(.T7*?^7@u4:þK0QK^;#>JNÿ 58.TKh0B9.^>5O0:Kh;_<=>ý#'z0ON.1s22@>92@W5O>9RS.T7@0Q>a5O2*;?;4Z5O?h7@0Q;#2XK 45
gN2@;#4:0Q9J;G.T5O0,7*2@;^~#Kh2@9>5OKh0QR7@W[2*>;I9<:49WS0Q;;#<:<$2@0:2Xi$5#,PkJ.1.17W^4QN;.1N´.T>0B?Kh.9(5#K10:.TM7@2@0:0$;#;#Z<aRbKKhN<Q;#0:2jK0Q5;.10Q5O7Z,0Q.T2*<:Kb0:;>0:;a<Q2@NWSk2@9WS;#0:0Q;;#,4=>(K4:NKb2@4aKh<D>N5#4_.T.1' >0O.Sk/KT;MZ5#,.T2@0:Rh;#,´RbKhN<:2@2@WS~#;_;#NÆ>4Q2@2@>Kh0:>JKP.T7*0Q2@,0$?<:;#4Q;P2*>/.T5OI;I,<:K9.hW5Q,.T;#>4_\^;?hý;#4au.Tþj<:ý ;$þ Kh>7@?^RhKKNP.T0 t
.114þjý >(Kh2@4:;ht(,_K1ý 3;#gh;#<_t0Q,;#?t 5.T.1>J>^N kJ;CWS_þ K$Nþ 2 J;N0QK_,Jý8._þjýgh;Kh9(0:7@2@;#<
N';#rs0:;Kh580Q0:2j2@58Kh;Z> [email protected]:46K.0Q,Jk.1?0I(W<:K.TN>9J? 5O0bKTýMz0Q,#;#þ 2@<6;O{;589#þ0:2@KhÿD>'ýN2@4B5#.T<BNKb90:7@2@;#<Q4
éê ê:ë æZðïðñ:óbðñ:ôïõDï Lø ïôí ø öðõQñ:÷!ø 6÷ð÷ô/ðñ ú
G.1>/,N;34:0Q0O,.1;#0:> 2@4Q0:2X2XN5#;#.1>70:.T2 JI;I4<:KKh.h95Q0Q,7*[email protected];#4:<Q4Q4a99(WS4:2@;>4!RÆ0:,(.P;0QWS;#4:K0^N;#5#7b.197@7@>J;NN ;#<QT7@þ@?ý 2@>RN2@4:0Q<:2@k980Qý 2*uKb'ù>DG0:,/,.1;^0!Rb0:;#;#4Q>0S;#<O5O.1Kh0Q>(;#4:4Z0:N<Q9J.T5O0B0Q.L2*Kb4:>-;#0 <:;_;h`h' RJ9('@2*t_<Q>;#4Kh<QW>.1K17N7@2@;4:N0QRb<:2@;k9.10Qk/2*KhKb9(> 0
IJgh.1.T<Q<B2X.1.1W[>J5O;#;b0:;tJ<:.14S>/NKTMD0:,(0:,;D; >9N(W.10BkJ. ;<Z4:;#KT0_Mzt;O4:{9/I/5:;,5O0:.1;_4SNPN(Kb.190B0:.ù7@2@;#N<:2@4_4:' 0Q<:2@k90Q2*Kb>-.1>JN >K17@;NRb;PK1MaN2@4:0Q<:2@k90Q2@Kh> IJ.1<O.1W[;#0:;#<Q4t4Q9J5Q,w.14[WS;.T>!t
}G,4Q;[0B.1Z0Q2@Kb4:<0:2X5#[email protected]>7!RPN,2@4B?5OIJKbKb<B0:N,.T;>J4:5O2@4?^2@0:4a;4:<Q06;#0B;8.T{(2*.T>(WS;Nù2@>2Y;#M64o0Q0$,Z;#K<Q;,?2@4IJKb>0:K´,;4:4:0B;#.T4_0:\
2@4:0Q. 2X5#.17@7@? þ 4Q2@Rh>2 5#.T>0aOý#;#þ@gýD2XN.1;#>/>/N5O;^.T> 4:9II/Kh<Q0:4$þ 2@0:4<:; O;5O0Q2*Kb8>!ý#þ@'ùý#' G,;
3Kh< 2@>R,?I/Kh0Q,;#4Q2*4 2@46.4:0O.10Q;#WS;#>00Q,J.100Q,;,Kh7@;DN.10O.D4Q;#0=58KhWS;4M<QKhW.1>[2*>(2*0Q2X.17/I<:KbkJ.1k2@7@2@0$?aW[KN;#7 ýt2$' ;h'@t
\ . ý ) ) ) OF
5OKb0OWS.10:I2@4Q7@0:?2X2@5#>.1RD7/0:;4:2@0:0,[2@40:,I/;;#<$WSMKbK<:W[N;;7Ný0:'!KDf 4QM ;#.;2@4,;#4:,0Q,K1;#<6>[.1>0:KKbk/kh;DO;[email protected]<[email protected]:>2@Rh06>(.T2 05#0:.1,>;0:7@7@?D;#gb7X;#.T7!<:RhKT;Mz0:;Kb4:<04:t(W^0:,.1;7@>P7 !2@2@0Z>2@<Q4;#>7X.1Kb0:0Z2@Kb<Q>a;.10Q4QKaKh>J0Q,.T;=k7@N;=2@4Q0Q0:K<:2@kJk;9(7*0:2@;#2@Khgb> ;
0:W,/9J.15Q0 ,P. N;#5OI/Kh;#W[>J;#N43;>M<:0KbWKb>ý
,(.12j>J5QN^¸, .Tý> WS.T7@K0:;#N<Q;#>J7.12@460Q2*gb5Q,;KbWS4:;#K>´N;#kJ7;_0Q5#,J.1.1904Q; . . 58KhWSWS2@Rh;,4303M<:kJKb;aW.T>^.1>KhKb90:0Q,7*;2@;#<6<WS9(K>JNN;;#7 <LlKh>2@;D46W[.bNKKhNI;#0Q7!;N.1>/'oNG.,;DI/<:;#;<¢M4:;95O7@0Q067*? 2@4ghgb.1;#7@<:2X?N
gh.17@9G;,9; >/MNKh;#<QW<0:K1,(MJ;D.1Kh7@0:0Q;,<:;#>J<.T' 0:2@gh;ZN2*4Q0:<Q2*k(90:2@Kh>C2*4.17@4:Kgb;#<:?C2*W[IJKb<:0O.1>0J2@>aN;#0:;#<QWS2@>2@>R0Q,;ZI/K13;#<!KTMJ0:,;o0:;#4Q0tb2u' ;h'0:,;3I<:KbkJ.1k(2*7@2@0$?
0:,/.103Kh< 2@>R,?I/Kh0Q,;#4Q2*4L2@4Z<Q;O;5O0Q;N ,;#> . 2@4<:;.T7@7*?S.T>^Kh90Q7*2@;#<_'G,;#<Q;a.1<Q;=4Q;#gh;<B.17MKb<:W[4K1M.17@0:;#<Q>J.10Q2@gh;,?I/Kh0Q,;#4Q;#4'
<:; Oz;_5O0:1;N !2@[>Mu._ gbKh1<3K1M_.1" >P/ .1'7@0:;f$>Æ<:>J0:.T,0:2@2@gh4a;5.1,4:?;bIJtKb0:0:,(,;S;#4Q32@4Kh0:< ,J.T2@>06RP.17@,7?0:I/,Kh;0:Kb,(k;#4:4:;#2@4<Qgh0:.1,J0Q.T2*Kb0a>[email protected]<Q;#2@7@4:;#;W[M;#<Q>Kh0:W4.T5OKh>W[Kh0Q;D,;#M <6<:KhNW2@4Q0:N<:2@2@k4Q0:9(<:0:2@k2@Kh9(> 0:2@Kh¡> \ ý 2@4
\.£ ) ) )
ý.T>JN
5,JOKh._>gh4Q;D0:<ON.12 2@>;#0:<:W46;#>Kb._0L>P?[WS0:kJ,(;;S;.TN>!M2Khth<QKb;#W<6<Q;#NKT>2@M0a4:I/cN;#2@<:4:N4Q0Q2@2@<:Kh4:2@0Q>!k<:9t(2@k0QKh2*9<6Kb0Q>.C2*Kb47*>^KbKh><D2*>^RhN;0Q2<,J0B.1;#.1<D0L2@7$2*Kh'0>(W7*? 9(2*4:>´0IJ,J.T._gb<B.1;=W[I/;#Kh0:0Q;;#<:>40:2XK1.1MZ70Q0:,K[;[email protected];Kh;9(N0:2@7@4:2@;#0Q<:<:4_2@k' 9(0QKh2*Kb<L>!;O'a{J.1noW[90DI7@0Q;h,t;#2@<Q0;W.1._<Q?;
k9"065O_Kb>10OS.1W[2*>/.11>0:4M_<:" Kh/W '4:GKbWS,;;LW[Kh0:2Y{,(0Q;#9<<:IJ;6Kb.TI7*90Q;#7X<:.1>/[email protected]:>!2@gb';=f$>^4Q0B.T0:,0:;#2@4645#0Q.T,J4:.1;D060QN,2@;D4O5O.1Kh7@<O0:N;#.1<Q>J>[email protected];7@9,;#4?I/.1Kh<Q;=0Q,>(;#Kh4Q2*034Kh2@94_\0Q7*2@;#<Q42@2> ý¤I/KhI97X.T0:2@Kh>
) ) )
\ . £ B) Qý
>.1<:9( ;" W2@kJ>J;#N <;/IJ.1Æ;#<Q>/2@4:N;D ;#2@>>J01NKh;IJk_;#4Q";#>//<:Ngh ;#.T'^>0:0:2@GKh7@?[>,432@M4<:M Kb<:.TWcKh7@W 0:;#0:<Q,(.D>J;D.1W[2@0Q>2*Kgb2@N0:;^2X2 .1/4:7/;0B.TWSN0:;#gbK4;#N<:;#0Q4Q7 ,J2*Kbý .1>^0K1.1M2@7@0:7ý,^0Q,IJ2@>;S.1<OKb.1kW[,(4:2j;#;#5Q<Q0:,^gh;#<Q.10:4 ,(0Q2*;=Kb>I/.T4S.1>J<BN.1.TI/WS.1;#<:0Q0C;#M<:,<Q4Kh2@7@,/W;._0:gh4Q,;Kh;WSkJ<:;;;;#W>PI(.1<:4:;#2@,(>4O2Y5O2@M ><:0:2@;RCk/N;#;' 7@N ;#WS4:W^;#>.10Q7@4 7
A@CBED
AFHG3I
AJCK
AFB
5BLJNM
&O
A
°
v4 76
¦
?`
(4 -6½
xÌ
Í
¦
*)
Y-=<>¬
$Z *=<
Q#
º"¦< RTQ7
<>=<
S<#\PS"¦XS' ?";.8.0Q?8PR
8"$ [7< [Q#º#0)
°.8.0SQ7-P¦R
S< [Pv.-.\SQ7-P¦R
;P*Z <>"* #&%L
%-Q W<[R
5·
~U~
¡$
v4
á
06
?PQS8#0P*)k<>" <
Y
ÖÓQÕ #&%cR&).TQ=<[R"
¸
<"*$#07< "/R3).Q7< RT"
¸
C© í
à
è
È
«;
-© ©
©S
Æ7Æ?Æ
Æ
¿4
6
<
u d
[
¸
7
¶©
à
è
í
È
«¥
-©
©S
Æ?Æ7Æ
Æ
¹
°
l
[
[
¸
^
à
4
[
º
Ã
6
º Y©
Ø
í
è
È
«¥
-©
'»
©S
Æ?Æ7Æ
Æ
Û Å
-§ Z© :ª =¨ « :«
E)
kM/Kb;=<6W^[email protected] 4BN5O;Kb;L<:<B;#2@N>S>.T0>J<:;0:5OR;#?^4Q.10D<O0:N[;#4:4Q0O0:0:.12@K>0Q2*R^4Q0:,.12X5O2X>J5:4DN[,^,/gh0Q._;#.1gh4:7@;0L9;0:kJK;#KT;M I>Æ0Q<:,;OIM ;D;#<:<[email protected]>Kb0Q4:[email protected];4:N´0:IJ2X5L.T<:M ,0:Kh2X2X<5O5Q9(,Æ;#[email protected];#.1<ZW[7@7@4QK1;#2@>0:9J0 .T0:. KP0:[email protected]@>!4 5#58';#}LtIN0D4:4Q2@4:Kb90Q<=WS<:2@<Qk2@;>9ORD;0Q582*0QKb0 ,J>S.1.[0KT3M 4QKhKhW[< 2@;42@>4:kR[0B9(.T,2*0:7@?2@034:I/0Q0:2XKhK 5 0Q,J¤;#>J4:,JN[2@4_.T' 4,3kJ;#;#,(0Q;,Kh> 2X;#5O<5Q;,gh2*Kb.144:7@;#90Q>K ;
[N2@4B2@4658KhN<B2@N(4B.15OKb><B06N.1.T>J>N[0_'60Q,;D2@Rh3>(2 Kh< 5#.12@>>0RI,<Q?KhI/kJKh.T0Qk,2@;#7*2@4Q0$2*?42@è4 <Q;O;5O0Q¨;N ' . L2@4;#gh.T7*9/.10:;_N'f M è 62@44Q95O2@;#>0:7@?^4:W^.17@7$th0Q,;#> . 2@4
f$>^5#.14Q;DK1MW97@0:2@I7@;3Kh90Q7@2*;<:40:,(;#<:;a.T<:;D0$3KkJ.14Q2j5L0$?I/;#46KTMzI<QK58;N9<Q;#4LMKh<6N;0:;5O0Q2@>RSKb90:7@2@;#<:4_\
8ý8'f$>[0:,2@465#.T4:;D;2*0Q,;#<.17@74:94QIJ;_5O0;#7@;#WS;#>0Q4Z0Q<:;.T0:;NP.T4Kh90Q7@2*;<:4Kh<6.T7@7!.h5#5O;I0:;N .1465OKb>4:2@4:0Q;#>0'
0:Khù ,0:,(;^;#ý7@<:;.12@4Q4:0$;bþ tKh0:9,(0Q;D7@2*;><a;Oý {2@400:WS;#4QKb0:<:$;;Lþ N ;O{/0:<:<:4:;0_WS' ;f M=;#7@2@;#80WSý#2*'!;4}>M 0KhI(92@43<:>JK0:N 5O;#;4Q0:N0:K´;9(N<:kJ;ht ;^t!.T5>JKb.1N[97@0:7@4:;7@K2@NP;#<Kbþ to>!ý80:' ,þ ;> .T7@u7Zt(W[2@4KhWS<:;[Kh<Q;O;={0:.b<Q5#;#5OWS;#I;^0Q;ghN.1'37@9f$;0:44W^.T<:.1;P2@>.17@2X4:NK´;.CKh9(2@40:7@0:2@;#,J<:.T4 0
I.1k/<QKhKhk}9(7@0;#W^W[IJ.1.#4<OO<:.1Kh;WS<`b9N;2@<O0:<:;#._;3<Q40:kJK K1.hMzJ5 S>J0Q,NCKT;DMKhN90:.1,0Q0O7@;2*.D;4:<:4Q0O4z;#.10.T0Qt(0!2*4Q4:W0:9J2X5#5Q9,[email protected]4I(2*W0:I,<:;;DK>.h4:[email protected],P0B>/.[email protected]7#N0:4Q2@,JIJ4:0Q.T.h<:05O2@;bkWS'90QKb]^2*4:Kb03Kh>!<Q0:';#;#K14Qgh0:4DK1;#3<_.1t1;#<Q0:gb;,(;#;ZM<Kht4Q<0B2@>^.14Q0Q2@>W2@4:Rh0:.T7@2X;D5#>.T?.170Q5#.T0:.1I<:4Q2@Ik;#<:49(Kt0:.h;#N5Q4_.T,DtJ0B.k(<Q;9N`b02@94:W2@0:<:<Q;#.T2@4k>9?S0Q,0:2@N(; Kb.1>0B>.W^K1W[._?D7@2@;>N>2@>RbKb;R0
k/; .146>NK1;#gb;#>!7@Kh'DI/;0BN^.10QKb2@<Z4:0:Kb2X5#k.T4:7;#<QWSgh;;#N 0Q,NK2@N4:0:4=<Q2@NkK[90:>2@KhKb0> Rb59J.1.1><O>.1Kb>00:;#kJ;;D0:.b,/N.1;0D`[email protected]!0QKb;#7@9?S0:7@W[2@;#<QK46N;#7@;2@7@N7zk/;C2@0:M,PKh9.T>/>N[?4QMKh0B.T<L>J0:N,.1;<ON^5#.TN4:;#2@4:4D0:<Q2@k,(9;#0:<:2@;Kb>!>'K[4:I/;5O2 50Q;#4:0
éê ê -ñ:óbðïú6ô÷ Lïzó÷ öðõQñ:÷!ø 6÷ð÷ô/ðñ ú
G2@> K 587LKh>9Kh><Q0:<6;<.1>JWN^.12@rs>RP7@2*W[)[email protected]@' Kh>42*W[IJKb4:;Nk?4Q0B.10Q2@4:0:2X5#.T7WS;#0Q,KN4t0Q,;6>(Kh0:2@Kb>SK1MzN2*4Q0B.T>J5O;Oi$kJ.14Q;N $V=n oKh90Q7*2@;#<32@4Z2@>0:<QKN9J5O;N
}[email protected]>/5O;Oi$kJ.14Q;N uVn 3Kh90Q7@2*;<2*4N; />;NP.T43MKh7@7@K14'
M}6<B.b>Æ5O0:Kh2@khKh8> ;5O[0 K1. M0:2@>Æ,(;=.PKbNkhO.T;0B5O.10Q4Q46;#0 2@> ±-2@4D7@2@;.P.TN0
[email protected]>/2*5O4Q;O0B.Ti$kJ>J.15O4Q;D;RbNÆ<:;Kb.T90:0:;#7@<L2@;#0:<D,J.T> 2@0:,´IJM <:.TKh<BW .1W[. ;#' 0:;<:4 .T>JN t!2$' ;h'@t 1 #t2YM=.T07*;_.14:0.
0:VL;2@2@4:0:4:0:,0B4L.T/>J0:5O2@0:;O0:2@i$,>kJR.C.T4:0Q4:;,2@N[>;DRbKhKb7@9(;6k0:4:.17@;#2@7@;#<QRh<ZghKb;<:RbN´2@;#0:>,N;#Wc2@<O4:.10QN<:7@2@2@;~#k0:;#9;45O0Q0Q2@KbKh2@0:>>^,R;#2@<>Kh0Q>>(K7@Kh?0:4:2@KbKhKbWS9>0Q4Z;7@2*I(;4:0O<:<:4K1.1g>JK12XNM!N.T0Q;<B,NNP;kNI?2*<:4QKb>0:IJ<Q92*KbWSk(4:9;;#0:<QN[2@KhKh0$9>´?4I/.1N;#>J2@44BN^'o58Khf$5Q0
<B,N(K._.1Khgb>J4QKh5O2*2X>(?NRS4Z0Q;#.CN4:2@0Q7@4BKh4=5O03Kb.T<BK1>JNMzN.T5O>J<QKb5O;#WS?PI7XI.h0Q9;#5O0O4:;0Q.1440Q'LW2*KbG> .1>,.T?D;#4:<:4QKT;8KMzM58Kh0Q2j<Q.T,;h0:;#t!;4:N ;.
N2@4:0On3.1>J.1584Q;O;iuNk/Kh.1>4:;_0:N^,2@Kh49>(0Q7@Kh2*0:;2@<Kb2*>a46KT.TM 7@4:KbK90:5#[email protected]@;#7@7@<;tTN^Kh>. ;65#.Tþ >4:,K1ù0:þ,J.T0tKhMKb< <zW^.1>?DNY2@þ 4B5O#Kb' <BN.T>J5O?0:;#4Q0:432M.T>aKbkhO;5O0 . [email protected]>aKb90:7@2@;#<.h5#58Kh<BN2*>(R
0:.K´>(.^Kh<:4:W^I/;.15O7!2 N2@5^4Q0:N<:2@2@k4B589(Kh0:<B2@N(Kh>^.1>JKh5Ok(?Æ4:;#0Q<Q;#gh4:.10_t0:[email protected]>2*440:.1,J7@4:.TK 067@. 2@;Ev1 Kh<LWSKh<Q;Kb94:0:[email protected]@;#>J<N.TMKb<BNP<D4:NKb;WSg2X;.T0:4:2@9Kh2@>0O4s.1kM<:7@?ÆKbWN; 0QJ,>;;_WSN ;.T> .T>J58N Kh>4Q'2jN(;#<:Kh;<DN ;80:{(K[.TWSkJ;I7@Kh;h9(t0:2Y7@M2@;#M <:Kh4_< t
0:,(;#>P;0:gh,(;#2*<O46.1N7/; ;OJ>5O2@2@0:;#2@Kb>>0
.T5#[email protected]>Kh<Qk/2@0:;D,9W[>(4!2 /M Kh;N[<W[k?^2*>(. 2*>(R=1 N2@u4:| 0O.1xb>Jxh58&h;O& iuk/B|.14:);_E NSKbuiu9Kb0:97@2@0:;#7@<Q2@4Z;#<_,J' ._gb;kJ;;#>PN;#gh;7*KbIJ;_N'G,;#?S.T<:;6Kb90:7@2@>;N[.14M Kh7@7@K14'
Kh.1þ <4 bi¢N[0Q<:)ý ;#;#>4_;t/2*Rb0:K,kJ4:Kb;þ .T<:4D<B5Qÿa.1,^<Q'3;DMGKbM<Kb,9>;>J;#2@2@N>JRht/N,;Ok/{Kh,i$<:;kJ4<:.1; KT4QMz;NP;.b.T2@5Q4=7*,PRb0QKh,Kh<Qkh;2*0QO,W;_Wc5O._0 {9. 2@W4Q2@;#>P94DW
.WN9>.17@9(0Q0OW2j.1N4:kJ2*;W;#06<L;#>K12@4QMZ0:2@,KhKb2@>Jkh>[O.T;7J<B5O.h2@0Q>JN4DN2*9(;84 {2@2@0:>,R.12@>P<:4QKb0:0Q9<Q,9J>J; 5ON[0:9(0:i$,/<:>;#.1;#4_02@t!RbKh,4Qkh9Jk/85QKh;, <Q5O,0.TK'o4=K}6N^34i$K10:4QM
<QK;#Kb.T;#>> 4
Kh9,0Q;#7*<:2@;#;<_tS2@02@42@4=0Q,5O;a7@;N.T2@<6WS0Q;,J>.14:0L2@KhKh>/kh.1O7@;2@580$0?a..1>J2@aN4> Kh02@4.1>^0:,Kh;C9(>0:7@9(2@;#W<kJ'3;#G<3,K12@[email protected]:;7@RhWSKh43<Q2@0:2*>^,Wc0Q,,/;D.1N4.10:0O,(.1;a4:;30tKh.1<Q>J4:0=N[[email protected]:4B;5#.T5OKh7*;W[46I37@;#;O{7@7z2*0$.1?46KT[M Rbµ <:K1u4='3 n9(0 t
0:.1,I2@I4a<QK5OKb.bWS5:,^I97@;O>/{5O2@Kh0$?^W[;#IJgh;#.10Q7@2@9J0:[email protected]:;h2@'Kh>´0B. h;#4C2*>0QK .b5#5OKb9>0a4Q;.1<O5:,ù0:2@WS;CKh>7@?t,2@7@;k92@7XN2@>R.T>Æ2*>/N;O{Æ2*0Q4:;#7M=5#.T>ÆW. h;D0Q,2@4
.WS17@ORh;#ý W[Kb<:Kh2@0:<:,?LW
k9 k9(;#0<32*4:0#IJ._þ .bgh5OKb;ÿ2XN2@'>4Z0QG2@K>J,0$N;CZ;O>{SK;#,J4:4:0Q0Q.T<:;7*9JgbNb5O;#i$0Q7@4K9.1Kb<:>J;I NC5O.TKb0:7@,(Rh>;=Kh4:0Q<QN<:2@0:9J.T,5O0BWc.10Q2@4QKh;#,/> [email protected]>>J0:0:NKL,;C4:0Q;#<:[email protected];#;#46W[<B.T0Q;D7JKa7@5OKhW[KhRbW[2@2X>5#[email protected]*.T~7@0:;ZK2@5Kh0Q,>/4_;D.1'z7!>no5O9Kb?WWS5#k/.1I;#<Q7@<Z;O;OM{KT92@Mz0$7@7@?Sf ?ab.15Q4L,K4_0:,Kh'!4Q;f$2*06>(2@>JNR=N2@0Qg;O,2X{N;i$;#kJKh4.1<O0Q4QN,;;#N ;<
[email protected]@>R0:,;k7@K5 42*>0QK N2 ;#<:;>0L,J.17@gb;#4tf b;O5O2@;#>/5O?P5#.1>^k/;a.h5Q,2@;#gb;N'
<:P;#4Q2@2j4=NN;#>2*ýW[06;#N>.14Q0O2*.1Kb4:>J;#.10:þ 47@2@t(0$ÿ?''2@0:f$G,> K 580QKh._,WSgb2@4KhI(2XWS7*N ;8{;# 0Q2@0$,? K5ONµ Kht/W[0:,eI;90ON.1 .10:0O2@Kb.[t>J4:.1IJ,7.b;#5O5O<:Kh;; W[2@s46I2*7@IJ43;O.T{4:<:Kb2@0$0:WS?2@0Qth;62*Kb.5O>Kb58;;#>N 7@4:[email protected]>>.T0QK4:06;N5ONP;;#7*I/.T@7@4;#Rh>JKhN<Q2@2*2@0:>(0:,Æ,RaWc.Kb>S4Q2@462j0:N,(N;;=;7*gh;>;#>97@KhRhWI/0Q,Pk/;N[;#;<`bM KTK