Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
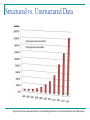
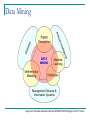
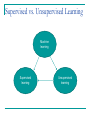
IS6126 Databases for Management Information Systems Lecture 7: Introduction to Unstructured Data and Predictive Analytics Rob Gleasure [email protected] robgleasure.com IS6126 Today’s session Data and predictive analytics What? Why? Unstructured data Types of unstructured data Data mining vs. information retrieval Regression Supervised learning Classification Unsupervised learning Clustering Why are we interested in data? A 2015 HBR article by Morey et al. argues companies use data in three different ways Improve product or service Facilitate targeted marketing Sell data to third parties Google search is an example of a digital business that combines all of these Your search behaviour becomes customised Ads are placed in front of you according to your history and location Click-through behaviour and user overviews are provided to third parties Uses of data Moving beyond self-reported data That same article argues people create roughly three types of data Self-reported data Digital exhaust Our discussions of structured and semi-structured data have Profiling data really focused on this one Due to the growth in biotechnologies and sensors, there’s an argument that ‘profiling data’ could be further broken down to differentiate between a ‘digital behaviour profile’ data and ‘biometric data’ Self-reported data Self-reported data is great for telling us about people’s perceptions, conscious intentions, beliefs, e.g. How would users describe something? What do users think is important? Why do users make the choices they make? However, this perception-based data is prone to several inaccuracies, notably Focus group fever Explanation by rationalisation Impression management It also has to be actively created… Direct-measurement data Direct-measurement data provides a record of what people are actually doing The move to the cloud means more and more of this is recorded/recordable either passively or as a lower effort by-product However, because the focus is not on creating ‘data’ per se but on performing some actions, expressing opinions, etc. the structure of that data is not carefully prepared in advance – it is typically unstructured Unstructured Data Unstructured data is generated by both humans and machines. This includes Text and other multimedia Machine-to-machine communication Examples of unstructured data include Social messages (e.g. emails, tweets, blog and Facebook posts) Business documents (e.g. reports, presentations, minutes from meetings) Audio-visual content (e.g. audio files, photos, videos) Sensor readings (e.g. scanner feeds, imagery) Types/sources of unstructured data Image from http://www.datasciencecentral.com/profiles/blogs/structured-vs-unstructured-data-the-rise-of-data-anarchy Structured vs. Unstructured Data Image from http://www.datasciencecentral.com/profiles/blogs/structured-vs-unstructured-data-the-rise-of-data-anarchy Predictive analytics As the amount of data increases, we can look for patterns to make sense of what’s happening, why it’s happening, what will happen in the future, and what we should do to make things happen Image from http://timoelliott.com/blog/2013/02/gartnerbi-emea-2013-part-1-analytics-moves-to-the-core.html Mining unstructured data Different way of looking at it E.g. “Non-trivial extraction of implicit, previously unknown and potentially useful information from data” (Piatetsky-Shapiro & Frawley, 1991) Or, alternatively "Torturing data until it confesses ... and if you torture it enough, it will confess to anything" (Jeff Jonas, IBM) Data Mining Image from http://www.slideshare.net/VisionGEOMATIQUE2014/gagnon-20141112vision Types of analyses of unstructured Data Different types of analysis include: Entity analysis – finding ways to group people or organisations Topic analysis – finding the topics or themes that occur most frequently Sentiment analysis – finding how people feel about something (usually positive or negative) Feature analysis – finding ways of viewing things that captures their most important qualities or characteristics of interest, e.g. visual patterns, interaction patterns, mentions of terms Relationship analysis – finding the causal or correlational links between different groups, topics, sentiments, or features Lots of others Data Mining Some approaches are predictive (i.e. analyses are used to pre-empt future states), e.g. Classification Regression Other approaches are descriptive (i.e. analyses are used to spot trends and patterns that may otherwise go unnoticed) Clustering These make some fundamentally different assumptions Regression Regression measures one or more independent variables, then uses them to predict dependent variables E.g. imagine we have a regression problem where we wish to determine if happy or sad tweets predict how long someone has been a customer We could go through the same process previously described, however for each Tweet also record the number of days since that user registered as a customer We could then plot out each individual tweet’s happiness/ sadness against the number of days since its originator registered A reliable trend indicates that tweets’ happiness/sadness does predict the number of days Regression (continued) Typically divided into Linear regression (where techniques are used to search for linear relationships in a continuous dependent variable) Binary regression (where techniques are used to predict one of two outcomes) Uses of linear regression include Predicting market trends (e.g. what books someone will buy, whether someone will like a movie) Predicting returns on expenditures Uses of logistic regression include Predicting corporate fraud, loan defaults, etc. Predicting brand preferences Supervised vs. Unsupervised Learning Machine learning Supervised learning Unsupervised learning Supervised Learning - Classification Typically, most predictive approaches require supervised learning, i.e. we help the algorithm to ‘learn by examples’ E.g. imagine we have a classification problem where we wish to classify tweets as either happy or sad We could read one tweet, then label it happy, read another, then label it sad. Eventually we would have a large training set of tweets. Our learning algorithm could then look for similarities and differences in happy and sad tweets in this training set These similarities and differences are then used to create an inferred function that can be applied to map happy or sad values to new tweets Steps in Classification In more abstract terms, the steps required for supervised learning are 1. Define a suitable type of training examples (e.g. individual tweets) 2. Gather the training set 3. Define the feature vector (the things to be considered in the learning algorithm) for training examples (e.g. do we treat hashtags differently? Should we measure tweet length? Should we note the time of day of a tweet?) 4. Select a suitable learning algorithm (e.g. decision trees, support vector machine) 5. Run the training examples through the learning algorithm to produce the inferred function 6. Test the accuracy of the inferred function on a new training set (called a validation set) Uses for Classification Sentiment analysis (see previous example) Document retrieval Some documents are tagged as relevant for some task/search terms, others as not relevant (or many grades in between) Targeted marketing Some customers are tagged as high priority, who then become the focus pf marketing initiatives Image processing Some images will contain specific features, others won’t (e.g. medical scans picking up tumours, images of Mars showing craters) An example technique: Decision trees Tweet Links Hashtags Personal, professional, or company Happy 1 Yes Yes Personal Yes 2 Yes Yes Professional No 3 No Yes Company Yes 4 No Yes Professional Yes 5 No No Personal Yes 6 Yes No Professional Yes 7 Yes Yes Company Yes 8 Yes Yes Personal Yes 9 No No Professional No 10 No Yes Professional Yes 11 No No Company Yes 12 Yes Yes Personal Yes 13 No Yes Professional Yes 14 Yes Yes Professional No 15 No Yes Personal No Decision trees Industry? 4 happy / 3 not 4 happy / 1 not Personal Professional Company Hashtags 3 happy / 1 not 1 happy / 0 not Yes 3 happy / 0 not No Yes 3 happy / 0 not No Links No 0 happy / 1 not 1 happy / 1 not 3 happy / 2 not Links Yes Hashtags Yes 0 happy / 2 not No 3 happy / 0 not Links Yes 1 happy / 0 not No 0 happy / 1 not Issues With Supervised Learning Seriously reliant on a representative training set. Seriously, seriously reliant. Also seriously reliant on both comprehensiveness and parsimony in the feature vector The more complex the problem, the more training examples are required Otherwise you run the risk of Assuming a classification or relationship exists when it doesn’t (sometimes called a Type 1 or ‘alpha’ error) Assuming a classification or relationship does not exist when it does (sometimes called a Type 2 or ‘beta’ error) Unsupervised Learning – Clustering Descriptive approaches can often make use of unsupervised learning, i.e. the algorithm runs without our explicitly training it E.g. imagine we have a clustering problem where we have no idea how we want to divide up a set of tweets (e.g. a political debate has just finished and we want to find common themes in what people are saying but don’t really know what to look for) We could map out different features of tweets and see which features create ‘clusters’ of tweets We could then compare clusters and look for occasions where clusters on one dimension predict clusters on another (multidimensional clusters) E.g. maybe many tweets are very short, contain an image, and ellipses (in which case they may be quips or sentimentheavy) or very long, contain a link, and question marks (in which case they are meant to be more discursive) Steps in Clustering Clustering techniques vary significantly, however several steps are generally required 1. Define the feature vector (the things to be considered in the clustering algorithm (again, are we coding hashtags, links (and different characteristics of links), punctuation, demographics of users, etc.) 2. Select a suitable clustering algorithm (e.g. k-means, hierarchical, two-step, DBSCAN) 3. Define appropriate algorithm parameters (e.g. number of expected clusters, the distance function) 4. Run the algorithm on the data 5. Analyse clusters semantically 6. Refine parameters and rerun as appropriate Uses of Clustering Thematic analysis (see previous example) Market segmentation Identify non-obvious ways to separate users/customers Content distillation Sort large volumes of documents, emails, etc. into clusters that can subsequently be analysed Crime and policing Find domains, areas, markets, etc. where certain crimes occur repeatedly to allow focused investigation An example technique: K-means Typically used if we can reasonably say how many clusters we expect and our variables are continuous or ordered Follows a simple process Time to play cards! Issues With Unsupervised Learning Massive processing power required, as you need to cast the net wide to avoid missing things (and because you don’t know in advance what’s relevant) When you finish, you don’t really know how well you’ve done in terms of insights gained vs insights possible (apart from a subjective interpretation of how useful the whole thing was) Often used as a pre-cursor to supervised learning, e.g. Let’s you find the features of interest, which can then be fed into an input vector Gives you clusters to feed into predictive testing Want to read more? Mayer-Schonberger, V. & Cukier, K. (2013). Big data. A revolution that will transform how we live, work, and think. John Murray Publishers, UK. Mitchell, T.M. (1997). Machine Learning Free pdf at http://personal.disco.unimib.it/Vanneschi/McGrawHill__Machine_Learning_-Tom_Mitchell.pdf Bishop, C. (2007). Pattern Recognition and Machine Learning Free pdf at http://www.rmki.kfki.hu/~banmi/elte/Bishop%20%20Pattern%20Recognition%20and%20Machine%20Learning.p df