Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Interactive Visualization and Tuning
of Multi-Dimensional Clusters for
Indexing
Dasari Pavan Kumar
(MS by Research Thesis)
IIIT Hyderabad
Centre for Visual Information Technology
Overview
• Provide a framework to generate better
clusters for high dimensional data points
IIIT Hyderabad
• Provide a fast cluster analysis/generation tool
Data, Data, Data !
• Digital data creation at an unprecedented rate
• Data is collected to extract/search “valuable”
information
– A difficult task however!
• Data generation in previous decade consisted
mostly of textual information
IIIT Hyderabad
– Inverted Index, suffix trees, N-grams, etc
More data !
• Flickr, Youtube, etc changed the game
– Non-textual information (images)
– Huge amounts of data!
• New methods! (Content based Image Retrieval)
– Underlying processes remain similar
• Why image search?
IIIT Hyderabad
– Copyright Infringement, Offensive, Education, etc
Multi-dimensional Multi-variate data
• Stock markets
• Weather/climate
• Business
IIIT Hyderabad
Huge datasets – multiple dimensions. Finding “insights”
can’t be fully automated.
Data Visualization
• Human intelligence/cognition is unmatchable
by computers
• Cluster analysis – descriptive modeling
• Information Visualizations to support analysis
IIIT Hyderabad
– Identify important features/patterns
Past Attempts!
• XMDV tool (M. Ward)
– Scatter-plot matrix
– Parallel Coordinate Plot
• Cluster tree (Stuetzle)
IIIT Hyderabad
• Cone trees (Robertson et. al)
What if you have millions of highdimensional data points?
Indexing images/videos
• Extract feature vectors from
images
• Apply clustering to compute bag
of words
IIIT Hyderabad
• Generate feature histogram and
perform some ML methods
Indexing images/videos
• Extract feature vectors from
images
• Apply clustering to compute
bag of words
IIIT Hyderabad
• Generate feature histogram
and perform some ML methods
Using SIFT features
• The fundamental problem
– sheer volume of data
• No. of dimensions – 128
• No. of data points – in millions
IIIT Hyderabad
• Other low-level image features exist
– GLOH, steerable filter, spin images
Clusters + visualization
• The problem
– choosing the right bag of words (clusters)
IIIT Hyderabad
• Better visual words lead to better classification
Cluster analysis
• Provide a framework for user to
– Identify better subspaces
– Efficiently/quickly compute clusters
IIIT Hyderabad
– Compare clustering schemas
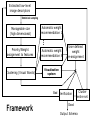
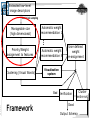
Extracted low-level
image descriptors
Statistical sampling
Manageable size
(high dimensional)
Automatic weight
recommendation 1
Priority/Weight
assignment to features
Automatic weight
recommendation N
Clustering (Visual Words)
Visualization
system
User defined
weight
re-assignment
Bad Verification
Framework
Cluster
entire set
Good
Output Schema
IIIT Hyderabad
Tool
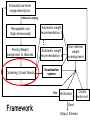
Extracted low-level
image descriptors
Statistical sampling
Manageable size
(high dimensional)
Automatic weight
recommendation 1
Priority/Weight
assignment to features
Automatic weight
recommendation N
Clustering (Visual Words)
Visualization
system
User defined
weight
re-assignment
IIIT Hyderabad
Bad Verification
Framework
Cluster
entire set
Good
Output Schema
Why prioritize dimensions?
• Dimensionality reduction !!
– Feature transformation
IIIT Hyderabad
– Feature selection
Why not feature transformation?
• Dimensions can be redundant/irrelevant
– Hence PCA cant be trivially applied
• Clusters could be lost in cloud of
dimensions (curse of dimensionality)
IIIT Hyderabad
• Difficult to interpret the combination
Feature selection
• Wrapper model
– “wrap” selection process around the mining
algorithm
– Go hand in hand giving little control
• Filter model
IIIT Hyderabad
– Examine intrinsic properties
“Interesting” dimensions
• Without any rank
– Analyze density distribution based on grids
– Difficult to compare since its highly dependent on density
parameter
• Rank dimensions
– Based on distribution of data
• Uniformity (Entropy)
• No. of outliers
• No. of unique values
IIIT Hyderabad
d>(Q3+1.5*IQR) || d<(Q1-1.5*IQR)
Ranked dimensions
• Assign weights based on the amount
of “interestingness”
– 1D Histogram of distribution
– 2D correlations - PCP
• How do we assign weights?
• Manual
IIIT Hyderabad
– Automatic suggestions !
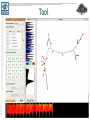
Glyph view
• Standard SIFT glyph
• Bar chart
– Length – rank
– Color - weight
IIIT Hyderabad
• Colormap
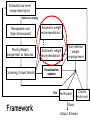
Extracted low-level
image descriptors
Statistical sampling
Manageable size
(high dimensional)
Automatic weight
recommendation 1
Priority/Weight
assignment to features
Automatic weight
recommendation N
Clustering (Visual Words)
Visualization
system
User defined
weight
re-assignment
Bad Verification
Framework
Cluster
entire set
Good
Output Schema
Data clustering
• Sample data set
– 1.3 million points with 128
dimensions
• Cluster such data on a
commodity pc
IIIT Hyderabad
– Almost impossible
Data clustering
• Plug-in for any cluster
technique
– Currently using k-means (GPU)
• Currently 200 iterations for 1.3
million SIFT vectors
IIIT Hyderabad
– 12 sec for each iteration for 1000
clusters
Extracted low-level
image descriptors
Statistical sampling
Manageable size
(high dimensional)
Automatic weight
recommendation 1
Priority/Weight
assignment to features
Automatic weight
recommendation N
Clustering (Visual Words)
Visualization
system
User defined
weight
re-assignment
Bad Verification
Framework
Cluster
entire set
Good
Output Schema
Cluster Viz.
• Visualizing clusters over 128
dimensions
– Not feasible
• Re-project into 2D space
– Necessity for some sort of layout
• Plug-in any graph drawing
IIIT Hyderabad
– Current – 2D force based
Graph representation
• Compute cluster tree of
nearest neighbor density
– Similar nodes must be close
– Can be estimated using MST
• Generate minimum spanning
tree (MST) of cluster centers
IIIT Hyderabad
– Single linkage dendogram
– Prim’s method
Graph drawing
• Use a GPU implementation of force based
graph layout
– Takes 0.2 sec for 1000 nodes
IIIT Hyderabad
• Drill-down “visual word” to actually see
the “sift” interest points to understand
the similarity
MST with layout
MST without layout
IIIT Hyderabad
Similar looking regions clustered into the same id
Cluster validation
• Two clustering schemas
– Visually not feasible to compare
Computationally not feasible
• Three basic strategies
– Internal – compare schema C with proximity matrix
– External – build an independent partition according
to our intuition
• Comparison with schema C or proximity matrix.
IIIT Hyderabad
– Relative – choose the one that best fits !!
Relative validity
• Some indices
– RS value
– Davies-Bouldin index
– SD index
GPU implementation
takes 1 second
IIIT Hyderabad
Around 1 minute for each schema C on CPU
Validity indices
• Indices plotted over a line graph
– Obtain min/max of the graph – optimal clusters Nc
IIIT Hyderabad
Index
Iteration
Extracted low-level
image descriptors
Statistical sampling
Manageable size
(high dimensional)
Automatic weight
recommendation 1
Priority/Weight
assignment to features
Automatic weight
recommendation N
Clustering (Visual Words)
Visualization
system
User defined
weight
re-assignment
Bad Verification
Framework
Cluster
entire set
Good
Output Schema
Automatic weight recommendation
• Only a suggestive process
IIIT Hyderabad
• Final decision left to user
Results on UIUC image collection
• A total of 4485 images
• 15 categories
IIIT Hyderabad
• Mean classification accuracy of 57.6% for SIFT
with DoG
Interesting observation
• 135◦, 215◦, 270◦
– Lower weights assigned by automatic schemas
• Same with corner cells
IIIT Hyderabad
• Ds = {4, 12, 22, 43, 44, 54, 55, 71,
78, 79, 83, 84, 110, 116}
1D histograms corresponding to dimensions (a)84, (b) 110, (c) 124
Results on UIUC image collection
• More clusters does not necessarily mean
better classification
IIIT Hyderabad
• Fei-Fei et al. report a mean accuracy of
52.5%
Summary
• Provide a framework for better cluster
generation
• Provide fast cluster analysis/generation tool
for a commodity pc enabled with GPU
• Able to analyze distributions across dimensions
IIIT Hyderabad
– Identified redundant dimensions
• Able to achieve higher classification ratios
with relative ease
Publications
IIIT Hyderabad
• Interactive Visualization and Tuning of SIFT
Indexing, Dasari Pavan Kumar and
P.J.Narayanan, Vision, Modelling and
Visualization, 2010, Siegen, Germany
Limitations
• Limited by GPU and CPU memory
• User needs to get familiarized with the tool
• Visual decoding of data is sometimes difficult
IIIT Hyderabad
• Cluster generation still depends on parameters
like K (no. of clusters).
Future Work
• Provide a brush for PCP view
• Incorporate support for subspace clustering
IIIT Hyderabad
• Conduct experiments based on wrapper
clustering methods
IIIT Hyderabad
Thank you